基于硬浮点FPGA的雷达超分辨测向方法、系统及数据处理设备与流程
本发明涉及雷达强实时doa领域,特别涉及一种基于硬浮点fpga的雷达超分辨测向方法、系统及数据处理设备。
背景技术:
:music算法是一种基于矩阵特征空间分解的方法,被广泛应用在doa(doa,是电子、通信、雷达、声呐等研究领域的行业内用语,通过处理接收到的回波信号,获取目标的距离信息和方位信息)相关领域中。由于music算法包含非常大的计算量,现有系统的处理速度难以满足实际应用的需要,因此music算法只能普遍应用于一些实时性要求不太严格的领域,如对雷雨天气的研究、对慢速船舶的定位等,但在移动通信、电子侦察以及电子对抗等对实时性要求严格领域中受到极大限制。由于整个music算法计算复杂度和灵活度都很大,信号处理平台(tidsp和常规fpga)在低功耗、轻重量限制及小型化要求下无法满足时间需求和精度需求,同时大多数的ew系统都要求浮点处理,所以国内大多采用dsp处理器运载music算法,处理速度慢,处理时间停留在ms量级,远远达不到实际应用的需要。矩阵运算被广泛的运用于科学计算、雷达数字信号处理和图像处理等领域,随着矩阵运算量和复杂程度的不断增加,传统硬件平台逐渐无法满足系统实时计算的需求。fpga具有运算速度快、灵活性高且可以并行计算的特点,这使其在矩阵运算中具有明显的优势。设计基于fpga的矩阵求逆ip核及其实验平台,对提高矩阵求逆的效率和运算速度,具有重要的工程应用价值。然而,随着矩阵阶数增大,定点数据在计算过程中的截位误差累积,造成最终的数据精度大幅下降,一般的fpga难以满足应用需求。由此,需要有一种更好的方案来解决现有技术中信号处理平台(tidsp和常规fpga)在低功耗、轻重量限制及小型化要求下处理能力不足及测量时间过长的缺陷,从而提升doa的计算效率,缩短计算时间。技术实现要素:有鉴于此,本发明提出了一种基于硬浮点fpga的雷达超分辨测向方法、系统及数据处理设备,具体方案如下:一种基于硬浮点fpga的雷达超分辨测向方法,包括:获取雷达数据,通过多通道形式将所述雷达数据写入硬浮点fpga,所述雷达数据为通道数×快拍数的定点矩阵;通过所述硬浮点fpga计算所述雷达数据的协方差矩阵;将所述协方差矩阵由定点模式转换为浮点模式,写入预设的特征分解模块,所述特征分解模块对所述协方差矩阵进行基于qr分解的特征分解计算和基于施密特正交的qr分解计算,获取多个特征值和多个特征向量;根据预设的信源数门限,参考所述特征值进行信源数判定,结合所述特征向量构造噪声矩阵;获取预设的流型阵,根据所述流型阵和所述噪声矩阵计算空间谱,基于预设的向量点乘器进行所述空间谱的计算和搜索,获取谱峰数据;根据所述谱峰数据获取所述雷达数据对应的空间坐标信息。在一个具体实施例中,所述谱峰数据的获取过程包括,初始谱峰获取:获取预设的流型阵,根据所述流型阵和所述噪声矩阵计算空间谱,基于预设的向量点乘器进行所述空间谱的计算和搜索,获取谱峰;谱峰迭代:将所述谱峰作为粗测结果,基于所述粗测结果对所述流型阵进行汇聚和插值处理,获取更新后的流型阵,根据所述噪声矩阵和更新后的流型阵重新计算空间谱,对更新后的空间谱进行计算和搜索,获得更新后的谱峰,重复迭代,直至满足迭代停止条件;谱峰数据获取:将满足迭代停止条件的谱峰作为所述谱峰数据。