一种考虑多元因素态势演变的配变迁移学习故障诊断方法与流程
本发明属于配电变压器故障诊断领域,更具体地,一种考虑多元因素态势演变的配变迁移学习故障诊断方法。
背景技术:
在配网中,配电变压器(配变)数量庞大,保证其安全性是电网稳定可靠运行的基础,对其状态的精确感知、故障的准确诊断、风险的及时排查,在保障供电可靠性、实现风险预警、降低事故发生概率等方面意义重大。
近年来,随着大数据、数据挖掘等技术的迅速发展,其在变压器故障诊断方面得到了广泛的应用。研究主要集中在故障特征量的智能化提取、故障类型与影响因素之间的关联性挖掘、故障诊断的高精度算法设计、故障类型的高效快速检出、非结构化数据在故障诊断中的应用等方面。该类研究的故障诊断对象主要是输电变压器(指110kv及以上的主变,下文简称输变),在实际中,输变与配变在运行工况、监测手段、诊断周期等方面均存在较大差异。输变通常不会过载运行,运行工况良好,所以一般不考虑外界环境对其故障的影响,且由于造价昂贵、更换周期长,对其内部状态量的监测一般是全方位的、用于故障诊断的数据量是丰富的;而配变数量庞大,质量参差不齐,更新换代快,数据监测量不全面,天气和负载率等运行工况对配变健康水平均会造成较大影响。通过上述分析,输变与配变的故障诱因存在差异,监测状态量有所不同,数据丰富度区别明显,不能将输变的故障诊断方法简单移植到配变。
技术实现要素:
针对现有技术的以上缺陷或改进需求,本发明旨在提供一种考虑多元因素态势演变的配变迁移学习故障诊断方法,针对配变单体故障数据少的问题,解决配变故障诊断问题。
为了达到上述目的,本发明公开了一种考虑多元因素态势演变的配变迁移学习故障诊断方法,包括如下步骤:
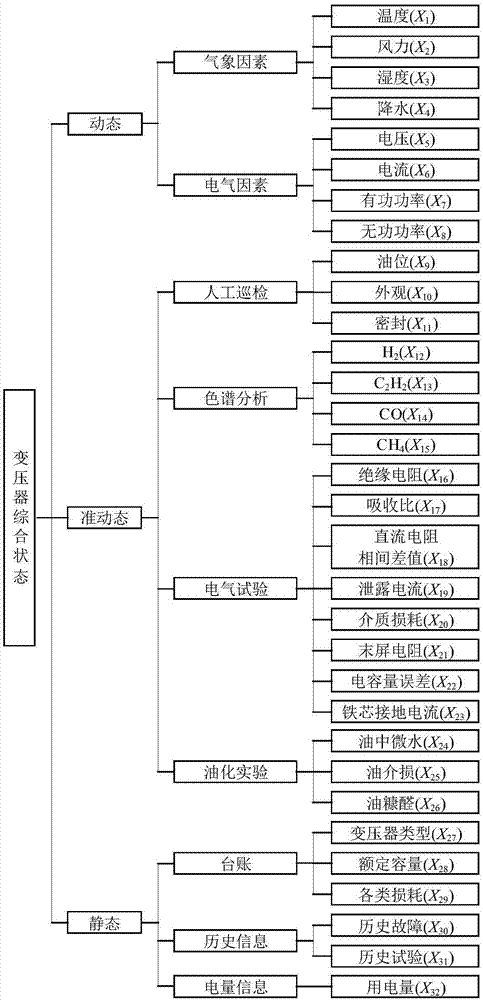
1)对影响配变运行状态的指标状态量分为动态指标状态量、准动态指标状态量及静态指标状态量,在此基础上构建配变运行状态评价指标体系;
2)对状态评价指标体系中的指标状态量进行二元量化,利用apriori算法计算这些指标状态量与配变故障之间的关联关系,对于关联关系较强的指标状态量,将其视为诱导配变故障的关键指标状态量;
3)获取需要进行故障诊断的目标配变和拥有故障记录的历史配变在各类故障下的关键指标状态量数据,利用tanimoto系数计算目标配变和历史配变的关键指标状态量数据的相似度,选择相似度较高的历史配变作为辅助配变;
4)利用迁移学习算法tradaboost对目标配变的关键指标状态量数据和辅助配变的关键指标状态量数据的权重进行求解,进而得到配变故障诊断模型,用以进行目标配变的故障诊断。
进一步的,所述步骤1)中动态指标状态量、准动态指标状态量及静态指标状态量分别为:
a.动态指标状态量指可以实时采集的数据,如气象数据、电气采集数据。该类指标状态量更新周期较短,一般15min或1h就可以更新一次,因此实时性较好;此外,该类指标状态量可有效反应配变状态的动态变化,是配变故障诊断的重要评估源;
b.准动态指标状态量指通过定期或不定期获取的数据,如变压器的试验及巡检数据。该类指标状态量的采集周期远高于动态状态量,因此数量较少;同时,由于配变的体量庞大、更换周期短,因此全方位的获取该类指标状态量难度较大。准动态指标状态量是评估配变局部缺陷的主要参照依据;
c.静态指标状态量指不需要通过系统交互获得的信息,如台账信息、历史用电量。该类指标状态量一旦记录在案便不再修改,是反应配变状态时间累积效应的数据来源。
进一步的,所述步骤2)中对状态评价指标体系中的指标状态量进行二元量化方法为:
