一种基于强化学习的车速控制方法、装置、设备和介质与流程
本发明涉及计算机,尤其涉及一种基于强化学习的车速控制方法、装置、设备和介质。
背景技术:
1、随着汽车的发展,用户越来越注重车辆行驶的安全性。汽车的制动能力是影响车辆行驶安全性的重要因素之一。滑移率可用于表征车辆的制动能力。滑移率是指在刹车或加速时车轮和路面间所产生的滑移距离与车辆移动距离之间的比值。车辆在抓地性最佳的情况下仍会存在5%-10%的滑移率,例如,车轮转动了100m的距离时车子只移动了90m-95m。
2、目前,通常是利用汽车防抱死制动系统(antilock brake system,abs)对车辆制动力进行控制。例如,abs在汽车制动时防止车轮抱死,从而避免前轮和/或后轮发生侧滑,进而保持制动时的方向稳定性。在车辆进行制动或加速时,abs会基于车辆出厂时标定的车轮线性特性和该车轮线性特性对应的滑动率控制方式对车速进行控制。然而,车辆在被使用后,每个车轮的磨损程度是不同的,还会存在某个车轮换新的情况,导致了车轮特性发生了非线性变化。此时,仍基于车辆出厂时标定的车轮线性特性和该车轮线性特性对应的滑动率控制方式对车速进行控制,会导致车轮的滑动率变大,并且无法保持车辆制动或加速时的方向稳定性,降低了车辆行驶的安全性和用户的驾驶体验。
技术实现思路
1、本发明提供了一种基于强化学习的车速控制方法、装置、设备和介质,以有效控制车速,从而保持车辆制动或加速时的稳定性,进一步提高车辆行驶的安全性和用户的驾驶体验。
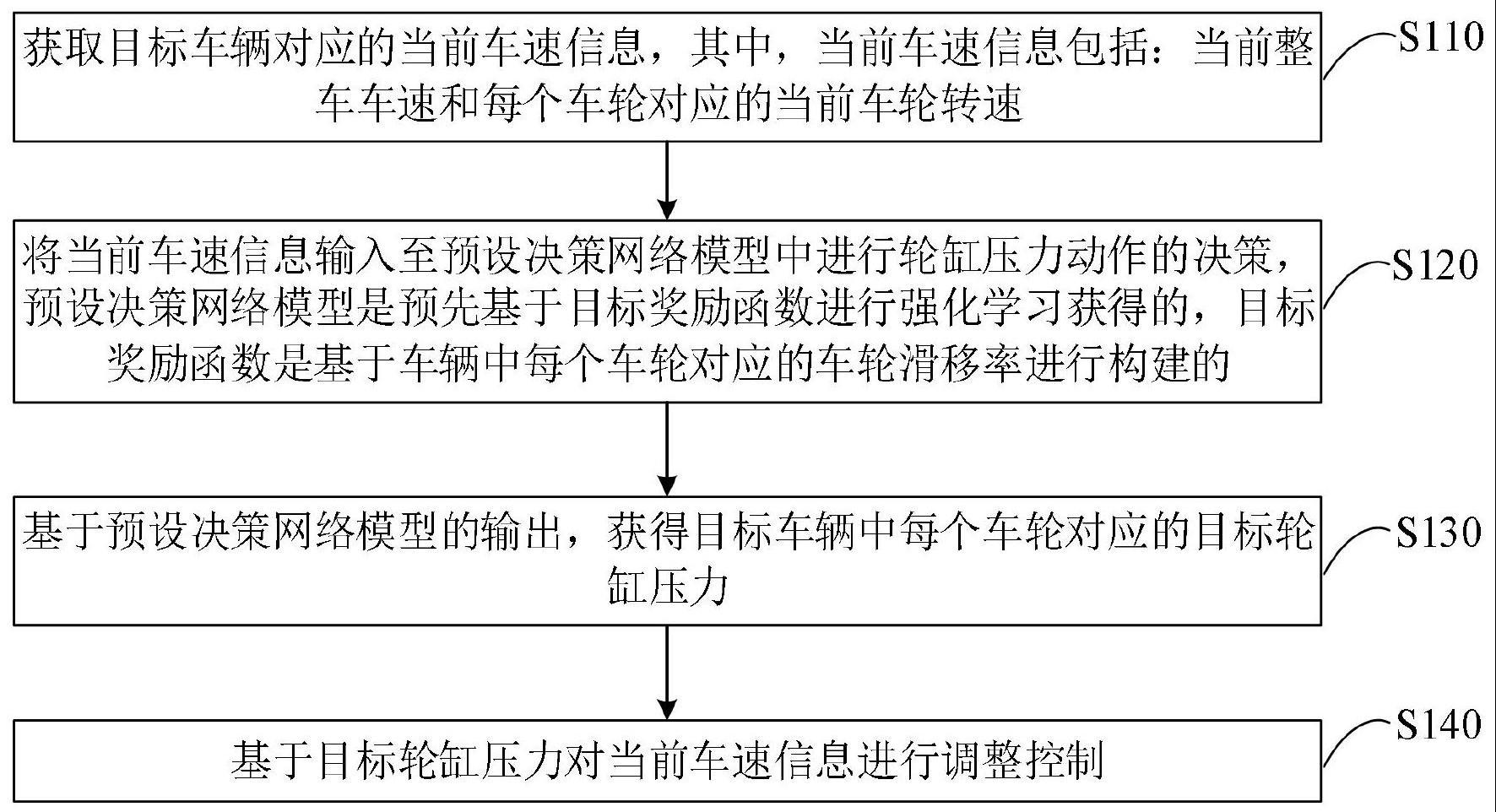
2、根据本发明的一方面,提供了一种基于强化学习的车速控制方法,该方法包括:
3、获取目标车辆对应的当前车速信息,其中,所述当前车速信息包括:当前整车车速和每个车轮对应的当前车轮转速;
4、将所述当前车速信息输入至预设决策网络模型中进行轮缸压力动作的决策,所述预设决策网络模型是预先基于目标奖励函数进行强化学习获得的,所述目标奖励函数是基于车辆中每个车轮对应的车轮滑移率进行构建的;
5、基于所述预设决策网络模型的输出,获得所述目标车辆中每个车轮对应的目标轮缸压力;
6、基于所述目标轮缸压力对所述当前车速信息进行调整控制。
7、根据本发明的另一方面,提供了一种基于强化学习的车速控制装置,该装置包括:
8、当前车速信息获取模块,用于获取目标车辆对应的当前车速信息,其中,所述当前车速信息包括:当前整车车速和每个车轮对应的当前车轮转速;
9、动作决策模块,用于将所述当前车速信息输入至预设决策网络模型中进行轮缸压力动作的决策,所述预设决策网络模型是预先基于目标奖励函数进行强化学习获得的,所述目标奖励函数是基于车辆中每个车轮对应的车轮滑移率进行构建的;
10、目标轮缸压力获得模块,用于基于所述预设决策网络模型的输出,获得所述目标车辆中每个车轮对应的目标轮缸压力;
11、当前车速信息调整模块,用于基于所述目标轮缸压力对所述当前车速信息进行调整控制。
12、根据本发明的另一方面,提供了一种电子设备,所述电子设备包括:
13、至少一个处理器;以及
14、与所述至少一个处理器通信连接的存储器;其中,
15、所述存储器存储有可被所述至少一个处理器执行的计算机程序,所述计算机程序被所述至少一个处理器执行,以使所述至少一个处理器能够执行本发明任一实施例所述的基于强化学习的车速控制方法。
