基于无人驾驶的多数据融合障碍物检测装置及其检测方法与流程
本发明涉及无人驾驶技术领域,尤其涉及一种基于无人驾驶的多数据融合障碍物检测装置及其检测方法。
背景技术:
随着人们对汽车智能化要求的不断提高,无人驾驶汽车作为智能驾驶的核心成为了人们最为关注的技术。而障碍物识别是实现自动驾驶的最基本的条件,如果检测结果不好,可能会导致碰撞的事故,因而,障碍物融合作为障碍物输出给规划和控制模块,必须能够很鲁棒,才能够适应各种传感器输出的误差,甚至是错误,以保证无人驾驶时的安全。
技术实现要素:
本发明针对现有技术中存在的上述问题,提供一种基于无人驾驶的多数据融合障碍物检测装置,保证了障碍物检测的鲁棒性,使得无人驾驶汽车更加安全可靠。
为实现上述目的和一些其他的目的,本发明采用如下技术方案:
一种基于无人驾驶的多数据融合障碍物检测装置,包括:
判断模型,其通过车辆驾驶过程中各种障碍物情况的样本数据收集并训练得到;
设置在车辆上的障碍物融合模块,其由多个传感器和融合模块组成;多个所述传感器获取所述障碍物融合模块覆盖区域内的障碍物信息,所述融合模块将所述障碍物信息融合后发送至所述判断模型内进行学习,并将所述判断模型判定的障碍物信息作为最终的障碍物结果发送至所述车辆的驾驶系统。
优选的是,所述的基于无人驾驶的多数据融合障碍物检测装置中,所述传感器包括雷达传感器、视觉传感器和激光传感器。
优选的是,所述的基于无人驾驶的多数据融合障碍物检测装置中,所述融合模块内设置有3d模型生成模块、调取模块和分析模块;所述3d模型生成模块用于依据行驶位置生成试剂行驶道路的3d模型;所述调取模块连接于所述传感器,以将由所述传感器获取的障碍物信息投影到所述3d模型上,所述分析模块与所述3d模型生成模块和调取模块分别连接,所述分析模块对投影到所述3d模型上的障碍物信息进行删除和合并后,形成融合的障碍物信息。
优选的是,所述的基于无人驾驶的多数据融合障碍物检测装置中,所述分析模块对投影到所述3d模型上的障碍物信息进行删除和合并的依据为:
对单独投影到所述3d模型任一位置的障碍物信息进行删除;以及
对投影到所述3d模型同一位置的多个障碍物信息进行合并。
一种基于无人驾驶的多数据融合障碍物检测装置的检测方法,主要包括以下步骤:
步骤a、通过车辆驾驶过程中各种障碍物情况的样本数据收集并训练得到判断模型;
步骤b、通过多个传感器获取所述传感器覆盖区域内的障碍物信息;
步骤c、将多个所述传感器获取的障碍物信息进行融合,得到融合的障碍物信息;
步骤d、将步骤c得到的融合的障碍物信息输入判断模型内,经判断模型学习后的结果作为最终的障碍物结果发送至车辆的驾驶系统。
优选的是,所述的基于无人驾驶的多数据融合障碍物检测装置的检测方法中,多个所述传感器包括:雷达传感器、视觉传感器和激光传感器。
优选的是,所述的基于无人驾驶的多数据融合障碍物检测装置的检测方法中,步骤c中将多个所述传感器获取的障碍物信息进行融合的方法具体包括以下步骤:
步骤a、依据行驶位置设置实际行驶道路的3d模型;
步骤b、将多个所述传感器获取的障碍物信息投影至所述3d模型上;
步骤c、对单独投影在所述3d模型任一位置的障碍物信息进行删除;
步骤d、将剩余的投影在3d模型同一位置的障碍物信息分别合并,合并后的障碍物信息的集合即为所述融合的障碍物信息。
优选的是,所述的基于无人驾驶的多数据融合障碍物检测装置的检测方法中,所述障碍物信息投影至所述3d模型的俯视图上。
本发明至少包括以下有益效果:
