一种基于人工智能的井下井眼轨迹跟踪方法
:
1.本发明涉及一种用于井下施工中能够实现井眼轨迹跟踪的方法。
背景技术:
2.油气田勘探和开发过程中,井眼轨迹测量非常重要,准确的井眼轨迹测量是地层对比、设计压裂等工作顺利进行的前提。当前石油天然气行业下井深度的测量方法主要是采用数钻杆的方式,但是在实际测量中由于钻杆在重力的作用下在井下会被拉长,所以我们很难获得比较准确的深度信息,造成误差。但由于影响因素错综复杂,无法全面考虑各种影响因素,同时由于技术与设备存在缺陷的原因,无法精确得到基本参数的数值,最终导致无法得到实时井眼轨迹。此外,现场所采用的测量方式得到的井深结果全部都在地面获得,不能在井下实时获取,这就导致在钻井及井眼调控过程效率低下,因此在井下获得实时的井眼轨迹在油田智能化趋势下已经变得极为重要。
技术实现要素:
3.为了解决背景技术中所提到的技术问题,本发明提出一种基于人工智能的井下井眼轨迹跟踪方法,该方法通过对目标区块进行钻井数据的相关采集及实时钻井数据等数据资料进行数据实时分析,对目标区块进行钻井数据的相关采集,将所获得的钻井数据进行数据预处理,将处理好的数据按一定比例分成训练集和测试集,并让人工智能算法或网络对训练集数据进行学习并输出训练好的模型;将测试集的数据输入到模型中并实时的得到井眼轨迹预计算的运行结果,再将得到的结果与数据流间隔时间相结合可得到井下井眼轨迹;再将实时数据流导入到成熟的集成模型中,之后将成熟的集成模型导入到井下设备的控制芯片中,控制芯片就可以对采集到的实时数据进行处理形成钻进过程中的井下井眼轨迹。
4.本发明的技术方案是:该种基于人工智能的井下井眼轨迹跟踪方法,其特征在于所述方法包括如下步骤:
5.第一步,对目标区块进行钻井数据采集,所述目标区块的钻井数据包括但不限于钻压、转速、扭矩、环空压力和地质信息;
6.第二步,对经由第一步所采集到的钻井数据进行数据预处理,所述数据预处理包括异常值剔除和数据标准化及归一化内容;
7.其中,所述异常值剔除按照如下路径进行:
8.对于钻井数据中的钻压、转速、扭矩、环空压力和地质信息,其中存在某组数据大于该列特征值的平均值的200%或者小于该列特征值的平均值的200%时,采用该特征的经验公式推导特征取值范围和人工删除该组数据的操作来进行异常值剔除;人工剔除异常值后,为防止对于钻井数据中的钻压、转速、扭矩、环空压力和地质信息中存在的干扰因素,采用异常值剔除算法dbscan进行剔除;
9.所述数据标准化及归一化按照如下路径进行:
10.(1)首先对钻井数据进行标准化,对钻井数据进行标准化所采用的函数为:
[0011][0012]
其中,x
i
代表原始数据,代表平均值,σ代表标准差;
[0013]
(2)对标准化后的钻井数据进行归一化操作,所采用的函数为:
[0014][0015]
其中,y
i
代表原始数据,min代表数据最小值,max代表数据最大值;
[0016]
第三步,建立一个在井下实时预测井眼轨迹的模型,所述模型的建立按照如下路径进行:
[0017]
(1)将经由第二步处理好的钻井数据按照80%的训练集和20%的测试集比例分成训练集和测试集;
[0018]
(2)利用人工智能算法对训练集数据进行学习并输出训练好的集成模型,具体路径如下:
[0019]
本步骤中的人工智能算法包括线性模型、树形模型和神经网络,其中,线性模型采用线性回归,模型定义为:
[0020]
f(x)=w0+w1x1+w2x2+
…
+w
n
x
n
[0021]
其中,w
i
代表权重,x
i
代表数据值;
[0022]
树形模型包括决策树,随机森林,bagging算法和xgboost算法;
[0023]
神经网络采用的是ann中的bp神经网络;
[0024]
线性模型、树形模型和神经网络按照如下模式配合,以输出可以得到井眼轨迹预计算运行结果训练好的模型:
[0025]
通过计算机编程语言python对这一过程进行编程,将数据输入到线性模型中,经过线性拟合后可得到具有拟合效果的线性模型;将数据输入到树形模型中,经过树形运算后可得到参数完善的树形模型;将数据输入到神经网络中,经过神经网络加权运算后可得到对应权重的神经网络,再将线性模型、树形模型和神经网络按照1:2:3的权重进行加权,即可得到用于输出井眼轨迹预计算结果的集成模型;
[0026]
所述集成模型的加权构建采用如下方法:
[0027]
model=lr+2
·
tree+3
·
dnn
[0028]
其中,model代表集成模型,lr代表线性模型,tree代表树形模型,ann代表神经网络模型;
[0029]
(3)将测试集的数据输入到经由第三步中步骤(2)得出的训练好的模型中,并实时的得到井眼轨迹预计算运行结果;再将得到的井眼轨迹预计算运行结果乘以现场实际数据测量时间的时间差,即可得到预测井眼轨迹;
[0030]
第四步,将经由第三步中步骤(2)所得到的集成模型导入到井下钻井设备芯片的运算器中,所述钻井设备芯片即为可自动处理上述过程并实时导出井眼轨迹结果的计算设备;所述集成模型导入流程如下:
[0031]
将所述钻井设备芯片与执行第三步中处理数据功能的计算机通过usb端口相连接,计算机检测到与所述钻井设备芯片连接成功时,打开keil5软件,用c语言对所述钻井设
备芯片进行编程,用于将经由第三步得到的集成模型的矩阵参数通过c语言写入到所述钻井设备芯片中用于实现自动计算井眼轨迹过程,用keil5完成编程后保存编程文件,打开stc
‑
isp软件加载keil5编程文件,通过stc
‑
isp软件最终完成对所述钻井设备芯片的导入过程;
[0032]
第五步,启动所述钻井设备实施钻进作业,所述钻井设备芯片自动调用集成模型中的参数完成井眼轨迹计算,实时获取井下井眼轨迹,实现基于人工智能的井下井眼轨迹跟踪。
[0033]
本发明具有如下有益效果:
[0034]
首先,本种基于人工智能的井下井眼轨迹跟踪方法,克服了现有技术受制于地质环境和技术与设备缺陷的缺点。由于在现场实际的工作中井眼轨迹结果是在井上地面获取的,缺乏一种在井下实时获取的井眼轨迹的方法,导致在钻进过程中对井下钻头位置和当前井眼轨迹的具体空间位置一无所知,一旦轨迹发生偏移在井上地面调整起来难度极大,而该方法可以有效解决上述问题,在井下实时获取井眼轨迹可以提高工作效率和降低轨迹的偏移。
[0035]
其次,该方法可以在非常短的时间内得到精准度较高的井眼轨迹数据,该方法的精准度高的原因在
技术实现要素:
中体现在:
[0036]
第一步的对目标区块进行钻井数据采集方面,数据资料收集详尽考虑全面;
[0037]
第二步的数据预处理方面,采用人工干预和算法处理的方式进行异常值剔除,这对于现场的数据来说尤为重要,现场所获取的数据存在错误可以及时发现及时剔除,用“专家知识驱动+数据驱动”的方式保证数据的流畅运转,在数据层面有效提高井眼轨迹精准度;
