一种AI加速芯片性能测试方法及其装置与流程
本发明涉及芯片测试领域,尤其涉及一种ai加速芯片性能测试方法及其装置。
背景技术:
ai加速芯片内部一般包含:指令调度、卷积运算、池化、激活函数计算、数据载入载出这些模块。由于目前主流ai算法参数量巨大,数据需要在片内存储与片外存储器之间进行反复搬移。因而系统的计算带宽与数据带宽的匹配度是影响ai加速芯片性能的最主要因素。另外,ai网络模型的多样性也导致各个模块的运行效率有较高的不确定性。因此ai芯片的性能不但取决于这些指令模块的单独性能,还取决于数据载入载出、和其他指令模块的调度效率,有必要提出一种测试方法,对每个指令模块性能以及指令模块间的并行度进行分析,方便后续进行芯片性能改进。
由于芯片用途不同,现有性能测试方法关注的重点也不同,有些测试方法关注芯片在不同利用率下的性能表现,方便进行芯片选型;有些测试方法关注内部某个模块的运行性能,方便后续进行改进;有些关注芯片多个模块运行的并行度,在开发阶段对芯片的最终性能进行预测。现阶段主要有以下几种典型方法:
1)控制芯片利用率,获取不同利用率下芯片性能测试结果,取几何平均数。如申请号为201310161217.6的《cpu性能评估方法与装置》专利所示通过控制指令控制cpu的利用率;对中央处理器cpu进行基准测试,获得cpu在每个利用率下的性能测试结果,其中每个性能测试结果表示cpu在一种负载下的性能;计算多个性能测试结果的几何平均数以获cpu最终性能评估结果。该专利只能通过测试指令片段预估性能,无法精确测量内部各模块的运行时间以及内部不同模块并行度。该专利无法测试出造成性能瓶颈的模块。
2)芯片内部的不同模块设计旁路电路,旁路后可以测试待测模块的性能。如申请号为201910103596.0的《人工智能模块的单元性能测试方法和系统芯片》专利所示,针对排列成二维阵列的多个ai处理单元,每个处理单元包括使能输入端,用于接收使能信号,并且根据使能信号暂停或启动处理单元的操作;可以对多个处理单元中具有与待测试处理单元相同维度1和/或维度2的处理单元配置为旁路状态,以便实现对所述待测试处理单元进行性能测试;通过赋予处理单元以旁路功能,可以更为便利地对ai模块进行测试。该专利通过旁路针对待测模块做测试,无法预估芯片整体性能;无法在真实场景中,观察到不同模块间的并行度。
3)通过绘制芯片内部每个计算区块的运行时间,预估芯片的整体性能。如申请号为201510387995.6的《一种用于预测gpu性能的方法和相应的计算机系统》专利所示,在待评估的gpu芯片中运行一组测试应用程序;捕获一组标量性能计数器和向量性能计数器;基于所捕获的标量性能计数器和向量性能计数器针对不同芯片配置创建用于评估和预测gpu性能的模型;以及预测gpu芯片的性能分数并且识别gpu流水线中的瓶颈。该专利针对gpu的计算模块并行度建立性能模型,但一个芯片包含通信部份与计算部份,通信部份有时对整体性能影响较大。
技术实现要素:
本发明的目的在于提供一种ai加速芯片性能测试方法及其装置,不但提供计算部份的性能分析,也提供通信部份与计算部份的并行度分析。本发明可以根据设定条件搜索条件范围内的并行指令,分析指令并行度,从而为芯片性能优化提供更好支持。
本发明采用的技术方案是:
一种ai加速芯片性能测试方法,其包括以下步骤:
步骤1,开启全局测试,将测试指令分发至ai加速芯片的各个模块;
步骤2,分别采样获取各个模块运行的每条指令的开始时间和结束时间形成数据记录上传至外部的性能分析器;
步骤3,性能分析器将数据记录按模块整理为列表;
步骤4,利用脚本语言对列表进行计算获得每条指令的运行时长;
步骤5,分别累计每个模块的所有指令的运行时长获取每个模块运行总时长,用于统计最占操作时间的指令按模块统计指令运行总时长;
