一种基于光谱数据的铁矿石全铁含量检测方法与流程
本发明属于计算机技术领域,尤其涉及一种基于光谱数据的铁矿石全铁含量检测方法。
背景技术
赤铁矿和磁铁矿是铁矿石的主要种类,铁矿石中的含铁量决定了铁矿石的品位和质量。铁矿石的品位和质量又关系到开采矿石的成本以及经济收益。选取准确简便的测定铁矿石全铁含量的方法对于开采铁矿石,获得较大的经济效益有重要的指导作用。对铁矿石中全铁含量的测定方法,主要有化学分析方法和仪器分析法。化学分析方法中最常用的就是经典的重铬酸钾滴定法,该方法灵敏度高,适用性较强,可以准确定量的观测到数据的大小和变化。但在测定过程中使用到的汞不能消除,会对环境造成一定的污染。仪器分析方法具有检测速度快,能够排除人为主观因素影响等优势,但如何尽可能降低复杂基体的干扰,提高仪器检测的准确度,涉及到样品前处理以及仪器分析软件的优化,仍待进一步完善。上述缺陷是本领域技术人员期望克服的。
技术实现要素:
(一)要解决的技术问题
为了解决现有技术的上述问题,本发明提供了一种基于光谱数据的铁矿石全铁含量检测方法,具有效率高、成本低、且精度高的优点。
(二)技术方案
为了达到上述目的,本发明采用的主要技术方案包括:
一种基于光谱数据的铁矿石全铁含量检测方法,包括以下步骤:
获取待检测铁矿石样品的光谱数据,所述光谱数据中包含m个光谱特征;
将所述光谱数据输入铁矿石分类模型中,获得所述待检测铁矿石样品的铁矿石类型;
其中,所述铁矿石分类模型为预先采用类型已知的多个铁矿石样品的光谱数据建立的,所述铁矿石分类模型为极限学习机神经网络,所述铁矿石分类模型用于处理包含m个光谱特征的铁矿石的光谱数据以获得光谱数据对应的铁矿石的种类。
根据获得的铁矿石类型,将所述光谱数据输入相应铁矿石类型的铁矿石全铁含量检测模型中,获得所述光谱数据对应的铁矿石全铁含量。
其中,所述铁矿石全铁含量检测模型为预先采用全铁含量已知的多个铁矿石样品的光谱数据建立的,所述铁矿石全铁含量检测模型为改进粒子群算法优化的双隐含层极限学习机神经网络模型,所述铁矿石全铁含量检测模型具有经过改进粒子群算法优化后的最优权重矩阵、最优偏置向量以及最优隐含层节点数,所述铁矿石全铁含量检测模型用于处理包括m个特征的铁矿石光谱数据以获得对应铁矿石的全铁含量。
优选地,将所述光谱数据输入铁矿石分类模型中,获得所述待检测铁矿石样品的铁矿石类型之前,还包括:
采用类型已知的多个铁矿石样品光谱数据,利用主成分分析算法对所述光谱数据进行处理,建立基于极限学习机神经网络的铁矿石分类模型。
优选地,所述方法还包括如下子步骤:
获取类型已知的多个铁矿石样品光谱数据,其中,每个铁矿石样品的光谱数据中包含m个光谱特征;
利用主成分分析算法将铁矿石样本光谱数据中m个光谱特征降为n个光谱特征;
设置极限学习机神经网络的参数,其中,设置输入层的节点个数为n,设置输出层的节点为1;
将类型已知的多个铁矿石样品光谱数据利用主成分分析算法处理后,作为所述极限学习机神经网络的输入数据;
将类型已知的多个铁矿石样品的铁矿石类型对应地作为所述极限学习机神经网络的输出数据,训练网络得到的极限学习机神经网络即为铁矿石分类模型。
优选地,在根据获得的铁矿石类型,将所述光谱数据输入相应铁矿石类型的铁矿石全铁含量检测模型中,获得所述光谱数据对应的铁矿石全铁含量之前,还包括:
