基于贝叶斯支持向量数据描述的雷达库外目标识别方法与流程
本发明属于雷达技术领域,特别涉及一种雷达库外目标识别方法,可用于雷达高分辨距离像的自动识别。
背景技术:
随着智能化水平的提高,雷达自动目标识别ratr技术受到广泛关注。雷达高分辨距离像hrrp是用宽带雷达信号获取的目标散射点子回波在雷达视线上投影的向量和。hrrp包含了对目标分类和识别十分有价值的结构信息,如目标的径向尺寸、散射点分布等,而具有且易于获取、存储和处理等优点。
在实际应用中,ratr系统所要识别的目标往往是非合作目标。因此在训练过程中想建立完备的数据库十分困难甚至难以实现。由于实际ratr系统的目标库往往是不完备的,当有别于库内所有目标的新目标的测试数据出现时,将其判别为库内的任一类样本目标都是不合理的,因此需要对库外目标进行预先识别。
库外目标识别问题的本质是针对库内和库外这两类目标的分类问题,然而在训练阶段往往难以获取库外目标的数据,因此常用单类分类器来实现对库外目标的识别。单类分类器只需用库内目标数据进行学习,形成对库内类别数据的描述,然后设计相似性度量方式,通过计算新来数据与库内类别数据的相似度,并同设定的阈值进行比较,来判定新数据的类别属性。
支持向量数据描述svdd是常见的单类分类器,其思想是通过对训练数据的学习,形成一个围绕训练数据的超球体,并且最小化该超球体的体积,等价于最小化超球体的半径,来达到最小识别错误率的目的。然而由于传统支持向量数据描述svdd在训练阶段是通过优化算法来求解模型参数,无法对模型参数提出概率分布假设,造成识别结果的置信度难以评估,且识别性能受限的不足。
技术实现要素:
本发明的目的在于针对上述传统svdd无法与概率模型相结合的问题,提出一种基于贝叶斯支持向量数据描述的雷达库外目标识别方法,以提高对库外目标的识别性能。
实现本发明目的的思路是,通过理论推导,加入隐变量,将svdd目标函数用概率模型来代替,对svdd的参数提出概率分布假设,从而给出贝叶斯支持向量数据描述bsvdd的层次化概率模型,实现传统的svdd算法与贝叶斯框架相结合。bsvdd具有全共轭先验分布,能够利用变分贝叶斯vb方法对其进行参数估计。
根据上述思路,本发明的实现步骤包括如下:
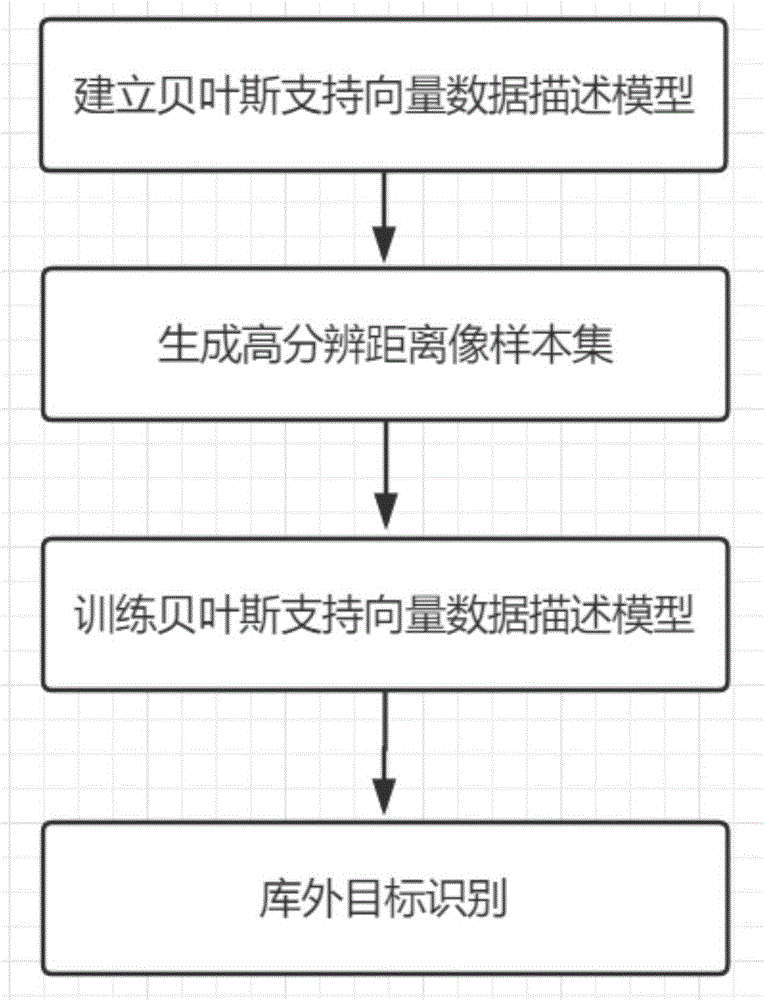
(1)建立贝叶斯支持向量数据描述模型:
其中,λ=[λ1,…,λn,…,λn]表示隐变量,λn表示第n个样本对应的隐变量,n表示样本总数,n表示第n个样本,n=1,…,n,k表示核矩阵,拉格朗日系数α服从高斯分布,方差项引入γ,参数γ为调和参数,服从形状参数为c,尺度参数为d的gamma分布,稀疏系数z服从参数为π的伯努利分布,z的先验分布参数π服从形状参数为τ1,τ2的贝塔分布,α=[α1,…,αn,…,αn]t,z=[z1,…zn,…zn]t,π=[π1,…,πn,…,πn]t,αn表示第n个样本对应的拉格朗日系数,zn表示第n个样本拉格朗日系数αn对应的稀疏系数,πn表示第n个样本zn的先验分布参数,kn表示k的第n列,c0为调节常数,
