分析数据处理方法和分析数据处理装置与流程
本发明涉及对由光谱分析装置等各种分析装置收集到的数据进行处理的分析数据处理方法和分析数据处理装置,该光谱分析装置例如为液相色谱仪、气相色谱仪、红外光谱仪、荧光x射线分析装置等。
背景技术:
在将液相色谱仪或气相色谱仪等成分分离装置与检测器组合而成的色谱仪中,在按时间顺序分离试样中包含的多种成分后利用检测器来测定该成分,由此得到由表示某个时间(保持时间)的信号强度的点数据的集合构成的分析数据(色谱数据)。另外,在使用质谱仪(ms)来作为检测器的色谱质谱仪(lc/ms、gc/ms等)中,在按时间顺序分离试样中包含的成分之后,利用质谱仪来测定各成分,由此能够获取由表示某个质荷比m/z下的信号强度的点数据的集合构成的分析数据(色谱数据、质谱数据)。
并且,在红外光谱仪、荧光x射线分析装置等光谱分析装置中,利用检测器来测定通过对作为试样的物质照射规定波长范围的光而从该物质放射出的光,由此得到由表示某个波长(波数)或能量下的信号强度的点数据的集合构成的分析数据(光谱数据)。构成这些分析数据的点数据的数量与分析装置所具备的检测器的通道的数量相当。
在任意的分析装置中都能够根据分析数据生成将以时间、质荷比(m/z)、波长或能量作为横轴且将检测器的通道的输出(信号强度值)作为纵轴的曲线图(色谱、质谱、光谱)。在这些曲线图中,在与试样中包含的成分的种类相应的位置(保持时间、波长/能量、质荷比m/z)出现峰值。因而,通过对关于试样得到的分析数据进行解析,能够识别该试样的种类、该试样所属的组等。
当将想要根据由分析装置收集到的分析数据进行调查的内容、也就是对分析数据进行解析的目的设为变量(目的变量)y、将检测器的各通道的输出设为变量(说明变量)x1、x2、x3……时,能够使用变量x1、x2、x3……来表示变量y。变量x1、x2、x3……为彼此独立的变量,因此在统计学上,能够将上述分析数据作为具有与变量x1、x2、x3……的数量相应的维度的多维数据来进行处理。
在关于由多种化合物的混合物构成的试样得到的分析数据的情况下,在曲线图中出现多个峰值,但关于全部的峰值对其位置、大小进行解析的操作的效率差。通过着眼于特定的峰值,能够实现操作的高效化,但难以判断应该着眼于哪个峰值。因此,作为解决这样的问题的解析方法,利用主成分分析(principalcomponentanalysis:pca,非专利文献1)、非负矩阵分解(nonnegativematrixfactorization:nmf,非专利文献2)、聚类分析等多变量解析。
在多变量解析中,在关于多组试样得到的分析数据之间,将曲线图中出现的峰值的位置、峰值形状进行比较,基于该结果从分析数据中删除不需要的点数据或者进行合并,由此将分析数据映射成低维度。之后,通过回归分析、判别分析的方法对被映射成低维度的分析数据进行模型化。
在说明变量的数量少的二维数据、三维数据等相对简单的数据的情况下,应用线性回归分析、线性判别分析的方法。另一方面,在如利用分析装置得到的分析数据这样的多维数据的情况下,难以应用线性回归、线性判别的分析方法,应用基于神经网络、支持向量机(svm)等学习机器的非线性回归分析、非线性判别分析的方法。
在pca、nmf中,在将分析数据模型化时,以能够将信号强度发生变动的维度全部进行反映的方式映射为低维度。
