一种预测汽油辛烷值的方法与流程
1.本发明涉及一种预测汽油辛烷值的方法,特别涉及一种利用近红外光谱预测汽油辛烷值的方法。
背景技术:
2.辛烷值是汽油的一个重要品质指标,汽油牌号一般以辛烷值命名,因此辛烷值的正确测量是十分重要的。测定汽油辛烷值的传统方法是台架试验,但操作和维护复杂,运行费用高,因此测定成本高。近红外(near infrared,nir)光谱分析方法具有测定快速、可在线分析等优点而受到广泛的关注和研究。
3.光谱定量分析是一种新兴的、快速的分析技术,将它和化学计量学与计算机技术结合起来,可以对研究对象进行快速定量。近些年来,红外、近红外光谱技术与多元分析方法的结合在各个领域都取得了长足发展。石油及石化产品以烃类为主,产品的性质大多取决于其组成,这是红外光谱分析技术可以用于石油及石化产品性质预测的基础。红外、近红外光谱技术具有操作简单、精密度高、分析速度快等优点,非常适合原油及油品的定量和定性分析。近红外光谱法快速测定汽油辛烷值的本质是利用汽油在近红外光谱区的c-h振动倍频信号提供的丰富信息,建立光谱数据与辛烷值的数学模型,红外、近红外光谱(nir)分析技术进行油品快速分析的核心建立稳健的定量校正模型,建模常用的线性校正方法有多元线性回归(mlr)、偏最小二乘(pls)等。
4.但若仪器运行一段时间后光谱采集条件发生一定变动时,模型的预测准确性会明显变差,产生所谓的界外样本,模型界外样本包括三类:浓度界外样本,即使用马氏距离(md)检测未知样本的浓度是否超出了校正样本的浓度范围;光谱残差界外样本,即使用光谱残差均方根(rmssr)检测未知样本是否含有校正集样本不存在的组分;最邻近距离界外样本,即使用最邻近距离检测未知样本是否位于校正集样本分布稀疏的区域。当未知样本的光谱残差、马氏距离和最邻近距离中有任何一项超出相应阈值时,则说明该样本为模型界外样本,其预测结果的准确性将受到较大质疑,为了提高模型的稳健性(或适应性),一般可将界外样本添加进校正集内重新建模以提高模型试用范围,但该样本数量过少的话可能很难被模型接纳。
5.褚小立在《支持向量回归建立成品汽油通用近红外校正模型的研究》(分析测试学报,2008,27(6):619-622)一文中,针对目前采用偏最小二乘法建立成品汽油分析模型存在的问题,采用近几年新兴的支持向量回归方法建立了多种汽油标号通用的校正模型,其预测能力优于对应的偏最小二乘法,对汽油研究法辛烷值、烯烃和芳烃的预测标准偏差分别为0.37、1.28%和1.38%,可应用于实际汽油管道自动调合的近红外光谱在线分析。
6.高俊在《人工神经网络用于近红外光谱预测汽油辛烷值》(分析科学学报,2006,22(1):71-74)一文中,对bp人工神经网络(ann)方法在汽油的辛烷值与其近红外光谱光谱吸光度之间的关联预报进行了研究,采用35个汽油实际样本数据,建立了利用汽油的近红外光谱吸光度来预测汽油辛烷值的bp人工神经网络模型,该模型对所有辛烷值的计算结果与
实测值进行了比较,得到的预测值与实测值的计算误差小于1.55。
技术实现要素:
7.本发明的目的是克服现有技术的不足,提供一种分析速度快、测试准确、重复性好的近红外光谱预测汽油辛烷值的方法。
8.本发明提出了一种预测汽油辛烷值的方法,包括如下步骤:
9.(1)获取已知辛烷值汽油样本的近红外光谱,建立校正集与任选的验证集;
10.(2)按相同的差减方法,获取校正集近红外光谱的差谱,以及与所述差谱相对应的辛烷值差值;
11.(3)建立校正集近红外光谱的差谱与辛烷值差值之间的关联模型;
12.(4)测定待测汽油样本的近红外光谱,从校正集中找到与待测汽油样本最邻近的光谱,计算两者之间的差谱,通过步骤(3)中的关联模型计算该差谱所对应的辛烷值差值,与所述最邻近光谱所对应汽油样本的辛烷值相加,得到待测汽油的辛烷值。
13.根据本发明,可选地,在步骤(1)中,收集已知辛烷值的n个汽油样本,采集每个样品的近红外光谱,作为校正集,n为大于等于5的整数;任选地,随机选取一个或多个成品汽油样本,作为验证集。
