基于LSTM神经网络模型的MEMS惯性导航系统定位增强方法
基于lstm神经网络模型的mems惯性导航系统定位增强方法
技术领域
1.本发明属于导航系统技术领域,具体涉及一种基于lstm神经网络模型的mems惯性导航系统定位增强方法。
技术背景
2.惯性导航系统(inertial navigation system,ins)是一种用于相对定位的系统,能够在已知载体初始位姿状态的前提下,利用航迹推算原理持续计算载体的位姿变化。ins主要包含惯性测量单元(inertial measurement unit,imu)模块和运算模块。其中,imu能够通过三轴加速度计和陀螺仪对载体的加速度和角速度进行实时测量;运算模块能够根据imu的测量值逐次积分,计算出载体的相对位姿变化。ins在实际运行过程中常伴随环境噪声、机械噪声、制造误差等干扰源,影响其定位精度。高成本ins具有精密的传感器(imu、磁力计等)和成熟的滤波算法,能够有效抑制干扰源对其定位性能的影响。然而,昂贵的成本限制了其在多领域中的批量生产和落地应用。
3.微机电系统(micro
‑
electro
‑
mechanical systems,mems)传感器是依托微电子和微机械加工技术制造而成的新型传感器。与高成本ins相比,mems惯性导航系统(mems
‑
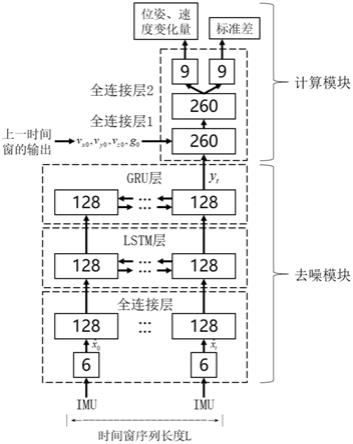
ins)具有成本低廉、安装简便、体积小、功耗低等优点,被广泛应用于运动捕捉追踪、车辆定位导航等产研领域中。然而,mems
‑
ins中配备的低成本mems
‑
imu模块在运行时易受前述干扰源的影响,其测量值通常掺杂大量噪声。另一方面,由于ins具有“自封闭”的特性,即其定位过程无需借助任何外部信息源(如卫星信号或基站)的辅助。这将导致ins定位误差随运行时间无限累积。噪声干扰问题和误差累积问题是mems
‑
ins研究和应用的关键问题和瓶颈问题。因此,亟需选用合适的算法对mems
‑
imu进行去噪,并采取的合适措施减弱ins的误差累积效应,以减小多种干扰源对mems
‑
ins定位性能的影响。这对mems
‑
ins的性能提升和产研应用均具有重要意义和实用价值。
4.目前,mems
‑
imu的主流去噪方法包括离散小波变换(discrete wavelet transform,dwt)、经验模态分解(empirical mode decomposition,emd)以及深度学习(deeplearning)等。dong等人采用改进阈值的dwt方法,以降低mems
‑
imu中的随机噪声。然而dwt方法中设置的基函数是先验固定的且dwt方法不适用于非线性信号的处理。emd方法能够在一定程度上克服dwt方法的缺陷,omitaomu等人提出了基于emd的分组重构去噪方法,以滤除imu原始信号中的高频(或低频)噪声。但是emd方法仍存在模态混叠的不足,模态混叠的出现不仅会导致imu信号错假的时频分布,更使其本征模态函数失去物理意义。近年来,深度学习技术在机器视觉、自然语言处理等领域发展迅速。特别是循环神经网络(recurrent neural network,rnn),其对于时序信息拥有良好的建模能力,故也被应用于imu时序信号的去噪中。jiang,han等学者均设计了多层长短期记忆(long short
‑
term memory,lstm)rnn神经网络,对imu原始数据进行去噪,与传统方法相比取得了更好的去噪效果。专利《一种基于循环神经网络的imu数据去噪方法》(申请号:201910888811.2)同样设计了lstm神经网络模型以对mems
‑
imu进行去噪。
5.上述针对mems
‑
imu进行优化的方法仅从原始信号去噪角度考虑如何尽可能恢复imu的真实测量信号,能够在一定程度上提高mems
‑