b.设定配变的指标状态量属性集合
p={p1,p2,...,pm}(1)
其中,p表示配变的指标状态量属性及故障集合,其元素包括影响配变运行状态的动态指标状态量、准动态指标状态量及静态指标状态量;p1,p2,...,pm表示指标状态量属性集合p中的元素,表示动态指标状态量中的某个指标状态量,或表示准动态指标状态量中的某个指标状态量,或表示静态指标状态量中的某个指标状态量;m表示指标状态量个数;
b.选取某台配变i,设定其故障事务库为
di={d1,d2,...,dn}(2)
其中,di表示配变i故障事务库,其元素包括配变i的故障记录;d1,d2,...,dn表示配变故障事务库di中的元素,表示配变i的某条故障记录,每条故障记录中的元素对应p中各元素的值以及故障类型;n表示配变i的故障记录条数;
c.对配变的指标状态量属性及故障集合p中的元素按照优劣分为“好”和“坏”,对di中的任意一条故障记录,若该记录中某指标状态量为“好”,则记为1,若该记录中某指标状态量为“坏”,则记为0。
进一步的,所述步骤2)中利用apriori算法计算这些指标状态量与配变故障之间的关联关系,对于关联关系较强的指标状态量,将其视为诱导配变故障的关键指标状态量的方法为:
a.对于di中的任意一条故障记录,设定其配变的指标状态量属性为关联规则挖掘中的前件x,其故障为关联规则挖掘中的后件y,若故障记录中的某指标状态量为1,则认为该指标状态量与该条故障记录的故障类型存在关联,若故障记录中的某指标状态量为0,则认为该指标状态量与该条故障记录的故障类型不存在关联,选取合适的支持度阈值,提取支持度大于支持度阈值的关联规则
其中,关联规则x→y的支持度计算公式为
其中,s(x→y)表示关联规则x→y的支持度;σ(x→y)表示关联规则x→y的支持度计数;n表示配变i的故障记录条数;
b.选取合适的置信度阈值,提取置信度大于置信度阈值的关联规则,关联规则x→y的置信度计算公式为
其中,c(x→y)表示关联规则x→y的置信度;σ(x→y)表示关联规则x→y的支持度计数;σ(x)表示关联规则中前件x的支持度计数。
c.选取同时满足支持度大于支持度阈值、置信度大于置信度阈值的关联规则;
d.对配变i所有同时满足支持度大于支持度阈值、置信度大于置信度阈值的关联规则中的指标状态量取并集,构成配变i的关键指标状态量集合ii;
e.取ii的并集,构成诱导变压器故障的关键指标状态量i
其中,z表示变压器台数;ii表示从第i台配变提取出的关键指标状态量集合;i表示用于配变故障诊断的指标指标状态量集合。
进一步的,所述步骤3)中利用tanimoto系数计算目标配变和历史配变的关键指标状态量数据的相似度,选择相似度较高的历史配变作为辅助配变的方法为:
a.定义目标配变和历史配变的故障分布比例如下:
式中,r表示故障类型数;
b.设定目标配变和历史配变的关键指标状态量集合为
式中,
c.对
式中,
d.引入tanimoto系数,得到目标配变和历史配变故障r的相似度:
式中,
e.结合故障分布比例,得到目标配变和历史配变所有故障的综合相似度
式中,tr表示目标配变和历史配变所有故障的综合相似度。
f.定义迁移度阈值δ,对历史配变进行筛选,若tr≥δ,则将此历史配变视为辅助配变,其关键指标状态量数据将用于接下来的目标配变故障诊断;反之,若tr<δ,则抛弃此历史配变以及其所对应的关键指标状态量数据。
