视觉惯性激光数据融合的模块化无人车定位方法及系统与流程
本发明涉及智能汽车定位技术,尤其涉及一种视觉惯性激光数据融合的模块化无人车定位方法及系统。
背景技术:
随着社会经济和科学技术的飞速发展,人们出行的需求也越来越旺盛,汽车逐渐成为了人们生活中不可或缺的代步工具。经过多年发展,传统的汽车行业为了应对今后越来越复杂多变的需求,也兴起一股无人驾驶技术的研究热潮。诸如国内的有百度、华为、驭势等,国外的则有谷歌、特斯拉等科技公司和nvidia等芯片厂商都加入了无人驾驶技术的研发当中。目前国内各大高校也开始重视无人驾驶相关技术的开发。未来,汽车工业的转型,无人驾驶将成为主要的方向。
基于各种传感器的定位技术是无人驾驶中的关键技术,利用传感器获取的车辆环境与车辆自身的各种信息,计算得到车辆在环境中的准确位置。单独一种或两种传感器的定位方案如imu航迹推演、视觉惯性里程计、激光惯性里程计等,因为传感器自身的局限性难以在复杂环境(高速运动、弱光照环境等)下进行准确的定位,鲁棒性和准确性无法保证应用要求,多传感器的融合方案中如何合理利用各传感器的优势也是一大挑战。基于此背景,本文提出一种视觉惯性激光数据融合的模块化无人车定位方法及系统。
技术实现要素:
本发明要解决的技术问题在于针对现有技术中的缺陷,提供一种视觉惯性激光数据融合的模块化无人车定位方法及系统。
本发明解决其技术问题所采用的技术方案是:一种视觉惯性激光数据融合的模块化无人车定位方法,包括以下步骤:
1)采集获取无人驾驶汽车当前信息,包括通过单目相机采集的图像信息,激光雷达采集的三维点云信息以及imu采集的加速度及角速度数据;
2)根据步骤1)采集的无人驾驶汽车当前信息,进行汽车的位姿估计,获得无人驾驶汽车的位姿信息;
3)根据位姿估计的位姿信息建立多传感器融合的优化模型,根据优化模型得到车辆的最佳位姿,并将其转化至世界坐标系下,得到车辆的实时位姿;所述优化模型为基于传感器模型的imu测量误差、激光测量误差、相机测量误差设定误差函数,根据误差函数联立建立多传感器融合的优化模型。
按上述方案,所述步骤2)中获得无人驾驶汽车的位姿信息,具体如下:
通过对极几何约束从本质矩阵中计算单目相机的帧间运动信息(xv,yv,zv,αv,βv,γv),,(其中6个物理量分别表示欧式坐标系中在x,y,z三坐标轴中的平移与旋转量,下同),并通过路标点对比算法筛选单目图像的关键帧进行标记,对imu的测量数据进行预积分处理,然后与单目相机进行联合初始化,恢复单目相机的尺度,并估计系统的速度、陀螺仪零偏及重力方向,得到无尺度的位姿变换(xvi,yvi,zvi,αvi,βvi,γvi),即无人驾驶汽车的位姿信息。
按上述方案,所述步骤2)中获得无人驾驶汽车的位姿信息,具体如下:
2.1)通过对极几何约束从本质矩阵中计算单目相机的帧间运动信息(xv,yv,zv,αv,βv,γv):
利用orb特征点算法提取图像中的orb特征点,并通过采用flann算法将相邻两帧图像i和i+1的特征点匹配,利用对极几何约束,通过ransac算法来估计两幅图像的本质矩阵,对本质矩阵进行奇异值分解获得两帧图像之间的旋转矩阵r与平移向量t,并恢复为帧间相对位姿(xv,yv,zv,αv,βv,γv);
2.2)利用共视路标点算法筛选图像中的关键帧,并进行标记;
2.3)利用imu在i时刻的检测量
