用于疾病的早期检测的蛋白质冠传感器阵列的系统和方法与流程
用于疾病的早期检测的蛋白质冠传感器阵列的系统和方法
1.本技术是中国专利申请cn201780011881.9的分案申请。
2.相关申请的交叉引用
3.本技术要求2016年12月16日提交的美国临时申请第62/435,409号的优先权,其内容通过引用全文纳入本文。
4.关于联邦资助研究的声明
5.无
6.通过引用纳入
7.本说明书中提到的所有发表物、专利和专利申请通过引用纳入本文,就好像将各篇单独的发表物、专利或专利申请专门和单独地通过引用纳入本文那样。
背景技术:
8.本发明的领域涉及用于检测和诊断不同疾病状态的传感器阵列,具体地,本发明涉及对疾病或病症进行诊断或预后的能力。
9.诊断出疾病的时间越早,疾病治愈或成功控制的可能性就越大,从而为患者提供更好的预后。当您及早治疗疾病时,您可能能够预防或延迟疾病的问题,并可能改善患者的治疗效果,包括延长患者的生命和/或生活质量。
10.癌症的早期诊断至关重要,因为许多类型的癌症可以在早期阶段成功治疗。例如,乳腺癌,卵巢癌和肺癌早期诊断和治疗后的五年生存率分别为90%,90%和70%,而在疾病最晚期诊断的患者分别为15%,5%和10%。一旦癌细胞离开其原始组织,使用可用的已建立的治疗剂的成功治疗变得非常不可能。尽管认识到癌症的警告信号并采取迅速行动可能导致早期诊断,但大多数癌症(例如,肺)仅在癌细胞已经侵入周围组织并在全身转移后才显示出症状。例如,超过60%的患有乳腺癌,肺癌,结肠癌和卵巢癌的患者在检测到癌症时具有隐藏甚至转移了的集落。因此,迫切需要开发用于早期检测癌症的有效方法。这种方法应该具有识别不同阶段的癌症的灵敏性以及当被测试者没有癌症时给出阴性结果的特异度。已经进行了大量努力来开发用于早期检测癌症的方法;虽然已经引入了大量的风险因素和生物标志物,但是早期检测各种癌症的广泛相关平台仍然难以实现。
11.由于各种类型的癌症可以改变血浆的组成-即使在其早期阶段-早期检测的一种有希望的方法是针对生物标志物的分子血液分析。虽然这种策略已经适用于一些癌症(如psa用于前列腺癌),但尚无特定的生物标志物可用于早期检测大多数癌症。对于这样的癌症(例如,肺癌),没有一种定义的候选循环生物标志物已经临床验证,并且很少有人已经达到晚期临床开发。因此,迫切需要新方法来提高我们在非常早期阶段检测癌症的能力。
技术实现要素:
12.本发明提供了一种灵敏的通用传感器阵列,用于检测多种疾病和病症以及确定对象的疾病状态。本发明的独特性在于来自对象样品的生物分子指纹识别和确定该对象的疾病状态或健康连续性的能力的组合。
13.在一些方面,本发明提供了一种传感器阵列,其包括多个传感器元件,其中所述多个传感器元件在至少一种物理化学特性方面彼此不同,并且所述多个传感器元件包括至少两个传感器元件。在一些方面,每个传感器元件能够结合样品中的多个生物分子以产生生物分子冠(corona)特征,其中每个传感器元件具有彼此不同的生物分子冠特征。在一些方面,传感器元件是纳米级传感器元件。
14.在一些方面,当与样品接触时,多个传感器元件产生多个生物分子冠特征(signature),其中多个生物分子冠特征的组合产生样品的生物分子指纹。
15.在一些方面,传感器元件连接到基材。
16.在一些方面,传感器元件是基材,板或芯片上的离散元件(区域),其具有拓扑和功能差异,其中每个不同的元件(区域)产生不同的生物分子冠特征。基材,芯片或阵列本身一起形成传感器阵列并为样品提供生物分子指纹。
17.在一些方面,本发明提供了检测对象的疾病状态的方法,包括:从对象获得样品;使样品与传感器阵列接触,其中传感器阵列包括多个传感器元件,其中多个传感器元件在至少一个物理化学特性方面彼此不同,并且多个传感器元件包括至少两个传感器元件,并且确定与样品相关的生物分子指纹,其中生物分子指纹可以区分对象的疾病状态。在一些方面,该方法还包括将样品的生物分子指纹与一组与多种疾病状态相关的生物分子指纹进行比较,以确定哪种疾病状态与样品相关。
