磁带SEG-D地震数据结构分析方法及解编装置与流程
本申请涉及地球物理勘探技术领域,尤其涉及一种磁带seg-d地震数据结构分析方法及解编装置。
背景技术:
本部分旨在为权利要求书中陈述的本发明实施例提供背景或上下文。此处的描述不因为包括在本部分中就承认是现有技术。
目前,野外现场采集的地震数据大多是道序的seg-d格式,且基本都是先记录到磁带中再进行后续处理。seg协会共发布了3个seg-d版本标准,不同仪器生产厂商经常采用不同的seg-d版本设计地震数据采集设备,同一厂商生产的不同地震数据采集设备采用的seg-d版本也经常不同;此外,seg-d格式的灵活性和可扩展性也导致各种地震数据采集设备的seg-d数据格式不统一,如文件头大小不一、重要参数的记录格式和位置各不相同等,导致非标准seg-d地震数据众多。
为满足海量数据写带速度的要求,写带格式也发生了变化,大都采用了文件间无文件结束符(endoffile,eof)和道块化记带方式。因此,解编装置无法解编seg-d磁带中不同文件的情况经常发生,给后续的地震数据处理造成了一定的麻烦。现有处理系统或专业转储软件的磁带seg-d地震数据解编装置一般都是针对符合seg标准的、常用的地震数据采集设备所采集的数据,对于非标准的、新地震数据采集设备所采集的seg-d地震数据往往无法支持。其原因大都是分析数据结构错误,以致寻址错位,不能得到正确的文件头、道头和道数据所占用的磁带块的数量,也就不能区分磁带中不同的文件。因此,解编装置经常需要修改程序以支持某种特定的数据格式或写带方式,通用性较差。
技术实现要素:
本申请实施例提供一种磁带seg-d地震数据结构分析方法,用以减少不能解编磁带的问题的发生,提高了解编装置的通用性,该方法包括:
按照指定顺序,逐个读取存储seg-d地震数据的磁带包括的磁带块的字节数和内容;如果磁带块的字节数不为指定字节数,则将磁带块的字节数和内容满足预设条件的第一个磁带块确定为第一初始磁带块;从第一初始磁带块的内容中提取目标数据;根据所述目标数据,计算文件头字节总数;根据所述文件头字节总数以及磁带块的字节数,确定文件头所占用的磁带块的数量;从文件头所占用的最后一个磁带块之后的第一个磁带块开始,查找符合预设条件的磁带块作为第二初始磁带块,将文件头所占用的最后一个磁带块之后的第一个磁带块至第二初始磁带块之间的磁带块作为地震道数据所占用的磁带块。
本申请实施例还提供一种解编装置,用以减少不能解编磁带的问题的发生,提高了解编装置的通用性,该装置包括:
获取模块,用于按照指定顺序,逐个读取存储seg-d地震数据的磁带包括的磁带块的字节数和内容;确定模块,用于当获取模块获取的磁带块的字节数不为指定字节数时,将磁带块的字节数和内容满足预设条件的第一个磁带块确定为第一初始磁带块;提取模块,用于从确定模块确定的第一初始磁带块的内容中提取目标数据;计算模块,用于根据提取模块提取的目标数据,计算文件头字节总数;确定模块,还用于根据计算模块计算得到的所述文件头字节总数以及获取模块获取的磁带块的字节数,确定文件头所占用的磁带块的数量;确定模块,还用于从文件头所占用的最后一个磁带块之后的第一个磁带块开始,查找符合预设条件的磁带块作为第二初始磁带块,将文件头所占用的最后一个磁带块之后的第一个磁带块至第二初始磁带块之间的磁带块作为地震道数据所占用的磁带块。