[0038]
第三步的井下实时预测井眼轨迹模型的建立方面,将目前机器学习领域和石油工程领域最有效的方法做了一个模型集成,综合考量各算法的优越性得到集成模型,在算法层面提高井眼轨迹精准度。
[0039]
此外,该方法不仅可用于实时获取井下井眼轨迹,还可以与地质条件相结合优化钻具组合,还能与地球物理测井方面结合实现实时的井下岩性识别,为现场施工人员提供更为多样化的辅助决策,也为现场的工作提高了效率,以达到最佳效果。
附图说明:
[0040]
图1是根据本发明实施例的井眼轨迹跟踪工作流程图。
[0041]
图2是根据本发明实施例的dbscan算法核心图。
[0042]
图3是根据本发明实施例的井眼轨迹跟踪可视化实例图。
具体实施方式:
[0043]
下面结合附图对本发明作进一步说明:
[0044]
为了使本技术领域的人员更好地理解本技术中的技术方案,下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述。
[0045]
本发明提供了一种基于人工智能的井下井眼轨迹跟踪方法,该方法通过在指定目标区块获取相关数据后,将现场随钻数据转化为可以输入到算法中的特定数据格式后,首
先通过对井眼轨迹预计算的分析与预测,提高井眼轨迹预计算的预测精度,进而与现场数据测量的时间间隔相结合,把现场所获取的时间间隔精确到以秒为单位,最终可以通过计算得到井眼轨迹跟踪的方法,再进一步可以根据软件可以绘制出有关于井眼轨迹随时间的变化曲线。
[0046]
图1是本发明技术方案中的井眼轨迹跟踪工作流程图,整个井眼轨迹跟踪工作流程图完全由python语言编程实现,由图1可知,对于数据的获取流程和清洗流程主要为随钻数据的获取、异常值剔除、数据标准化或归一化、最后经过格式的转换可以得到模型可读取的有效数据。在异常值剔除过程中,对于数据量较小的数据和某组数据大于该列特征值的平均值的200%或者小于该列特征值的平均值的200%时进行人工删除操作,处理数据量较大的数据时可采用dbscan密度聚类算法进行异常值剔除,可大大提高现场的效率和缩短现场施工人员的工作量,经处理后的有效数据可输入到训练好的集成模型中,可得到准确的井眼轨迹计算值。
[0047]
对于现场的实际情况,上述过程可细化为由四步组成:
[0048]
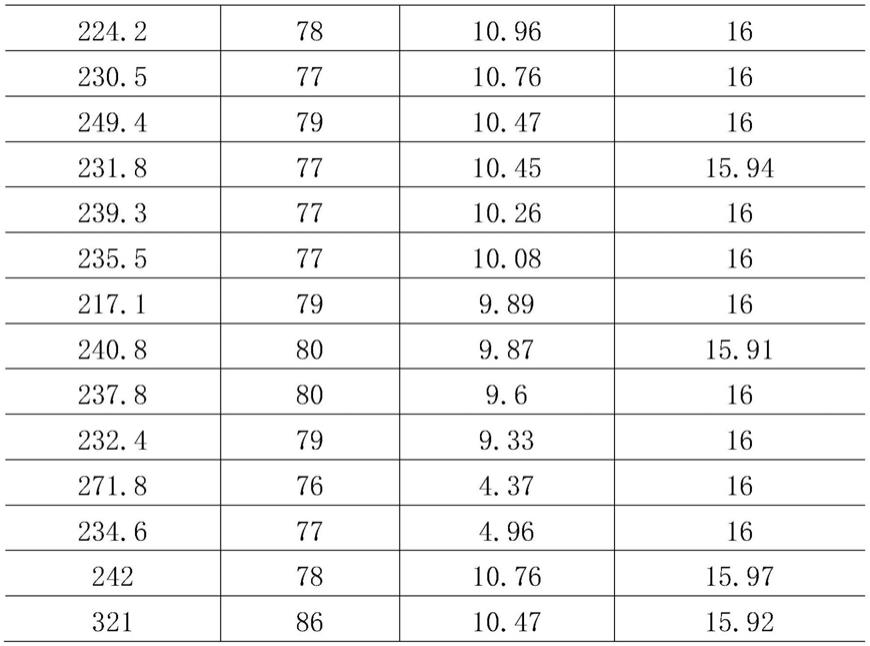
第一步,对目标区块进行钻井数据采集,所述目标区块的钻井数据包括但不限于钻压、转速、扭矩、环空压力和地质信息;选取部分真实数据如下:
[0049]
表1部分钻井数据
[0050][0051][0052]
第二步,对经由第一步所采集到的钻井数据进行数据预处理,所述数据预处理包括异常值剔除和数据标准化及归一化两项内容;
[0053]
其中,所述异常值剔除按照如下路径进行:
[0054]
对于钻井数据中的钻压、转速、扭矩、环空压力和地质信息,其中存在某组数据大于该列特征值的平均值的200%或者小于该列特征值的平均值的200%时,采用用该特征的经验公式推导特征取值范围和人工删除该组数据的操作来进行异常值剔除;人工剔除异常值后,为防止对于钻井数据中的钻压、转速、扭矩、环空压力和地质信息中存在的干扰因素,采用异常值剔除算法dbscan进行剔除,图2对异常值剔除算法dbscan流程进行了解释;
