预测LCO加氢原料与产物的烃族组成的方法和装置与流程
本公开涉及化学工业领域,具体地,涉及一种预测lco加氢原料与产物的烃族组成的方法和装置。
背景技术:
国内石油化工科学研究院(简称石科院)将开发的劣质lco(轻循环油)转化为催化裂化汽油或轻质芳烃(lcotoaromaticsandgasoline,ltag),这样,将低价值的lco转化成为高附加值的高辛烷值车用汽油或芳烃,可大大缓解企业压力,同时提高汽柴比也符合我国国情。
ltag工艺包含两个关键性技术:对lco的选择性加氢技术以及后续的对加氢产品进行选择性催化裂化的技术,前者是将lco中多环芳烃(如双环芳烃)选择性加氢饱和为单环芳烃,ltag加氢单元的加氢深度和选择性直接影响到后续催化裂化单元目标产品的收率和质量。选择性加氢饱和后的结果的好坏可以通过lco加氢前后单环芳烃和多环芳烃的含量变化来确定,另外还可以通过特定芳烃化合物(如茚满或四氢萘、萘类等物质)的含量变化来确定。因此,保持对ltag加氢单元中lco原料和产品的性质监控,尤其是对烃族组成的监控,对于整个ltag工艺来说是必不可少的,这样,有利于及时调整加氢及催化裂化的工况,降低能耗并优化最终产品质量。
目前,对于柴油烃族组成(例如芳烃组成),主要的分析方法有质谱法,质谱法可以给出柴油的组成信息,包括链烷烃、不同环数环烷烃以及不同环数芳烃的含量分布等,满足对lco原料和产品性质的分析需求,但是质谱法需要对样品进行预分离,即将样品分离为饱和烃和芳烃后再分别进行质谱分析,从而使得分析时长较长,难以满足快速监控的要求。
技术实现要素:
为了解决上述问题,本公开提供一种预测lco加氢原料与产物的烃族组成的方法和装置。
为了实现上述目的,根据本公开实施例的第一方面,提供一种预测lco加氢原料与产物的烃族组成的方法,包括:
收集lco加氢原料与产物样本;
获取所述lco加氢原料与产物样本的第一烃族组成数据;
采集所述lco加氢原料与产物样本在预设谱区内常温下的红外光谱;
根据所述红外光谱的主成分与从所述第一烃族组成数据中获取的所述主成分对应的第二烃族组成数据建立第一校正模型;
根据所述红外光谱和所述主成分获取光谱残差,并根据所述光谱残差与所述光谱残差对应的烃族组成残差数据建立第二校正模型;所述烃族组成残差数据为所述第一烃族组成数据中除所述第二烃族组成数据之外的数据;
获取待测lco加氢原料与产物的红外光谱,并根据所述待测lco加氢原料与产物的红外光谱通过所述第一校正模型和所述第二校正模型预测所述待测lco加氢原料与产物的烃族组成。
可选地,所述获取所述lco加氢原料与产物样本的第一烃族组成数据包括:
通过sh/t0606方法获取所述lco加氢原料与产物样本的第一烃族组成数据。
可选地,所述预设谱区包括:1840~950cm-1和3000~2400cm-1。
可选地,所述采集所述lco加氢原料与产物样本在预设谱区内常温下的红外光谱包括:
采集所述lco加氢原料与产物样本在预设谱区内常温下的待测光谱;
对所述待测光谱进行预处理得到所述红外光谱。
可选地,所述根据所述待测lco加氢原料与产物的红外光谱通过所述第一校正模型和所述第二校正模型预测所述待测lco加氢原料与产物的烃族组成包括:
获取所述待确定lco加氢原料的红外光谱;
将所述待测lco加氢原料与产物的红外光谱的主成分输入至所述第一校正模型得到第一预测结果;
