一种基于干涉条纹和深度学习的水面水下分类目标的方法与流程
本发明属于水声工程、海洋工程技术等领域,涉及一种基于干涉条纹和深度学习的水面水下分类目标的方法。一种基于干涉条纹图像和深度神经网络dbn与cnn的分类方法来分类水面和水下目标,适用于目标深度在20m以上的水面目标和20m以下的水下目标。
背景技术:
在图像识别领域,水面和水下目标的分类一直是一个亟待解决的问题。传统的方法都是先利用波束形成和doa(beamforminganddirectionofarrival)估计等信号处理方法来估计源深度,再根据估计得到的目标深度来分类水面与水下目标。尽管通过这种方法可以描述每个目标的物理特性,如方位和深度,但是需要人为地对每一个目标信号进行单独处理,针对不同目标要进行参数调整和优化,不具有普遍适应能力。而且为了实现水面和水下目标分类的目的,传统的方法无法同时进行大量的数据处理,不具有自主分类的能力。此外,由于水下目标的数据样本少且精确度不高,很难被应用于深度学习或学习到的特征不够全面,因此目前基于水面和水下目标分类的深度学习方法很难有较高的准确度和普遍适应性。
目前采用深度学习进行目标分类的方法都是基于合成孔径雷达sar(syntheticapertureradar)的水面舰船分类,最新提出的方法是利用高精度的sar图像和卷积神经网络cnn(convolutionalneuralnetwork)实现小数据集的船只分类,该方法参见“shipclassificationinhigh-resolutionsarimagesusingdeeplearningofsmalldatasets”,该文2018年9月发表于《sensors》第18(9)期,起始页码2929。虽然可以分类水面目标,但是sar图像只能观测到水面舰艇的活动,无法检测到水下运动目标,因此无法同时分类水面与水下目标。声场干涉条纹图像可用于目标声源的深度定位,定位方法参见“acoustic-intensitystriationsbelowthecriticaldepth:interpretationandmodeling”,该文2017年发表于《journaloftheacousticalsocietyofamerica》第142(3)期,页码245-250。在已知声速剖面ssp(soundspeedprofile)的条件下,可以通过仿真得到大量的声场干涉条纹图像,目前还没有将声场干涉条纹图像应用于水面和水下目标分类的报道。
技术实现要素:
要解决的技术问题
为了避免现有技术的不足之处,本发明提出一种基于干涉条纹和深度学习的水面水下分类目标的方法。
技术方案
一种基于干涉条纹和深度学习的水面水下分类目标的方法,其特征在于步骤如下:
步骤1:获取某海域的温度t、深度h、盐度s与静水压力p;根据声速经验公式计算得到对应深度下的声速:
ch=1449.2+4.6t-0.055t2+0.00029t3+(1.34-0.01t)(s-35)+0.0168p
其中:h为深度,ch为对应深度h下的声速,t为温度,s为盐度,p为标准大气压下的静水压力;
绘制声速剖面ssp:在海平面~混合层最大深度的范围内每隔2m计算一个声速值,混合层最大深度~声道轴深度的范围内每隔20m计算一个声速值,声道轴深度~声源深度的范围内每隔100m计算一个声速值,声源深度~海底深度的范围内每隔1000m计算一个声速值;
步骤2:利用高斯射线声学模型bellhop和已知的ssp仿真得到声场干涉条纹图像集合;所述条纹图像包括不同声源深度和不同距离条件下的无干扰的完整图像,模糊图像和有随机深度误差的图像;
步骤3、利用声场干涉条纹图像训练cnn网络:cnn的输入图像为灰度图,图像大小为256*256;cnn网络模型设计包括五个卷积层conv,五个整流线性单元relu,四个池化层pool和输出层,输出层包括全连接层fc和softmax层;cnn中每层卷积层由若干卷积神经单元组成,每个神经单元的参数都是通过反向传播算法优化得到;
每一层卷积层的计算公式如下:
