一种SLAM与目标跟踪方法与流程
本申请属于同步定位与构图技术领域,特别是涉及一种slam与目标跟踪方法。
背景技术:
无人驾驶汽车作为汽车发展的主要发展方向之一,其在未来改变人类出行方式中扮演者越来越重要的角色。高精度地图为无人驾驶平台提供丰富的信息,是无人驾驶汽车实现自主导航的关键所在。构建高精度地图,车辆需要感知自身在真实物理空间中的方位,以及场景的三维结构,这依赖于同步定位与构图技术。传统的同步定位与构图技术专注于研究无移动目标的理想静态场景,如乡村道路,林间小道,而无人驾驶车辆所面对的环境中,往往包含许多移动目标,如场景复杂的真实城区环境。因此研制一种面向城市道路场景的同步定位与构图系统,必然能够提高无人驾驶汽车在城区环境的定位精度,构建一致性好的城区场景地图,增强同步定位与技术的环境适应性,为同步定位与构图技术实现商用奠定基础。
目前的同步定位与构图方法按照应用场景的不同,分为静态场景与动态场景,静态场景下的移动机器人同步定位与构图假设环境中不存在其他动态目标,移动的传感器从静态对象(地面,树木、墙壁)上提取特征信息,以计算自身定位与构造静态地图。动态场景则是在静态场景的基础上加入移动对象,移动对象会对背景有遮挡,影响对静态场景的特征提取。按传感器的不同分为:基于激光雷达的同步定位与构图,基于视觉的同步定位与构图。
单一的激光雷达同步定位与构图系统存在能耗高、感知分辨率低的特点,对于深度值变化不明显的场景,无法完成高精度场景建图。而单一的视觉同步定位与构图系统,精度低、定位精度易受光照变化影响。
技术实现要素:
1.要解决的技术问题
基于单一的激光雷达同步定位与构图系统存在能耗高、感知分辨率低的特点,对于深度值变化不明显的场景,无法完成高精度场景建图。而单一的视觉同步定位与构图系统,精度低、定位精度易受光照变化影响,本申请提供了一种可同时实现slam与目标跟踪的方法。
2.技术方案
为了达到上述的目的,本申请提供了一种slam与目标跟踪方法,所述方法包括如下步骤:
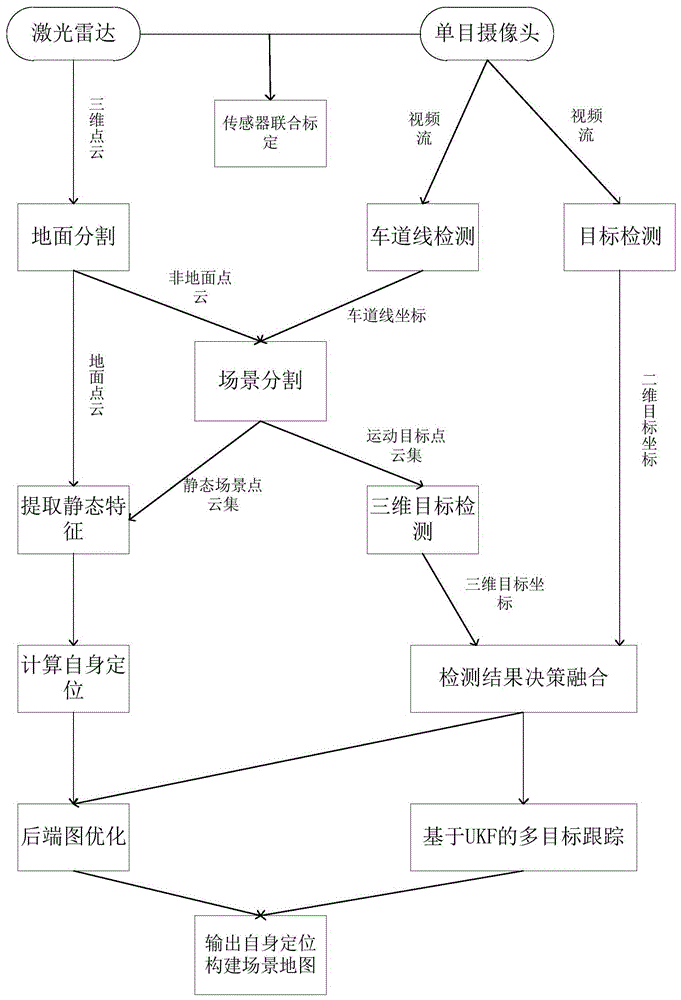
步骤1:采集真实城市道路场景下三维点云数据,对所述三维点云数据进行滤波处理,采集真实城市道路场景下图像视频数据,对所述图像视频流数据进行目标检测和车道线检测,获取目标回归框坐标和车道线坐标;
步骤2:根据所述车道线检测结果对滤波后的所述三维点云数据进行分割处理,得到静态场景和动态场景;
步骤3:对所述静态场景进行基于静态特征点的同步定位和构图,输出自身定位与静态场景子图,对所述动态场景三维点云数据进行三维目标检测,输出三维回归框坐标,将所述三维回归框坐标结合所述目标回归框坐标进行检测结果决策融合,基于所述融合结果进行基于贝叶斯滤波的多目标跟踪,输出动态目标位姿与轨迹,构建动态对象子图;
步骤4:采用图优化全局优化方法,输入所述自身定位,将所述静态特征点与动态语义对象作为统一的路标点,优化自身位置与路标位置,输出优化后的所述自身定位和场景地图。
本申请提供的另一种实施方式为:所述动态场景点为所述车道线内的所述三维点云数据;所述静态场景点包括所述车道线外的所述三维点云数据和被滤波的所述三维点云数据。
本申请提供的另一种实施方式为:所述步骤1中对所述三维点云数据进行的滤波处理为基于特征轴的地面点提取,将原始三维点云数据分为地面点与非地面点。
本申请提供的另一种实施方式为:所述三维点云数据通过激光雷达进行采集,所述图像视频数据通过摄像头采集。