将所述待测lco加氢原料与产物的红外光谱的光谱残差输入至所述第二校正模型得到第二预测结果;
将所述第一预测结果与所述第二预测结果相加得到所述待测lco加氢原料与产物的烃族组成。
根据本公开实施例的第二方面,提供一种预测lco加氢原料与产物的烃族组成的装置,包括:
收集模块,用于收集lco加氢原料与产物样本;
获取模块,用于获取所述lco加氢原料与产物样本的第一烃族组成数据;
采集模块,用于采集所述lco加氢原料与产物样本在预设谱区内常温下的红外光谱;
第一建立模块,用于根据所述红外光谱的主成分与从所述第一烃族组成数据中获取的所述主成分对应的第二烃族组成数据建立第一校正模型;
第二建立模块,用于根据所述红外光谱和所述主成分获取光谱残差,并根据所述光谱残差与所述光谱残差对应的烃族组成残差数据建立第二校正模型;所述烃族组成残差数据为所述第一烃族组成数据中除所述第二烃族组成数据之外的数据;
预测模块,用于获取待测lco加氢原料与产物的红外光谱,并根据所述待测lco加氢原料与产物的红外光谱通过所述第一校正模型和所述第二校正模型预测所述待测lco加氢原料与产物的烃族组成。
可选地,所述获取模块,用于通过sh/t0606方法获取所述lco加氢原料与产物样本的第一烃族组成数据。
可选地,所述预设谱区包括:1840~950cm-1和3000~2400cm-1。
可选地,所述采集模块包括:
采集子模块,用于采集所述lco加氢原料与产物样本在预设谱区内常温下的待测光谱;
预处理子模块,用于对所述待测光谱进行预处理得到所述红外光谱。
可选地,所述预测模块包括:
第一输入子模块,用于将所述待测lco加氢原料与产物的红外光谱的主成分输入至所述第一校正模型得到第一预测结果;
第二输入子模块,用于将所述待测lco加氢原料与产物的红外光谱的光谱残差输入至所述第二校正模型得到第二预测结果;
第三获取子模块,用于将所述第一预测结果与所述第二预测结果相加得到所述待测lco加氢原料与产物的烃族组成。
通过上述技术方案,收集lco加氢原料与产物样本;获取所述lco加氢原料与产物样本的第一烃族组成数据;采集所述lco加氢原料与产物样本在预设谱区内常温下的红外光谱;根据所述红外光谱的主成分与从所述第一烃族组成数据中获取的所述主成分对应的第二烃族组成数据建立第一校正模型;根据所述红外光谱和所述主成分获取光谱残差,并根据所述光谱残差与所述光谱残差对应的烃族组成残差数据建立第二校正模型;所述烃族组成残差数据为所述第一烃族组成数据中除所述第二烃族组成数据之外的数据;获取待测lco加氢原料与产物的红外光谱,并根据所述待测lco加氢原料与产物的红外光谱通过所述第一校正模型和所述第二校正模型预测所述待测lco加氢原料与产物的烃族组成,这样,通过检测lco加氢原料与产物的红外光谱,并将该红外光谱的主成分和光谱残差分别输入至第一校正模型和第二校正模型得到该lco加氢原料与产物的烃族组成,从而实现lco加氢原料与产物的烃族组成的快速预测,避免了现有技术中需要对lco加氢原料与产物进行预分离的繁琐过程。
本公开的其他特征和优点将在随后的具体实施方式部分予以详细说明。
附图说明
附图是用来提供对本公开的进一步理解,并且构成说明书的一部分,与下面的具体实施方式一起用于解释本公开,但并不构成对本公开的限制。在附图中:
图1为本公开实施例示出的一种预测lco加氢原料与产物的烃族组成的方法的流程图;
图2为本公开实施例示出的又一种预测lco加氢原料与产物的烃族组成的方法的流程图;
图3为环烷烃组成红外预测值与环烷烃组成标准方法测量值之间的相关示意图;
图4为单环芳烃组成红外预测值与单环芳烃组成标准方法测量值之间的相关示意图;
图5为双环芳烃组成红外预测值与双环芳烃组成标准方法测量值之间的相关示意图;
图6为三环芳烃组成红外预测值与三环芳烃组成标准方法测量值之间的相关示意图;
图7为总芳烃组成红外预测值与总芳烃组成标准方法测量值之间的相关示意图;
图8为烷基苯组成红外预测值与烷基苯组成标准方法测量值之间的相关示意图;
图9为茚满(四氢萘)组成红外预测值与茚满(四氢萘)组成标准方法测量值之间的相关示意图;
图10为萘类组成红外预测值与萘类组成标准方法测量值之间的相关示意图;
图11为苊类组成红外预测值与苊类组成标准方法测量值之间的相关示意图;
图12为苊烯类组成红外预测值与苊烯类组成标准方法测量值之间的相关示意图;
图13为本公开实施例示出的一种预测lco加氢原料与产物的烃族组成的装置框图;
图14为本公开实施例示出的又一种预测lco加氢原料与产物的烃族组成的装置框图;
图15为本公开实施例示出的再一种预测lco加氢原料与产物的烃族组成的装置框图。
具体实施方式
以下结合附图对本公开的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本公开,并不用于限制本公开。
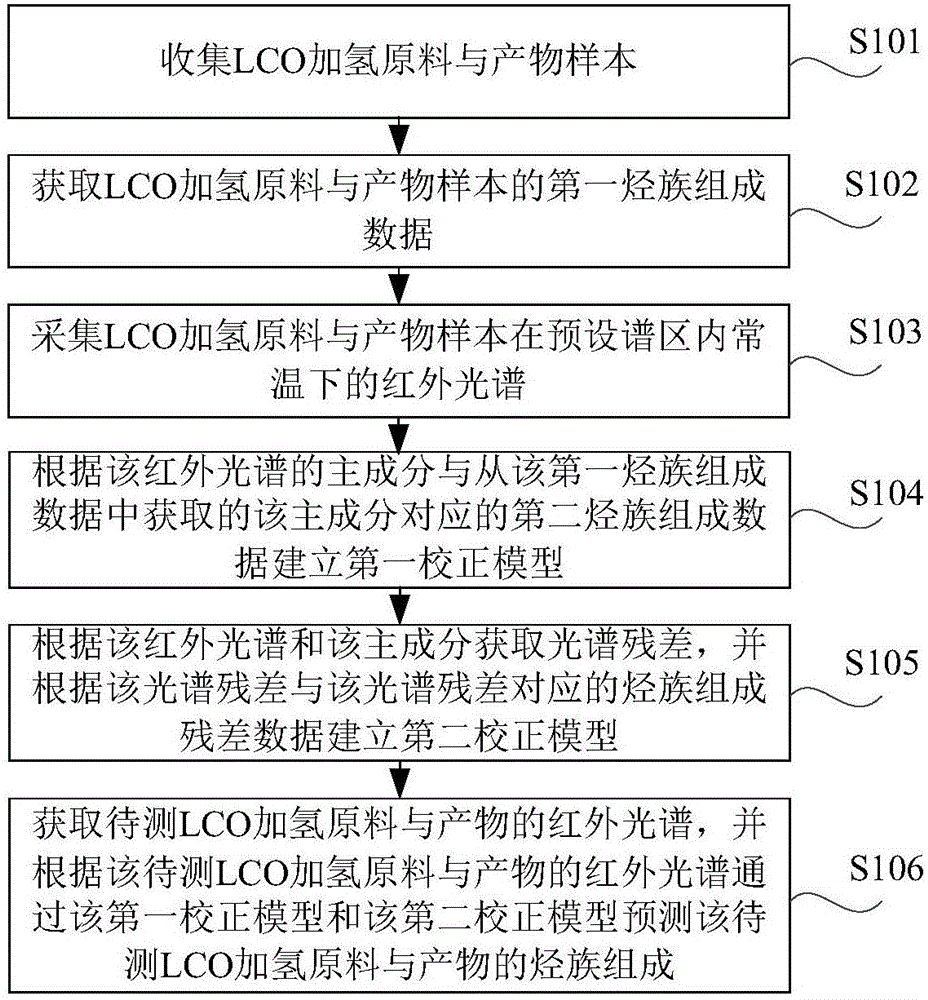
图1为本公开实施例示出的一种预测lco加氢原料与产物的烃族组成的方法的流程图,如图1所示,包括以下步骤:
s101、收集lco加氢原料与产物样本。
为了使得后续步骤中构建的第一校正模型和第二校正模型较准确以及可靠度较高,在本步骤中,需要收集不同类型的以及性质差异较大的lco加氢原料与产物样本,但实际操作中为减少工作量,一般选取适当数量且能涵盖所有可能预测到的烃族组成的样本,优选的,不同类型的lco加氢原料与产物样本的数量为200~340个,本公开采集中石化炼厂的lco加氢原料与产物样本为200个,示例地,该lco加氢原料与产物包括催化裂化柴油、加氢精制柴油及二者混兑柴油等,上述示例只是举例说明,本公开对此不作限定。
s102、获取lco加氢原料与产物样本的第一烃族组成数据。
在本步骤中,可以通过sh/t0606方法获取lco加氢原料与产物样本的第一烃族组成数据,具体方法与现有技术中的方法相同,不再赘述。
s103、获取lco加氢原料与产物样本在预设谱区内常温下的红外光谱。
红外光谱(mir)分析技术是目前应用较广泛的快速分析方法之一,由于mir中具有丰富的组成信息和结构信息,可通过mir分析技术分析由有机化合物构成的石油及石油产品(如石油燃料和石油溶剂等),在本公开中,可通过手持式透射红外光谱仪测定lco加氢原料与产物样本的待测光谱,并对该待测光谱进行预处理得到该红外光谱,这样,由于手持式透射红外光谱仪构造简单,性能稳定,无需对lco加氢原料与产物样本进行预分离,可以直接测定lco加氢原料与产物样本的待测光谱,进而得到该红外光谱,因此,mir分析技术可将预测lco加氢原料与产物样本的烃族组成的时间缩短至几分钟,在提高预测效率的同时还能减低预测费用。
