用户自适应接口的制作方法
本文实施例通常涉及用户自适应接口。
背景技术:
通常,自然语言接口在计算设备中是常见的,尤其在移动计算设备中,例如智能电话、平板计算机和膝上型计算机等。自然语言接口(nli)可以使用户能够利用自然语言(口语单词)与计算设备交互,而不是打字、用鼠标、触摸屏幕或者其他输入方式。用户可以简单地说出普通的日常单词和短语,并且nli将对输入进行检测、分析并进行反应。即使在nli可要求和/或接受文本输入的情况下,nli也可以提供可听的输出语音。所述反应可以包括提供合适的口头(合成语音)或文本响应。目前,nli技术提供的响应是静态的,也就是,通常nli对基本相似的用户输入每次以相同方式进行响应。
例如,如果用户向nli提供请求,如“你可以为我发个电子邮件吗?”,来自nli的响应可以是“你想要我给谁发这个消息呢?”或者“我应该给谁发送它呢?”。来自同一nli的响应会每次基本相同,无论用户使用的输入是“你可以为我发个电子邮件吗?”,还是更简洁的输入“发个电子邮件”或者更简单的输入“发电子邮件”。
作为另一例子,如果用户要求导航系统从他/她家指引至特定位置,目前可用的导航系统接口将会提供从用户家附近(例如从用户邻居的一点)至某点的相同或基本相似的指引。不论这个区域可能对于该用户而言是多么熟悉,导航系统接口都会提供相同的指引,从用户家导航至最近的洲际高速公路的入口匝道。目前可用的导航系统接口完全不考虑用户可能熟悉该地域,以及用户多年居住在该地域和/或在与提供前往洲际高速公路的相同指引的导航系统接口多次交互中,用户可能已经了解从家到洲际高速公路的路。
附图说明
图1是根据本公开的一个实施例的用于提供用户自适应自然语言接口的系统的示意图。
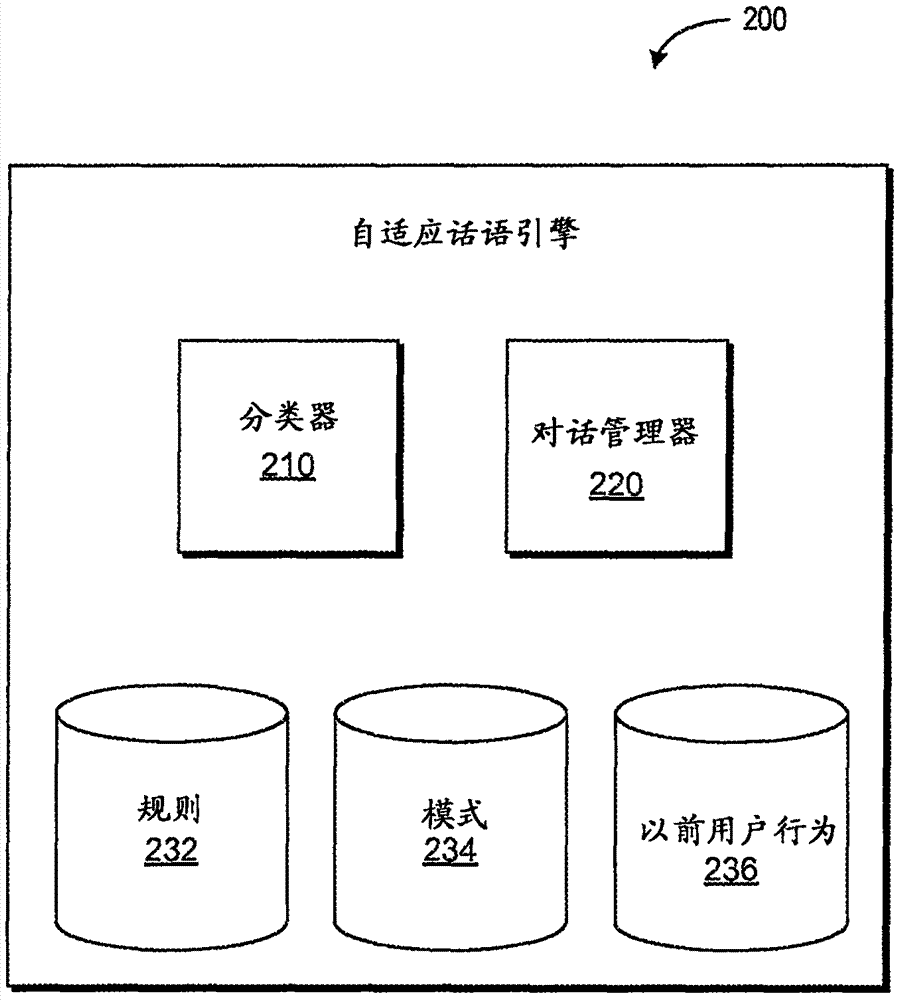
图2是根据一个实施例的用于提供用户自适应自然语言接口的系统的自适应话语引擎的示意图。
图3是根据本公开的一个实施例的用于提供用户自适应自然语言接口的方法的流程图。
图4是根据本公开的一个实施例的用于在导航系统中提供用户自适应指引的系统的示意图。
具体实施方式
自然语言接口(nli)技术目前普遍可用于各种计算设备中,尤其是移动计算设备,如智能电话、平板计算机以及膝上型计算机等。目前,nli技术提供的输出语音是静态的。换言之,nli技术提供的响应是静态的,也就是对于基本相似的输入语音的响应每次基本上是相同的。旨在相似响应的不同变化的输入语音(例如“你愿意为我发个电子邮件吗?”,“发个电子邮件”,或“发电子邮件”),从相同的nli在每种情况下都会给出基本相同的响应。nli不会考虑过去与同一用户的交互。并且,当前可用的nli技术不会基于用户如何讲出输入语音,而改变输出语音的风格或冗长度。
考虑到由于期望值不同,与商业同事不熟悉,不确定新商业同事会有什么样的响应,对亲近的朋友讲话可能不同于对新的商业同事讲话。讲话时可在风格(例如礼节程度)、冗长度(例如单词量、详细程度、叙述性程度)、个别单词或者单词序列的发音方式(例如:“我想要见见她”和“我想要见她”)、讲话者选择的特定词(例如:“我遇到她了”和“我碰到她了”)、用于传达给定含义的特定的单词顺序(例如:“约翰踢了小猫”和“小猫被约翰踢了”)不同。目前可用的nli技术不考虑输入语音的特征而提供用户自适应响应。
当前可用的nli技术的缺点的示意性示例是在导航系统中。不论特定地域对于用户可能多么熟悉,当前可用的nli技术都会对于从用户家至附近洲际高速公路的入口匝道给出基本相同的指引,不考虑用户可能熟悉该地域,并且用户多年居住在该地域或原先多次与提供前往洲际高速公路指引的nli交互中,用户可能已经了解从家到洲际高速公路的路。不包括nli、但是提供另一种接口(例如,视觉的)的导航系统,具有相似的缺点。
一些nli技术可能具有几个响应选项,但是这些选项是静态的,并且通常只是基于内部因子而简单地周期性旋转或者改变,如计时器或者计数器。这些对于响应的改变不是基于输入语音的方式或者特征的改变。简言之,当前可用的nli技术在响应用户输入方面(例如:用户语音、用户行为)不是自适应的。
本发明人意识到,提供用户自适应nli技术可以改善用户体验。使其行为适应给定用户的nli技术可以提供更合适于给定用户(例如更宜人的、更可接受的、更满意的)的响应。
公开的实施例提供了一种动态方法来呈现输出,如nli中的输出语音。公开的实施例可以记录用户行为和/或用户-系统交互,包括但不限于,发生的频度、语言学内容、风格、持续时间、工作流程、传递的信息等等。可以对于给定的用户创建模型,从而允许对于给定用户的自适应输出行为。所述模型可以例如基于使用模式、用户所作的语言学选择、成功和不成功交互的数量和/或特性、以及用户设置来对用户特征化。基于这些因子,公开的实施例可以被分类,所述分类可以允许对用于适配输出语音,例如通过改变单词选择、改变语音语域、改变冗长度、简化过程和/或交互、和/或假设输入,除非另有规定。