其中
按上述方案,所述步骤2.2)利用共视路标点算法筛选图像中的关键帧,具体为:
将先验关键帧的a个共视匹配特征点存储为路标点集合,获取单目相机传入的最新图像i,检测到i中共有b个特征点,其中有w个与路标点匹配,判断是否满足下式:
σwa和σwb分别为预先设置的阈值,如果满足则将i记录为新的关键帧,并将先验关键帧中的最旧帧删除。
按上述方案,所述步骤3)中优化模型的误差函数如下:
imu测量误差函数
其中,
相机测量误差函数
其中,
激光测量误差函数
其中,
其中,
对坐标
按上述方案,所述步骤3)中根据优化模型得到车辆的最佳位姿,是通过建立位姿优化模型的最小二乘问题,构建残差函数进行最小二乘的迭代优化,利用l-m法迭代优化该最小二乘问题,得到车辆的最佳位姿,其中残差函数为:
其中,
σ为视觉测量误差的权重系数,τ为激光测量误差的权重系数。
按上述方案,所述步骤3)中视觉测量误差的权重系数和激光测量误差的权重系数确定方法如下:
根据环境信息调控单目相机与激光雷达在优化中所占的权重,权重系数根据单目相机的关键帧共视路标点数和激光雷达点云数据的匹配特征数确定,设定两帧图像关键帧的最佳共视路标点数为a及两帧激光点云数据的最佳匹配特征点数为b,在每次建立优化模型前系计算当前关键帧共视路标点数a与最佳共视路标点数a比值a/a,计算当前激光点云匹配特征点数b与最佳匹配特征点数b比值b/b,视觉测量误差的权重系数σ=2×(a/a)/(b/b),激光测量误差的权重系数τ=2×[1-(a/a)/(b/b)]。
一种视觉惯性激光数据融合的模块化无人车定位系统,包括:
采集模块,用于采集获取无人驾驶汽车当前信息,包括通过单目相机采集的图像信息,激光雷达采集的三维点云信息以及imu采集的加速度及角速度数据;
位姿估计模块,用于根据无人驾驶汽车当前信息,进行汽车的位姿估计,获得无人驾驶汽车的位姿信息;
位姿优化模块,用于根据位姿估计模块的位姿信息建立多传感器融合的优化模型,根据优化模型得到车辆的最佳位姿,并将其转化至世界坐标系下,得到车辆的实时位姿;所述优化模型为基于传感器模型的imu测量误差、激光测量误差、相机测量误差设定误差函数,根据误差函数联立建立多传感器融合的优化模型。
按上述方案,所述位姿估计模块中获得无人驾驶汽车的位姿信息,具体如下:
1)通过对极几何约束从本质矩阵中计算单目相机的帧间运动信息(xv,yv,zv,αv,βv,γv):
利用orb特征点算法提取图像中的orb特征点,并通过采用flann算法将相邻两帧图像i和i+1的特征点匹配,利用对极几何约束,通过ransac算法来估计两幅图像的本质矩阵,对本质矩阵进行奇异值分解获得两帧图像之间的旋转矩阵r与平移向量t,并恢复为帧间相对位姿(xv,yv,zv,αv,βv,γv);
2)利用共视路标点算法筛选图像中的关键帧,并进行标记;
3)利用imu在i时刻的检测量
其中
按上述方案,所述位姿优化模块中优化模型的误差函数如下:
imu测量误差函数
其中,
相机测量误差函数
其中,
激光测量误差函数
其中,
其中,
对坐标
按上述方案,所述位姿优化模块中根据优化模型得到车辆的最佳位姿,是通过建立位姿优化模型的最小二乘问题,构建残差函数进行最小二乘的迭代优化,利用l-m法迭代优化该最小二乘问题,得到车辆的最佳位姿,其中残差函数为:
其中,
