用于诊断井漏的建模方法及诊断井漏的方法与流程
本发明涉及油气钻探工程技术领域,具体地涉及一种用于诊断井漏的建模方法及诊断井漏的方法。
背景技术:
井漏是石油钻井过程中的常见复杂事故,井漏事故会带来严重的危害:不仅会增加非生产时间和操作成本,还会导致其他复杂事故,例如井塌、卡钻、甚至井喷等。井漏常发生在疏松的、衰竭的、溶洞或裂缝发育的地层,尤其是缝洞发育的碳酸盐岩地层,这些地层容易发生严重漏失,并且漏失机理复杂。
井漏的复杂情况是众多因素共同作用的结果,且存在随机性和不确定性。地震和测井方法虽然能在一定程度上预测易发生漏失的区域、层位,但是预测精度不高。
技术实现要素:
本发明的目的是提供一种用于诊断井漏的建模方法及诊断井漏的方法,其可得到录井特征参数与井漏或非井漏结果之间的多个对应关系,从而获得用于诊断井漏的诊断模型,并基于该诊断模型可对正在钻井过程中的待诊断井对进行诊断,从而实现对井下漏失的精确预警。
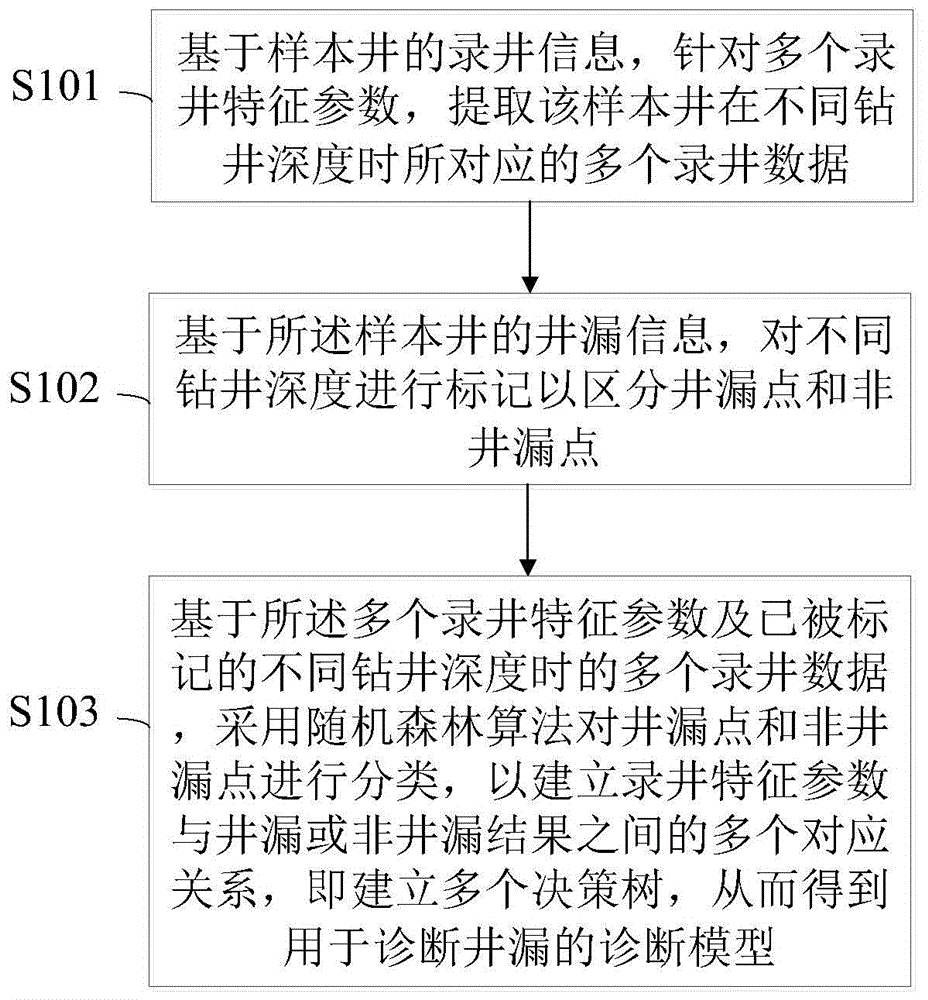
为了实现上述目的,本发明一方面提供一种用于诊断井漏的建模方法,该建模方法包括:基于样本井的录井信息,针对多个录井特征参数,提取该样本井在不同钻井深度时所对应的多个录井数据;基于所述样本井的井漏信息,对不同钻井深度进行标记以区分井漏点和非井漏点;以及基于所述多个录井特征参数及已被标记的不同钻井深度时的多个录井数据,采用随机森林算法对井漏点和非井漏点进行分类,以建立录井特征参数与井漏或非井漏结果之间的多个对应关系,即建立多个决策树,从而得到用于诊断井漏的诊断模型。
可选的,所述基于所述多个录井特征参数及已被标记的不同钻井深度时的多个录井数据,采用随机森林算法对井漏点和非井漏点进行分类包括以下步骤:基于不同钻井深度所对应的多个录井数据,随机选取相同或不同钻井深度所对应的多个录井数据,以组成训练集合,其中,随机选取的次数与所述不同钻井深度的样本数相同;按照预设顺序,采用所述多个录井特征参数对所述训练集合逐步进行分割;以及在满足停止分割条件的情况下,停止执行分割动作,从而获得所述训练集合所对应的决策树,进而实现对井漏点和非井漏点的分类。
可选的,所述停止分割条件为预设的分割次数。
可选的,所述预设顺序由在各个录井特征参数在不同钻井深度时所对应的录井数据下的所述训练集合的基尼指数的大小决定。
可选的,所述在各个录井特征参数在不同钻井深度时所对应的录井数据下的所述训练集合的基尼指数为,
可选的,该建模方法还包括:在一录井特征参数在某钻井深度所对应的录井数据下的所述训练集合的基尼指数最小的情况下,最先采用该录井特征参数及其所对应的录井数据对所述训练集合进行分割。
可选的,该建模方法还包括:基于所有训练集合及其所对应的决策树,对建立所述决策树时用于分割的多个录井特征参数进行重要性排序。
可选的,所述基于所有训练集合及其所对应的决策树,对建立所述决策树时用于分割的多个录井特征参数进行重要性排序包括以下步骤:基于在组成每个所述训练集合时的袋外数据,确定每个所述训练集合所对应的决策树的袋外误差;针对建立每个所述训练集合所对应的决策树时用于分割的多个录井特征参数中的每一者,随机打乱所述袋外数据中该录井特征参数所对应的录井数据以重新形成一个测试集合;基于建立每个所述训练集合所对应的决策树时用于分割的多个录井特征参数中的每一者所对应的重新形成的测试集合及该决策树,重新确定与该多个录井特征参数中的每一者所对应的打乱后的误差;以及基于建立每个所述训练集合所对应的决策树时用于分割的多个录井特征参数中的每一者所对应的打乱后的误差及该决策树的袋外误差,确定建立所述决策树时用于分割的多个录井特征参数中的每一者的重要性,其中,所述袋外数据为未被选取到的多个钻井深度中各钻井深度所对应的多个录井数据。
