通过对健康人血浆蛋白中N-糖蛋白的分析,预测2型糖尿病的发展过程的制作方法
本发明涉及通过定量分析附着在健康人血浆蛋白上的n-聚糖来预测2型糖尿病(t2d)发展的方法。技术问题本发明解决了当前健康人确定未来2型糖尿病(t2d)发展风险的技术问题。本发明通过使用通过单次分析定量分析附着在被调查者的血浆蛋白上的n-聚糖来解决上述技术问题。
背景技术:
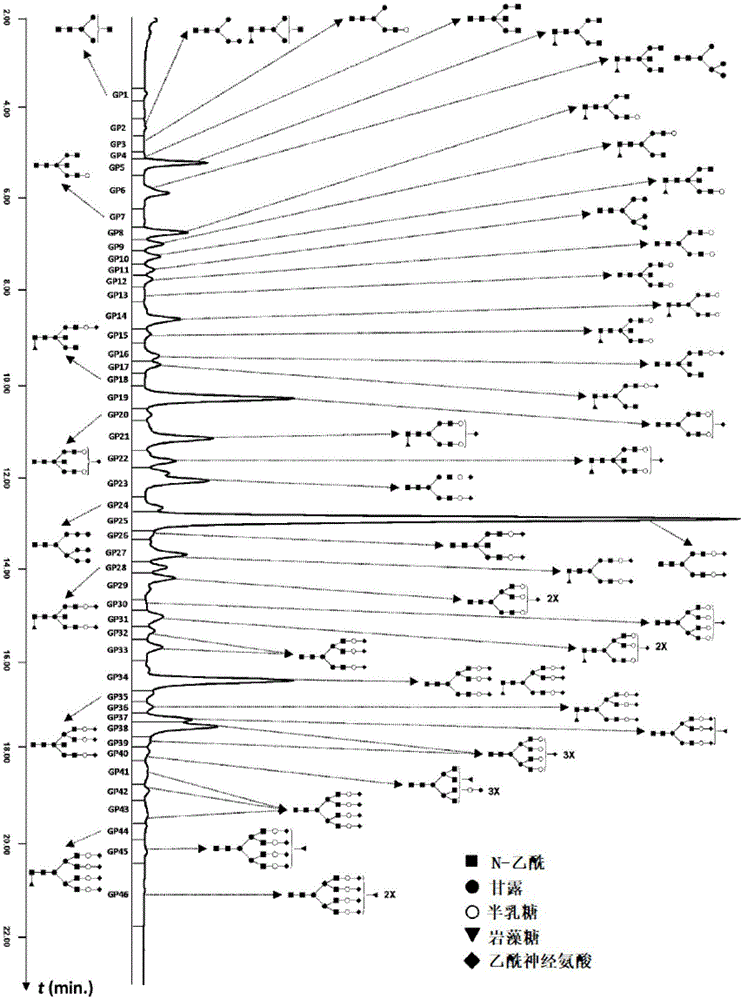
:糖类是复杂的碳水化合物,通常附着在蛋白质上,参与许多生理和病理过程。因此,它们作为各种生理和病理状态的生物标志物的诊断潜力是众所周知的;参见参考文献1:(1)g˙奥普德纳柯,p˙m˙路德,c˙p˙庞廷,r˙a˙德韦克:糖生物学的概念和原理,美国实验生物学会联合会会志j·7(1993)1330-1337。通过这种方式,定量分析附在血浆蛋白上的n-聚糖可用于各种诊断目的。因此,n-聚糖分析能够得出关于被调查者的病理状况的结论,例如:败血症、急性胰腺炎、炎症和其他疾病和状况;参见参考文献2-4:(2)o˙戈尔尼克,l˙罗伊尔,d˙j˙哈维,c˙m˙拉德克利夫,r˙萨尔道瓦,r˙a˙德韦克,p˙路德,g˙劳克,脓毒症和急性胰腺炎期间血清糖类的变化,糖生物学17(2007)1321-1332;(3)o˙戈尔尼克,i˙戈尔尼克,v˙加斯帕罗维奇,g˙劳克,转铁蛋白唾液酸化的变化是急性胰腺炎严重程度的潜在预后标记物,克林生物化学,41(2008)504-510;(4)o˙戈尔尼克,g˙劳克,在炎症性疾病中血清蛋白的糖基化,疾病标记,25(2008)267-278。糖尿病是现代最显著的疾病之一,特别是由于它的频率。2型糖尿病(t2d)也是最重要的全球流行病学问题之一。据估计,到2025年,糖尿病患病率将增加到7.3%。伊藤等人研究了2型糖尿病(t2d)中小鼠和人血浆中n-聚糖的变化,他们发现,在这两个物种中,含有ɑ-1,6-岩藻糖和二分n-乙酰氨基葡萄糖的双味聚糖的水平有所增加。假设肝脏中α-1,6-岩藻糖基转移酶的水平和活性增加。作者认为,α-1,6-岩藻糖基化水平的升高对t2d的病理生理学具有指导意义。此外,他们的结果暗示了利用n-聚糖分析,特别是ɑ-1,6-岩藻糖基化水平进行t2d诊断的可能性;参见参考文献5:(5)n˙伊藤,s˙萨卡页,h˙那卡嘎瓦,m˙库容宫日,h˙奥伊拉,k˙德古奇尔,s˙i˙倪氏穆拉,m˙倪氏穆拉,db/db小鼠和2型糖尿病人血清糖蛋白中n-聚糖的分析,美国生理学杂质,293(2007)e1069-e1077。特斯塔等人描述了与健康对照组相比,2型糖尿病(t2d)和代谢综合征(ms)患者血浆n-聚糖谱的显著变化。他们观察到t2d患者单半乳糖化的n-聚糖与ɑ-(l,6)和ɑ-(1,3)半乳糖化显著降低,岩心岩藻糖化的二元n-聚糖ng1(6)a2f和ng1(3)a2f显著降低;参见参考文献6:(6)r˙特斯塔,v˙尹灏宏,a˙r˙班费理,m˙波尔弥日,f˙奥利,a˙凯丽莱,s˙各诺维斯,l˙手帕福木,v˙博日历,m˙g˙巴卡利亚,s˙萨维利,p˙格日利亚,s˙德威乐尔,c˙李贝提,c˙桑切斯,2型糖尿病患者的血清蛋白中n-聚糖变化与并发症和新陈代谢综合参数的关系,影响因子(2015)doi:10.1371/期刊杂志011993。文章明确指出,血清n-聚糖可以作为2型糖尿病的非侵袭性生物标记,见论文的结论。参考文献(5)和(6)中指出的事实表明,通过分析血浆n-聚糖来诊断先前患糖尿病的可能性。然而,参考文献(5)和(6)没有指出直接使用血浆n-聚糖来预测当前健康的人未来患糖尿病的可能性。对于当前健康的人来说,预测未来糖尿病发展的概念已经为时尚所熟知。例如,尓迪亚等人通过分析从被调查者的血浆中衍生的生化标记物的特定组合,设计了糖尿病预测诊断程序,该诊断程序在疾病的潜在发病前1、2.5、5、7.5或10年,即:1.血糖;2.甘油三酯;和3.脂联素(蛋白质)同时设计了预测被调查者中糖尿病发展的概率的数学模型;参见参考文献(7):(7)美国2015/193587a1;m.s.尓迪亚,m.p.麦肯纳,p.a.斯霍德尼亚:糖尿病相关的生物标记物及其使用方法;健康诊断实验室,股份有限公司(美国)。文章指出诊断程序的可能性,其中,为被调查者分析上述关键生物标志物,并且基于它们产生的浓度与它们在特定人群中的浓度范围比较,产生预测,即糖尿病的未来发展的可能性。根据我们最新的知识,对于目前健康的人,将血浆n-聚糖作为预测未来糖尿病发展的标记物的使用没有在现有技术中描述,也没有以任何方式建议。本发明解决了预测或确定当前健康人未来糖尿病发展的风险的技术问题,这在本发明做详细描述。技术实现要素:本发明公开了一种该方法是基于血浆n-聚糖的单一定量分析,然后通过基于人群研究和监测的特定数学模型来确定当前健康人未来2型糖尿病(t2d)发展风险的方法,糖尿病发病率呈时间依赖性。