特征化用户的模型可以引起语音超越所选特定单词或词序的变化。特别地,所述模型还可以利用语言中的非词汇线索。这种线索的示例包括但不限于:语调(“约翰是法国人!”和“约翰是法国人?”)、重音(“他是罪犯!”和“判罚有罪”)、各种语言成分的长度、停顿和节拍、填充停顿(例如:约翰是嗯……朋友)以及其他不流利(例如:你说的是…是香蕉吗?)。由什么来构成非词汇线索可能取决于给定语言,包括方言。在某种意义上,任何语言学特征都可以作为非词汇线索,并可以被分析从而对语音分类。可以分析对nli技术的输入语音,从而识别语言学特征和/或非词汇线索,从而提高输入语音的分类。如前面提到的,可以基于输入语音的分类适配响应话语,从而提供自适应的nli。
图1是根据一个实施例的用于提供用户自适应nli的系统100的示意图。系统100可包括处理器102、存储器104、音频输出106、输入设备108以及网络接口140。处理器102可专用于系统100,或者可以合并进另一系统或计算设备和/或从其借入,例如台式机或移动计算设备(例如,膝上型计算机、平板计算机、智能电话等)。存储器104可以耦合于102或以其他方式可由处理器102访问。存储器104可以包括和/或存储协议、模块、工具、数据等。音频输出106可以是扩音器,其提供可听的合成输出语音。在其他实施例中,音频输出106可以是输出端口,用于向其他系统传输包括音频输出的信号。输入设备108可以是麦克风,如图所示。在其他实施例中,输入设备108可以是键盘或其他输入外围设备(例如,鼠标、扫描器)。在另外的实施例中,输入设备108可以简化为输入端口,其配置为接收传输文本或输入语音的输入信号。输入设备108可以包括或耦合于网络接口140,以接收来自计算机网络的文本数据。
系统100可以进一步包括语音-文本系统110(例如:自动语音识别或“asr”系统)、命令执行引擎112以及用户自适应对话系统120。
系统100可以包括语音-文本系统110,用于接收输入语音(例如:输入音频波形)并将音频波形转换为文本。该文本可以由系统100和/或其他系统处理,从而基于语音-文本输出而处理命令和/或执行操作。语音-文本系统110可以识别输入语音中的语音提示。语音提示可以传输到用户自适应对话系统120,该用户自适应对话系统120可以利用该语音提示导出用户行为,如下面将描述的。
所述系统还可以包括命令执行引擎112,被配置为基于用户输入(例如:输入语音、输入文本、其他输入)执行命令。所述命令执行引擎112例如可以启动另一应用(例如:电子邮件客户端、地图应用、sms文本客户端、浏览器等)、与其他系统和/或系统组件交互、通过网络接口140查询网络(例如:互联网)等。
网络接口140可以将系统100耦合至计算机网络,例如互联网。在一个实施例中,网络接口140可以是专用网络接口卡(nic)。网络接口140可以专用于系统100,或者可以合并入另一系统或计算设备、和/或从其借入,例如台式计算机或移动计算设备(例如,膝上型计算机、平板计算机、智能电话等)。
系统100可以包括用户自适应对话系统120,对用户输入(例如输入语音、输入文本)生成用户自适应响应。用户自适应对话系统120还可以包括一个或多个前面所述的组件,包括但不限于,语音-文本系统110、命令执行引擎112等。在图1所示的实施例中,用户自适应对话系统120可以包括输入分析器124、自适应话语引擎130、记录引擎132、语音合成器126、和/或数据库128。
用户自适应对话系统120提供用户自适应nli,对于给定用户适配其行为。用户自适应对话系统120可以是例如对于计算设备提供用户自适应nli的系统。用户自适应对话系统120可以确定并记录用户行为和/或用户-系统交互。所述用户行为可以包括利用频度或语言学特征发生的频度、语言学内容、风格、持续时间、工作流、传递的信息等。用户自适应对话系统120可以利用机器学习算法开发和/或使用模型。例如,用户自适应对话系统120可以使用回归分析、最大熵建模、或其他合适的机器学习算法。所述模型可以允许nli对于给定用户适配其行为。所述模型可以基于例如使用模式、用户做出的语言学选择、成功和不成功交互的数量和/或特性、以及用户设置,来特征化用户。基于这些因素,用户自适应对话系统120能够例如通过改变单词选择、改变语音提示、改变冗长度、简化程序和/或交互、和/或假设输入来适应于用户,除非另有规定。
系统100可以包括输入分析器124,用于分析系统100接收的用户输入。输入分析器124对用户输入的分析可以发起用户-系统交互。输入分析器124可以导出用户输入的含义。所述含义的导出可以包括识别命令和/或查询、想要的结果、和/或对所述命令和/或查询的响应。所述含义可以从文本输入或用户接口输入组件(例如:无线电按钮、复选框、列表框等)的操作导出。在其他实施例中,输入分析器124可以包括语音-文本系统110,用于将用户输入语音转换为文本。
输入分析器124还可以导出当前用户行为数据。输入分析器124可以分析用户输入,从而确定输入语音的语言学特征。当前用户行为数据可以包括识别的语言学特征和/或非词汇线索。当前用户行为数据还可以包括语言学选择标识,包括但不限于,单词选择、风格、语调降低或提高、音高、重音和音长。当前用户行为数据还可以包括用户设置。例如,用户可以将系统配置为给出简洁或简明的响应,而其他用户可能更优选让系统给出更详细和更多修饰的响应(例如:“下午4点”和“当然,我可以告诉你现在是什么时间了。现在是下午4点”)。作为另一示例,用户可以将系统配置为基本模式(其提供充分的细节)或专家模式(其假设用户知晓多个细节)。当前用户行为数据还可以包括利用频度或语言学特征发生的频度。