本申请提供的另一种实施方式为:所述步骤2中包括预先对所述摄像头进行内参标定,获取摄像头内参;并对激光雷达与摄像头进行联合标定,获取所述三维点云数据与所述图像像素点之间的投影变换矩阵。
本申请提供的另一种实施方式为:所述步骤2中基于所述视频流的车道线检测输出的二维坐标,经过所述摄像头内参的透视变换,得到摄像头坐标系下的坐标信息;再根据联合校准的结果,对所述摄像头坐标系下的点进行旋转平移变换,得到车道线信息在激光雷达坐标系下的坐标。
本申请提供的另一种实施方式为:所述步骤3包括如下步骤:
a、对于所述静态场景,对激光雷达每一圈扫描的点计算曲率,按曲率大小对所有点进行排序,取曲率排名前四的点作为边缘点,取曲率排名最后的两个点视为平面点;
b、根据相邻两帧数据计算边缘点与线的运动变化,平面点与面的运动变化,用莱文贝格-马夸特方法进行优化,输出优化后的结果并以此作为自身相邻两帧的运动变化;
c、利用点柱编码器,对动态场景三维点云数据进行基于竖直方向上三维点云数据数量特征提取,将三维信息转换为二维信息,再使用二维卷积神经网络对二维编码信息进行检测,获取三维目标的类别与三维回归框坐标;
d、将三维目标投影到二维图像,剔除与二维检测目标类别不匹配的目标,将剩余类别匹配的对象作为融合后的决策结果,输出决策结果的位姿,对决策结果进行基于贝叶斯滤波的多目标跟踪,输出目标的运动轨迹。
本申请提供的另一种实施方式为:所述步骤3中动态目标的数学模型为:
其中,st表示第t帧检测到的所有语义目标,sk表示当前语义目标,一个目标状态sk应该包含三个部分:
本申请提供的另一种实施方式为:所述步骤4中所述图优化的路标点包括了静态场景特征点的几何信息与动态场景中的语义目标信息。
本申请提供的另一种实施方式为:所述几何信息和所述语义目标信息统一在期望似然测量模型中,所述模型为:
ed[logp(z|x,l,d)|xi,li,z]
其中,xi表示i时刻几何对象的位置,
li表示i时刻语义对象的位置,
z表示两者的观测值。
优化问题转化为给定初始估计xi和li,让这个期望测量似然取最大值的x和l即是我们所需要的下一步状态的xi+1和li+1,优化模型为:
xi+1,li+1=argmaxed[logp(z|x,l,d)|xi,li,z]
其中,xi表示i时刻几何对象的位置,
li表示i时刻语义对象的位置,z表示两者的观测值,
xi+1表示第i+1时刻几何对象的位置,
li+1表示第i+1时刻语义对象的位置
3.有益效果
与现有技术相比,本申请提供的一种slam与目标跟踪方法的有益效果在于:
本申请提供的slam与目标跟踪方法,通过分别基于激光雷达三维点云数据滤波处理,基于摄像头视频流车道线检测,对单帧数据进行场景分割,巧妙地将复杂的城区场景分割为静态场景与动态场景。分别对静态场景与动态场景实施不同的同步定位与构图技术,可以实现对静态场景的重构与对动态对象的实时跟踪。最后构建的基于多信息的图优化数学模型,可在一个优化框架下同时更新静态几何特征与动态语义对象的位置,达到全局最优。
本申请所提的slam与目标跟踪方法,在对静态场景提取特征点,实施静态场景下的同步定位与构图的同时,对车道线内的动态场景实施基于激光雷达与图像融合的目标检测,提取动态语义对象,实施基于bayes滤波的多目标跟踪,并构建同时更新静态场景特征点与动态语义对象的图优化模型,实现了在复杂城市场景中对无人驾驶汽车定位精度高,构建高精度地图一致性好的目标。