附图说明图1描述了当采用基于亲水相互作用的超高效液相色谱(hilic-uplc)时,通过定量分析血浆n-聚糖,用2-氨基苯甲酰胺(2-ab)荧光标记的而获得的典型色谱图。根据prese的分析发明,见实施例2。图2描述了roc(接收器操作特性)曲线(实线),该实线将在急性疾病中高血糖患者(2型糖尿病发展的风险增加)和在急性疾病中血糖水平正常的患者区别。该roc曲线是以总血浆n-聚糖作为预测指标构建。此外,图2还示出了roc曲线(虚线),其示出糖化血红蛋白(hbalc)的鉴别值,这作为现有技术中2型糖尿病的标准诊断标志物。图3描述了通过逻辑回归获得比值比的对数(这里及整个文本中对数基数=e),其对应于每个测量聚糖(gp1-gp46)的一个标准偏差的变化。比值比(or)的对数通过逻辑回归得到,并且对应于每个测量聚糖(gp1-gp46)的一个标准偏差的变化。为了调整对数(or)以适应一个标准偏差(标准对数(or))的变化,在进行逻辑回归之前,还要对聚糖测量进行标准化(到n(0,1)分布)。条形高表示估计的比值比的对数,误差条表示估计效果的95%置信区间,y轴表示通过对应于测量聚糖的一个标准偏差变化的逻辑回归得到的对数(or)。根据本发明,通过hilic-uplc方法对因急性疾病而在重症监护病房住院期间出现高血糖的患者(59例和59例对照)的血浆n-聚糖进行分析。多重直接测量的聚糖在病例和对照之间有显著差异。血浆聚糖的差异显示为条形带,其中条形带的高度表示效应大小;估计是基于逻辑回归和错误率,95%的置信区间。图4描述了血浆中的丰度的差异,用比值比对数表示;如图2所示,x轴才表示具有相似特征的不同聚糖组:高支化(hb);低支化(lb);中性聚糖(so);唾液酸化聚糖:单唾液酸化(s1),半乳糖化水平(s2),唾液酸三糖(s3),唾液糖四酸(s4);以及关于半乳糖基化水平:琼脂糖化(g0)、单乳糖化(gl)、双乳糖化(g2)、三乳糖化(g3)和四乳糖化(g4)聚糖。在病例组和对照组之间观察到显著差异。血浆聚糖的差异显示为条形图,其中条形图的高度表示基于逻辑回归(比值比的对数)估计的效应大小,而误差条表示估计效应的95%的置信区间。具体实施方式本发明解决了确定当前健康人未来2型糖尿病(t2d)发展风险的技术问题。根据本发明的程序基本上包括:(ⅰ)对被调查者的血浆中n-聚糖的定量分析;(ⅱ)将获得的n-聚糖定量百分比的结果并入特定的数学公式,这些公式是群体研究中获得的,并且通过以时间依赖的方式监测该人群中糖尿病的发病率,以及(ⅲ)基于获得的数据,得出被调查者未来2型糖尿病(t2d)发展风险是否增加的结论。在对大量的健康人群(n=108)的血浆n-聚糖组成进行研究之后,出现了本发明的主要发现。在大样本研究人群中,监测血浆n-聚糖的变化和2型糖尿病(t2d)的发病率。研究从六个月期间(2013年2月至7月)萨格勒布大学医院的重症监护病房(icu)招募的患者。有糖尿病阴性病史的成年人(>18岁)有资格参加这项研究。排除在住院前或住院期间诊断为糖尿病或糖尿病前期的患者、有妊娠糖尿病记录的患者、怀孕患者和入院前或3个月前服用糖皮质激素的患者。被招募的患者被要求参加出院后6-8周的随访。本次访问制定了纳入/退出标准。限定将全血计数和crp排除持续性炎症过程。2周后再次对炎症标志物升高的患者进行检测。对所有患者进行口服葡萄糖耐量试验(ogtt)和hbalc测定以确认先前存在的糖尿病。设计了ada诊断糖尿病标准,将有糖尿病前期或糖尿病的患者排除。记录身高、体重和体重指数,记录糖尿病家族史。研究共纳入108例患者,其一般特征见表1。表1:血浆n-聚糖的研究包括患者的常规特征。实施例1描述了详细的研究报告。对于每个血浆样品,根据下述的程序进行n-聚糖的定量分析。血浆n-聚糖定量分析与血浆蛋白相连的n-聚糖的定量分析包括以下步骤:(ⅰ)采集健康人的血样;(ⅱ)从血液样品中分离血浆;(ⅲ)通过n-糖苷酶的酶水解释放总血浆n-聚糖;(ⅳ)任选地,使用适于提高这种标记的n-聚糖的检测灵敏度的试剂衍生n-聚糖混合物;(ⅴ)纯化n-聚糖混合物或标记的n-聚糖混合物;以及(ⅵ)使用适当的定量分析技术分离和定量n-聚糖或标记的n-聚糖。作为分离血浆n-聚糖的合适的定量分析技术,可以使用任何能够分离和定量的分析技术。用于血浆n-聚糖分离的合适的定量分析技术的实施例有如下技术:超高效液相色谱(uplc)、毛细管电泳(ce)、maldi-tof质谱、液相色谱与质谱联用(lc-ms)等合适的定量技术-如现有技术中众所周知;参见,例如,国际专利申请wo2014/203010a1,发明人是g˙劳克等人。在本研究中,使用的超效液相色谱(uplc)并不是首选的技术,只是许多可能的替代技术之一。在本发明中,术语n-聚糖和/或n-聚糖基是指来源于血浆的一个或多个聚糖,这些聚糖先前附着在血浆糖蛋白内的氮(n-)原子上。在分析期间,使用n-糖苷酶f从蛋白质部分释放聚糖,并且在定量分析期间,根据所使用的分析方法,单个色谱峰只能包含一种或多种n-聚糖,在这种情况下,使用术语n-聚糖基。