采用多组类型和全铁含量已知的铁矿石光谱数据,利用主成分分析算法对光谱数据处理后,对不同类型的铁矿石分别建立基于改进粒子群算法优化的双隐含层极限学习机神经网络的铁矿石全铁含量检测模型。
优选地,所述方法还包括如下子步骤:
获取多个类型和全铁含量已知的铁矿石光谱数据,其中,每个光谱数据中包含m个光谱特征;
利用主成分分析算法将光谱数据中m个光谱特征降为n个光谱特征;
设置改进粒子群算法优化的双隐含层极限学习机神经网络的参数,其中,设置输入层的节点个数为n,设置输出层的节点为1;
将铁矿石光谱数据利用主成分分析算法处理后,作为所述改进粒子群算法优化的双隐含层极限学习机神经网络的输入数据;
将铁矿石全铁含量作为所述改进粒子群算法优化的双隐含层极限学习机神经网络的输出数据;
使用改进粒子群算法得到所述双隐含层极限学习机神经网络第一个隐含层的最优权重矩阵、最优偏置向量以及最优的隐含层节点数;
将所述最优权重矩阵设置为所述改进粒子群算法优化的双隐含层极限学习机神经网络第一个隐含层的权重矩阵;
将所述最优偏置向量设置为所述改进粒子群算法优化的双隐含层极限学习机神经网络第一个隐含层的偏置向量;
将所述最优隐含层节点数设置为所述改进粒子群算法优化的双隐含层极限学习机神经网络的隐含层节点数;
获得的改进粒子群算法优化的双隐含层极限学习机神经网络即为相应类型铁矿石全铁含量的检测模型。
优选地,在使用改进粒子群算法得到所述改进粒子群算法优化的双隐含层极限学习机神经网络第一个隐含层的最优权重矩阵和最优偏置向量时,在每一轮迭代中,根据第一公式获取惯性权重ω(k),所述第一公式为:
ω(k)=ωstart-(ωstart-ωend)·k/tmax
其中,ωstart=0.9,ωend=0.4,k为当前迭代次数,tmax为最大迭代次数。
优选地,在每一轮迭代中,根据第二公式更新粒子的个体极值适应度值pib和群体极值适应度值pg,所述第二公式为:
其中,pi为第i个粒子的位置;
优选地,在使用改进粒子群算法得到所述粒子群算法优化的双隐含层极限学习机神经网络的最优隐含层节点数时,在每一轮迭代中,根据第三公式更新粒子长度,即改变隐含层节点数l,所述第三公式为:
其中,rand()为产生一个[0,1]的数,lk+1为变异操作后的隐含层节点数,lk为变异前的隐含层节点数。
优选地,所述改进粒子群算法优化的双隐含层极限学习机神经网络中,极限学习机神经网络中的激活函数为1-e-x/1+e-x。
优选地,还包括:对铁矿石样品进行多次光谱测试,并将多次光谱测试的光谱数据进行算术平均后作为所述铁矿石样品的光谱数据;其中,所述光谱测试中的光谱范围包括:可见光光谱和近红外光光谱。
(三)有益效果
本发明的有益效果是:本发明提供的一种基于光谱数据的铁矿石全铁含量检测方法,采用具有最优权重矩阵、最优偏置向量以及最优隐含层节点数的改进粒子群算法优化的双隐含层极限学习机神经网络对铁矿石样品的光谱数据进行处理,得到的铁矿石样品全铁含量精度较高且该方法效率高、成本低。
附图说明
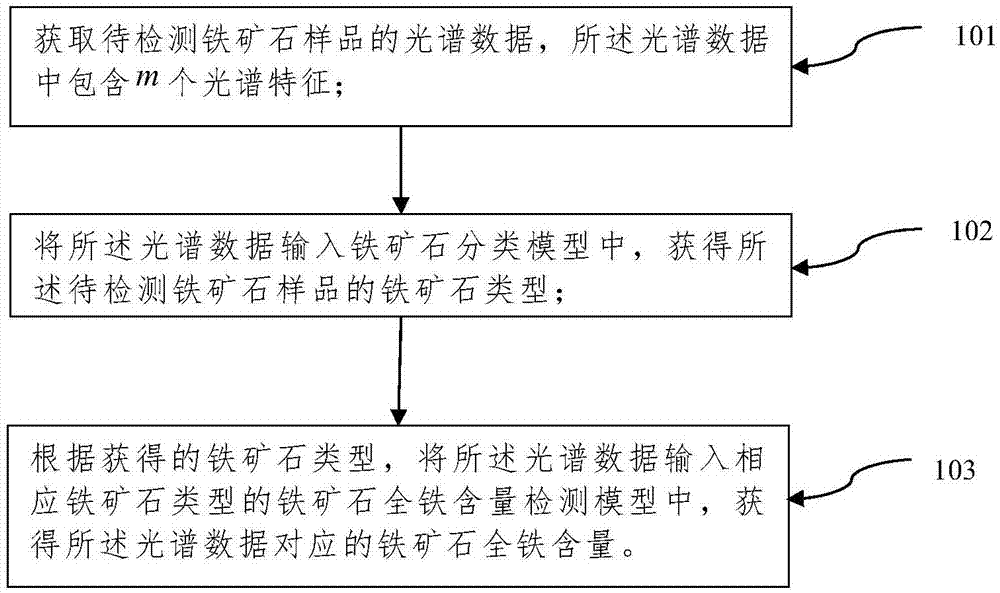
图1为本发明一种基于光谱数据的铁矿石全铁含量检测方法的流程示意图;
