基于聚类分析监测片剂包衣终点的方法及其应用与流程
本发明涉及一种薄膜包衣终点判别方法,具体涉及基于聚类分析监测片剂包衣终点的方法及其应用。
背景技术:
近年来,近红外光谱结合判别模式分析技术,由于可直接对样品进行快速、无损检测,而被广泛应用于制药行业的过程分析技术。该技术已用于缓控释制剂、糖包衣片、滴丸、肠溶片、中药片剂包衣及在线监测等包衣终点判断领域的研究。
聚类分析是一种无监督学习方法,在没有任何先验信息条件下,将现有无标记数据进行归类,其中,聚类分析处理的数据集中是不存在类别归属标识。但是,在有监督学习方法中,数据分类方法所使用的数据是已知类别归属的。这是聚类与分类二者的主要区别。目前,聚类分析算法可大致分为以下几种:基于划分的算法、基于层次的算法、基于密度的算法、基于网格的算法和基于模型的算法等。
现有技术中,已报道的有公开申请cn108318440a“一种利用近红外指纹光谱技术快速判断片剂包衣终点的方法”,其公开了利用近红外技术结合正交偏最小二乘判别分析模型对包衣终点进行判断;另外文献如夏春燕等发表的“近红外光谱快速预测天舒片包衣终点研究”,利用近红外技术集合nirs判别模型对包衣终点进行判断。但是采用近红外结合聚类识别模型,尚鲜有报道。
技术实现要素:
本发明的目的在于提供基于聚类分析监测片剂包衣终点的方法及其应用。该法将采集到的片剂薄膜包衣全过程内样品和薄膜包衣标准片的近红外光谱,经预处理得到特征峰信息,并建立系统聚类识别模型,对薄膜包衣终点判断,具有快速、便捷、无损、精度高的优点,能够保证不同批次间衣膜质量具有良好的均一性。
为了实现上述目的,本发明采用以下技术方案:
一方面,提供了基于聚类分析监测片剂包衣终点的方法及其应用,包括以下步骤:
(1)采集薄膜包衣标准片和待测片剂,两种片剂薄膜包衣全过程内样品的近红外光谱;
(2)将步骤(1)获取的近红外光谱确定有效光谱波长范围,再经预处理得到特征峰信息;
(3)利用步骤(2)获得的特征峰信息,建立近红外光谱系统聚类识别模型;
(4)运用步骤(3)聚类识别模型对待测片剂薄膜包衣全过程内样品的薄膜包衣进度和薄膜包衣终点情况进行判断。
进一步地,步骤(3)中构建聚类识别模型,具体步骤为:
将特征峰信息导入建模软件进行聚类建模,薄膜包衣标准片每个时间点的平均光谱设为训练集,使用euclidean距离测量方法,聚类数为5,形成五个聚类簇的识别模型;待测片剂的特征峰信息作为测试集,计算待测片剂到每个标准片平均光谱的距离,将待测片剂归属到与标准片距离最近的簇中。
更进一步地,五个聚类分别为第一类:片芯;第二类:薄膜包衣初期;第三类:薄膜包衣进展期;第四类:薄膜包衣近终期;第五类:薄膜包衣终点期。
更进一步地,五个聚类簇的结果展示,采用树状图和表格形式。
进一步地,步骤(1)中薄膜包衣全过程内样品包括片芯、不同薄膜包衣时间但未进入薄膜包衣终点的中间片和薄膜包衣成品片。
进一步地,步骤(2)中预处理是标准化处理。
另一方面,提供了一种上述方法应用于制药领域中薄膜包衣片的薄膜包衣进度监测及预测薄膜包衣终点。
本发明有益效果:
1.本发明采用近红外光谱技术,结合聚类方法进行薄膜包衣进度识别,一方面利用了近红外光谱技术快速、便捷、无损的优点;另一方面利用聚类模型结构简单,易于理解,是一种无监督方法,适用于未标明类别的数据,聚类模型不仅可以用于终点判断,还可以实现全过程检测,对于生产过程和生产质量,能及时有效监测和控制。
2.本发明采用的系统聚类方法,可根据聚类的实际情况选择适当的分类,在最后结果展示上,采用树状图展示聚类结果,可以直观的看到每个丛集。系统聚类是一种常用的聚类方法,它既可以对样本聚类,也可以对变量聚类,变量可以是连续型变量也可以是分类变量。此外,它的类间距离计算方法也十分丰富,本专利采用组间连接法。
附图说明
图1是地格达-4味汤片薄膜包衣标准片的近红外原始光谱;
图2是地格达-4味汤片薄膜包衣标准片的近红外平均光谱;
图3是地格达-4味汤片薄膜包衣标准片经标准化处理的近红外光谱;
图4是地格达-4味汤片薄膜包衣系统聚类模型图。
具体实施方式