imu的定位性能。但是,噪声是无法避免的,任何微小误差经过运算模块积分运算后都会随时间不断累积,最终产生极大的定位误差。相关现有技术和方法对传统ins中运算模块因逐次积分而导致的误差累积缺乏考虑与改进。
技术实现要素:
6.本发明所要解决的技术问题主要有二:
7.在载体的运动过程中,环境噪声、机械噪声、制造误差等干扰源会将噪声引入imu中。且不同环境、不同工况下的噪声特性不同,导致imu中的噪声具有很强的复杂性和不确定性。现有的mems
‑
imu由于成本因素限制,对加速度、角速度等测量信号缺乏精细的去噪处理,使得上述噪声持续影响imu的测量精度,致其测量结果迅速发散。本发明基于lstm神经网络模型,针对mems
‑
imu设计去噪层,通过足量样本数据离线训练后,该模型能够有效减少各种干扰源对imu的影响,提升其测量准确性。
8.现有的ins均使用逐次积分的方法计算载体相对时刻的位姿变化量。imu测量误差经积分运算后将产生累积效应,导致ins的定位精度随时间迅速下降。本发明基于lstm神经网络模型,将imu的加速度、角速度测量作为模型输入,载体的相对位姿变化量作为模型输出;将ins的航迹推算原理直接抽象为模型输入与输出之间的非线性映射关系,通过深度学习的方法对lstm神经网络模型进行离线训练,从而能够有效解决ins的误差累积问题,获得更精确的载体相对位姿变化。
9.本发明提供的技术方案:
10.基于lstm神经网络模型的mems惯性导航系统定位增强方法,包括以下步骤:
11.s1、神经网络模型搭建
12.面向mems
‑
ins定位增强的lstm神经网络模型包含两个模块,即去噪模块和计算模块;
13.去噪模块由一个全连接层、一个lstm层和一个门控循环单元gru层依次连接组成,其作用是对mems
‑
imu测量的时序信号进行去噪处理,输出去噪后的imu信号序列;
14.计算模块由两个全连接层连接组成,其作用是根据去噪处理后的imu时序信号计算出载体相对时刻间的位姿变化量。
15.lstm层由多个首尾相连的lstm单元组成。
16.记imu原始测量信号为其主要包含三轴加速度计测量(a
x
,a
y
,a
z
)和三轴陀螺仪测量(ω
x
,ω
y
,ω
z
)6个分量。进入lstm层之前,将首先进入全连接层。记lstm单元的imu输入张量为x
t
,lstm单元的输出张量为y
t
17.全连接层由多个具有6
‑
128个神经元的全连接单元组成,其作用是将中的6个分量转化为具有128个数据分量的x
t
,进而与lstm层输入张量的维度相匹配;
18.全连接层后的lstm层与gru层均具有128个隐藏节点。
19.计算模块由具有260
‑
260个神经元的全连接层1和260
‑
18个神经元的全连接层2连接组成;全连接层1中取时间窗内最终时刻双向gru单元的输出量y
t,bi
‑
gru
作为前256个输入,
取时间窗内的载体初速度和重力加速度(v
x0
,v
y0
,v
z0
,g0)作为全连接层1的后4个输入;
20.全连接层2的作用是输出时间窗内载体位姿和速度变化量outputs=(δp
x
,δp
y
,δp
z
,δα
x
,δα
y
,δα
z
,δv
x
,δv
y
,δv
z
)及其不确定度(标准差)σ3×3=(σ
pos
,σ
att
,σ
vel
)。
21.本发明模型的完整数学表达为:
[0022][0023]
其中,为当前时间窗内imu的所有线加速度和角速度测量数据,v0为当前时间窗的初始线速度,g0为当前时间窗的初始重力加速度。
[0024]
s2、数据集获取及预处理
[0025]
神经网络搭建完毕后,需要采集数据并对数据集进行预处理,以供神经网络的训练与测试。本发明拟使用陆地车辆作为mems
‑
ins的载体用于数据集获取。
[0026]
具体地,将mems
‑
imu与高精度gnss/ins组合导航系统(作为基准)固连安装于载体上。
