阿拉比卡和罗伯斯塔两种咖啡豆的快速鉴别方法
本发明涉及一种咖啡豆鉴别方法,尤其是阿拉比卡和罗伯斯塔两种咖啡豆的快速鉴别方法,属于食品检测技术领域。
背景技术:
咖啡是一种原产于埃塞俄比亚西南部的热带植物,它的果实经过脱皮、发酵、脱胶、干燥后成为生咖啡。阿拉比卡和罗伯斯塔是目前咖啡交易市场两种主要的咖啡豆品种,这两种咖啡豆外观相似,但价格差异较大,很多不法商家往往以次充好,利用其中差价谋取暴利。因此研究快速、准确的咖啡豆种类无损鉴别方法对于保障消费者权益具有重要意义。
激光拉曼光谱是基于拉曼散射效应的分子结构表征技术,其谱线位置、谱带强度等可反映物质成分等信息,已经广泛应用于诸多行业。郭鹏程等结合激光拉曼技术成功的分辨出了灵芝孢子油;温丹华等建立山西老陈醋醋龄拉曼光谱快速检测方法;corvucci等将蜂蜜的激光拉曼光谱与主成分分析模型相结合成功用于蜂蜜产地追溯。此外,在农产品检测领域,激光拉曼技术已经应用于辣椒苏丹红、蔬菜水果农药残留以及生鲜肉中的瘦肉精等的定性定量检测。
深度学习通过组合低层特征形成更加抽象的高层表示以发现数据的属性类别,具有强大的学习能力。循环神经网络(recurrentneuralnetworks,rnn)是深度学习的重要分支,其可以通过为网络添加额外的权重来在网络图中创建循环,已经在故障诊断、语音识别、情感分类等诸多领域展现了出色的特征提取和学习能力。近些年深度学习在光谱分析领域也得到关注,le等将近红外技术与深度学习相结合,成功筛选出含有曲黄霉素的稻谷;赵勇等利用一维卷积神经网络进行三类雌性激素粉末的拉曼光谱分类;虞浩月等将双向长短期记忆网络运用到太赫兹光谱识别领域。
目前,pawel等人利用两种咖啡豆香味的离子迁移率成功区分阿拉比卡与罗伯斯塔,但是检测速度较慢。marie等人使用dna检测技术区分出了两种咖啡豆,但是所需成本较大。
而本专利将拉曼光谱与循环神经网络(lstm)算法相结合,应用于两种咖啡豆的种类鉴别,具有对样本无损性、快速、成本低等优点。
技术实现要素:
本发明需要解决的技术问题是提供阿拉比卡和罗伯斯塔两种咖啡豆的快速鉴别方法,鉴别快速、成本低,并且抗噪声能力明显高于传统分类算法,同时具备样本无损性。
为解决上述技术问题,本发明所采用的技术方案是:
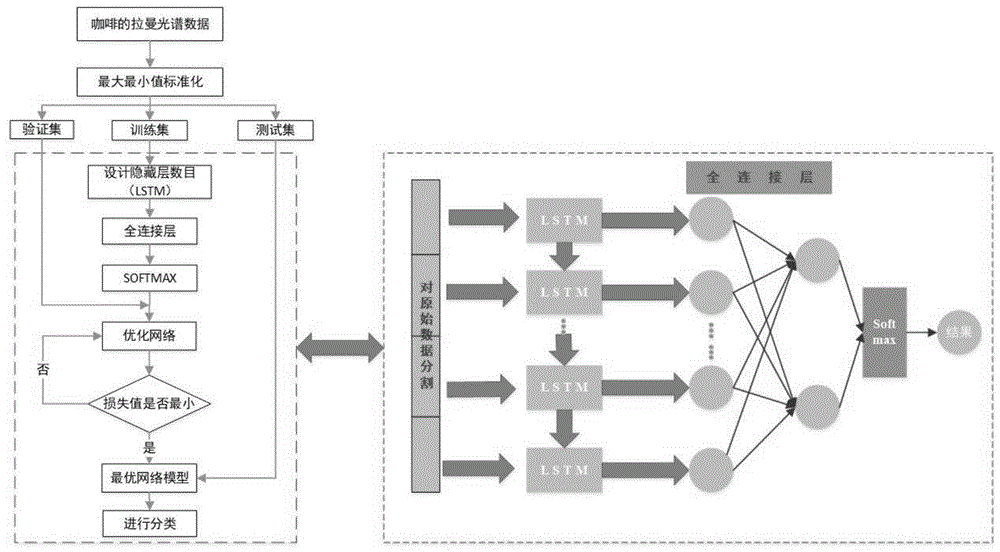
阿拉比卡和罗伯斯塔两种咖啡豆的快速鉴别方法,利用阿拉比卡与罗伯斯塔两种咖啡豆样本均在拉曼光谱波段有明显吸收的现象,得到拉曼光谱的原始数据,将原始数据扣除基线并进行平滑滤波处理,然后添加高斯白噪声用于扩充数据,然后将每种咖啡豆扩充后的数据放入lstm神经网络进行训练与测试,搭建lstm神经网络模型,通过寻优找到最佳参数,最终得出咖啡豆样本的分类结果。
本发明技术方案的进一步改进在于:包括以下步骤:
1)咖啡豆样本的前处理:对咖啡豆样本进行筛选,晾干;
2)利用拉曼光谱仪测定咖啡豆样本得到原始拉曼光谱数据,并对原始拉曼光谱数据进行预处理;
3)将预处理后的原始拉曼光谱数据进行数据扩充,使每种咖啡豆样本的光谱数据扩充到2000个样本;