(2)生成高分辨距离像样本集:
(2a)选择三类飞机的雷达高分辨距离像hrrp数据,其中两类作为库内样本,剩下的一类作为库外样本,从库内的两类样本中各选择300个样本,共600个样本组成训练样本集,从每类飞机样本中分别选择800个样本,共2400个样本组成测试样本集;
(2b)用测试样本集中的每个高分辨距离像数据除以该高分辨距离像数据的模二范数,得到归一化后的测试样本集;
(2c)用训练样本集中的每个高分辨距离像数据除以该高分辨距离像数据的模二范数,得到归一化后的训练样本集;
(3)对(1)建立的贝叶斯支持向量数据描述模型进行训练:
(3a)对贝叶斯支持向量数据描述模型进行参数初始化,设置收敛门限ξ=0.1;
(3b)将归一化后的训练样本集输入到贝叶斯支持向量数据描述模型中,对模型中的所有参数进行更新;
(3c)计算在当前迭代次数t下的变分下界lb(t),并判断下界是否收敛:
当|lb(t)-lb(t-1)|/|lb(t-1)|>ξ,则认为下界不收敛,重复步骤(3b),其中t为迭代次数,lb(t)为第t次的变分下界,lb(t-1)为第t-1次的变分下界;
当|lb(t)-lb(t-1)|/|lb(t-1)|≤ξ,则认为下界收敛,将当前参数取值作为模型的解,得到训练好的贝叶斯支持向量数据描述模型;
(4)将归一化后的测试样本集中所有样本输入到训练好的贝叶斯支持向量数据描述模型中进行目标识别,得到测试样本集所有样本的分类标签,库内为1,库外为-1;
本发明与现有技术相比具有以下优点:
本发明由于对svdd模型参数提出了概率分布假设,并构建了贝叶斯支持向量数据描述模型,克服了在传统求解过程中因svdd模型无法对参数提出概率分布假设,及不能利用变分贝叶斯方法对模型参数进行参数估计而造成的识别率较低的问题,提高了对库外目标的识别性能。
附图说明
图1是本发明的实现流程图;
图2(a)是现有支持向量数据描述svdd方法的接收机工作特性曲线;
图2(b)是本发明贝叶斯支持向量数据描述bsvdd方法的接收机工作特性曲线。
具体实施方式
下面结合附图对本发明的实施例和效果做进一步的描述。
参照图1,对本实施例的实现步骤如下:
步骤1,建立贝叶斯支持向量数据描述模型。
(1.1)计算训练样本集x=[x1,…xn,…,xn]的核矩阵k:
(1.1a)根据径向基函数,计算核矩阵k第i行第j列元素为:
其中,σ为核参数,σ>0,xi和xj分别表示第i个和第j个训练样本,i=1,…n,j=1,…n,||·||2表示模2范数;
(1.1b)根据步骤(1.1a)得到的核矩阵k中第i行第j列元素k(xi,xj),得到训练核矩阵为:
(1.2)使用拉格朗日因子法得到支持向量数据描述的对偶问题:
约束条件为,
其中,αi为第i个样本对应的拉格朗日系数,αj为第j个样本对应的拉格朗日系数;
(1.3)将隐变量λ引入(1.2)中得到支持向量数据描述对偶问题的伪似然形式:
其中,λ=[λ1,…,λn,…,λn]表示隐变量,λn表示第n个样本对应的隐变量,n表示样本总数,n表示第n个样本,n=1,…,n,k表示核矩阵,拉格朗日系数α=[α1,…,αn,…,αn]t,kn表示k的第n列,c0为调节常数,
(1.4)由于拉格朗日系数α具有很强的稀疏性,所以将稀疏系数z引入到(1.3)的伪似然形式中,利用z使得α具有稀疏性,得到贝叶斯支持向量数据描述的概率模型:
其中,稀疏系数z=[z1,…zn,…zn]t,zn表示第n个样本拉格朗日系数αn对应的稀疏系数,
步骤2,生成高分辨距离像样本集。
(2.1)选择三类飞机的雷达高分辨距离像hrrp数据,两类作为库内样本,剩下的一类作为库外样本,从库内的两类样本中各选择300个样本,共600个样本组成训练样本集,从每类飞机样本中分别选择800个样本,共2400个样本组成测试样本集;
(2.2)用测试样本集中的每个高分辨距离像数据除以该高分辨距离像数据的模二范数,得到归一化后的测试样本集;
(2.3)用训练样本集中的每个高分辨距离像数据除以该高分辨距离像数据的模二范数,得到归一化后的训练样本集;
步骤3,对步骤1建立的贝叶斯支持向量数据描述模型进行训练:
(3.1)对贝叶斯支持向量数据描述模型进行参数初始化,
设置收敛门限ξ=0.1,调节常数c0取值为0.97;
设拉格朗日系数α服从的条件后验分布为高斯分布,设置其均值为0,方差为0.67;
设调和参数γ的条件后验分布为伽马分布,形状参数c=10-4,尺度参数d=10-3;
设置稀疏系数z的先验分布参数π,服从形状参数为τ1=10-4,τ2=10-6的贝塔分布;
(3.2)将归一化后的训练样本集输入到贝叶斯支持向量数据描述模型中,对模型中的所有参数进行更新,即对协方差矩阵σα,后验均值μα,第n个样本的稀疏系数zn,zn的先验分布参数πn的形状参数τ′1,τ′2,调和参数γ的形状参数c′,尺度参数d′,第n个样本对应的隐变量λn的逆
(3.2a)设拉格朗日系数组成列向量α的条件后验分布为高斯分布n(α|μα,σα),计算协方差矩阵σα,后验均值μα:
其中,
(3.2b)设πn的条件后验分布为贝塔分布beta(πn|τ′1,τ′2),计算更新后的参数τ′1=<zn>+τ1,τ′2=1-<zn>+τ2;
(3.2c)计算zn的条件后验分布
(3.2d)设调和参数γ的条件后验分布为伽马分布ga(γ|c′,d′),计算更新后的形状参数
其中,*表示向量与矩阵的相乘;
(3.2e)计算第n个样本对应的隐变量λn的逆
(3.3)计算在当前迭代次数t下的变分下界lb(t):
(3.3a)计算贝叶斯支持向量数据描述模型的伪似然函数期望<lnp(x|α,λ,z)>:
其中,trace(·)表示求矩阵迹操作;
(3.3b)计算拉格朗日系数向量α的kl距离的期望<kl(q(α)||p(α|γ))>:
其中,kl距离表示变量的变分分布与后验分布之间的散度,
α的变分分布为
