基于视觉识别的分拣方法、智能分拣系统及可读存储介质与流程
1.本技术涉及智能分拣机器人技术领域,尤其是涉及基于视觉识别的分拣方法、智能分拣系统及计算机可读存储介质。
背景技术:
2.对于堆叠场景下的工件分拣,通常使用3d传感器,例如深度相机来获取每个工件的三维数据(包括深度图像和点云),然后通过位姿匹配算法计算每个工件的空间位姿(6dof,6degree of freedom,表示沿x、y、z三个直角坐标轴方向的移动自由度和绕这三个坐标轴的转动自由度),进而通过每个工件的空间位姿确定可抓取的工件,从而控制智能分拣机器人抓取该工件。
3.本技术的发明人在长期研究中发现,现有技术通常为深度相机每拍摄识别一次每个工件的空间位姿才执行一次抓取操作,由于抓取过程中的不确定性,剩余物体的状态可能会发生变化,所以在每次工件抓取后需要重新进行拍摄识别,然后计算每个工件的空间位姿并执行分拣操作,分拣效率低。
技术实现要素:
4.本技术的目的是提供基于视觉识别的分拣方法、智能分拣系统及计算机可读存储介质,以解决现有技术中在每次工件抓取后需要重新进行拍摄识别,然后计算每个工件的空间位姿并执行分拣操作,分拣效率低的问题。
5.为了实现上述目的,本技术实施例提供的一种基于视觉识别的分拣方法,包括:
6.获取待分拣场景中上一次分拣操作前所有分拣目标的二维图像,以及所述分拣操作后剩余分拣目标的二维图像;
7.将所述分拣操作后所述剩余分拣目标的二维图像与上一次分拣操作前所有分拣目标的二维图像进行相似度对比,以确定所述剩余分拣目标的实际位置是否发生改变;
8.若确定至少部分所述剩余分拣目标的实际位置未发生改变,则提取实际位置未发生改变的剩余分拣目标的当前位姿,然后按照预设抓取策略以及所述剩余分拣目标的当前位姿,控制智能分拣机器人对实际位置未发生改变的剩余分拣目标执行本次分拣操作;其中,所述剩余分拣目标的当前位姿为最近一次所述剩余分拣目标未进行位姿更新的历史位姿。
9.作为上述方案的改进,还包括:
10.若确定所有所述剩余分拣目标的实际位置均发生改变,则重新计算所有所述剩余分拣目标的当前位姿,以更新所述剩余分拣目标的历史位姿,然后按照所述预设抓取策略以及重新计算的所述剩余分拣目标的当前位姿,控制所述智能分拣机器人对所述剩余分拣目标执行本次分拣操作。
11.作为上述方案的改进,还包括:
12.所述重新计算所有所述剩余分拣目标的当前位姿,包括:
13.获取所述待分拣场景中所有所述剩余分拣目标的三维图像;
14.基于位姿估计算法以及所有所述剩余分拣目标的三维图像,计算出所有所述剩余分拣目标的位姿;
15.基于位姿优化算法,对所有所述剩余分拣目标的位姿进行位姿优化,以获得所述剩余分拣目标的当前位姿。
16.作为上述方案的改进,还包括:
17.获取所述待分拣场景中最近一次所有分拣目标均未进行位姿更新的历史位姿;
18.基于最近一次所有分拣目标均未进行位姿更新的历史位姿,至少确定与每个所述剩余分拣目标的历史位姿所对应的感兴趣区域;
19.从上一次分拣操作前所有分拣目标的二维图像中,提取与每个所述剩余分拣目标的感兴趣区域对应的第一子图像;
20.则所述将分拣操作后所述剩余分拣目标的二维图像与上一次分拣操作前所有分拣目标的二维图像进行相似度对比,以确定所述剩余分拣目标的实际位置是否发生改变,包括:
21.从所述分拣操作后剩余分拣目标的二维图像中,提取与每个所述剩余分拣目标的感兴趣区域对应的第二子图像;
22.将每个所述剩余分拣目标对应的所述第二子图像与所述第一子图像进行相似度对比;
23.若至少部分所述剩余分拣目标的所述第二子图像与所述第一子图像的相似度大于等于相似度阈值,则确定至少部分所述剩余分拣目标的实际位置未发生改变;
24.若所有所述剩余分拣目标的所述第二子图像与所述第一子图像的相似度均小于所述相似度阈值,则确定所有所述剩余分拣目标的实际位置均发生改变。
25.作为上述方案的改进,还包括:
26.获取所述待分拣场景中分拣目标的模板边界框;
27.则基于最近一次所有分拣目标均未进行位姿更新的历史位姿,至少确定与每个所述剩余分拣目标的历史位姿所对应的感兴趣区域,包括:
28.将所述模板边界框按照最近一次每个所述剩余分拣目标均未进行位姿更新的历史位姿,逐一框选每个所述剩余分拣目标的与所述历史位姿对应的三维图像,然后记录每次框选过程中所述模板边界框在相机坐标系下的顶点坐标;
29.将每次框选记录的所述模板边界框在相机坐标系下的顶点坐标转换成像素坐标系下的顶点坐标;
30.在图像坐标系下,构建容纳所述模板边界框所有顶点坐标的最小外接矩形,然后将所述最小外接矩形确定为所述剩余分拣目标的历史位姿所对应的感兴趣区域;
31.重复以上所有操作,直至确定所有所述剩余分拣目标的历史位姿所对应的感兴趣区域。
32.作为上述方案的改进,所述将每个所述剩余分拣目标对应的所述第二子图像与所述第一子图像进行相似度对比,包括:
33.基于结构相似性算法,确定每个所述剩余分拣目标的所述第二子图像与所述第一子图像的相似度;