更准确地说,术语“聚糖”前面的前缀“n-”指的是相应的聚糖和/或聚糖基团的来源,在它们从糖蛋白的蛋白质部分释放之前,即,这意味着碳水化合物(聚糖)与氮(n-)原子化学结合。被称为糖蛋白的血浆蛋白。具体而言,血浆n-聚糖的定量分析包括以下步骤:(i)采集健康人的血样;(ii)从血液样品中分离血浆;(iii)通过n-糖苷酶f的酶水解释放总血浆n-聚糖;(iv)在还原胺化反应中使用2-氨基苯甲酰胺(2-ab),以2-吡啶硼烷为还原剂,衍生n-聚糖混合物,用于n-聚糖荧光标记;(v)荧光标记的n-聚糖混合物的纯化;(vi)纯化的、荧光标记的n-聚糖的uplc分析,以便获得46个n-聚糖或n-聚糖基gp1-gp46中的每一个的定量百分比;见表2和3。具体而言,作为n-聚糖定量的适当定量分析方法之一,文献中已知有超高效液相色谱(uplc);参见参考文献8:(8)r˙萨尔道瓦,a.a.谌尼,v.d.哈亚汉森,i.斯坦菲尔德、m.希利亚德,i.基弗,赫兰,z.雅克赫伊尼,a.-l.博日森-德勒,p.m.路德:使用高分辨率定量uplc的n-糖基化与乳腺癌和系统特征的关联,生化研究方法,13(2014)2314-2327。上述uplc分析方法已使用下列条件进行:(i)色谱柱:沃特世亚乙基桥杂化颗粒技术;(ii)流动相:溶剂a=100mm甲酸铵水溶液,ph=4,4;b=乙腈;线性梯度70-53%,v/v,乙腈;(iii)流速:0.56毫升/分钟;(iv)温度:25℃;(v)检测:荧光检测器,激发波长250nm,发射波长428nm;(vi)分析运行:25分钟。使用所描述的uplc方法,实现了所有46个荧光(2ab)标记的聚糖或聚糖基团(gp1-gp46)的良好分离,其中典型的色谱图如图1所示。该分析方法的实施细节在实施例2中描述,而先前用2-氨基苯甲酰胺荧光标记的n-聚糖基团的保留时间如表2所示。表2。在超效液相色谱(uplc)分析中,46个荧光标记血浆n-聚糖或n-聚糖基团(gp1-gp46)获得的保留时间(tr)。gptr[min]gptr[min]gptr[min]13.91710.03316.124.81810.43416.835.11910.83517.145.42011.23617.455.62111.73717.666.22212.13817.876.82312.53918.187.22412.94018.497.42513.34118.7107.62613.64219.1117.92714.14319.6128.22814.34419.9138.52914.74520.4149.13015.14620.7159.33115.4--169.93215.9--在还原胺化反应中,用2-氨基苯甲酰胺(1)标记n-聚糖,以2-吡啶硼烷为还原剂(2pb)。uplc法:专栏:水beh;流动相:溶剂a=100mm甲酸铵水溶液,ph=4,4;b=乙腈;线性梯度70-53%,v/v,乙腈;流速:0.56ml/min;温度:25℃;检测:荧光检测器,激发波长250nm和发射波长为428nm;分析运行:25分钟。然而,图1所示的色谱图中的每个色谱峰包含一个或多个结构相似的聚糖(gp1-gp46),其化学结构如表3所示。表3.根据实施例2中描述的分析方法,在图1所示的色谱图中,n-聚糖或n-聚糖基被分离为单个色谱峰(gp1-gp46)的化学结构;参见参考文献8。gp=聚糖基;*表示具有相同组成,但异构结构,具有不同连接唾液酸的聚糖。对来自上述患者群体糖体组成检测研究的所有血浆样品进行了n-聚糖的描述定量。将得到的n-聚糖定量组成的结果在两组患者之间进行比较:(i)在急性疾病期间有记录的高血糖者(已知t2d发展的风险增加);(ii)在急性疾病期间仍保持血糖正常的人;见表1。基于统计数据处理,建立了上述两组患者的判别模型。上述模型基于总的聚糖分布,在此基础上形成了roc(接收器操作特性)曲线;参见图2。图2所示的roc曲线分析描述了用于诊断患有急性疾病(t2d发展风险增加)的患者的高血糖的判别模型。正则逻辑回归用于分类分析,其中46个血浆聚糖都被用作预测因子。roc曲线是基于“差一法”交叉验证(10cv)获得的验证集定义的。从图2中可以明显看出,血浆n-糖组以高灵敏度和特异性显著区分急性疾病期间的高血糖患者和在相同条件下保持血糖正常的患者。为了比较,图2还显示了糖化血红蛋白(hba1c)的roc曲线,从现有技术状态来看,糖化血红蛋白(hba1c)是高血糖诊断或2型糖尿病治疗成功的标准标志物;参见参考文献9:(9)m.劳伦斯基,l.斯密日兹克.杜威尼伽克,d.惹理威克:[血红蛋白a1c和糖尿病护理质量],阿克曼病理学,137(2015)92~29。从图2中可以明显看出,与现有技术中的糖化血红蛋白(hba1c)相比,血浆聚糖作为生物标志物具有显著更高的鉴别力,因此hba1c不能作为我们检测人群中t2d易感性的标志。