基于激光雷达的果蝇视觉启发的三维运动目标检测方法与流程
本发明属于运动目标检测领域,具体涉及一种动态环境下基于激光雷达的果蝇视觉启发的三维运动目标检测方法,旨在利用仿生类脑算法实现场景中的三维运动目标检测。
背景技术:
动态场景理解是自动驾驶汽车的一项非常重要且极具挑战性的任务,其中运动目标检测是一项基本的子任务。当前深度神经网络的发展极大地促进了目标检测技术的进步,然而目标检测还不能够适应其动态场景的运行环境。因为静态的物体可以简单的建模为场景中的障碍物;而诸如运动的车辆、行人等运动的物体却不能简单的当作障碍物,它们会给无人车带来严重的威胁,直接影响路径规划和决策的结果。此外,运动目标检测对无人车的同时定位与建图技术(slam)也非常重要,现有的slam方法普遍将运动物体当作异常值,需要设计鲁棒的算法来削弱它们的影响。从另一个层面讲,运动物体蕴含丰富的隐藏信息,有助于交通态势的预测,尤其在拥挤交通环境,可以通过其他物体的运动信息预测未来的道路布局。
相比于二维检测,三维运动目标检测可以直接为无人车所用。立体相机和激光雷达是自动驾驶汽车的常见三维传感器。立体相机可以提供丰富的颜色、纹理和三维信息,但它们易受光照变化的干扰,不能提供高精度的三维信息。而激光雷达可以准确地获取场景的三维信息。因而本发明旨在提出一种简单有效的基于激光雷达的三维运动目标检测新型方法。
目前,运动目标检测方法大致可以分为两类:基于“检测-跟踪”的方法和基于“光流/场景流”的方法。
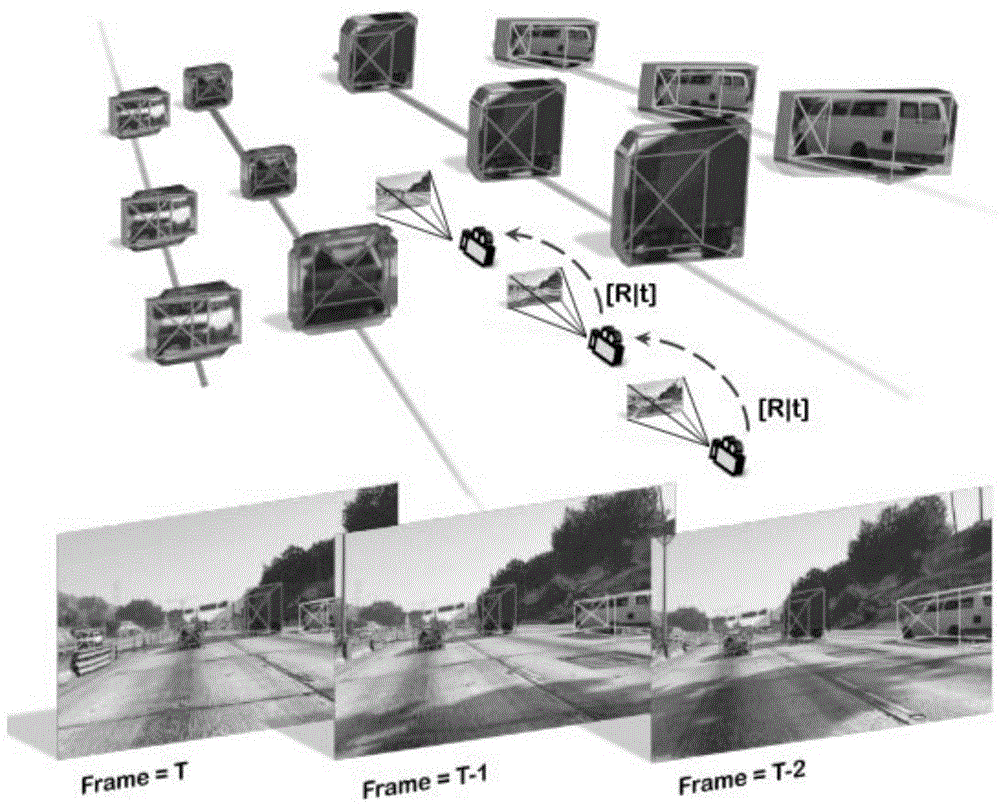
基于“检测-跟踪”的方法,首先检测出场景中的所有潜在运动目标,然后对它们进行跟踪,以判断是否运动,流程如图1所示。该方法将运动目标检测分解为“检测”和“跟踪”两个子任务,策略简单,容易部署使用。然而,这种多任务级联的结构也有弊端。目标检测过程中,如果存在场景中目标漏检情况,则直接会导致运动目标检测的失败;多目标跟踪又是计算机视觉中极具挑战性的工作,跟踪结果的稳定性差。只有当两个子任务都正确输出,才能确保运动目标检测的准确性。此外,多任务级联的策略无疑也增加了计算代价。
基于“光流/场景流”的方法,跳过了宏观层面的目标检测环节,直接计算每个像素或激光雷达点的运动,然后估计自身运动,最后计算出场景中的真实运动,流程如图2所示。该方法不需要对场景进行目标层面的语义理解,便可以自下而上地计算出场景中的运动信息,在一定程度上避免了“检测-跟踪”方法的缺点。但是光流/场景流计算量大,也容易受到光照、雨雾等天气条件的干扰,鲁棒性差,复杂的背景也会影响真实运动的检测。此外,该方法灵活性差,不能针对性的检测已知特定运动。
在自然界中,果蝇对运动非常敏感,神经生物学家研究的初级运动检测器(elementarymotiondetector)理论模型初步解释了果蝇基本的运动检测机制。该模型由一对间距△d的相邻感受器a和b组成,如图3虚线框所示。假设一个光点从a运动到b,a接收到信号后,延迟一段时间,使其与b接收到的信号在时间轴上相遇,两信号相乘,信号达到峰值。如果不能相遇,则信号为0。通常情况下,模型还存在另一个对称镜像臂,这样从b到a的运动则输出大小相等符号相反的信号。该理论模型原理简单,这也导致其鲁棒性较差,实用性不高。目前有少数工作将其运用在简单的静态图像中。