下面结合实施例对本发明做进一步的描述,有必要在此指出的是以下实施例只是用于对本发明进行进一步的说明,不能理解为对本发明保护范围的限制,该领域的技术熟练人员根据上述发明内容所做出的一些非本质的改进和调整,仍属于本发明的保护范围。
在本申请中所述的薄膜包衣标准片,是指通过实验或专家确定的进入薄膜包衣终点的薄膜包衣片,具体的是指符合药典标准的薄膜包衣片或经过防潮实验、崩解实验、口感评价、溶出度等实验确定进入薄膜包衣终点的薄膜包衣片。
下面通过具体的建立近红外光谱聚类识别模型实验,来进行说明,包括如下步骤:
1.采集薄膜包衣标准片和待测片剂,从片芯开始抽样,不同薄膜包衣时间的中间片和薄膜包衣成品片进行近红外漫反射的光谱。
在本申请中所述的薄膜包衣标准片,是指通过实验或专家确定的进入薄膜包衣终点的薄膜包衣片,具体的是指符合药典标准的薄膜包衣片或经过防潮实验、崩解实验、口感评价、溶出度等实验确定进入薄膜包衣终点的薄膜包衣片。
2.计算各时间点样品的光谱数据平均值,确定有效光谱波长范围,再经预处理得到特征峰信息。
3.采用系统聚类为例,对标准片各时间点的平均光谱数据聚类建模。
4.根据聚类效果,五个聚类分别为第一类:片芯;第二类:薄膜包衣初期;第三类:薄膜包衣进展期;第四类:薄膜包衣近终期;第五类:薄膜包衣终点期。
5.采用训练得到的系统聚类模型对标准片各时间点的其他光谱数据预测,判断标准片各时间点光谱数据的平均光谱能否较好地代表该时间点的全部光谱数据。采用训练得到的系统聚类模型对两批待测片剂各时间点的光谱数据进行预测,对薄膜包衣进度检测和薄膜包衣终点的快速判断。
实施例1
将本发明的方法应用于地格达-4味汤片薄膜包衣进度监测和终点的快速判断,地格达-4味汤片的薄膜包衣材料为欧巴代胃溶型黄色薄膜包衣粉。
1.实验材料
(1)实验仪器:
micronironsite便携式近红外光谱仪(viavisolutions公司);pycharmcommunityedition2020.1.2作为数据分析处理软件;ht/f700无孔包衣机(意大利immergas公司)。
扫描条件:样品扫描前,先将便携式近红外光谱仪开启预热20min,待温度稳定再开始扫描样品。本法采用积分球漫反射模式采集样本光谱。
采集条件:光谱扫描范围908-1678nm,积分时间7.9ms,扫描次数100次,分辨率6.2nm,扫描环境参数为:温度23℃±3℃,湿度25%±4%。每份样片正反面各采集三张光谱,再将光谱平均,所得到的平均光谱作为该样品的最终光谱。
(2)实验样品:
一批次地格达-4味汤片标准片,两批次为待测片剂,包括其片芯、多个不同薄膜包衣时间的中间片、薄膜包衣成品片。
2.实验方法和结果
2.1获取近红外原始平均光谱
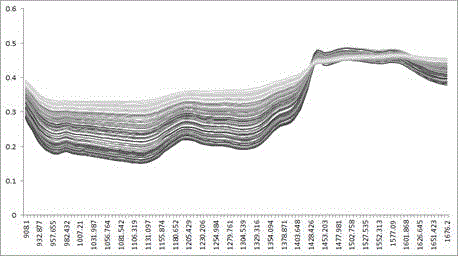
将实验样品,按扫描条件和测试条件获得样品近红外原始光谱,如图1所示,其中横坐标为波长,纵坐标为吸光度;近红外原始光谱经近红外平均化处理后得近红外平均光谱,如图2所示,其中横坐标为波长,纵坐标为吸光度。
2.2近红外原始平均光谱标准化处理
对近红外平均光谱,选择待测片剂与标准片相同波长的数据,并经预处理,预处理后的近红外光谱,如图3所示,其中横坐标为波长,纵坐标为吸光度。
2.3薄膜包衣近红外指纹光谱快速判别方法的建立
标准片和两批薄膜包衣片剂样品,将每一批样品按照时间划分为一类,标准片为训练集,两批薄膜包衣片剂样品为测试集,数据相关说明见表1,将数据导入pycharmcommunityedition2020.1.2建模软件中进行聚类建模,使用euclidean距离区间测量方法,聚类数设为5,得到预测模型。
表1.三批次时间点标识意义及作用
将标准片各时间点的平均光谱数据集导入pycharmcommunityedition2020.1.2软件中进行系统聚类,得到结果如图4所示。
图4中,横坐标为时间点标识,纵坐标为欧式距离。从图4中可知,第一类:sp,表明片芯;第二类:t10m,t20m,t30m,表明薄膜包衣初期;第三类:t40m,t50m,表明薄膜包衣进展期;第四类:t60m,t70m,t80m,t90m,t100m,表明薄膜包衣近终期;第五类:t110m,t120m,t130m,zy(终点),表明薄膜包衣的终点期。