例如,在基于荧光x射线分析装置的检测结果来判别塑料的种类的情况下,预先关于塑料的种类已知的多个组获取光谱数据,在这多个组的数据间进行多变量解析。光谱中除了包含由作为塑料的基础的材料产生的峰值以外,还包含由涂料、增塑剂/阻燃剂等添加物产生的峰值。一般来讲,当塑料的种类不同时添加物的种类也不同,因此在多个组的数据间发生变动的不仅有由基础材料产生的峰值,也有由添加物产生的峰值。因而,在该情况下,以能够再现由基础材料产生的峰值和由添加物产生的峰值这两者的方式将分析数据映射为低维度。
另外,例如在使用关于健康者组的生物体样本得到的质谱数据和关于癌症患者组的生物体样本得到的质谱数据来进行多变量解析以探索癌症患者的病理标志物的情况下,有时由作为病理标志物的成分以外的成分产生的峰值发生变动。这是因为大多数癌症患者具有共同的生活习惯(吸烟、饮酒等),在健康者组与癌症患者组的数据间,由因该生活习惯引起的成分产生的峰值也存在差异。因而,在该情况下,以使由作为癌症患者的病理标志物的成分产生的峰值和由因生活习惯引起的成分产生的峰值也能够再现的方式将分析数据映射为低维度。
非专利文献1:“利用多变量解析(主成分分析)的色谱数据解析”,株式会社岛津制作所hp,[平成28年7月25日检索],网址<url:http://www.an.shimadzu.co.jp/hplc/support/lib/lctalk/82/82tec.htm>
非专利文献2:ngoc-diepho,“nonnegativematrixfactorizationalgorithmsandapplications”网址<url:https://www.researchgate.net/profile/ngoc_diep_ho/publication/262258846_nonnegative_matrix_factorization_algorithms_and_applications/links/02e7e537226cb7e59b000000.pdf>
非专利文献3:tomooaoyamaandhiroshiichikawa,“obtainingthecorrelationindicesbetweendrugactivityandstructuralparametersusinganeuralnetworl”,chem.pharm.bull.39(2)372-378,(1991)
非专利文献4:karensimonyanetal.,“deepinsideconvolutionalnetworks:visualisingimageclassificationmodelsandsaliencymaps”,网址<url:http://arxiv.org/pdf/1312.6034v2.pdf>
技术实现要素:
发明要解决的问题
当如上述那样将被映射为低维度后的分析数据输入神经网络、svm等学习机器中并使用非线性回归分析、非线性判别分析的方法进行模型化时,发生如下的问题。
上述的由添加物产生的峰值、由因生活习惯引起的成分产生的峰值不表示塑料的种类、癌症患者的特征,峰值的大小与塑料的种类或者是否为癌症患者(疾病的状态)之间不存在因果关系。也就是说,两者之间本来就没有相关性,即使发现了相关性也是假的相关性(伪相关性)。因此,在将关于塑料的种类、疾病的状态已知的多个试样得到的分析数据作为用于进行模型化的学习数据的情况下,即使在该学习数据中在由添加物产生的峰值与塑料的种类之间发现相关性、或者在由因生活习惯引起的成分产生的峰值与疾病的状态之间发现了相关性,在解析对象的分析数据中也未必发现同样的相关性。其结果是,成为与学习数据相同的方法不适于解析对象的分析数据的所谓的过拟合状态。
为了防止过拟合,需要将多种参数的分析数据作为学习数据来进行非线性回归分析、非线性判别分析使得由示出伪相关性的成分产生的峰值成为不会变为随机噪声的存在而能被忽略,因此需要准备大量的试样,并不现实。