后验分布为
ψ(·)表示伽马函数的导数,i为单位矩阵;
(3.3c)计算调和系数γ的kl距离的期望<kl(q(γ)||p(γ|c,d))>:
其中,γ的变分分布为
后验分布为
γ(·)表示伽马函数,c为更新前的形状参数,d为更新前的尺度参数,c′为更新后的形状参数,d′为更新后的尺度参数;
(3.3d)计算稀疏系数z的kl距离的期望<kl(q(z)||p(z|π))>:
其中,q(z)为z的变分分布,p(z|π)为z的后验分布,zn为第n个样本的稀疏系数,q(zn=1)为zn=1时的概率分布,q(zn=0)为zn=0时的概率分布;
(3.3e)计算先验π的kl距离的期望<kl(q(π)||p(π|τ1,τ2))>:
其中,π的变分分布为
(3.3f)计算变分下界lb(t):
lb(t)=<lnp(x|α,λ,z)>-<kl(q(α)||p(α|γ))>-<kl(q(z)||p(z|π))>-<kl(q(γ)||p(γ|c,d))>-<kl(q(π)||p(π|τ1,τ2))>
(3.3e)判断下界是否收敛:
若|lb(t)-lb(t-1)|/|lb(t-1)|>ξ,则认为下界不收敛,返回(3.2),
若|lb(t)-lb(t-1)|/|lb(t-1)|≤ξ,则认为下界收敛,将当前参数取值作为模型的解,得到训练好的贝叶斯支持向量数据描述模型;
其中,lb(t-1)为第t-1次迭代的变分下界,ξ为收敛门限。
步骤4,将归一化后的测试样本集中所有样本输入到训练好的贝叶斯支持向量数据描述模型中进行目标识别,得到测试样本集所有样本的分类标签,库内为1,库外为-1;
下面结合仿真实验对本发明的效果做进一步的描述。
1、仿真实验条件:
本发明实验所采用的雷达实测数据为某院的c波段雷达实测的飞机一维hrrp数据。实验的对象包含三类不同类型的飞机:“雅克-42”、“奖状”和“安-26”。表1给出了实验所用雷达和飞机目标的参数:
表1雷达和飞机参数
本发明的仿真实验的硬件测试平台为:intelcorei7cpu,主频3.4ghz,内存16gb,软件平台为:windows7操作系统和matlabr2017a。
2.实验内容及结果分析
选择三类飞机的雷达高分辨距离像hrrp数据,两类作为库内样本,剩下的一类作为库外样本,从库内的两类样本中各选择300个样本,共600个样本组成训练样本集,从每类飞机样本中分别选择800个样本,共2400个样本组成测试样本集。分别采用本发明和现有支持向量数据描述svdd两种方法进行库外目标识别实验,结果如图2所示,其中,图2(a)是用现有方法识别的结果,图2(b)是用本发明实验的结果。
从图2(a)可见,其roc曲线下的面积auc值为0.862,
从图2(b)可见,其roc曲线下的面积auc值为0.886,本发明的识别性能相比现有方法的auc值提升了0.024。
综上,本发明的仿真实验结果证明本发明能有效地提高对雷达高分辨距离像的库外目标识别性能。
- 还没有人留言评论。精彩留言会获得点赞!