[0027]
在车辆运动的过程中,利用电脑(或工控机)同时采集上述两种传感器的测量数据。
[0028]
采集足量数据后,需按照时间窗序列长度l对数据集进行分割预处理。具体地,将mems
‑
imu采集的加速度、角速度数据分割成(l
×
sample num
×
input features)的维度大小。其中sample num为分割后的样本总数,input features为输入张量的种类数。将高精度gnss/ins组合导航系统采集的位姿、速度数据按照时间窗序列长度l逐段划分,并计算各窗口始末的位姿变化量与速度变化量,再将位姿变化量与速度变化量由导航坐标系转换到载体坐标系中,最终得到标签张量的维度大小为(sample num
×
output features)。其中output features为输出张量的种类数。
[0029]
最后,将预处理后的数据集依照8:2的比例分为训练集和测试集,以对本发明提出的神经网络模型进行训练和测试。
[0030]
s3、神经网络模型训练与测试
[0031]
本发明定义损失函数为均方误差(mse)损失函数,即表示神经网络模型预测值与基准值的欧氏距离之和,如下式所示:
[0032][0033]
训练阶段,本发明使用adam优化器对神经网络模型中的权重进行优化计算,初始学习率设置为10
‑4。
[0034]
本发明设定最大训练步数为1000epochs(周期),在每个训练周期中,通过前向传播计算神经网络模型的预测输出以及对应的损失函数;通过反向传播算法与adam优化器对模型的权重进行优化。
[0035]
在训练过程中每经过20epochs对神经网络模型的损失函数进行比较,若损失函数收敛到预设的阈值以内,则代表训练完成,终止对神经网络模型的训练。
[0036]
测试阶段,将测试集中的数据输入到训练完毕后的lstm神经网络模型中,计算神经网络模型的预测输出与损失函数值,进而评估神经网络模型的性能。
[0037]
最终,将经训练与测试后的lstm神经网络模型,用于低成本mems
‑
ins的实际使用中。将设定时间窗序列长度中mems
‑
imu测得的原始数据作为神经网络模型的输入,模型最
终输出当前时间窗始末载体的相对位姿变化量。
[0038]
本发明具有的有益效果:
[0039]
本发明提出的神经网络模型能够有效降低环境噪声、机械噪声、制造误差等多种干扰源对mems
‑
ins的影响,能够提高mems
‑
ins相对定位的准确性和鲁棒性。
[0040]
与传统的逐次积分法相比,本发明采用神经网络模型直接表征ins输入与输出之间的非线性映射关系。改善后的ins定位精度理论上能够达到与基准数据同级,本发明中的技术方案为厘米级,因而有效解决ins的误差累积问题,且大大提升了ins的定位精度。
附图说明
[0041]
图1为本发明面向mems
‑
ins定位增强的lstm神经网络模型;
[0042]
图2为本发明lstm单元结构图;
[0043]
图3为本发明gru单元结构图;
[0044]
图4为本发明典型全连接层示意图。
具体实施方式
[0045]
结合附图说明本发明的具体技术方案。
[0046]
本发明提供的完整技术方案依次通过以下三个步骤实施:
[0047]
基于lstm神经网络模型的mems惯性导航系统定位增强方法,包括以下步骤:
[0048]
s1、神经网络模型搭建
[0049]
面向mems
‑
ins定位增强的lstm神经网络模型包含两个模块,即去噪模块和计算模块,如图1所示。
[0050]
去噪模块由一个全连接层、一个lstm层和一个门控循环单元(gated recurrent unit,gru)层依次连接组成,其作用是对mems
‑
imu测量的时序信号进行去噪处理;计算模块由两个全连接层连接组成,其作用是根据去噪处理后的imu时序信号计算出载体相对时刻间的位姿变化量。