虽然急性疾病期间的高血糖可识别出2型糖尿病(t2d)发展的高危患者,但仅将其作为预测方法应用于已入住重症监护病房(icu)的急性疾病患者是可能的。糖类作为急性疾病中高血糖的间接但高度可靠的预测因子,是t2d发展风险的更好的生物标志物,因为可以通过对血液样本的简单分析对当前健康人进行分析。在以下数据分析步骤中,为了对糖尿病发展的易感性作出可能的结论,将聚糖分为:(i)高支化聚糖(hb);(ii)低支化聚糖(lb);(iii)中性聚糖(s0);(iv)根据唾液酸化的程度:单唾液酸化(s1)、二唾液酸化(s2)、三唾液酸化(s3)、四唾液酸化(s4);(v)根据半乳糖化程度:琼脂糖化(g0)、单乳糖化(g1)、二乳糖化(g2)、三乳糖化(g3)和四乳糖化(g4)聚糖。上述聚糖类型由以下个体聚糖或聚糖组组成:hb=gp29+gp30+gp31+gp32+gp33+gp34+gp35+gp36+gp37+gp38+gp39+gp40+gp41+gp42+gp43+gp44+gp45+gp46lb=gp1+gp2+gp3+gp4+gp5+gp6+gp7+gp8+gp9+gp10+gp11+gp12+gp13+gp14+gp15+gp16+gp17+gp18+gp19+gp20+gp21+gp22+gp23+gp24+gp25+gp26+gp27+gp28s0=gp1+gp2+gp3+gp4+gp5+gp6+gp7+gp8+gp9+gp10+gp11+gp12+gp13+gp14+gp15s1=gp16+gp17+gp18+gp19+gp20+gp21+gp22+gp30s2=gp23+gp25+gp26+gp27+gp28+gp29+gp31s3=gp32+gp33+gp34+gp35+gp36+gp37+gp38+gp39+gp40s4=gp41+gp42+gp43+gp44+gp45+gp46g0=gp1+gp2+gp4+gp5+gp6g1=gp3+gp7+gp8+gp9+gp10+gp16+gp17+gp18g2=gp12+gp13+gp14+gp15+gp19+gp20+gp21+gp22+gp23+gp25+gp26+gp27+gp28g3=gp29+gp31+gp32+gp33+gp34+gp35+gp36+gp37+gp40g4=gp30+gp38+gp39+gp41+gp42+gp43+gp44+gp45+gp46t2d高危人群(高血糖组)和对照组之间有显著差异;参见图4。图4清楚地显示了人群中出现的特征,即2型糖尿病(t2d)的易感性以高支链聚糖(hb)为特征。统计学上显著不同,高支化聚糖(hb)和低支化聚糖(lb)的简单比率是确定被检查的当前健康人是否增加了未来患2型糖尿病(t2d)的风险(见图4)的良好鉴别参数。在实施例3中描述了来自研究的统计数据处理的细节。按照所述方式,对当前健康的人进行预测未来2型糖尿病发展(t2d)的诊断程序是可行的。分析附着在正常人血浆蛋白上的n-聚糖预测2型糖尿病发展的过程。利用如前所述相同的方法,通过定量分析附着在健康人血浆蛋白上的n-聚糖作为诊断方案。所有的n-聚糖的定量分析结果都包含在数学公式a和/或b中。所得到的数值用于推断当前健康的人是否具有未来2型糖尿病发展的显著可能性。根据本发明的诊断程序包括以下步骤:(i)采集健康人的血样;(ii)从血液样品中分离血浆;(iii)通过n-糖苷酶的酶水解释放总血浆n-聚糖;(iv)任选地,使用适于提高这种标记的n-聚糖的检测灵敏度的试剂衍生n-聚糖混合物;(v)n-甘聚糖混合物或衍生的n-聚糖混合物的纯化;(vi)使用适当的定量分析技术分离和定量n-聚糖或衍生的n-聚糖;(vii)如步骤(vi)所述获得的所有n-聚糖的定量百分比用作以下模型的输入变量:f(gp1,gp2,…,gpx;d,s)其中,x、d和s是模型f的参数,其含义如下:x=从gp1到gpx分析的n-聚糖的总数;d=调查者的年龄;s=调查对象性别,男性为1,女性为0;通过分析人群的统计数据处理得到模型常数;(viii)将步骤(vii)中得到的用于被调查者的结果f与阈值t进行比较,阈值t是在相同人群中统计确定的,并且规定未来2型糖尿病(t2d)发展的风险增加。具体地说,根据本发明的诊断程序包括以下步骤:(i)采集健康人的血样;(ii)从血液样品中分离血浆;(iii)通过n-糖苷酶f的酶水解释放总血浆n-聚糖;(iv)在还原胺化反应中使用2-氨基苯甲酰胺(2-ab),以2-吡啶硼烷为还原剂,衍生n-聚糖混合物,用于n-聚糖荧光标记;(v)荧光标记的n-聚糖混合物的纯化;(vi)使用定量分析技术分离和定量荧光标记的n-聚糖;(vii)如步骤(vi)所述获得的所有46个n-聚糖和/或n-聚糖基团的所获得的定量百分比用作以下模型的输入变量:f(gp1,gp2,…,gp46;d,s)其中,d和s是模型f的可选参数:d=被调查者的年龄;s=调查对象性别,男性为1,女性为0;通过分析种群的统计数据处理得到模型常数;(viii)将步骤(vii)中得到的用于被调查者的结果f与阈值t进行比较,阈值t是在相同人群中统计确定的,并且规定未来2型糖尿病(t2d)发展的风险增加。