在一个具体实施例中,所述空间谱的表达式为:其中,pmu表示空间谱,a表示流型阵,en表示噪声矩阵,h表示矩阵共轭转置。在一个具体实施例中,所述硬浮点fpga包括intelarria10系列,开发平台包括quartus。在一个具体实施例中,所述特征分解模块由多多个qr分解迭代构成,迭代的次数包括所述通道数的5倍;特征分解计算时间的表达式为:tqr=l×c×2k。其中,tqr表示特征分解计算时间,l表示通道数,c表示迭代次数,k表示单次qr分解的时间。在一个具体实施例中,所述协方差矩阵的表达式为:a=xxt其中,a表示协方差矩阵,x表示雷达数据;对所述协方差矩阵进行qr分解,可得:a=qr其中,a表示协方差矩阵,q表示正交矩阵,r表示上三角矩阵,rq与a正交相似,具有相同的特征值。在一个具体实施例中,所述流型阵包括128×128的矩阵;每个谱峰获取的时间为128×128个周期。一种基于硬浮点fpga的雷达超分辨测向系统,包括如下,数据获取单元:用于获取雷达数据,通过多通道形式将所述雷达数据写入硬浮点fpga,所述雷达数据为通道数×快拍数的定点矩阵;协方差计算单元:用于通过所述硬浮点fpga中计算所述雷达数据的协方差矩阵;特征分解单元:用于将所述协方差矩阵由定点模式转换为浮点模式,写入预设的特征分解模块,所述特征分解模块对所述协方差矩阵进行基于qr分解的特征分解计算和基于施密特正交的qr分解计算,获取多个特征值和多个特征向量;噪声计算单元:用于根据预设的信源数门限,参考所述特征值进行信源数判定,结合所述特征向量构造噪声矩阵;谱峰搜索计算单元:用于获取预设的流型阵,根据所述流型阵和所述噪声矩阵计算空间谱,基于预设的向量点乘器进行所述空间谱的计算和搜索,获取谱峰数据;坐标获取单元:用于根据所述谱峰数据获取所述雷达数据对应的空间坐标信息。在一个具体实施例中,所述谱峰搜索计算单元包括,初始谱峰获取单元:用于获取预设的流型阵,根据所述流型阵和所述噪声矩阵计算空间谱,基于预设的向量点乘器进行所述空间谱的计算和搜索,获取谱峰;谱峰迭代单元:用于将所述谱峰作为粗测结果,基于所述粗测结果对所述流型阵进行汇聚和插值处理,获取更新后的流型阵,根据所述噪声矩阵和更新后的流型阵重新计算空间谱,对更新后的空间谱进行计算和搜索,获得更新后的谱峰,重复迭代,直至满足迭代停止条件;谱峰数据获取单元:用于将满足迭代停止条件的谱峰作为所述谱峰数据。一种雷达数据处理设备,包括计算机、光纤和数据计算板卡,所述光纤分别连接所述计算机和所述数据计算板卡;所述数据计算板卡上设置有上述所述的基于硬浮点fpga的雷达超分辨测向系统。有益效果:本发明提出了一种基于硬浮点fpga的雷达超分辨测向方法、系统及数据处理设备,克服了现有技术中的信号处理平台(dsp和常规fpga)在低功耗、轻重量限制及小型化要求下处理能力不足及测量时间过长的缺陷。采用music算法,基于intel硬浮点fpga进行算法的工程化实现。其中以并行的qr迭代方法实现厄米特矩阵特征值分解,以并行的汇聚插值算法实现谱估计,同时基于特殊的硬浮点fpga结构大大提升了doa的计算效率,缩短了计算时间。