本申请实施例中,可以读取磁带seg-d地震数据中所包含的数据,通过预设条件确定当前文件的文件头所占用的第一个磁带块,之后读取文件头占用的第一个磁带块中的数据计算文件头字节总数,进一步确定文件头所占用的磁带块的数量。在确定文件头所占用的磁带块的基础上,再通过预设条件确定下一个文件的文件头所占用的第一个磁带块,当前文件的文件头占用的最后一个磁带块后的第一个磁带块到下一个文件的文件头所占用的第一个磁带块之间的磁带块即为当前文件中地震道数据占用的磁带块。这样一来,在得到新的磁带seg-d地震数据之后,通过上述过程,就可以具体根据该磁带seg-d地震数据中包括的内容进行分析,得到正确的文件头、地震道头和道数据所占用的磁带块,也就可以区分磁带中不同的文件,从而减少了不能解析磁带问题的发生,提高了解编装置的通用性。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。在附图中:
图1为本申请实施例中磁带seg-d地震数据结构分析方法的流程图;
图2为本申请实施例中截取的磁带seg-d地震数据文件头的开始部分的数据图;
图3为本申请实施例中解编装置的结构图。
具体实施方式
为使本申请实施例的目的、技术方案和优点更加清楚明白,下面结合附图对本申请实施例做进一步详细说明。在此,本申请的示意性实施例及其说明用于解释本申请,但并不作为对本申请的限定。
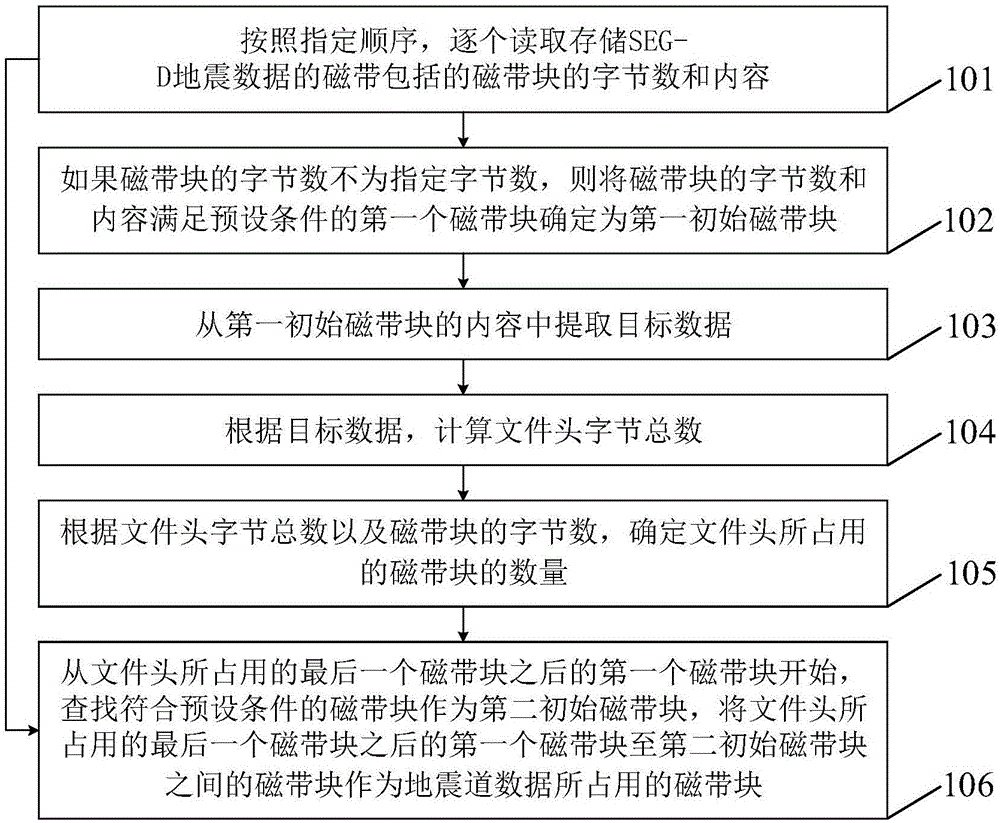
本申请实施例提供一种磁带seg-d地震数据结构解析方法,如图1所示,该方法包括步骤101至步骤106:
步骤101、按照指定顺序,逐个读取存储seg-d地震数据的磁带包括的磁带块的字节数和内容。
其中,指定顺序为由先至后。
需要说明的是,地震数据文件由文件头、道头和道数据组成,所有的文件头数据存储在整个文件占用的磁带块中的前几个磁带块中,道头和道数据占用剩余的磁带块。在道头和道数据占用的磁带块中,每个磁带块中同时存储道头和道数据,也就是说,每个磁带块中的数据组成均为“道头和道数据”,不存在某个磁带块单独存储道头或道数据的情况。此外,文件头占用的磁带块的数量、道头和道数据占用的磁带块的数量由其各自的数据量决定。
此外,随着采集技术的发展,文件头记录的信息逐渐增多,目前有些seg-d文件头最大将近100mb,必须记录在连续多个磁带块中,且对这种情况每块记录多大,不同仪器有不同的规则。
步骤102、如果磁带块的字节数不为指定字节数,则将磁带块的字节数和内容满足预设条件的第一个磁带块确定为第一初始磁带块。
可选的,指定字节数为128。如果第一个磁带块的大小是128字节,则该磁带块中存储磁带标签,而非地震数据。因此,在确定第一初始磁带块时,先判断从先至后读取的第一个磁带块的字节数是否不为128。如果磁带块的字节大小为128,则跳过该磁带块判断下一个磁带块的字节大小;如果磁带块的字节大小不为128,则将磁带块的字节数和内容满足预设条件的第一个磁带块确定为第一初始磁带块。
具体的,预设条件包括磁带块的字节数能够整除32,且seg-d地震数据的格式码是指定格式码之一,且采样间隔为指定采样间隔之一,其中,seg-d地震数据的格式码和采样间隔从磁带块的内容中提取。
如果满足预设条件,则将磁带块确定为第一初始磁带块或第二初始磁带块。
其中,指定格式码包括0x8080、0x8058、0x8048、x8044、0x8042、x8024、0x8022或x8015;指定采样间隔包括1/16毫秒ms、1/8ms、1/4ms、1/2ms、1ms、2ms、4ms或8ms。
步骤103、从第一初始磁带块的内容中提取目标数据。