14.根据本发明,可选地,在步骤(1)中,对校正集中近红外光谱的吸光度变量进行微分预处理,选择预设谱区,得到包含n条光谱的光谱矩阵x,根据校正集所对应的汽油样本中的辛烷值得到包含n个辛烷值的辛烷值矩阵y。所述微分预处理可以为一阶微分预处理或二阶微分预处理。
15.根据本发明,在步骤(1)中,优选地,选择波数为7000-7500cm-1
和/或8200-8700cm-1
的光谱谱区作为预设谱区。
16.根据本发明,在步骤(1)中,可以在室温采集每个样本的近红外光谱,也可以在高于室温或低于室温的条件下采集,只要在相同温度下采集即可,并没有特别的限定。
17.根据本发明,在步骤(1)中,优选地,按照校正集所对应的汽油样本中辛烷值的大小,对所述光谱矩阵x和辛烷值矩阵y进行从低到高排序,得到光谱矩阵xs和辛烷值矩阵ys。
18.根据本发明,在步骤(1)中,在光谱矩阵xs中具有从第1条到第n条的n条光谱,在辛烷值矩阵ys具有对应所述n个汽油样本的n个辛烷值,第1个辛烷值为辛烷值矩阵ys中的最低值,对应辛烷值最低的汽油样本,第n个辛烷值为辛烷值矩阵ys中的最高值,对应辛烷值最高的汽油样本,所述相同的辛烷值可以对应一个汽油样本,也可以对应多个汽油样本。
19.根据本发明,可选地,在步骤(2)中,按相同的差减计算方法,分别计算光谱矩阵xs中n条光谱之间的差谱和辛烷值矩阵ys中n个辛烷值之间的差值,得到包含n’条光谱的差谱矩阵和包含n’个辛烷值差值的辛烷值差值矩阵。
20.根据本发明,在步骤(2)中,优选地,按相同的差减计算方法,分别计算光谱矩阵xs中第i条光谱与第1条至第(i-1)条光谱之间的差谱,分别计算辛烷值矩阵ys中第i个辛烷值与第1个至第(i-1)个辛烷值之间的差值,得到包含(n-1)
×
n/2条光谱的差谱矩阵xc和包含(n-1)
×
n/2个辛烷值差值的辛烷值差值矩阵yc;其中i为大于1小于等于n的整数。由于差谱矩阵中光谱数目较多,可以按规定间隔分别选取差谱矩阵中的部分光谱作为校正集,例如可以按顺序选取差谱矩阵中的第1个、第6个、第11个、
…
作为校正集。
21.根据本发明,在步骤(3)中,优选地,采用多元回归分析方法建立差谱矩阵xc和辛烷值差值矩阵yc的关联模型,所述多元回归分析方法包括偏最小二乘(pls)、多元线性回归(mlr)和主成分回归(pcr)方法中的一种或多种,更优选地,采用偏最小二乘法建立差谱矩阵xc和辛烷值差值矩阵yc的关联模型。
22.根据本发明,在步骤(3)中,任选地,利用已知辛烷值的汽油样本组成验证集,获取其近红外光谱,按相同的差减方法,获取验证集近红外光谱的差谱,以及与所述差谱相对应的辛烷值差值,代入关联模型计算辛烷值,来验正关联模型的准确性。
23.根据本发明,在步骤(4)中,优选地,通过计算移动窗口相关系数或欧式距离,从光谱矩阵x中找到与待测汽油样本最邻近的光谱。
24.根据本发明,在步骤(4)中,优选地,所述移动窗口相关系数q的计算方法为:
[0025][0026]
其中r
p
为相关系数,p为移动窗口的序号,n为移动窗口总数;
[0027]
所述相关系数r
p
的计算公式如下:
[0028][0029]
式中,分别为第i个和第j个光谱或光谱区间所有波数点吸光度的均值,n为波数采样点数,k为波数采样序号,x
ik
、x
jk
分别为第i个和第j个光谱或光谱区间内第k个吸光度变量。两个光谱越接近,它们之间的移动窗口相关系数的绝对值越接近于1。
[0030]
根据本发明,在步骤(4)中,优选地,所述欧式距离的计算方法为:
[0031][0032]
其中,n为变量的维度,j,k为两个光谱样本,ji,ki为j,k为两个光谱样本的第i个吸光度。
[0033]
本发明方法分析速度快,测试准确,重复性好,适用于快速预测汽油样品的辛烷值。
附图说明
[0034]