本发明选择与烃族组成有良好相关性的红外光谱区作为预设谱区,即波数为1840~950cm-1和3000~2400cm-1的波段区间作为该预设谱区,该常温的范围可以为10~30℃,如常温为25℃,上述示例只是举例说明,本公开对此不作限定。
s104、根据该红外光谱的主成分与从该第一烃族组成数据中获取的该主成分对应的第二烃族组成数据建立第一校正模型。
其中,该第一校正模型用于确定该红外光谱的主成分对应的烃族组成数据。
s105、根据该红外光谱和该主成分获取光谱残差,并根据该光谱残差与该光谱残差对应的烃族组成残差数据建立第二校正模型。
其中,该烃族组成残差数据为该第一烃族组成数据中除该第二烃族组成数据之外的数据,该第二校正模型用于确定该光谱残差对应的烃族组成数据。
s106、获取待测lco加氢原料与产物的红外光谱,并根据该待测lco加氢原料与产物的红外光谱通过该第一校正模型和该第二校正模型预测该待测lco加氢原料与产物的烃族组成。
采用上述方法,通过将lco加氢原料与产物的烃族组成和红外光谱结合起来构建第一校正模型和第二校正模型,这样,通过检测lco加氢原料与产物的红外光谱,并将该红外光谱的主成分和光谱残差分别输入至第一校正模型和第二校正模型得到lco加氢原料与产物的烃族组成,从而实现lco加氢原料与产物的烃族组成的快速预测,避免了现有技术中需要对lco加氢原料与产物进行预分离的繁琐过程。
图2为本公开实施例示出的一种预测lco加氢原料与产物的烃族组成的方法的流程图,如图2所示,包括以下步骤:
s201、收集lco加氢原料与产物样本。
为了使得后续步骤中构建的第一校正模型和第二校正模型较准确以及可靠度较高,在本步骤中,需要收集不同类型的以及性质差异较大的lco加氢原料与产物样本,但实际操作中为减少工作量,一般选取适当数量且能涵盖所有可能预测到的烃族组成的样本,优选的,不同类型的lco加氢原料与产物样本的数量为200~340个,本公开采集中石化炼厂的lco加氢原料与产物样本为200个,示例地,该lco加氢原料与产物包括催化裂化柴油、加氢精制柴油及二者混兑柴油等,上述示例只是举例说明,本公开对此不作限定。
表1为该lco加氢原料与产物样本的组成统计表,如表1所示:
表1lco加氢原料与产物样本的组成统计表
s202、通过sh/t0606方法获取lco加氢原料与产物样本的第一烃族组成数据。
其中,sh/t0606方法为中间馏分烃类组成的测定方法(即质谱法),该方法与现有技术中的方法相同,不再赘述。
s203、采集lco加氢原料与产物样本在预设谱区内常温下的待测光谱值。
红外光谱(mir)分析技术是目前应用较广泛的快速分析方法之一,由于mir中具有丰富的组成信息和结构信息,可通过mir分析技术分析由有机化合物构成的石油及石油产品(如石油燃料和石油溶剂等),在本公开中,可通过手持式透射红外光谱仪测定lco加氢原料与产物样本的待测光谱,这样,由于手持式透射红外光谱仪构造简单,性能稳定,无需对lco加氢原料与产物样本进行预分离,可以直接测定lco加氢原料与产物样本的待测光谱,因此,mir分析技术可将预测lco加氢原料与产物样本的烃族组成的时间缩短至几分钟,在提高预测效率的同时还能减低预测费用,具体地,用吸管吸取一滴测试样品(相当于本公开中的lco加氢原料与产物样本),并加入znse晶体池中,通过fluidscanq1000mid-ir透射红外光谱仪以空气为参比进行光谱扫描,扫描次数为20次,采谱范围:4000~940cm-1。