可选的,所述基于建立每个所述训练集合所对应的决策树时用于分割的多个录井特征参数中的每一者所对应的打乱后的误差及该决策树的袋外误差,确定建立所述决策树时用于分割的多个录井特征参数中的每一者的重要性包括:基于建立每个所述训练集合所对应的决策树时用于分割的任一录井特征参数所对应的打乱后的误差及该决策树的袋外误差的差值,确定该录井特征参数对应的该差值在所有决策树上的平均值;基于所述录井特征参数所对应的打乱后的误差及所述决策树的袋外误差的差值,确定该录井特征参数对应的该差值在所有决策树上的标准差;以及基于所确定的平均值及标准差,确定该录井特征参数的重要性。
可选的,该建模方法还包括:对所提取的多个录井数据进行处理,以剔除无效数据。
可选的,所述录井特征参数包括所述钻井深度、钻速、转速、大钩载荷、钻压、泵压、扭矩、泵冲、钻井液流入密度、钻井液流出密度、排量、出口流量以及气测含量。
相应地,本发明还提供一种诊断井漏的方法,该方法包括:将待诊断井的录井特征参数及相应的录井数据输入上述的用于诊断井漏的建模方法建立的诊断模型;以及根据所述诊断模型输出的诊断结果,确定所述待诊断井的井漏结果。
相应地,本发明还提供一种机器可读存储介质,所述机器可读存储介质上存储有指令,该指令用于使得机器执行上述的诊断井漏的方法。
通过上述技术方案,本发明创造性地通过提取样本井在不同钻井深度时与多个录井特征参数相应的多个录井数据,然后对包括钻井深度在内的每组录井特征参数所对应的多个录井数据进行井漏点和非井漏点标记,最后采用随机森林算法对已被标记的不同钻井深度时的录井数据进行井漏点和非井漏点分类,获得录井特征参数与井漏或非井漏结果之间的多个对应关系,从而得到用于诊断井漏的诊断模型。通过该诊断模型可在待诊断井的钻井过程中对其进行诊断,实现对井下漏失的精确预警。
本发明的其它特征和优点将在随后的具体实施方式部分予以详细说明。
附图说明
附图是用来提供对本发明的进一步理解,并且构成说明书的一部分,与下面的具体实施方式一起用于解释本发明,但并不构成对本发明的限制。在附图中:
图1是本发明一种实施方式提供的用于诊断井漏的建模方法的流程图;
图2是本发明一种实施方式提供的已被标记的包含钻井深度与钻速所对应的录井数据的对应关系图;
图3是本发明一种实施方式提供的用于诊断井漏的建模方法所产生的一棵决策树的示意图;
图4是本发明一种实施方式提供的生成决策树的过程中对录井数据进行分割的示意图;
图5(a)是本发明一种实施方式提供的诊断模型的训练结果的混淆矩阵;
图5(b)是本发明一种实施方式提供的诊断模型的训练结果的混淆矩阵;
图5(c)是本发明一种实施方式提供的诊断模型的训练结果的混淆矩阵;
图6是本发明一种实施方式提供的录井特征参数的重要性评估的结果图;
图7是本发明一种实施方式提供的待诊断井对诊断模型准确度的测试结果图;以及
图8是本发明一种实施方式提供的诊断井漏的方法的流程图。
具体实施方式
以下结合附图对本发明的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本发明,并不用于限制本发明。
现有技术中采用地震和测井方法诊断待诊断井是否漏失,虽然能在一定程度上预测易发生漏失的区域及层位,但其预测结果的精度不高。针对上述诊断方法,发明人考虑到由于其没有考虑钻井过程中的施工参数,故在待诊断井的钻井过程中不能进行诊断,即不能进行随钻诊断。另外,由于井漏的各个特征参数和井漏结果之间没有明显可见的对应关系,现有技术无法根据各个特征参数对井漏进行准确诊断。