步骤6,利用脚本语言对列表进行计算获得各个模块内相邻指令的间隔;
步骤7,从列表查找需分析的指定范围内的并行指令运行结果;
步骤8,输出显示查找到的并行指令的运行结果。
进一步地,步骤1中ai加速芯片的各个模块包括具体计算模块负责数据搬运的通信模块。
进一步地,步骤2中ai加速芯片通过一定时器获取基准时间,并利用基准时间来记录指令的开始时间和结束时间。
进一步地,步骤2中的数据记录写入到易失性存储器,并在存储器容量到达水线或指令运行结束后上传至性能分析器。
进一步地,步骤2中的数据记录通过设在ai加速芯片上的通信接口直接上传至性能分析器。
进一步地,步骤4或6中的脚本语言为python语言。
进一步地,步骤7中列表查找包括三种模式,具体如下:
模式1:根据设定时间,查找时间范围内的并行指令;
模式2:根据指定的模块指令序列号,查找时间范围内的并行指令
模式3:搜索某个模块内指令间隔最长的指令索引,寻找时间范围内的并行指令;
进一步地,模式3的具体步骤为:
步骤7-1,通过对指定模块内的指令间隔排序,获取指令间隔最大的指令索引号;
步骤7-2,以该最大指令索引号往前q条指令对应的启动时间做为timemin;以及往后p条指令对应的启动时间作为timemax,q、p值的由用户设定;
步骤7-3,以timemin和timemax作为时间范围查找并行指令。
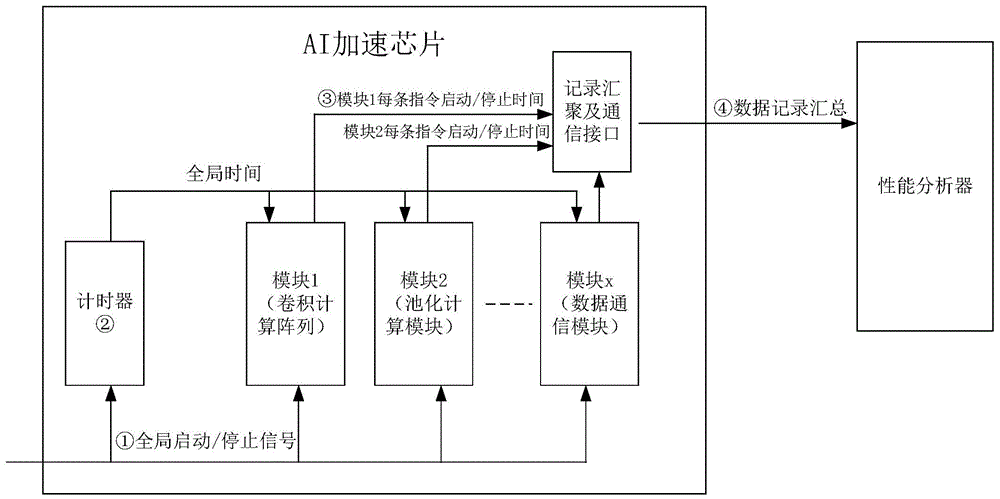
本发明还公开了一种ai加速芯片性能测试装置,其包括芯片内部数据记录生成电路和性能分析器,芯片内部数据记录生成电路包括测试控制电路、计时器和指令时间记录汇总及通信电路,测试控制电路分别连接定时器以及芯片内的各个模块,测试控制电路用于控制芯片开始或结束性能测试,计时器用于产生时间基准并提供给芯片内的各个模块,每个ai加速芯片的每个模块均设有时间采样电路,时间采样电路用于采用获取各自模块内每条指令的运行开始时间和结束时间;指令时间记录汇总及通信电路用于汇总生成的指令运行时间并上传给性能分析器。
进一步地,所述指令时间记录汇总及通信电路包括竞争判断及记录保持电路、内部ram存储器和通信接口,
竞争判断及记录保持电路按照公平轮转的原则将记录写入内部ram存储器,ai加速芯片模块个数为x时,则x个时钟周期把所有记录写入;
竞争判断及记录保持电路为一套,竞争判断及记录保持电路的每条指令的运行周期数大于ai加速芯片模块个数;或者采用多套轮转的竞争判断及记录保持电路,且竞争判断及记录保持电路的每条指令的运行周期数时于ai加速芯片模块个数,每一套竞争判断及记录保持电路轮转的周期小于指令运行周期;
内部ram存储器用于存储记录数据,并提供存储状态信息;
通信接口与性能分析器通信连接,在内部ram存储器的容量到达水线或指令运行结束后通过通信接口将记录上传至性能分析器;
性能分析器为pc机、平板、智能手机或云端服务器。
本发明采用以上技术方案,通过采样记录芯片内每个模块的各个指令的开始时间和结束时间形成数据记录;再将数据记录整理成列表,进而对列表进行相应的计算处理,以获取芯片各个模块的指令运行时长以及相关参数;此外还可从列表中查找获取指定模块或指定时间的并行指令,并文字打印或图行显示,以供并行分析。本发明不但提供计算部份的性能分析,也提供通信部份与计算部份的并行度分析。本发明可以根据设定条件搜索条件范围内的并行指令,分析指令并行度,从而为芯片性能优化提供更好支持。
附图说明
以下结合附图和具体实施方式对本发明做进一步详细说明;
图1为本发明的测试原理示意图;
图2为本发明的指令时间记录汇总及通信电路的原理示意图
图3为本发明的性能测试数据生成流程示意图;
图4为本发明性能分析器的分析流程示意图;