σ为视觉测量误差的权重系数,τ为激光测量误差的权重系数。
按上述方案,所述位姿优化模块中视觉测量误差的权重系数和激光测量误差的权重系数确定方法如下:
根据环境信息调控单目相机与激光雷达在优化中所占的权重,权重系数根据单目相机的关键帧共视路标点数和激光雷达点云数据的匹配特征数确定,设定两帧图像关键帧的最佳共视路标点数为a及两帧激光点云数据的最佳匹配特征点数为b,在每次建立优化模型前系计算当前关键帧共视路标点数a与最佳共视路标点数a比值a/a,计算当前激光点云匹配特征点数b与最佳匹配特征点数b比值b/b,视觉测量误差的权重系数σ=2×(a/a)/(b/b),激光测量误差的权重系数τ=2×[1-(a/a)/(b/b)]。
本发明产生的有益效果是:
1)本发明在位姿估计中弥补了单目视觉里程计的未知尺度,并修正了imu的零偏bias缺陷;
2)建立各传感器的误差函数,在位姿优化中对估计的位姿进行二次优化;
3)通过建立一种新的误差权重系数调节方式,对单目相机和激光雷达的测量误差根据环境场景进行权重系数的动态调节,最终通过滑动窗口和l-m法得到车辆实时地精确定位信息;
4)本发明提高了传统定位方法的环境适应性,能够满足在复杂环境下无人驾驶车辆定位的精确性和鲁棒性要求,适用于无人驾驶车辆的复杂环境下的定位。
附图说明
下面将结合附图及实施例对本发明作进一步说明,附图中:
图1是本发明实施例的结构示意图;
图1是本发明实施例的系统结构示意图;
图2是本发明实施例的单目视觉里程计的原理流程图;
图3是本发明实施例的单目视觉里程计中本质矩阵奇异值分解得到四种r、t的示意图;
图4是本发明实施例的imu预积分与单目相机的联合初始化方法流程图;
图5是本发明实施例的误差函数权重系数动态调节的方法流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
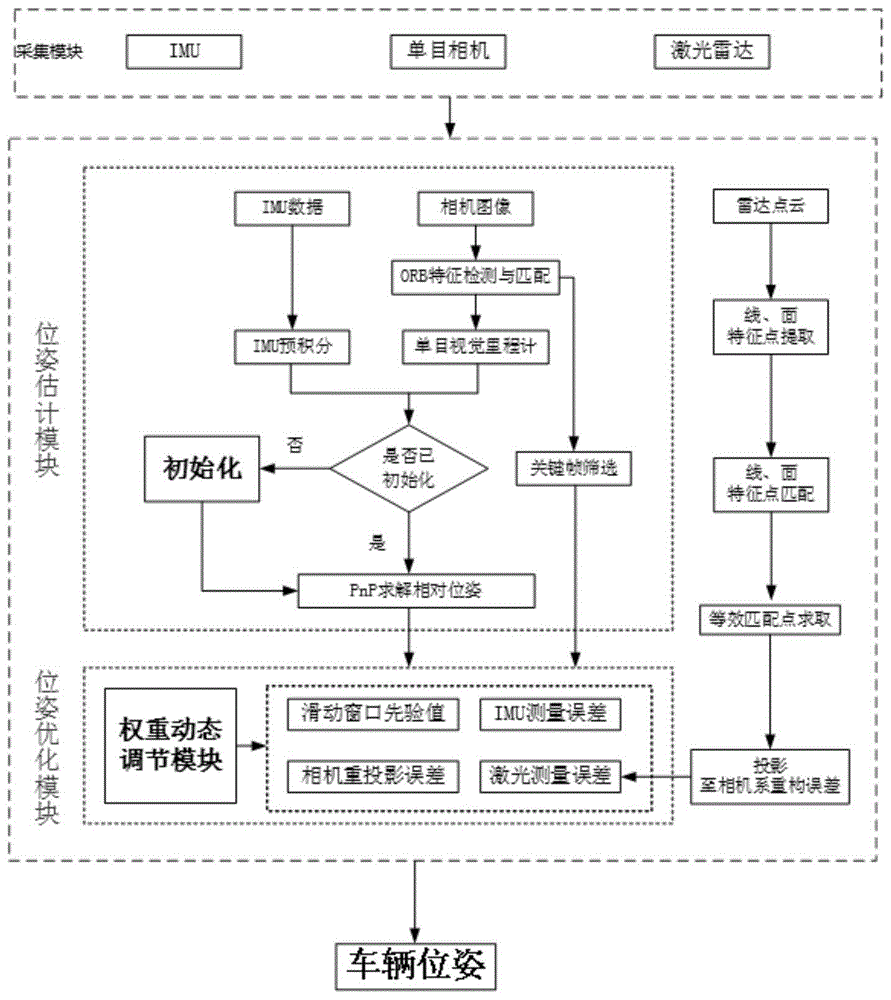
如图1所示,一种视觉惯性激光数据融合的模块化无人车定位系统,采集模块涉及的传感器包括imu、激光雷达、单目相机,将三种传感器的实时检测数据传入系统内处理模块处理,系统进行多模块的分离式设计,位姿估计模块通过imu与单目相机进行联合初始化解决单目视觉里程计的尺度问题;位姿优化模块接受位姿估计模块传入的位姿信息,建立多传感器融合的优化模型,并根据不同环境动态调节相机与激光雷达在优化中的比重,通过滑动窗口法得到车辆在世界坐标系下的最优定位信息。
如图1,具体实施过程为:
采集模块,当无人驾驶车辆在环境中运行驶时,采集模块通过三种传感器实时检测车辆的周围环境,激光雷达提供周围环境的三维点云数据,单目相机提供连续图像帧组成的视频流,imu提供车辆自身的加速度和角速度信息,传感器的数据上传给系统的位姿估计模块,处理步骤如下:
如图2,
1)首先位姿估计模块接收单目相机的视频流信息,进行单目视觉里程计的计算,步骤如下:
(1)系统从视频流中获取相邻两帧图像i和i+1,通过张正友标定法获取相机的内部参数和畸变参数,利用畸变参数对图像进行去畸变处理。
(2)通过orb算法检测图像i和i+1的orb特征点,如果特征点数未达到预期,则重新检测;
(3)通过对比二进制形式的brief描述子的汉明距离,汉明距离即二进制数相同位数的个数,并采用flann算法将i和i+1的特征点匹配,判定特征点匹配数,如果小于某个阈值,则重新进行特征点检测;
