一种识别进口铁矿石品牌的方法与流程
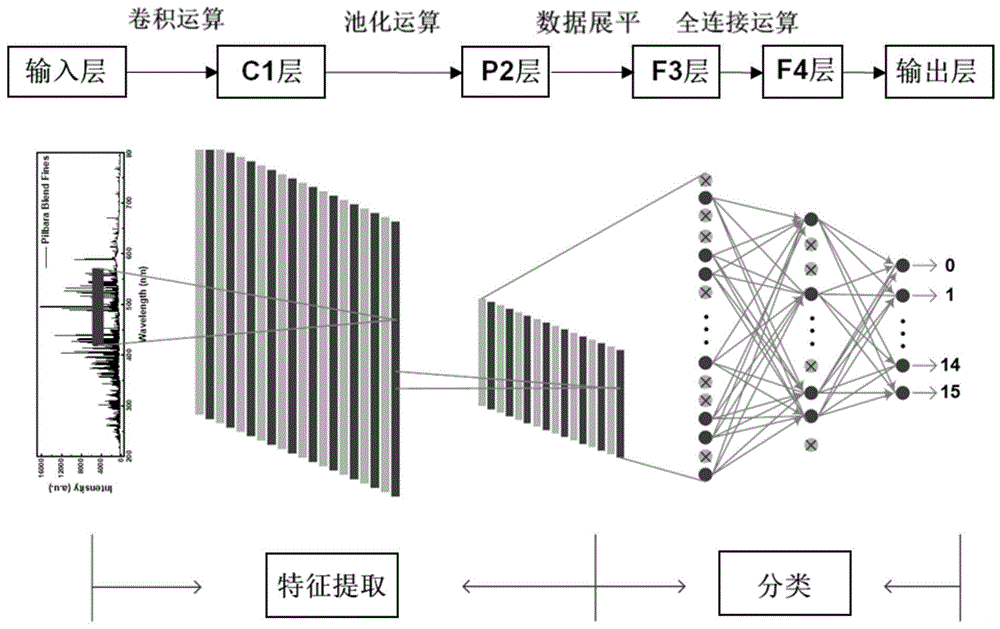
本发明涉及一种识别进口铁矿石品牌的方法。
背景技术:
:铁矿石是钢铁工业的重要原材料。进口铁矿石入境报关时会申报品名、原产地等信息,建立一种现场快速识别铁矿石原产地和品质状况的溯源分析,能有效筛查掺杂、掺假等现象,保障贸易便利化。专利文献cn111239103a公开了一种识别铁矿石生产国家及品牌的方法,其采用激光诱导击穿光谱(libs)结合人工神经网络(ann)模型实现了铁矿石生产国家和品牌的分类。该模型需要三种预处理方法(savitzky-golay多项式滤波、多元散射校正和二次拟合)去除光谱背景、色散和噪声,并利用主成分分析(pca)对libs数据进行降维。这些做法有效地克服了铁矿石品牌分类中libs光谱质量低的问题。然而,复杂的光谱预处理和特征选择会延长分析时间,且有可能导致光谱失真和识别准确率降低。因此,需要建立一种进口铁矿石品牌的技术,其识别准确率高。技术实现要素:本发明为了解决现有技术中的识别进口铁矿石品牌的方法中存在识别准确率低的缺陷,而提供了一种识别进口铁矿石品牌的方法。本发明的品牌识别方法准确率高,模型建立操作简单。本发明通过以下技术方案解决上述技术问题。本发明提供了一种识别进口铁矿石品牌的方法,其步骤包括:s1.取至少16个品牌,每个品牌至少10个批次的铁矿石,用激光诱导击穿光谱法进行检测,得到建模光谱数据,建立卷积神经网络模型;其中,所述卷积神经网络模型包括依次进行的输入层、卷积层、池化层、全连接层和输出层;其中全连接层还包括依次进行的展平层和隐藏层;所述输入层为所述建模光谱数据;所述卷积层的卷积核的大小为10~90;所述卷积层的卷积核的数量为5~25;所述卷积层的激活函数为s型函数、双曲正切函数或修正线性单元函数;所述隐藏层的激活函数为s型函数、双曲正切函数或修正线性单元函数;所述隐藏层的神经元的个数为100~160;s2.将待测样品铁矿石用激光诱导击穿光谱法进行检测,得到待测光谱数据,将所述待测光谱数据代入所述卷积神经网络模型,确定所述待测样品铁矿石的品牌。本发明中,本领域技术人员知晓,用于建立模型的品牌和批次的数据量为越多越好,因此对于品牌和批次的数据量上限不作特别限定,较佳地,每个品牌铁矿石的批次数为10~27。本发明中,较佳地,所述建模光谱数据为建模光谱原数据,所述待测光谱数据为待测光谱原数据;或者,所述建模光谱数据为所述建模光谱原数据经过预处理过程得到的数据,所述待测光谱数据为所述待测光谱原数据经过所述预处理过程得到的数据。其中,较佳地,所述建模光谱原数据或所述待测光谱原数据为波长范围为187~972nm内的12814个数据点。其中,较佳地,所述预处理为特征线选择或小波变换,或者为savitzky-golay多项式滤波器、多元散射校正、二次拟合和主成分分析的组合。较佳地,所述特征线选择为选择fe、mg、mn、si、al、ca、na、k和ti的元素特征发射线的周围连续5个数据点。较佳地,所述小波变换中采用bior1.3小波。本发明中,可将所述步骤s1中的建模光谱数据分为三组,分别是训练集、验证集和预测集。其中,所述训练集、所述验证集和所述预测集按70%:15%:15%的比例随机选取的,每次选取的案例编号会不同。本发明中,所述卷积层的作用是从输入的建模数据中提取光谱特征。其中,较佳地,所述卷积核的大小为10、30、50、70或90。其中,较佳地,所述卷积层的卷积核的数量为5、10、15、20、25或30。其中,较佳地,所述卷积层的激活函数为双曲正切函数。其中,较佳地,所述卷积层的层数为1~2。其中,较佳地,所述卷积层的步长为4。本发明中,所述池化层的作用是减小特征尺寸和压缩网络参数,以减少过度拟合,提高模型的容错能力。