目前人工智能中的机器学习方法被广泛应用于各行各业,机器学习中的一些算法能寻找大量数据与结果之间模糊未知的联系。因此,本发明利用机器学习中的随机森林算法对已钻井的相关数据进行挖掘、训练,建立一种基于人工智能随钻数据分析的用于诊断井漏的诊断模型,根据所建立的诊断模型结合待诊断井的随钻数据可对井漏结果进行精确地预测。
图1是本发明一实施例提供的用于诊断井漏的建模方法的流程图。如图1所示,本发明提供的用于诊断井漏的建模方法可包括以下步骤:步骤s101,基于样本井的录井信息,针对多个录井特征参数,提取该样本井在不同钻井深度时所对应的多个录井数据;步骤s102,基于所述样本井的井漏信息,对不同钻井深度进行标记以区分井漏点和非井漏点;以及步骤s103,基于所述多个录井特征参数及已被标记的不同钻井深度时的多个录井数据,采用随机森林算法对井漏点和非井漏点进行分类,以建立录井特征参数与井漏或非井漏结果之间的多个对应关系,即建立多个决策树,从而得到用于诊断井漏的诊断模型。该建模方法可通过提取样本井在不同钻井深度时与多个录井特征参数相应的多个录井数据,然后对包括钻井深度在内的每组录井特征参数所对应的多个录井数据进行井漏点和非井漏点标记,最后采用随机森林算法对已被标记的不同钻井深度时的录井数据进行井漏点和非井漏点分类,获得录井特征参数与井漏或非井漏结果之间的多个对应关系,从而得到用于诊断井漏的诊断模型。通过该诊断模型可在待诊断井的钻井过程中对其进行诊断,实现对井下漏失的精确预警。
对于步骤s101,选取同一区块的已钻漏失井为样本井,例如选取15个样本井,针对该15个样本井所执行的操作步骤完全相同,故下面仅针对一个样本井的情况进行描述。基于所述样本井的录井信息,提取该样本井在不同钻井深度时与多个录井特征参数相应的多个录井数据,以形成多组与包括钻井深度在内的多个录井特征参数一一相应的录井数据。其中,所述录井特征参数可包括所述钻井深度、钻速、转速、大钩载荷、钻压、泵压、扭矩、泵冲、钻井液流入密度、钻井液流出密度、排量、出口流量以及气测含量等施工参数。例如,可建立以同一录井特征参数为列(以上述13个录井特征参数为例,共13列),且以同一钻井深度所对应的与上述13个录井特征参数一一相应的13个录井数据为行的特征样本矩阵,在本发明中将一行所对应的13个录井数据称为一个样本。
在执行步骤s101之后,该建模方法还可包括:对所提取的多个录井数据进行处理,以剔除无效数据。具体地,对所提取的多个录井数据进行预处理,然后利用数据统计中的异常点检测算法清理异常数据,并删除缺失数据。该步骤可剔除一些无效数据,从而为建立真实有效的诊断模型打下基础。
对于步骤s102,基于所述样本井的井漏信息,即不同钻井深度所对应的井漏结果之间的对应关系,对已建立的特征样本矩阵进行标记,形成带有输出响应的训练样本矩阵。具体地,根据统计的井漏点所在的钻井深度,一方面,可对已建立的样本矩阵进行标记,在最后增加一列用于记录井漏结果的输出响应,(例如,用1代表井漏点,0代表非井漏点);另一方面,如图2所示,在钻井深度与钻速的关系图中进行标记(菱形表示井漏点,圆点表示非井漏点或正常点)。其中,所述井漏信息可利用样本井的钻井日志、完井报告等资料统计漏失信息。