针对传统方法存在的不足,本发明从果蝇视觉模型的初级运动检测器理论中获得启发,将其思想拓展到三维空间中,将果蝇视觉神经通路与人脑认知理论相结合,实现动态坏境下基于雷达点云的三维运动目标检测。该方法计算量较小,对运动反应敏感,鲁棒性好;通过改变神经通路的连接方式,可以实现对特定方向、特定速度的运动物体的检测。
技术实现要素:
为了改善现有方法普遍存在的模型复杂、鲁棒性差、灵活性不足的短板,尤其是针对不具有运动方向检测特异性的缺点,本发明受果蝇视觉模型的启发,将初级运动检测器思想拓展到三维空间中,将果蝇视觉神经通路与人脑认知理论相结合,实现基于雷达点云的三维运动目标检测,流程框架如图4所示。通过改变神经通路的连接方式,可以实现对特定方向、特定速度的运动物体的检测。该方法可应用于自动驾驶汽车或机器人的环境感知系统,也可以用于空天监控系统,具有很强的实际应用价值。
为了达到上述发明目的,本发明采用的技术方案是:
基于激光雷达的果蝇视觉启发的三维运动目标检测方法,包含以下步骤:
步骤(1):获取场景表达数据。获取的场景表达数据包括连续多帧激光雷达点云数据,并同时记录相应的惯性测量单元(inertialmeasurementuint,imu)数据。
步骤(2):数据预处理。根据imu数据,将多帧雷达点云转换到当前时刻t对应的局部雷达坐标系下(右手坐标系,右-前-天分别对应x-y-z轴),并通过滤波去除雷达点云中的地面点。
步骤(3):雷达点云栅格化。对多帧雷达点云进行栅格化处理,栅格分辨率为0.2×0.2×h,其中h由该帧点云垂直方向上最高点与最低点差值决定;栅格化处理后形成类似鸟瞰视角的栅格图,每个栅格作为果蝇复眼中的每个光感受器(小眼睛)。
步骤(4):运动区域的快速搜索。首先,构造水平和竖直两个方向上的视觉神经通路连接方式:针对每个栅格(i,j),只在水平方向和竖直方向上选择另一个感受器(例如(i-1,j),(i+1,j),(i,j-1),(i,j+1))与其组成视觉通路,即形成“十”字状的视觉神经连接通路,其构成搜索半径为r的“十”字状局部搜索区域,如图5所示,其中,五角星栅格只能与四角星相连,而不与圆形栅格相连通;继而,快速计算每个栅格(i,j)在局部搜索区域内的运动置信度得分:
其中,i,j表示雷达栅格图的坐标值;x,y∈[-r,r]表示搜索区域中的局部坐标值;i(i,j)(t)表示t时刻雷达栅格占据图中栅格(i,j)的值;i(i,j)(t-1)表示t-1时刻雷达栅格占据图中栅格(i,j)的值;sh(i,j)和sv(i,j)表示栅格(i,j)在上述局部搜索区域内的运动得分;sh(i,j)和sv(i,j)的最大值对应的xsm和ysm值反映了物体运动大致方向,方向向量记为(xsm,ysm);并且,根据计算得分,运动区域与非运动区域即可准确分割出来。
步骤(5):运动信息的精细计算。根据步骤(4)的计算结果,基于一个局部范围内的精确匹配模板实现准确计算每个栅格的运动信息;针对运动区域,定义一个局部直角扇形搜索空间
