一种基于MODIS和机器学习模型融合的PM2.5反演方法与流程
本发明涉及遥感影像处理技术领域,特别涉及一种基于MODIS和机器学习模型融合的PM2.5反演方法。
背景技术:
气溶胶,又称气胶或烟雾质,是指固体或液体微粒稳定地悬浮于气体介质中形成的分散体系,其一般大小在0.01-10微米之间,可分为自然和人类产生两种;气溶胶会影响气候,包括吸收辐射或散射辐射,另外气溶胶会成为凝结核而影响云的性质等。天空中的云、雾、尘埃,工业上和运输业上用的锅炉和各种发动机里未燃尽的燃料所形成的烟,采矿、采石场磨材和粮食加工时所形成的固体粉尘,人造的掩蔽烟幕和毒烟等都是气溶胶的具体实例。气溶胶的消除,主要靠大气的降水、小粒子间的碰并、凝聚、聚合和沉降过程。
在全球气候变化大背景下,近年京津冀、长江三角洲、珠江三角洲、川渝等城市群雾霾现象频发,北京天津、广州深圳、上海等城市雾霾污染天数占全年总天数的30%~50%,且范围在扩大,雾霾已成为我国一种新的复合型危害性大气污染,这主要是不断增加人为排放的大气气溶胶与气象条件共同作用的结果。雾霾主要由可入肺颗粒物PM2.5(空气动力学直径≤2.5μm的颗粒物)组成,也称细颗粒物,雾霾天中PM2.5颗粒物浓度约占总悬浮颗粒物的56.7%~75.4%,占PM10(空气动力学直径≤10μm的颗粒物)80%~90%以上成分,因此,相比PM10甚至沙尘暴(主要成分为沙尘物质),PM2.5对人体健康危害更大,更易引发哮喘、支气管炎和心血管等方面的疾病。因此,科学的监测PM2.5质量浓度,对研究PM2.5的物理、化学光学特性,进而对揭示雾霾成因及理解空气污染产生机制等都有重要的意义。
目前采用的监测手段为建立地面观测站,如全球自动观测网(AER ONET)、美国环境可视化监测站(IMPROVE),以及美国环保署EPA近4000个空气观测站(SLAMS),这些能对气溶胶进行连续观测,可直接反映污染物地面浓度信息,但地面环境观测站的稀疏不连续性,难以大范围反映PM2.5气溶胶粒子的时空分布、污染源及传输特性等,观测数据不充分及地面仪器昂贵等均制约了PM2.5的有效监测及宏观分析;现在较为先进地监测采用PM2.5的反演进行监测分析,PM2.5的反演指的是其质量浓度的反演,而现有PM2.5的反演的方法,都是先反演大气气溶胶光学厚度AOD,然后再建立气溶胶光学厚度AOD与地面实测PM2.5的统计关系,再用该统计关系得到无地面观测点区域的PM2.5值,在反演AOD过程中,会带来误差,再用AOD建立实测PM2.5的过程,会导致误差的传递,从而影响最终PM2.5的反演精度。
技术实现要素:
为了克服上述所述的不足,本发明的目的是提供一种基于MODIS和机器学习模型融合的PM2.5反演方法,从遥感影像本身数据出发,通过机器学习算法的手段和模型融合,直接建立遥感影像本身与实测PM2.5的关系,从而避免了误差传递,从而达到精度更高的反演结果。
本发明解决其技术问题的技术方案是:
一种基于MODIS和机器学习模型融合的PM2.5反演方法,其中,包括如下步骤:
步骤S1、获取需要反演PM2.5当天的MODIS影像,同时获取PM2.5环境监测站点的PM2.5监测数据;
步骤S2、将监测到的PM2.5数据插值成与MODIS影像的相同分辨率的PM2.5插值影像;
步骤S3、将MODIS影像进行云检测,并将有云的区域标记为0,无云的区域标记为1;
步骤S4、将PM2.5环境监测站点随机按比例m:n分成训练站点和测试站点,分别构建训练集和测试集;
步骤S5、将训练集用于机器学习算法的训练,并将训练的模型用于测试集,计算模型在测试集上的表现指标;