[0051]
典型的lstm层由多个首尾相连的lstm单元组成。与传统的rnn相比,lstm能够有效解决梯度消失的问题,且能够有效处理长跨度输入间的依赖关系,因此能够更好地进行时序信号的建模和预测。
[0052]
本实施例的一个lstm单元的结构如图2所示。区别于传统的rnn,lstm中存在两个隐含状态c
t
和h
t
。记lstm单元的imu输入张量为x
t
,lstm单元的输出张量为y
t
,其隐含状态的更新过程阐述如下:
[0053]
首先,根据上一时刻的隐含状态h
t
‑1和当前时刻输入张量x
t
进行四个不同的线性变换,并应用不同的激活函数输出四个不同的值,如下式所示:
[0054]
f
t
=σ(w
if
·
x
t
+b
if
+w
hf
·
h
t
‑1+b
hf
)
[0055]
i
t
=σ(w
ii
·
x
t
+b
ii
+w
hi
·
h
t
‑1+b
hi
)
[0056]
g
t
=tanh(w
ig
·
x
t
+b
ig
+w
hg
·
h
t
‑1+b
hg
)
[0057]
o
t
=σ(w
io
·
x
t
+b
io
+w
ho
·
h
t
‑1+b
ho
)
[0058]
其中,w和b分别代表施加于各输入量的权重和偏置;σ代表sigmoid激活函数;tanh代表tanh激活函数。sigmoid激活函数能够把任意输入量,非线性映射为(0,1)之间的输出
量,表示流入信息的比重多少;tanh激活函数能够把任意输入量,非线性映射为(
‑
1,1)之间的输出量,表示流入的信息。通过以上四式即可将非线性特征引入到lstm神经网络模型中。
[0059]
可以用“门控”的观点解释lstm的作用机理。f
t
被称为“遗忘门”,在计算当前时刻隐含状态c
t
时,需要用到f
t
×
c
t
‑1,即通过f
t
的大小控制上一时刻隐含状态c
t
‑1流入到当前时刻c
t
的多少,以实现对先前时刻信息的选择性遗忘。g
t
能够计算流入当前时刻lstm单元中的信息,i
t
被称为“输入门”,能够控制g
t
流到神经网络信息的多少。通过遗忘门和输入门的作用,当前时刻更新后的隐含状态c
t
的信息由下式给出:
[0060]
c
t
=f
t
×
c
t
‑1+i
t
×
g
t
[0061]
最后,由“输出门”o
t
控制当前时刻lstm单元的输出y
t
,其计算式如下:y
t
=h
t
=o
t
×
tanhc
t
[0062]
其中,tanhc
t
表示c
t
流入到输出量中的信息,o
t
控制流入信息的比重。当前时刻lstm单元的输出量y
t
即等于当前时刻的隐含状态h
t
。
[0063]
综上,lstm单元能够有目的性地遗忘上一时刻的信息,同时控制当前时刻的输入信息。多个lstm单元首尾相联形成的lstm神经网络层对于imu量测时序信号具有良好的建模能力。
[0064]
gru作为lstm的一种变体,对lstm的网络结构做了适度简化,如图3所示。相比于lstm,gru中只有一个隐含状态h
t
。
[0065]
通过输入张量x
t
和隐含状态h
t
‑1的线性变换,首先计算得到隐含状态流入的权重r
t
和z
t
:
[0066]
r
t
=σ(w
ir
·
x
t
+b
ir
+w
hr
·
h
t
‑1+b
hr
)
[0067]
z
t
=σ(w
iz
·
x
t
+b
iz
+w
hz
·
h
t
‑1+b
hz
)
[0068]
其中r
t
用于和h
t
‑1的线性变换相乘,同时和输入张量x
t
的线性变换相加,使用tanh激活函数计算得到隐含状态的中间更新值n
t
:
[0069]
n
t
=tanh(w
in
·
x
t
+b
in
+r
t
×
(w
hn
·
h
t
‑1+b
hn
))
[0070]
z
t
用于计算n
t
和上一时刻隐含状态h