在本发明的一个实施例中,上述模型f(gp1,gp2,...,gp46;d,s)定义如下:d=被调查者的年龄;s=被调查者的性别;男性=1,女性=0:f=241.22–0.08·d+4.90·s+340.97·gp1+148.85·gp2–601.13·gp3–126.73·gp4–3.63·gp5+2.88·gp6+83.43·gp7–3.25·gp8–16.05·gp9–61.37·gp10–0.97·gp11–29.26·gp12+493.12·gp13–26.78·gp14–60.56·gp15–75.38·gp16+6.70·gp17–192.66·gp18+5.29·gp19–122.71·gp20+24.31·gp21+28.30·gp22+24.25·gp23+99.98·gp24-15.34·gp25+88.79·gp26+16.41·gp27+0.30·gp28–33.34·gp29+204.62·gp30+35.04·gp31–49.97·gp32–135.63·gp33+1.28·gp34+223.98·gp35–14.25·gp36+63.65·gp37–2.92·gp38–33.94·gp39–204.07·gp40+181.01·gp41+101.38·gp42–101.40·gp43–113.31·gp44+128.24·gp45–87.65·gp46而阈值t=-3.627;如果f>t,则意味着被调查者未来患2型糖尿病(t2d)的风险增加。在本发明的另一个实施例中,上述模型f(gp1,gp2,...,gp46)定义如下:f=-3.82+16.30·(hb/lb)其中,hb和lb通过定量聚糖百分比另外定义;因子hb表示支化聚糖的总和,而因子lb表示低支化聚糖的总和;hb=gp29+gp30+gp31+gp32+gp33+gp34+gp35+gp36+gp37+gp38+gp39+gp40+gp41+gp42+gp43+gp44+gp45+gp46lb=gp1+gp2+gp3+gp4+gp5+gp6+gp7+gp8+gp9+gp10+gp11+gp12+gp13+gp14+gp15+gp16+gp17+gp18+gp19+gp20+gp21+gp22+gp23+gp24+gp25+gp26+gp27+gp28其中,阈值t=0.33;如果f>t,则意味着被调查者未来患2型糖尿病(t2d)的风险增加。健康人2型糖尿病发展预测程序(t2d)的应用。根据本发明,诊断程序用于通过对当前健康人的单个血浆n-聚糖分析预测未来发生2型糖尿病(t2d)的风险。本发明的实施模式总注释克罗地亚萨格勒布临床医院伦理委员会批准了患者n-聚糖分析的研究方案。所有被招募的患者都签署了知情同意书以参与研究。所用试剂、装置和其他缩写的缩写:edta=乙二胺四乙酸;sds=十二烷基硫酸钠(阴离子洗涤剂);pngasef=肽-n4-(n-乙酰基-β-葡糖胺基)-天冬酰胺酰胺酶;dmso=二甲基亚砜;2ab=2-氨基苯甲酰胺;2pb=2-甲基吡啶硼烷;pbs=磷酸盐缓冲溶液;ghpfilter=生长激素聚酰亚胺(ghp)膜过滤器(过滤介质:亲水性聚丙烯);igepal-ca630=辛基苯氧基-聚(乙烯氧基)乙醇(非离子洗涤剂);uplc=超高效液相色谱法;hilic=亲水相互作用液相色谱实施例1,以时间依赖性方式测定血浆n-聚糖组成变化与2型糖尿病(t2d)发病率的研究。研究假设:分析在急性炎症期间经历高血糖的较大人群的血浆n-聚糖,然后在6-8周后,当确信他们健康时,即在正常血糖血症阶段和当早期疾病状态不再发生时,再次分析血浆n-聚糖。他们的n-聚糖组成。通过统计分析,基于这两个患者组之间n-聚糖组成的差异,形成了区分2型糖尿病高危个体和低危个体的模型。或者,通过分析n-聚糖并将结果存档,对相同大小的种群进行研究。血浆n-聚糖的分析,然后在若干年后在相同人数上重复。在这几年中罹患2型糖尿病的个人被明确归入高危组。没有发展成2型糖尿病的个人被归类为未来发展成2型糖尿病的低风险组。然后通过上述统计方法形成统计模型,以区分发展为2型糖尿病的高危个体和低风险个体。该研究对6个月(2013年2月至7月)内萨格勒布临床医院重症监护病房(icu)的患者进行。成年(>18岁)糖尿病阴性病史患者入住icu,生后出院,符合纳入标准。排除在住院前或住院期间诊断为糖尿病或糖尿病前期的患者、有妊娠糖尿病记录的患者、怀孕患者和入院前或3个月服用糖皮质激素的患者。在出院后6-8周,患者被要求进行随访。这次访问制定了纳入/排除标准。测定全血计数和crp排除持续性炎症过程。2周后再次检测炎症标志物升高的患者。所有患者都进行了口服葡萄糖耐量试验(ogtt)和测定hba1c,以确定先前存在的糖尿病。