其中m*n是内核的大小,w(u,v)是位置为(u,v)的内核的权重,xi,j是卷积层的输入,yi,j是卷积运算的输出,i,j对应于卷积核的位置;
采用最大池化操作:
每层整流线性单元relu的输出y的定义如下:
y=max(0,yi,j)
将上一池化层输出的所有二维的图像特征平铺为全连接的一维向量,之后将其输入到softmax层,softmax的计算公式如下:
t代表是分类的数目,t=2,i,j是目标类别,输出yi是该样本属于各个类别的标签,
每个conv层的内核大小设为3,内核的步幅设为1,除了第一个conv层的补零为10之外,其余的conv层的补零全部设为1,各个conv层的隐藏神经元数量分别设为64,64,128,256和512;各个pool层的步幅和内核大小都设为2,隐藏神经元的数量分别为64,128,256和512;完全连接层的隐藏神经元数量为4096,softmax层的神经元数量为2,输出值仅包含“0”和“1”,即softmax层输出二进制分类标签:当声源深度≤20m时,输出为[0,1];相反,如果声源深度>20m,则输出[1,0]
cnn训练的成功率设置为94%,当测试结果>94%时,表示cnn已经训练完成;
步骤4、利用声场干涉条纹图像训练dbn网络:dbn网络模型设计包括6层:四层堆叠的限制玻尔兹曼机rbm和反向传播神经网络bp层;dbn训练的成功率设置为90%,当测试结果>90%时,表示dbn已经训练完成;
步骤5:输入的水声信号经过波束形成处理后输入到dbn,将训练好的dbn作为训练好的cnn的前端处理模块,而判决模块作为cnn的后端输出模块;
步骤6:当cnn的输出标签为[0,1]标签时,判断为水面目标;输出[1,0]时,判断为水下目标。
所述声速值ch的精度应保留到小数点后四位。
所述步骤2仿真图像时,设定接收深度接近海底,目标声源深度范围设定为1~500m,每隔1m取一个声源深度,距离设定为5~30km,每隔100m取一个距离,声源频率为宽带信号,频带为50-500hz,每隔1hz取一个频点;对于各个深度上的目标,利用bellhop模型计算该深度声源的每个频率点的传播损失tl,将所有频点的tl曲线拼接在一起,从而获得当前深度下无干扰且完整的干涉条纹图像。
所述步骤2对于设定好的声源深度,模糊图像的仿真是在频带50-500hz内,分别每隔2hz,3hz,4hz,5hz,6hz,7hz,8hz,9hz,10hz取一个频点的tl,再将射线声学模型计算得到的所有tl拼接,得到9种具有不同模糊程度的干涉条纹图像。
所述步骤2仿真有随机深度误差的图像时,对于设定好的声源深度,随机误差范围设定为此声源深度的±10%,在该误差范围内产生450个随机数,对应于每个频点的声源深度,将bellhop模型计算得到的所有频点的tl拼接起来,得到有随机深度误差的图像。
有益效果
本发明提出的一种基于干涉条纹和深度学习的水面水下分类目标的方法,先利用高斯射线声学模型仿真得到大量的声场干涉条纹图像,包括清晰图像、模糊图像和有随机深度误差的图像,作为深度置信网络dbn(deepbeliefnetwork)和cnn的训练集进行,再将训练好的dbn作为cnn的前端处理模块,同时添加波束形成用于构成系统的预处理模块,最后将经过预处理的图像输入dbn,实现自主地对输入的条纹图像进行分类。该方法通过仿真大量的声场干涉条纹图像,解决了深度学习中训练集样本过小的问题;设计dbn模型优化了实际输入图像中的模糊和条纹偏移问题;设计cnn实现了自主地分类水面和水下目标。
有益效果是:步骤一和步骤二利用已知的ssp和bellhop模型,对不同深度下的声源对应的声场干涉图像进行了仿真,得到了大量的仿真图像,解决了深度学习中面临的水声训练数据少,仿真目标的模型建模困难的问题;步骤三中该方法设计了用于分类水下与水面目标的cnn网络模型,利用仿真数据训练得到的损失率仅为6.42%,采用106个实验数据验证发现成功率高达88.68%;在步骤四中该方法设计了用于优化干涉条纹图像的dbn网络模型,采用106个实验数据验证发现未添加dbn模块的cnn的成功率仅达82.08%,少了6.6%,说明dbn很好的提高了目标分类准确率。该方法可以自动进行水面与水下目标分类,且经实验数据验证具有高达88.68%的准确率。