本发明选择与烃族组成有良好相关性的红外光谱区作为预设谱区,即波数为1840~950cm-1和3000~2400cm-1的波段区间作为该预设谱区,该常温的范围可以为10~30℃,如常温为25℃,上述示例只是举例说明,本公开对此不作限定。
s204、对该待测光谱进行预处理得到红外光谱。
其中,可以对该待测光谱进行一阶微分处理或二阶微分处理后得到红外光谱,这样,可以去除待测光谱中的噪声,从而消除干扰,上述示例只是举例说明,本公开对此不作限定。
s205、根据该红外光谱的主成分与从第一烃族组成数据中获取的该主成分对应的第二烃族组成数据建立第一校正模型。
其中,该第一校正模型用于确定该红外光谱的主成分对应的烃族组成数据。
通常该第一校正模型采用线性方法建立,如偏最小二乘法(pls)方法以及主成分回归法(pcr)等,上述示例只是举例说明,本公开对此不作限定。
s206、根据该红外光谱和该主成分获取光谱残差,并根据该光谱残差与该光谱残差对应的烃族组成残差数据建立第二校正模型。
其中,该烃族组成残差数据为该第一烃族组成数据中除该第二烃族组成数据之外的数据,该第二校正模型用于确定该光谱残差对应的烃族组成数据。
通常该第二校正模型采用非线性方法,如支持向量机(svm)方法,随机森林(rf)方法或人工神经网络(ann)方法等,上述示例只是举例说明,本公开对此不作限定。
示例地,该第二校正模型采用svm方法,则可以将光谱残差与该光谱残差对应的烃族组成残差数据输入至预设svm模型进行训练得到第二校正模型。
为了验证获取的第一校正模型和第二校正模型的准确度,可以采集验证样本集,其中,该验证样本集中包括的验证样本的数量可以为lco加氢原料与产物样本的数量的1/2,分别测量每个验证样本在常温下的波数为1840~950cm-1以及3000~2400cm-1波段内的待测光谱,并对该待测光谱进行二阶微分处理得到红外光谱,将该红外光谱的主成分代入第一校正模型得到第一预测结果,并将该红外光谱的光谱残差代入第二校正模型得到第二预测结果,将该第一预测结果与该第二预测结果相加得到该验证样本的烃组成红外预测值,通过sh/t0606方法获取该验证样本的烃组成标准方法预测值,通过比较该验证样本的烃组成红外预测值和该验证样本的烃组成标准方法预测值得到比较结果,该比较结果如图3至图12所示。
s207、获取待测lco加氢原料与产物的红外光谱。
其中,测量待测lco加氢原料在常温下的波数为1840~950cm-1以及3000~2400cm-1波段内的待测光谱,并对该待测光谱进行二阶微分处理得到红外光谱。
s209、将该待测lco加氢原料与产物的红外光谱的主成分输入至该第一校正模型得到第一预测结果。
s210、将该待测lco加氢原料与产物的红外光谱的光谱残差输入至该第二校正模型得到第二预测结果。
s211、将该第一预测结果与该第二预测结果相加得到该待测lco加氢原料与产物的烃族组成。
采用上述方法,通过将lco加氢原料与产物的烃族组成和红外光谱结合起来构建第一校正模型和第二校正模型,这样,通过检测lco加氢原料与产物的红外光谱,并将该红外光谱的主成分和光谱残差分别输入至第一校正模型和第二校正模型得到lco加氢原料与产物的烃族组成,从而实现lco加氢原料与产物的目标烃族组成的快速预测,避免了现有技术中需要对lco加氢原料与产物进行预分离的繁琐过程。