4)建立lstm神经网络模型进行光谱定性分类,确定模型最优参数,选取最优网络结构;
5)根据最优的网络结构得到两种咖啡豆样本的分类结果。
本发明技术方案的进一步改进在于:所述步骤2)中拉曼光谱仪的型号为i-
本发明技术方案的进一步改进在于:所述步骤2)中的预处理为对测量的原始拉曼光谱数据进行基线校正与平滑滤波处理。
本发明技术方案的进一步改进在于:所述步骤3)中对测量的原始拉曼光谱数据添加不同参数的高斯白噪声,模拟真实光谱采集过程中的各种干扰信号,同时将每种咖啡豆的光谱数据扩充到2000个样本。
本发明技术方案的进一步改进在于:将扩充后的两种咖啡豆样本的拉曼光谱数据打乱标签与数据顺序。
本发明技术方案的进一步改进在于:所述步骤4)中对扩充后的光谱数据随机划分为60%的训练集、20%的测试集和20%的验证集,得到特征光谱数据,将特征光谱数据合理划分给每个lstm神经单元,然后测量每条光谱数据的维度,将每条光谱数据等间隔分割,并输入lstm神经网络中进行迭代,确定模型最优参数,得到分类准确率最高的模型,继而得到最优的网络结构。
本发明技术方案的进一步改进在于:所述确定模型最优参数的确定过程为:选择合理的迭代次数,通过准确率选择最优的lstm单元内的光谱数量以及lstm的神经元个数。
本发明技术方案的进一步改进在于:按照lstm最优网络模型,运行5次,取分类结果准确率的平均值。
由于采用了上述技术方案,本发明取得的技术进步是:
本发明利用阿拉比卡和罗伯斯塔两种咖啡豆对拉曼光谱的吸收得到的不同光谱数据,并且利用lstm神经网络对咖啡样本进行分类鉴定,最终将两种咖啡豆样本进行分类,结果也证明了本发明对咖啡豆分类结果准确率是可靠的。本发明利用lstm神经网络,能够处理大量咖啡豆样本,并能够高效、准确的对样本进行分类,最终完成咖啡豆种类的定性鉴别。
附图说明
图1是本发明lstm单元传递图;
图2是本发明lstm内部结构图;
图3是本发明阿拉比卡与罗伯斯塔基线校正与平滑滤波后的拉曼光谱图;
图4是本发明不同数据结构和隐层节点数结果对比图;
图5是本发明迭代次数对正确率的影响图;
图6是本发明lstm正确率与损失值曲线图。
具体实施方式
下面结合实施例对本发明做进一步详细说明:
如图1和图2所示,阿拉比卡和罗伯斯塔两种咖啡豆的快速鉴别方法,利用阿拉比卡与罗伯斯塔两种咖啡豆样本均在拉曼光谱波段有明显吸收的现象,得到拉曼光谱的原始数据,将原始数据扣除基线并进行平滑滤波处理,然后添加高斯白噪声用于扩充数据,然后将每种咖啡豆扩充后的数据放入lstm神经网络进行训练与测试,搭建lstm神经网络模型,通过寻优找到最佳参数,最终得出咖啡豆样本的分类结果。
包括以下步骤:
1)咖啡豆样本的前处理:对咖啡豆样本进行筛选,晾干;
2)利用拉曼光谱仪测定咖啡豆样本得到原始拉曼光谱数据,并对原始拉曼光谱数据进行预处理;
3)将预处理后的原始拉曼光谱数据进行数据扩充,使每种咖啡豆样本的光谱数据扩充到2000个样本;
4)建立lstm神经网络模型进行光谱定性分类,确定模型最优参数,选取最优网络结构;