附图说明图1为本发明实施例1基于硬浮点fpga的雷达超分辨测向方法流程图;图2为本发明实施例1硬浮点fpga的结构图;图3为本发明实施例1向量点乘模块图;图4为本发明实施例1硬浮点ip的模块图;图5为本发明实施例1谱峰示意图;图6为本发明实施例2基于硬浮点fpga的雷达超分辨测向系统结构图;图7为本发明实施例3雷达超分辨测向数据处理设备结构图。为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。附图标记:1-数据获取单元;2-协方差计算单元;3-特征分解单元;4-噪声计算单元;5-谱峰搜索计算单元;6-坐标获取单元;12-计算机;14-光纤;16-数据计算板卡;51-初始谱峰获取单元;52-谱峰迭代单元;53-谱峰数据获取单元。具体实施方式在下文中,将更全面地描述本公开的各种实施例。本公开可具有各种实施例,并且可在其中做出调整和改变。然而,应理解:不存在将本公开的各种实施例限于在此公开的特定实施例的意图,而是应将本公开理解为涵盖落入本公开的各种实施例的精神和范围内的所有调整、等同物和/或可选方案。本发明提供了一种基于硬浮点fpga的雷达超分辨测向方法、系统及数据处理设备,克服了现有技术中的信号处理平台(dsp和常规fpga)在低功耗、轻重量限制及小型化要求下处理能力不足及测量时间过长的缺陷。采用music算法,基于intel硬浮点fpga进行算法的工程化实现。其中以并行的qr迭代方法实现厄米特矩阵特征值分解,以并行的汇聚插值算法实现谱估计,同时基于特殊的硬浮点fpga结构大大提升了doa的计算效率,缩短了计算时间。在雷达系统领域,尤其是在stap、dbf、cfar等雷达关键技术方面,目前使用fpga方案的比较少,仅有少数研究所在从事这方面的研究。这主要是因为:1.国内fpga在雷达方面的应用案例还比较少,缺乏借鉴经验;2.需要对fpga的架构、工具以及算法有深入的了解,才能有效利用fpga;3.算法由dsp、gpu、x86平台移植到fpga平台存在较大的技术难度,平台之间的技术移植受限于平台的规则、技术的复杂度以及技术的适用性等方面,难以进行移植。不同厂家的fpga芯片内部构造不同,尤其是高精度、高速率的fpga,内部构造极为复杂,需要对该芯片程度极深的认识和理解。本发明在某些特定领域,尤其是实时性要求严格的领域,具有很高的应用价值和推广价值。本发明可应用于弹载雷达导引头实时处理系统,使系统具备对高超音速辐射源进行连续、稳定的超分辨率测量的能力。在本公开的各种实施例中使用的术语仅用于描述特定实施例的目的并且并非意在限制本公开的各种实施例。如在此所使用,单数形式意在也包括复数形式,除非上下文清楚地另有指示。除非另有限定,否则在这里使用的所有术语(包括技术术语和科学术语)具有与本公开的各种实施例所属领域普通技术人员通常理解的含义相同的含义。所述术语(诸如在一般使用的词典中限定的术语)将被解释为具有与在相关
技术领域:
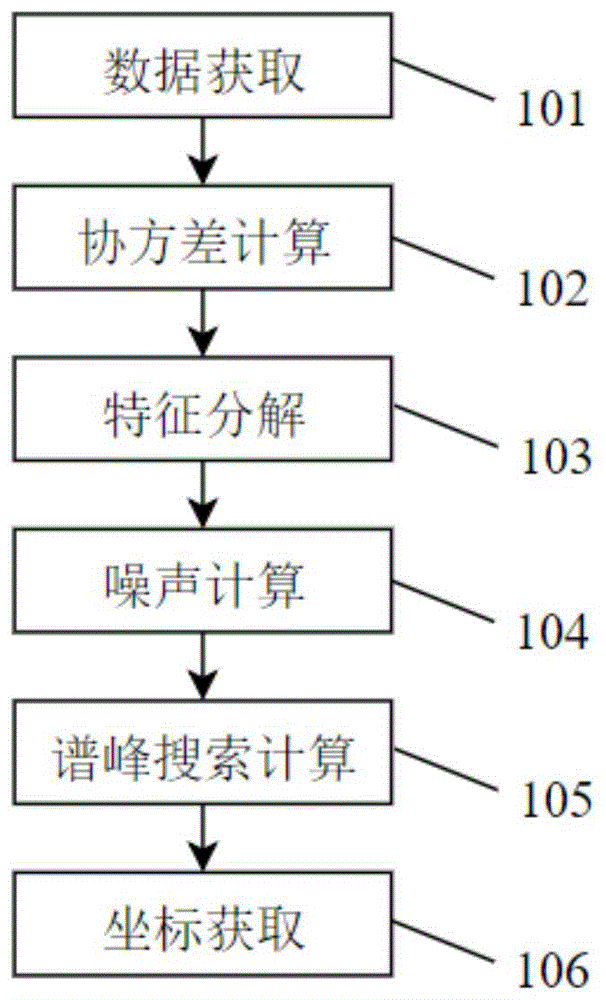