34.判断每个所述剩余分拣目标的所述第二子图像与所述第一子图像的相似度是否大于等于所述相似度阈值。
35.作为上述方案的改进,所述预设抓取策略,包括:
36.判断所述待分拣场景中所述剩余分拣目标是否存在堆叠;
37.若不存在堆叠,则计算出与每个所述剩余分拣目标的当前位姿对应的置信度;
38.按照所述置信度从高到低的顺序依次抓取所述剩余分拣目标;
39.若存在堆叠,则提取每个所述剩余分拣目标的当前位姿中的竖直高度值;
40.按照所述竖直高度值排序从高到低的顺序依次抓取所述剩余分拣目标。
41.本技术实施例提供的一种基于视觉识别的分拣方法,包括:
42.获取待分拣场景中所有分拣目标的初始三维图像;
43.通过所有所述分拣目标的初始三维图像,分别计算出所有所述分拣目标的初始位姿,并将所有所述分拣目标的初始位姿作为所有所述分拣目标的首次历史位姿;
44.控制智能分拣机器人按照预设抓取策略抓取至少部分所述分拣目标,并将至少部分所述分拣目标放置于目标位置,以执行首次分拣操作;
45.按照如上述任一实施例所述的基于视觉识别的分拣方法,确定所述待分拣场景中所述剩余分拣目标的实际位置是否发生改变,并基于确定结果执行本次分拣操作;
46.重复执行上述最后一个步骤,直至分拣完所述待分拣场景中所有分拣目标。
47.本技术实施例提供的一种智能分拣系统,包括:
48.智能分拣机器人;
49.摄像头,设置在所述智能分拣机器人上,用于采集待分拣场景中所有分拣目标的二维图像和三维图像;
50.一个或多个处理器,分别与所述智能分拣机器人和所述摄像头连接;
51.存储器,与所述处理器耦接,用于存储一个或多个程序;
52.当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现如上述任一实施例所述的基于视觉识别的分拣方法。
53.本技术实施例提供的一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如上述任一实施例所述的基于视觉识别的分拣方法。
54.相较于现有技术,本技术实施例中的基于视觉识别的分拣方法、智能分拣系统及计算机可读存储介质具有如下有益效果:
55.通过获取待分拣场景中上一次分拣操作前所有分拣目标的二维图像,以及所述分拣操作后剩余分拣目标的二维图像,然后将所述分拣操作后所述剩余分拣目标的二维图像与上一次分拣操作前所有分拣目标的二维图像进行相似度对比,以确定所述剩余分拣目标的实际位置是否发生改变,若不改变,则提取最近一次所述剩余分拣目标未进行位姿更新的历史位姿作为剩余分拣目标的当前位姿,然后基于剩余分拣目标的当前位姿以及预设抓取策略继续分拣剩余分拣目标,若改变,则重新计算剩余分拣目标的当前位姿。如此,本技术减少了整体计算分拣目标位姿的工作量,分拣效率更高。
附图说明
56.本技术将结合附图对实施方式进行说明。本技术的附图仅用于描述实施例,以展
示为目的。在不偏离本技术原理的条件下,本领域技术人员能够轻松地通过以下描述根据所述步骤做出其他实施例。
57.图1是本技术一实施例中的智能分拣系统分拣剩余分拣目标的场景示意图;
58.图2是本技术一实施例中的基于视觉识别的分拣方法的流程示意图;
59.图3是本技术一实施例中的基于视觉识别的分拣方法的流程示意图;
60.图4是本技术一实施例中的基于视觉识别的分拣方法的流程示意图;
61.图5是本技术一实施例中的基于视觉识别的分拣方法的流程示意图;
62.图6是本技术一实施例中的基于视觉识别的分拣方法的流程示意图;
63.图7是本技术一实施例中的基于视觉识别的分拣方法的流程示意图;
64.图8是本技术一实施例中的采用模板边界框框选每个剩余分拣目标的示意图。
具体实施方式
65.下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述。可以理解的是,此处所描述的具体实施例仅用于解释本技术,而非对本技术的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本技术相关的部分而非全部结构。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
66.本技术中的术语“第一”、“第二”等是用于区别不同对象,而不是用于描述特定顺序。此外,术语“包括”和“具有”以及它们任何变形,意图在于覆盖不排他的包含。例如包含了一系列步骤或单元的过程、方法、系统、产品或设备没有限定于已列出的步骤或单元,而是可选地还包括没有列出的步骤或单元,或可选地还包括对于这些过程、方法、产品或设备固有的其它步骤或单元。
67.在本文中提及“实施例”意味着,结合实施例描述的特定特征、结构或特性可以包含在本技术的至少一个实施例中。在说明书中的各个位置出现该短语并不一定均是指相同的实施例,也不是与其它实施例互斥的独立的或备选的实施例。本领域技术人员显式地和隐式地理解的是,本文所描述的实施例可以与其它实施例相结合。
68.以下对本文中涉及的部分技术用语进行说明,以便于本领域技术人员理解。