系统100可以包括自适应话语引擎130。自适应话语引擎130利用机器学习算法,以考虑以前用户行为数据和当前用户行为数据,从而确定用户输入的类别,并且选择响应于用户输入的自适应话语。自适应话语引擎130可以考虑用户行为,用户行为可以基于多个因素而特征化,包括利用频度或语言学特征发生的频度、语言学内容、风格、持续时间、工作流、传递的信息等。
自适应话语引擎130可以利用机器学习算法开发和/或利用模型。例如,自适应话语引擎130可以利用回归分析、最大熵建模、或其他合适的机器学习算法。所述模型可以允许nli使其行为适应于给定用户。所述模型可以根据当前用户行为数据,例如包括使用模式、用户做出的语言学选择、成功和不成功交互的数量和/或特性、以及用户设置,来特征化用户。所述特征可以允许对用户输入分类。所述分类可以由自适应话语引擎130用来选择自适应话语作为对用户输入的响应。所述自适应话语是自适应的,因为它们改变一个或多个单词的选择、语音提示、冗长度、简化或复杂过程和/或交互、和/或有关信息的假设。下面参照图2对自适应话语引擎的实施例进行更充分的描述。
系统100可以包括记录引擎132,用于记录用户-系统交互。记录引擎132的记录可以包括记录当前用户行为数据。换言之,记录引擎132可以记录用户输入的语言学特征和/或语音提示。从当前用户-系统交互记录的用户行为数据之后可以由自适应话语引擎130在未来的用户-系统交互中使用(作为以前用户行为数据)。
语音合成器126可以从自适应话语引擎130所选择的所选自适应话语合成语音。语音合成器可以包括任何合适的语音合成技术。语音合成器126可以通过连接数据库128中存储的录音片段来生成合成的语音。数据库128中存储的录音片段可以是与潜在的自适应话语对应的单词和/或部分单词对应。语音合成器126可以取出或以其他方式访问数据库128中存储的所存储的录音单元(完整的单词和/或部分单词,例如音素或双音素),并将这些录音连接在一起从而生成合成语音。语音合成器126可以配置为将文本自适应话语转换为合成语音。
数据库128可以存储如前所述的录音单元。数据库128还可以存储自适应话语引擎130所用的数据,从而对用户输入进行分类,包括但不限于使用方式、用户做出的语言学选择、交互成功和不成功的数量和/或特性、以及用户设置。
图2是根据一个实施例的用于提供用户自适应nli的系统的自适应话语引擎200的示意图。自适应话语引擎200包括分类器210和对话管理器220。自适应话语引擎200可以根据以前用户行为数据236和/或其他考量,例如规则232(例如,开发者所生成的规则、系统定义的规则等)和模式234(例如,统计模式、开发者所生成的模式等)来考虑当前用户行为数据,从而响应于用户输入选择自适应话语。
分类器210可以利用机器学习算法来开发和/或利用模型来考虑以前用户行为数据236、规则232和模式234,以便特征化用户输入,并生成用户输入的类别。分类器210可以利用回归分析、最大熵建模、或其他合适的机器学习算法。分类器210的机器学习算法可以考虑以前用户行为数据236,包括但不限于使用的频度(例如,语音提示、部分单词、单词、单词序列等)、语言学选择(例如,单词选择、风格、语调降低/提高、音高、重音、音长)、交互成功和不成功的数量和/或特性以及用户设置(例如,有关nli或对于提供有nli的计算设备的任何其他设置)。规则232和模式234还可以是分类器210的机器学习算法中考虑和/或利用的因素。通过利用机器学习算法,分类器210可以开发出可以特征化用户(和潜在用户)的输入的模型。基于这些考虑的因素(以及潜在的模型),分类器210可以特征化用户输入和/或生成用户输入的类别。
作为类别的示例,分类器210可以将给定语音输入特征化为“正式”,并利用指示“正式”的类别对其进行分类。所述类别可以提供正式的程度。例如,诸如“hello,howdoyoudo?(喂,您好吗?)”的输入语音可以分类为“正式”,而诸如“hi(你好)”的输入语音可以分类为“非正式”。
分类器210可以与将用户输入和所述类别传输给对话管理器。所述用户输入例如可用作为字符串(例如,文本)进行传输。在其他实施例中,用户输入可以作为波形(例如,输入语音的波形)进行传输。
对话管理器220利用用户输入和所述类别来选择自适应话语作为对用户输入的响应。自适应话语可以是自适应的,因为根据所述类别(通过考虑以前用户行为数据236和其他考量而生成),它们包括改变单词选择、语音提示、冗长度、简化或复杂过程和/或交互、和/或关于信息的假设中的一个或多个。
在一些实施例中,对话管理器220可以执行一个或多个命令,和/或包括命令执行引擎来根据用户输入执行一个或多个命令。例如,对话管理器220可以例如启动其他应用(例如,电子邮件客户端、地图应用、sms文本客户端、浏览器等)、与其他系统和/或系统组件交互、查询网络(例如互联网)等。换言之,对话管理器220可以从用户输入导出意思。