本发明所述的基于无人驾驶的多数据融合障碍物检测装置中,由于有多个传感器的互相对照,可以完全忽略某一个传感器发生问题的情况,使得整体方案更加的稳定,与传统方法接入所有输入,使用所有信息,虽然大部分情况下可以工作的很好,但是当系统发生某种未知故障时候,可能会出现比较大的故障,与传统方法比,该方法鲁棒性比较高,不需要人为的设置先验。
本发明的其它优点、目标和特征将部分通过下面的说明体现,部分还将通过对本发明的研究和实践而为本领域的技术人员所理解。
附图说明
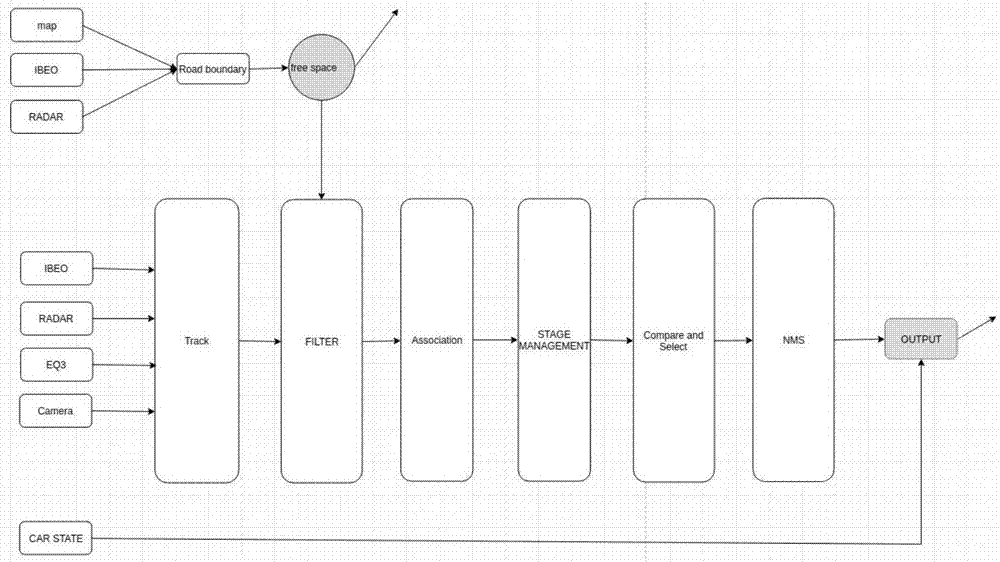
图1是本发明所述的基于无人驾驶的多数据融合障碍物检测装置的检测方法流程图;
图2是本发明所述的基于无人驾驶的多数据融合障碍物检测装置的检测方法的网络结构图。
具体实施方式
下面结合附图对本发明做详细说明,以令本领域普通技术人员参阅本说明书后能够据以实施。
一种基于无人驾驶的多数据融合障碍物检测装置,包括:判断模型,其通过车辆驾驶过程中各种障碍物情况的样本数据收集并训练得到;
设置在车辆上的障碍物融合模块,其由多个传感器和融合模块组成;多个所述传感器获取所述障碍物融合模块覆盖区域内的障碍物信息,所述融合模块将所述障碍物信息融合后发送至所述判断模型内进行学习,并将所述判断模型判定的障碍物信息作为最终的障碍物结果发送至所述车辆的驾驶系统。
在上述方案中,车辆在行驶过程中,通过车辆上安装的障碍物融合模块中的多个传感器持续的对周围环境中的障碍物进行检测,然后通过将检测的障碍物信息在融合模块内融合,并经过判断模型的判断后,输出最终的障碍物结果,以供无人驾驶车辆根据周遭的障碍物情况进行驾驶状态的选择。
通过多个传感器的设置使得检测结果的准确度大大提高,且在其中一个传感器发生误检或者漏召回的情况下对整体检测结果的准确度的影响较小,提高了无人驾驶的安全性和可靠性。
一个优选方案中,所述传感器包括雷达传感器、视觉传感器和激光传感器。
在上述方案中,雷达传感器对于障碍物的检测没有物体的大小信息,只有位置和速度信息,同一个车可能会有多个雷达传感器的结果返回,视觉传感器对于障碍物的检测有速度、位置以及车尾部大小等信息,但是位置和速度不是很准确,激光传感器对障碍物的检测有位置、大小以及速度等信息,比较稳定和准确,但是没有办法区分静态场景和静止的障碍物,比如路缘石或静止的车辆等,因而通过将障碍物融合模块内的传感器设置为雷达传感器、视觉传感器和激光传感器的组合能够互相取长补短,使得最终输出的检测结果的准确度大大提高。
一个优选方案中,所述融合模块内设置有3d模型生成模块、调取模块和分析模块;所述3d模型生成模块用于依据行驶位置生成试剂行驶道路的3d模型;所述调取模块连接于所述传感器,以将由所述传感器获取的障碍物信息投影到所述3d模型上,所述分析模块与所述3d模型生成模块和调取模块分别连接,所述分析模块对投影到所述3d模型上的障碍物信息进行删除和合并后,形成融合的障碍物信息。
在上述方案中,通过3d模型生成模块、调取模块和分析模块设置,使得所述障碍物融合模块能够根据车辆行驶的真实场景生成3d模型,从而使得各个传感器检测的结果落在对应于真实行驶场景的3d模型内才进一步对检测的各个障碍物信息进行处理,使得融合的障碍物信息依据真实行驶场景得到,进一步保证了输出的结果的准确性。
一个优选方案中,所述分析模块对投影到所述3d模型上的障碍物信息进行删除和合并的依据为:对单独投影到所述3d模型任一位置的障碍物信息进行删除;以及
对投影到所述3d模型同一位置的多个障碍物信息进行合并。