步骤S6、重复步骤S4和步骤S5,得到若干个表现指标的植,按照一定的间隔,做出表现指标的直方图;选择直方图中频度最高的直方图区间所对应的所有模型,作为需要反演的该天的最优模型组合;
步骤S7、将选出的最优模型组合用于整幅MODIS影像,进行模型融合的反演。
作为本发明的一种改进,在步骤S4内,在构建训练集的过程中,对于训练集中的每一个站点,获取该站点在MODIS影像上k*k邻域内的像素;对于在k*k邻域内的每一个像素,若该像素的云检测标记为0,则弃用此像素,若该像素的云检测标记为1,则取其16个发射率(EMI值)、22个辐射率(RAD值)、22个反射率(REF值),以及该像素在PM2.5插值影像上对应的PM2.5的值,从而构成一条记录,则每个站点最多能构成k*k条记录。
作为本发明的进一步改进,在步骤S4内,在构建测试集的过程中,对于测试集中的每一个站点,获取该站点在MODIS影像上的像素,对于该像素,若该像素的云检测标记为0,则弃用此像素,若标记为1,取其16个发射率(EMI值)、22个辐射率(RAD值)、22个反射率(REF值),以及该像素在PM2.5插值影像上对应的PM2.5的值,从而构成一条记录,则每个站点最多能构成1条记录。
作为本发明的更进一步改进,在步骤S5内,表现指标包括相关系数、均方根误差和决定系数。
作为本发明的更进一步改进,在步骤S5内,机器学习算法包括随机森林法、支持向量机法和人工神经网络法。
作为本发明的更进一步改进,在步骤S1内,获取需要反演PM2.5当天的MODIS影像,计算得到16个波段的发射率(EMI值)、22个波段的辐射率(RAD值)和22个波段的反射率(REF值)。
作为本发明的更进一步改进,在步骤S7内,对于MODIS影像上的每一个像素,若该像素的云检测标记为0,则将此像素的PM2.5反演结果置为0,若标记为1,取其16个发射率(EMI值)、22个辐射率(RAD值)、22个反射率(REF值),构成一条记录,并将该记录输入到步骤S6内选出的最优模型中,每个像素的模型输出一个PM2.5预测值,然后依据每个像素的模型的表现指标,对该模型的PM2.5预测值进行加权计算,输出为该像素的PM2.5最终预测值;将整幅MODIS影像的所有像素都计算完毕后,即可得到整幅MODIS影像的PM2.5反演结果。
作为本发明的更进一步改进,在步骤S2内,将监测到的PM2.5数据插值成与MODIS影像的相同分辨率的PM2.5插值影像的插值方法采用最邻近插值法或反距离加权法或克里金插值法。
作为本发明的更进一步改进,在步骤S1内,PM2.5监测数据的获取时间与MODIS影像的获取时间为相同或相近。
作为本发明的更进一步改进,在步骤S7内,加权计算是指按照每个模型的表现指标的值进行线性加权,当前值除以所有值的和,作为当前模型的权重。
在本发明中,从遥感影像本身数据出发,通过机器学习算法的手段和模型融合,直接建立遥感影像本身与实测PM2.5的关系,从而避免了误差传递,从而达到精度更高的反演结果;本发明避免了误差传递,反演精度高。
附图说明
为了易于说明,本发明由下述的较佳实施例及附图作以详细描述。
图1为本发明的步骤流程框图;
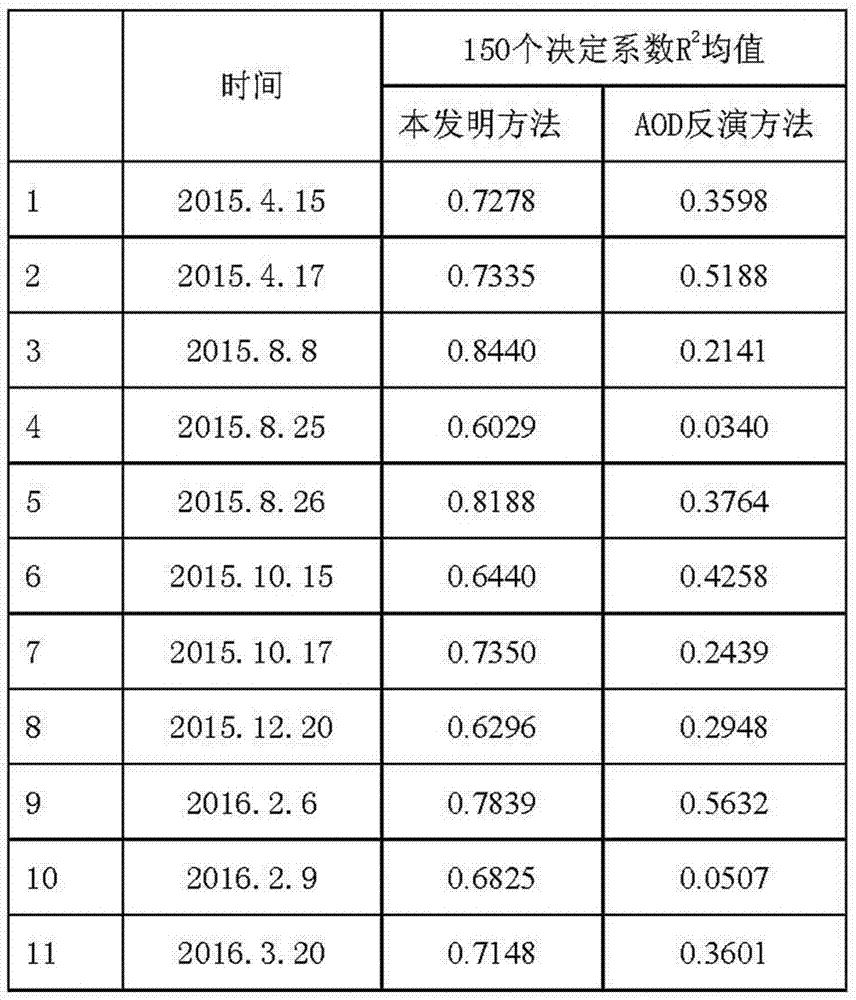
图2为本发明按照不同季节随机选取日期进行PM2.5反演产生的反演结果表图;
图3为本发明选取2015年10月17日当天进行AOD反演产生的结果直方图;
图4为本发明选取2015年10月17日当天进行PM2.5反演产生的结果直方图;
图5为本发明选取2015年12月20日当天进行AOD反演产生的结果直方图;