对于所述建模数据,所述池化层可以对所提取特征的保持平移不变性,并增加位移的鲁棒性。其中,较佳地,所述池化层的类型为最大池化或平均池化,例如为最大池化。其中,较佳地,所述池化层的池化窗口数量为20。其中,较佳地,所述池化层的层数为1。其中,较佳地,所述池化层的池化窗口大小为4。其中,较佳地,所述池化层的池化窗口步长为4。本发明中,所述展平层的作用是在卷积区域提取了光谱特征之后,将输出的高维数据转换成一维,用作后面分类器的输入数据。其中,较佳地,所述展平层中采用dropout方法。较佳地,所述展平层中的dropout技术失活概率为0.5,可有效防止模型在训练数据时出现过度拟合。本发明中,所述隐藏层的作用相当于传统人工神经网络的隐藏层。其中,较佳地,所述隐藏层的神经元个数为100、110、120、130、140、150或160。其中,较佳地,所述隐藏层中采用dropout方法。较佳地,所述隐藏层中的dropout技术失活概率为0.5,可有效防止模型在训练数据时出现过度拟合。其中,较佳地,所述隐藏层的激活函数为s型函数。本发明中,较佳地,所述卷积层的激活函数为修正线性单元函数,所述隐藏层的激活函数为s型函数;或者,所述卷积层的激活函数为双曲正切函数,所述隐藏层的激活函数为s型函数;或者,所述卷积层和所述隐藏层的激活函数为修正线性单元函数;或者,所述卷积层的激活函数为双曲正切函数,所述隐藏层的激活函数为修正线性单元函数;或者,所述卷积层和所述隐藏层的激活函数为双曲正切函数;或者,所述卷积层的激活函数为修正线性单元函数,所述隐藏层的激活函数为双曲正切函数。本发明中,较佳地,所述输出层为所述品牌。其中,较佳地,所述输出层的激活函数为softmax函数。本发明中,较佳地,所述卷积神经网络模型的学习速率为0.001。本发明中,较佳地,所述卷积神经网络模型的优化器为adam优化算法,其需要的内存少,计算效率高。本发明中,较佳地,所述建立卷积神经网络模型的过程通过t分布随机邻域嵌入算法进行数据降维,以可视化所述卷积神经网络模型的优化效果。在符合本领域常识的基础上,上述各优选条件,可任意组合,即得本发明各较佳实例。本发明所用试剂和原料均市售可得。本发明的积极进步效果在于:本发明的品牌识别方法准确率高,模型建立操作简单。本发明一优选实施方式中,在建立卷积神经网络模型前,无需光谱数据预处理的过程,处理时间短。附图说明图1为实施例1采用的卷积神经网络模型的流程示意图。图2为实施例1中经过cnn模型计算得到的混淆矩阵。图3为对比例1中经过knn模型计算得到的混淆矩阵。图4为对比例2中经过lda模型计算得到的混淆矩阵。图5为对比例3中经过rf模型计算得到的混淆矩阵。图6为对比例4中经过svm模型计算得到的混淆矩阵。图7为对比例5中经过bpann模型计算得到的混淆矩阵。图8为实施例2中cnn模型各层输出数据的t-sne二维散点图。(a)输入层;(b)p2层;(c)f4层;(d)输出层。图9为实施例3中卷积核大小不同对品牌识别准确率和时间的影响。图10为实施例3中卷积核数量不同对品牌识别准确率和时间的影响。图11为实施例4中不同激活函数的组合和池化类型对品牌识别准确率的影响。图12为实施例5中全连接层神经元数量不同对品牌识别准确率的影响。图13为实施例6中3000次迭代过程可视化的分类准确率曲线。图14为实施例6中3000次迭代过程可视化的损失函数曲线。具体实施方式下面通过实施例的方式进一步说明本发明,但并不因此将本发明限制在所述的实施例范围之中。下列实施例中未注明具体条件的实验方法,按照常规方法和条件,或按照商品说明书选择。本发明各实施例和对比例中,铁矿石的样品收集和样品检测过程如下:1、样品收集在中国上海、宁波、新疆等城市港口的卸货过程中,收集了266批次来自澳大利亚、南非、巴西三个产地的16类品牌铁矿石。