本申请提出的slam与目标跟踪方法,能提高大规模复杂场景下无人驾驶汽车的定位精度,构建一致性好的高精度场景地图,同时实现对运动目标的跟踪。
本申请提出的slam与目标跟踪方法,基于3d激光雷达和摄像头的数据融合,通过对道路上车道线的检测与地面点的提取,实现将道路环境分割为运动目标部分与静态背景部分,进而实现车辆高精度的自身定位和环境地图的构建。
本申请提出的slam与目标跟踪方法,实现方法简单高效,场景分割效果好,通过有效区分环境中的运动目标和静态背景,实现高精度定位与一致性建图的同时,还能实现目标跟踪效果。
附图说明
图1是本申请的slam与目标跟踪方法原理示意图;
图2是本申请的静态场景下同步定位与构图原理示意图。
具体实施方式
在下文中,将参考附图对本申请的具体实施例进行详细地描述,依照这些详细的描述,所属领域技术人员能够清楚地理解本申请,并能够实施本申请。在不违背本申请原理的情况下,各个不同的实施例中的特征可以进行组合以获得新的实施方式,或者替代某些实施例中的某些特征,获得其它优选的实施方式。
slam(simultaneouslocalizationandmapping),也称为cml(concurrentmappingandlocalization),即时定位与地图构建,或并发建图与定位。
视频流是指视频数据的传输,例如,它能够被作为一个稳定的和连续的流通过网络处理。因为流动,客户机浏览器或插件能够在整个文件被传输完成前显示多媒体数据。视频流技术基于2密钥技术,视频译码技术和可升级的视频分发技术发展。
ukf(unscentedkalmanfilter),中文释义是无损卡尔曼滤波、无迹卡尔曼滤波或者去芳香卡尔曼滤波。是无损变换(ut)和标准kalman滤波体系的结合,通过无损变换使非线性系统方程适用于线性假设下的标准kalman滤波体系。
参见图1~2,本申请提供一种slam与目标跟踪方法,所述方法包括如下步骤:
步骤1:采集真实城市道路场景下三维点云数据,对所述三维点云数据进行滤波处理,采集真实城市道路场景下图像视频数据,对所述图像视频流数据进行目标检测和车道线检测,获取目标回归框坐标和车道线坐标;从视频流获取的检测对象与滤波后的点云需要进行同步操作,分别提取两个时间轴上对应一点的数据,整合成一帧数据。
步骤2:根据所述车道线检测结果对滤波后的所述三维点云数据进行分割处理,得到静态场景和动态场景;
步骤3:对所述静态场景进行基于静态特征点的同步定位和构图,输出自身定位与静态场景子图,对所述动态场景三维点云数据进行三维目标检测,输出三维回归框坐标,将所述三维回归框坐标结合所述目标回归框坐标进行检测结果决策融合,基于所述融合结果进行基于贝叶斯滤波的多目标跟踪,输出动态目标位姿与轨迹,构建动态对象子图;
步骤4:采用图优化全局优化方法,输入所述自身定位,将所述静态特征点与动态语义对象作为统一的路标点,优化自身位置与路标位置,输出优化后的所述自身定位和场景地图。
进一步地,所述动态场景点为所述车道线内的所述三维点云数据;所述静态场景点包括所述车道线外的所述三维点云数据和被滤波的所述三维点云数据。
进一步地,所述步骤1中对所述三维点云数据进行的滤波处理为基于特征轴的地面点提取,将原始三维点云数据分为地面点与非地面点。
进一步地,所述三维点云数据通过激光雷达进行采集,所述图像视频数据通过摄像头采集。这里的摄像头采用单目摄像头。
