一种蛋白合成筛选方法与流程
本发明涉及一种蛋白翻译起始区筛选方法,尤其涉及一种快速便捷的蛋白翻译起始区筛选方法以提高目的蛋白的产量,以及相应的高通量蛋白筛选芯片。
背景技术:
蛋白质作为潜在的治疗性生物制剂、药物靶标和生物催化剂,具有重要的科学和实际意义。目前重组蛋白的生产仍多以活细胞作为工厂,将目的蛋白的基因序列,插入合适的表达载体并转入活细胞中表达和生产蛋白。现有技术已实现了众多蛋白的成功表达和生产,然而许多具有重要意义的蛋白由于各种原因仍难以有效表达,比如表达量过低的蛋白、难溶蛋白以及细胞毒性蛋白等。
为解决这些难表达蛋白的问题,研究者们进行了大量实验。重组蛋白的表达本质上是使用成熟的重组dna技术,将特定基因的dna序列构建为蛋白质表达的模板,以dna为模板转录出相应的mrna,以mrna为模板翻译合成蛋白质的过程。重组蛋白的表达模板一般包含5'utr区(启动子、核糖体结合位点)起始密码子、目的蛋白序列、终止密码子。位于起始密码子上下游的翻译起始区是蛋白质整体翻译水平的主要决定因素(simmonslc,yansuradg.translationallevelisacriticalfactorforthesecretionofheterologousproteinsinescherichiacoli.natbiotechnol.1996;14(5):629-634.doi:10.1038/nbt0596-629;seosw,yangjs,kimi,etal.predictivedesignofmrnatranslationinitiationregiontocontrolprokaryotictranslationefficiency.metabeng.2013;15:67-74.doi:10.1016/j.ymben.2012.10.006)。ojima-katoetal.(ojima-katot,nagais,nakanoh.n-terminalskikpeptidetagmarkedlyimprovesexpressionofdifficult-to-expressproteinsinescherichiacoliandsaccharomycescerevisiae.jbioscibioeng.2017;123(5):540-546.doi:10.1016/j.jbiosc.2016.12.004)通过在起始密码子后添加编码丝氨酸-赖氨酸-异亮氨酸-赖氨酸序列(skik标签)后,使重组蛋白产量提高2~8倍。nguyenetal.(nguyentkm,kimr,sonrg,packsp.thent11,anovelfusiontagforenhancingproteinexpressioninescherichiacoli.applmicrobiolbiotechnol.2019;103(5):2205-2216.doi:10.1007/s00253-018-09595-w)报道的nt-11标签则增强了其所测试蛋白的可溶性。此外重组蛋白中常见的gst、sumo等标签均是常用的提高蛋白可溶产量的融合标签。
然而蛋白的复杂性和独特性决定了没有一种载体设计可以高效的表达所有种类蛋白,例如gst标签会导致部分蛋白活性降低,skik也会导致一部分的蛋白可溶性下降。因此每一种新的目的蛋白需要合成时均需要构建大量表达载体以选出最优的设计。由于在筛选最适的表达载体需要经过复杂的生物学实验如转入感受态细胞,测序,提质粒,转入新的感受态细胞表达,蛋白纯化鉴定等,需要大量的人力、物力以及时间。其中构建表达载体需1天;转入感受态细胞,平板培养过夜并在第二天挑克隆交送测序公司测序验证,得到测序结果且结果正确至少需2天,然而实际操作中由于不同载体构建难易不同,很可能会花费更长的时间;测序正确后提出质粒转入新的表达宿主并培养过夜需1天,诱导表达需1天,蛋白纯化及鉴定需1天,在最理想的状态下,鉴定一个新蛋白的表达至少需要6天的时间。针对构建载体的繁琐性,invitrogen公司开发的gateway体系可以使实现基因高效的克隆入多个表达载体中,在构建入门载体后无需更多复杂的亚克隆技术;但由于gateway技术提供的载体相对固定,自主改造仍需重复上述载体构建的复杂步骤,并且gateway所需的酶和载体价格昂贵,难以被广泛使用。
因此需要以一种快速便捷的蛋白翻译起始区筛选方法以提高目的蛋白产量。
技术实现要素:
本发明的主要目的就是针对以上现状,提供一种快速便捷的蛋白翻译起始区筛选方法,以克服现有技术中的不足。
本发明的另一主要目的在于提供一种高通量蛋白筛选芯片。
为实现前述发明目的,本发明采用的技术方案包括:
本发明实施例提供了一种蛋白筛选芯片,其包括液流层、气动控制层以及弹性膜,所述弹性膜设置于所述液流层和气动控制层之间;
其中,所述液流层包括复数个结构单元,每个所述结构单元包括相互连通的液流管道,每个所述结构单元均与作为输入管道的第一液流管道、作为输入或输出管道的第二液流管道连通,各结构单元之间通过第三液流管道连通;
所述气动控制层至少用于驱使弹性膜产生趋向液流层的形变和/或位移,从而在所述至少一液流管道内产生能够驱使液流流动的力;所述气动控制层包括沿所述结构单元长度方向依次分布设置的第一气动控制管道、第二气动控制管道、第三气动控制管道、第四气动控制管道及第五气动控制管道,所述第一气动控制管道与第一液流管道对应设置,所述第四气动控制管道与第三液流管道对应设置且能够形成微阀,所述第五气动控制管道与第二液流管道对应设置。
在一些实施例中,每个所述结构单元包括可供液流循环流动且进行反应的循环液流管道,所述循环液流管道包括第一区域、第二区域和第三区域,所述第一区域和第二区域位于第三液流管道上方,并且,所述第二区域靠近所述第三液流管道,所述第三区域位于第三液流管道下方。
在一些实施例中,所述第四气动控制管道包括相互垂直且连通设置的横向延伸部和纵向延伸部,所述横向延伸部与结构单元垂直交叉设置,所述纵向延伸部与所述第三液流管道垂直交叉且形成所述微阀,当向所述第四气动控制管道通入压力不小于一阈值的气体时,所述第四气动控制管道能够驱使所述弹性膜产生趋向液流层的形变和/或位移,从而将第三液流管道在选定位置处关闭。
本发明实施例还提供了一种蛋白合成筛选方法,所述筛选方法主要基于前述的蛋白筛选芯片而实施,并且所述筛选方法包括:
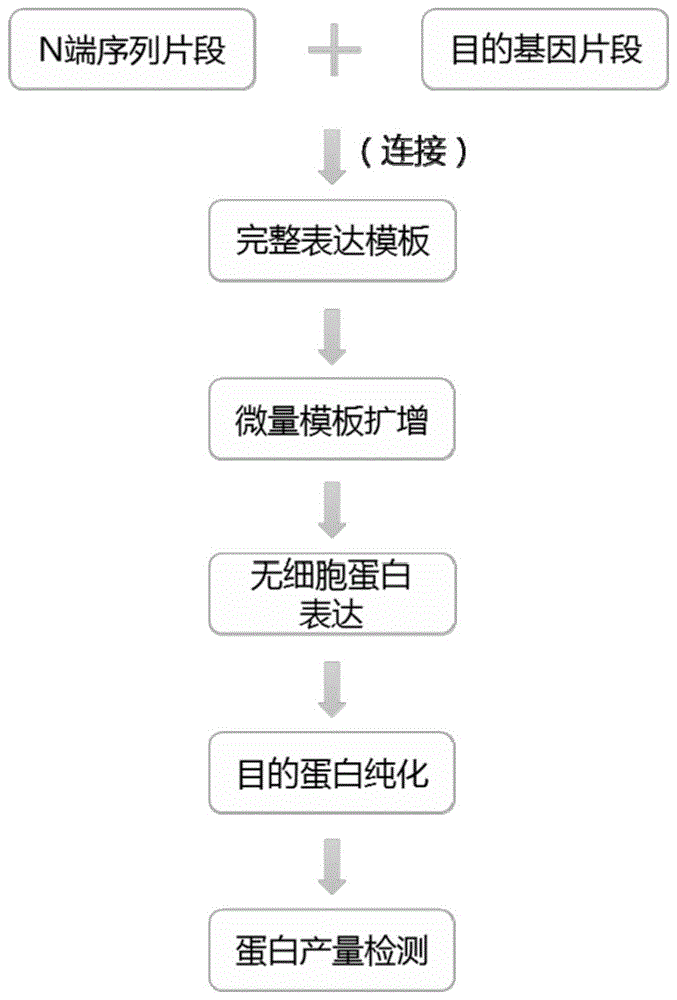
使待筛选的n端序列片段、目的基因片段和连接混合液在循环液流管路内进行连接反应;
将扩增混合液输入所述循环液流管路,并进行扩增反应;
将无细胞蛋白表达混合液输入所述循环液流管路,并进行无细胞蛋白表达反应,之后进行富集、纯化处理,获得目的蛋白。
与现有技术相比,本发明的优点包括:
1)本发明提供的快速便捷的蛋白翻译起始区筛选方法是在高通量蛋白筛选芯片上进行的,该方法集目的基因模板优化、扩增、蛋白表达、纯化和检测一体化,操作简单便捷,可在一天时间内完成对目的蛋白最适载体的筛选,以提高目的蛋白产量;
2)本发明提供的高通量蛋白筛选芯片结构设计合理,可实现目的基因模板n端序列片段与目的基因的连接、微量目的基因模板的扩增、蛋白质的体外表达、富集并纯化所表达的目的蛋白、同时可实现富集蛋白表达情况的检测。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明中记载的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明一典型实施方案中快速便捷的蛋白翻译起始区筛选方法的流程及原理示意图,以一个结构单元为例;
图2是本发明一典型实施方案中高通量蛋白筛选芯片的俯视图;
图3是图2中高通量蛋白筛选芯片沿1e方向的剖视图;
图4是本发明一典型实施方案中向高通量蛋白筛选芯片的气动控制管道1203和第四气动控制1104充入高压气体实现每个反应步骤之间的换液的示意图;
图5是本发明一典型实施方案中关闭第一气动控制管道、第五气动控制管道,并向第四气动控制管道中充入高压气体时的状态示意图;
图6是本发明一典型实施方案中向高通量蛋白筛选芯片中通入蛋白纯化磁珠的状态示意图。
附图标记说明:110-液流层,1101-结构单元,a-第一区域,b-第二区域,c-第三区域,1102-第一液流管道,1103-第二液流管道,1104-第三液流管道,120-气动控制层,1201-第一气动控制管道,1202-第二气动控制管道,1203-第三气动控制管道,1204-第四气动控制管道,12041-纵向延伸部,12042-横向延伸部,1205-第五气动控制管道,12021、12022-气动控制管道,130-透气弹性膜。
具体实施方式
鉴于现有技术的不足和缺陷,本案发明人经长期研究和大量实践,得以提出本发明的技术方案,提供了一种快速便捷的蛋白翻译起始区筛选方法以提高目的蛋白的产量,以及相应的高通量蛋白筛选芯片。如下将对该技术方案、其实施过程及原理等作进一步的解释说明。
下文将对本发明的技术方案作更为详尽的解释说明。但是,应当理解,在本发明范围内,本发明的上述各技术特征和在下文(如实施例)中具体描述的各技术特征之间都可以互相组合,从而构成新的或优选的技术方案。限于篇幅,在此不再一一累述。
本发明实施例的一个方面提供的一种蛋白筛选芯片包括液流层、气动控制层以及弹性膜,所述弹性膜设置于所述液流层和气动控制层之间;