图2为本发明一种基于铁矿石光谱数据的铁矿石全铁含量检测方法中建立铁矿石全铁含量检测模型的流程示意图;
图3为本发明实施例中赤铁矿测试样品的全铁含量检测数据与实际数据的对比图;
图4为本发明实施例中磁铁矿测试样品的全铁含量检测数据与实际数据的对比图。
具体实施方式
为了更好的解释本发明,以便于理解,下面结合附图,通过具体实施方式,对本发明作详细描述。
如图1所示:本发明实施例中基于光谱数据的铁矿石全铁含量检测方法,包括以下步骤:
101、获取待检测铁矿石样品的光谱数据,所述光谱数据中包含m个光谱特征。
102、将所述光谱数据输入铁矿石分类模型中,获得所述待检测铁矿石样品的铁矿石类型。
其中,所述铁矿石分类模型为预先采用类型已知的多个铁矿石样品的光谱数据建立的,所述铁矿石分类模型为极限学习机神经网络模型,所述铁矿石分类模型用于处理包括m个特征的铁矿石光谱数据以获得对应的铁矿石的类型,方便根据铁矿石的类型选择对应的铁矿石全铁含量检测模型。
103、根据获得的铁矿石类型,将所述光谱数据输入相应铁矿石类型的铁矿石全铁含量检测模型中,获得所述光谱数据对应的铁矿石全铁含量。
其中,所述铁矿石全铁含量检测模型为预先采用全铁含量已知的多个铁矿石样品的光谱数据建立的,所述铁矿石全铁含量检测模型为改进粒子群算法优化的双隐含层极限学习机神经网络模型,所述铁矿石全铁含量检测模型具有经过改进粒子群算法优化后的最优输入权重矩阵、最优偏置向量以及最优隐含层节点数,所述铁矿石全铁含量检测模型用于处理包括m个特征的铁矿石光谱数据以获得对应的铁矿石的全铁含量。
铁矿石分类模型
本实施例还提供了关于铁矿石分类模型的建立方法,具体地,在所述采用铁矿石分类模型对所述光谱数据进行处理之前,还包括:
采用类型已知的多个铁矿石样品的光谱数据,使用主成分分析算法处理后,建立基于极限学习机神经网络的铁矿石分类模型。
详细地,所述方法还包括如下子步骤:
获取类型已知的多个铁矿石样品光谱数据,其中,每个铁矿石样品的光谱数据中包含m个光谱特征。
利用主成分分析算法将铁矿石样本光谱数据中m个光谱特征降为n个光谱特征。
设置极限学习机神经网络的参数,其中,设置输入层的节点个数为n,设置输出层的节点为1。
将类型已知的多个铁矿石样品光谱数据利用主成分分析算法处理后,作为所述极限学习机神经网络的输入数据。
将类型已知的多个铁矿石样品的铁矿石类型对应地作为所述极限学习机神经网络的输出数据,训练网络得到的极限学习机神经网络即为铁矿石分类模型。
铁矿石全铁含量检测模型
本实施例还提供了铁矿石全铁含量检测模型的建立方法,具体地在本实施例中在根据获得的铁矿石类型,将所述光谱数据输入相应铁矿石类型的铁矿石全铁含量检测模型中,获得所述光谱数据对应的铁矿石全铁含量之前,还包括:
采用多组类型和全铁含量已知的铁矿石光谱数据,利用主成分分析算法对光谱数据处理后,对不同类型的铁矿石分别建立基于改进粒子群算法优化的双隐含层极限学习机神经网络的铁矿石全铁含量检测模型。
应当理解为,建立基于改进粒子群算法优化的双隐含层极限学习机神经网络的铁矿石全铁含量检测模型的步骤应当在采用铁矿石全铁含量检测模型对所述光谱数据进行处理之前。