图6为本发明选取2015年12月20日当天进行PM2.5反演产生的结果直方图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
对于本领域的普通技术人员而言,可以通过具体情况理解上述术语在本发明中的具体含义。
如图1所示,本发明的一种基于MODIS和机器学习模型融合的PM2.5反演方法,包括如下步骤:
步骤S1、获取需要反演PM2.5当天的MODIS影像,同时获取PM2.5环境监测站点的PM2.5监测数据;
步骤S2、将监测到的PM2.5数据插值成与MODIS影像的相同分辨率的PM2.5插值影像;
步骤S3、将MODIS影像进行云检测,并将有云的区域标记为0,无云的区域标记为1;
步骤S4、将PM2.5环境监测站点随机按比例m:n分成训练站点和测试站点,分别构建训练集和测试集;
步骤S5、将训练集用于机器学习算法的训练,并将训练的模型用于测试集,计算模型在测试集上的表现指标;
步骤S6、重复步骤S4和步骤S5,得到若干个表现指标的植,按照一定的间隔,做出表现指标的直方图;选择直方图中频度最高的直方图区间所对应的所有模型,作为需要反演的该天的最优模型组合;
步骤S7、将选出的最优模型组合用于整幅MODIS影像,进行模型融合的反演。
在本发明中,从遥感影像本身数据出发,通过机器学习算法的手段和模型融合,直接建立遥感影像本身与实测PM2.5的关系,从而避免了误差传递,从而达到精度更高的反演结果。
其中,在步骤S4内,在构建训练集的过程中,对于训练集中的每一个站点,获取该站点在MODIS影像上k*k邻域内的像素;对于在k*k邻域内的每一个像素,若该像素的云检测标记为0,则弃用此像素,若该像素的云检测标记为1,则取其16个发射率(EMI值)、22个辐射率(RAD值)、22个反射率(REF值),以及该像素在PM2.5插值影像上对应的PM2.5的值,从而构成一条记录,则每个站点最多能构成k*k条记录;在步骤S4内,在构建测试集的过程中,对于测试集中的每一个站点,获取该站点在MODIS影像上的像素,对于该像素,若该像素的云检测标记为0,则弃用此像素,若标记为1,取其16个发射率(EMI值)、22个辐射率(RAD值)、22个反射率(REF值),以及该像素在PM2.5插值影像上对应的PM2.5的值,从而构成一条记录,则每个站点最多能构成1条记录。
在本发明中,在步骤S5内,表现指标包括但不限于相关系数、均方根误差和决定系数。
在本发明中,在步骤S5内,机器学习算法包括但不限于随机森林法、支持向量机法和人工神经网络法。
在本发明中,在步骤S1内,获取需要反演PM2.5当天的MODIS影像,计算得到16个波段的发射率(EMI值)、22个波段的辐射率(RAD值)和22个波段的反射率(REF值)。
在本发明中,在步骤S7内,对于MODIS影像上的每一个像素,若该像素的云检测标记为0,则将此像素的PM2.5反演结果置为0,若标记为1,取其16个发射率(EMI值)、22个辐射率(RAD值)、22个反射率(REF值),构成一条记录,并将该记录输入到步骤S6内选出的最优模型中,每个像素的模型输出一个PM2.5预测值,然后依据每个像素的模型的表现指标,对该模型的PM2.5预测值进行加权计算,输出为该像素的PM2.5最终预测值;将整幅MODIS影像的所有像素都计算完毕后,即可得到整幅MODIS影像的PM2.5反演结果;加权计算是指按照每个模型的表现指标的值进行线性加权,当前值除以所有值的和,作为当前模型的权重。