附图说明
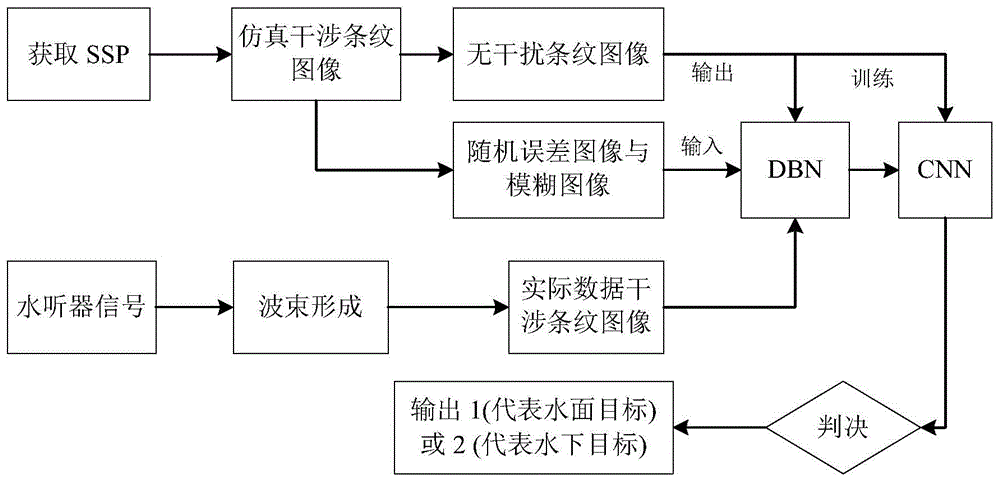
图1是本发明方法提出的基于深度学习的水面水下分类流程示意图。
图2是中国南海某海域测得的ssp。
图3是仿真得到的声源深度分别为5、11、20、50、150、300m时的频率-距离相关的声场干涉条纹图
图4是cnn网络模型。
图5是dbn网络模型。
图6dbn测试气枪数据的输入与输出结果对比
(a)输入气枪目标的干涉条纹图像(b)输出dbn优化后的干涉条纹图像
图7是cnn的损失率与实验数据测试的成功率。
具体实施方式
现结合实施例、附图对本发明作进一步描述:
本发明提出利用高斯射线声学模型bellhop和已知的ssp仿真得到几千张声源深度不同的声场干涉条纹图像,包括无干扰的完整图像,模糊图像和有随机深度误差的图像。然后将模糊图像和有随机深度误差的图像作为输入训练集,无干扰的完整图像作为输出训练集训练dbn;将所有的条纹图像作为输入训练集,图像的类别作为输出训练集训练cnn,dbn和cnn需要进行上千次的训练直至收敛。在dbn与cnn训练好之后,将dbn作为cnn的前端处理模块,同时添加波束形成作为预处理模块,最后添加判定模块输出水下和水面目标的类别,实现自主地分类水面和水下目标。其分类过程分为以下步骤:
步骤一获取某海域的ssp数据,采用投弃式温度剖面测量系统xbt(expendablebathythermograph),温盐深仪ctd(conductancetemperaturedepth)等设备探测海洋的温度、深度、盐度与静水压力,根据声速经验公式计算得到对应深度下的声速:
ch=1449.2+4.6t-0.055t2+0.00029t3+(1.34-0.01t)(s-35)+0.0168p(1)
其中,h为深度,ch为对应深度h下的声速,t为温度,s为盐度,p为标准大气压下的静水压力。
根据公式(1)计算得到各个深度下的声速ch。绘制声速剖面ssp时,在海平面-混合层最大深度的范围内每隔2m取一个声速值,混合层最大深度-声道轴深度的范围内每隔20m取一个声速值,声道轴深度-声源深度的范围内每隔100m取一个声速值,声源深度-海底深度的范围内每隔1000m取一个声速值,声速值ch的精度应保留到小数点后四位。
步骤二利用高斯射线声学模型bellhop和已知的ssp仿真得到大量的声场干涉条纹图像,这些条纹图像包括不同声源深度和不同距离条件下的无干扰的完整图像,模糊图像和有随机深度误差的图像。在确定的声场中,不同的声源深度和距离处干涉现象均不相同,表现在图像中就是干涉条纹的数量和形状均不相同。
仿真图像时,设定接收深度接近海底,目标声源深度范围设定为1-500m,每隔1m取一个声源深度,距离设定为5-30km,每隔100m取一个距离,声源频率为宽带信号,频带为50-500hz,每隔1hz取一个频点。对于各个深度上的目标,利用bellhop模型计算该深度声源的每个频率点的传播损失tl(transmissionloss),将所有频点的tl曲线拼接在一起,从而获得当前深度下无干扰且完整的干涉条纹图像。
相似的,对于设定好的声源深度,模糊图像的仿真是在频带50-500hz内,分别每隔2hz,3hz,4hz,5hz,6hz,7hz,8hz,9hz,10hz取一个频点的tl,再将射线声学模型计算得到的所有tl拼接,得到9种具有不同模糊程度的干涉条纹图像。
仿真有随机深度误差的图像时,对于设定好的声源深度,随机误差范围设定为此声源深度的±10%,在该误差范围内产生450个随机数,对应于每个频点的声源深度,将bellhop模型计算得到的所有频点的tl拼接起来,得到有随机深度误差的图像。