进一步的,所述步骤4)中利用迁移学习算法tradaboost对目标配变的关键指标状态量数据和辅助配变的关键指标状态量数据的权重进行求解,进而得到配变故障诊断模型,其具体步骤为:
a.设定目标配变的故障记录为ta,ta作为目标训练集合,设定辅助配变的故障记录为tb,tb作为辅助训练集合;
b.设定ta样本数量为m,tb样本数量为n,合并训练集t=ta∪tb,迭代次数iter,基本分类算法神经网络,其中
式中,x为配变关键指标状态量的标幺值,y为故障类型;
c.初始化权重向量
d.初始化参数
e.开始迭代,迭代t=1,2,...,iter
f.输出故障诊断模型,该模型的输出即为目标配变的故障诊断结果
进一步的,所述步骤e中迭代过程为:
a.权重归一化,令
b.调用神经网络算法,根据t、pt得到故障弱诊断器ht:x→y;
c.计算故障弱诊断器ht在ta上面的错误率:
式中,ht(xi)表示分类器对xi得到的学习标识;
d.设置故障弱诊断器权重参数αt以及目标权重调整参数βt
e.权重更新
本发明与现有技术相比,具有以下有益效果:
本发明所建立的配变迁移学习故障诊断模型通过迁移学习的方式将辅助配变的故障信息迁移至目标配变,较好地解决了配变单体故障数据少给配变故障诊断带来的难题。
附图说明
图1是本发明实施例的配变运行状态评价指标示意图;
图2是本发明实施例的配变准动态状态量与故障的关联规则图示意图;
图3是本发明实施例的辅助数据与诊断精度的关系图示意图;
图4是本发明实施例的迁移度阈值与诊断精度的关系图示意图;
图5是本发明实施例的不同数据量下m1的诊断精确度示意图;
图6是本发明实施例的迭代次数对m1诊断精确度的影响示意图;
图7是本发明考虑多元因素态势演变的配变迁移学习故障诊断方法的流程图。
具体实施方式
下面结合本发明中的附图和具体实施例,对本发明中的技术方案进行清楚、完整地描述。
如图7所示,本发明提供一种考虑多元因素态势演变的配变迁移学习故障诊断方法,包括以下步骤:
1)对影响配变运行状态的指标状态量分为动态指标状态量、准动态指标状态量及静态指标状态量,在此基础上构建配变运行状态评价指标体系;
2)对状态评价指标体系中的指标状态量进行二元量化,利用apriori算法计算这些指标状态量与配变故障之间的关联关系,对于关联关系较强的指标状态量,将其视为诱导配变故障的关键指标状态量;
3)获取需要进行故障诊断的目标配变和拥有故障记录的历史配变在各类故障下的关键指标状态量数据,利用tanimoto系数计算目标配变和历史配变的关键指标状态量数据的相似度,选择相似度较高的历史配变作为辅助配变;
4)利用迁移学习算法tradaboost对目标配变的关键指标状态量数据和辅助配变的关键指标状态量数据的权重进行求解,进而得到配变故障诊断模型,用以进行目标配变的故障诊断
具体的,所述步骤1)中动态状态量、准动态状态量及静态状态量分别为:
a.动态状态量指可以实时采集的数据,如气象数据、电气采集数据。该类状态量更新周期较短,一般15min或1h就可以更新一次,因此实时性较好;此外,该类状态量可有效反应配变状态的动态变化,是配变故障诊断的重要评估源;
b.准动态状态量指通过定期或不定期获取的数据,如变压器的试验及巡检数据。该类状态量的采集周期远高于动态状态量,因此数量较少;同时,由于配变的体量庞大、更换周期短,因此全方位的获取该类状态量难度较大。准动态状态量是评估配变局部缺陷的主要参照依据;
c.静态状态量指不需要通过系统交互获得的信息,如台账信息、历史用电量。该类状态量一旦记录在案便不再修改,是反应配变状态时间累积效应的数据来源。