[0055]
图2是上述过程中的dbscan算法核心图,图2可理解为图中靠近边界的点为边界点,因为在半径eps内,它领域内的点不超过minpts个,假设设置的minpts为5;而中间的点之所以为核心点,是因为它邻域内的点是超过minpts个点的,通过这种聚类的方法,可以将部分由于现场记录出错或者设备误差等原因造成的异常值进行剔除,可得到对算法而言更有效的数据。
[0056]
dbscan算法执行步骤具体描述如下所示:
[0057]
输入:数据集d,半径参数eps,密度阈值minpts;
[0058]
输出:聚类结果及噪声数据;
[0059]
步骤1:从数据集d中随机抽取一个未被处理的对象p,且在它的eps近邻满足密度阈值要求称为核对象;
[0060]
步骤2:遍历整个数据集,找到所有从对象p的密度可达对象,形成一个新的簇;
[0061]
步骤3:通过密度相连产生最终簇结果;
[0062]
步骤4:重复执行步骤2和步骤3,直到数据集中所有对象都为“已处理”。
[0063]
通过上述步骤的数据剔除再配合人工筛选的辅助决策,可以使现场数据的存在更为有效。
[0064]
所述数据标准化及归一化按照如下路径进行:
[0065]
(1)首先对钻井数据进行标准化,对钻井数据进行标准化所采用的函数为:
[0066][0067]
其中,x
i
代表原始数据,代表平均值,σ代表标准差;
[0068]
(2)对标准化后的钻井数据进行归一化操作,所采用的函数为:
[0069][0070]
其中,y
i
代表原始数据,min代表数据最小值,max代表数据最大值;
[0071]
对于上述部分数据,当扭矩为10.47时,钻压列数据显然不符合规律,可以通过人工修改限制性条件的方式剔除;对于钻压为271.8和234.6时,扭矩列存在记录误差的情况但人工不易观察,所以可通过dbscan算法剔除这部分数据,异常值剔除后得到如下数据:
[0072]
表2异常值剔除后的数据
[0073][0074]
异常值剔除操作后对数据进行标准化和归一化,得到的结果如下表:
[0075]
表3标准化和归一化后的数据
[0076][0077]
第三步,建立一个在井下实时预测井眼轨迹的模型,所述模型的建立按照如下路径进行:
[0078]
(1)将经由第二步处理好的钻井数据按照80%的训练集和20%的测试集比例分成训练集和测试集;
[0079]
(2)利用人工智能算法对训练集数据进行学习并输出训练好的模型,具体路径如下:
[0080]
本步骤中的人工智能算法包括线性模型、树形模型和神经网络,其中,线性模型采
用线性回归,模型定义为:
[0081]
f(x)=w0+w1x1+w2x2+
…
w
n
x
n
[0082]
其中,w
i
代表权重,x
i
代表数据值;
[0083]
树形模型包括决策树,随机森林,bagging算法和xgboost算法;
[0084]
神经网络采用的是ann中的bp神经网络;
[0085]
线性模型、树形模型和神经网络按照如下模式配合,以输出可以得到井眼轨迹预计算运行结果训练好的模型:
[0086]