对于步骤s103,所述基于所述多个录井特征参数及已被标记的不同钻井深度时的多个录井数据,采用随机森林算法对井漏点和非井漏点进行分类可包括以下步骤:基于不同钻井深度所对应的多个录井数据,随机选取相同或不同钻井深度所对应的多个录井数据,以组成训练集合,其中,随机选取的次数与所述不同钻井深度的样本数相同;按照预设顺序,采用所述多个录井特征参数对所述训练集合逐步进行分割;以及在满足停止分割条件的情况下,停止执行分割动作,从而获得所述训练集合所对应的决策树,进而实现对井漏点和非井漏点的分类。其中,所述停止分割条件为预设的分割次数。通过提前设置预设的分割次数,可防止对样本进行过度拟合,从而确保所建立的诊断模型的精确性。或者,当经分割之后的数据组仅含有同一类井漏点或非井漏点时,停止对该数据组的分割。
所述按照预设顺序,采用所述多个录井特征参数对所述训练集合逐步进行分割可包括:基于预设规则随机选取所述多个录井特征参数中的几者,并且按照所述预设顺序对所述训练集合进行分割。所述预设规则可为从n个录井特征参数中随机抽取
具体地,对于样本数量为n的训练样本集(n行特征样本矩阵),有放回地随机抽样n次,组成样本数量为n的训练集合d,其中存在相同或不同样本的录井数据。利用13个录井特征参数对上述n个样本建立决策树进行分类。重复以上步骤t次,即获得了t棵决策树,根据这t棵决策树的投票结果决定样本是否为井漏点。
对于一棵决策树的生成过程可包括如下三个步骤:
步骤一,对于每一次分割,随机地从13个录井特征参数中抽取几个,抽取个数采用经验值
步骤二,按照最终所筛选出的最小值所对应的录井特征参数将训练集合d进行二元分割,分割之后形成两个节点。若经过步骤一中的计算及筛选步骤,获取的最小值为在出口流量l的l=16.52%下的基尼指数gini(d,l)min,则首先按照出口流量l将训练集合d分割为l<16.52%及l≥16.52%的两个节点,如图3所示。首次经出口流量分割之后,节点1(l<16.52%)中的样本多为井漏点,节点1(l≥16.52%)中的样本中包括混杂在一起的井漏点和非井漏点,如图4所示。
步骤三,递归地调用步骤一、二将各个(子)节点分割两个新的子节点,直到满足停止分割条件。对于分割之后的两个节点,形成各自对应的新的训练集合d1和d2,分别重复上述步骤一:针对节点1(训练集合d1)获取钻井深度h的h=2357m下的基尼指数gini(d1,h)min最小;以及针对节点2(训练集合d2)获取泵冲s的s=47.5spm(strokesperminutes)下的基尼指数gini(d2,s)min最小。接着,分别重复上述步骤二:针对节点1,按照钻井深度h将训练集合d1分割为h<2357m及h≥2357m的两个子节点,其中,子节点h<2357m中的所有样本可基于井漏信息被确定均为非井漏点,如图4所示,则停止对该子节点h<2357m进行分割操作;针对节点2,按照泵冲s将训练集合d2分割为s<47.5及s≥47.5的两个子节点。然后,对于其他三个子节点再重复步骤一、二,对各个子节点逐步进行分割,直至满足停止分割条件,从而可获得所述训练集合d所对应的决策树,进而可实现对井漏点和非井漏点的分类。
对于t个训练集合,分别重复上述步骤一至步骤三,可获得了t棵决策树,从而得到用于诊断井漏的诊断模型。对于待诊断井的随钻录井数据,可根据这t棵决策树的投票结果决定样本是否为井漏点(1表明为井漏点,0表明为非井漏点)。