16、根据本发明的另一方面,提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机指令,所述计算机指令用于使处理器执行时实现本发明任一实施例所述的基于强化学习的车速控制方法。
17、本发明实施例的技术方案,通过获取目标车辆对应的当前车速信息,以便基于获取的当前车速信息,确定出当前时刻目标车辆中每个车轮对应的调整策略,从而对比上一时刻和当前时刻目标车辆中每个车轮对应的调整策略。其中,所述当前车速信息包括:当前整车车速和每个车轮对应的当前车轮转速;将所述当前车速信息输入至预设决策网络模型中进行轮缸压力动作的决策,所述预设决策网络模型是预先基于目标奖励函数进行强化学习获得的,所述目标奖励函数是基于车辆中每个车轮对应的车轮滑移率进行构建的;基于所述预设决策网络模型的输出,获得所述目标车辆中每个车轮对应的目标轮缸压力;基于所述目标轮缸压力对所述当前车速信息进行调整控制,使得每个车轮不会出现抱死的情况,且可以将车轮的滑移率控制在最优滑移率的范围内,从而有效控制车速,并有效缩短车辆的制动距离,进而保持车辆制动或加速时的稳定性,进一步提高车辆行驶的安全性和用户的驾驶体验。
18、应当理解,本部分所描述的内容并非旨在标识本发明的实施例的关键或重要特征,也不用于限制本发明的范围。本发明的其它特征将通过以下的说明书而变得容易理解。
技术特征:
1.一种基于强化学习的车速控制方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,基于车辆中每个车轮对应的车轮滑移率构建目标奖励函数,包括:
3.根据权利要求2所述的方法,其特征在于,每个车轮对应的车轮奖励函数是关于车轮滑移率的分段奖励函数。
4.根据权利要求3所述的方法,其特征在于,基于车辆中每个车轮对应的车轮滑移率,确定每个车轮对应的车轮奖励函数,包括:
5.根据权利要求2所述的方法,其特征在于,基于各个所述车轮奖励函数,构建目标奖励函数,包括:
6.根据权利要求1所述的方法,其特征在于,基于所述目标轮缸压力对所述当前车速信息进行调整控制,包括:
7.根据权利要求1所述的方法,其特征在于,所述预设决策网络模型的强化学习过程,包括:
8.一种基于强化学习的车速控制装置,其特征在于,包括:
9.一种电子设备,其特征在于,所述电子设备包括:
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储有计算机指令,所述计算机指令用于使处理器执行时实现权利要求1-7中任一项所述的基于强化学习的车速控制方法。
技术总结
本发明公开了一种基于强化学习的车速控制方法、装置、设备和介质。该方法包括:获取目标车辆对应的当前车速信息,其中,当前车速信息包括:当前整车车速和每个车轮对应的当前车轮转速;将当前车速信息输入至预设决策网络模型中进行轮缸压力动作的决策,预设决策网络模型是预先基于目标奖励函数进行强化学习获得的,目标奖励函数是基于车辆中每个车轮对应的车轮滑移率进行构建的;基于预设决策网络模型的输出,获得目标车辆中每个车轮对应的目标轮缸压力;基于目标轮缸压力对当前车速信息进行调整控制。通过本公开实施例的技术方案,可以有效控制车速,从而保持车辆制动或加速时的稳定性,进一步提高车辆行驶的安全性和用户的驾驶体验。
技术研发人员:汪娟,周俊杰
受保护的技术使用者:南栖仙策(南京)高新技术有限公司
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!