采用ada诊断糖尿病的标准,排除有糖尿病前期或糖尿病的患者。记录身高、体重和体重指数,记录糖尿病家族史。在装有抗凝剂的试管中采集用于聚糖分析的血液样本,立即分离血浆并在-20℃储存直到分析;参见实施例2。排除任何自身免疫、恶性或其他慢性疾病的个体。在入院期间,共有241人入住医疗icu,其中203人从医院活体出院。排除的48例为既往糖尿病,15例为糖皮质激素治疗,2例为妊娠期糖尿病,1例为孕妇。16例患者拒绝同意,7例患者未在随访中显示。另2例因持续炎症反应排除,4例因新诊断为糖尿病。其余108例患者进行聚糖分析。本研究中包括108例患者的一般特征见表1。实施例2.血浆n-聚糖分析(1)血样采集和血浆分离:根据良好的临床实践和标准的静脉穿刺程序采集血液样品,在含有抗凝剂(edta或柠檬酸盐)的管中取样,并立即进一步处理以分离血浆。(2)血浆分离:用离心法分离血浆,分离后在-20℃保存至进一步分析。(3)血浆蛋白n-聚糖释放:每份血浆样品中加入20μl的2%sds(w/v)(美国加利福尼亚州卡尔斯巴德英杰生命技术有限公司)变性10μl,65℃孵育10min,随后,10μl的4%igepal-ca630(美国密苏里州圣路易街西格玛奥德里奇)和1.25mu的pngasef(美国加利福尼亚州海沃德prozyme公司)在10μl5×10μl中变性。加入pbs。样品在37℃下孵育,用于n-聚糖释放。(4)用2-氨基苯甲酰胺(2-ab)还原胺化荧光释放n-聚糖的荧光标记:用n-氨基苯甲酰胺(2-ab)还原胺化荧光标记n-聚糖。将2-ab(19.2mg/ml,美国密苏里州圣路易街西格玛-奥德里奇)和2-吡啶啉硼烷(44.8mg/ml,美国密苏里州圣路易街西格玛-奥德里奇)溶解在dmso(美国密苏里州圣路易街西格玛-奥德里奇)和冰醋酸(德国默克达姆施塔)混合物(70:30,v/v)中制备标记混合物。将25μl的标记混合物添加到96孔板中的每个n-聚糖样品中,然后用粘合剂密封板。混合通过摇动10分钟,然后在65℃下培养2小时完成。样品(75μl的体积)通过加入300μl的acn达到80%的acn值(v/v)(美国新泽西州菲利普斯堡杰帝贝柯公司)。(5)荧光标记的n-聚糖混合物的纯化:使用hilic-spe从样品中除去游离标记物和还原剂。将200μl0.1g/ml微晶纤维素悬浮液(德国达姆施塔特默克)应用于0.45μmghp滤板(美国密歇根州安阿伯市颇尔公司)的每个井。通过使用真空歧管(美国马萨诸塞州比尔里卡密理博公司)应用真空除去溶剂。所有井都用5×200μl水预洗,然后用3×200μl乙腈/水(80:20,v/v)进行平衡。样品被加载到威尔斯。随后用200μl乙腈/水(80:20,v/v)洗涤7×威尔斯。糖用100μl水洗脱2×2次,组合洗脱液在-20℃保存至uplc分析。(6)通过亲水相互作用(hilic)超高效液相色谱(uplc)对荧光标记的n-聚糖进行定量分析(分离):在由四元溶剂管理器、样品管理器和荧光检测器组成的水含量仪(美国马萨诸塞州米尔福德市)上,采用亲水相互作用高效液相色谱(hilic-uplc)分离荧光标记的n-聚糖。分别为250和428nm的avelgnen。该仪器在empower2软件的控制下,建造2145(美国马萨诸塞州米尔福德沃特斯)。采用水桥式乙烯杂化甘油色谱柱,150×2.1mm和1.7μm的beh颗粒,100mm甲酸铵,ph4.4,溶剂a和乙腈为溶剂b,对标记的n-聚糖进行分离。在25分钟的分析运行中,流速为0.561ml/min的流速(v/v)。样品在注射前保持在5℃,分离温度为25℃,系统采用水解和2-ab标记的葡萄糖低聚物外标法进行标定,用于将单糖保留时间转换为葡萄糖单元。数据处理采用自动处理方法,采用传统的积分算法,然后手动校正每个色谱图以维持所有样品的积分间隔相同。所有色谱图以相同的方式分离成46个峰(gp1-gp46),每个峰中的聚糖含量表示为总积分面积的百分比。文献中描述了上述uplc定量分析方法;参见参考文献8。典型的色谱图如图1所示。(7)根据本发明,将获得的46n-聚糖定量百分比的结果并入通过对研究结果进行统计分析而获得的数学模型,并得出结论:从本研究中招募的46名患者的血浆n-聚糖(gp1-gp46)定量分析的所得结果中,通过实施例3和图2-4中描述的统计分析,获得了用于确定风险的两种不同模型和两个阈值。