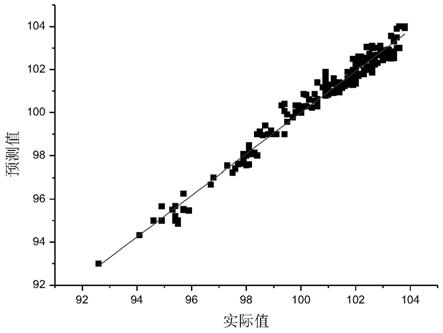
图1为本发明方法得到的辛烷值实际值与预测值的对比图。
[0035]
图2为本发明对比例方法得到的辛烷值实际值与预测值的对比图。
具体实施方式
[0036]
本发明采用操作较为简便的近红外光谱测量汽油的辛烷值,通过计算差谱扩大校正集范围,选择近红外光谱的特征谱区,进行差谱处理,再将该差谱与汽油样品的辛烷值相关联,通过多元回归分析建立关联模型,然后通过关联模型,由未知样品在所选特征谱区的光谱即可预测待测汽油样品的辛烷值。
[0037]
近红外光谱是由于分子的振动—转动能级跃迁而产生的。习惯上,往往把波长为2500~25000nm(波数4000~400cm-1
)的谱区称为中红外(简称红外)区,把波长为780~2500nm(波数12820~4000cm-1
)的谱区称为近红外区。
[0038]
建立关联模型时,所选样品的数量越多,所建模型越准确、可靠。但实际操作中为减少工作量,一般选取适当数量且能涵盖所有可能预测值的样品,优选不同类型的样品数量为300-500个,如果差谱矩阵的数目较多,对差谱矩阵和辛烷值矩阵每5个样本取一个作为校正集样本(例如可以为第1个,第6个,第11个,
…
)。
[0039]
为检验关联模型的准确性,一般将汽油样本分成校正集和验证集。校正集样品数量较多,并且具有代表性,即校正集汽油样本中的辛烷值应涵盖所有预先测定的汽油样本中的辛烷值。而验证集则是随机抽取,将其作为未知样本,来验正关联模型的准确性。在本发明中,验证集样本可以是收集的各炼厂出产的成品汽油样本。
[0040]
用近红外光谱仪测定其近红外光谱,然后可以对所选谱区光谱的吸光度变量进行一阶或二阶微分处理,以消除干扰。
[0041]
关联模型是差谱和辛烷值差值之间的数学关系。按照辛烷值的大小对光谱矩阵x和辛烷值矩阵y进行从低到高排序,得到光谱矩阵xs和辛烷值矩阵ys。计算差谱,对第i条光谱,分别计算与第1条光谱的差谱、与第2条光谱的差谱、
…
、与第(i-1)条光谱的差谱,其中i为1~n之间的整数;即,对光谱矩阵xs的第2条光谱:计算与第1条光谱的差谱,对第3条光谱:分别计算与第1条光谱的差谱、与第2条光谱的差谱;对第4条光谱:分别计算与第1条光谱的差谱、与第2条光谱的差谱、与第3条光谱的差谱;以此类推,对光谱矩阵xs中的n条光谱,可以得到1+2+3+
…
+(n-1)条差谱。对辛烷值矩阵ys也做相同的差减计算,获得与所述差谱对应的1+2+3+
…
+(n-1)个辛烷值差值。
[0042]
本发明方法优选采用偏最小二乘法(pls)建立关联模型,然后用验证集样本在7000-7500cm-1
和/或8200-8700cm-1
谱区的光谱代入校正模型,预测其辛烷值,再与其实际辛烷值进行比较,以验证模型的准确度。
[0043]
下面对本发明的采用偏最小二乘法(pls)建立关联模型的方法说明如下:
[0044]
pls算法
[0045]
首先对于光谱矩阵x(n
×
m)和辛烷值矩阵y(n
×
1)进行如下分解,在本算法中n为样品数,m为特征谱区吸光度波长点数,即特征谱区内吸光度的采样点数。
[0046][0047][0048]
其中:tk(n
×
1)为光谱矩阵x的第k个主因子的得分;
[0049]
pk(1
×
m)为光谱矩阵x的第k个主因子的载荷;
[0050]
uk(n
×
1)为浓度矩阵y的第k个主因子的得分;
[0051]
qk(1
×
1)为浓度矩阵y的第k个主因子的载荷;f为主因子数。即:t和u分别为x和y矩阵的得分矩阵,p和q分别为x和y矩阵的载荷矩阵,e
x
和ey分别为x和y的pls拟合残差矩阵。
[0052]
第二步是将t和u作线性回归:
[0053]
u=tb
[0054]
b=(t
t
t)-1
t
ty[0055]
在预测时,首先根据p求出未知样品光谱矩阵x
未知
的得分t
未知
,然后由下式得到浓度的预测值:y
未知
=t
未知