t
‑1的混合权重:
[0071]
y
t
=h
t
=(1
‑
z
t
)
×
n
t
+z
t
×
h
t
‑1[0072]
最终,当前时刻gru单元的输出结果y
t
同样等于h
t
。相比于lstm,gru缺少一个隐含状态c
t
,故其计算量较小,但它们构造模型表现出的准确率相近。
[0073]
记imu原始测量信号为其主要包含三轴加速度计测量(a
x
,a
y
,a
z
)和三轴陀螺仪测量(ω
x
,ω
y
,ω
z
)6个分量。进入lstm层之前,将首先进入全连接层。典型全连接层的结构如图4所示。该全连接层由多个具有6
‑
128个神经元的全连接单元组成,其作用是将中的6个分量转化为具有128个数据分量的x
t
,进而与lstm层输入张量的维度相匹配。
[0074]
全连接层后的lstm层与gru层均具有128个隐藏节点,增加隐藏节点(神经元)的目的是提高本发明神经网络模型刻画imu复杂数据特征的能力。
[0075]
本实施例中,单个lstm层(gru层)所具有的lstm单元(gru单元)数目称为时间窗的序列长度l,表示单次处理mems
‑
imu测量数据的时间跨度。l越大,即表示模型采用越长的imu数据序列进行学习,所得到的预测结果更加精确,但增加了计算负担。
[0076]
进一步地,为更好地表达imu数据特征,本实施例设计了lstm与gru混合的双层神
经网络架构。其中,在lstm
‑
lstm、gru
‑
lstm、gru
‑
gru、lstm
‑
gru四种混合方式中,本发明优选性能最佳的lstm
‑
gru混合方式作为去噪模块主体的神经网络结构,如图1所示。通过lstm
‑
gru混合双层神经网络模型,去噪模块能够识别和削减当前时间窗内imu原始测量信号带有的环境噪声、机械噪声、制造误差等干扰因素,输出去噪后的imu信号序列。
[0077]
为防止模型的过拟合,本发明在lstm层和gru层之后均采用了dropout技术。神经网络模型的过拟合指模型在训练集上有较好的效果,但是在测试集上的效果很差,过拟合会导致模型的差泛化能力。之前很多学者已经充分证明了采用dropout技术能有效解决神经网络的过拟合问题。具体地,在训练模型时引入dropout,部分按比例随机选定的神经网络节点和其相连的边会暂时关闭,不参与当次的训练。
[0078]
本发明认为过去时刻和未来时刻的imu数据信息都与当前时刻的imu数据信息息息相关,合理建立它们之间的时序关系能够使去噪模块具有更好的效果。故本发明采用双向lstm和双向gru的结构,如图1所示,以充分刻画当前时刻imu数据信息与过去、未来时刻信息之间的相关性。
[0079]
作为本发明的核心,计算模块由具有260
‑
260个神经元的全连接层1和260
‑
18个神经元的全连接层2连接组成,如图1所示。全连接层1中取时间窗内最终时刻双向gru单元的输出量y
t,bi
‑
gru
作为前256个输入。根据航迹推算原理,仅根据去噪后的imu信号序列无法直接求得载体的相对位姿变化,求解相对位姿变化还需要载体初速度v0=(v
x0
,v
y0
,v
z0
)、重力加速度g0等已知量。故取时间窗内的载体初速度和重力加速度(v
x0
,v
y0
,v
z0
,g0)作为全连接层1的后4个输入。全连接层2的作用是输出时间窗内载体位姿和速度变化量outputs=(δp
x
,δp
y
,δp
z
,δα
x
,δα
y
,δα
z
,δv
x
,δv
y
,δv
z
)及其不确定度(标准差)σ3×3=(σ
pos
,σ
att
,σ
vel
)。
[0080]
假设神经网络模型输出的载体位姿和速度变化量服从高斯分布则其对应标准差可通过非监督学习的方法获得。
[0081]
基于以上对本发明所用神经网络模型的剖析,本发明模型的完整数学表达为:
[0082][0083]