具体地,在本实施例中,配变运行状态评价指标体系如图1所示。
具体的,所述步骤2)中对指标状态量进行二元量化方法为:
c.设定配变的状态量属性集合
p={p1,p2,...,pm}(1)
其中,p表示配变的状态量属性及故障集合,其元素包括影响配变运行状态的动态状态量、准动态状态量及静态状态量;p1,p2,...,pm表示状态量属性集合p中的元素,表示动态状态量中的某个状态量,或表示准动态状态量中的某个状态量,或表示静态状态量中的某个状态量;m表示状态量个数;
b.选取某台配变i,设定其故障事务库为
di={d1,d2,...,dn}(2)
其中,di表示配变i故障事务库,其元素包括配变i的故障记录;d1,d2,...,dn表示配变故障事务库di中的元素,表示配变i的某条故障记录,每条故障记录中的元素对应p中各元素的值以及故障类型;n表示配变i的故障记录条数;
c.对配变的状态量属性及故障集合p中的元素按照优劣分为“好”和“坏”,对di中的任意一条故障记录,若该记录中某状态量为“好”,则记为1,若该记录中某状态量为“坏”,则记为0。
为清晰表示p与di之间的关系,绘制两者之间的关系如表1所示:
表1p与di之间的关系
具体的,所述步骤2)中利用apriori算法挖掘其与故障之间的关联关系,提取诱导变压器故障的关键状态量的方法为:
a.对于di中的任意一条故障记录,设定其配变的状态量属性为关联规则挖掘中的前件x,其故障为关联规则挖掘中的后件y,若故障记录中的某状态量为1,则认为该状态量与该条故障记录的故障类型存在关联,若故障记录中的某状态量为0,则认为该状态量与该条故障记录的故障类型不存在关联,选取合适的支持度阈值,提取支持度大于支持度阈值的关联规则
其中,关联规则x→y的支持度计算公式为
其中,s(x→y)表示关联规则x→y的支持度;σ(x→y)表示关联规则x→y的支持度计数;n表示配变i的故障记录条数;
为通俗表述该步骤,以di中的某几条故障数据为例,说明提取支持度大于支持度阈值的关联规则的方法:
假设
p1p2p3p4p5...故障类型
d1={1,0,1,1,0,...,y1}
d2={1,1,0,1,0,...,y1}
d3={0,0,1,1,1,...,y2}
......
即第1条故障数据和第2条故障数据均为y1故障,第3条故障数据为y2故障,
假设配变i的故障记录条数n=10,支持度阈值为0.18,则在配变i为y1故障时,
p1为1出现了2次,σ(p1→y1)=2,s(p1→y1)=2/10=0.2,大于支持度阈值0.18,
p4为1出现了2次,σ(p4→y1)=2,s(p4→y1)=2/10=0.2,大于支持度阈值0.18,
p1和p4同时为1出现了2次,σ(p1,p4→y1)=2,s(p1,p4→y1)=2/10=0.2,大于支持度阈值0.18,
因此,支持度大于支持度阈值的关联规则有:
p1→y1,p4→y1,p1,p4→y1
b.选取合适的置信度阈值,提取置信度大于置信度阈值的关联规则,关联规则x→y的置信度计算公式为
其中,c(x→y)表示关联规则x→y的置信度;σ(x→y)表示关联规则x→y的支持度计数;σ(x)表示关联规则中前件x的支持度计数。
为通俗表述步骤(2.6),以di中的某几条故障数据为例,说明提取置信度大于置信度阈值的关联规则的方法:
假设
p1p2p3p4p5...故障类型
d1={1,0,1,1,0,...,y1}
d2={1,1,0,1,0,...,y1}
d3={0,0,1,1,1,...,y2}
......