根据gb/t10322.1-2014《铁矿石取样和制样方法》相关样品制备规范,将进口铁矿样品研磨成颗粒直径约为100μm的铁矿粉。在采用激光诱导击穿光谱法(libs)收集光谱之前,所有的铁矿粉都保存在干燥的环境中。表1列出了样本详细的信息。表1铁矿石样品信息表2、样品检测本发明各实施例和对比例中的样品均使用美国tsi公司型号为chemrevealtm-3764的商业化libs设备进行检测。配备发射波长为1064nm的q型开关的nd:yag激光器,其峰值能量为200mj。该系统中准直光学元件的光纤据样本表面约20mm,ccd检测器的光谱检测范围为190~950nm。光谱采集过程处于大气环境下,样品直接放置在x-y-z手动微调样品台上,利用摄像系统小窗口进行微区调节与对焦,烧蚀光斑最佳直径设为200μm,激光脉冲与ccd检测器之间的延迟时间设为2μs,激光重复频率为5hz,为了信噪比(snr)最大化,优化后的激光器发射能量为30mj。在不添加任何黏着剂的条件下,先将聚乙烯环放于不锈钢垫片表面,将约8g铁矿粉置于其中,在台式压样机(zhy-401b型,北京众合创业科技发展有限责任公司)30t的压力下保压60s后退模,最终制成约5mm厚的样品薄片,若样品表面均匀且无裂纹、脱落现象,用塑封袋密封后置于干燥器内以备光谱采集用。测量时,用洗耳球吹净压片表面,为了减小样品异质性引起的光谱波动,在每个样本表面随机选取光谱测量位置,每个位置由5×5的测量点阵构成。在每个测量点,先用5次激光脉冲清除表面浮灰,然后累积发射5次激光脉冲,收集到5条libs光谱。最后,对测量点阵上收集到的所有光谱(5×5×5)取平均,得到一条原始分析光谱。对于每条光谱,收集了187~972nm整个波长范围内的共12814个数据点。对于每批次样品,选取不同的位置,将上述操作重复6次,分别得到6条原始分析光谱。此研究中,将每批次样品中每个位置的分析光谱作为一个独立的光谱样本,最终得到1596条(266个样品×6条)分析光谱样本。3、品牌识别准确率计算准确率代表了预测的类别与真实的类别是否一致,准确率越高,模型的分类性能越好。其公式如下:其中ncorr为正确预测的样本数,n为所有预测样本数。4、混淆矩阵(confusionmatrix)混淆矩阵是一种人工智能领域用来呈现模型性能的可视化方法,可以直观地评估模型在监督学习中预测能力的优劣。一般,混淆矩阵的每一列代表预测结果,每一行代表真实类别。斜对角线表示正确区分的样本,其他位置均为错分样本。实施例1.1~1.266实施例1采用的卷积神经网络模型(cnn)参数和流程如图1和下表2所示。表2实施例1采用的cnn模型的参数k折交叉验证(k-foldcross-validation,k-cv)方法可以估计cnn的泛化能力,并消除样本之间的相关性。k值通常选择5或10以实现平衡偏差和方差。本实施例中,使用了五倍交叉验证(5-cv)方法,将原始光谱样本分成5等份(其中4份各319条,另一份320条),每一次将其中4份用于模型验证,其余1份用于模型预测,共进行五次完整的cnn计算过程。校准集和预测集的分类正确率和损失函数值被记录下来,直到五组数据都作为预测集进行预测时,进行结果统计,如表3所示。表3cnn模型品牌识别结果5-cv验证集准确率(%)预测集准确率(%)损失函数199.92(1276/1277)100.00(319/319)0.0329299.77(1274/1277)100.00(319/319)0.0351399.92(1276/1277)100.00(319/319)0.0246499.84(1275/1277)99.69(318/319)0.0452599.84(1275/1276)99.69(319/320)0.0401平均值99.8699.880.0356标准偏差0.060.170.00785由表3可知,验证集分类正确率和预测正确率分别在99.77%~99.92%和99.69%~100.00%区间范围内,证明cnn模型具有较强的品牌分类能力。