中的语境含义相同的含义并且将不被解释为具有理想化的含义或过于正式的含义,除非在本公开的各种实施例中被清楚地限定。实施例1本发明实施例1公开了一种基于硬浮点fpga的雷达超分辨测向方法,具体步骤如说明书附图1所示,具体方案如下:101、数据获取:获取雷达数据,通过多通道形式将雷达数据写入硬浮点fpga,雷达数据为通道数×快拍数的定点矩阵;102、协方差计算:通过硬浮点fpga中计算雷达数据的协方差矩阵;103、特征分解:将协方差矩阵由定点模式转换为浮点模式,写入预设的特征分解模块,特征分解模块对协方差矩阵进行基于qr分解的特征分解计算和基于施密特正交的qr分解计算,获取多个特征值和多个特征向量;104、噪声构造:根据预设的信源数门限,参考特征值进行信源数判定,结合特征向量构造噪声矩阵;105、谱峰数据获取:获取预设的流型阵,根据流型阵和噪声矩阵计算空间谱,基于预设的向量点乘器进行空间谱的计算和搜索,获取谱峰数据;106、坐标获取:根据谱峰数据获取雷达数据对应的空间坐标信息。随着矩阵阶数增大,定点数据在计算过程中的截位误差累积,造成最终结果精度大幅下降,难以满足应用需求,因此必须采用浮点处理。但常规fpga进行浮点计算时,采用的软浮点(用逻辑构造乘加运算)结构,在运行过程中会降低矩阵求逆的效率。针对这一弊端,本发明采用业界第一款硬浮点架构的fpga(intelarria10)实现浮点复矩阵求逆运算,极大提升了求逆算法的效率具体地,本实施例为了提升运算效率,设计选用搭载硬浮点dsp计算单元的intelarria10系列fpga实现,芯片内部结构如说明书附图2所示。该dsp单元采用芯片硬件定制浮点设计,遵循ieee754标准,单个dsp即可实现一个浮点加法和一个浮点乘法,无需额外的逻辑资源。此外通过调整dsp内部流水寄存器级数,可以满足不同的latency和fmax的需求,无需在timing上做过多努力,就能工作在极高的工作频率。在浮点计算密集的情况下,arria10比起业界同等级的fpga在资源、效率、运算速度方面均有明显优势。相对于传统fpga,本实施例采用的雷达超分辨测向方法在求逆算法效率上能够提升2-3倍。具体地,101、数据获取:获取雷达数据,通过多通道形式将雷达数据写入硬浮点fpga,雷达数据为通道数×快拍数的定点矩阵。雷达数据通过高速串行总线发送,在写入硬浮点fpga之前,还需要对雷达数据进行数据下变频处理。数字下变频,是指在超外差式接收机中经过混频后得到的中频信号比原始信号的频率低的一种混频方式。具体地,102、协方差计算:通过硬浮点fpga中计算雷达数据的协方差矩阵。计算单元dot(向量点乘器)的并行宽度通常为快拍数的8分之1。如果通道数为8,协方差矩阵计算时间为8×8×(512/8)=1024时钟周期。为了节省bram,需考虑:(1)协方差矩阵计算为定点模式,计算完成后转为单精度浮点模式;(2)计算所需的共轭对称矩阵用原始矩阵变换,无需存储。具体的协方差矩阵计算包括:输入雷达数据x,快拍数为m,通道数为n,协方差矩阵地表达式为:a=xxt其中,雷达回波数据x为n×m的定点矩阵。具体地,103、特征分解:将协方差矩阵由定点模式转换为浮点模式,写入预设的特征分解模块,特征分解模块对协方差矩阵进行基于qr分解的特征分解计算和基于施密特正交的qr分解计算,获取多个特征值和多个特征向量。将协方差矩阵转为由定点模式转为浮点模式,写入特征分解模块的bram缓存。其中,特征分解模块由qrd(qr分解)迭代构成,迭代的次数可通过上位机设置,迭代次数通常为通道数的1.5倍。特征分解模块的启动信号由协方差矩阵计算完成信号经延时形成,即协方差矩阵计算完成后,延时预设时间即可启动特征分解模块。