但是,获取多个待检测的铁矿石样品的光谱数据可以在建立基于改进粒子群算法优化的双隐含层极限学习机神经网络的铁矿石全铁含量检测模型的步骤之前,或者之后。
具体地,获取多个待检测的铁矿石样品的光谱数据在建立基于改进粒子群算法优化的双隐含层极限学习机神经网络的铁矿石全铁含量检测模型步骤之前,适应于在模型建立阶段。具体地,将获得的铁矿石样品,采用无差异的参数得到其对应的光谱数据。并将这些铁矿石样品随机的选择出一部分作为建立模型的训练样品,一部分作为验证样品,将其余的样品作为测试样品。
具体地,在建立基于改进粒子群算法优化的双隐含层极限学习机神经网络的铁矿石全铁含量检测模型之后,对获得的类型和全铁含量未知的铁矿石样品,采用与训练样本和验证样本相同的参数得到其对应的光谱数据。采用铁矿石分类模型对所述光谱数据进行处理,获得所述光谱数据对应的铁矿石类型,然后采用与铁矿石类型相对应的铁矿石全铁含量检测模型分别对不同类型的铁矿石的光谱数据进行处理,获得所述光谱数据对应的铁矿石的全铁含量。
经过前述的训练步骤和验证步骤,预测样品全铁含量的预测值误差较小,可以满足生产实际需要。
具体地,极限学习机(extremelearningmachine,以下简称elm)神经网络是huang在2004年提出的一种单隐含层前馈神经网络。传统的bp神经网络主要是基于梯度下降算法,该方法通常会由于运行不当或者陷入局部极小而变得非常缓慢。而elm神经网络的特点是随机生成隐含层节点参数,训练模型速度快,并具有更好的泛化性能。为了提高elm的准确率,2016年boyangqu等提出了双隐含层极限学习机(two-hiddenextremelearningmachine,以下简称telm)。
在上述双隐含层极限学习机神经网络中,第一隐含层的权值矩阵和偏置向量是随机给定的,这将导致极限学习机的部分权值和偏差不能达到最优,所以每一次输出的结果差异比较大。
而粒子群优化(particleswarmoptimization,以下简称pso)算法是一种全局优化算法。因此,双隐含层极限学习机和粒子群优化算法结合起来,可以对双隐含层极限学习机第一个隐含层的权重矩阵和偏置向量进行全局优化,但是传统的pso在粒子速度的更新过程中采用恒定不变的惯性权重,将会造成pso后期陷入局部最优,因此本发明的方法中在粒子群优化算法中引入线性递减的惯性权重来克服该缺点。所述双隐含层极限学习机的隐含层节点数是根据经验选取的,本发明的方法中将遗传算法中变异的思想引入粒子群算法用来寻找所述双隐含层极限学习机隐含层节点数的最优值。使用以上改进粒子群优化算法来对双隐含层极限学习机神经网络第一隐含层的权重矩阵、偏置向量以及网络的隐含层节点数进行全局优化,获得的具有最优权重矩阵、最优偏置向量以及最优隐含层节点数的改进粒子群算法优化的双隐含层极限学习机神经网络可用于处理铁矿石光谱数据以获得光谱数据对应的铁矿石的全铁含量。
然而所得到的光谱数据彼此之间有一定的相关性,因而所得到的铁矿石的光谱数据所反应的信息在一定程度上有重叠。而主成分分析法(principalcomponentanalysis,以下简称pca)旨在利用降维的思想,把多指标转化为几个综合指标(即主成分),其中每个主成分都能反映原始变量的大部分信息,且所含信息互不重复。因此要将所述铁矿石光谱数据利用主成分分析法进行处理后再利用所述铁矿石全铁含量检测模型检测全铁含量。