69.三维图像:是一种特殊的信息表达形式,其特征是表达的空间中三个维度的数据,表现形式包括:深度图像、几何模型(由cad软件建立)以及点云模型。
70.深度图像:也叫距离影像,是指将从图像采集器到场景中各点的距离(深度)值作为像素值的图像,获取方法有:激光雷达深度成像法、计算机立体视觉成像、坐标测量机法、莫尔条纹法以及结构光法。
71.点云:当一束激光照射到物体表面时,所反射的激光会携带方位、距离等信息。若将激光束按照某种轨迹进行扫描,便会边扫描边记录到反射的激光点信息,由于扫描极为精细,则能够得到大量的激光点,因而可形成激光点云。深度图像经过坐标转换可以计算为点云数据;有规则及必要信息的点云数据可以反算为深度图像。
72.位姿:在同步定位与建图(simultaneous localization and mapping,slam)中,位姿是世界坐标系到相机坐标系的变换,包括旋转与平移。
73.分拣目标的位姿估计:利用相机坐标系下图像像素点和世界坐标系下分拣目标三
维空间物体点的对应关系,估计分拣目标的位置和姿态信息。
74.请参阅图1,本技术实施例提供的一种智能分拣系统100,包括智能分拣机器人10、摄像头20、一个或多个处理器、以及存储器。
75.摄像头20设置在所述智能分拣机器人10上,用于采集待分拣场景中所有分拣目标的二维图像和三维图像。
76.一个或多个处理器,分别与所述智能分拣机器人10和所述摄像头20连接。存储器,与所述处理器耦接,用于存储一个或多个程序。当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现如上述任一实施例所述的基于视觉识别的分拣方法。
77.处理器用于控制该智能分拣系统100的整体操作,以完成上述的基于视觉识别的分拣方法的全部或部分步骤。存储器用于存储各种类型的数据以支持在该智能分拣系统100的操作,这些数据例如可以包括用于在该智能分拣系统100上操作的任何应用程序或方法的指令,以及应用程序相关的数据。该存储器可以由任何类型的易失性或非易失性存储设备或者它们的组合实现,例如静态随机存取存储器(static random access memory,简称sram),电可擦除可编程只读存储器(electrically erasable programmable read-only memory,简称eeprom),可擦除可编程只读存储器(erasable programmable read-only memory,简称eprom),可编程只读存储器(programmable read-only memory,简称prom),只读存储器(read-only memory,简称rom),磁存储器,快闪存储器,磁盘或光盘。
78.在一个实施例中,请参阅图1,智能分拣机器人10包括驱动组件和机械臂11,驱动组件与机械臂11驱动连接并与处理器通信连接,摄像头20设置在机械臂11上。
79.在一个实施例中,摄像头20包括rgb-d摄像头,rgb-d摄像头能够采集分拣目标的点云和二维彩色图像。
80.在一个实施例中,可由同一个处理器分别与智能分拣机器人10和摄像头20连接,处理摄像头20采集到的待分拣场景中所有分拣目标的二维图像和三维图像,然后对采集结果进行处理,并根据采集结果生成相应的控制命令,从而控制智能分拣机器人10执行相应的分拣操作。
81.在另一个实施例中,可由一个处理器与智能分拣机器人10连接,以控制智能分拣机器人10进行分拣操作,由另一个处理器处理摄像头20采集到的待分拣场景中所有分拣目标的二维图像和三维图像,然后对采集结果进行处理,并根据采集结果生成相应的控制命令发送至智能分拣机器人10的处理器,从而控制智能分拣机器人10执行相应的分拣操作。
82.请参阅图2,本技术实施例提供的一种基于视觉识别的分拣方法,包括以下步骤:
83.s110、获取待分拣场景中所有分拣目标的初始三维图像;
84.s120、通过所有所述分拣目标的初始三维图像,分别计算出所有所述分拣目标的初始位姿,并将所有所述分拣目标的初始位姿作为所有所述分拣目标的首次历史位姿;
85.s130、控制智能分拣机器人10按照预设抓取策略抓取至少部分所述分拣目标,并将至少部分所述分拣目标放置于目标位置,以执行首次分拣操作;
86.s140、按照如本技术图3至图7任一实施例实施例所述的基于视觉识别的分拣方法,确定所述待分拣场景中所述剩余分拣目标200的实际位置是否发生改变,并基于确定结果执行本次分拣操作;
87.s150、重复执行上述步骤s140,直至分拣完所述待分拣场景中所有分拣目标。
88.在待分拣场景中,多个分拣目标可随智能分拣系统100的传送带或其他运输结构运行到分拣工位处,然后传送带或其他运输结构停止运行。此时,多个分拣目标可为依次分开无序摆放,也可为堆叠无序摆放。每次执行分拣操作,智能分拣系统100的智能分拣机器人10能够将至少部分分拣目标移送至目标位置。智能分拣系统100的若判断所述待分拣场景中存在剩余分拣目标200,则重复执行上述步骤s140;若判断所述待分拣场景中不存在剩余分拣目标200,则可结束所述待分拣场景的分拣操作。