其中,所述液流层包括复数个结构单元,每个所述结构单元包括相互连通的液流管道,每个所述结构单元均与作为输入管道的第一液流管道、作为输入或输出管道的第二液流管道连通,各结构单元之间通过第三液流管道连通;
所述气动控制层至少用于驱使弹性膜产生趋向液流层的形变和/或位移,从而在所述至少一液流管道内产生能够驱使液流流动的力;所述气动控制层包括沿所述结构单元长度方向依次分布设置的第一气动控制管道、第二气动控制管道、第三气动控制管道、第四气动控制管道及第五气动控制管道,所述第一气动控制管道与第一液流管道对应设置,所述第四气动控制管道与第三液流管道对应设置且能够形成微阀,所述第五气动控制管道与第二液流管道对应设置。
在一些优选实施例中,所述弹性膜可以是聚苯乙烯膜,优选为透气弹性膜,例如聚二甲基硅氧烷等,但不限于此。
在一些优选实施例中,每个所述结构单元包括可供液流循环流动且进行反应的循环液流管道,所述循环液流管道包括第一区域、第二区域和第三区域,所述第一区域和第二区域位于第三液流管道上方,并且,所述第二区域靠近所述第三液流管道,所述第三区域位于第三液流管道下方。
在一些优选实施例中,所述第一气动控制管道对应设置于所述第一液流管道的正上方,至少用以驱使所述弹性膜产生趋向液流层的形变和/或位移,从而使将所述第一液流管道在选定位置处关闭。
在一些优选实施例中,所述第三气动控制管道对应设置于循环液流管道的第二区域的正上方,至少用以驱使所述弹性膜产生趋向液流层的形变和/或位移,从而使将所述循环液流管道的第二区域在选定位置处关闭。
在一些优选实施例中,所述第二气动控制管道对应设置于循环液流管道的第一区域的正上方。
在一些优选实施例中,所述气动控制层还包括至少一微泵,每一微泵由第二气动控制管道的两条以上气动控制管道形成,所述两条以上气动控制管道与循环液流管道在不同位置处交叉,当在设定时段向所述两条以上气动控制管道内分别输入具有不同压力的气体时,所述两条以上气动控制管道能够分别驱使所述弹性膜的不同局部区域产生不同程度的形变和/或位移,从而在所述循环液流管道内产生能够驱使各种液流流动并均匀混合的力。
在一些优选实施例中,所述第四气动控制管道包括相互垂直且连通设置的横向延伸部和纵向延伸部,所述横向延伸部与结构单元垂直交叉设置,所述纵向延伸部与所述第三液流管道垂直交叉且形成所述微阀,当向所述第四气动控制管道通入压力不小于一阈值的气体时,所述第四气动控制管道能够驱使所述弹性膜产生趋向液流层的形变和/或位移,从而将第三液流管道在选定位置处关闭。
在一些优选实施例中,所述第五气动控制管道对应设置于所述第二液流管道的正上方,至少用以驱使所述弹性膜产生趋向液流层的形变和/或位移,从而使将所述第二液流管道在选定位置处关闭。
综上,本发明的高通量蛋白筛选芯片结构设计合理,可实现目的基因模板n端序列片段与目的基因的连接、微量目的基因模板的扩增、蛋白质的体外表达、富集并纯化所表达的目的蛋白、同时可实现富集蛋白表达情况的检测。
本发明实施例的另一个方面提供的一种蛋白合成筛选方法主要基于前述的高通量蛋白筛选芯片而实施,并且所述筛选方法包括:
使待筛选的n端序列片段、目的基因片段和连接混合液在循环液流管路内进行连接反应;
将扩增混合液输入所述循环液流管路,并进行扩增反应;
将无细胞蛋白表达混合液输入所述循环液流管路,并进行无细胞蛋白表达反应,之后进行富集、纯化处理,获得目的蛋白。
在一些优选实施例中,所述蛋白翻译起始区筛选方法具体包括:
将待筛选的n端序列片段从第二液流管道输入并预埋在所述结构单元的循环液流管道的第三区域中,并向第五气动控制管道内充入高压气体;
将目的基因片段和连接混合液从第一液流管道输入所述结构单元的循环液流管道,并向第一气动控制管道、第四气动控制管道内充入高压气体,之后启动第二气动控制管道组成的微泵,并使待筛选的n端序列片段、目的基因片段和连接混合液混合所获反应液进行连接反应,获得用于蛋白表达的线性模板。
进一步地,所述连接反应采用的方法可以包括黏性末端连接、平末端连接以及同源重组等,优选为t4连接酶连接,反应温度为4~40℃,反应时间为5min~24h。
在一些优选实施例中,所述蛋白翻译起始区筛选方法具体包括:
将扩增混合液从第三液流管道输入所述结构单元的循环液流管道,并向第四气动控制管道内充入高压气体,撤去第三气动控制管道内的高压气体,之后启动第二气动控制管道组成的微泵,并使所述线性模板和扩增混合液混合所获反应液于20~45℃进行扩增反应5min~24h,获得扩增产物。
进一步地,所述扩增的方法可以为等温扩增法,优选为phi29聚合酶等温扩增,反应温度为20~45℃,优选为37~45℃,反应时间为2~24小时。
在一些优选实施例中,所述蛋白翻译起始区筛选方法具体包括:
将无细胞蛋白表达混合液从第三液流管道输入所述结构单元的循环液流管道,并向第四气动控制管道内充入高压气体,撤去第三气动控制管道内的高压气体,之后启动第二气动控制管道组成的微泵,并使所述扩增产物和无细胞蛋白表达混合液混合所获反应液于15~40℃进行无细胞蛋白表达反应2~24h,获得目的蛋白。
进一步地,所述无细胞蛋白表达反应的温度为20~40℃。
在一些优选实施例中,所述蛋白翻译起始区筛选方法具体包括:
将至少用以蛋白纯化的磁珠从第三液流管道输入所述循环液流管道,且使磁珠均匀分布在每个结构单元内,并向第四气动控制管道内充入高压气体,撤去第三气动控制管道内的高压气体,之后启动第二气动控制管道组成的微泵,将所述目的蛋白和磁珠混合均匀,使目的蛋白富集到磁珠上,之后将磁铁置于第三气动控制管道与第二气动控制管道之间,从而将富集有目的蛋白的磁珠固定在每个结构单元内;以及,
将洗脱液从第三液流管道输入所述循环液流管道,并向第四气动控制管道内充入高压气体,撤去第三气动控制管道内的高压气体,之后启动第二气动控制管道组成的微泵,将所述富集有目的蛋白的磁珠和洗脱液混合均匀以进行洗脱,从而收集目的蛋白。
进一步地,该方法所提供的芯片可实现富集并纯化所表达的目的蛋白,可根据不同的目的蛋白选择合适纯化磁珠,优选为组氨酸标签蛋白纯化磁珠。
进一步地,所述筛选方法还包括:对所述目的蛋白进行检测。
在一些优选实施例中,所述筛选方法具体包括:
将显色液从第三液流管道输入所述循环液流管道,并向第四气动控制管道内充入高压气体,撤去第三气动控制管道内的高压气体,之后启动第二气动控制管道组成的微泵,将所述目的蛋白和显色液混合均匀,并以光学检测装置收集产生的光学信号,从而实现对所表达的目的蛋白的定量分析。
进一步地,该方法所提供的芯片可实现富集蛋白表达情况的检测,可根据不同的目的蛋白选择合适的检测方法,优选为采用bradford法对所述目的蛋白进行检测。
进一步地,所述筛选方法还包括:先向第三气动控制管道内输入高压气体,撤去第四气动控制管道内的高压气体,并将清洗液从第三液流管道输入所述循环液流管道进行清洗,之后再通入扩增混合液、无细胞蛋白表达混合液、磁珠或洗脱液等。
综上所述,本发明提供的快速便捷的蛋白翻译起始区筛选方法是在高通量蛋白筛选芯片上进行的,该方法集目的基因模板优化、扩增、蛋白表达、纯化和检测一体化,操作简单便捷,可在一天时间内完成对目的蛋白最适载体的筛选,以提高目的蛋白产量。
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行详细的描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图2和图3所示,本发明一典型实施例的高通量蛋白筛选芯片由三个上下层叠的结构层组成。底层是液流层110,上层是气动控制层120,两层之间有透气弹性膜130相隔。液流层110中有12个结构单元1101组成的液流管道,上方为统一作为输入管道的第一液流管道1102,下方为作为各结构单元单独的输入或输出管道的第二液流管道1103,各结构单元间由第三液流管道1104相连,第三液流管道1104最左侧输入,最右侧输出。各液流管道除特殊说明外,宽度均为200微米,高度为200微米。气动控制层120中有第一气动控制管道1201、第二气动控制管道1202、第三气动控制管道1203、第四气动控制管道1204及第五气动控制管道1205。其中第四气动控制管道1204包括横向延伸部12042和纵向延伸部12041,横向延伸部12042与结构单元1101垂直交叉,横向延伸部12042的截面积较小,不会与结构单元1101在交叉处形成微阀;纵向延伸部12041与横向延伸部12042连通,纵向延伸部12041与结构单元1101之间的第三液流管道1104垂直交叉形成微阀,实现各结构单元间的分隔功能。其中气动控制层中分布有循环驱动第二气动控制管道1202组成的微泵。各气动控制管道除特殊说明外宽度均为200微米,高度为200微米。
具体的,每个所述结构单元1101包括可供液流循环流动且进行反应的循环液流管道,所述循环液流管道包括第一区域a、第二区域b和第三区域c,所述第一区域a和第二区域b位于第三液流管道1104上方,并且,所述第二区域b靠近所述第三液流管道1104,所述第三区域c位于第三液流管道1104下方。
所述第一气动控制管道1201对应设置于所述第一液流管道1102的正上方,至少用以驱使所述透气弹性膜产生趋向液流层的形变和/或位移,从而使将所述第一液流管道在选定位置处关闭。所述第二气动控制管道1202对应设置于循环液流管道的第一区域a的正上方,所述第三气动控制管道1203对应设置于循环液流管道的第二区域b的正上方,至少用以驱使所述透气弹性膜产生趋向液流层的形变和/或位移,从而使将所述循环液流管道的第二区域b在选定位置处关闭。所述第五气动控制管道1205对应设置于所述第二液流管道1103的正上方,至少用以驱使所述透气弹性膜产生趋向液流层的形变和/或位移,从而使将所述第二液流管道在选定位置处关闭。