在本申请实施例中,可以读取文件头模板文件中包括的目标数据字段的起始位置和所占字节数;根据目标数据字段的起始位置和所占字节数,从磁带块的内容中提取目标数据。
模板文件为定义seg-d地震数据流中各个位置的数据的含义的文件。模板文件中每行表示一个字段,由字段名称、起始字节位置(起始位置)、整数字节数(整数部分)、小数字节数(小数部分)、存储格式和输出格式六部分组成。用户可根据实际数据修改除字段名称之外的内容。其中,起始位置用于表示该字段在文件头数据流中的字节位置,整数部分和小数部分用于表示该字节所占的字节个数。由于存在字段占用半个字节的情况,因此在本申请实施例中,将模板文件中起始位置利用公式((实际字节位置-1)×2)确定,整数部分用公式(实际字节数×2)确定,小数部分同样使用(实际字节数×2)确定。
示例性的,下表一给出了一个非seg-d版本3的文件头模板文件,该文件头模板文件中字段名称为“filenumber”的字段所在的起始位置为“0”,整数部分为4,小数部分为0,则意味着,该字段在文件头数据流的第1个字节开始,占2个字节,该字段为bcd格式,解析输出为整型的文件号数值,范围0-9999。
表一
与文件头计算方法类似,计算由道头和道数据组成的地震道数据的字节总数时使用的参数也可以通过道头模板文件获取。示例性的,下表二给出了一个地震道数据的道头模板文件,道头模板文件中起始位置、整数部分、小数部分的含义与文件头模板文件中相同,在此不再赘述。
表二
根据道头模板文件,可以获取道头扩展块数h、采样点数i和seg-d地震数据的格式码对应的每个采样点的字节数j。
可选的,可以根据公式ts=20+h×32+i×j计算地震道数据字节总数ts。
需要说明的是,一般seg-d规定第一个扩展道头中都记录了采样点数,但有些非生产等类型的数据,如测试类数据、试验类数据,没有扩展道头,这时就需要通过记录道长和采样间隔计算采样点数。第二目标数据中包括记录道长l和采样间隔si,利用记录道长和采样间隔计算采样点数的方法如下:
根据公式i=l/si计算测试采样点数i’;根据计算得到的测试采样点数i’计算地震道数据字节总数ts,判断磁带块的字节数是否能整除ts;如果能,则根据公式ts=20+h×32+i’×j计算地震道数据字节总数ts;如果不能,则根据公式ts=20+h×32+(i’+1)×j计算地震道数据字节总数ts。
步骤104、根据目标数据,计算文件头字节总数。
其中,目标数据包括额外通用头段个数a、通道组数c、采样时偏头段个数d、扫描类型块数b、扩展头段个数e和外部头段个数f。
可选的,如果seg-d数据的版本号为3,则根据公式fs=(1+a+(c×3+d)×b+e+f)×32计算文件头字节总数fs。如果seg-d数据的版本号不为3,则根据公式fs=(1+a+(c+d)×b+e+f)×32计算文件头字节总数fs。
文件头由若干块数据组成,每块大小都是32字节。与其总字节大小有关的关键字段值都记录在最开始的2个通用块数据内,即应用前64个字节可计算出文件头的大小。对这两个通用头块的字段,seg-d版本3和之前的版本seg-d版本1和seg-d版本2的差异较大,因此文件头的模板文件可以分成seg-d版本3模板文件和非seg-d版本3模板文件。
下面将以具体的实例说明文件头字节总数的计算方法。