图3是根据本公开的一个实施例的用于提供用户自适应nli的方法300的流程图。可以接收302用户输入,从而发起用户-系统交互。所述用户输入可以是输入语音、输入文本及其组合。接收302用户输入可以包括语音向文本转换,以将输入语音转换为文本。可以分析304用户输入,以导出当前用户行为数据。当前用户行为数据可以包括指示用户输入的特性和/或语言学特征的数据,例如语音提示。当前用户行为数据还可以包括语言学选择的标识,包括但不限于单词选择、风格、语调降低或提高、音高、重音以及音长。
用户输入可以被特征化和/或分类306,基于一次或多次以前用户-系统交互过程中先前记录的以前用户行为数据和当前用户行为数据。分类306可以包括生成用户输入的类别。以前用户行为数据可以包括指示在一次或多次以前用户-系统交互期间用户输入的特征和/或语言学特征的数据(例如语音提示)。当前用户行为数据还可以包括语言学选择的标识,包括但不限于单词选择、风格、语调降低或提高、音高、重音和音长。
分类306可以包括利用机器学习算法处理用户输入,该机器学习算法考虑以前用户行为数据和当前用户行为数据。机器学习算法可以是任何合适的机器学习算法,例如最大熵、回归分析等。分类306可以包括考虑从用户输入推断的语言学特征(例如语音提示)的统计模式。分类306可以包括考虑包括用户语言学选择的以前用户行为数据和当前用户行为数据,来确定用户输入的类别。分类306可以包括考虑用户设置来确定用户输入的类别。分类306可以包括考虑规则来确定用户输入的类别。
可以基于用户输入和用户输入的类别来选择308用户自适应话语。可以基于用户输入的类别来选择用户自适应话语308,以包括一个或多个语音提示、改变的冗长、简化(例如,忽略典型响应中的一个或多个部分)、和/或附加输入的假设(例如,频繁选择的选项、系统参数的用户设置),除非用户输入另有规定。
可以记录310用户-系统交互。记录310的信息可以包括当前用户行为数据。记录310的信息可以包括更新的用户行为数据,基于以前用户行为数据和当前用户行为数据。记录310的当前用户行为数据之后变成未来用户-系统交互中的以前用户行为数据,这在未来用户-系统交互期间对用户输入分类306时会考虑。
可以生成用户输入的响应,其可以包括从所选择的用户自适应话语合成312输出语音。输出语音合成312可以包括连接例如可以存储在数据库中的录音片段。存储的录音片段可以对应于与潜在自适应话语对应的单词和/或部分单词。语音合成312可以包括取出或以其他方式访问存储的录音单元(例如,完整单词和/或部分单词,如音素或双音素),并将这些录音连接在一起以生成合成语音。
图4是根据本公开的一个实施例的用于在导航系统中提供用户自适应指引的系统400的示意图。自适应指引可以以各种输出形式呈现,包括但不限于,通过可视显示器和/或通过自然语言接口。系统400可以根据用户对行驶路线的熟悉程度自适配指引的详细程度。例如,只要用户行驶在熟悉地带,系统400可以推断用户知晓特定路线,从而能够选择跳过逐转弯指引。一旦用户进入不熟悉地域时,系统400可以适配并且开始提供更详细的指引。
作为示例,不是指示用户“在北方第一大街左转,在montague右转,并入101高速公路”,而是系统400可以适配所述指引,以简单地提供“前进至101”。所述指引可以通过显示器屏幕上的地图、在显示器屏幕上打印的文本而可视地呈现,和/或音频指示(例如,通过nli)。
系统400还可以学习用户偏好,例如更频繁地选择特定高速公路而不是其他、或者更频繁地选择本地公路而不是高速公路等。无论何时对可能的路线排序时,系统400都可以将这种偏好考虑进来,并将用户优选的路线排在更前。
无论何时对备选道路进行排序时,系统400还可以结合犯罪率信息,从而可以优选更安全的路线(超越更快和/或更熟悉)。
在图4所示的实施例中,与图1所示的系统100类似,系统400可以包括处理器402、存储器404、音频输出406、输入设备408以及网络接口440。
图4的系统400可以与前面参照图1所描述的系统100类似。相应地,类似的特征可以采用相同的参考数字标识。前面对相似地标识的特征已经阐述了相关公开,因此,此后可不再赘述。此外,系统400中的特定特征在附图中未示出或未通过参考数字标识,或者在后续的书面描述中也未特殊论述。然而,可以清楚的是这些特征与其他实施例中描述的或者相对这种实施例描述的特征相同或基本相同。从而,这种特征的相关描述等同地应用于系统400中的特征。相对于系统100相同描述的特征的任何合适的组合以及变形都可以适用于系统400,反之亦然。公开的该模式等同地适用于后续附图中描绘的和此后描述的任何其他实施例。
系统400包括其上显示地图数据、路线数据和/或位置数据的显示器(例如,显示屏幕、触摸屏等)。
系统400可以进一步包括用户自适应指引系统420,配置为基于以前用户行为数据(例如,对路线或其部分的熟悉度、用户偏好等)和/或统计模式(例如,关于给定区域的犯罪率)来生成用户自适应指引。
用户自适应指引系统420可以提供适用于给定用户和/或用户输入的用户自适应输出。用户自适应指引系统420可以是用于提供用户自适应nli的系统,例如用于导航系统。用户自适应指引系统420还可以提供用户自适应视觉接口,例如,采用地图、文本和/或其他视觉特征作为视觉输出呈现于显示屏幕上的自适应指引。