特征分解包括基于qr分解的特征分解计算、基于施密特正交的qr分解计算和关键算子dot(向量点乘)的硬浮点实现。基于qr分解的特征分解计算包括:对于非奇异方阵a,进行qr分解,可得a=qr,其中r为上三角矩阵,q为正交矩阵,即qtq=i,i为单位矩阵。则可推导出:qtaq=qtqrq=rq也就是说,rq与a是正交相似的,它们具有相同的特征值。因此可以采用如下的qr迭代格式:ak=qkrk,k∈nak+1=qk+1rk+1,k∈n取a1=a,经过第二个迭代式进行迭代,可以证明ak收敛于矩阵a的特征值,即uk=q1q2…qk。基于施密特正交的qr分解计算,本实施例通过matlab实现,具体代码如下:关键算子dot(向量点乘)的硬浮点实现涉及到n维方阵相乘,需要计算n×n次n维向量点乘。向量点乘的运算效率对整个方法的实现效率具有非常关键的作用,本实施例采用脉动架构实现向量点乘,可大大降低fpga的资源占用,提升fpga的运算效率。具体结构如说明书附图3所示。高效率的浮点算子(如浮点加,减,乘,向量点乘),都可以采用quartus的硬浮点ip生成,如说明书附图4所示。特征分解计算时间的表达式为:tqr=l×c×2k。其中,tqr表示特征分解计算时间,l表示通道数,c表示迭代次数,k表示单次qr分解的时间。如果通道数为8,特征分解计算时间约为8×1.5×2k(单次qrd时间)=24k时钟周期,完成特征分解计算后,输出8个特征值(d1,....d8)和8个特征向量(v1,....v8)。具体地,104、噪声构造:根据预设的信源数门限,参考特征值进行信源数判定,结合特征向量构造噪声矩阵。105、谱峰数据获取:获取预设的流型阵,根据流型阵和噪声矩阵计算空间谱,基于预设的向量点乘器进行空间谱的计算和搜索,获取谱峰数据。根据上位机设定的信源数门限,参考103获取的8个特征值结果,进行信源数判定,再选出相应的特征向量,形成噪声矩阵。然后读入ddr(双倍速率同步动态随机存储器)中的流型阵,计算空间谱。整个空间谱的计算和搜索过程基于dot(向量点乘器)全部展开,每个谱峰点的计算/搜索时间为1个周期,整个谱峰生成,搜索时间为128×128=16384周期。噪声空间计算具体包括:将矩阵的特征值λ进行从小到大的排序:λ1≥λ2≥...≥λm>0,其中d个较大的特征值对应于信号,m-d个较小的特征值对应于噪声。用噪声向量构造一个噪声矩阵:en=[vd+1,vd+2,...,vm]空间谱的表达式为:其中,pmu表示空间谱,a表示流型阵,en表示噪声矩阵,h表示矩阵共轭转置。空间谱生成也基于大量的向量点乘(dot),采用并行脉动架构可大大降低fpga的资源占用。谱峰搜索计算具体包括:采用并行九宫搜峰算法进行谱峰搜索。九宫搜峰算法如表1所示表1九宫搜峰算法p1p2p3p4p5p6p7p8p9p5>(p1,p2,p3,p4,p6,p7,p8,p9)andp5>搜峰门限其中,p5为所需谱峰,其坐标对应为辐射源的俯仰和方向角,谱峰搜索模块有大量并行浮点比较器构成。特别地,在本实施例中,谱峰数据的获取需要经过迭代。一次完整的空间谱搜索和计算往往不能满足测量精度的需求。本实施例通过前一次搜索的峰值更新流型阵,进而实现谱峰的更新,大大提升了测量精度。