在本发明中,在步骤S2内,将监测到的PM2.5数据插值成与MODIS影像的相同分辨率的PM2.5插值影像的插值方法采用最邻近插值法或反距离加权法或克里金插值法。
在本发明中,在步骤S1内,PM2.5监测数据的获取时间与MODIS影像的获取时间为相同或相近;在步骤S2内,插值方法采用克里金插值法。
本发明不依赖于AOD,实验表明,精度更高(如下所述)。
本发明通过实施例的实验来进行表明实验结果:
(1)获取需要反演PM2.5当天的MODIS影像,计算得到16个波段的发射率EMI、22个波段的辐射率RAD和22个波段的反射率REF,同时获取当天与MODIS影像获取时间相同或相近时刻的环境监测站的PM2.5监测数据;
(2)将PM2.5数据插值成与MODIS影像同样分辨率的影像,采用的插值方法可以是最邻近插值、反距离加权法、克里金插值法等;将MODIS影像进行云检测,并将有云的区域标记为0,无云的区域标记为1;
(3)将PM2.5监测站点随机按比例m:n分成训练站点和测试站点,构建训练集和测试集;
(4)构成训练集的过程为:对训练集中的每一个站点,获取该站点在影像上k*k邻域内的像素,对于该邻域内的每一个像素,若该像素的云检测标记为0,则弃用此像素,若标记为1,则取其16个EMI值、22个RAD值、22个REF值,以及该像素在PM2.5插值影像上对应的PM2.5的值,构成一条记录,则每个站点最多能构成k*k条记录;
(5)构建测试集的过程为:对测试集中的每一个站点,获取该站点在影像上的像素,对于该像素,若该像素的云检测标记为0,则弃用此像素,若标记为1,取其16个EMI值、22个RAD值、22个REF值,以及该像素在PM2.5插值影像上对应的PM2.5的值,构成一条记录,则每个站点最多能构成1条记录;
(6)将训练集用于机器学习算法的训练,并将训练的模型用于测试集,计算模型在测试集上的表现指标,表现指标包括相关系数、均方根误差等;所述的机器学习算法包括但不限于随机森林、支持向量机、人工神经网络等等;
(7)选择一种机器学习算法和一种表现指标,重复3到6的过程p次,得到p个表现指标值,按照一定的间隔,做出p个表现指标的直方图;选择直方图频度最高的直方图区间所对应的所有模型,作为需要反演的该天的最优多模型组合;
(8)将多模型组合用于整幅MODIS影像,进行多模型融合的反演,具体过程为:对MODIS影像上的每一个像素,若该像素的云检测标记为0,则将此像素的PM2.5反演结果置为0,若标记为1,取其16个EMI值、22个RAD值、22个REF值,构成一条记录,输入到步骤7的多模型中,每个模型输出一个PM2.5预测值,然后依据每个模型的表现指标值,对该模型预测的PM2.5值进行加权计算,输出为该像素的PM2.5最终预测值;将整幅影像的所有像素都计算完毕后,即可得到整幅影像的PM2.5遥感反演结果。
该实施例与AOD反演进行对比,如下:
(一)对比数据处理方式
AOD反演:先计算AOD,然后再通过AOD反演PM2.5,一般用线性模型来反演。
该实施例采用MODIS产品中分辨率最高的3km气溶胶产品,该产品采用最新的C6算法,将暗目标法和深蓝算法的结果进行融合;获取反演当天的MODIS影像,按前述方法生成本发明所需的训练数据,然后获取当天对应的AOD产品,采用克里金插值方法,将AOD产品中的空洞进行填补,并插值成MODIS同样分辨率的影像。
(二)区域选择
实验选取广东省的102个环境监测站点发布的PM2.5监测数据。
(三)方法测试