其中,为当前时间窗内imu的所有线加速度和角速度测量数据,v0为当前时间窗的初始线速度,g0为当前时间窗的初始重力加速度。
[0084]
本发明提出的神经网络模型能够通过多种开源深度学习框架搭建,主流的有:tensorflow、pytorch等。这些深度学习框架已经被广泛使用,并取得了极好的效果。
[0085]
s2、数据集获取及预处理
[0086]
神经网络搭建完毕后,需要采集数据并对数据集进行预处理,以供神经网络的训练与测试。本发明拟使用陆地车辆作为mems
‑
ins的载体用于数据集获取。
[0087]
具体地,将mems
‑
imu与高精度gnss/ins组合导航系统(作为基准)固连安装于载体上。全球卫星导航系统(global navigation satellite system,gnss)与高精度ins互补结合的高精度gnss/ins组合导航系统利用载波相位差分技术能够在大多数环境下达到后处理厘米级的定位精度,故在本发明中用于为神经网络模型提供训练基准(标签)。
[0088]
在车辆运动的过程中,利用电脑(或工控机)同时采集上述两种传感器的测量数据。在采集数据的过程中,需要车辆遍历多种不同的路面环境,以尽可能获取不同的噪声特
性,这有助于提升模型的泛化性能。此外,采集数据时需要车辆执行直行、转向、加速、制动等机动类型,并将上述机动类型混合执行,以尽可能多地获取载体加速度和角速度的可能状态,以提高数据集的完备程度、模型的精确度和鲁棒性。
[0089]
采集足量数据后,需按照时间窗序列长度l对数据集进行分割预处理。具体地,将mems
‑
imu采集的加速度、角速度数据分割成(l
×
sample num
×
input features)的维度大小。其中sample num为分割后的样本总数,input features为输入张量的种类数。将高精度gnss/ins组合导航系统采集的位姿、速度数据按照时间窗序列长度l逐段划分,并计算各窗口始末的位姿变化量与速度变化量,再将位姿变化量与速度变化量由导航坐标系转换到载体坐标系中,最终得到标签张量的维度大小为(sample num
×
output features)。其中output features为输出张量的种类数。
[0090]
最后,将预处理后的数据集依照8:2的比例分为训练集和测试集,以对本发明提出的神经网络模型进行训练和测试。
[0091]
s3、神经网络模型训练与测试
[0092]
本发明定义损失函数为均方误差(mse)损失函数,即表示神经网络模型预测值与基准值的欧氏距离之和,如下式所示:
[0093][0094]
训练阶段,本发明使用adam优化器对神经网络模型中的权重进行优化计算,初始学习率设置为10
‑4。adam算法是一种基于梯度的优化算法,其具有实现简洁,计算高效等诸多优点,已被广泛应用于多种深度学习任务中。
[0095]
本发明设定最大训练步数为1000epochs(周期),在每个训练周期中,通过前向传播计算神经网络模型的预测输出以及对应的损失函数;通过反向传播算法与adam优化器对模型的权重进行优化。
[0096]
在训练过程中每经过20epochs对神经网络模型的损失函数进行比较,若损失函数收敛到预设的阈值以内,则代表训练完成,终止对神经网络模型的训练。
[0097]
测试阶段,将测试集中的数据输入到训练完毕后的lstm神经网络模型中,计算神经网络模型的预测输出与损失函数值,进而评估神经网络模型的性能。
[0098]
最终,将经训练与测试后的lstm神经网络模型,用于低成本mems
‑
ins的实际使用中。将设定时间窗序列长度中mems
‑
imu测得的原始数据作为神经网络模型的输入,模型最终输出当前时间窗始末载体的相对位姿变化量。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1