损失函数的平均值为0.0356,保持在较低的水平,说明cnn具有较高的预测精度和清晰的分类边界。神经网络5-cv结果的标准偏差(standarddeviation,sd)主要用于评估cnn模型的可重复性。验证集、预测集和损失函数的sd分别是0.06、0.17和0.00785,证明该模型具有相对稳定的学习效果。对比例1.1~1.236~对比例5.1~5.236与实施例1相比,为了评估cnn与其他传统机器学习方法对品牌铁矿石的分类性能的差异,进行了模型对比实验。将原始光谱样本作为输入变量,输入k-近邻(knn)、线性判别分析(lda)、随机森林(rf)、支持向量机(svm)和反向传播人工神经网络(bpann)模型,其相应的5-cv的校准集和预测集的平均分类正确率记录在表4中。其中,bpann模型参数如表5所示。表4不同模型的品牌识别准确率模型验证集准确率(%)预测集准确率(%)对比例1.1~1.236knn91.4890.35对比例2.1~2.236lda97.1296.86对比例3.1~3.236rf100.0094.11对比例4.1~4.236svm98.1897.36对比例5.1~5.236bpann99.2597.93实施例1.1~1.236cnn99.8699.88表5对比例5采用的bpann模型的参数在输入的数据均为建模光谱原数据情况下,所建立的cnn模型具有最高的校准集和预测集分类准确率,表现出良好的品牌分类能力。各模型的详细错分情况如图2~7所示的混淆矩阵。对于16种品牌铁矿石的预测,cnn模型只将两个杨迪粉铁矿误判为哈杨粉铁矿,而其他模型则显示出大量的错分样本。分析这些大面积错分现象产生的原因,铁矿石的libs光谱维数较高(12814个像素点),且由于铁基体的强烈影响,其发射谱线组成复杂,因此传统的模式识别方法需要复杂的预处理和特征选择工程来提高其分类性能。在cnn模型中,卷积层和池化层相当于一个特征提取器,能密集的挖掘多个局部特征;而全连接层是一个优化和改进的bpann分类器。因此,cnn模型在简化实验流程的同时,能够自适应学习libs光谱的特征,以获得更好的分类结果。与机器学习相比,所设计的cnn模型具有较强的抗干扰能力和特征提取能力,有助于克服传统复杂预处理造成的光谱失真缺陷,简化分析过程,实现更高的预测精度。实施例2.2~2.236本实施例使用t分布随机邻域嵌入(t-distributedsymmetricneighborembedding,t-sne)算法降低cnn中每个特征层输出数据的尺寸,并直观的展示在2d散点图中(图8),用于解释实施例1的cnn模型的有效性。t-sne算法主要包括两个步骤:1、构建一个高维对象之间的概率分布,使得相似的对象有更高的概率被选择,而不同的对象有较低的概率被选择。2、在低维空间中建立这些对象的概率分布,使两个概率分布尽可能相似(本实施例用kullback-leibler散度),以此更直观的度量观察对象间的相似性。本实施例在低维空间中采用了t分布,能够有效减少sne算法可能出现的拥堵和优化困难问题,既保持了局部结构,又捕捉了数据的整体特征。结果如图8a所示,在输入层中,代表不同品牌铁矿石原始libs数据的点集出现了大量的交叉现象,这是由于与铁矿石的主要化学成分密切相关。根据gb/t6730.5-2007的三氯化钛还原法和gb/t6730.62-2005的x射线荧光光谱法,本实施例分别获取了铁矿中的fe元素和其他主要化学成分(sio2、al2o3、tio2、cao和mgo)的定量数据,在所有品牌的铁矿石中,除fe元素外,其他化学成分的含量非常相似。