bq。
[0056]
通常pls算法把矩阵分解和回归并为一步,即x和y矩阵的分解同时进行,并且将y的信息引入到x矩阵分解过程中,在计算每一个新主成分前,将x的得分t与y的得分u进行交换,使得到的x主成分直接与y关联。
[0057]
pls算法优选按照h wold提出的非线性迭代偏最小二乘算法(nipals)计算完成,其具体算法如下:
[0058]
对于校正过程,忽略残差阵e,主因子数取1时有:
[0059]
对x=tp
t
,左乘t
t
得:p
t
=t
t
x/t
t
t;右乘p得:t=xp/p
t
p。
[0060]
对y=uq
t
,左乘u
t
得:q
t
=u
t
y/u
t
u,两边同除得q
t
得:u=y/q
t
。
[0061]
(1)求吸光度矩阵x的权重向量w
[0062]
取浓度矩阵y的某一列(在本发明里只有一列)作u的起始迭代值,以u代替t,计算w
[0063]
方程为:x=uw
t
,其解为:w
t
=u
t
x/u
tu[0064]
(2)对权重向量w归一化
[0065]wt
=w
t
/||w
t
||
[0066]
(3)求吸光度矩阵x的因子得分t,由归一化后w计算t
[0067]
方程为:x=tw
t
,其解为:t=xw/w
tw[0068]
(4)求浓度矩阵y的载荷q值,以t代替u计算q
[0069]
方程为:y=tq
t
,其解为:q
t
=t
t
y/t
t
t
[0070]
(5)对载荷q归一化
[0071]qt
=q
t
/||q
t
||
[0072]
(6)求浓度矩阵y的因子得分u,由q
t
计算u
[0073]
方程为:y=uq
t
,其解为:u=yq/q
tq[0074]
(7)再以此u代替t返回第(1)步计算w
t
,由w
t
计算t
新
,如此反复迭代,若t已收敛(‖t
新-t
旧
‖≤10-6
‖t
新
‖),转入步骤(8)运算,否则返回步骤(1)。
[0075]
(8)由收敛后的t求吸光度矩阵x的载荷向量p
[0076]
方程为:x=tp
t
,其解为:p
t
=t
t
y/t
t
t
[0077]
(9)对载荷p归一化
[0078]
p
t
=p
t
/||p
t
||
[0079]
(10)标准化x的因子得分t
[0080]
t=t||p||
[0081]
(11)标准化权重向量w
[0082]
w=w||p||
[0083]
(12)计算t与u之间的内在关系b
[0084]
b=u
t
t/t
t
t
[0085]
(13)计算残差矩阵e
[0086]ex
=x-tp
t
[0087]ey
=y-btq
t
[0088]
(14)以e
x
代替x,ey代替y,返回步骤(1),以此类推,求出x、y的诸主因子的w、t、p、u、q、b。用交互检验法确定最佳主因子数f,保存wf、pf、qf。
[0089]
对待测汽油样本的辛烷值y
un
的预测过程如下:
[0090]
x
un
为待测汽油样本在特征谱区的吸光度,调用已保存的wf、pf、qf;
[0091]yun
=y
near
+b
pls
x
un
,其中b
pls
=w
ft
(pfw
ft
)-1
qf,y
near
为与x
un
最相近的校正集样本的辛烷值。
[0092]
本发明方法适用于汽油辛烷值的预测分析。
[0093]
下面通过实例详细说明本发明,但本发明并不限于此。
[0094]
实施例1
[0095]
建立汽油辛烷值的关联模型并进行验证。
[0096]
(1)建立汽油样本近红外光谱的校正集与验证集;
[0097]
分别采集某炼厂生产的涵盖所有牌号的成品车用汽油样本200个,并在室温下采集这200个样品的近红外光谱,其中60个作为校正集,140个作为验证集。200个样品的辛烷值实测值通过国标gb/t 5487-2015实验得到。用thermo antaris ii近红外光谱仪通过透射方式采集汽油样品的近红外光谱,使用的附件是光程为0.5cm的顶空瓶,采集温度为室温。