请参阅图1所示,作为一更为具体的实施案例之一,本发明的快速便捷的蛋白翻译起始区筛选方法具体包括以下步骤:
(1)连接反应:请参阅图4和图5,先在各结构单元1101中从第二液流管道1103预埋各个需筛选的n端序列片段,注意注入量不要超过设置的第三液流管道1104。向第五气动控制管道1205充入高压气体。从第一液流管道1102注入所需目的基因片段和连接混合液,向第一气动控制管道1201、第四气动控制管道1204充入高压气体后,启动第二气动控制管道1202组成的微泵,将反应液均匀混合,于4~40℃进行连接反应。
(2)扩增反应:连接反应完毕后,向第三气动控制管道1203中充入高压气体,撤去第四气动控制管道1204的高压气体,从第三液流管道1104通入一定体积的清洗液后,通入扩增混合溶液,向第四气动控制管道1204中充入高压气体后,撤去第三气动控制管道1203的高压气体,启动第二气动控制管道1202组成的微泵,将反应液均匀混合,37~45℃进行扩增反应。
(3)无细胞蛋白表达:扩增反应完毕后,向第三气动控制管道1203充入高压气体,撤去第四气动控制管道1204的高压气体,从第三液流管道1104通入一定体积的清洗液后,通入无细胞蛋白表达混合液,向第四气动控制管道1204充入高压气体后,撤去第三气动控制管道1203的高压气体,启动第二气动控制管道1202组成的微泵,将反应液均匀混合,20~40℃进行无细胞蛋白表达反应。
(4)目的蛋白富集,纯化:请参阅图6所示,无细胞蛋白表达反应完成后,向第三气动控制管道1203中充入高压气体,撤去第四气动控制管道1204的高压气体;从第三液流管道1104通入一定体积的清洗液后,通入蛋白纯化磁珠,使磁珠均匀分布在各结构单元内,向第四气动控制管道1204中充入高压气体后,撤去第三气动控制管道1203的高压气体,启动第二气动控制管道1202组成的微泵,将反应液均匀混合,目的蛋白富集到磁珠上后,将长条磁铁放在第三气动控制管道1203与第二气动控制管道1202之间位置,将捕获蛋白的磁珠固定各结构单元内;向第三气动控制管道1203充入高压气体,撤去第四气动控制管道1204的高压气体,从第三液流管道1104输入清洗液,向第四气动控制管道1204充入高压气体后,撤去第三气动控制管道1203的高压气体,启动第二气动控制管道1202组成的微泵,将反应液均匀混合;洗涤后的目的蛋白可以通过第二液流管道1103将各结构单元表达的蛋白洗脱收集也可以在芯片内进行检测;洗脱蛋白操作如下:向第三气动控制管道1203充入高压气体,撤去第四气动控制管道1204的高压气体,从第三液流管路1104通入洗脱液,向第四气动控制管道1204充入高压气体后,撤去第三气动控制管道1203的高压气体,启动第二气动控制管道1202组成的微泵,将反应液均匀混合,撤去第五气动控制管道1205的高压气体,通过第二液流管道1103分别收集各结构单元内的目的蛋白;
(5)目的蛋白检测:向第三气动控制管道1203充入高压气体,撤去第四气动控制管道1204的高压气体,从第三液流管路1104通入显色液,向第四气动控制管道1204充入高压气体后,撤去第三气动控制管道1203的高压气体,启动第二气动控制管道1202组成的微泵,将反应液均匀混合,产生的光学信号被外界光学检测器收集,从而完成对所表达的蛋白进行定量。
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及若干优选实施例对本发明的技术方案作进一步的说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,但其中的实验条件和设定参数不应视为对本发明基本技术方案的局限。并且本发明的保护范围不限于下述的实施例。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
实施例1
绿色荧光蛋白目的基因n端序列的优化:(以一个结构单元中绿色荧光蛋白添加组氨酸标签为例说明)
(1)线性模板构建:
ⅰ.本实施例所涉及用于蛋白表达的线性模板由n端序列片段与目的基因片段连接得到;n端序列片段可根据实验需求自由设计,其中n端序列片段由5’非翻译区、筛选标签、连接片段以及适当间隔序列组成;5’非翻译区包含转录翻译所需的重要元件,启动子和核糖体结合位点;连接片段,当使用酶切连接的方法时,可为任意核酸内切酶位点,当使用同源重组法时,可为与目的基因同源重组的片段;其中目的基因片段为需筛选的目的基因n端加入连接片段;