参阅图2,图2是某磁带seg-d文件的文件头开始部分。该磁带是ibm3592记录的,最大磁带块为2mb,而最大的文件头的字节数多于100mb,需要记录在多个磁带块中,且同一个磁带中不同文件的文件头大小也不相同,文件之间没有记录eof,无法通过eof定位区分不同的文件,可以使用本申请实施例提供的方法确定文件头及地震道数据分别占用的磁带块的数量。根据该文件头开始部分以及表一中定义的文件头模板文件,可知a=1,b=1,c=4,d=0,e=3,f=2882601,h=10,i=65500,j=4,fs=92243520,则ts=20+32×10+65500×4=262340,之后,可以叠加磁带块的字节数来确定文件头占用的磁带块。
步骤105、根据文件头字节总数以及磁带块的字节数,确定文件头所占用的磁带块的数量。
在本申请实施例中,可以从文件头占用的第一个磁带块开始,逐个叠加磁带块的字节数,直到叠加结果为文件头字节总数,那么叠加得到文件头字节总数的磁带块的数量是文件头所占用的磁带块的数量。
如果叠加若干个磁带块的字节数后,得到的磁带块的字节数与文件头字节总数不相等,则重新从步骤102开始执行确定初始磁带块的过程及后续过程。示例性的,如果文件头字节总数为87,叠加2个磁带块得到的字节总数为61,继续叠加第3个磁带块,得到的字节总数为90,那么确定该文件储存错误,重新从第4个磁带块开始,确定初始磁带块,在确定初始磁带块之后继续执行后续过程。
步骤106、从文件头所占用的最后一个磁带块之后的第一个磁带块开始,查找符合预设条件的磁带块作为第二初始磁带块,将文件头所占用的最后一个磁带块之后的第一个磁带块至第二初始磁带块之间的磁带块作为地震道数据所占用的磁带块。
需要说明的是,通过预设条件,可以判断磁带块是否为文件头占用的第一个磁带块,当前文件的文件头占用的磁带块后的第一个磁带块到下一个文件的文件头占用的第一个磁带块之间的磁带块则为当前文件中地震道数据占用的磁带块。示例性的,当前文件的文件头占用第一至第四这4个磁带块,通过预设条件判断下一个文件的文件头占用的第一个磁带块为第九磁带块,那么当前文件的地震道数据占用的磁带块则为第五至第八这四个磁带块。这样,也就确定可当前文件占用第一至第八磁带块,下一个文件占用的磁带块从第九磁带块开始。
在确定了当前文件的下一个文件占用的第一个磁带块,即第二初始磁带块之后,可以按照上述步骤103至步骤106中的过程确定该当前文件的下一个文件的文件头与地震道数据占用的磁带块的数量,直至读取完所有磁带块。
本申请实施例中,可以读取磁带seg-d地震数据中所包含的数据,通过预设条件确定当前文件的文件头所占用的第一个磁带块,之后读取文件头占用的第一个磁带块中的数据计算文件头字节总数,进一步确定文件头所占用的磁带块的数量。在确定文件头所占用的磁带块的基础上,再通过预设条件确定下一个文件的文件头所占用的第一个磁带块,当前文件的文件头占用的最后一个磁带块后的第一个磁带块到下一个文件的文件头所占用的第一个磁带块之间的磁带块即为当前文件中地震道数据占用的磁带块。这样一来,在得到新的磁带seg-d地震数据之后,通过上述过程,就可以具体根据该磁带seg-d地震数据中包括的内容进行分析,得到正确的文件头、地震道头和道数据所占用的磁带块,也就可以区分磁带中不同的文件,从而减少了不能解析磁带问题的发生,提高了解编装置的通用性。
本申请实施例还提供一种解编装置,如图3所示,该解编装置300包括获取模块301、确定模块302、提取模块303和计算模块304。
其中,获取模块301,用于按照指定顺序,逐个读取存储seg-d地震数据的磁带包括的磁带块的字节数和内容。