同时从图8a中可以看出,只有南非铁精粉和澳大利亚超特粉两个品牌的点集与集群距离较远,可以明显区分出来。依据元素定量数据(表6,表中的定量数据均为平均值±标准偏差)可知:超特粉是所有品牌中铁品位最低的铁矿石,比较容易鉴别;另外,南非铁精粉中tio2、cao和mgo含量最高,sio2的最低,与其他品牌明显存在差异。然而,实现对所有品牌的分类仍然需要cnn进一步提取有用信息。基于t-sne二维散点图和定量数据,可从池化层(p2)、隐藏层(f4)到输出层解释cnn模型逐层提取光谱特征的递进性和合理性。表6进口铁矿石各品牌的元素定量数据cnn模型的卷积区域对原始数据进行特征提取后的t-sne二维散点图如图8b所示,同一类别的点集表现出明显的聚集,交叉现象显著减少,这表明卷积区域在挖掘光谱数据更多非线性特征方面起着至关重要的作用。卷积层和池化层可以快速捕获品牌内的相似特征以及品牌间的差异特征。然而,仍然能清楚看到有四片混淆的区域,根据元素定量数据进行进一步分析。首先,杨迪粉铁矿和哈默斯利杨迪粉都来自西澳大利亚皮尔巴拉地区的杨迪矿,从图8b中可以看出,尽管这两个品牌的cao含量略有差异,但其他成分几乎相同,光谱特征也相对接近。这与图2中混淆矩阵错分情况保持一致,在实施例1的cnn模型的实际应用中只有这两种类型的铁矿石出现了误判。然后,昆巴标准粉和昆巴标准块在fe和cao的含量上只有很小的差异,两者都是南非昆巴铁矿公司的产品,其基质非常相似,因此卷积区域未能有效地提取到差异性信息。其他重叠区域分别为皮尔巴拉混合粉和纽曼混合粉,皮尔巴拉混合块和纽曼混合块,这两组中的纽曼混合粉和纽曼混合块在fe、sio2和al2o3含量均略高于前者。然而,tio2、cao和mgo的含量呈现不规则分布,导致两组光谱特征复杂。因此,卷积区域这些铁矿石的识别度仍需要进一步提高。随后,全连接层的bp分类器继续学习了所提取出的光谱特征,将特征数据与其所属的类别进行拟合,从而准确识别样本品牌。如图8c所示,经过全连接层的学习,除了杨迪粉和哈杨粉的少量交叉,相同颜色的点集几乎都聚集在一起。值得注意的是,卡拉加斯粉、皮尔巴拉混合块和巴西混合粉散点图中都有少量的离散点,这可能与样品本身的误差有关。当cnn运行结束时,如图8d所示,同类别样本的散点非常收敛,聚集成一堆。特别是,南非铁精粉聚集到一点,证明深度学习很容易学习到这类样品光谱的特点。此外,澳大利亚铁精粉中的fe含量相对较高,sio2和mgo含量最高,al2o3和tio2含量最低,同样属于易于区分的产品。因此,在图8d中,这种品牌的散点也会聚成为几个点。将深度学习中各层提取的光谱特征信息输出进行可视化后,可以直观地观察到每层呈现越来越好的识别效果,各类铁矿石的相似性和差异性逐渐明显。此外,结合铁矿石主要化学成分的定量数据,可以充分解释深度学习在学习libs光谱特征中出现的误判及误判原因,可通过该方式优化cnn模型的各参数。实施例3.1~3.236本实施例中,仅比较不同的数据预处理方式对识别铁矿石品牌准确率的影响。以下4种方式中,分别为:(1)建模光谱原数据、(2)建模光谱原数据经人工选择的特征线(选择如表7所示的铁矿石各元素特征发射线周围连续5个数据点,直接提取元素特征谱线的强度进行计算)、(3)建模光谱原数据经小波变换去噪后(采用双正交1.3小波对libs光谱进行4层分解后,采用固定软阈值法过滤信号)、(4)建模数据原数据经savitzky-golay多项式滤波器、多元散射校正和二次拟合后进行主成分分析处理后。将原始光谱样本首先按照70%(训练集)、15%(验证集)、15%(预测集)的比率随机划分为三组,用于本实施例的实验研究。