e(x,y)=ω1(l-e′1(x,y))+ω2(l-e′2(x,y))+ω3e′3(x,y),
其中,(x,y)是扇形搜索区域下的局部坐标,表示每个栅格(i,j)所在patch的运动位移量;e′为归一化的不同模态信号对应的能量函数,e′1,e′2,e′3分别描述栅格占据高斯滤波图、栅格占据图和平均高度图三种模态信号输入下对应的运动得分;ω为权重参数,ω1,ω2,ω3分别对应e′1,e′2,e′3能量的权重,用来平衡不同模态能量的贡献率;e为总能量值,反映了每个patch在不同位移量时的置信度;vi,j为运动向量,每个栅格的运动向量vi,j由能量最小化计算得到,并且不同的模态信号对应的能量函数定义如下:
其中,m为patch尺寸大小;a,b表示patch中每个栅格对应的局部坐标值;
最后,根据几何信息和运动信息,将栅格聚类,形成物体候选区,并将候选区内的点云提取出来,传递给接下来的检测网络。
步骤(6):运动点云的认知计算。根据步骤(5)的聚类结果,将物体候选区内的点云送入目标检测网络中,依次经过点云语义分割网络去除地面、背景等噪声点;坐标转换网络,进行坐标变换;物体回归网络,进行物体的分类以及目标三维框的回归,以实现运动目标的认知,如图6所示。
本发明的有益效果在于:
通用性强:本发明对激光雷达点云进行环境感知的系统均切实有效,对于航空器拍摄的俯视视角图像,该方法亦实用;
计算量小:相比于现有的“检测-跟踪”和“光流/场景流”方法,本发明提出的方法模型简单,计算量小;
灵活性好:相比于现有的方法,本发明可以根据实际情况设计改变神经通路的连接方式,可以实现对特定方向、特定速度的运动物体的检测,如图7所示。
附图说明
图1是基于“检测-跟踪”的方法模型示意图;
图2是基于“光流/场景流”的方法模型示意图;
图3是“初级运动检测器”模型示意图;
图4是本发明框架流程结构图;
图5是本发明运动区域快速搜索阶段网络结构连接示意图;
图6是本发明运动目标检测结果图;
图7是本发明针对水平向右特定运动目标检测的结果图。
具体实施方式
下面对本发明进行详细说明,应当理解,此处所描述的内容仅用以解释本发明,并不局限于本发明。
本发明受果蝇视觉模型的启发,将初级运动检测器思想拓展到三维空间中,将果蝇视觉神经通路与人脑认知理论相结合,实现基于雷达点云的三维运动目标检测,流程框架如图4所示。通过改变神经通路的连接方式,可以实现对特定方向、特定速度的运动物体的检测。该方法可应用于自动驾驶汽车或机器人的环境感知系统,也可以用于空天监控系统,具有很强的实际应用价值。
为了达到上述发明目的,本发明采用的技术方案是:
基于激光雷达的果蝇视觉启发的三维运动目标检测方法,包含以下步骤:
步骤(1):获取场景表达数据。获取的场景表达数据包括连续多帧激光雷达点云数据,并同时记录相应的惯性测量单元(inertialmeasurementuint,imu)数据。
步骤(2):数据预处理。根据imu数据,将多帧雷达点云转换到当前时刻t对应的局部雷达坐标系下(右手坐标系,右-前-天分别对应x-y-z轴),并通过滤波去除雷达点云中的地面点。