通过计算机编程语言python对这一过程进行编程,将数据输入到线性模型中,经过线性拟合后可得到具有拟合效果的线性模型;将数据输入到树形模型中,经过树形运算后可得到参数完善的树形模型;将数据输入到神经网络中,经过神经网络加权运算后可得到对应权重的神经网络,再将线性模型、树形模型和神经网络按照1:2:3的权重进行加权,即可得到用于输出井眼轨迹预计算结果的集成模型;
[0087]
所述集成模型的加权构建采用如下方法:
[0088]
model=lr+2
·
tree+3
·
ann
[0089]
其中,model代表集成模型,lr代表线性模型,tree代表树形模型,ann代表神经网络模型;
[0090]
在实际操作过程中,用python语言编程得到的集成模型是一种.dat文件格式,该模型文件占储存空间为12.2mb,这种文件中存储的就是通过机器学习算法学习所获得的模型参数,这种参数可直接与井下获取的数据相乘获取井眼轨迹。
[0091]
(3)将测试集的数据输入到经由第三步步骤(2)得出的训练好的模型中,并实时的得到井眼轨迹预计算运行结果;再将得到的井眼轨迹预计算运行结果乘以现场实际数据测量时间的时间差,即可得到预测井眼轨迹;
[0092]
第四步,将第三步所得到的集成模型导入到井下芯片的运算器中,所述井下芯片即为可自动处理上述过程并实时导出井眼轨迹结果的计算设备,将第三步所得到的集成模型导入到井下芯片流程如下:
[0093]
将井下芯片与第三步处理数据的计算机通过usb端口相连接,计算机检测到井下芯片连接成功时,打开keil5软件,用c语言对井下芯片进行编程,主要编程内容是将第三步得到的集成模型的矩阵参数通过c语言改写写入到井下芯片中并实现自动计算井眼轨迹过程,用keil5完成编程后保存编程文件,打开stc
‑
isp软件加载keil5编程文件,通过stc
‑
isp软件正式完成对井下芯片的导入过程;
[0094]
在实际工程中,对于井下芯片的选取可以按照电子方面专业人员的知识进行组装,要求为可以完成运算和存储功能的井下芯片即可。
[0095]
第五步,将第三步所得到的集成模型导入到井下芯片的运算器后,井下芯片自动调用集成模型中的参数完成井眼轨迹计算,实时获取井下井眼轨迹,实现基于人工智能的井下井眼轨迹跟踪。
[0096]
图3是图1井眼轨迹跟踪工作流程图中最后一步的可视化结果,从图中可以看出随着数据量的变化,井眼轨迹也在实时的发生变化,具体的变化趋势完全取决于现场的随钻数据所传递回来的参数,数据不同,曲线的变化趋势也就不同。通过这样的数据可视化,可以将实时的数据传递转化为实时的井眼轨迹跟踪曲线,极大地提升了现场施工作业人员的
工作效率,提供了辅助决策。下表为部分现场实际情况下,井下芯片中的模型计算的累计井深和该口测试井的真实井深:
[0097]
表4实际井深与预测井深对比
[0098][0099][0100]
由上表可知经由芯片计算过的累计井深和实测的累计井深几乎相同,由此可证明该方法在井下井眼轨迹跟踪方面具有可行性。
[0101]
以上所述的具体实施例,对本发明的目的、技术方案和效果进行了进一步详细说明,并不用于限制本技术。对于本领域技术人员来说,本技术可以有各种更改和变化。凡在本技术的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本技术的权利要求范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1