(4)通过ransac算法来估计两幅图像的本质矩阵e,对本质矩阵e进行奇异值分解e=u∑vt,则:
如图3,此时得到旋转矩阵r与平移向量t有四种结果,只有图3(d)是所需要求解的运动,通过检测点p在两个相机下的深度,当两个深度均为正时,所得到的r、t则为需要的解,最后利用三角测量恢复深度,输出带有尺度的视觉里程计的相对位姿(xv,yv,zv,αv,βv,γv);
在进行单目视觉里程计计算的同时,前端位姿估计模块同步地筛选图像序列中的关键帧,将先验关键帧的a个共视匹配特征点存储为路标点集合,获取单目相机传入的最新图像i,检测到i中共有b个特征点,其中有w个与路标点匹配,判断是否满足
2)对单目视觉里程计的结果进行尺度恢复操作,该操作是通过建立的imu预积分与单目相机的联合初始化完成,具体步骤如图4所示:
(1)建立旋转约束
(2)建立待估参数向量
(3)建立最小二乘方程
其中
3)利用恢复的尺度信息将视觉里程计的位姿恢复至世界坐标系中得到(xvi,yvi,zvi,αvi,βvi,γvi),极大地提高了前段位姿优化的精确度。
位姿优化模块:
视觉惯性激光数据融合的位姿估计模块位姿估计完成后,位姿优化模块将接受位姿估计模块对位姿进行进一步的优化,具体过程如下:
1)建立位姿优化模块优化模型的误差函数,包括三种传感器的数据,首先是imu测量误差:
其中,其中,
2)然后建立位姿优化模块优化的相机测量误差:
其中,
3)为了位姿优化模块优化的误差模型形模型的复杂度,本申请提出了一种激光雷达点云数据的点对点匹配算法,具体步骤为:通过kd-tree方法找寻相邻两帧激光点云间的点-线匹配和点-面特征匹配,点
求解其匹配点的约束方程得到匹配点
建立激光测量误差函数,将其转换为视觉测量误差的相同形式,首先计算激光特征的点-点匹配,得到两帧激光点云的匹配点
其中
融合三种传感器的误差函数,建立权重动态调节模块,根据环境信息调控单目相机与激光雷达在优化中所占的权重,权重系数根据单目相机的关键帧共视路标点数和激光雷达点云数据的匹配特征数,具体步骤如图5:
系统将设定两帧图像关键帧的最佳共视路标点数为a及两帧激光点云数据的最佳匹配特征点数为b,在每次建立优化模型前系统计算当前关键帧共视路标点数a与最佳共视路标点数a比值a/a,计算当前激光点云匹配特征点数b与最佳匹配特征点数b比值b/b,于是视觉测量误差的权重系数σ与激光测量误差的权重系数τ计算为:
系统建立视觉惯性激光数据融合的模块化无人车定位方法的位姿优化模块的优化模型,将位姿估计模块估计的位姿传入位姿优化模块进行滑动窗口优化,具体步骤为:
导入算法位姿估计模块估计的位姿,并筛选其中关键帧的位姿
其中,
利用l-m法优化该最小二乘问题,得到优化后得最佳位姿,并将其转化至世界坐标系下,得到车辆实时位姿pvil=(xvil,yvil,zvil,αvil,βvil,γvil)。
根据上述系统的介绍,我们容易获得对应的定位方法,,包括以下步骤:
1)采集获取无人驾驶汽车当前信息,包括通过单目相机采集的图像信息,激光雷达采集的三维点云信息以及imu采集的加速度及角速度数据;
2)根据步骤1)采集的无人驾驶汽车当前信息,进行汽车的位姿估计,获得无人驾驶汽车的位姿信息;