用户自适应指引系统420可以包括输入分析器424、定位引擎414、路线引擎416、地图数据418、自适应指引引擎430、记录引擎432、语音合成器426、和/或数据库428。
输入分析器424可以包括语音-文本系统并可以接收用户输入,包括到希望目的地的导航指引的请求。输入分析器424还可以导出当前用户行为数据,如上述参照图1的输入分析器124描述的那样。接收的输入包括路线的排除部分的指示,其指定可以从用户自适应导航指引中排除路线的一部分。例如,用户可以位于家中,并且可以频繁地行驶至收费公路,并且熟悉至收费公路的路线。用户可以提供用户输入作为语音命令,如“以收费公路为起点,指引至纽约市”。从这个命令中,输入分析器可以确定从当前位置至收费公路的排除部分。排除部分可以被自适应指引引擎430在生成用户自适应导航指引时考虑。
定位引擎414可以检测当前位置。路线引擎416可以分析地图数据418,从而确定从当前位置至希望目的地的潜在路线。
自适应指引引擎430可以生成用户自适应指引。自适应指引引擎430可以考虑当前用户行为数据和以前用户行为数据,从而使输出(例如,指引)适应于用户。例如,自适应指引引擎430可以推断出用户知晓某些路线,并且因此,可以选择自适应视觉线索和/或话语(例如,方向),只要用户行驶在熟悉区域就跳过逐转弯指引。一旦用户进入不熟悉地域时,自适应指引引擎430可以适配并且开始选择提供更详细的指引的自适应输出。考虑的用户行为可以包括使用的频度或语言学特征的频度、语言学内容、风格、持续时间、工作流程、传递的信息、路线的排除部分等。
自适应指引引擎430可以利用机器学习算法来开发和/或利用模型。例如,自适应指引引擎430可以利用回归分析、最大熵建模、或其他合适的机器学习算法。所述模型可以允许系统400使其行为适应于给定用户。所述模型可以考虑,例如使用模式(例如,频繁路线、熟悉区域)、用户做出的语言学选择、成功交互和不成功交互的数量和/或特性、以及用户设置。基于这些因素,用户自适应指引系统420能够适应于用户,例如通过改变视觉线索、改变单词选项、改变语音提示、改变冗长度、简化过程和/或交互(例如路线指引)、和/或假设输入,除非另有规定。
自适应指引引擎430可以进一步利用生成的模型来方便地从路线引擎416标识的潜在路线中进行路线选择。如上所述,自适应指引引擎430可以基于学习的用户偏好,例如更频繁选择高速公路(或路线的其他部分)、更频繁地选择某类路线部分(例如,地方道路或高速公路)以及用户设置(例如,总是基于时间(行驶的分钟)而非距离选择最短路线),对潜在的路线进行排序(或以其他方式便于路线选择)。
自适应指引引擎430还可以结合其他统计模式信息,例如犯罪率信息、收费、拥堵等,对备选路线进行排序,并且可以优选更安全(超过更快和/或更熟悉)、更便宜等的路线。
语音合成器426可以对自适应指引引擎430所选择的选定自适应指引合成语音。语音合成器426可以包括任何合适的语音合成技术。语音合成器426可以通过将存储在数据库428中的录音片段进行连接来生成合成语音。存储在数据库428中的录音片段可以对应于与潜在自适应指引对应的单词和/或部分单词。语音合成器426可以取出或以其他方式访问存储在数据库428中的录音单元(例如,完整的单词和/或部分单词,例如音素或双音素),并且将这些录音连接在一起从而生成合成语音。语音合成器426可以配置为将文本自适应话语转换为合成语音。
如可以意识到的,用户自适应话语可以用于各种应用中,并且不仅是上述实施例。其他应用可以包括媒体发布应用。
示例性实施例
下面提供自适应自然语言接口和其他自适应输出系统的一些示例性实施例。
示例1。一种用于提供用户自适应自然语言接口的系统,包括:输入分析器,分析用户的输入,以导出当前用户行为数据,其中当前用户行为数据包括用户输入的语言学特征;分类器,考虑以前用户行为数据和当前用户行为数据,并且确定用户输入的类别;对话管理器,基于用户输入和用户输入的类别来选择用户自适应话语;记录引擎,记录当前用户-系统交互,包括当前用户行为数据;以及语音合成器,从所选择的用户自适应话语合成输出语音,作为音频响应。
示例2。示例1的系统,其中所述输入分析器包括语音-文本子系统,用于接收语音用户输入,并将所述语音用户输入转换为文本,以分柝用户行为数据。
示例3。示例1-2中任一个的系统,其中所述分类器考虑包括语言学特征的统计模式的以前用户行为数据和当前用户行为数据来确定用户输入的类别,以及从用户输入推断的统计模式。
示例4。示例3的系统,其中所述语言学特征包括语音提示。
示例5。示例1-4中任一个的系统,其中,所述分类器考虑包括用户语言学选项的以前用户行为数据和当前用户行为数据,来确定用户输入的类别。
示例6。示例1-5中任一个的系统,其中所述分类器进一步考虑用户设置来确定用户输入的类别。
示例7。示例1-6中任一个的系统,其中所述分类器进一步考虑开发者生成的规则来确定用户输入的类别。
示例8。示例1-7中任一个的系统,其中所述分类器包括机器学习算法,用于结合以前用户行为来考虑当前用户行为,以确定用户输入的类别。
示例9。示例8的系统,其中所述分类器的机器学习算法包括最大熵和回归分析中的一个。