在上述方案中,通过将单独投影到任一位置的障碍物信息删除,剔除了个别传感器发生误检或漏召回对检测结果的准确度的影响,通过对落在同一位置的多个障碍物信息进行合并,使得各个传感器的检测数据取长补短相互补充,使得对各个障碍物的状态判断更加准确,且减少了融合后的障碍物信息放入判断模型学习的数据处理量,提高了检测结果的输出速率。
如图1和图2所示,一种基于无人驾驶的多数据融合障碍物检测装置的检测方法,主要包括以下步骤:
步骤a、通过车辆驾驶过程中各种障碍物情况的样本数据收集并训练得到判断模型;
步骤b、通过多个传感器获取所述传感器覆盖区域内的障碍物信息;
步骤c、将多个所述传感器获取的障碍物信息进行融合,得到融合的障碍物信息;
步骤d、将步骤c得到的融合的障碍物信息输入判断模型内,经判断模型学习后的结果作为最终的障碍物结果发送至车辆的驾驶系统。
在上述方案中,车辆在行驶过程中,通过车辆上安装的障碍物融合模块中的多个传感器持续的对周围环境中的障碍物进行检测,然后通过将检测的障碍物信息在融合模块内融合,并经过判断模型的判断后,输出最终的障碍物结果,以供无人驾驶车辆根据周遭的障碍物情况进行驾驶状态的选择。
判断模型通过车辆驾驶过程中各种障碍物情况的样本数据收集并训练得到,使得得到的判断模型涵盖车辆在行驶过程中大部分障碍物状态的情况,因而在障碍物信息融合后在所述判断模型中进行学习进一步提高了障碍物判断的准确度。
通过多个传感器的设置使得检测结果的准确度大大提高,且在其中一个传感器发生误检或者漏召回的情况下对整体检测结果的准确度的影响较小,提高了无人驾驶的安全性和可靠性。
一个优选方案中,多个所述传感器包括:雷达传感器、视觉传感器和激光传感器。
在上述方案中,雷达传感器对于障碍物的检测没有物体的大小信息,只有位置和速度信息,同一个车可能会有多个雷达传感器的结果返回,视觉传感器对于障碍物的检测有速度、位置以及车尾部大小等信息,但是位置和速度不是很准确,激光传感器对障碍物的检测有位置、大小以及速度等信息,比较稳定和准确,但是没有办法区分静态场景和静止的障碍物,比如路缘石或静止的车辆等,因而通过将障碍物融合模块内的传感器设置为雷达传感器、视觉传感器和激光传感器的组合能够互相取长补短,使得最终输出的检测结果包含车辆周围障碍物的大小、位置以及速度等信息,准确度大大提高。
一个优选方案中,步骤c中将多个所述传感器获取的障碍物信息进行融合的方法具体包括以下步骤:
步骤a、依据行驶位置设置实际行驶道路的3d模型;
步骤b、将多个所述传感器获取的障碍物信息投影至所述3d模型上;
步骤c、对单独投影在所述3d模型任一位置的障碍物信息进行删除;
步骤d、将剩余的投影在3d模型同一位置的障碍物信息分别合并,合并后的障碍物信息的集合即为所述融合的障碍物信息。
在上述方案中,所述的障碍物信息进行融合的方法使得所有的障碍物都需要互相对照,在多个传感器覆盖的区域,我们通过学习一个模型来判定是否要输出最终的障碍物,输入为多元传感器的输入,并投影到依据真实行驶场景生成的3d模型上,并最终通过在判断模型中的学习来判定是否应该输出某个障碍物,保证了输出结果的准确性,提高了无人驾驶的安全性和可靠性。
一个优选方案中,所述障碍物信息投影至所述3d模型的俯视图上。
在上述方案中,障碍物信息投影至3d模型的俯视图上更加直观,便于后续相关人员对输出结果的核定,以利于对所述检测方法进行改进。
尽管本发明的实施方案已公开如上,但其并不仅仅限于说明书和实施方式中所列运用,它完全可以被适用于各种适合本发明的领域,对于熟悉本领域的人员而言,可容易地实现另外的修改,因此在不背离权利要求及等同范围所限定的一般概念下,本发明并不限于特定的细节和这里所示出与描述的图例。
- 还没有人留言评论。精彩留言会获得点赞!