步骤三利用声场干涉条纹图像训练cnn网络,为了避免与实际目标干涉条纹的色差而导致分类出错,cnn的输入图像应为灰度图,图像大小为256*256。cnn网络模型设计包括五个卷积层conv(convolutionallayer),五个整流线性单元relu(rectifiedlinearunits),四个池化层pool(pollinglayer)和输出层,输出层包括全连接层fc(fully-connectedlayer)和softmax层。
cnn中每层卷积层由若干卷积神经单元组成,每个神经单元的参数都是通过反向传播算法优化得到的。卷积运算的目的是提取输入不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角度等特征,更多层的网络能从低级特征中迭代提取更复杂的特征。每一层卷积层的计算公式如下:
其中m*n是内核的大小,w(u,v)是位置为(u,v)的内核的权重,xi,j是卷积层的输入,yi,j是卷积运算的输出,i,j对应于卷积核的位置。
通常在卷积层之后会得到维度很大的特征,池化层的作用是将这些特征分割为几个区域,取其最大值或平均值,得到新的、维度较小的特征,也就是降采样。常用的池化层的计算有两种:最大池化(maxpooling)操作和均值池化(meanpooling)操作。由于本发明提出的分类方法是基于cnn的条带特征识别进行分类的,因此这里采用最大池化操作:
每层整流线性单元relu的输出y的定义如下:
y=max(0,yi,j)(4)
全连接层是把所有局部特征结合转化为全局特征,用来计算最后每一类的概率,需要将上一池化层输出的所有二维的图像特征平铺为全连接的一维向量,之后将其输入到softmax层,softmax的计算公式如下:
这里t代表是分类的数目,t=2,i,j是目标类别,输出yi是该样本属于各个类别的标签,
每个conv层的内核大小设为3,内核的步幅设为1,除了第一个conv层的补零(zero-padding)为10之外,其余的conv层的补零全部设为1,各个conv层的隐藏神经元数量分别设为64,64,128,256和512。类似地,各个pool层的步幅和内核大小都设为2,隐藏神经元的数量分别为64,128,256和512。完全连接层的隐藏神经元数量为4096,softmax层的神经元数量为2,输出值仅包含“0”和“1”,即softmax层输出二进制分类标签:当声源深度≤20m时,输出为[0,1];相反,如果声源深度>20m,则输出[1,0]。
cnn训练的成功率设置为94%,当测试结果>94%时,表示cnn已经训练完成。
步骤四利用声场干涉条纹图像训练dbn网络。dbn网络模型设计包括6层:四层堆叠的限制玻尔兹曼机rbm(restrictedboltzmannmachines)和反向传播神经网络bp(backpropagation)层。
rbm的能量函数e(v,h)定义如下:
这里,m和n是可见层神经元vj和隐藏层神经元hi的数量,i=1,2...n,j=1,2…m,aj,bi分别是它们对应的偏置,wij是可见神经元vj到隐藏神经元hi之间的连接权重。假设每层的序号是l=1,2…6,激活函数sigmoid函数定义为:
因此,各层的条件概率密度可以推导为:
这里条件概率密度分布即dbn的目标函数,它包含可见层vj,隐藏层hi,还有可见层与隐藏层间的连接权值wij,以及偏置aj,bi,相当于对能量函数e(v,h)求指数e,然后进行归一化的结果。训练过程就是反复对这个函数求它的最大似然对数。
每个rbm网络都有2层,其中第一层称为可视层,即输入层v,第二层是隐含层h,即特征提取层。dbn的可见层即第一个rbm1的输入层是v1,输入数据为大小为256*256的图像,输入层v1的隐藏神经元的数量是4096,除了v1,其他隐藏层的神经元数量均设置为512,bp神经网络的隐藏神经元数量是4096。在完成rbm1的训练之后,将隐藏层h1视为下一层rbm2的输入层v2,新的隐藏层h2添加在h1之后作为rbm2的隐藏层,依此类推,直到第四个rbm4训练完成,在隐藏层h4后添加bp作为全连接层,对整个dbn进行微调。bp的输出应再次重新整形为256*256大小的矩阵,并绘制成灰度图作为cnn的输入。