89.而在执行首次分拣操作之前,需要对待分拣场景中所有的分拣目标进行位姿估计。
90.具体的,通过获取该待分拣场景中所有分拣目标的初始三维图像,然后通过位姿估计算法计算出所有分拣目标的初始位姿,保存该初始位姿,以作为所有分拣目标的首次历史位姿。在后续的分拣操作过程中,历史位姿可实时或者根据需求进行更新。
91.在获得所有分拣目标的初始位姿后,智能分拣机器人10根据初始位姿以及预设抓取策略抓取部分或者所有的分拣目标,然后将这些分拣目标放置在目标位置,从而实现了首次分拣操作。
92.在一个实施例中,位姿估计算法包括基于点对特征(point pair features,ppf)的模型匹配算法、基于深度卷积网络(convolutional neural network,cnn)的6d位姿估计算法、基于模板匹配算法、基于关键点检测算法等。
93.其中,ppf算法的核心思想是整体建模,局部匹配。通过构建两点及其法向量之间的几何关系形成的四维特征作为点对特征,在线下建立哈希表存储模型的所有四维特征作为模型的整体描述,在线上匹配阶段,借用全局坐标系简化刚体变换自由度,使得位姿计算变得简单。同时借助广义霍夫变换的投票思想,对参数空间投票,获得可靠位姿。
94.可以理解,位姿估计算法为现有常见的计算物体位姿方法,具体可参见现有文献中对该算法的描述,本技术在此不再赘述。
95.在一个实施例中,还可通过位姿优化算法对于计算出来的初始位姿进行迭代优化。
96.位姿优化算法包括迭代最近点(iterative closest point,icp)算法。
97.其中,icp算法是基于em(expectation-maximization algorithm)思想的方法,采用交替迭代法优化点云匹配及优化运动估计。
98.可以理解,位姿估计算法为现有常见的计算物体位姿方法,具体可参见现有文献中对该算法的描述,本技术在此不再赘述。
99.在一个实施例中,分拣目标可为立体规则工件或不规则工件。
100.在一个实施例中,三维图像包括深度图像或点云。
101.为更好地理解本技术的发明构思,以下实施例以三维图像为点云为例进行说明。
102.在一个实施例中,所述预设抓取策略,包括:
103.判断所述待分拣场景中所述分拣目标是否存在堆叠;
104.若不存在堆叠,则计算出与每个所述分拣目标的当前位姿对应的置信度;
105.按照所述置信度从高到低的顺序依次抓取所述分拣目标;
106.若存在堆叠,则提取每个所述分拣目标的当前位姿中的竖直高度值;
107.按照所述竖直高度值排序从高到低的顺序依次抓取所述分拣目标。
108.本实施例根据分拣目标的堆叠情况进行抓取,如果判断分拣目标不存在堆叠,则按照每个分拣目标的当前位姿计算出对应的置信度,然后对置信度进行排序,按照置信度从高到低的顺序依次抓取部分或所有分拣目标。如此,智能分拣系统100能够通过所有分拣目标的当前位姿识别出无遮挡可分拣的分拣目标,然后进行分拣操作。
109.其中,置信度用于表征每个分拣目标抓取的几率。在一个实施例中,置信度归一化至[0,1],其中接近1的值表示更高的抓取置信度,即抓取成功的机会更高。在另一个实施例中,置信度归一化至[0,100],其中接近100的值表示更高的抓取置信度,即抓取成功的机会更高。
[0110]
在一个实施例中,置信度可通过现有的置信度计算方法计算出来,示例性的,以ppf算法为例,置信度是ppf算法的一个参数,每个分拣目标通过该算法所估计的位姿都会有一个分数,如此,在通过ppf算法计算出每个分拣目标的位姿后,也能获得每个分拣目标对应的置信度。
[0111]
此外,其他置信度计算方法具体可参见现有文献中对该算法的描述,本技术在此不再赘述。
[0112]
如果判断分拣目标存在堆叠,则优先抓取堆叠分拣目标中处于高位的分拣目标,即对当前位姿中的竖直高度值进行排序,按照竖直高度值从高到低的顺序依次抓取部分或所有分拣目标。
[0113]
在其他实施例中,如果判断部分分拣目标存在堆叠,部分分拣目标不存在堆叠,则可以综合使用置信度抓取方法和竖直高度值抓取方法,对待分拣场景中的分拣目标进行分拣,例如对于堆叠摆放的分拣目标,优先使用竖直高度值抓取置信度抓取方法,对于不堆叠摆放的分拣目标,优先使用置信度抓取方法。
[0114]
请参阅图1和图3,本技术实施例提供的一种基于视觉识别的分拣方法,包括以下步骤:
[0115]
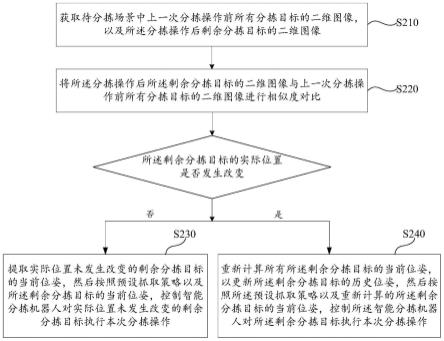
s210、获取待分拣场景中上一次分拣操作前所有分拣目标的二维图像,以及所述分拣操作后剩余分拣目标200的二维图像。
[0116]
本实施例在该待分拣场景中每执行一次分拣操作,均要获取该分拣操作前后两次的分拣目标的二维图像。具体的,不仅需要获取上一次分拣操作前所有分拣目标的二维图像,同时也需要获取分拣操作后剩余分拣目标200的二维图像。