ⅱ.分别以基因合成或pcr法得到n端序列片段(具体序列如no.2所示),目的基因片段(具体序列如no.3所示);分别将两者使用核酸内切酶bamhi切割后,使用pcr清洁试剂盒回收储存以待使用;
ⅲ.n端筛选序列与目的基因片段连接:核酸内切酶bamhi切割后的n端序列片段(具体序列如no.2所示),目的基因片段(具体序列如no.3所示)通过t4连接酶进行连接,连接后得到的模板序列的序列如no.1所示;将t4连接酶缓冲液,t4连接酶与bamhi切割后目的基因片段的配置成混合液备用;先在各结构单元1101中从第二液流管道1103预埋的各个需筛选的n端序列片段,注意注入量不要超过设置的第三液流管路1104。从第一液流管道1102注入所需目的基因片段和连接混合液,向第一气动控制管道1201、第四气动控制管道1204、第五气动控制管道1205充入高压气体后,启动第二气动控制管道1202组成的微泵,将反应液均匀混合,16℃进行连接反应2小时。
(2)模板扩增
将连接后的基因表达模板进行等温扩增反应,所述扩增体系成分如下:25μm随机引物、1x反应buffer、0.5u/μlphi29聚合酶、0.5mmdntp、1mmdtt;将上述等温扩增体系配置成2×的混合液,向第三气动控制管道1203、第五气动控制管道1205充入高压气体,撤去第四气动控制管道1204的高压气体,从第三液流管路1104通入一定体积的清洗液后,通入2×扩增混合溶液,向第一气动控制管道1201、第四气动控制管道1204、第五气动控制管道1205充入高压气体后,启动第二气动控制管道1202组成的微泵,将反应液均匀混合,45℃进行扩增反应2小时。
(3)无细胞蛋白表达
所述表达系统成分如下:57mmhepes-koh缓冲液、1.2mmatp、0.85mmutp、0.85mmctp、0.85mmgtp、0.64mmcamp、200mm谷氨酸钾、80mm醋酸铵、15mm醋酸镁、33μg/mlt7rna聚合酶、500μm氨基酸、重量比2%的peg8000、33mm磷酸烯醇式丙酮酸、体积比24%的大肠杆菌抽提物;将上述无细胞蛋白表达系统配制成2×的混合液,扩增反应完毕后,向第三气动控制管道1203、第五气动控制管道1205充入高压气体,撤去第四气动控制管道1204的高压气体,从第三液流管路1104通入一定体积的清洗液后,通入无细胞蛋白表达混合液,向第一气动控制管道1201、第四气动控制管道1204、第五气动控制管道1205充入高压气体后,启动第二气动控制管道1202组成的微泵,将反应液均匀混合,30℃进行无细胞蛋白表达反应2小时。
(4)目的蛋白富集、纯化
无细胞蛋白表达反应完成后,向第三气动控制管道1203、第五气动控制管道1205充入高压气体,撤去第四气动控制管道1204的高压气体;从第三液流管路1104通入一定体积的清洗液后,通入蛋白纯化磁珠,使磁珠均匀分布在各结构单元1101内,向第一气动控制管道1201、第四气动控制管道1204、第五气动控制管道1205充入高压气体后,启动第二气动控制管道1202组成的微泵,将反应液均匀混合,目的蛋白富集到磁珠上后,将长条磁铁放在第三气动控制管道1203与第二气动控制管道1202之间位置,将捕获蛋白的磁珠固定各结构单元内;向第三气动控制管道1203、第五气动控制管道1205充入高压气体,撤去第四气动控制管道1204的高压气体,从第三液流管路1104通入清洗液,向第一气动控制管道1201、第四气动控制管道1204、第五气动控制管道1205充入高压气体后,启动第二气动控制管道1202组成的微泵,将反应液均匀混合。
(5)目的蛋白产量测定
向第三气动控制管道1203、第五气动控制管道1205充入高压气体,撤去第四气动控制管道1204的高压气体,从第三液流管路1104通入显色液考马斯亮蓝g250,向第一气动控制管道1201、第四气动控制管道1204、第五气动控制管道1205充入高压气体后,启动第二气动控制管道1202组成的微泵,将反应液均匀混合,产生的光学信号被外界光学检测器收集,从而完成对所表达的蛋白进行定量,本实施例中测得绿色荧光蛋白产量为0.4mg/ml。
综上所述,藉由上述技术方案,本发明的快速便捷的蛋白翻译起始区筛选方法是在高通量蛋白筛选芯片上进行的,该方法集目的基因模板优化、扩增、蛋白表达、纯化和检测一体化,操作简单便捷,可在一天时间内完成对目的蛋白最适载体的筛选,以提高目的蛋白产量。
本发明的各方面、实施例、特征及实例应视为在所有方面为说明性的且不打算限制本发明,本发明的范围仅由权利要求书界定。在不背离所主张的本发明的精神及范围的情况下,所属领域的技术人员将明了其它实施例、修改及使用。