进一步地,所述步骤2中包括预先对所述摄像头进行内参标定,获取摄像头内参;并对激光雷达与摄像头进行联合标定,获取所述三维点云数据与所述图像像素点之间的投影变换矩阵。
进一步地,所述步骤2中基于所述视频流的车道线检测输出的二维坐标,经过所述摄像头内参的透视变换,得到摄像头坐标系下的坐标信息;再根据联合校准的结果,对所述摄像头坐标系下的点进行旋转平移变换,得到车道线信息在激光雷达坐标系下的坐标。
进一步地,所述步骤3包括如下步骤:
a、对于所述静态场景,对激光雷达每一圈扫描的点计算曲率,按曲率大小对所有点进行排序,取曲率排名前四的点作为边缘点,取曲率排名最后的两个点视为平面点;
b、根据相邻两帧数据计算边缘点与线的运动变化,平面点与面的运动变化,用莱文贝格-马夸特方法进行优化,输出优化后的结果并以此作为自身相邻两帧的运动变化;
c、利用点柱编码器,对动态场景三维点云数据进行基于竖直方向上三维点云数据数量特征提取,将三维信息转换为二维信息,再使用二维卷积神经网络对二维编码信息进行检测,获取三维目标的类别与三维回归框坐标;
d、将三维目标投影到二维图像,剔除与二维检测目标类别不匹配的目标,将剩余类别匹配的对象作为融合后的决策结果,输出决策结果的位姿,对决策结果进行基于贝叶斯滤波的多目标跟踪,输出目标的运动轨迹。
进一步地,所述步骤3中动态目标的数学模型为:
其中,st表示第t帧检测到的所有语义目标,sk表示当前语义目标,一个目标状态sk应该包含三个部分:
进一步地,所述步骤4中所述图优化的路标点包括了静态场景特征点的几何信息与动态场景中的语义目标信息。
进一步地,所述几何信息和所述语义目标信息统一在期望似然测量模型中,所述模型为:
ed[logp(z|x,l,d)|xi,li,z]
其中,xi表示i时刻几何对象的位置,
li表示i时刻语义对象的位置,
z表示两者的观测值。
优化问题转化为给定初始估计xi和li,让这个期望测量似然取最大值的x和l即是我们所需要的下一步状态的xi+1和li+1,优化模型为:
xi+1,li+1=argmaxed[logp(z|x,l,d)|xi,li,z]
其中,xi表示i时刻几何对象的位置,
li表示i时刻语义对象的位置,z表示两者的观测值,
xi+1表示第i+1时刻几何对象的位置,
li+1表示第i+1时刻语义对象的位置
该决策模型为软决策模型,将观测到的路标点状态视为一个静态特征点与动态语义对象的一个概率分布叠加。
实施例
参见图1,本申请包括:
s1.分别采集真实城市道路场景下三维点云数据与图像视频数据,将采集到的三维点云数据进行地面点分割,得到地面点与非地面点,对视频流数据进行目标检测与车道线检测,获取目标回归框坐标与车道线坐标。
s2.对非地面三维点云数据,根据车道线坐标进行分割,将车道线内的点作为动态场景点;将车道线外的三维点云数据与s1得到的地面三维点云数据进行整合,得到静态场景点;
s3.对静态场景进行基于特征点的同步定位与构图,输出自身定位与静态场景子图。对动态场景三维点云数据进行目标检测,输出三维回归框坐标,结合s1的二维回归框进行检测结果决策融合,最后基于融合结果进行基于bayes滤波的多目标跟踪,输出动态目标位姿与轨迹;
s4.将三维目标投影到二维图像,剔除与二维检测目标类别不匹配的目标,将剩余类别匹配的对象作为融合后的决策结果,输出决策结果的位姿。对决策结果进行基于bayes滤波的多目标跟踪,输出目标的运动轨迹;
对三维点云数据进行的滤波处理为基于特征轴的地面点提取,将原始三维点云数据数据分为地面点与非地面点。