[0117]
在一个实施例中,可由摄像头20采集该待分拣场景每次分拣操作前后所有分拣目标的二维图像。
[0118]
在一个实施例中,二维图像包括可见光图像或红外图像。
[0119]
可以理解,每次在执行分拣操作前均需要采集待分拣场景中所有分拣目标的二维图像,所采集的二维图像存储在存储器中。在执行下一次分拣操作前,可从存储器调取相应分拣操作前的二维图像,同时通过摄像头20获取当前待分拣场景剩余分拣目标200的二维图像。
[0120]
s220、将所述分拣操作后所述剩余分拣目标200的二维图像与上一次分拣操作前所有分拣目标的二维图像进行相似度对比,以确定所述剩余分拣目标200的实际位置是否发生改变。
[0121]
本实施例将分拣操作前后两次的分拣目标的二维图像进行相似度对比,从而确定每次分拣操作之后,分拣操作是否对剩余分拣目标200有影响,即确定剩余分拣目标200的实际位置是否发生改变。
[0122]
s230、若确定至少部分所述剩余分拣目标200的实际位置未发生改变,则提取实际位置未发生改变的剩余分拣目标200的当前位姿,然后按照预设抓取策略以及所述剩余分拣目标200的当前位姿,控制智能分拣机器人10对实际位置未发生改变的剩余分拣目标200执行本次分拣操作;其中,所述剩余分拣目标200的当前位姿为最近一次所述剩余分拣目标200未进行位姿更新的历史位姿。
[0123]
对于所有的剩余分拣目标200,如果所有剩余分拣目标200的实际位置没有发生改变,表示所有剩余分拣目标200的当前位姿并未改变,通过提取实际位置未发生改变的剩余分拣目标200的当前位姿,然后按照当前位姿以及预设分拣策略,控制智能分拣机器人10对所有剩余分拣目标200执行分拣操作。
[0124]
如果部分剩余分拣目标200的实际位置没有发生改变,表示这些剩余分拣目标200的当前位姿并未改变,通过提取实际位置未发生改变的剩余分拣目标200的当前位姿,然后按照当前位姿以及预设分拣策略,控制智能分拣机器人10对这些剩余分拣目标200执行分拣操作。
[0125]
可以理解,剩余分拣目标200的实际位置发生改变包括剩余分拣目标200的实际位置完全改变或者部分较为明显的改变,比如对于堆叠分拣目标,在进行分拣操作后,部分剩余分拣目标200从高位降落到低位,或者对于易变形的分拣目标,在移除上面的分拣目标后,下面的分拣目标恢复形变,体积增大等。
[0126]
请参阅图3,在一个实施例中,所述基于视觉识别的分拣方法还包括以下步骤:
[0127]
s240、若确定所有所述剩余分拣目标200的实际位置均发生改变,则重新计算所有所述剩余分拣目标200的当前位姿,以更新所述剩余分拣目标200的历史位姿,然后按照所述预设抓取策略以及重新计算的所述剩余分拣目标200的当前位姿,控制所述智能分拣机器人10对所述剩余分拣目标200执行本次分拣操作。
[0128]
在本实施例中,如果确定所有剩余分拣目标200的实际位置均发生改变,则剩余分拣目标200原有的历史位姿不再适用,需重新计算当前位姿,同时更新剩余分拣目标200的历史位姿,然后智能分拣系统100按照重新计算的当前位姿和预设抓取策略对这些剩余分拣目标200执行分拣操作。
[0129]
本技术实施例在分拣一次后,获取剩余分拣目标200的二维图像,然后将其与上一次拍摄的分拣目标的二维图像进行相似度对比,从而确定剩余分拣目标200的位姿是否发生改变,若不改变,则提取最近一次剩余分拣目标200未进行位姿更新的历史位姿作为剩余分拣目标200的当前位姿,然后基于剩余分拣目标200的当前位姿以及预设抓取策略继续分拣剩余分拣目标200,若改变,则重新计算剩余分拣目标200的当前位姿。
[0130]
需要说明的是,相似度对比需要比较分拣操作前后两次的二维图像,而提取剩余分拣目标200的当前位姿则不受中间分拣几次的影响,因此在本技术中,上一次并不相当于最近一次。
[0131]
具体的,最近一次剩余分拣目标200未进行位姿更新的历史位姿表示未重新计算剩余分拣目标200的当前位姿,以对其历史位姿进行更新的位姿。只有所有剩余分拣目标
200的实际位置均发生改变,才会更新对应的历史位姿,是否执行分拣操作与更新历史位姿没有必然联系。
[0132]
例如,在执行首次分拣操作之前,确定了所有分拣目标的首次历史位姿。
[0133]
如果在执行首次分拣操作之后,所有剩余分拣目标200的实际位置均发生改变,则需重新计算所有剩余分拣目标200的当前位姿以进行第二次分拣操作,并更新对应的历史位姿。
[0134]
如果在执行首次分拣操作之后,至少部分剩余目标的实际位置未发生改变,则提取对应的历史位姿以进行第二次分拣操作,此时未对原有的历史位姿进行更新。如果在执行第二次分拣操作之后,所有剩余分拣目标200的实际位置均发生改变,则需重新计算所有剩余分拣目标200的当前位姿以进行第三次分拣操作,并更新对应的历史位姿。如果在执行第二次分拣操作之后,至少部分剩余目标的实际位置未发生改变,则提取对应的历史位姿以进行第三次分拣操作,此时未对原有的历史位姿进行更新。