在本发明的一个实施例中,上述模型f(gp1,gp2,...,gp46;d,s)定义如下:d=被调查者的年龄;s=被调查者的性别;男性=1,女性=0:f=241.22–0.08·d+4.90·s+340.97·gp1+148.85·gp2–601.13·gp3–126.73·gp4–3.63·gp5+2.88·gp6+83.43·gp7–3.25·gp8–16.05·gp9–61.37·gp10–0.97·gp11–29.26·gp12+493.12·gp13–26.78·gp14–60.56·gp15–75.38·gp16+6.70·gp17–192.66·gp18+5.29·gp19–122.71·gp20+24.31·gp21+28.30·gp22+24.25·gp23+99.98·gp24-15.34·gp25+88.79·gp26+16.41·gp27+0.30·gp28–33.34·gp29+204.62·gp30+35.04·gp31–49.97·gp32–135.63·gp33+1.28·gp34+223.98·gp35–14.25·gp36+63.65·gp37–2.92·gp38–33.94·gp39–204.07·gp40+181.01·gp41+101.38·gp42–101.40·gp43–113.31·gp44+128.24·gp45–87.65·gp46阈值t=-3.627;如果f>t,则意味着被调查者未来患2型糖尿病(t2d)的风险增加。如果f<t,则风险不明显。在本发明的另一个实施例中,上述模型f(gp1,gp2,...,gp46)的定义方式不包括可选变量d和s:f=-3.82+16.30·(hb/lb)其中,hb和lb用定量聚糖百分比另外定义;因子hb表示高度支化的聚糖的总和,而因子lb表示具有低支化的聚糖的总和;hb=gp29+gp30+gp31+gp32+gp33+gp34+gp35+gp36+gp37+gp38+gp39+gp40+gp41+gp42+gp43+gp44+gp45+gp46lb=gp1+gp2+gp3+gp4+gp5+gp6+gp7+gp8+gp9+gp10+gp11+gp12+gp13+gp14+gp15+gp16+gp17+gp18+gp19+gp20+gp21+gp22+gp23+gp24+gp25+gp26+gp27+gp28阈值t=0.33;如果f>t,则意味着被调查者未来发生2型糖尿病(t2d)的风险增加。如果f<t,则风险不明显。实施例3.统计分析对于统计分析,为了预测高血糖状态,使用规则化的逻辑回归模型(弹性网,λ=0,alfa=0.1),使用r包“glmnet”;(参见参考文献10)。(10)http://jstatsoft.org/v33/i01/为了分类,所有46个血浆n-聚糖被用作预测因子。为了评估聚糖的生物标志物潜力,使用“留一法”交叉验证训练和验证模型,更具体地说,10-交叉验证过程(10cv)。在10cv程序中,以一个验证集仅包含一个样本的方式执行数据分类,同时对所有剩余样本检查预测模型。每个验证轮的预测被合并到一个验证集中,基于曲线下面积(auc)来评估队列特定模型的性能。模型1的发展:作为预测高血糖的模型,使用参数λ=0、alfa=0.1的正则逻辑回归(r包“glmnet”)。使用以下变量作为分类模型的输入变量:(i)从实施例2中通过uplc方法获得的46个聚糖的定量百分比;(ii)被调查人的年龄;(iii)被调查者的性别(0=女性或1=男性)。模型预测的变量是被调查者的高血糖状态(0=无高血糖或1=高血糖)。糖测量不作为峰面积(原始数据)输入模型,而是作为总糖体的百分比;进行总面积归一化,其中,每个糖峰的面积除以相应色谱图的总面积;所有归一化峰的总和为100%。模型中使用性别参数作为连续变量;“glmnet”不允许使用分类变量作为输入变量。所提到的输入变量不转换(日志转换)或缩放(n(0,1)上的标准化)。在“弹性网”模型中输入所提及的输入变量,输出结果定义为y=f(gp1,gp2,...,gp46,s,d),其中y在域[-∞,+∞]。一些模型可以导致归一化y,例如,在区间[0,1]中。本发明所示的模型系数是通过对107个样本进行上述模型的“训练”而获得的。模型预测能力用10次交叉验证程序进行评估,并用roc曲线表示。根据roc曲线,考虑分类模型的敏感性和特异性比,确定最佳阈值t=-3627。当模型结果为y>-3.627时,被调查者被归类为高血糖者。模型2的发展:作为预测高血糖的模型,使用逻辑回归(r包“stats”)。使用以下变量作为分类模型的变量:(i)2个衍生性状-低(lb)和高(hb)支化的n-聚糖;(ii)作为模型输入变量,使用上述两个派生性状的比率。模型预测的变量是患者的高血糖状态(0=无高血糖或1=高血糖)。在“glm”模型中使用提到的变量(组=“二项式”),输出结果定义为y=f(lb/hb),其中,y是在域[-∞,+∞]。通过对107个样本进行“训练”得到模型系数。因为使用简单的方法,没有交叉验证程序。图2-4显示了从患有和不患有高血糖的患者群体中得到的roc曲线和对血浆n-糖体组成的研究的处理结果。实施例4:定量分析当前健康人血浆n-聚糖预测2型糖尿病(t2d)发展的方法预测t2d发展的过程与实施例2中描述的过程相同,其包括以下步骤:(1)血样采集和血浆分离:根据良好的临床实践和标准的静脉穿刺程序采集血液样本,将样本用抗凝剂(edta或柠檬酸盐)管收集并立即进一步处理以分离血浆。