具体流程如下:初始谱峰获取:获取预设的流型阵,根据流型阵和噪声矩阵计算空间谱,基于预设的向量点乘器进行空间谱的计算和搜索,获取谱峰。此时的谱峰为第一次搜峰完成后的结果。谱峰迭代:将谱峰作为粗测结果,基于粗测结果对流型阵进行汇聚和插值处理,获取更新后的流型阵,根据噪声矩阵和更新后的流型阵重新计算空间谱,对更新后的空间谱进行计算和搜索,获得更新后的谱峰,重复迭代,直至满足迭代停止条件。谱峰数据获取:将满足迭代停止条件的谱峰作为谱峰数据。例如,为进一步提升测量精度,在上一次搜峰(粗测)完成后,可以改变流型阵(基于粗测结果,对流型阵进行汇聚、插值),进行第二次测量(精测)。精测时间与粗测相同,测量精度的提升与插值的倍数相关。106、坐标获取:根据谱峰数据获取雷达数据对应的空间坐标信息。峰值数据示意如说明书附图5所示。本实施例采用的方法与现有技术中不同平台music性能对比如表2所示:(music规格,8通道数,512快拍数,128×128流型阵)表2性能对比表由上述实验结果可以看出,采用本实施例提供的方法,在处理时间和设备时延上远远领先现有技术。实际测试测试结果表明,本实施例提供的方法在满负荷工作时,功耗小于20w,远低于同样性能的dsp/gpu(提升3-5倍能效比)。本实施例提供的方法克服了现有的信号处理平台(dsp和常规fpga)在低功耗、轻重量限制及小型化要求下处理能力不足及测量时间过长的缺陷。本实施例提供了一种基于硬浮点fpga的雷达超分辨测向方法,可应用于弹载实时处理系统中。该方法克服了现有技术中的信号处理平台(dsp和常规fpga)在低功耗、轻重量限制及小型化要求下处理能力不足及测量时间过长的缺陷。采用music算法,基于intel硬浮点fpga进行算法的工程化实现。其中以并行的qr迭代方法实现厄米特矩阵特征值分解,以并行的汇聚插值算法实现谱估计,同时基于特殊的硬浮点fpga结构大大提升了doa的计算效率,缩短了计算时间。实施例2本发明实施例2公开了一种基于硬浮点fpga的雷达超分辨测向系统,在实施例1的基础上,将实施例1的方法系统化,使其更具实际应用性。系统的结构图如说明书附图6所示,具体方案如下:一种基于硬浮点fpga的雷达超分辨测向系统,包括依次连接的数据获取单元1、协方差计算单元2、特征分解单元3、噪声计算单元4、谱峰搜索计算单元5和坐标获取单元6。数据获取单元1:用于获取雷达数据,通过多通道形式将雷达数据写入硬浮点fpga,雷达数据为通道数×快拍数的定点矩阵。数据在写入硬浮点fpga之前,还包括对雷达数据进行数字下变频处理。协方差计算单元2:用于通过硬浮点fpga中计算雷达数据的协方差矩阵。协方差计算单元2计算协方差时为定点模式,计算完成后转为单精度浮点,计算协方差所需的共轭对称矩阵用原始矩阵变换,无需存储。特征分解单元3:设置有特征分解模块,用于将协方差矩阵由定点模式转换为浮点模式,写入预设的特征分解模块,特征分解模块对协方差矩阵进行基于qr分解的特征分解计算和基于施密特正交的qr分解计算,获取多个特征值和多个特征向量。特征分解模块有qrd(qr分解)迭代构成,迭代的次数可有上位机设置,通常为通道数的1.5倍。特征分解模块的启动信号由协方差矩阵计算完成信号经延时形成。