为了防止在分割过程进行过度分割(即过度拟合),下面采用5折交叉验证来评估诊断模型的准确度,如图5所示。图5(a)中区域1和区域4分别表示诊断正确的非井漏点和井漏点的样本数量,以及区域2和区域3分别表示诊断错误的非井漏点和井漏点的样本数量;图5(b)中区域1和区域4分别表示诊断正确的非井漏点和井漏点的百分比,以及区域2和区域3分别表示诊断错误的非井漏点和井漏点的百分比;以及图5(c)中区域1和区域3分别表示非井漏点和井漏点的识别率;区域2和区域4分别表示非井漏点和井漏点的错误率。具体地,对于一个样本数量为9061的训练集合,8992个样本的输出结果正确,69个样本的输出错误;以及在396个井漏样本中,339个样本的输出正确,57个样本的输出错误,对于井漏点的识别率为86%。由此可见,由本发明所提供的用于诊断井漏的建模方法所建立的诊断模型的准确率较高。
本发明提供的用于诊断井漏的建模方法还可包括:基于所有训练集合及其所对应的决策树,对建立所述决策树时用于分割的多个录井特征参数进行重要性排序。所述基于所有训练集合及其所对应的决策树,对建立所述决策树时用于分割的多个录井特征参数进行重要性排序包括以下步骤:基于在组成每个所述训练集合时的袋外数据,确定每个所述训练集合所对应的决策树的袋外误差;针对建立每个所述训练集合所对应的决策树时用于分割的多个录井特征参数中的每一者,随机打乱所述袋外数据中该录井特征参数所对应的录井数据以重新形成一个测试集合;基于建立每个所述训练集合所对应的决策树时用于分割的多个录井特征参数中的每一者所对应的重新形成的测试集合及该决策树,重新确定与该多个录井特征参数中的每一者所对应的打乱后的误差;以及基于建立每个所述训练集合所对应的决策树时用于分割的多个录井特征参数中的每一者所对应的打乱后的误差及该决策树的袋外误差,确定建立所述决策树时用于分割的多个录井特征参数中的每一者的重要性,其中,所述袋外数据为未被选取到的多个钻井深度中各钻井深度所对应的多个录井数据。
其中,所述基于建立每个所述训练集合所对应的决策树时用于分割的多个录井特征参数中的每一者所对应的打乱后的误差及该决策树的袋外误差,确定建立所述决策树时用于分割的多个录井特征参数中的每一者的重要性包括:基于建立每个所述训练集合所对应的决策树时用于分割的任一录井特征参数所对应的打乱后的误差及该决策树的袋外误差的差值,确定该录井特征参数对应的该差值在所有决策树上的平均值;基于所述录井特征参数所对应的打乱后的误差及所述决策树的袋外误差的差值,确定该录井特征参数对应的该差值在所有决策树上的标准差;以及基于所确定的平均值及标准差,确定该录井特征参数的重要性。
具体地,对所述多个录井特征参数进行重要性排序的过程包括以下三个步骤:
步骤一,对于决策树t(t=1,...,t),确定随机抽样产生用于生成决策树t的训练集合时,未抽到的样本(即袋外样本)及抽取的用于分割并生成决策树t的录井特征参数xj(若在生成决策树t的过程中,采用了13个录井特征参数进行分割,则j=1,2,3...,12,13);将袋外样本的录井数据输入决策树t,获得投票结果;将诊断错误的样本数量与袋外样本的数量相除,获取该决策树t的袋外误差et。
步骤二,对于每个录井特征参数xj,随机打乱袋外样本中录井特征参数xj所对应的录井数据,例如,对于钻井深度h,若袋外样本为样本1及样本2,则袋外数据中钻井深度h所对应的录井数据为h1及h2,经随机打乱后可能存在包含样本1(包含h2及保持不变的其他录井特征参数所对应的录井数据,例如出口流量l及泵冲s分别对应的l1及s1)及样本2(包含h1及保持不变的其他录井特征参数所对应的录井数据,例如出口流量l及泵冲s分别对应的l2及s2)。基于录井特征参数xj及其所对应的随机打乱后的录井数据,重新测试决策树t的打乱后的误差etj。由于对生成决策树t时未用于分割的录井特征参数,未进行打乱操作,故其所对应的袋外误差与打乱后的误差相同。