本发明要解决的课题在于,在基于由分析装置关于多个试样收集到的多维数据、即分析数据,利用使用统计机器学习的解析方法对所述分析数据进行处理时,留下所述分析数据中包含的表示试样的特征的维度并且排除噪声。
用于解决问题的方案
一般来讲,对回归分析或判别分析有贡献的维度与回归分析或判别分析中使用的函数的输出值的相关性高,因此考虑在分析中仅利用相关性高的维度,删除相关性不高的维度。当然,由于完全不具有相关性的维度为噪声的可能性高,因此将其删除。
在线性回归分析、线性判别分析中,能够通过计算来求出相关系数,但在基于神经网络、支持向量机等机器学习利用非线性函数进行的回归分析、判别分析中,无法求出相关系数。其中,在利用神经网络的回归/判别分析中,能够使用偏微分法来计算输入的各维度相对于输出的贡献度(非专利文献4)。此外,在非专利文献4中记载了在基于神经网络的非线性回归/判别分析中使用s形函数(sigmoidfunction),但不限于s形函数,作为利用神经网络的学习法,一般为梯度法,因此能够计算回归函数或判别函数的各数据点的偏微分(或二阶偏微分)。另外,在基于利用支持向量机的机器学习进行的回归/判别分析中也是,只要为输入和输出均取连续的值的机器学习方法,就能够同样地计算偏微分值、或者计算使输入微小地变化的情况下的差来作为与偏微分相当的值。如果能够计算分析数据的各数据点的偏微分值或与其相当的值,则能够根据该值来计算贡献度。
因此,本发明为一种对分析数据进行处理方法,该分析数据是由分析装置关于多个试样中的各个试样收集到的、由该分析装置所具备的多通道检测器的多个通道的输出值构成的多维的分析数据,在该方法中,通过对该分析数据应用使用统计机器学习的解析方法来对该分析数据进行处理,所述方法的特征在于,
计算表示关于已知试样得到的分析数据的非线性回归函数或非线性判别函数,
根据计算出的所述非线性回归函数或非线性判别函数的微分值,来计算构成所述已知试样的分析数据的多个通道的输出值各自的对于该非线性回归函数或所述非线性判别函数的贡献度,
基于该贡献度,从所述检测器的多个通道中决定在关于未知试样得到的分析数据的处理中使用的通道。
在上述分析数据处理方法中,分析装置只要具备多通道检测器即可,可以为任何分析装置,作为代表性的分析装置,列举质谱仪、液相色谱仪、气相色谱仪、红外光谱仪、荧光x射线分析装置等光谱分析装置。
另外,已知试样是指成分已知的试样,如塑料的种类已知的试样、是癌症患者还是健康者这样的所属的组已知的试样等。反之,未知试样是指所含成分未知的试样、所属的组为未知的试样。
在统计机器学习中能够使用神经网络、支持向量机等学习机器。
利用表示检测器的各通道的输出值的变量(说明变量)对回归函数或判别函数进行偏微分,由此能够计算表示已知试样的分析数据的非线性回归函数或非线性判别函数的微分值,但为了减少计算所花费的时间,也可以选取分析数据的一部分数据、或者对分析数据进行聚类分析来用各个类的代表点进行代替、或者对根据经验求出的标准的数据模式求出微分值。
在上述分析数据处理方法中,能够根据经验设定基于贡献度来决定通道的基准。作为代表性的基准,例如列举按照贡献度从高到低的顺序选择前n个通道的方法。
在该情况下,以不产生过拟合的方式决定所选择的通道的数量n为宜。