[0098]
采集方法为:将汽油样品注入到顶空瓶中,以空气为参比进行光谱扫描,扫描次数为128次,扫描范围为10000-3500cm-1
,分辨率为8cm-1
。
[0099]
(2)按相同的差减方法,获取校正集近红外光谱的差谱,以及与所述差谱相对应的辛烷值差值;
[0100]
将得到的近红外光谱进行二阶微分处理,取波数为7000-7500cm-1
和8200-8700cm-1
吸光度构成光谱矩阵x,汽油中的辛烷值构成辛烷值矩阵y,按照辛烷值的大小对光谱矩阵x和辛烷值矩阵y进行从低到高排序,得到光谱矩阵xs和辛烷值矩阵ys;
[0101]
计算差谱,对光谱矩阵xs的第二条光谱x2,计算与第一条光谱x1的差谱x
2-x1;对第三条光谱x3,分别计算与第一条光谱x1的差谱x
3-x1、与第二条光谱的差谱x
3-x2;对第四条光谱x4,分别计算与第一条光谱x1的差谱x
4-x1、与第二条光谱x2的差谱x
4-x2、与第三条光谱x3的差谱x
4-x3;以此类推,对光谱矩阵xs中n条光谱,可以得到1+2+3+
…
+(n-1)条差谱共计为1770条,构成光谱差谱矩阵xc。对辛烷值矩阵ys也作相同的差减计算,对辛烷值矩阵ys的第二个辛烷值y2,计算与第一个辛烷值y1的差值y
2-y1;对第三个辛烷值y3,分别计算与第一个辛烷值y1的差值y
3-y1、与第二个辛烷值的差值y
3-y2;对第四个辛烷值y4,分别计算与第一个辛烷值y1的差值y
4-y1、与第二个辛烷值y2的差值y
4-y2、与第三个辛烷值y3的差值y
4-y3;以此类推,辛烷值矩阵ys中n个辛烷值获得对应的1+2+3+
…
+(n-1)个辛烷值差值,构成辛烷值差值矩阵yc。
[0102]
(3)建立校正集近红外光谱的差谱与辛烷值差值之间的关联模型
[0103]
将差谱矩阵xc与辛烷值差值矩阵yc用偏最小二乘法(pls)建立关联模型,建立模型所用的相关统计参数见表1,预测标准偏差rmsep和决定系数r2的计算公式如下。
[0104][0105]
其中m为验证集样本总数,n为校正集样本总数,y
i,actual
为标准方法实测值,y
i,predicted
为预测值,rmsep为预测标准偏差,r2为决定系数。
[0106]
(4)将验证集样本作为辛烷值未知的样本,来验证关联模型的准确性
[0107]
按步骤(2)的方法测定验证集中每个汽油样品的近红外光谱并作相同的光谱处理。首先通过计算移动窗口相关系数,从光谱矩阵x中分别找到与每个验证集样本(假定为待测样本)最邻近的光谱,并分别计算两者之间的差谱,通过步骤(3)得到的关联模型计算差谱对应的辛烷值,最终的辛烷值由最邻近样本的辛烷值与关联模型计算出的辛烷值差值加和得到。
[0108]
表1参数统计
[0109][0110]
图1为本发明方法得到的辛烷值预测值与实际值的对比图。由表1和图1可知,rmsep(预测标准偏差)只有0.33,可见本发明方法能够较为准确地预测汽油样品的辛烷值。
[0111]
对比例1
[0112]
建立汽油辛烷值的关联模型并进行验证。
[0113]
步骤(1)同实施例1。
[0114]
(2)建立校正集近红外光谱与辛烷值之间的关联模型
[0115]
将得到的近红外光谱进行二阶微分处理,取波数为7000-7500cm-1
和8200-8700cm-1
吸光度构成光谱矩阵x,汽油的辛烷值构成辛烷值矩阵y,将光谱矩阵x与辛烷值矩阵y用偏最小二乘法(pls)建立汽油近红外光谱与辛烷值之间的关联模型,建立模型所用的相关统计参数见表2。
[0116]
(3)将验证集样本作为辛烷值未知的样本,来验证关联模型的准确性
[0117]
按与步骤(1)相同的方法测定验证集中每个汽油样品(假定为待测样本)的近红外光谱,经二阶微分处理后,取波数为7000-7500cm-1
和8200-8700cm-1
吸光度代入步骤(2)建