即第1条故障数据和第2条故障数据均为y1故障,第3条故障数据为y2故障,
假设置信度阈值为0.8,易知,
σ(p1)=2,c(p1→y1)=2/2=1,大于置信度阈值0.8,
σ(p4)=3,c(p4→y1)=2/3=0.67,小于置信度阈值0.8,
σ(p1,p4)=2,c(p1,p4→y1)=2/2=1,大于置信度阈值0.8,
因此,置信度大于置信度阈值的关联规则有:
p1→y1,p1,p4→y1
c.选取同时满足支持度大于支持度阈值、置信度大于置信度阈值的关联规则;
d.对配变i所有同时满足支持度大于支持度阈值、置信度大于置信度阈值的关联规则中的状态量取并集,构成配变i的关键状态量集合ii;
e.取ii的并集,构成诱导变压器故障的关键状态量i
其中,z表示变压器台数;ii表示从第i台配变提取出的关键状态量集合;i表示用于配变故障诊断的指标状态量集合。
具体地,在本实施例中,支持度阈值设置为0.1,置信度阈值设置为0.6,准动态状态量与故障类型的关联规则如图2所示。图中,横坐标表示配变的准动态量,纵坐标表示配变的故障类型,垂直坐标表示置信度水平,圆柱体的高度表示关联规则的置信度,圆柱体上的数字表示关联规则的支持度。图中灰色平面表示置信度阈值,只有圆柱被该平面切割,该关联规则才能视为强关联,所对应的状态量才能被视为影响变压器故障的关键状态量。通过筛选,在本实施例中,除风力、降水、吸收比、额定容量以及各类损耗,其余状态量与配变故障均有较强的关联关系,在配变的故障诊断中需要考虑这些关键状态量的影响。
具体的,所述步骤3)中引入tanimoto系数,将有效的辅助故障数据迁移至目标配变的方法为:
a.定义目标配变和辅助配变的故障分布比例如下:
式中,r表示故障类型数;
b.设定状态量集合为
式中,
c.对
式中,
d.引入tanimoto系数,得到目标配变和辅助配变故障r的相似度:
式中,
e.结合故障分布比例,得到目标配变和辅助配变所有故障的综合相似度
式中,tr表示目标配变和辅助配变所有故障的综合相似度。
f.定义迁移度阈值δ,对辅助配变进行筛选,若tr≥δ,则将此辅助配变的故障数据作为待迁移的信息;反之,若tr<δ,则抛弃此辅助配变的故障数据。
具体地,在本实施例中,迁移度阈值δ选为0.6,选取一台配变作为待诊断的目标配变,对目标配变和其他14台配变的故障数据进行综合相似度检验。经检验,8台配变的故障数据与目标配变相似度较高,将其作为辅助配变,编号依次为f1-f8,其余6台配变依次编号为s1-s6。
具体的,所述步骤4)中利用迁移学习算法tradaboost对目标故障数据与辅助故障数据的权重进行迭代求解,得到配变故障诊断器的方法为:
a.设定目标配变的故障记录为ta,ta作为目标训练集合,设定辅助配变通过相似度检验后的故障记录为tb,tb作为辅助训练集合;
b.设定ta样本数量为m,tb样本数量为n,合并训练集t=ta∪tb,迭代次数iter,基本分类算法神经网络,其中
式中,x为配变关键状态量的标幺值,y为故障类型;
c.初始化权重向量
d.初始化参数
e.开始迭代,迭代t=1,2,...,iter
f.输出故障强诊断器
具体地,在本实施例中,为说明本发明中的诊断器(记为m1)的精确性,将其与仅通过目标配变数据训练的故障分类诊断器(记为m1_0)进行对比。在得到诊断器后,采用目标配变状态量作为诊断器的输入,计算诊断结果。两种诊断器的诊断对比如表2所示。从表中可以看出,m1在各种故障类型的诊断结果精度均较高,稳定性也较高;而m1_0仅在过热故障及放电故障诊断中较为精确,而对其他类型故障的诊断精度均较低。这是由于目标配变的故障数据量太少,仅用其训练的故障诊断器m1_0泛化能力较弱,难以根据新的输入状态量得到正确的故障分类结果,甚至将训练数据作为故障诊断器的输入,也很难得到满意的计算结果;而m1借助了其他配变的故障信息,利用综合相似度进行了故障信息的一次筛选,并通过迁移学习进行了不断对故障信息的权重进行迭代,有效信息利用率较高。