图13为本公开实施例示出的一种预测lco加氢原料与产物的烃族组成的装置,如图13所示,包括:
收集模块131,用于收集lco加氢原料与产物样本;
获取模块132,用于获取该lco加氢原料与产物样本的第一烃族组成数据;
采集133,用于采集该lco加氢原料与产物样本在预设谱区内常温下的红外光谱;
第一建立模块134,用于根据该红外光谱的主成分与从该第一烃族组成数据中获取的该主成分对应的第二烃族组成数据建立第一校正模型;
第二建立模块135,用于根据该红外光谱和该主成分获取光谱残差,并根据该光谱残差与该光谱残差对应的烃族组成残差数据建立第二校正模型;该烃族组成残差数据为该第一烃族组成数据中除该第二烃族组成数据之外的数据;
预测模块136,用于获取待测lco加氢原料与产物的红外光谱,并根据该待测lco加氢原料与产物的红外光谱通过该第一校正模型和该第二校正模型预测该待测lco加氢原料与产物的烃族组成。
可选地,该获取模块132,用于通过sh/t0606方法获取该lco加氢原料与产物样本的第一烃族组成数据。
可选地,该预设谱区包括:1840~950cm-1和3000~2400cm-1。
图14为本公开实施例示出的一种预测lco加氢原料与产物的烃族组成的装置,如图14所示,该采集模块133包括:
采集子模块1331,用于采集该lco加氢原料与产物样本在预设谱区内常温下的待测光谱;
预处理子模块1332,用于对该待测光谱进行预处理得到该红外光谱。
图15为本公开实施例示出的一种预测lco加氢原料与产物的烃族组成的装置,如图15所示,该预测模块136包括:
第一输入子模块1361,用于将该待测lco加氢原料与产物的红外光谱的主成分输入至该第一校正模型得到第一预测结果;
第二输入子模块1362,用于将该待测lco加氢原料与产物的红外光谱的光谱残差输入至该第二校正模型得到第二预测结果;
第三获取子模块1362,用于将该第一预测结果与该第二预测结果相加得到该待测lco加氢原料与产物的烃族组成。
采用上述装置,通过将lco加氢原料与产物的烃族组成和红外光谱结合起来构建第一校正模型和第二校正模型,这样,通过检测lco加氢原料与产物的红外光谱,并将该红外光谱的主成分和光谱残差分别输入至第一校正模型和第二校正模型得到lco加氢原料与产物的烃族组成,从而实现lco加氢原料与产物的目标烃族组成的快速预测,避免了现有技术中需要对lco加氢原料与产物进行预分离的繁琐过程。
关于上述实施例中的装置,其中各个模块执行操作的具体方式已经在有关该方法的实施例中进行了详细描述,此处将不做详细阐述说明。
以上结合附图详细描述了本公开的优选实施方式,但是,本公开并不限于上述实施方式中的具体细节,在本公开的技术构思范围内,可以对本公开的技术方案进行多种简单变型,这些简单变型均属于本公开的保护范围。
另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合,为了避免不必要的重复,本公开对各种可能的组合方式不再另行说明。
此外,本公开的各种不同的实施方式之间也可以进行任意组合,只要其不违背本公开的思想,其同样应当视为本公开所公开的内容。
- 还没有人留言评论。精彩留言会获得点赞!