基于深度Bi-LSTM网络的近红外光谱模型迁移方法
基于深度bi-lstm网络的近红外光谱模型迁移方法
技术领域
1.本发明涉及基于深度bi-lstm网络的近红外光谱模型迁移方法,属于近红外模型转移技术领域。
背景技术:
2.近红外光谱技术是一种无损快速分析方法,在化学成分测定的快速分析方面得到广泛应用。然而在现实应用中,外部测量环境的改变(如不同光谱仪间、不同温度间、不同时间)会导致与原有模型不匹配,这间接制约了近红外光谱技术的普及。由于近红外光谱吸收带是有机物中能量较高的化学键(主要是ch、oh、nh)在中红外光谱区基频吸收的倍频、合频和差频吸收带叠加而成,因此近红外光谱区存在严重重叠性,某些物质的光谱相似却有着细微区别,使原有的定量模型不再兼容新物质含量的预测,因此模型迁移是对光谱模型间一致性的修复。
3.大数据时代下,标注数据成为了一项枯燥无味且代价巨大的任务。将迁移学习应用于近红外光谱技术,能够充分利用现有“过期”数据,对源域“过期”有标记数据进行有效的权重分配,让源域“过期”数据的分布接近目标域数据的分布,从而在目标域建立精度高、性能稳定的定量模型。另外,结合神经网络充分挖掘数据特征的优势,推进近红外光谱技术在更多检测领域的应用,对规范市场、保障人民利益、节约资源具有现实意义。
4.目前,基于深度bi-lstm网络的近红外光谱模型迁移方法仍处于空白研究阶段。
技术实现要素:
5.本发明的目的是提供一种基于深度bi-lstm网络的近红外光谱模型迁移方法,来解决不同外部测量环境造成模型间不匹配和不同样品间模型不适应的问题。
6.为了实现上述目的,本发明采用的技术方案是:
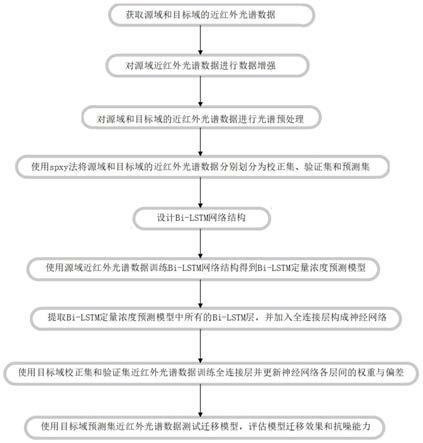
7.一种基于深度bi-lstm网络的近红外光谱模型迁移方法,包括以下步骤:
8.(1)获取源域和目标域的近红外光谱数据;
9.(2)对源域近红外光谱数据进行数据增强;
10.(3)对源域和目标域的近红外光谱数据进行光谱预处理;
11.(4)使用spxy法将源域和目标域的近红外光谱数据分别划分为校正集、验证集和预测集;
12.(5)设计bi-lstm网络结构;
13.(6)使用源域近红外光谱数据训练bi-lstm网络结构得到bi-lstm定量浓度预测模型;
14.(7)提取bi-lstm定量浓度预测模型中所有的bi-lstm层,并加入全连接层构成神经网络;
15.(8)使用目标域校正集和验证集近红外光谱数据训练全连接层并更新神经网络各层间的权重与偏差;
16.(9)使用目标域预测集近红外光谱数据测试迁移模型,评估模型迁移效果和抗噪能力。
17.本发明技术方案的进一步改进在于:所述步骤(2)中,在源域近红外光谱数据中加入不同信噪比的高斯白噪声进行数据增强。
18.本发明技术方案的进一步改进在于:所述步骤(3)中,使用vmd提取每条近红外光谱的第一个子模态imf1,其余子模态作为高频噪声舍弃,并对所有提取出的imf1进行snv变换,消除谱线偏移,然后对snv变换后的近红外光谱数据归一化,加速神经网络损失函数的收敛。
19.本发明技术方案的进一步改进在于:所述vmd算法公式不断迭代更新模态、对应的中心频率和拉格朗日乘数,直到相关系数满足条件,停止迭代,输出所有imfs。
20.本发明技术方案的进一步改进在于:所述步骤(5)中,设计的bi-lstm网络结构为:
21.sequenceinputlayer-bilstmlayer-batchnormalizationlayer-leakyrelulayer-flattenlayer-bilstmlayer-batchnormalizationlayer-leakyrelulayer-flattenlayer-bilstmlayer-batchnormalizationlayer-leakyrelulayer-flattenlayer-bilstmlayer-batchnormalizationlayer-leakyrelulayer-flattenlayer-bilstmlayer-leakyrelulayer-flattenlayer-fullyconnectedlayer-fullyconnectedlayer-fullyconnectedlayer-dropoutlayer-fullyconnectedlayer-regressionlayer。
22.本发明技术方案的进一步改进在于:所述步骤(7)中,提取bi-lstm定量浓度预测模型中所有的bi-lstm层,其结构为:
23.sequenceinputlayer-bilstmlayer-batchnormalizationlayer-leakyrelulayer-flattenlayer-bilstmlayer-batchnormalizationlayer-leakyrelulayer-flattenlayer-bilstmlayer-batchnormalizationlayer-leakyrelulayer-flattenlayer-bilstmlayer-batchnormalizationlayer-leakyrelulayer-flattenlayer-bilstmlayer-leakyrelulayer-flattenlayer。