确定模块302,用于当获取模块301获取的磁带块的字节数不为指定字节数时,将磁带块的字节数和内容满足预设条件的第一个磁带块确定为第一初始磁带块。
提取模块303,用于从确定模块302确定的第一初始磁带块的内容中提取目标数据。
计算模块304,用于根据提取模块303提取的目标数据,计算文件头字节总数。
确定模块302,还用于根据计算模块304计算得到的文件头字节总数以及获取模块301获取的磁带块的字节数,确定文件头所占用的磁带块的数量。
确定模块302,还用于从文件头所占用的最后一个磁带块之后的第一个磁带块开始,查找符合预设条件的磁带块作为第二初始磁带块,将文件头所占用的最后一个磁带块之后的第一个磁带块至第二初始磁带块之间的磁带块作为地震道数据所占用的磁带块。
可选的,指定字节数为128。
可选的,预设条件,包括:
磁带块的字节数能够整除32,且seg-d地震数据的格式码是指定格式码之一,且采样间隔为指定采样间隔之一。
其中,seg-d地震数据的格式码和采样间隔从磁带块的内容中提取;指定格式码包括0x8080、0x8058、0x8048、x8044、0x8042、x8024、0x8022或x8015;指定采样间隔包括1/16毫秒ms、1/8ms、1/4ms、1/2ms、1ms、2ms、4ms或8ms。
可选的,提取模块303,用于:
读取文件头模板文件中包括的目标数据字段的起始位置和所占字节数;
根据目标数据字段的起始位置和所占字节数,从磁带块的内容中提取目标数据。
可选的,确定模块302,用于:
从第一初始磁带块开始,逐个叠加磁带块的字节数,直到叠加结果为文件头字节总数;
将叠加得到文件头字节总数的磁带块的数量作为文件头所占用的磁带块的数量。
本申请实施例中,可以读取磁带seg-d地震数据中所包含的数据,通过预设条件确定当前文件的文件头所占用的第一个磁带块,之后读取文件头占用的第一个磁带块中的数据计算文件头字节总数,进一步确定文件头所占用的磁带块的数量。在确定文件头所占用的磁带块的基础上,再通过预设条件确定下一个文件的文件头所占用的第一个磁带块,当前文件的文件头占用的最后一个磁带块后的第一个磁带块到下一个文件的文件头所占用的第一个磁带块之间的磁带块即为当前文件中地震道数据占用的磁带块。这样一来,在得到新的磁带seg-d地震数据之后,通过上述过程,就可以具体根据该磁带seg-d地震数据中包括的内容进行分析,得到正确的文件头、地震道头和道数据所占用的磁带块,也就可以区分磁带中不同的文件,从而减少了不能解析磁带问题的发生,提高了解编装置的通用性。
本申请实施例还提供一种计算机设备,该计算机设备包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,该处理器执行计算机程序时实现磁带seg-d地震数据结构分析方法。
本申请还提供一种计算机可读存储介质,计算机可读存储介质存储有执行磁带seg-d地震数据结构分析方法的计算机程序。
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
以上所述的具体实施例,对本申请的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本申请的具体实施例而已,并不用于限定本申请的保护范围,凡在本申请的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本申请的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!