在本发明案中标题及章节的使用不意味着限制本发明;每一章节可应用于本发明的任何方面、实施例或特征。
在本发明案通篇中,在将组合物描述为具有、包含或包括特定组份之处或者在将过程描述为具有、包含或包括特定过程步骤之处,预期本发明教示的组合物也基本上由所叙述组份组成或由所叙述组份组成,且本发明教示的过程也基本上由所叙述过程步骤组成或由所叙述过程步骤组组成。
应理解,各步骤的次序或执行特定动作的次序并非十分重要,只要本发明教示保持可操作即可。此外,可同时进行两个或两个以上步骤或动作。
此外,本案发明人还参照前述实施例,以本说明书述及的其它原料、工艺操作、工艺条件进行了试验,并均获得了较为理想的结果。
尽管已参考说明性实施例描述了本发明,但所属领域的技术人员将理解,在不背离本发明的精神及范围的情况下可做出各种其它改变、省略及/或添加且可用实质等效物替代所述实施例的元件。另外,可在不背离本发明的范围的情况下做出许多修改以使特定情形或材料适应本发明的教示。因此,本文并不打算将本发明限制于用于执行本发明的所揭示特定实施例,而是打算使本发明将包含归属于所附权利要求书的范围内的所有实施例。
序列表
<110>苏州珀罗汀生物技术有限公司
<120>一种蛋白合成筛选方法
<160>3
<170>siposequencelisting1.0
<210>1
<211>1520
<212>dna
<213>人工序列(人工序列)
<400>1
tggagcggatcggggattgtctttcttcagctcgctgatgatatgctgacgctcaatgcc60
gtttggcctccgactaacgaaaatcccgcatttggacggctgatccgattggcacggcgg120
acggcgaatggcggagcagacgctcgtccgggggcaatgagatatgaaaaagcctgaact180
caccgcgacgtatcgggccctggccaggatctgatattaatacgactcactataggggag240
ctgtcaccggatgtgctttccggtctgatgagtccgtgaggacgaaacagcctctagaaa300
taattttgtttaactttaagaaggagatataccatgcatcatcatcatcatcacggatcc360
gctagccatatgcgtaaaggcgaagagctgttcactggtgtcgtccctattctggtggaa420
ctggatggtgatgtcaacggtcataagttttccgtgcgtggcgagggtgaaggtgacgca480
actaatggtaaactgacgctgaagttcatctgtactactggtaaactgccggtaccttgg540
ccgactctggtaacgacgctgacttatggtgttcagtgctttgctcgttatccggaccat600
atgaagcagcatgacttcttcaagtccgccatgccggaaggctatgtgcaggaacgcacg660
atttcctttaaggatgacggcacgtacaaaacgcgtgcggaagtgaaatttgaaggcgat720
accctggtaaaccgcattgagctgaaaggcattgactttaaagaagacggcaatatcctg780
ggccataagctggaatacaattttaacagccacaatgtttacatcaccgccgataaacaa840
aaaaatggcattaaagcgaattttaaaattcgccacaacgtggaggatggcagcgtgcag900
ctggctgatcactaccagcaaaacactccaatcggtgatggtcctgttctgctgccagac960
aatcactatctgagcacgcaaagcgttctgtctaaagatccgaacgagaaacgcgatcat1020
atggttctgctggagttcgtaaccgcagcgggcatcacgcatggtatggatgaactgtac1080
aaatgatgaccggctgcagcccgtacctctagtagagtcgagggggaacccggccgcgtc1140
cggcgcccccgccgccttcgacgagatcccgcaaaagcggcctttgactccctgcaagcc1200
tcagcgaccgaatatatcggttatgcgtgggcgatggttgttgtcattgtcggcgcaact1260
atcggtatcaagctgtttaagaaattcacctcgaaagcaagctgataaaccgatacaatt1320