示例10。示例1-9中任一个的系统,其中通过包括基于所述用户输入的类别选择的语音提示而使通过对话管理器选择的所述用户自适应话语适应于用户输入。
示例11。示例1-10中任一个的系统,其中通过包括基于所述用户输入的类别选择的冗长度而使通过对话管理器选择的所述用户自适应话语适应于用户输入。
示例12。示例1-11中任一个的系统,其中通过简化用户交互而使通过对话管理器选择的所述用户自适应话语适应于用户输入。
示例13。示例12的系统,其中所述用户自适应话语通过忽略典型响应中的一个或多个部分而简化用户交互。
示例14。示例1-13中任一个的系统,其中通过包括附加输入的假设而使由对话管理器选择的所述用户自适应话语适应于用户输入,以其他方式附加输入未与用户输入一起提供。
示例15。示例14的系统,其中所述假设的附加输入包括频繁选择的选项。
示例16。示例14的系统,其中所述假设的附加输入包括系统参数的用户设置。
示例17。示例1-16中任一个的系统,进一步包括语音-文本子系统,接收语音用户输入,并将语音用户输入转换为文本,用于输入分析器进行分析。
示例18。示例1-17中任一个的系统,其中所述对话管理器包括命令执行引擎,基于用户输入在所述系统上执行命令。
示例19。示例1-18中任一个的系统,其中所述输入分析器进一步配置为导出用户输入的含义。
示例20。示例1-19中任一个的系统,其中记录当前用户行为数据包括:基于以前用户行为数据和当前用户行为数据,记录更新的用户行为数据。
示例21。一种用于提供用户自适应自然语言接口的计算机实现的方法,包括:在一个或多个计算设备上接收用户输入以发起用户-系统交互;在一个或多个计算设备上分析所述用户输入,从而导出当前用户行为数据,包括指示所述用户输入的特征的数据;基于一次或多次以前用户-系统交互期间以前记录的以前用户行为数据和当前用户行为数据,在一个或多个计算设备上对所述用户输入进行分类,从而生成所述用户输入的类别,所述以前用户行为数据包括指示在一次或多次以前用户-系统交互中的用户输入的特征的数据;基于所述用户输入和用户输入的类别来选择用户自适应话语;在一个或多个计算设备上记录所述用户-系统交互,包括当前用户行为数据;以及生成对所述用户输入的响应,包括从所选择的用户自适应话语合成输出语音。
示例22。示例21的方法,其中分类包括利用机器学习算法在一个或多个计算设备上处理所述用户输入,所述机器学习算法考虑以前用户行为数据和当前用户行为数据。
示例23。示例22的方法,其中所述机器学习算法是最大熵和回归分析中的一个。
示例24。示例21-23中任一个的方法,其中分类包括考虑语言学特征的统计模式,从而对所述用户输入进行分类,所述统计模式从所述用户输入推断。
示例25。示例24的方法,其中所述语言学特征包括语音提示。
示例26。示例21-25中任一个的方法,其中分类包括考虑包括用户语言学选项的以前用户行为数据和当前用户行为数据,来确定用户输入的类别。
示例27。示例21-26中任一个的方法,其中分类包括考虑用户设置来确定用户输入的类别。
示例28。示例21-27中任一个的方法,其中分类包括考虑规则来确定用户输入的类别。
示例29。示例21-28中任一个的方法,其中所述用户自适应话语包括根据所述用户输入的类别所选择的语音提示。
示例30。示例21-29中任一个的方法,其中所述用户自适应话语包括基于所述用户输入的类别选择的改变的冗长度。
示例31。示例21-30中任一个的方法,其中所述用户自适应话语基于所述用户输入的类别来简化用户交互。
示例32。示例31的方法,其中所述用户自适应话语通过忽略典型响应中的一个或多个部分而简化所述用户交互。
示例33。示例21-32中任一个的方法,其中基于附加输入的假设选择所述用户自适应话语,所述附加输入以其他方式未与用户输入一起提供。
示例34。示例33的方法,其中附加输入的假设包括频繁选择的选项。
示例35。示例33的方法,其中假设的附加输入包括关于系统参数的用户设置。
示例36。示例21-35中任一个的方法,其中接收用户输入包括将语音用户输入转换为文本用于分析,以导出当前用户行为。
示例37。示例21-36中任一个的方法,其中分析所述用户输入进一步包括导出用户输入的含义。
示例38。示例21-37中任一个的方法,其中记录当前用户行为数据包括基于以前用户行为数据和当前用户行为数据,记录更新的用户行为数据。
示例39。一种计算机可读介质,其上存储指令,当由处理器执行时,该指令使得处理器执行操作以提供用户自适应自然语言接口,所述操作包括:在一个或多个计算设备上接收用户输入以发起用户-系统交互;在一个或多个计算设备上分析所述用户输入,以导出当前用户行为数据,包括指示所述用户输入的特征的数据;基于一次或多次以前用户-系统交互过程中先前记录的以前用户行为数据和当前用户行为数据,在一个或多个计算设备上对所述用户输入进行分类,从而生成所述用户输入的类别,所述以前用户行为数据包括指示在一次或多次以前用户-系统交互期间的用户行为的特征的数据;基于所述用户输入和用户输入的类别选择用户自适应话语;在一个或多个计算设备上记录所述用户-系统交互,包括当前用户行为数据;以及生成对所述用户输入的响应,包括从所选择的用户自适应话语合成输出语音。