过拟合状态是指该回归函数或判别函数与求出回归函数或判别函数时使用的分析数据本身拟合但不与除此以外的分析数据拟合的状态。例如,将成分已知的分析数据分为用于求出回归函数或判别函数的学习数据以及用于验证关于学习数据得到的回归函数或判别函数的测试数据,求出将关于学习数据得到的回归函数或判别函数应用于学习数据本身的情况下的匹配率和将所述回归函数或判别函数应用于测试数据的情况下的匹配率,两者之差越大,则判断为越处于过拟合状态。
根据以上内容,在上述分析数据处理方法中,优选的是,将关于已知试样得到的分析数据分为学习数据和测试数据,使用学习数据临时决定在关于未知试样得到的分析数据的处理中使用的通道,在使用所述临时决定的通道对所述学习数据和所述测试数据进行处理时该学习数据的匹配率与该测试数据的匹配率之差处于规定范围内时,将所述临时决定的通道正式地决定为在关于未知试样得到的分析数据的处理中使用的通道。
另外,在上述分析数据处理方法中,优选的是,根据检测器的各通道的贡献度,对构成已知试样的分析数据的多个通道的每个通道进行加权,
针对加权后的分析数据再次计算贡献度,重复地更新权重。基于该权重或贡献度来决定在关于未知试样得到的分析数据的处理中使用的通道。
关于加权,优选强调贡献度这样的处理,也就是使大的贡献度变得更大这样的处理,例如列举对贡献度进行乘方、取贡献度的对数之类的处理。另外,也可以根据试样的种类、分析装置的种类等,通过实验求出权重的大小。在像这样进行加权的情况下、根据贡献度来直接决定通道的情况下,也可以通过对利用所决定的通道的输出值得到的机器学习结果再次重复进行同样的通道决定,来阶段性地减少通道的数量。
此外,在基于进行加权之前的贡献度来决定通道的情况下、基于进行加权之后的贡献度来决定通道的情况下都是,在机器学习的结果取决于成为机器学习对象的系数的初始值的情况下,贡献度也受到该初始值的影响。因而,在这样的情况下,可以求出针对多次执行机器学习所得的结果得到的多个贡献度或者与贡献度对应的权重的最小值、最大值、平均值并用于决定通道。执行多次的结果是,将被决定为要使用的通道的次数作为基准来决定正式使用的通道。
另外,本发明的其它方式为一种装置,通过对由分析装置关于多个试样中的各个试样分别收集到的、由该分析装置所具备的多通道检测器的多个通道的输出值构成的多维的分析数据应用使用统计机器学习的解析方法,来对该分析数据进行处理,所述装置的特征在于,具备:
a)函数计算部,其计算表示关于已知试样得到的分析数据的非线性回归函数或非线性判别函数;
b)贡献度计算部,其根据由所述函数计算部计算出的非线性回归函数或非线性判别函数的微分值,来计算构成所述已知试样的分析数据的多个通道的输出值各自的对于所述非线性回归函数或所述非线性判别函数的贡献度;以及
c)通道决定部,其基于所述贡献度,从所述检测器的多个通道中决定在关于未知试样得到的分析数据的处理中使用的通道。
发明的效果
根据本发明所涉及的分析数据处理方法和分析数据处理装置,能够排除分析数据中包含的多个通道的输出值中的成为噪声的通道的输出值,且能够使用对回归分析/判别分析有贡献的通道的输出值、即表示试样的特征的通道的输出值对未知试样的分析数据进行解析。
附图说明
图1是作为本发明的一个实施方式的分析系统的概要结构图。
图2是表示数据处理方法的过程的流程图。
图3是关于pp的试样得到的吸收比光谱的一例。
图4是全连接神经网络的概念图。
图5是表示分析数据的各数据点的贡献度的图。
图6是调查过拟合的发生而得到的图。
图7是表示进行加权之后的贡献度的图。
具体实施方式
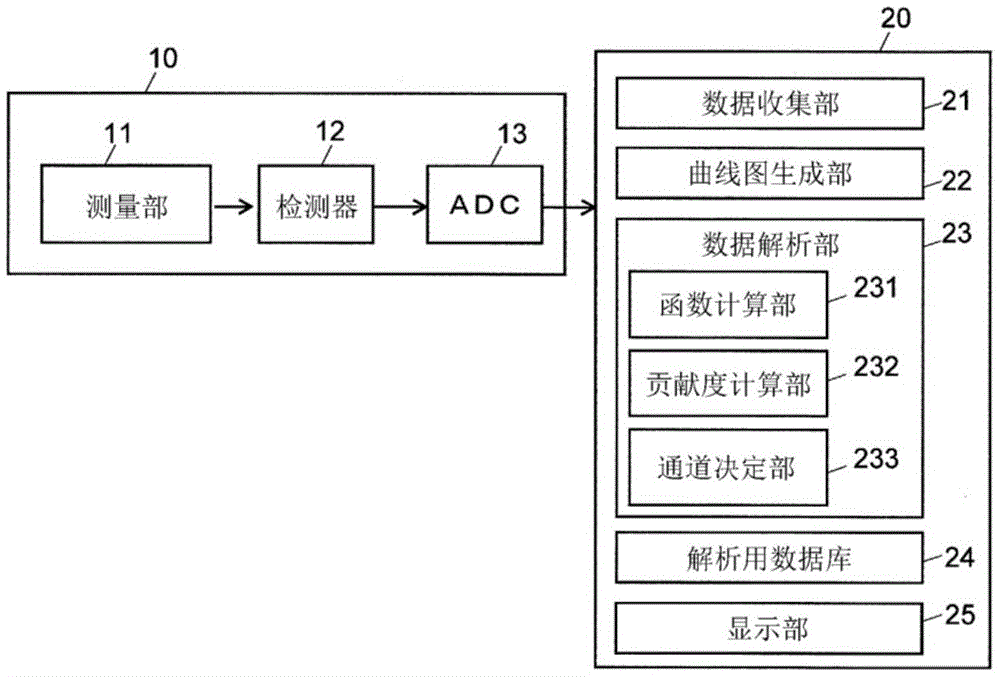
图1是作为本发明的一个实施方式的分析系统的概要结构图。