(2)血浆分离:用离心法分离血浆,分离后在-20℃保存至进一步分析。(3)血浆蛋白n-聚糖释放:每份血浆样品中加入20μl的2%sds(w/v)(美国加利福尼亚州卡尔斯巴德英杰生命技术有限公司)变性10μl,65℃孵育10min,随后,10μl的4%igepal-ca630(美国密苏里州圣路易街西格玛奥德里奇)和1.25mu的pngasef(美国加利福尼亚州海沃德prozyme公司)在10μl5×10μl中变性。加入pbs。样品在37℃下孵育,用于n-聚糖释放。(4)用2-氨基苯甲酰胺(2-ab)还原胺化荧光释放n-聚糖的荧光标记:用n-氨基苯甲酰胺(2-ab)还原胺化荧光标记n-聚糖。将2-ab(19.2mg/ml,美国密苏里州圣路易街西格玛-奥德里奇)和2-吡啶啉硼烷(44.8mg/ml,美国密苏里州圣路易街西格玛-奥德里奇)溶解在dmso(美国密苏里州圣路易街西格玛-奥德里奇)和冰醋酸(德国默克达姆施塔)混合物(70:30,v/v)中制备标记混合物。将25μl的标记混合物添加到96孔板中的每个n-聚糖样品中,然后用粘合剂密封板。混合通过摇动10分钟,然后在65℃下培养2小时完成。样品(75μl的体积)通过加入300μl的acn达到80%的acn值(v/v)(美国新泽西州菲利普斯堡杰帝贝柯公司)。(5)荧光标记的n-聚糖混合物的纯化:使用hilic-spe从样品中除去游离标记物和还原剂。将200μl0.1g/ml微晶纤维素悬浮液(德国达姆施塔特,默克)应用于0.45μmghp滤板(美国密歇根州安阿伯市颇尔公司)的每个井。通过使用真空歧管(美国马萨诸塞州比尔里卡密理博公司)应用真空除去溶剂。所有井都用5×200μl水预洗,然后用3×200μl乙腈/水(80:20,v/v)进行平衡。样品被加载到威尔斯。随后用200μl乙腈/水(80:20,v/v)洗涤7×威尔斯。糖用100μl水洗脱2×2次,组合洗脱液在-20℃保存至uplc分析。(6)通过亲水相互作用(hilic)超高效液相色谱(uplc)对荧光标记的n-聚糖进行定量分析(分离):在由四元溶剂管理器、样品管理器和荧光检测器组成的水含量仪(美国马萨诸塞州米尔福德市)上,采用亲水相互作用高效液相色谱(hilic-uplc)分离荧光标记的n-聚糖。分别为250和428nm的avelgnen。该仪器在empower2软件的控制下,建造2145(美国马萨诸塞州米尔福德沃特斯)。采用水桥式乙烯杂化甘油色谱柱,150×2.1mm和1.7μm的beh颗粒,100mm甲酸铵,ph4.4,溶剂a和乙腈为溶剂b,对标记的n-聚糖进行分离。在25分钟的分析运行中,流速为0.561ml/min的流速(v/v)。样品在注射前保持在5℃,分离温度为25℃,系统采用水解和2-ab标记的葡萄糖低聚物外标法进行标定,用于将单糖保留时间转换为葡萄糖单元。数据处理采用自动处理方法,采用传统的积分算法,然后手动校正每个色谱图以维持所有样品的积分间隔相同。所有色谱图以相同的方式分离成46个峰(gp1-gp46),每个峰中的聚糖含量表示为总积分面积的百分比。文献中描述了上述uplc定量分析方法;参见参考文献8。典型的色谱图如图1所示。根据本发明,将获得的46n-聚糖定量百分比的结果合并到模型中,风险确定方法:在得到46个n-聚糖定量百分比的结果之后,有可能使用前面在实施例2第(7)项中描述的所提供的模型之一。使用模型的探讨有趣的是,根据输入参数,模型彼此显著不同;基于因子hb和lb百分比的模型具有更强的鲁棒性,因为它独立于被调查者的性别和年龄。根据本发明,所创建的数学模型包括血浆n-聚糖在当前健康人的2型糖尿病(t2d)发展中具有重大作用,并且可以显著有助于识别具有发展t2d风险增加的个体。尽管一些聚糖在观察组之间显示出统计学上的显著差异,但是它们都不是识别2型糖尿病发展倾向的良好个体标记。另一方面,根据本发明,建立的数学模型包括所有46个n-聚糖,显示出预测t2d发展的显著能力。高支化(hb)n-聚糖以及它们与低支化n-聚糖的比率(hb/lb)在模型的预测中起重要作用。由于葡萄糖在糖基化途径中扮演着重要角色,葡萄糖水平的中断调节与高度支化(hb)n-聚糖相关。部分原因是葡萄糖是形成udp-glcnac的六糖胺生物合成途径(hbp)中的关键代谢物。udp-glcnac是一个关键的单糖供体,对于n-聚糖在内质网中开始生物合成是必需的,随后在高尔基体系中,n-聚糖发生分支。所有这些都清楚地表明了葡萄糖的破坏调节与高度支化(hb)n-聚糖百分比随之增加的关系。根据本发明,在所描述的数学模型中使用hbn-聚糖,即它们与低分支(lb)n-聚糖的相对比率,作为预测当前健康人t2d发展的关键因素。工业适用性本发明公开了通过定量分析血浆n-聚糖来确定当前健康人未来患2型糖尿病风险的方法。因此,本发明的工业适用性是显而易见的。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1