图5为本发明性能分析器整理的列表示意图;
图6为本发明的列表查找中模式1的原理示意图;
图7为本发明的列表查找中模式2的原理示意图;
图8为本发明的列表查找中模式3的原理示意图;
图9为本发明的指令运行总时长的结果示意图;
图10为本发明的设定时间范围内的并行指令的查找结果示意图;
图11为本发明的指定索引的指令对应时间范围内的并行指令的查找结果示意图。
具体实施方式
如图1-11之一所示,本发明公开了一种ai加速芯片性能测试装置,其包括芯片内部数据记录生成电路和性能分析器,芯片内部数据记录生成电路包括测试控制电路、计时器和指令时间记录汇总及通信电路,
测试控制电路分别连接定时器以及芯片内的各个模块,测试控制电路用于控制芯片开始或结束性能测试;计时器用于产生时间基准并提供给芯片内的各个模块;每个ai加速芯片的每个模块均设有时间采样电路,时间采样电路用于采用获取各自模块内每条指令的运行开始时间和结束时间,此外,ai加速芯片包括的模块可以是具体计算模块,也可以是负责数据搬运的通信模块,本发明不但可以测试计算模块,也可以测试通信模块;指令时间记录汇总及通信电路用于汇总采样的指令运行时间数据并上传给性能分析器。
具体地,如图2所示,指令时间记录汇总及通信电路包含一个竞争判断及记录保持电路,当多条记录同时到来时,按照公平轮转的原则将记录写入内部小容量ram存储器。模块个数为x时,x个时钟周期可以把所有记录写入,因此该电路有个适用条件,每条指令的运行周期数大于模块数。如果不满足该条件,就需要设计多套这样的电路,每一套轮转的模块小于指令运行周期。
内部小容量ram用于存储记录数据,并提供存储状态信息。写入的每一条记录包含,指令类型,该指令类型序列(第几条指令),该指令起止时间。
存储容量到达一定水线(保证ram不会溢出),或者全部指令运行结束时,启动通信接口,将记录上传至性能分析器,通信接口可以是芯片的带外接口,比如spi接口,千兆接口等。注意通信接口的传输带宽必须保证内部小容量ram不溢出。
具体的,作为一种实施方式,所述性能分析器为pc机、平板或者智能手机,具有如下功能:
a)针对上传的数据记录做数据分析。b)显示或打印每一条指令的运行时间。c)统计每一种类型指令的总运行时间。d)根据设定条件搜索条件范围内的并行运行指令,并显示。
进一步地,本发明还公开了一种ai加速芯片性能测试方法的具体步骤如下:
本发明的步骤1至2部分性能测试数据生成流程,具体如图3所示,
步骤1,接收指令运行启动信号,启动全局计时器,提供时间基准,开启全局测试,将测试指令分发至ai加速芯片的各个模块;进一步地,步骤1中ai加速芯片的各个模块包括具体计算模块负责数据搬运的通信模块。
步骤2,分别采样获取各个模块运行的每条指令的开始时间和结束时间形成数据记录上传至外部的性能分析器;
具体地,每条每条指令的开始时间和结束时间保存为一条记录;
进一步地,作为一种实施方式,步骤2中的数据记录写入到易失性存储器,并在存储器容量到达水线或指令运行结束后上传至性能分析器。进一步地,作为另一种实施方式,步骤2中的数据记录通过设在ai加速芯片上的通信接口直接上传至性能分析器,以减小内部存储器的使用
本发明的步骤3至8部分涉及性能分析器的分析流程,具体如图4所示,其中start(n)是指模块中第n条指令的起始时间;end(n)是指模块中第n条指令的结束时间。
步骤3,性能分析器将数据记录按模块整理为列表,将每个模块的指令时间记录整理成如图5所示的列表格式,方便后续分析处理,其中,start表示指令的启动时间,end表示指令的结束时间。
步骤4,利用脚本语言对列表进行计算获得每条指令的运行时长;
具体地,比如python语言,对上述列表进行计算,计算出每条指令的运行时长。公式为:
module_x_inst_cycle(n)=end(n)-start(n)1≤n≤index_max
其中,start(n):模块x中第n条指令的起始时间;end(n):模块x中第n条指令的结束时间;module_x_inst_cycle(n):第x模块的第n条指令的运行时长;index_max:指令最大编号。
步骤5,分别累计module_x_inst_cycle(n)每个模块的所有指令的运行时长获取每个模块运行总时长,用于统计最占操作时间的指令按模块统计指令运行总时长;
步骤6,利用脚本语言对列表进行计算获得各个模块内相邻指令的间隔;脚本语言为python语言,具体公式为:
module_x_gap_cycle(n)=start(n)-end(n-1)2≤n≤index_max
其中,module_x_gap_cycle(n):模块x中第n条指令与第(n-1)条指令的指令间隔。
步骤7,从列表查找需分析的指定范围内的并行指令运行结果;进一步地,步骤7中列表查找包括三种模式,具体如下:
模式1:根据设定时间,查找时间范围内的并行指令;具体的原理如图6所示,其中timemin和timemax是用户设定的显示时间范围。
模式2:根据指定的模块指令序列号,查找时间范围内的并行指令;具体的原理如图7所示,其中的timemin和timemax是用户设定的显示时间范围。
模式3:搜索某个模块内指令间隔最长的指令索引,寻找时间范围内的并行指令;
进一步地,如图8所示,模式3的具体步骤为:
步骤7-1,通过对指定模块内的指令间隔排序,获取指令间隔最大的指令索引号;
步骤7-2,以该最大指令索引号往前q条指令对应的启动时间做为timemin;以及往后p条指令对应的启动时间作为timemax,q、p值的由用户设定;
步骤7-3,以timemin和timemax作为时间范围查找并行指令。
步骤8,输出显示查找到的并行指令的运行结果。根据上述查找结果图行显示或文字打印指令并行运行结果。
下面以ai加速芯片的测试实例对本发明进行效果说明。
1)如图9所示,测试ai加速芯片的指令运行总时长的显示结果,其中,load指数据加载指令运行总时长,save指计算结果保存指令运行总时长,conv指卷积指令运行总时长,pooling指池化计算指令运行总时长。
2)如图10所示,进一步测试ai加速芯片的设定时间范围内的并行指令,显示结果如下:
timefrom1000to15000000instseqis:
loadinstseq:[2:7141]
saveinstseq:[0:1749]
convinstseq:[0:311]
miscinstseq:[0:271]。
3)如图11所示,进一步测试指定索引的指令对应时间范围内的并行指令(指定模块1指令索引1000~1200),显示结果如下:
timefrom2841401to3155305instseqis:
loadinstseq:[1000:1200]
saveinstseq:[536:639]
convinstseq:[74:81]
miscinstseq:[110:130]。
本发明采用以上技术方案,通过采样记录芯片内每个模块的各个指令的开始时间和结束时间形成数据记录;再将数据记录整理成列表,进而对列表进行相应的计算处理,以获取芯片各个模块的指令运行时长以及相关参数;此外还可从列表中查找获取指定模块或指定时间的并行指令,并文字打印或图行显示,以供并行分析。本发明不但提供计算部份的性能分析,也提供通信部份与计算部份的并行度分析。本发明可以根据设定条件搜索条件范围内的并行指令,分析指令并行度,从而为芯片性能优化提供更好支持。
- 还没有人留言评论。精彩留言会获得点赞!