[0135]
以此类推,直至分拣完待分拣场景中所有分拣目标。
[0136]
可以理解,首次历史位姿以及后续更新的历史位姿均可存储于存储器中,在需提取最近一次剩余分拣目标200未进行位姿更新的历史位姿时,可从存储器调取相应的历史位姿。
[0137]
请参阅图4,在一个实施例中,可通过以下方式重新计算所有所述剩余分拣目标200的当前位姿。
[0138]
具体的,所述重新计算所有所述剩余分拣目标200的当前位姿,包括以下步骤:
[0139]
310、获取所述待分拣场景中所有所述剩余分拣目标200的三维图像;
[0140]
320、基于位姿估计算法以及所有所述剩余分拣目标200的三维图像,计算出所有所述剩余分拣目标200的位姿;
[0141]
330、基于位姿优化算法,对所有所述剩余分拣目标200的位姿进行位姿优化,以获得所述剩余分拣目标200的当前位姿。
[0142]
在一个实施例中,位姿估计算法包括ppf算法、基于cnn的6d位姿估计算法、基于模板匹配算法、基于关键点检测算法等。
[0143]
在一个实施例中,位姿优化算法包括icp算法。
[0144]
可以理解,本实施例重新计算所有剩余分拣目标200的当前位姿与上述实施例中计算所有分拣目标的初始位姿计算方法相同,详细计算方法可参见上述实施例计算所有分拣目标的初始位姿,在此不再赘述。
[0145]
在一个实施例中,所述预设抓取策略,包括:
[0146]
判断所述待分拣场景中所述剩余分拣目标200是否存在堆叠;
[0147]
若不存在堆叠,则计算出与每个所述剩余分拣目标200的当前位姿对应的置信度;
[0148]
按照所述置信度从高到低的顺序依次抓取所述剩余分拣目标200;
[0149]
若存在堆叠,则提取每个所述剩余分拣目标200的当前位姿中的竖直高度值;
[0150]
按照所述竖直高度值排序从高到低的顺序依次抓取所述剩余分拣目标200。
[0151]
本实施例根据剩余分拣目标200的堆叠情况进行抓取,如果判断剩余分拣目标200不存在堆叠,则按照每个剩余分拣目标200的当前位姿计算出对应的置信度,然后对置信度进行排序,按照置信度从高到低的顺序依次抓取部分或所有剩余分拣目标200。
[0152]
可以理解,本实施例的预设抓取策略与上述实施例中的预设抓取策略思路相同,详细预设抓取策略可参见上述实施例,在此不再赘述。
[0153]
综上,相较于现有技术中每次分拣操作前均需要计算分拣目标的位姿,计算量大,分拣效率低,本技术实施例通过获取待分拣场景中上一次分拣操作前所有分拣目标的二维图像,以及所述分拣操作后剩余分拣目标200的二维图像,然后将所述分拣操作后所述剩余分拣目标200的二维图像与上一次分拣操作前所有分拣目标的二维图像进行相似度对比,以确定所述剩余分拣目标200的实际位置是否发生改变,若不改变,则提取最近一次所述剩余分拣目标200未进行位姿更新的历史位姿作为剩余分拣目标200的当前位姿,然后基于剩余分拣目标200的当前位姿以及预设抓取策略继续分拣剩余分拣目标200,若改变,则重新计算剩余分拣目标200的当前位姿。如此,本技术减少了整体计算分拣目标位姿的工作量,分拣效率更高。
[0154]
请参阅图5,在一个实施例中,所述基于视觉识别的分拣方法还包括以下步骤:
[0155]
s250、获取所述待分拣场景中最近一次所有分拣目标均未进行位姿更新的历史位姿;
[0156]
s260、基于最近一次所有分拣目标均未进行位姿更新的历史位姿,至少确定与每个所述剩余分拣目标200的历史位姿所对应的感兴趣区域;
[0157]
s270、从上一次分拣操作前所有分拣目标的二维图像中,提取与每个所述剩余分拣目标200的感兴趣区域对应的第一子图像。
[0158]
则所述步骤s220,将分拣操作后所述剩余分拣目标200的二维图像与上一次分拣操作前所有分拣目标的二维图像进行相似度对比,以确定所述剩余分拣目标200的实际位置是否发生改变,包括以下子步骤:
[0159]
s221、从所述分拣操作后剩余分拣目标200的二维图像中,提取与每个所述剩余分拣目标200的感兴趣区域对应的第二子图像;
[0160]
s222、将每个所述剩余分拣目标200对应的所述第二子图像与所述第一子图像进行相似度对比;
[0161]
s223、若至少部分所述剩余分拣目标200的所述第二子图像与所述第一子图像的相似度大于等于相似度阈值,则确定至少部分所述剩余分拣目标200的实际位置未发生改变;
[0162]
s224、若所有所述剩余分拣目标200的所述第二子图像与所述第一子图像的相似度均小于所述相似度阈值,则确定所有所述剩余分拣目标200的实际位置均发生改变。
[0163]
本实施例基于每个剩余分拣目标200的位姿,确定每个剩余分拣目标200的感兴趣区域(region of interest,roi),进而获取分拣操作前后两次的二维图像中与感兴趣区域对应的子图像,比较两个子图像的相似度,以确定剩余分拣目标200的实际位置是否发生改变。相较于比较分拣操作前后两次整张二维图像的相似度,计算量大且对比不够精确。本实例通过每个剩余分拣目标200的感兴趣区域将整张二维图像划分为一个或多个子图像,每个子图像对应一个剩余分拣目标200,然后比较每个剩余分拣目标200对应子图像的相似度,计算量少且对比精确。