5)根据最优的网络结构得到两种咖啡豆样本的分类结果。
进一步的,步骤2)中拉曼光谱仪的型号为i-
进一步的,步骤2)中的预处理为对测量的原始拉曼光谱数据进行基线校正与平滑滤波处理。
进一步的,步骤3)中对测量的原始拉曼光谱数据添加不同参数的高斯白噪声,模拟真实光谱采集过程中的各种干扰信号,同时将每种咖啡豆的光谱数据扩充到2000个样本。将扩充后的两种咖啡豆样本的拉曼光谱数据打乱标签与数据顺序。
进一步的,步骤4)中对扩充后的光谱数据随机划分为60%的训练集、20%的测试集和20%的验证集,得到特征光谱数据,将特征光谱数据合理划分给每个lstm神经单元,然后测量每条光谱数据的维度,将每条光谱数据等间隔分割,并输入lstm神经网络中进行迭代,确定模型最优参数,得到分类准确率最高的模型,继而得到最优的网络结构。
进一步的,lstm的内部输入门it,遗忘门ft,输出门ot,内部隐藏状态ctx,新单元状态ct,新状态ht计算公式为
it=σ(wiht-1+uixt);
ft=σ(wfht-1+ufxt);
ot=σ(woht-1+uoxt);
ctx=tanh(wctht-1+uctxt);
ct=(ct-1×ft)+(ctx×it);
ht=tanh(ct)×ot;
进一步的,确定模型最优参数的确定过程为:选择合理的迭代次数,通过准确率选择最优的lstm单元内的光谱数量以及lstm的神经元个数。
进一步的,按照lstm最优网络模型,运行5次,取分类结果准确率的平均值。
实施例1:
基于拉曼光谱结合lstm神经网络对咖啡豆种类鉴别,本实施例采用的样本为阿拉比卡与罗伯斯塔两种咖啡豆。
1)对购买的两种咖啡豆进行筛选,晾干;
2)利用拉曼光谱仪测量两种咖啡豆的拉曼光谱各30条;
3)通过基线校正与平滑滤波得到两种咖啡豆的拉曼光谱平均图,如图3所示;
4)通过准确率选择最优的lstm单元内的光谱数量以及lstm的神经元个数;
5)根据最优的网络结构得到两种咖啡豆样本的分类结果。
lstm神经网络是一种改进的循环神经网络(rnn),能够有效解决rnn结构中长时间前重要信息丢失问题,lstm神经网络应用到拉曼光谱上有着独特的优势。
每类的咖啡豆拉曼光谱数测30条,测得的拉曼光谱是1*1809数据,通过添加噪声的方式扩充拉曼光谱数据,每种咖啡豆数据扩充至2000条,因为1809能被9、27、67与201整除,所以分别设定lstm网络每一单元的输入数据大小为201、67、27和9,针对四种数据结构进行实验;同时,隐藏层节点数(神经元个数)分别讨论了96、112、128、144与160的5种情况,在不同数据结构和不同隐层节点数时,咖啡豆的分类正确率结果如表1所示,作图为图4所示。
表1
如图4可以看出,当每个lstm单元输入201个数据时,每个样本光谱的lstm个数是9,正确率最高,达到92.51%,其原因是咖啡豆拉曼光谱保存相对完整,可以提取更多lstm单元光谱信息,从而提高正确率。