示例40。示例39的计算机可读介质,其中分类包括利用机器学习算法在一个或多个计算设备上处理所述用户输入,所述机器学习算法考虑以前用户行为数据和当前用户行为数据。
示例41。示例40的计算机可读介质,其中所述机器学习算法包括最大熵和回归分析中的一个。
示例42。示例39-41中任一个的计算机可读介质,其中分类包括考虑语言学特征的统计模式,以对所述用户输入进行分类,所述统计模式从所述用户输入推断出。
示例43。示例42的计算机可读介质,其中所述语言学特征包括语音提示。
示例44。示例39-43中任一个的计算机可读介质,其中所述分类包括考虑包括用户语言学选项的以前用户行为数据和当前用户行为数据,来确定用户输入的类别。
示例45。示例39-44中任一个的计算机可读介质,其中分类包括考虑用户设置来确定用户输入的类别。
示例46。示例39-45中任一个的计算机可读介质,其中分类包括考虑规则来确定用户输入的类别。
示例47。示例39-46中任一个的计算机可读介质,其中所述用户自适应话语包括根据所述用户输入的类别所选择的语音提示。
示例48。示例39-47中任一个的计算机可读介质,其中所述用户自适应话语包括基于所述用户输入的类别所选择的改变的冗长度。
示例49。示例39-48中任一个的计算机可读介质,其中所述用户自适应话语基于所述用户输入的类别简化用户交互。
示例50。示例49的计算机可读介质,其中所述用户自适应话语通过忽略典型响应中的一个或多个部分而简化所述用户交互。
示例51。示例39-50中任一个的计算机可读介质,其中基于附加输入的假设选择所述用户自适应话语,所述附加输入以其他方式未与用户输入一起提供。
示例52。示例51的计算机可读介质,其中所述附加输入的假设包括频繁选择的选项。
示例53。示例51的计算机可读介质,其中假设的附加输入包括关于系统参数的用户设置。
示例54。示例39-53中任一个的计算机可读介质,其中接收用户输入包括将语音用户输入转换为文本用于分析,从而导出当前用户行为。
示例55。示例39-54中任一个的计算机可读介质,其中分析所述用户输入进一步包括导出用户输入的含义。
示例56。示例39-55中任一个的计算机可读介质,其中记录当前用户行为数据包括基于以前用户行为数据和当前用户数据,记录更新的用户行为数据。
示例57。一种提供用户自适应导航指引的导航系统,包括:输入分析器,分析用户的输入,导出指引至希望目的地的请求以及导出当前用户行为数据,其中当前用户行为数据包括指示用户输入特征的数据;地图数据,提供地图信息;路线引擎,用于利用所述地图信息生成从第一位置至希望目的地的路线;自适应指引引擎,通过考虑以前用户行为数据和当前用户行为数据确定所述用户输入的类别以及基于所述用户输入、用户输入的类别和/或用户对路线上给定地域的熟悉程度选择用户自适应导航指引,生成用户自适应导航指引;以及记录引擎,记录当前用户-系统交互,包括当前用户行为数据。所述导航系统可以包括其上呈现用户自适应导航指引的显示器。所述导航系统可以进一步包括语音合成器,用于从所选择的用户自适应指引合成输出语音,作为音频响应。
示例58。示例57的导航系统,进一步包括定位引擎,用于确定所述导航系统的当前位置,其中所述对话管理器进一步基于所述导航系统的当前位置选择用户自适应导航指引,并且其中所述语音合成器基于所述导航系统的当前位置将所选择的自适应导航指引转换为语音输出。
示例59。示例57-58中任一个的导航系统,其中所述路线引擎利用地图信息生成多个从第一位置至希望目的地的潜在路线,并且其中所述自适应指引引擎对所述多个潜在路线进行排序,并对于所述多个潜在路线中排序最前的潜在路线选择用户自适应导航指引。
示例60。示例59的导航系统,其中所述自适应指引引擎至少部分基于用户偏好对所述多个潜在路线进行排序。
示例61。示例59的导航系统,其中所述自适应指引引擎至少部分基于所述多条潜在路线中的每一个上的区域中的犯罪率对所述多个潜在路线进行排序。
示例62。权利要求57的导航系统,其中所述用户输入包括指示从用户自适应导航指引中排除的所述路线的排除部分,并且其中所述自适应指引引擎生成忽略相对于所述路线的所述排除部分的指引的用户自适应导航指引。所述用户输入可以是语音输入,包括所述排除部分的口头指示。
示例63。一种提供用户自适应导航指引的方法,所述方法包括:在一个或多个计算设备上接收包括用于导航指引的请求的用户输入,以发起用户-系统交互;在一个或多个计算设备上分析所述用户输入,从而导出希望目的地并导出当前用户行为数据;利用地图信息生成从第一位置至所述希望目的地的路线;在一个或多个计算设备上,基于一次或多次以前用户-系统交互期间以前记录的以前用户行为数据和当前用户行为数据对所述用户输入进行分类,从而生成所述用户输入的类别,所述以前用户行为数据包括指示用户对所述路线上给定地域熟悉度的数据,其中所述类别反映用户对所述路线上给定地域的熟悉度;基于所述用户输入和用户输入的类别选择用户自适应导航指引,包括用户对路线上给定地域的熟悉度;在一个或多个计算设备上记录用户-系统交互,包括当前用户行为数据;以及生成对所述用户输入的响应,包括从所选择的用户自适应导航指引合成输出语音。