aaaggctccttttggagcctttttttttggagattttcaacgtgaaaaaattattattcg1380
caattcctttagttgttcctttctattctcactccgctgaaactgttgaaagttgtttag1440
caaaacctcatacagaaaattcatttactaacgtctggaaagacgacaaaactttagatc1500
ctctagctagagtcgaccgg1520
<210>2
<211>369
<212>dna
<213>人工序列(人工序列)
<400>2
tggagcggatcggggattgtctttcttcagctcgctgatgatatgctgacgctcaatgcc60
gtttggcctccgactaacgaaaatcccgcatttggacggctgatccgattggcacggcgg120
acggcgaatggcggagcagacgctcgtccgggggcaatgagatatgaaaaagcctgaact180
caccgcgacgtatcgggccctggccaggatctgatattaatacgactcactataggggag240
ctgtcaccggatgtgctttccggtctgatgagtccgtgaggacgaaacagcctctagaaa300
taattttgtttaactttaagaaggagatataccatgcatcatcatcatcatcacggatcc360
gctagccat369
<210>3
<211>1168
<212>dna
<213>人工序列(人工序列)
<400>3
agggatccgctagccatatgcgtaaaggcgaagagctgttcactggtgtcgtccctattc60
tggtggaactggatggtgatgtcaacggtcataagttttccgtgcgtggcgagggtgaag120
gtgacgcaactaatggtaaactgacgctgaagttcatctgtactactggtaaactgccgg180
taccttggccgactctggtaacgacgctgacttatggtgttcagtgctttgctcgttatc240
cggaccatatgaagcagcatgacttcttcaagtccgccatgccggaaggctatgtgcagg300
aacgcacgatttcctttaaggatgacggcacgtacaaaacgcgtgcggaagtgaaatttg360
aaggcgataccctggtaaaccgcattgagctgaaaggcattgactttaaagaagacggca420
atatcctgggccataagctggaatacaattttaacagccacaatgtttacatcaccgccg480
ataaacaaaaaaatggcattaaagcgaattttaaaattcgccacaacgtggaggatggca540
gcgtgcagctggctgatcactaccagcaaaacactccaatcggtgatggtcctgttctgc600
tgccagacaatcactatctgagcacgcaaagcgttctgtctaaagatccgaacgagaaac660
gcgatcatatggttctgctggagttcgtaaccgcagcgggcatcacgcatggtatggatg720
aactgtacaaatgatgaccggctgcagcccgtacctctagtagagtcgagggggaacccg780
gccgcgtccggcgcccccgccgccttcgacgagatcccgcaaaagcggcctttgactccc840
tgcaagcctcagcgaccgaatatatcggttatgcgtgggcgatggttgttgtcattgtcg900
gcgcaactatcggtatcaagctgtttaagaaattcacctcgaaagcaagctgataaaccg960
atacaattaaaggctccttttggagcctttttttttggagattttcaacgtgaaaaaatt1020
attattcgcaattcctttagttgttcctttctattctcactccgctgaaactgttgaaag1080
ttgtttagcaaaacctcatacagaaaattcatttactaacgtctggaaagacgacaaaac1140
tttagatcctctagctagagtcgaccgg1168
- 还没有人留言评论。精彩留言会获得点赞!