[0164]
具体的,先获取待分拣场景中最近一次所有分拣目标均未进行位姿更新的历史位姿,然后这些历史位姿,至少确定与每个剩余分拣目标200的历史位姿所对应的感兴趣区
域。可以理解,每个剩余分拣目标200的历史位姿对应一个感兴趣区域,因此,待分拣场景中剩余分拣目标200的数量与感兴趣区域的数量一一对应。
[0165]
在确定每个剩余分拣目标200的感兴趣区域后,对待分拣场景中上一次分拣操作前所有分拣目标的二维图像进行处理,从而从该二维图像中提取出与每个剩余分拣目标200感兴趣区域对应的第一子图像。可以理解,第一子图像可以是每个剩余分拣目标200完整的成像图案,也可以是剩余分拣目标200被其他剩余分拣目标200遮挡后不完整的成像图案,第一子图像的数量与感兴趣区域的数量一一对应。
[0166]
对应的,在确定每个剩余分拣目标200的感兴趣区域后,也需对分拣操作后剩余分拣目标200的二维图像进行处理,从而从该二维图像中提取出与每个剩余分拣目标200感兴趣区域对应的第二子图像。可以理解,第二子图像可以是每个剩余分拣目标200完整的成像图案,也可以是剩余分拣目标200被其他剩余分拣目标200遮挡后不完整的成像图案,第二子图像的数量与感兴趣区域的数量一一对应。
[0167]
将每个剩余分拣目标200对应的第二子图像与第一子图像进行相似度对比:如果至少部分剩余分拣目标200的第二子图像与第一子图像的相似度大于等于相似度阈值,则确定至少部分剩余分拣目标200的实际位置未发生改变;如果所有剩余分拣目标200的第二子图像与第一子图像的相似度均小于相似度阈值,则确定所有剩余分拣目标200的实际位置均发生改变。
[0168]
示例性的,请参阅图1,当前待分拣场景中有5个剩余分拣目标200,5个部分剩余分拣目标200呈堆叠摆放,部分呈单独摆放。
[0169]
将第一个剩余分拣目标200对应的第二子图像与第一子图像进行相似度对比:如果该剩余分拣目标200的第二子图像与第一子图像的相似度大于等于相似度阈值,则确定该剩余分拣目标200的实际位置未发生改变,后续执行步骤s230;如果该剩余分拣目标200的第二子图像与第一子图像的相似度均小于相似度阈值,则确定该剩余分拣目标200的实际位置均发生改变,后续执行步骤s240。
[0170]
将第二个剩余分拣目标200对应的第二子图像与第一子图像进行相似度对比:如果该剩余分拣目标200的第二子图像与第一子图像的相似度大于等于相似度阈值,则确定该剩余分拣目标200的实际位置未发生改变,后续执行步骤s230;如果该剩余分拣目标200的第二子图像与第一子图像的相似度均小于相似度阈值,则确定该剩余分拣目标200的实际位置均发生改变,后续执行步骤s240。
[0171]
同理依次类推,直至比较完5个剩余分拣目标200对应的第二子图像与第一子图像的相似度,得到对应的比较结果,然后根据比较结果执行步骤s230或步骤s240。
[0172]
请参阅图5,在一个具体实施例中,所述步骤s222将每个所述剩余分拣目标200对应的所述第二子图像与所述第一子图像进行相似度对比,包括以下子步骤:
[0173]
s222a、基于结构相似性算法,确定每个所述剩余分拣目标200的所述第二子图像与所述第一子图像的相似度;
[0174]
s222b、判断每个所述剩余分拣目标200的所述第二子图像与所述第一子图像的相似度是否大于等于所述相似度阈值。
[0175]
本实施例采用结构相似性算法(structural similarity index method,ssim)来对每个剩余分拣目标200对应的第二子图像与第一子图像进行相似度对比。具体的,先通过
ssim算法计算出每个剩余分拣目标200的第二子图像与第一子图像的相似度,然后判断对应的相似度是否大于等于相似度阈值,然后根据判断结果执行步骤s223或s224。
[0176]
可以理解,ssim算法为现有常见的图像相似度对比方法,具体可参见现有文献中对该算法的描述,本技术在此不再赘述。
[0177]
在其他实施例中,也可采用其他的图像相似度对比方法来对每个剩余分拣目标200对应的第二子图像与第一子图像进行相似度对比,在此不做具体限定。
[0178]
需要说明的是,步骤s250~s270可以在步骤s210之后,步骤s220之前执行,也可在步骤s210之前执行,在此不做具体限定。
[0179]
请参阅图7和图8,在一个实施例中,可通过如下方式获取每个剩余分拣目标200对应的感兴趣区域。
[0180]
具体的,所述基于视觉识别的分拣方法还包括以下步骤:
[0181]
s280、获取所述待分拣场景中分拣目标的模板边界框201。
[0182]