深度学习的迭代次数对正确率也有很重要的影响,随着迭代次数的增加,正确率会发生改变,在确定数据结构与隐藏层节点数的基础上,对模型迭代次数参数进行实验研究,不同迭代次数对应的分类正确率和程序运行时间结果如图5所示。从图5可以看出,当迭代次数在40到60的时候,正确率有着明显的上升趋势,当迭代次数在60到90时,正确率基本维持不变。迭代次数增加会导致时间延长,综合考虑时间因素,迭代次数选择60次,运行时间为26.60秒。
综上所述,lstm的单元类型为201个数据,隐藏层的节点数选择128个,迭代次数进行60次时,咖啡豆分类正确率最高,达到92.51%,并且此时的运行时间最少,为26.60秒。训练结果的正确率和损失曲线结果如图6所示。
为了验证所提出的lstm模型的分类性能,本发明同时采用k近邻(knn)、梯度提升(gradientboosting)、随机森林(randomforest)和决策树(decisiontree)分类方法对咖啡豆拉曼光谱数据进行处理,实验环境与lstm所在的搭建环境相同。lstm分类算法与传统分类算法都事先进行了基线校正与平滑滤波处理,然后再进行分类研究。本发明基于正确率、精准率、召回率与f1值四个指标对比不同分类方法,同时对不同方法所用时间进行比较,不同分类算法比较结果如表2所示。
表2
由表2可以看出,尽管lstm分类方法所用的时间不是最短的,lstm算法的正确率与f1值最高,可以达到92.51%,两种咖啡豆的f1值分别为92.83%与93.67%。实验结果证明lstm方法的有效性,可以与拉曼光谱相结合用于两种咖啡豆的种类鉴别。
咖啡豆的拉曼光谱在现场采集过程中必然存在类似环境光和样品位置等较多不可控的干扰,因此对所设计模型的强抗干扰能力要求更高。基于以上确定的网络结构和模型参数,对原始光谱添加不同强度高斯白噪声,噪声强度分别为65dbw、70dbw、75dbw、80dbw、85dbw与90dbw,对比不同分类算法评价提出的lstm方法的抗噪声性能,结果表3所示。
表3
从表3可以清晰的看出,当添加噪声相对较弱时,各种分类方法的正确率相差不大;随着噪声强度的增加,传统分类方法的分类效果均有较大下降,lstm方法仍然保持较高分类正确率;当噪声达到90dbw时,lstm的正确率还能达到84.12%,在五种分类算法中最高。以上结果充分表明lstm神经网络非常适合有噪声干扰情况下的拉曼光谱精准分类。
本发明提出一种基于深度学习的拉曼光谱定性分类模型,实现两类咖啡豆的定性鉴别。向光谱中添加了高斯白噪声从而扩充了原始咖啡豆的拉曼数据,并搭建lstm网络分类模型并确定最优参数,完成lstm模型训练和测试,与传统方法对比发现,lstm方法的分类正确率和抗干扰能力明显优于其他方法。实验结果表明lstm神经网络是一种优秀的拉曼光谱定性分析方法,具有鲁棒性强的明显优势,在现场采集的拉曼光谱分析领域有重要应用价值。
尽管本发明的实施方案已公开如上,但其并不仅仅限于说明书和实施方式所列运用,它完全可以被适用于各种适合本发明的领域,对于熟悉本领域的人员而言,可容易地实现另外的修改,因此在不背离权利要求及等同范围所限制的一般概念下,本发明并不限于特定的细节和这里示出的实施例。
- 还没有人留言评论。精彩留言会获得点赞!