在本实施例中,通道数为8,特征分解计算时间约为8×1.5×2k(单次qrd时间)=24k时钟周期,完成计算后,输出8个特征值(d1,....d8)和8个特征向量(v1,....v8)。噪声计算单元4:用于根据预设的信源数门限,参考特征值进行信源数判定,结合特征向量构造噪声矩阵。根据上位机设定的信源数门限,参考8个特征值结果,进行信源数判定,再选出相应的特征向量,形成噪声矩阵。谱峰搜索计算单元5:用于获取预设的流型阵,根据流型阵和噪声矩阵计算空间谱,基于预设的向量点乘器进行空间谱的计算和搜索,获取谱峰数据。读入ddr(双倍速率同步动态随机存储器)中的流型阵a(128*128矩阵),计算空间谱。整个空间谱的计算和搜索过程基于dot(向量点乘器)全部展开,每个谱峰点的计算/搜索时间为1个周期,整个谱峰生成及搜索时间为128×128=16384周期。坐标获取单元6:用于根据谱峰数据获取雷达数据对应的空间坐标信息。此外,谱峰搜索单元5包括初始谱峰获取单元51、谱峰迭代单元52和谱峰数据获取单元53。具体包括:初始谱峰获取单元51:用于获取预设的流型阵,根据流型阵和噪声矩阵计算空间谱,基于预设的向量点乘器进行空间谱的计算和搜索,获取谱峰;谱峰迭代单元52:用于将谱峰作为粗测结果,基于粗测结果对流型阵进行汇聚和插值处理,获取更新后的流型阵,根据噪声矩阵和更新后的流型阵重新计算空间谱,对更新后的空间谱进行计算和搜索,获得更新后的谱峰,重复迭代,直至满足迭代停止条件;谱峰数据获取单元53:用于将满足迭代停止条件的谱峰作为谱峰数据。本实施例提供了一种基于硬浮点fpga的雷达超分辨测向系统,在实施例1的基础上,将实施例1的方法系统化,使其更具实际应用性。实施例3本发明实施例提供了一种雷达数据处理设备,结构如说明书附图7所示,具体方案如下:一种雷达数据处理设备,包括计算机12、光纤14和数据计算板卡16,光纤14分别连接计算机12和数据计算板卡16。数据计算板卡16上设置有实施例2所述的基于硬浮点fpga的雷达超分辨测向系统。本实施例提供了一种雷达数据处理设备,将实施例2的系统应用到具体场景。本发明提供了一种基于硬浮点fpga的雷达超分辨测向方法、系统及数据处理设备,克服了现有技术中的信号处理平台(dsp和常规fpga)在低功耗、轻重量限制及小型化要求下处理能力不足及测量时间过长的缺陷。采用music算法,基于intel硬浮点fpga进行算法的工程化实现。其中以并行的qr迭代方法实现厄米特矩阵特征值分解,以并行的汇聚插值算法实现谱估计,同时基于特殊的硬浮点fpga结构大大提升了doa的计算效率,缩短了计算时间。本领域技术人员可以理解附图只是一个优选实施场景的示意图,附图中的模块或流程并不一定是实施本发明所必须的。本领域技术人员可以理解实施场景中的装置中的模块可以按照实施场景描述进行分布于实施场景的装置中,也可以进行相应变化位于不同于本实施场景的一个或多个装置中。上述实施场景的模块可以合并为一个模块,也可以进一步拆分成多个子模块。上述本发明序号仅仅为了描述,不代表实施场景的优劣。以上公开的仅为本发明的几个具体实施场景,但是,本发明并非局限于此,任何本领域的技术人员能思之的变化都应落入本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1