采用标准片各时间点平均光谱训练的系统聚类模型,测试标准片的全部数据(有15个时间点,每个时间点有60个样本,共900个样本),均值代表性是指与参照时间点的均值光谱在同一簇中的光谱数量在该时间点所有光谱数量的占比,结果如表2所示。
表2.标准片数据各时间点的分类情况
表2中,可以清晰地每个时间点的所有样本处于薄膜包衣的哪个过程,有益于薄膜包衣进度的实时监测和终点的快速判断。此外,大多数时间点的均值代表性都较强,而个别处于簇间相邻时间点的均值代表性稍弱是合理的,由于薄膜包衣过程本身存在细微的差异导致相邻时间点的样本难以完全分开。
采用标准片训练的系统聚类模型,测试第一批所有数据(有14个时间点,每个时间点有60个样本,共840个样本),每个时间点的类别由该时间点的多数样本决定,如表3所示。
表3.第一批测试数据各时间点的分类情况
表3中,第一批数据的1sp、1t10m与标准片薄膜包衣过程中的片芯数据归于一类;第一批数据的1t20m、1t30m与标准片的薄膜包衣初期(t10m、t20m、t30m)数据归于一类;第一批数据的1t40m与标准片的薄膜包衣进展期(t40m,t50m)数据归于一类;第一批数据的1t50m、1t60m、1t70m、1t80m与标准片的薄膜包衣近终期(t60m、t70m、t80m、t90m、t100m)数据归于一类;第一批数据的1t90m、1t100m、1t110m、1t120m、1zy与标准片的薄膜包衣终期(t110m、t120m、t130m、zy)数据归于一类。结果表明:第一批测试数据在90分钟就达到了薄膜包衣终点进入期,在120分钟达到所有数据达到薄膜包衣终点期,薄膜包衣进度更快;另外,第一批数据片芯和10分钟分为一类是合理的,因为在实际薄膜包衣过程中,薄膜包衣10分钟的片剂所含衣膜材料非常少,与片芯无明显差别。因此,第一批测试数据薄膜包衣有序地进行、薄膜包衣进展比标准片数据快、有终点期且稳定时间段较长。
采用标准片训练的系统聚类模型,测试第二批所有数据(有14个时间点,每个时间点有30个样本,共420个样本),每个时间点的类别由该时间点的多数样本决定,如表4所示。
表4.第二批测试数据各时间点的分类情况
表4中,第二批数据的2sp、2t10m、2t20m与标准片薄膜包衣初期(t10m、t20m、t30m)数据归于一类;第二批数据的2t30m、2t40m与标准片薄膜包衣进展期(t40m、t50m)数据归于一类;第二批数据的2t50m、2t60m、2t70m、2t80m、2t90m、2t100m与标准片薄膜包衣近终期(t60m、t70m、t80m、t90m、t100m)数据归于一类;第二批数据的2t110m、2t120m、2t132m与标准片薄膜包衣终期(t100m、t110m、t120m、t130m、zy)数据的归于一类。结果表明:1)第二批测试数据的片芯、薄膜包衣10分钟、20分钟与标准片的薄膜包衣初期分为一类是合理的,因为实际薄膜包衣过程中,薄膜包衣初期的片剂所含衣膜材料非常少,片剂与片芯无明显差别。2)第二批测试数据50分钟就进入了薄膜包衣近终期,表明前面40分钟薄膜包衣进度较快;此外,近终期的持续时间段较长,表明这个过程薄膜包衣速度有所减缓。3)第二批测试样本在110分钟到达了薄膜包衣终点进入期,薄膜包衣进度与标准片一样。因此,第二批测试数据整体薄膜包衣进展与标准片差不多、薄膜包衣近终期持续时间较长、有终点期。
由上述实验结果表明:(1)预测第一批的薄膜包衣终点偏向于90分钟,第二批数据的薄膜包衣终点偏向于110分钟;(2)第一批和第二批样品的片芯和薄膜包衣初期的片剂相差不明显,易分于同一类别中,这表明生产过程中,薄膜包衣初期的片剂衣膜材料非常少,与片芯无明显差别。因此,本模型判别能力良好,可快速识别未知样品的薄膜包衣进度和终点。
另外,系统聚类具有以下优点:(1)系统聚类是一种常用的聚类方法,它既可以对样本聚类,也可以对变量聚类,变量可以是连续型变量也可以是分类变量。此外,它的类间距离计算方法也十分丰富,包括最短距离法、最长距离法、中间距离法、组间连接法、组内连接法等。(2)系统聚类的结果以树状图显示,直观形象、易于理解。
- 还没有人留言评论。精彩留言会获得点赞!