相应的铁矿石全铁含量检测模型建立步骤为:
获取多个类型和全铁含量已知的铁矿石光谱数据,其中,每个光谱数据中包含m个光谱特征。
利用主成分分析算法将光谱数据中m个光谱特征降为n个光谱特征;
设置改进粒子群算法优化的双隐含层极限学习机神经网络的参数,其中,设置输入层的节点个数为n,设置输出层的节点为1。
将铁矿石光谱数据利用主成分分析算法处理后,作为所述改进粒子群算法优化的双隐含层极限学习机神经网络的输入数据。
将铁矿石全铁含量作为所述改进粒子群算法优化的双隐含层极限学习机神经网络的输出数据。
使用改进粒子群算法得到所述双隐含层极限学习机神经网络第一个隐含层的最优权重矩阵、最优偏置向量以及最优的隐含层节点数。
将所述最优权重矩阵设置为所述改进粒子群算法优化的双隐含层极限学习机神经网络第一个隐含层的权重矩阵。
将所述最优偏置向量设置为所述改进粒子群算法优化的双隐含层极限学习机神经网络第一个隐含层的偏置向量。
将所述最优隐含层节点数设置为所述改进粒子群算法优化的双隐含层极限学习机神经网络的隐含层节点数。
获得的改进粒子群算法优化的双隐含层极限学习机神经网络即为相应类型铁矿石全铁含量的检测模型。
具体地,所述的方法中,采用多组类型和全铁含量已知的铁矿石光谱数据,利用主成分分析算法对光谱数据处理后,对不同类型的铁矿石分别建立基于改进粒子群算法优化的双隐含层极限学习机神经网络的铁矿石全铁含量检测模型,在具体的实施过程中,应当针对同一种类型的铁矿石采集其全铁含量的光谱数据进行建立相应类型铁矿石全铁含量的检测模型。
详细地,包括如下步骤:
获取同一类型全铁含量已知的铁矿石光谱数据,其中,每个光谱数据中包含m个光谱特征;
利用主成分分析算法将光谱数据中m个光谱特征降为n个光谱特征。
设置改进粒子群算法优化的双隐含层极限学习机神经网络的参数,其中,设置输入层的节点个数为n,设置输出层的节点为1。
将铁矿石光谱数据利用主成分分析算法处理后,作为所述改进粒子群算法优化的双隐含层极限学习机神经网络的输入数据。
将铁矿石全铁含量作为所述改进粒子群算法优化的双隐含层极限学习机神经网络的输出数据。
使用改进粒子群算法得到所述双隐含层极限学习机神经网络第一个隐含层的最优权重矩阵、最优偏置向量以及最优的隐含层节点数。
将所述最优权重矩阵设置为所述改进粒子群算法优化的双隐含层极限学习机神经网络第一个隐含层的权重矩阵。
将所述最优偏置向量设置为所述改进粒子群算法优化的双隐含层极限学习机神经网络第一个隐含层的偏置向量。
将所述最优隐含层节点数设置为所述改进粒子群算法优化的双隐含层极限学习机神经网络的隐含层节点数。
获得的改进粒子群算法优化的双隐含层极限学习机神经网络即为相应类型铁矿石全铁含量的检测模型。
此外,对主成分分析算法说明如下:
假如我们的数据集是n维的,共有m个数据(x(1),x(2),l,x(m))。我们希望将这m个数据的维度从n维降到n′维,为了让这n′维的数据尽可能表示原来的数据,降维的标准为:样本点到这个超平面的距离足够近,或者说样本点在这个超平面上的投影能尽可能的分开。基于上面的标准,可以采用基于最小投影距离的思想进行推导:
假设m个n维数据(x(1),x(2),l,x(m))都已经进行了中心化,即
如果我们将数据从n维降到n′维,假设新的坐标系为{ω1,ω2,lωn′},样本点x(i)在n′维坐标系中的投影为:
考虑整个样本集,我们希望所有的样本到这个超平面的距离足够近,即要使下式最小化:
将这个式子进行整理,可以得到:
注意到
利用拉格朗日函数可以得到
j(w)=-tr(wtxxtw)+λ(wtw-i)(4)
对j(w)求导有-xxtw+λw=0,整理下即为:
xxtw=λw(5)
可以看出,w为xxt的n′个特征向量组成的矩阵,而λ为xxt的特征值。当我们将数据集从n维降到n′维时,需要找到最大的n′个特征值对应的特征向量。这n′个特征向量组成的矩阵w即为我们需要的矩阵。对于原始数据集,我们只需要用z(i)=wtx(i),就可以把原始数据集降维到最小投影距离的n′维数据集。
对极限学习机神经网络说明如下:
假设极限学习机神经网络有l个隐含层节点,有n个训练样本数据(xi,ti)。
其中,xi=[xi1xi2lxin]t∈rn。则该神经网络的输出为:
其中,ωi=[ωi1ωi2lωin]t为连接第i个隐藏层节点与输入节点的输入权值。βi为连接第i个隐藏层节点与输出节点的输出权值。bi为第i个隐藏层节点的偏置。g(x)代表隐含层神经元的输出,对于加法型隐藏节点,g(x)为:g(ωi,bi,xj)=g(ωi·xj+bi)。让神经网络的实际输出和期望输出相等,还可以表示为:
hβ=t(7)
其中,h为隐藏层输出矩阵,β为隐藏层输出权值矩阵,t为期望输出。
huang教授的算法是随机选择输入权值和隐含层偏差值,训练这个网络结构相当于求解线性系统hβ=t的最小二乘解
minimize:||hβ-t||(10)
最后huang教授已经证明该线性系统最小二乘解的最小值是:
这里:h+是h的moore-penrose广义逆矩阵,并且hβ=t的最小二乘解的最小值是唯一的。
对双隐含层极限学习机的说明如下:
假设telm神经网络的训练样本数据集为{x,t}={xi,ti}(i=1,2,l,q),其中x为样本的输入,t为样本的输出。且假定telm模型中两个隐含层都含有相同的隐含层节点数和激活函数。
首先,在telm的算法设计中,先把它的两个隐含层看成是含有单隐含层的elm神经网络,这样,隐含层的输出h为:
h=g(wx+b)(12)
其中w和b都是随机初始化的单隐含层elm中隐含层的权值与偏差。
隐含层与输出层之间的权值矩阵β为:
β=h+t(13)
把第二个隐含层加入到telm神经网络中,且两个隐含层之间是全连接的关系,可以得到第二个隐含层的预测输出h1为:
h1=g(w1h+b1)(14)
其中,w1是第一个隐含层与第二个隐含层之间的权值矩阵,b1是第二个隐含层的偏差,h为第一个隐含层的输出矩阵。
而第二个隐含层的期望输出h1*为:
h1*=tβ+(15)
为了满足最终隐含层的预测输出无穷接近于期望输出,使得h1=h1*。
假设矩阵whe=[b1w1],因此第二个隐含层的权值w1和阈值b1可以求解得:
whe=g-1(h1*)he+(16)
其中,
当第二个隐含层的权值参数w1和阈值参数b1全部求解过后,我们可以更新第二个隐含层的预测输出h2:
h2=g(w1h+b1)=g(whehe)(17)
因此,隐含层的输出矩阵β可以更新为:
最后可以得到最终的神经网络输出f(x)为:
f(x)=h2βnew(19)
对粒子群算法说明如下:
粒子群算法是由kennedy和eberhart提出的一种全局优化算法,源于对鸟群捕食行为的研究。粒子群算法的基本思想是通过群体中个体之间的协作和信息共享来寻找最优解。由于粒子群算法结构简单、容易实现,并且没有许多参数的调节,目前已被广泛应用于函数优化、神经网络训练等领域。
粒子群优化算法实现过程如下:在一个种群里,每一只鸟被抽象为一个粒子,并延伸到n维空间,粒子i在n维空间的位置xi=(xi1,xi2,l,xin),飞行的速度vi=(vi1,vi2,l,vin),每个粒子都有一个由目标函数决定的适应度值,其中,i=1,2,l,m。
在每一次迭代中,粒子通过跟踪粒子本身经历的最好的位置pbesti=(pbesti1,pbesti2,l,pbestin)和整个群体所经过的最好的位置gbesti=(gbesti1,gbesti2,l,gbestin),并根据公式(20)和(21)不断更新速度和位置。
其中,k为当前迭代次数,c1,c2为学习因子,ω为惯性权重。
本发明实施例的方法中,采用线性递减的惯性权重,从而更有效地避免早熟收敛,对网络增加稳定性。
具体地,所述的方法中,在使用粒子群优化算法得到所述粒子群算法去优化的极限学习机神经网络的最优权重矩阵和最优偏置向量时,在每一轮迭代中,根据第一公式获取惯性权重ω,所述第一公式为:ω(k)=ωstart-(ωstart-ωend)·k/tmax,其中,ωstart=0.9,ωend=0.4,k为当前迭代次数,tmax为最大迭代次数。
在每一轮迭代中,根据第二公式更新粒子的个体极值适应度值pib和群体极值适应度值pg,所述第二公式为:
其中,pi为第i个粒子的位置,
具体地,所述的方法中,在使用改进粒子群算法得到所述改进粒子群算法优化的双隐含层极限学习机神经网络的最优隐含层节点数时,在每一轮迭代中,根据第三公式更新粒子长度,即改变隐含层节点数l,所述第三公式为:
其中,rand()为产生一个[0,1]的数,lk+1为变异操作后的隐含层节点数,lk为变异前的隐含层节点数。
具体地,所述的方法中,所述改进粒子群优化算法优化的双隐含层极限学习机神经网络中,极限学习机神经网络中的激活函数为1-e-x/1+e-x函数。
应当理解为,所述的方法中,还包括获取铁矿石样品的光谱数据的步骤:
对铁矿石样品进行多次光谱测试,并将多次光谱测试的光谱数据进行算术平均后作为所述铁矿石样品的光谱数据,其中,所述光谱测试中的光谱范围包括:可见光光谱和近红外光光谱,所述光谱数据中包含m个光谱特征。
以下结合具体应用,对本发明实施例中的基于光谱数据检测铁矿石全铁含量的方法进行说明。
收集铁矿石样品,共有123个样品,其中包括91个赤铁矿样品,32个磁铁矿样品。采用美国spectravista公司的svchr-1024便携式地物光谱仪作为实验仪器。该仪器光谱范围:350-2500nm。内置存储器:500scans(扫)。重量:3kg,通道数:1024。光谱分辨率(fwhm≦8.5nm)1000~1850nm。最小积分时间:1毫秒。