同步处理要求:从视频流获取的检测对象与滤波后的三维点云数据需要进行同步操作,分别提取两个时间轴上对应一点的数据,整合成一帧数据。
预先对摄像头进行内参标定,获取摄像头内参。对激光雷达与摄像头进行联合标定,获取三维三维点云数据与图像像素点之间的投影变换矩阵。
基于视频流的车道线检测所输出的二维坐标,经过摄像头内参的透视变换,得到投影后摄像头坐标系下的坐标信息。再根据联合校准的结果,对摄像头坐标系下的点进行旋转平移变换,得到车道线信息在激光雷达坐标系下的坐标。
结合图2,本实施例中,步骤s3中对静态场景实施基于特征点的同步定位与构图的具体步骤为:
s311.对于静态场景部分,对激光雷达每一圈所扫描的点计算曲率,按曲率大小对点进行排序,取曲率排名前四的点作为边缘点,取曲率排名最后的两个点视为平面点。
s312.根据相邻两帧数据计算边缘点与线的运动变化,平面点与面的运动变化,对运动变化运用莱文贝格-马夸特(lm)方法进行优化,输出优化后的结果并以此作为无人驾驶汽车自身相邻两帧的运动变化。
本实施例中,步骤s3中对动态场景实施基于激光雷达与视觉融合的动态目标检测与跟踪的具体步骤为:
s321.利用点柱编码器,对动态场景三维点云数据进行基于z轴方向三维点云数据数量特征提取,将三维信息转换为二维信息。再使用二维卷积神经网络对二维编码信息进行检测,获取三维目标的类别与三维回归框。
s322.将三维目标投影到二维图像,剔除与二维检测目标类别不匹配的目标,将剩余类别匹配的对象作为融合后的决策结果,输出决策结果的位姿。对决策结果实施基于无迹卡尔曼滤波的多目标跟踪,输出目标的运动轨迹。
动态目标的数学模型应符合如下模型:
其中,st表示第t帧检测到的所有语义目标,sk表示当前语义目标,一个目标状态sk应该包含三个部分:
图优化优化路标点部分,路标点包括了静态场景特征点的几何信息与动态场景中的语义目标信息,两者应统一在一个数学模型中,统一在期望似然测量模型中:
ed[logp(z|x,l,d)|xi,li,z]
其中,xi表示i时刻几何对象的位置;
li表示i时刻语义对象的位置;
z表示两者的观测值。
优化问题转化为给定初始估计xi和yi,让这个期望测量似然取最大值的x和l即是我们所需要的下一步状态的xi+1和li+1,优化模型为:
xi+1,li+1=argmaxed[logp(z|x,l,d)|xi,li,z]
其中,xi表示i时刻几何对象的位置;
li表示i时刻语义对象的位置,z表示两者的观测值;
xi+1表示第i+1时刻几何对象的位置;
li+1表示第i+1时刻语义对象的位置。
决策模型为软决策模型,将观测到的路标点状态视为一个静态特征点与动态语义对象的一个概率分布叠加。
本申请所提的slam与目标跟踪方法,在对静态场景提取特征点,实施静态场景下的同步定位与构图的同时,对车道线内的动态场景实施基于激光雷达与图像融合的目标检测,提取动态语义对象,实施基于bayes滤波的多目标跟踪,并构建同时更新静态场景特征点与动态语义对象的图优化模型,实现了在复杂城市场景中对无人驾驶汽车定位精度高,构建高精度地图一致性好的目标。
尽管在上文中参考特定的实施例对本申请进行了描述,但是所属领域技术人员应当理解,在本申请公开的原理和范围内,可以针对本申请公开的配置和细节做出许多修改。本申请的保护范围由所附的权利要求来确定,并且权利要求意在涵盖权利要求中技术特征的等同物文字意义或范围所包含的全部修改。
- 还没有人留言评论。精彩留言会获得点赞!