通过对极几何约束从本质矩阵中计算单目相机的帧间运动信息(xv,yv,zv,αv,βv,γv),并通过路标点对比算法筛选单目图像的关键帧进行标记,对imu的测量数据进行预积分处理,然后与单目相机进行联合初始化,恢复单目相机的尺度,并估计系统的速度、陀螺仪零偏及重力方向,得到无尺度的位姿变换(xvi,yvi,zvi,αvi,βvi,γvi),即无人驾驶汽车的位姿信息。
3)根据位姿估计的位姿信息建立多传感器融合的优化模型,根据优化模型得到车辆的最佳位姿,并将其转化至世界坐标系下,得到车辆的实时位姿;所述优化模型为基于传感器模型的imu测量误差、激光测量误差、相机测量误差设定误差函数,根据误差函数联立建立多传感器融合的优化模型。
3.1)导入位姿估计的位姿,并筛选其中关键帧的位姿
建立优化模型的视觉测量误差:
建立优化模型的imu测量误差:
通过近似匹配的思想,将点对线或点对面的激光点云特征匹配转换成点对点的特征匹配,通过求解下列约束方程:
通过kd-tree方法找寻相邻两帧激光点云间的点-线匹配和点-面特征匹配。第k帧点云中的点
同样地,点
建立视觉测量误差相同形式的优化模型的激光测量误差
利用近似匹配点思想计算激光特征的点-点匹配,得到两帧激光点云的匹配点
将匹配点转换至相机坐标系下:
其中
对坐标
计算重构后的激光测量误差为:
3.2)定位姿估计模块中的误差函数权重系数动态调节;
环境信息调控单目相机与激光雷达在优化中所占的权重,权重系数根据单目相机的关键帧公式路标点数和激光雷达点云数据的匹配特征数进行动态调节。系统将设定两帧图像关键帧的最佳共视路标点数为a及两帧激光点云数据的最佳匹配特征点数为b,在每次建立优化模型前系统计算当前关键帧共视路标点数a与最佳共视路标点数a比值a/a,计算当前激光点云匹配特征点数b与最佳匹配特征点数b比值b/b,于是视觉测量误差的权重系数σ=2×(a/a)/(b/b),激光测量误差的权重系数τ=2×[1-(a/a)/(b/b)]。
3.3)将估计的位姿传入位姿优化模型进行滑动窗口优化,具体步骤为:
导入算法位姿估计中的位姿,并筛选其中关键帧的位姿
建立优化模型优化的最小二乘问题,构建系统的残差函数进行最小二乘的迭代优化:
其中,
3.4)利用l-m法优化该最小二乘问题,得到优化后得最佳位姿,并将
其转化至世界坐标系下,得到车辆实时位姿pvil=(xvil,yvil,zvil,αvil,βvil,γvil)。
本发明在位姿估计模块利用imu的预积分模型与单目相机进行联合的初始化,弥补了单目视觉里程计的未知尺度,并修正了imu的零偏bias缺陷,在位姿优化模块利用滑动窗口法对估计的位姿进行二次优化,建立各传感器的误差函数,将三种传感器的数据融合在一起,并通过建立一种新的误差权重系数调节方式,对单目相机和激光雷达的测量误差根据环境场景进行权重系数的动态调节,最终通过滑动窗口和l-m法得到车辆实时地精确定位信息,本发明提高了传统定位方法的环境适应性,能够满足在复杂环境下无人驾驶车辆定位的精确性和鲁棒性要求,适用于无人驾驶车辆的复杂环境下的定位。
应当理解的是,对本领域普通技术人员来说,可以根据上述说明加以改进或变换,而所有这些改进和变换都应属于本发明所附权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!