表2m1与m1_0的诊断对比
为验证辅助故障数据量对m1故障诊断精度的影响,将不同数量的辅助配变故障信息作为辅助数据参与到目标配变的故障诊断器训练中,图3显示了诊断对比情况。从图中可以看出,若将辅助配变在f1-f8中选取,则随着辅助配变的增加,各种类型故障的诊断精确度在整体上均呈现增加的趋势;而若将s1-s6的故障数据作为辅助数据,则诊断精度会有所下降,诊断的泛化能力有所减弱。这说明配变的故障诊断不仅与辅助数据的数量有关,同样决定于辅助数据与目标数据的相似程度,进一步验证了在配变迁移学习故障诊断器训练之前,通过综合相似度对数据进行筛选的必要性。
通过以上分析可以看出,配变故障诊断精度与辅助数据的选择有着密切的关系,高质量、多数量的辅助数据有利于提高诊断的精度。在辅助数据的选取中,需要定义迁移度阈值δ,取综合相似度大于迁移度阈值的数据作为辅助数据,因此,选择不同的δ对辅助数据进行选取,研究不同δ下的故障诊断器精度,计算结果如图4所示。
为分析目标数据量与辅助数据量对配变故障诊断模型的影响,选取了不同数据量和比值的故障数据对m1进行训练,故障诊断的精度如图5所示。从图中可以看出,目标数据与辅助数据数量比值为1时,m1的诊断精度最差;当比值小于1时,m1的诊断精度随着比值的增大而迅速减小,这是由于随着辅助数据的减少,配变故障诊断器的泛化能力不断减弱,导致诊断器的精度越来越差;当比值大于1时,辅助数据的减少反而会有助于提高诊断精度,但幅度不大,这是由于辅助数据与目标数据之间存在差异性,当辅助数据数量较少时,辅助数据的影响被削弱,故障诊断器的精度会有所提高,但是一般而言,辅助数据的数量一般比目标数据多,所以这种情形具有理论研究意义,对实践的指导意义不大。同时,当辅助数据数量一定时,目标数据数量越多,诊断精度越高,这是由于当目标数据数量较多时,其受辅助数据的影响越少,鲁棒性越强,诊断精度会有所提高。
本发明所提方法通过不断调整目标数据和辅助数据的权重不断对配变故障诊断模型进行修正,下面研究迭代次数对m1故障诊断精度的影响。本算例中,m1目标数据均取30组,而辅助数据取50组、80组、110组、140组,计算不同迭代次数下的故障诊断精度,如图6所示。从图中可以看出,在迭代初期,各种数量辅助数据下的诊断器收敛速度相差不大;而随着迭代次数的增加,辅助数据少的诊断器首先收敛,能达到的诊断精度较低,辅助数据多的诊断器收敛较慢,但能达到更好的诊断精度。
本发明在进行故障诊断之前,首先利用模糊apriori算法对诱导配变故障的关键状态量进行挖掘,有必要验证关键状态量挖掘的必要性,计算结果如表3所示,算例中,m1目标数据均取30组,而辅助数据分别取80组、110组、140组。
表3关键状态量挖掘对诊断精度的影响
具体的,所述迭代过程为:
a.权重归一化,令
b.调用神经网络算法,根据t、pt得到故障弱诊断器ht:x→y;
c.计算故障弱诊断器ht在ta上面的错误率:
式中,ht(xi)表示分类器对xi得到的学习标识;
d.设置故障弱诊断器权重参数αt以及目标权重调整参数βt
e.权重更新
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!