步骤(3):雷达点云栅格化。对多帧雷达点云进行栅格化处理,栅格分辨率为0.2×0.2×h,其中h由该帧点云垂直方向上最高点与最低点差值决定;栅格化处理后形成类似鸟瞰视角的栅格图,每个栅格作为果蝇复眼中的每个光感受器(小眼睛)。
步骤(4):运动区域的快速搜索。首先,构造水平和竖直两个方向上的视觉神经通路连接方式:针对每个栅格(i,j),只在水平方向和竖直方向上选择另一个感受器(例如(i-1,j),(i+1,j),(i,j-1),(i,j+1))与其组成视觉通路,即形成“十”字状的视觉神经连接通路,其构成搜索半径为r的“十”字状局部搜索区域,如图5所示,其中,五角星栅格只能与四角星相连,而不与圆形栅格相连通;继而,快速计算每个栅格(i,j)在局部搜索区域内的运动置信度得分:
其中,i,j表示雷达栅格图的坐标值;x,y∈[-r,r]表示搜索区域中的局部坐标值;i(i,j)(t)表示t时刻雷达栅格占据图中栅格(i,j)的值;i(i,j)(t-1)表示t-1时刻雷达栅格占据图中栅格(i,j)的值;sh(i,j)和sv(i,j)表示栅格(i,j)在上述局部搜索区域内的运动得分;sh(i,j)和sv(i,j)的最大值对应的xsm和ysm值反映了物体运动大致方向,方向向量记为(xsm,ysm);并且,根据计算得分,运动区域与非运动区域即可准确分割出来。
步骤(5):运动信息的精细计算。根据步骤(4)的计算结果,基于一个局部范围内的精确匹配模板实现准确计算每个栅格的运动信息;针对运动区域,定义一个局部直角扇形搜索空间
e(x,y)=ω1(l-e′1(x,y))+ω2(l-e′2(x,y))+ω3e′3(x,y),
其中,(x,y)是扇形搜索区域下的局部坐标,表示每个栅格(i,j)所在patch的运动位移量;e′为归一化的不同模态信号对应的能量函数,e′1,e′2,e′3分别描述栅格占据高斯滤波图、栅格占据图和平均高度图三种模态信号输入下对应的运动得分;ω为权重参数,ω1,ω2,ω3分别对应e′1,e′2,e′3能量的权重,用来平衡不同模态能量的贡献率;e为总能量值,反映了每个patch在不同位移量时的置信度;vi,j为运动向量,每个栅格的运动向量vi,j由能量最小化计算得到,并且不同的模态信号对应的能量函数定义如下:
其中,m为patch尺寸大小;a,b表示patch中每个栅格对应的局部坐标值;
最后,根据几何信息和运动信息,将栅格聚类,形成物体候选区,并将候选区内的点云提取出来,传递给接下来的检测网络。
步骤(6):运动点云的认知计算。根据步骤(5)的聚类结果,将物体候选区内的点云送入目标检测网络中,依次经过点云语义分割网络去除地面、背景等噪声点;坐标转换网络,进行坐标变换;物体回归网络,进行物体的分类以及目标三维框的回归,以实现运动目标的认知,如图6所示。
尽管上面对本发明说明性的具体实施方式进行了描述,并给出算例以便于技术领域的技术人员能够理解本发明,但是本发明并不仅限于此范围,对本技术领域的普通技术人员而言,只要各种变化在本发明精神和范围内,一切利用本发明构思的发明创造均在保护之列。
- 还没有人留言评论。精彩留言会获得点赞!