在本实施例中,模板边界框201(bounding box,简称bbox)的形状可以为与分拣目标的形状一致,用于后续识别三维图像中的每个剩余分拣目标200,以便确定每个剩余分拣目标200的感兴趣区域。
[0183]
具体以三维图像为点云为例,通过点云匹配识别出三维点云中每个剩余分拣目标200的当前位姿,而模板边界框201也为三维点云,本身具有6d位姿属性以及由8个三维顶点构成,8个三维顶点的相互关系为已知。
[0184]
在其他实施例中,模板边界框201的形状也可以为预设形状,具有6d位姿属性以及多个特征点,多个特征点的相互关系也为已知。
[0185]
则所述步骤s260基于最近一次所有分拣目标均未进行位姿更新的历史位姿,至少确定与每个所述剩余分拣目标200的历史位姿所对应的感兴趣区域,具体包括以下子步骤:
[0186]
s261、将所述模板边界框201按照最近一次每个所述剩余分拣目标200均未进行位姿更新的历史位姿,逐一框选每个所述剩余分拣目标200的与所述历史位姿对应的三维图像,然后记录每次框选过程中所述模板边界框201在相机坐标系下的顶点坐标;
[0187]
s262、将每次框选记录的所述模板边界框201在相机坐标系下的顶点坐标转换成像素坐标系下的顶点坐标;
[0188]
s263、在图像坐标系下,构建容纳所述模板边界框201所有顶点坐标的最小外接矩形,然后将所述最小外接矩形确定为所述剩余分拣目标200的历史位姿所对应的感兴趣区域;
[0189]
s264、重复以上所有操作,直至确定所有所述剩余分拣目标200的历史位姿所对应的感兴趣区域。
[0190]
由于每个剩余分拣目标200所形成的点云模型可能具有复杂纹理信息,因此通过点云模型直接获取每个剩余分拣目标200特征点的计算量大。为解决此问题,本实施例通过模板边界框201逐一框选剩余分拣目标200,能够快速确定每个剩余分拣目标200的特征点,然后基于最小外接矩形法确定每个剩余分拣目标200的感兴趣区域。
[0191]
具体的,在利用模板边界逐一框选点云中每个剩余分拣目标200时,由于模板边界框201的8个三维顶点的相互关系为已知,因此若模板边界框201按照当前位姿,逐一框选每个剩余分拣目标200,实际为匹配每个剩余分拣目标200,则每个剩余分拣目标200的特征点
能够转换成模板边界框201的8个三维顶点,然后通过获取模板边界框2018个三维顶点的坐标,即可获得对应剩余分拣目标200的特征点坐标。如此,减少提取剩余分拣目标200特征点的计算量。
[0192]
在一个实施例中,如图8所示,模板边界框201框选剩余分拣目标200的标准为:根据所获得剩余分拣目标200的最近一次未进行位姿更新的历史位姿,可以将模板边界框201的8个三维顶点依次转换到相机坐标系下每个剩余分拣目标200对应的位置,并且所识别出来的每个剩余分拣目标200点云被包裹在模板边界框201的8个三维顶点内。
[0193]
然后通过摄像头20的相机内参,将相机坐标系下的模板边界框201的8个三维顶点映射到二维图像中图像坐标系下,从而得到8个顶点的像素坐标值,再通过基于最小外接矩形法以及8个顶点的像素坐标值,构建容纳8个顶点的最小外接矩形,从而在二维图像中确定剩余分拣目标200的历史位姿所对应的感兴趣区域的位置和大小。
[0194]
重复以上所有操作,直至确定所有剩余分拣目标200的历史位姿所对应的感兴趣区域。
[0195]
综上,本实施例基于每个剩余分拣目标200的位姿,采用模板边界框201框选每个剩余分拣目标200,从而获取每个剩余分拣目标200对应的感兴趣区域,相较于通过点云模型直接获取每个剩余分拣目标200特征点的方式,计算量少。此外,相较于在二维图像中直接识别每个剩余分拣目标200并获取对应感兴趣区域的方式,在二维图像中直接识别每个剩余分拣目标200难度较大,同时也易受到剩余分拣目标200堆叠所带来的识别影响,而本实施例采用模板边界框201框选每个剩余分拣目标200,由于在计算每个剩余分拣目标200的位姿时就已经识别出每个剩余分拣目标200,因此此方式无需重复在二维图像中识别出每个剩余分拣目标200,同时也不易受到剩余分拣目标200堆叠所带来的识别影响,识别精度更高。
[0196]
在其他实施例中,也可通过深度学习的方法获取每个剩余分拣目标200对应的感兴趣区域。
[0197]
在一示例性实施例中,本技术还提供一种包括计算机程序的计算机可读存储介质,该计算机程序被处理器执行时实现如上述任一项实施例所述的基于视觉识别的分拣方法的步骤。例如,该计算机可读存储介质可以为上述包括计算机程序的存储器,上述计算机程序可由智能分拣系统100的处理器执行以完成如上述任一实施例所述的基于视觉识别的分拣方法,并达到如上述方法一致的技术效果。
[0198]
以上仅为本技术的较佳实施方式,并非因此限制本技术的专利范围,凡是利用本技术说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本技术的专利保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1