在真实环境中,出于成本等因素考虑,不可能建立大量密集的PM2.5地面观测站,因此无法对遥感影像上所有像素点的PM2.5反演结果进行验证。为了说明实施例的方法的有效性,基于有限的地面观测站,对实施例的方法进行测试;为了实现对反演结果的验证,本实施例从102个站点中随机选择32个站点作为固定的验证站点,再从剩余的70个站点中随机选择40个站点做训练,30个站点做测试。按照实施例的方法,构建训练集和测试集。对于每一次随机选择的训练集,输入到随机森林模型中进行训练,并基于测试集得到表现指标值,表现指标可以有相关系数、均方根误差、决定系数R2等;本实施例选择决定系数R2作为评价模型好坏的指标,相关系数越高,说明模型越好,按照该方法重复150次,得到150个模型,以及这150个模型的决定系数R2,将这150个决定系数R2按照0.1的间隔,计算直方图,选择直方图频度最高的区间所对应的模型作为最终入选的模型;同样地,作为比较,在上述150次重复过程中,对于每一次重复过程,将40个站点的AOD与对应位置的PM2.5进行线性回归,得到回归系数,用于对当次重复过程的30个测试站点进行预测,计算预测结果与真实观测值的决定系数R2,得到150个决定系数R2,将这150个决定系数R2按照0.1的间隔,计算直方图,选择直方图频度最高的区间所对应的模型作为最终入选的比较模型。
(四)实验结果
按照不同的季节,随机从春夏秋冬等季节中选择云量比较少的日期进行反演,日期为:2015.4.15、2015.4.17、2015.8.8、2015.8.25、2015.8.26、2015.10.15、2015.10.17、2015.12.20、2016.2.6、2016.2.9、2016.3.20,按照前述方法计算均方根误差,结果如图2所示表图,从图2中可以看出,实施例方法的决定系数远高于AOD方法,说明实施例方法能够更好地预测PM2.5的值。
从图3、图4、图5和图6所示,为两个日期预测值的150个决定系数R2的直方图分布,从两个日期的预测结果可以看出,实施例的方法要优于AOD反演法。
(五)方法运行
通过上面的测试,可以看出,实施例方法能够很好地达到预测效果,决定系数比AOD方法要好很多,说明了实施例方法的正确性;将实施例方法应用于实际MODIS遥感影像时,采用同样的方法,只不过在训练过程中不需要建立验证集。方法如下:
(1)将102个站点随机选择70个站点作为训练站点,剩下的32个站点作为测试站点,按照实施例的方法,重复步骤(3)到(6)的过程150次,每重复一次,则得到一个模型,选择的机器学习算法是随机森林算法,选择的表现指标为相关系数,相关系数越大,表明结果越好,也可以选择均方根误差作为表现指标,均方根误差越小,表明结果越好,也可以使用其它指标;得到训练集上150个模型的相关系数、均方根误差、决定系数R2;
(2)设置间隔为0.1,计算150个相关系数的直方图,即将0.8-0.9之间的值视为相等,得到10个区间以及每个区间内的频度,选择直方图频度最高的直方图区间所对应的所有模型,作为需要反演的该天的最优多模型;将多模型用于整幅MODIS影像,进行多模型融合的反演,具体过程为:对MODIS影像上的每一个像素,若该像素的云检测标记为0,则将此像素的PM2.5反演结果置为0,若标记为1,取其16个EMI值、22个RAD值、22个REF值,构成一条记录,输入到实施例中步骤(7)的模型中,每个模型输出一个PM2.5预测值,然后依据每个模型的表现指标值,对该模型预测的PM2.5值进行加权计算,输出为该像素的PM2.5最终预测值;将整幅影像的所有像素都计算完毕后,即可得到整幅影像的PM2.5遥感反演结果。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!