在获取铁矿石样品的光谱数据时,仪器扫描时间为1秒/次,光谱仪的探头距样品片表面300mm,并垂直于样品片表面。在实验过程中为减少周围环境对光谱测试的干扰,要求实验都在一个封闭室内完成,避免太阳和其他光源的照射,实验人员不得走动并穿着深色服装。
利用光谱仪(svchr-1024)对各样品进行五次光谱测试,然后取平均值作为该样品的光谱数据。实验中每10分钟进行一次白板测量校准。所得到的光谱数据彼此之间有一定的相关性,因而所得到的铁矿石的光谱数据所反应的信息在一定程度上有重叠。因此借助主成分分析对光谱数据进行降维处理,能够有效的减小预测误差。
具体地,获得的赤铁矿样品及光谱数据共有123组,其中选取86组作为训练数据,训练极限学习机神经网络作为铁矿石分类模型,37组作为测试数据,检验模型分类的准确性。仿真得到模型分类的准确率为100%。
对赤铁矿和磁铁矿分别建立具有最优权重矩阵、最优偏置向量以及最优隐含层节点数的改进粒子群优化算法优化的双隐含层极限学习机神经网络作为基于光谱数据的铁矿石全铁含量检测模型。如图2所示,本发明实施例中基于光谱数据检测铁矿石全铁含量的方法中建立铁矿石全铁含量检测模型的方法,步骤如下:
(1)把光谱数据输入给pca进行处理,每个光谱数据有973个光谱特征,主成分分析后,输出数据为5个特征。
(2)初始化改进粒子群算法和telm神经网络,粒子的最大迭代次数为50,粒子群数量为30;选择1-e-x/1+e-x函数作为telm神经网络的激活函数。
(3)使用telm算法对训练集光谱特征数据训练、验证以得到改进粒子群的适应度值,对适应度值进行判断,然后保存最优的适应度值和改进粒子群的速度、位置以及粒子长度。
(4)当网络达到最大迭代次数时就退出寻优,这时的改进粒子群算法优化的双隐含层极限学习机神经网络具有最优权重矩阵、最优偏置向量以及最优的隐含层节点数。
利用赤铁矿全铁含量检测模型处理18组测试数据,得到的赤铁矿全铁含量的检测结果如图3所示。测试的均方误差为1.3233,相关系数为0.9572,准确率为95.61%。可以很好地对全铁含量的实际值进行拟合。
利用磁铁矿全铁含量检测模型处理6组测试数据,得到的磁铁矿全铁含量的检测结果如图4所示。测试的均方根误差为1.5940,相关系数为0.9923,准确率为96.54%。可以很好地对全铁含量的实际值进行拟合。
综上所述,与传统的铁矿石全铁含量检测方法相比,本发明实施例的基于光谱数据对全铁含量检测的方法,采用可见、近红外光谱,采用改进粒子群算法优化双隐含层极限学习机神经网络建立的铁矿石全铁含量检测模型在全铁含量检测时准确、高效。本发明实施例的基于光谱数据对铁矿石全铁含量检测的方法在经济、速度、准确性方面具有很大的优势和重要的实际应用价值。
最后应说明的是:以上所述的各实施例仅用于说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分或全部技术特征进行等同替换;而这些修改或替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
- 还没有人留言评论。精彩留言会获得点赞!