示例64。示例63的方法,进一步包括:确定当前位置,其中部分基于所述导航系统的当前位置选择所述用户自适应导航指引,并且其中基于所述导航系统的当前位置合成所述用户自适应导航指引以输出语音。
示例65。示例61-64中任一个的方法,其中生成路线包括:利用地图信息生成从第一位置至希望目的地的多个潜在路线,所述方法进一步包括:对所述多个潜在路线进行排序,其中对于所述多个潜在路线中排序最前的潜在路线,选择所述用户自适应导航指引。
示例66。示例65的方法,其中至少部分基于所述用户偏好对所述多个潜在路线进行排序。
示例67。示例65的方法,其中至少部分基于所述多个潜在路线中的每一个上的区域中的犯罪率对所述多个潜在路线进行排序。
示例68。一种系统,包括用于实现示例21-38及62-67中任一个的方法的部件。
示例69。一种用于提供用户自适应自然语言接口的系统,包括:用于分析用户输入以导出当前用户行为数据的部件,其中所述当前用户行为数据包括所述用户输入的语言学特征;用于基于以前用户行为数据和当前用户行为数据对所述用户输入进行分类的部件;用于基于所述用户输入和用户输入的类别选择用户自适应话语的部件;用于记录包括当前用户行为数据的当前用户-系统交互的部件;以及用于从所选择的用户自适应话语合成输出语音作为音频响应的部件。
示例70。示例69的系统,其中所述分类部件考虑以前用户行为数据和当前用户行为数据,包括语言学特征的统计模式,从而确定所述用户输入的类别,所述统计模式从所述用户输入推断出。
示例71。一种用于提供用户自适应自然语言接口的系统,包括:输入分析器,分析用户输入以导出当前用户行为数据,其中所述当前用户行为数据包括所述用户输入的语言学特征;分类器,考虑以前用户行为数据和当前用户行为数据,并且确定所述用户输入的类别;记录引擎,记录当前用户-系统交互,包括当前用户行为数据;以及对话管理器,基于所述用户输入和所述用户输入的类别,呈现用户自适应话语。
示例72。示例71的系统,其中所述分类器考虑以前用户行为数据和当前用户行为数据,包括语言学特征的统计模式,从而确定所述用户输入的类别,所述统计模式从所述用户输入推断出。
示例73。示例71的系统,其中所述分类器进一步考虑用户设置和开发者生成的规则中的至少一个,以确定所述用户输入的类别。
示例74。示例71的系统,其中所述输入分析器分析用户输入,从而导出到希望位置的导航指引的请求,并且其中所述用户自适应话语是用户自适应导航指引。
示例75。示例71的系统,进一步包括语音合成器,从所选择的用户自适应话语合成输出语音,作为音频响应。
为了全面理解本文所述的实施例,以上描述提供了大量的特定细节。然而,本领域技术人员将会意识到一个或多个特定细节是可以省略的,或者可以采用其它方法、部件或材料。某种情况下,众所周知的特征、结构或操作未示出或未详细描述。
此外,在一个或多个实施例中,所描述的特征、操作或特性可以按任何合适的方式进行各种不同的配置和/或组合来布置和设计。因此,所述系统和方法的实施例的详细描述,并不意在于限制本公开的要求保护的范围,而仅为表述本公开的可能实施例。此外,还将容易理解,如对于本领域技术人员显而易见的,结合所公开的实施例而描述的方法的步骤或动作的顺序可以改变。因此,附图中的任何顺序或细节描述只是为了图示的目的,并不意味着暗示所需顺序,除非指定为需要顺序。
实施例可以包括各种步骤,其可以体现在由通用或专用计算机(或其他电子设备)执行的机器可执行指令中。备选地,所述步骤可以由包括用于执行所述步骤的具体逻辑的硬件部件来执行,或者由硬件、软件和/或固件的结合来执行。
实施例还可以提供为计算机程序产品,包括其上具有存储指令的计算机可读存储介质,所述指令可用来对计算机(或其他电子设备)进行编程,从而执行本文所述的过程。所述计算机可读存储介质可以包括但不限于:硬驱动器、软盘、光盘、cd-rom、dvd-rom、rom、ram、eprom、eeprom、磁卡或光卡、固态存储设备或其他类型的适于存储电子指令的介质/机器可读介质。
如本文所使用的,软件模块或部件可以包括任何类型的位于存储设备和/或计算机可读存储介质中的计算机指令或计算机可执行代码。例如,软件模块可以包括计算机指令的一个或多个物理或逻辑模块,其可以被组织为执行一个或多个任务或实现特定抽象数据类型的例程、程序、对象、组件、数据结构等。
在某些实施例中,特定软件模块可以包括存储在存储设备中不同位置处的不同的指令,其一起实现模块的所述功能。事实上,模块可以包括单个指令或多个指令,并且可以分布在不同程序中的几个不同的代码段上以及跨几个存储设备分布。一些实施例可以实现在分布式计算机环境中,其中,由通过通信网络链接的远程处理设备执行任务。在分布式计算环境中,软件模块可以位于本地和/或远程存储器存储设备上。此外,数据库记录中被捆绑在一起或一起实施的数据可以驻留在相同的存储设备上,或者跨几个存储器设备驻留,并且可以在跨网络的数据库中的记录域中链接在一起。
对于本领域技术人员将是显然的是,在不脱离本发明的基本原理的情况下,可以对上述实施例的细节作出多个改变。因此,本发明的范围应当仅由下面的权利要求来确定。
- 还没有人留言评论。精彩留言会获得点赞!