步骤三,对13个录井特征参数中的每个录井特征参数,计算针对决策树的打乱后的误差与袋外误差的差值dtj=etj-et以及针对所有决策树的该差值dtj的平均值dj和标准差σj;然后,根据平均值dj和标准差σj可确定录井特征参数xj的重要性指标为dj/σj。该重要性指标dj/σj的数值越大,表明录井特征参数xj对于诊断井漏结果越重要。根据图6所示的录井特征参数的重要性结果,可以看出出口流量、钻进深度、流入钻井液密度、转速、气测含量对于诊断井漏结果相对更重要,并且重要性逐渐减低。
因此,根据本发明所提供的用于诊断井漏的建模方法所建立的诊断模型的可解释性较好,还能结合工程实际给出一些解释。并且,不用人为筛选特征录井参数,可得出一个输入特征的重要性排序。
综上所述,本发明创造性地通过提取样本井在不同钻井深度时与多个录井特征参数相应的多个录井数据,然后对包括钻井深度在内的每组录井特征参数所对应的多个录井数据进行井漏点和非井漏点标记,最后采用随机森林算法对已被标记的不同钻井深度时的录井数据进行井漏点和非井漏点分类,获得录井特征参数与井漏或非井漏结果之间的多个对应关系,从而得到用于诊断井漏的诊断模型。通过该诊断模型可在待诊断井的钻井过程中对其进行诊断,实现对井下漏失的精确预警。
相应地,如图8所示,本发明还提供一种诊断井漏的方法,该方法可包括以下步骤:步骤s801,将待诊断井的录井特征参数及相应的录井数据输入根据上述的用于诊断井漏的建模方法建立的诊断模型;以及根据所述诊断模型输出的诊断结果,确定所述待诊断井的井漏结果。
具体地,可将待诊断井的录井数据按照上述建立诊断模型过程中录井特征参数的顺序整理成标准格式,即含有13个特征参数的矩阵,并将该矩阵输入根据上述的用于诊断井漏的建模方法建立的诊断模型中,根据输出结果(例如,用1代表井漏点,0代表非井漏点)即可判断待诊断井在某钻井深度是否会发生漏失,当然,由于诊断模型包括多个决策树,故可根据输出结果为1或0的概率的大小来判断,例如,若输出结果为1的概率更大,则表明该钻井深度为井漏点,否则,表明该钻井深度为非井漏点。在有井漏点的情况下,确定该待诊断井具有井漏风险;在没有井漏点的情况下,确定该待诊断井不具有井漏风险。
选取一待诊断井(未参与机器学习)来测试诊断模型的准确度,将基于诊断模型所得到的诊断结果和根据统计的井漏信息所确定的实际漏失情况进行对比,如图7所示。为了明显地展示对比结果,将诊断结果所对应的数据集体左移,(从所示数据的纵坐标来看)诊断结果几乎能把大部分的井漏位置诊断出来。因此,基于上述诊断井漏的方法可对待诊断井的漏失情况进行智能化诊断,且诊断结果的精确度很高,从而实现对井下漏失进行准确预警。
相应地,本发明还提供一种机器可读存储介质,所述机器可读存储介质上存储有指令,该指令可用于使得机器执行上述的诊断井漏的方法。
以上结合附图详细描述了本发明的优选实施方式,但是,本发明并不限于上述实施方式中的具体细节,在本发明的技术构思范围内,可以对本发明的技术方案进行多种简单变型,这些简单变型均属于本发明的保护范围。
另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合。为了避免不必要的重复,本发明对各种可能的组合方式不再另行说明。
此外,本发明的各种不同的实施方式之间也可以进行任意组合,只要其不违背本发明的思想,其同样应当视为本发明所公开的内容。
- 还没有人留言评论。精彩留言会获得点赞!