应用机器学习中支持向量机、主成分分析和粒子群算法合成地震动场的方法与流程
本发明涉及应用机器学习中支持向量机、主成分分析和粒子群算法合成地震动场的方法,属于地震危险性分析领域。
背景技术:
地震危险性分析(psha)一直是抗震研究的主题之一,地震危险性分析的第一步是地震灾害的情景再现,然而具有破坏性大地震动记录的匮乏一直制约着地震危险性分析的发展。从学术角度和社会安全角度来看,大地震震源、路径以及场地的不确定性一直是模拟大地震再现的技术关键。随着城市化进程的加速,城市大规模的发展向着地震多发地区延伸以及基础设施的老化正在加剧地震危险性。过去,地震动的峰值加速度(pga)以及谱加速度(sa)被用来表征地震动的所有特性,逐渐一些其他的强度参数也被提出(ims,如pgv,pgd,epv等)。但是不能指望仅通过几个简单的强度参数(ims)就能够完全捕捉到具有复杂性过程地震动的特性。在强地面运动中,强度参数(ims)无法可靠地预测具有复杂过程的地震动破坏潜力。因此,在抗震设计规范中提出需要对结构进行非线性时程分析,但实际地震动记录不能够满足抗震设计的需求。为了解决这个问题,有不少方案被提出来,第一种需要通过对地震记录调幅来获得需要的地震动记录,但越来越多的证据表明通过调幅得到的地震动,但可能会将地震动最不利影响最小化。相对于直接使用基于选择和调幅的地震记录而获得的地震动,第二种随机地震动模拟是一种具有吸引力的替代方法。但是,随机地震动模拟的方法可能会忽略某些重要的地震动信息。随着大陆台站的兴建,截止到2019年,我国的强震数据记录的数目已经超过了一万条。机器学习理论是由概率论、统计学、近似理论以及算法复杂度等组成交叉学科。在当今大数据环境下,机器学习理论主要是研究如何有效利用信息,注重从巨量数据中获取隐藏的、有效的、可理解的知识。因此,这才有了应用机器学习方法合成地震动的可能。
技术实现要素:
本发明的目的是提出应用机器学习中支持向量机、主成分分析和粒子群算法合成地震动场的方法,利用国内的已有的地震动数据库,应用机器学习的方法构建地震动场。实现对原有地震动信息更多的保留,且解决随机地震动模拟的方法可能会忽略某些重要的地震动信息的问题。
应用机器学习中支持向量机、主成分分析和粒子群算法合成地震动场的方法,其特征在于,所述方法包括以下步骤:
步骤一、应用主成分分析方法从既有的国内地震动数据中提取地震动的母波;
步骤二、应用支持向量机算法建立地震动预测模型,并验证模型的正确性;
步骤三、通过步骤二三得到的地震动预测模型gmms,将特定场地参数(m,r,vs30)输入到gmms,预测特定场地的加速度反应谱;应用pca方法提取地震动母波,所述地震动母波和地震动具有相同的时间间隔,因此,合成的地震动由提取的地震动母波线性组而成,即
进一步的,在步骤一中,具体包括以下步骤:
步骤一一、选取强震数据库,数据库包括地震震源信息、强震台站信息和强震记录;
步骤一二、应用主成分分析pca从选取的地震动数据库中提取地震动母波,提取的地震动母波用于合成地震动记录。
进一步的,所述地震震源信息包括震级和断层机制,所述强震台站信息包括台站到震源距离和台站所在场点场地参数vs30,所述强震记录包括加速度时程、由加速度时程计算所得的峰值加速度pga和加速度反应谱sa。
进一步的,在步骤二中,具体包括以下步骤:
步骤二一、所述地震动预测模型考虑了震级m和距离衰减项r以及场地效应项vs30,结合地震学基本原理和强震观测数据集整体所表现出的基本特征选取合理的特征参数;
步骤二二、应用支持向量机svm回归地震动衰减关系,其中svm模型中三个重要参数的确定(c,ε和r)依据以下的选择原则:
步骤二三、按照svm训练地震动预测模型gmms,对训练得到的gmms分别进行测试级测试,以及与现有的比较成熟的模型比较,验证模型的准确性。
进一步的,在步骤三中,具体包括以下步骤:
步骤三一、通过步骤二三得到的地震动预测模型gmms,将特定场地参数(m,r,vs30)输入到gmms,预测特定场地的加速度反应谱;
步骤三二、应用pca方法提取地震动母波,所述地震动母波和地震动具有相同的时间间隔,因此,合成的地震动由提取的地震动母波线性组而成,即
步骤三三、合成的地震动的反应谱sa(t)与通过预测方程得到的反应谱sa*(t)相匹配,即
步骤三四、构建粒子群算法pso、自变量ki初始值、最大迭代次数、粒子的最大速度、粒子群的规模以及整个搜索空间;
步骤三五、个体极值以及全局最优解:个体极值为每个粒子找到的最优解,从最优解中找到一个全局值,叫做本次全局最优解,与历史全局最优比较,进行更新;
步骤三六、更新速度和位置公式:
vid=ωvid+c1random(0,1)(pid-xid)+c2random(0,1)(pgd-xid)
xid=xid+vid
其中,ω为惯性因子,当取值较大时寻优能力强,c1和c2为加速度常数,pid为个体极值,pgd为群体极值,xid为粒子当前的位置,vid粒子的速度,maxgen是迭代的次数;
步骤三七、设置迭代次数:当迭代次数达到设置迭代次数时,即停止计算,反复测试迭代次数,当误差值稳定时,得到的一组系数ki即为最优解;
步骤三八、合成的地震动即为
本发明的主要优点是:本发明将机器学习的理论引入了合成地震动方法中,能够保留原始的地震动信息,避免了以往应用随机地震动模拟的方法可能会忽略某些重要的地震动信息的问题出现。此外,由于机器学习理论是基于大数据提出的方法,随着国内地震动数据量的进一步增大,本发明提出的方法对实测数据有好的包容性。本发明能够较好的实现地震巨灾情景再现,具有很好的应用前景。
附图说明
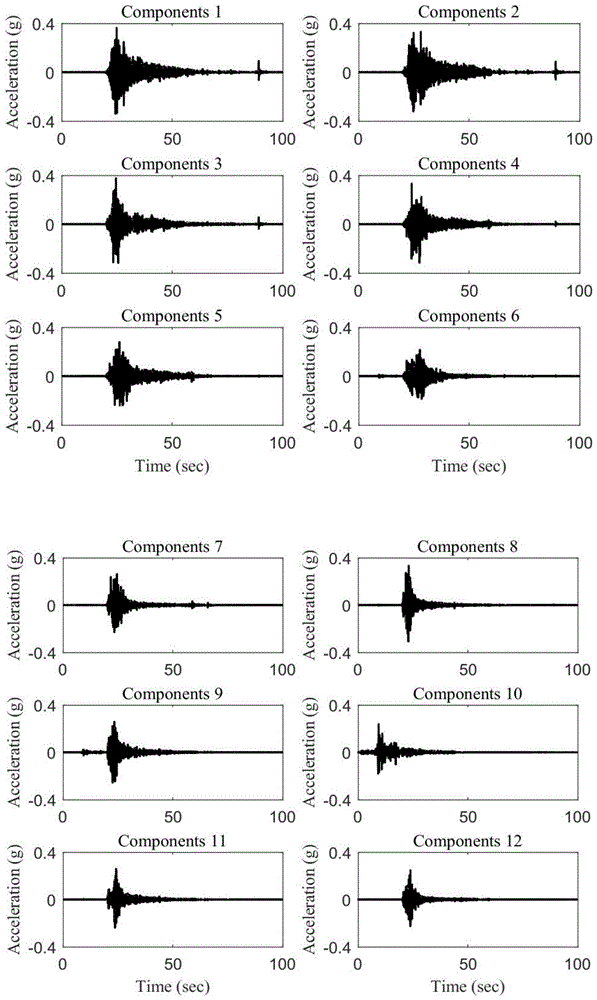
图1为提取的地震动母波的示意图;
图2为模拟得到的地震动的反应谱与通过预测方程得到的反应谱比较示意图,其中,图2(a)中,m=5.5,r=10km;图2(b)中,m=6.0,r=10km;图2(c)中,m=5.5,r=30km;图2(d)中,m=6.0,r=30km;
图3为通过机器学习方法模拟的地震动时程示意图,其中,图3(a)中,m=5.5,r=10km;图3(b)中,m=6.0,r=10km;图3(c)中,m=5.5,r=30km;图3(d)中,m=6.0,r=30km;
图4为本发明的应用机器学习中支持向量机、主成分分析和粒子群算法合成地震动场的方法的方法流程图。
具体实施方式
下面将结合本发明实施例中的附图对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
参照图1-图4所示,应用机器学习中支持向量机、主成分分析和粒子群算法合成地震动场的方法,所述方法包括以下步骤:
步骤一、应用主成分分析方法从既有的国内地震动数据中提取地震动的母波;
步骤二、应用支持向量机算法建立地震动预测模型,并验证模型的正确性;
步骤三、通过步骤二三得到的地震动预测模型gmms,将特定场地参数(m,r,vs30)输入到gmms,预测特定场地的加速度反应谱;应用pca方法提取地震动母波,所述地震动母波和地震动具有相同的时间间隔,因此,合成的地震动由提取的地震动母波线性组而成,即
在本部分优选实施例中,在步骤一中,具体包括以下步骤:
步骤一一、选取强震数据库,数据库包括地震震源信息、强震台站信息和强震记录;
步骤一二、应用主成分分析pca从选取的地震动数据库中提取地震动母波,提取的地震动母波用于合成地震动记录。
在本部分优选实施例中,所述地震震源信息包括震级和断层机制,所述强震台站信息包括台站到震源距离和台站所在场点场地参数vs30,所述强震记录包括加速度时程、由加速度时程计算所得的峰值加速度pga和加速度反应谱sa。
在本部分优选实施例中,在步骤二中,具体包括以下步骤:
步骤二一、所述地震动预测模型考虑了震级m和距离衰减项r以及场地效应项vs30,结合地震学基本原理和强震观测数据集整体所表现出的基本特征选取合理的特征参数;
步骤二二、应用支持向量机svm回归地震动衰减关系,其中svm模型中三个重要参数的确定(c,ε和r)依据以下的选择原则:
步骤二三、按照svm训练地震动预测模型gmms,对训练得到的gmms分别进行测试级测试,以及与现有的比较成熟的模型比较,验证模型的准确性。
在本部分优选实施例中,在步骤三中,具体包括以下步骤:
步骤三一、通过步骤二三得到的地震动预测模型gmms,将特定场地参数(m,r,vs30)输入到gmms,预测特定场地的加速度反应谱;
步骤三二、应用pca方法提取地震动母波,所述地震动母波和地震动具有相同的时间间隔,因此,合成的地震动由提取的地震动母波线性组而成,即
步骤三三、合成的地震动的反应谱sa(t)与通过预测方程得到的反应谱sa*(t)相匹配,即
步骤三四、构建粒子群算法pso、自变量ki初始值、最大迭代次数、粒子的最大速度、粒子群的规模以及整个搜索空间;
步骤三五、个体极值以及全局最优解:个体极值为每个粒子找到的最优解,从最优解中找到一个全局值,叫做本次全局最优解,与历史全局最优比较,进行更新;
步骤三六、更新速度和位置公式:
vid=ωvid+c1random(0,1)(pid-xid)+c2random(0,1)(pgd-xid)
xid=xid+vid
其中,ω为惯性因子,当取值较大时寻优能力强,c1和c2为加速度常数,pid为个体极值,pgd为群体极值,xid为粒子当前的位置,vid粒子的速度,maxgen是迭代的次数;
步骤三七、设置迭代次数:当迭代次数达到设置迭代次数时,即停止计算,反复测试迭代次数,当误差值稳定时,得到的一组系数ki即为最优解;
步骤三八、合成的地震动即为
本发明共收集国内地震动8442条地震动记录。其中地震动记录都集中在中国西南地区。图1、图2、图3是以本发明做的一个震例分析,从图3中可以看出本文基于机器学习方法得到的合成地震动的反应谱能够较好的匹配预测方程反应谱。同时在频谱方面较好的保留了原始地震动特征。
- 还没有人留言评论。精彩留言会获得点赞!