将经过不同的数据预处理后的数据作为输入变量输入cnn模型,平行训练5次后取平均准确率,比较预测结果,如下表8所示。表7铁矿石光谱的主要元素特征发射线表8四种数据预处理的方式对铁矿石品牌识别准确率的影响从表8可以看出,方式(2)有效地降低了光谱数据维数(12814到320),缩短了训练时间,cnn模型的平均分类准确率达到99%以上,表明所选的特征谱线具有很强的代表性,但是人工选择的特征线具有不能够充分反映光谱特征的缺陷。经过验证,方式(3)可以有效地提高信噪比,其cnn的预测准确率为98.75%,但具有小波变换方法的参数调整过程复杂耗时的缺点。采用方式(4)的综合预处理后,cnn模型对训练集、验证集和预测集的分类准确率分别为98.57%、97.74%和98.08%,均差于单一预处理后的预测效果。该现象证明过于复杂的预处理方法可能导致了光谱失真,且降低维度后的数据量太少,降低了让cnn学习光谱特征所带来的效果。通常,libs数据具有很多复杂的冗余信息,因此需要适当的预处理方法,并且减小数据尺寸和降噪的过程通常是不可避免的。但在本实施例中,与不同预处理后的光谱数据作为输入变量相比,使用原始分析光谱的cnn学习效率最高,预测集的准确率达到99.58%,最优选的方式是直接使用原始光谱作为其输入变量,有效简化实验过程,避免人为因素造成的光谱失真。对比例6.1~6.236对比例6是为了与实施例3比较,对比卷积神经网络(cnn)与反向传播人工神经网络(bpann,模型参数除了输入层外,如表5所示)在经过相同的数据预处理方法后,模型计算后获得的品牌识别准确率。对比例6中,分别将(1)建模光谱原数据、(2)建模光谱原数据经人工选择的特征线(选择如表7所示的铁矿石各元素特征发射线周围连续5个数据点,直接提取元素特征谱线的强度进行计算)、(3)建模光谱原数据经小波变换去噪后(采用双正交1.3小波对libs光谱进行4层分解后,采用固定软阈值法过滤信号)。将原始光谱样本首先按照70%(训练集)、15%(验证集)、15%(预测集)的比率随机划分为三组,用于本系列对比例的实验研究。将经过不同的数据预处理后数据作为输入变量输入cnn模型,平行训练5次后取平均准确率,比较预测结果,如下表9所示。表9cnn和bpann模型中不同数据预处理方式对铁矿石品牌识别准确率的影响由表9中可知,无论使用哪种数据预处理方法得到的libs光谱数据,cnn模型的品牌识别能力都优于bpann。方式(2)有效地降低了光谱数据维数(12814到320),缩短了训练时间;与准确率为95.91%的bpann相比,cnn模型的平均准确度达到了99%以上,表明所选特征谱线的代表性。而且,cnn依靠少量的光谱数据显示出强大的数据挖掘能力和较高的分析准确性。在数据采集过程中不可避免地会产生噪声,经过验证,小波变换可以有效地处理包含信号的噪声并提高信噪比snr。经过方式(3)处理后的数据分别输入bpann和cnn模型,平均准确率分别为96.43%和99.55%;经过方式(1)处理后的数据分别输入bpann和cnn模型,平均准确率分别为96.43%和99.55%;这证明深度学习在更高的频谱质量下表现更好。实施例4.1~4.236本实施例中,仅分析卷积层中卷积核的大小和数量对识别铁矿石品牌准确率的影响。将原始光谱样本首先按照70%(训练集)、15%(验证集)、15%(预测集)的比率随机划分为三组,用于本实施例的实验研究。如图9和表10所示,将卷积核大小分别设置为10,30,50,70,90,并记录不同方案的预测正确率和运行时间。当卷积核大小为50时,训练集、验证集和预测集的准确率达到最大值(99.10%、99.58%、97.50%),三个集合平均预测正确率为98.73%;此条件下的折线图显示,模型的运算时间也为最小值(59分钟)。