24.本发明技术方案的进一步改进在于:所述步骤(7)中,加入的全连接层结构为:
25.fullyconnectedlayer-fullyconnectedlayer-fullyconnectedlayer-dropoutlayer-fullyconnectedlayer-regressionlayer。
26.本发明技术方案的进一步改进在于:所述步骤(9)中,评估模型迁移效果的指标为相关系数r2、均方根误差rmsep和相对分析误差rpd。
27.由于采用了上述技术方案,本发明取得的技术效果有:
28.本发明对近红外光谱数据进行数据增强和预处理后,构建深度bi-lstm神经网络,进而训练得到了源域定量模型。通过拆分和重组bi-lstm神经网络,用少量的目标域数据训练,实现从目标域定量模型向源域定量模型的迁移,节约了大量重建模型的时间且保持了较高精度的预测。
附图说明
29.图1是本发明的流程图;
30.图2是不同仪器下模型迁移前后药片目标域的分布;
31.图3是深度bi-lstm神经网络结构;
32.图4是聚谷氨酸生命液和能量液在模型迁移前后目标域(能量液)的分布。
具体实施方式
33.下面结合附图及具体实施例对本发明做进一步详细说明:
34.一种基于深度bi-lstm网络的近红外光谱模型迁移方法,如图1所示,包括以下步骤:
35.(1)获取源域和目标域的近红外光谱数据。
36.(2)对源域近红外光谱数据进行数据增强。
37.在源域近红外光谱数据中加入不同信噪比的高斯白噪声进行数据增强。
38.(3)对源域和目标域的近红外光谱数据进行光谱预处理。
39.使用vmd提取每条近红外光谱的第一个子模态imf1,其余子模态作为高频噪声舍弃,并对所有提取出的imf1进行snv变换,消除谱线偏移,然后对snv变换后的近红外光谱数据归一化,加速神经网络损失函数的收敛。
40.所述vmd算法公式不断迭代更新模态、对应的中心频率和拉格朗日乘数,直到相关系数满足条件,停止迭代,输出所有imfs。
41.(4)使用spxy法将源域和目标域的近红外光谱数据分别划分为校正集、验证集和预测集。
42.(5)设计bi-lstm网络结构;结构为:
43.sequenceinputlayer-bilstmlayer-batchnormalizationlayer-leakyrelulayer-flattenlayer-bilstmlayer-batchnormalizationlayer-leakyrelulayer-flattenlayer-bilstmlayer-batchnormalizationlayer-leakyrelulayer-flattenlayer-bilstmlayer-batchnormalizationlayer-leakyrelulayer-flattenlayer-bilstmlayer-leakyrelulayer-flattenlayer-fullyconnectedlayer-fullyconnectedlayer-fullyconnectedlayer-dropoutlayer-fullyconnectedlayer-regressionlayer。
44.(6)使用源域近红外光谱数据训练bi-lstm网络结构得到bi-lstm定量浓度预测模型。
45.(7)提取bi-lstm定量浓度预测模型中所有的bi-lstm层,并加入全连接层构成神经网络。
46.提取bi-lstm定量浓度预测模型中所有的bi-lstm层,其结构为:
47.sequenceinputlayer-bilstmlayer-batchnormalizationlayer-leakyrelulayer-flattenlayer-bilstmlayer-batchnormalizationlayer-leakyrelulayer-flattenlayer-bilstmlayer-batchnormalizationlayer-leakyrelulayer-flattenlayer-bilstmlayer-batchnormalizationlayer-leakyrelulayer-flattenlayer-bilstmlayer-leakyrelulayer-flattenlayer;
48.加入的全连接层结构为:
49.fullyconnectedlayer-fullyconnectedlayer-fullyconnectedlayer-dropoutlayer-fullyconnectedlayer-regressionlayer。
50.(8)使用目标域校正集和验证集近红外光谱数据训练全连接层并更新神经网络各层间的权重与偏差。
51.(9)使用目标域预测集近红外光谱数据测试迁移模型,评估模型迁移效果和抗噪能力。
52.评估模型迁移效果的指标为相关系数r2、均方根误差rmsep和相对分析误差rpd。
53.实施例1:
54.(1)使用国际漫反射会议网站发布的药片近红外光谱数据集,数据集下载网址:(http://www.idrc-charmbersburg.org/shootout2002.html)。
55.(2)将源域近红外光谱数据分别加入信噪比为70db和80db的高斯白噪声。