分析系统包括分析装置10和数据处理装置20。分析装置10具备测量部11、多通道检测器12(以下称作检测器12)以及将该检测器12的检测信号转换为数字数据的模拟-数字转换部(adc)13。例如在分析装置10为傅里叶变换红外光谱仪(ftir)的情况下,测量部11包括生成向试样照射的红外干涉光的干涉仪,检测器12包括tgs检测器、mct检测器等。
数据处理装置20具备:数据收集部21,其通过对在adc13中进行模拟-数字转换后的检测器12的通道的输出数据进行规定的数据处理,来生成作为多维数据的分析数据;曲线图生成部22,其基于分析数据来生成红外吸收光谱、色谱等曲线图;数据解析部23,其对所述分析数据进行解析;解析用数据库24,其使用于数据解析部23中的解析;以及显示部25,其显示在数据解析部23中进行解析得到的结果。
此外,关于数据处理装置20的功能,一般通过将通用的个人计算机作为硬件资源并且执行该个人计算机中安装的专用的处理软件来实现,但也能够使用专用的硬件来实现。
接着,参照图2所示的流程图来说明上述数据处理装置20中的数据处理方法的过程。由数据处理装置20的数据解析部23执行图2的流程图的各步骤的处理。此外,在以下的说明中,“输入数据”是指向数据解析部23输入的数据,“输出数据”是指从数据解析部23输出的数据。
<步骤1输入数据的标准化(日语:正規化)>
就分析装置10而言,检测器12的输出值的再现性低,即使同一试样也存在每次测定时检测器12的各通道的输出值不同的情况。另外,就分析装置10而言,也存在检测器12的每个通道的灵敏度、sn比不同的情况。例如,在质谱仪中,检测器的再现性低,质谱中出现的峰值的再现性低。另外,在ftir等吸收光谱仪中,根据波长不同而检测器的灵敏度、sn有很大不同。
因此,进行标准化使得检测器12的各通道的输出值的变动量的期望值大致固定,也就是说使得检测器12的通道的输出值的标准差固定。关于标准化,能够使用各种公知的方法。例如,能够设为将构成多个分析数据的任意的通道的输出值、也就是光谱、质谱、色谱中的任意的峰值除以该标准差的处理。
<步骤2利用学习机器进行非线性回归分析或非线性判别分析>
关于学习数据,进行利用神经网络、svm等学习机器的非线性回归或非线性判别(学习)。学习数据例如是指关于解析结果已知的试样如种类已知的树脂、已知是癌症患者还是健康者的生物体样本等从分析装置10得到的分析数据。在该情况下,利用与对解析对象试样的分析数据应用的非线性回归分析或非线性判别分析同样的回归对象变量或判别标签,来对学习数据进行非线性回归分析或非线性判别分析。通过步骤2的处理,求出表示学习数据的回归函数或判别函数。
<步骤3计算输入数据的偏微分值>
对关于学习数据得到的回归函数/判别函数进行偏微分。例如能够使用非专利文献4所记载的方法进行偏微分。在该方法中,将输入softmax函数的值视作输出值来进行微分。
<步骤4计算贡献度>
使用在步骤3中计算出的偏微分值来计算各通道的贡献度。例如,如为了识别树脂种类而得到的光谱数据那样,特定的通道的信号强度值变得越大则包含某种物质的确定度越高,在这样的情况下,偏微分值表示正的值,因此对偏微分值取平均值即可。另一方面,例如在用于调查用以判断是否患有某种疾病的病理标志物的质谱数据中,重要的是特定的通道的信号值相对于适当值发生何种程度的偏离。在这样的情况下,出现正负两种偏微分值,因此根据偏微分值的二范数来计算贡献度。
<步骤5决定通道>
按通过步骤4计算出的贡献度从大到小的顺序选择前n个通道。在该情况下,作为要选择的数量n,可以设定一个值,但最好是设定几个值,使用关于已知的测试数据(除学习数据以外的已知的分析数据)选择出的n个通道的输出值来进行步骤2的回归/判别分析,如果结果是过拟合少,由于减少通道引起的精度下降少,则将这n个通道最终决定为在数据处理中使用的通道。