表10卷积核大小不同对品牌识别准确率和时间的影响如图10和表11所示,当卷积核的大小为50时,进一步研究卷积核的个数对品牌识别性能的影响。将卷积核的数量分别设为5,10,15,20,25,30。当卷积数为5时,计算时间最短,主要是因为卷积核的数量少,使得模型的整体变量数较少,模型运行时间较快,但此条件下并不能达到最为理想的分类正确率。当卷积核数增加到20时,分类的准确率较高且运行时间较短。表11卷积核数量不同对品牌识别准确率和时间的影响实施例5.1~5.236本实施例中,分析激活函数类型以及池化类型对识别铁矿石品牌准确率的影响。将原始光谱样本首先按照70%(训练集)、15%(验证集)、15%(预测集)的比率随机划分为三组,用于本实施例的实验研究。将池化层的类型选定为平均池化,对于卷积层(c1层)和隐藏层(f4层)两层所涉及的非线性映射关系,选取三种函数s型函数(sigmoid)、双曲正切函数(tanh)和修正线性单元函数(rectifiedlinearunit,relu)进行6种组合优化,其中,图11中a对应为relu和sigmoid组合,b对应为tanh和sigmoid函数组合,c对应为relu和relu组合,d对应为tanh和relu组合,e对应为tanh和tanh组合,f对应为relu和tanh组合。如图11所示,当选择tanh和sigmoid函数组合(b组合)时,预测集分类正确率和三个集合(训练集、验证集和预测集)的平均分类正确率达到最大值。另外,在组合b的激活函数组合下,池化类型为平均池化时的预测集分类准确率为98.75%,平均准确率为99.52%(箭头起点处)。当将此时的池化类型改为最大池化后,分类准确率分别提高到99.17%和99.60%(箭头端点处)。在平均池化时,因为组合b、e、f的性能较好,因此仅进一步比较了组合b、e、f在最大池化时的品牌识别准确率,结果如下表12所示。最大池化算法可以有效地保留libs光谱的局部关键信息,减少参数数量,提高模型的泛化能力。表12不同激活函数的组合和池化类型对品牌识别准确率和时间的影响实施例6.1~6.236本实施例中,分析全连接层的神经元数量对识别铁矿石品牌准确率的影响。将原始光谱样本首先按照70%(训练集)、15%(验证集)、15%(预测集)的比率随机划分为三组,用于本实施例的实验研究。如图12和表13所示,在全连接层,所设置的神经元数量过少会导致分类边界拟合程度较差,而数量过多会增加模型参数,存在过拟合的风险。当全连接层的神经元数量在100,110,120,130,140,150和160范围内,cnn模型的分类精度波动幅度较大,说明神经元数量会影响模型稳定性。当神经元数量为120时,预测集和平均准确率都达到了最高值99.5%以上。表13全连接层神经元数量不同对品牌识别准确率和时间的影响为了进一步确认cnn模型所有参数在经过全面优化后的综合效果,本实施例将训练集和验证集的训练过程中,每一次计算(迭代)结束时的分类正确率和损失函数值导出,并绘制在二维图中进行迭代过程可视化。cnn模型3000次迭代过程的分类正确率如图13所示,模型以较快的速度进行收敛,在500次迭代时,分类正确率达到95%;在1500次迭代时,分类正确率超过99%,表明该模型具有良好的学习能力和稳定性。另外,从损失函数值看(图14),经过500次迭代后,损失函数值逐渐趋向于0,意味着模型的预测值与实际值逐渐接近。虽然整个训练过程经过3000次迭代大约需要1.5~2个小时,但预测数百个光谱样本只需要300~400μs。实验表明,将dropout技术应用于cnn分类器可以有效地防止过拟合现象;此外,参数调整的较为合适,使模型能够快速实现更高的分类正确率。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1