由于每一层rbm网络只能确保自身层内的权值对该层特征向量映射达到最优,而非对整个dbn网络的特征向量映射达到最优,因此bp网络负责将信息自顶向下传播至每一层rbm,微调整个dbn网络。
dbn训练的成功率设置为90%,当测试结果>90%时,表示dbn已经训练完成。
步骤五输入的水声信号经过波束形成处理后输入到dbn,将训练好的dbn作为训练好的cnn的前端处理模块,而判决模块作为cnn的后端输出模块
步骤六,判决模块用于识别cnn的输出标签,输出为[0,1]标签时,判断为水面目标;输出[1,0]时,判断为水下目标。最终实现自主的水下和水面目标识别。
图1是本发明方法提出的基于深度学习的水面水下分类流程示意图。如图所示,本发明方法的具体流程是事先采集目标所在海域的声速剖面ssp;再以该ssp与射线声学模型仿真大量的不同声源深度与不同距离上的干涉条纹图像;接着以这些干涉条纹图像为训练集训练dbn与cnn;之后将训练好的dbn作为训练好的cnn的前端处理模块,而判决模块作为cnn的后端模块,形成自动目标分类系统;最后把输入
的水声目标信号经过波束形成处理后输入到dbn,最终得到自主的水下和水面目标分类识别结果。
图2是本发明方法仿真得到的干涉条纹图像,如图所示,图中目标所处的深度分别为5,11,20,50,150和300m,距离全为5-30km,频率带宽均为50-500hz,且频率分辨率为1hz。
图3是中国南海某海域测得的ssp,此声速剖面是典型的深海声速剖面图,在深度为0-100m(混合层最大深度)的范围内每隔2m取一个声速值,100-1190m(声道轴对应的深度)的范围内每隔20m取一个声速值,1190-4500m(目标声源深度)的范围内每隔100m取一个声速值,4500-5500m(最大海深)的范围内每隔1000m取一个声速值,声速值精确到小数点后四位。
图4是本发明方法采用的cnn网络模型,图中各个卷积层用conv表示,池化层用pool表示,后跟各层的序号,冒号后的四个参数从左到右依次代表:隐藏神经元的个数,补零的个数,内核函数的大小以及内核移动的步幅。
图5是本发明方法采用的cnn网络模型,v表示可见层,h表示隐藏层,由于dbn是四层rbm堆叠而成,因此rbm1的隐藏层h1被视为下一层rbm2的可见层v2,rbm2的隐藏层h2则被视为rbm3的可见层v3,rbm3的隐藏层h3则被视为rbm3的可见层v4,而rbm4的隐藏层h4后添加bp神经网络作为最后一层。各层所跟的参数代表隐藏神经元的数量。
图6是本发明方法提出的dbn模型测试气枪数据的输入与输出结果对比,图(a)是输入气枪目标的干涉条纹图像,图(b)是输出dbn优化后的干涉条纹图像。输入数据是海上试验得到的气枪数据,该气枪的深度为11m为水面目标,接收距离为6-20km,由于目标辐射噪声信号是每隔1.9km采集一次,导致图6(a)中实际得到的干涉条纹较为模糊,但是经过dbn测试后,图6(b)可以得到更为清晰的带状干涉条纹图像,说明dbn可以起到优化条纹图像的作用。
图7是本发明方法提出的cnn模型采用仿真图像训练得到的损失率,与实验数据测试的成功率。仿真图像共6000张,包括无干扰的完整图像、模糊图像和有随机深度误差的图像,图中的红线显示损失率低至6.6%。用于测试的实验图像共106个,其声源信号的采集地点与图3中的ssp一致,结果显示添加了dbn模块的cnn可以成功识别94个图像的类别,成功率为88.68%,未添加dbn模块的cnn仅能对87个图像正确分类,成功率为82.08%,两者有6.4%的差距,说明dbn可以有效地提高分类成功率,对图像有优化作用。
本发明在典型实施例中取得了明显的实施效果,与现有技术相比其优越性在于利用深度学习的方法自动分类水面水下目标的声场干涉条纹图像,达到分类水面与水上目标的目的,实测数据验证表明该方法具有高达88.68%的成功率。
- 还没有人留言评论。精彩留言会获得点赞!