56.(3)对所有近红外光谱进行vmd(variational mode decomposition)分解,vmd算法公式不断迭代更新模态、对应的中心频率和拉格朗日乘数,直到相关系数满足条件,停止迭代,输出所有imfs,只提取每条光谱第一个子模态imf1;对所有imf1进行snv(standard normal variate)校正;对校正后的光谱数据进行归一化。
57.(4)使用spxy算法从源域校正集中筛选920条光谱、验证集中筛选80条光谱、预测集中筛选310条光谱;目标域校正集中筛选155条光谱、验证集中筛选40条光谱、预测集中筛选100条光谱。
58.(5)建立bi-lstm网络结构:由5层bi-lstm、5层flatten层、4层全连接层以及leakyrelu激活函数、标准化函数组成。
59.(6)对训练神经网络进行如下配置:分类器选用adam;最大迭代次数500次;初始学习率为0.001;梯度阈值设置为1。
60.(7)将训练好的源域api预测模型中最后4层全连接层删除,重新加入新的4层全连接层,
61.(8)使用目标域的校正集和验证集,重新训练全连接层,并微调更新各层间的权值和偏差。
62.(9)用目标域的预测集测试迁移后的api预测定量模型,将测试模型的评标指标记录于表1。
63.表1实施例1迁移前后的api定量预测模型结果
[0064][0065][0066]
实施例1迁移效果评估:
[0067]
由表1可知:模型迁移前,目标域预测集的均方根误差rmsep=21.9934,目标域预测集相对分析误差rpd=1.6196,目标域预测集的相关系数r2=0.7866;模型迁移后,目标域预测集的预测均方根误差rmsep=4.702、相对分析误差rpd=2.897,目标域预测集的相关系数r2=0.9385。通过对比,可以得到以下结论:在源域的api定量预测模型下,对不同仪器下采集的药片近红外光谱数据泛化能力低,表现在目标域预测集在源域的模型下误差较大;通过基于深度bi-lstm神经网络的近红外光谱模型迁移方法,完成了目标域到源域的模
型迁移,目标域在迁移模型下的性能指标优于源域下的api定量模型指标。
[0068]
另一方面,对比图2可知,目标域预测集在迁移模型下预测值与真实值所构成点的分布集中在y=x上,说明模型在迁移后误差得到减小,具备抗噪声干扰能力。
[0069]
实施例2:
[0070]
(1)将聚谷氨酸生命液和能量液按逐次稀释浓度50%的方法得到浓度为3.5g/ml、1.75g/ml、0.875g/ml、0.4375g/ml、0.21875g/ml的样品液。
[0071]
(2)利用布鲁克傅里叶变换近红外光谱仪采集所有样品的近红外光谱,将生命液的近红外光谱数据作为源域数据,能量液的近红外光谱数据作为目标域数据。
[0072]
(3)为避免训练的神经网络模型过拟合,在采集后的生命液数据中加入信噪比为70db和80db的高斯白噪声。
[0073]
(4)对所有光谱进行vmd分解,只取imf1;对所有imf1进行snv校正;对校正后的光谱数据进行归一化。
[0074]
(5)使用spxy算法将生命液光谱数据和能量液光谱数据划分为校正集、验证集和预测集。
[0075]
(6)建立深度bi-lstm神经网络:由5层bi-lstm、5层flatten层、4层全连接层以及leakyrelu激活函数、标准化函数组成,神经网络各层神经元如图3所示。
[0076]
(7)对训练神经网络进行如下配置:分类器选用adam;最大迭代次数500次;初始学习率为0.001;梯度阈值设置为1。
[0077]
(8)将训练好的生命液浓度预测模型中最后4层全连接层删除,重新加入新的4层全连接层。
[0078]
(9)使用能量液的校正集和验证集,重新训练全连接层,并微调更新各层间的权值和偏差。
[0079]
(10)用能量液的预测集测试迁移后的浓度预测定量模型,将测试模型的评标指标记录于表2。
[0080]
表2实施例2迁移前后的能量液浓度定量预测模型结果
[0081][0082]
实施例2迁移效果评估:
[0083]
由表2可知:模型迁移前能量液预测集的均方根误差rmsep=2.5889,能量液预测集相对分析误差rpd=1.5568,能量液预测集相关系数r2=0.7664;模型迁移后能量液预测集的预测均方根误差rmsep=0.45581、相对分析误差rpd=2.8306,能量液预测集相关系数r2=0.9355。通过对比,可以得到以下结论:相同成分不同产品的聚谷氨酸能量液近红外光谱数据不能很好的匹配原有模型,表现为能量液测试集数据在生命液浓度定量预测模型误差较大;通过基于深度bi-lstm神经网络的近红外光谱模型迁移方法,完成了源域到目标域的模型迁移,且克服了过拟合,使源域分布接近于目标域分布;通过重组神经网络和更新与
目标域相关的权值,使迁移模型弱化了源域中噪声的影响。
[0084]
对比图4可知,目标域预测集在迁移模型下预测值与真实值构成的点均匀分布在y=x两侧,说明基于深度bi-lstm神经网络的近红外光谱模型迁移方法在不同样品模型间的转移成功。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1