立的汽油近红外光谱与辛烷值之间的关联模型,得到辛烷值预测值,与其真实测定的辛烷值相比较。预测值与实际值的相关统计参数见表2,预测集与实际值的对比见图2。可以看出当校正集样本较少时,预测结果较差。
[0118]
表2参数统计
[0119][0120]
实施例2
[0121]
建立汽油辛烷值的关联模型并进行验证。
[0122]
(1)建立汽油样本近红外光谱的校正集与验证集;
[0123]
分别采集某炼厂生产的涵盖所有牌号的成品车用汽油样本200个,并在室温下采集这200个样品的近红外光谱,其中60个作为校正集,140个作为验证集。200个样品的辛烷值实测值通过国标gb/t 5487-2015实验得到。用thermo antaris ii近红外光谱仪通过透射方式采集汽油样品的近红外光谱,使用的附件是光程为0.5cm的顶空瓶,采集温度为室温。
[0124]
采集方法为:将汽油样品注入到顶空瓶中,以空气为参比进行光谱扫描,扫描次数为128次,扫描范围为10000-3500cm-1
,分辨率为8cm-1
。
[0125]
(2)按相同的差减方法,获取校正集近红外光谱的差谱,以及与所述差谱相对应的辛烷值差值;
[0126]
将得到的近红外光谱进行二阶微分处理,取波数为7000-7500cm-1
和8200-8700cm-1
吸光度构成光谱矩阵x,汽油中的辛烷值构成辛烷值矩阵y,按照辛烷值的大小对光谱矩阵x和辛烷值矩阵y进行从低到高排序,得到光谱矩阵xs和辛烷值矩阵ys;
[0127]
计算差谱,对光谱矩阵xs的第二条光谱x2,计算与第一条光谱x1的差谱x
2-x1;对第三条光谱x3,分别计算与第一条光谱x1的差谱x
3-x1、与第二条光谱的差谱x
3-x2;对第四条光谱x4,分别计算与第一条光谱x1的差谱x
4-x1、与第二条光谱x2的差谱x
4-x2、与第三条光谱x3的差谱x
4-x3;以此类推,对光谱矩阵xs中n条光谱,可以得到1+2+3+
…
+(n-1)条差谱共计为1770条,构成光谱差谱矩阵xc。对辛烷值矩阵ys也作相同的差减计算,对辛烷值矩阵ys的第二个辛烷值y2,计算与第一个辛烷值y1的差值y
2-y1;对第三个辛烷值y3,分别计算与第一个辛烷值y1的差值y
3-y1、与第二个辛烷值的差值y
3-y2;对第四个辛烷值y4,分别计算与第一个
辛烷值y1的差值y
4-y1、与第二个辛烷值y2的差值y
4-y2、与第三个辛烷值y3的差值y
4-y3;以此类推,辛烷值矩阵ys中n个辛烷值获得对应的1+2+3+
…
+(n-1)个辛烷值差值,构成辛烷值差值矩阵yc。按顺序从第1个开始,每隔5个差谱取1个谱图作为校正集样本x
c’=[x
c1
,x
c6
,x
c11
,x
c16
,
…
],y
c’=[y
c1
,y
c6
,y
c11
,y
c16
,
…
]。
[0128]
(3)建立校正集近红外光谱的差谱与辛烷值差值之间的关联模型
[0129]
将差谱矩阵xc与辛烷值差值矩阵yc用偏最小二乘法(pls)建立关联模型,建立模型所用的相关统计参数见表3。
[0130]
(4)将验证集样本作为辛烷值未知的样本,来验证关联模型的准确性
[0131]
按步骤(2)的方法测定验证集中每个汽油样品的近红外光谱并作相同的光谱处理。首先通过计算移动窗口相关系数,从光谱矩阵x中分别找到与每个验证集样本(假定为待测样本)最邻近的光谱,并分别计算两者之间的差谱,通过步骤(3)得到的关联模型计算差谱对应的辛烷值,最终的辛烷值由最邻近样本的辛烷值与关联模型计算出的辛烷值差值加和得到。
[0132]
表3参数统计
[0133][0134]
由表3可知,rmsep(预测标准偏差)为0.39,预测结果略差于实施例1。实施例3不使用全部1770个差谱样本作为校正集,而是按顺序从每5个样本中提出第一个样本进入校正集,总计354个样本构成差谱矩阵x
c1
进行建模后预测。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1