另外,在选择前n个通道之后,当关于由这n个通道的输出构成的分析数据进行步骤2~4的处理时,有时各通道的贡献度的大小排名发生变化。因此,也可以是,首先选择比最终选择的数量n多的数量(n+α)个通道,关于选择出的这些通道进行步骤2~5的处理并阶段性地减少通道的数量,最终决定n个通道。由此,也能够减轻通道的贡献度的排名发生变化的影响。
接着,关于本发明,参照图3~图6对基于关于塑料试样使用ftir收集到的分析数据来进行用于判定试样的树脂种类的数据处理得到的结果进行说明。
图3~图5示出进行以下识别得到的结果:基于关于作为添加物等包含的pp(聚丙烯树脂)、pe(聚乙烯树脂)、pur(聚氨酯树脂)、abs树脂(丙烯腈-丁二烯-苯乙烯共聚合成树脂)这四种树脂通过ftir得到的分析数据(光谱数据),来识别是pp还是非pp。
图3示出关于pp的试样得到的吸收比光谱的一例。该光谱为对通过ftir得到的吸收比光谱进行标准化处理(将各测定点处的信号强度值除以全部的测定点处的信号强度值的标准差的处理)而得到的。向数据解析部23的函数计算部231输入像这样进行标准化后的吸收比光谱数据。
在数据解析部23中,使用图4所示的全连接神经网络来进行pp树脂和非pp的树脂的判别。在此,使用elu函数来作为中间层的激活函数,使用softmax函数来作为输出层的激活函数。作为结果,在图5中示出得到的贡献度。图5的横轴和图3的横轴均与检测器12的通道对应。
图5示出基于所得到的贡献度使用由前n个通道的输出值构成的学习数据和测试数据来识别树脂种类时的正确率(%)。数据数量均为10000。
在使用分析数据中包含的全部通道的输出值(1000通道)来识别是pp还是非pp时,测试数据的正确率为94.1%,学习数据的正确率为99.2%,但也取决于神经网络的初始值。也就是说,成为在学习数据中得到了高的正确率但在测试数据中正确率下降这样的过拟合状态。与此相对,当使通道的数量减少时,看出测试数据的正确率逐渐下降而学习数据的正确率上升的趋势,可知在通道的数量为约40时达到峰值。根据以上情况可知:在该实验例中,通过使用贡献度为前40的通道的输出值,能够抑制过拟合,提高正确率(识别率)。
另外,图6示出在进行将图4所示的贡献度设为四次方的强调处理的基础上进行标准化的处理(加权)所得的结果。根据图6可知,通过进行加权,得到可读性非常高的结果。基于进行加权处理后的贡献度,使用由前40个通道的输出值构成的分析数据来求出正确率的结果是,测试数据的正确率为95.5%、学习数据的正确率为96%,过拟合得到了抑制。由此可知,加权处理对于防止过拟合是有效的。
此外,本发明不限于上述的实施方式,能够进行适当的变更。
例如,作为进行标准化的方法,能够使用除以根据偏差求出的变异系数(=标准差/平均值)的公知的方法。
在上述实施方式中,在进行将贡献度设为四次方的强调处理的基础上,进行使均值为1的标准化,但强调处理为与选择前n个贡献度类似的概念,能够根据经验来调整要强调的程度(乘方的次数)。另外,除了基于对贡献度进行乘方的强调处理之外,也能够使用步骤函数、s形函数等一般的非线性的单调函数。
附图标记说明
10:分析装置;11:测量部;12:检测器;13:adc;20:数据处理装置;21:数据收集部;22:曲线图生成部;23:数据解析部;231:函数计算部;232:贡献度计算部;233:通道决定部;24:解析用数据库;25:显示部。
- 还没有人留言评论。精彩留言会获得点赞!