18.另一方面,本发明提供了一种确定与至少疾病状态或至少一种疾病或病症相关的生物分子指纹的方法,该方法包括以下步骤:(a)从被诊断有疾病状态或至少一种疾病或病症的至少两个对象中获得样品;(b)使每个样品与本文所述的传感器阵列接触,和(c)确定与疾病状态或至少一种疾病或病症相关的传感器阵列的生物分子指纹。在一些方面,步骤(c)还包括检测每个传感器元件的生物分子冠的组成,其中不同传感器元件之间的每个生物分子冠的组成的组合产生与样品相关的生物分子指纹。在其他方面,步骤(c)包括从每个传感器元件解离生物分子冠并测定每个生物分子冠的多个生物分子,其中测定的生物分子的组合产生生物分子指纹。
19.在另一个方面,本发明提供了对于对象的疾病或病症进行诊断或预后的方法,包括从对象获得样品;使样品与本文所述的传感器阵列接触以产生生物分子指纹,将生物分子指纹与一组与多种疾病或病症相关的生物分子指纹进行比较;并对该疾病或病症进行诊断或预后。
20.在另一个方面,本发明提供鉴定与疾病或病症相关的生物标志物模式(pattern)的方法,该方法包括:(a)从诊断患有该疾病或病症的至少两个对象和至少两个对照对象获得样品;(b)使每个样品与传感器阵列接触以为每个对象产生多个生物分子冠,以及(c)将患有疾病或病症的对象的多个生物分子冠的组成与对照对象多个生物分子冠的组成进行比较,以确定与疾病或病症相关的生物标志物的模式。
21.在一些方面,疾病或病症是癌症,内分泌病症,心血管疾病,炎性疾病或神经疾病。
22.在一个方面,疾病或病症是癌症。
23.在另一方面,疾病或病症是心血管疾病。在一个方面,心血管疾病是冠状动脉疾病(cad)。
24.在另一方面,疾病或病症是神经病症。在一个方面,神经病症是阿尔茨海默病。
25.在一些方面,本发明提供了用于对疾病或病症进行诊断或预后的试剂盒,该试剂盒包括:传感器阵列,其包括多个纳米级传感器元件,其中所述多个传感器元件在至少一种物理化学特性方面彼此不同并且多个传感器元件包括至少两个传感器元件。
26.在其他方面,本发明提供用于确定和/或检测与疾病或病症相关的至少一种生物标志物的试剂盒,其包括至少一个传感器阵列,所述传感器阵列包括多个传感器元件,其中所述多个传感器元件在至少一个物理化学特性上彼此不同并且多个传感器元件包括至少两个传感器元件。
27.在又一方面,本发明提供了一种使用具有不同物理化学性质的表面的多个颗粒来区分对象的复杂生物样品(complex biological sample)的状态的方法,其中该方法包括:将复杂生物样品暴露于多个颗粒以允许复杂生物样品的蛋白质与多个颗粒的结合,其中多个颗粒之间蛋白质的结合模式根据颗粒表面的物理化学性质而不同;定义代表结合多个颗粒的蛋白质的生物分子指纹;并将生物分子指纹与对象的生物状态相关联。
28.另一方面,本发明提供了一种传感器阵列,其包括具有不同物理化学性质的表面的多个颗粒,其中复杂生物样品的蛋白质在复杂生物样品暴露于多个颗粒时与多个颗粒结合,其中多个颗粒之间蛋白质结合的模式取决于颗粒表面的物理化学性质。
29.在又一方面,本发明提供了包含多个脂质体的传感器阵列,其中所述多个脂质体在由每个脂质体的基于脂质的表面限定的至少一种蛋白质结合性质方面不同;其中每个脂质体的基于脂质的表面在脂质-蛋白质界面处接触样品的蛋白质亚组,从而结合蛋白质亚组以产生蛋白质结合模式;其中第一脂质体的蛋白质结合模式不同于第二脂质体的蛋白质结合模式,第二脂质体在所述至少一种蛋白质结合性质中与第一脂质体不同。
30.另一方面,本发明提供了使用多个脂质体鉴定对象的生物状态的方法,所述脂质体在由每种脂质体的基于脂质的表面限定的至少一种蛋白质结合性质上不同,其中所述方法包括:使样品暴露至多个脂质体,以允许样品的蛋白质与多个脂质体结合,其中蛋白质的结合模式在具有不同蛋白质结合特性的脂质体之间不同;将蛋白质与脂质体分离;定义从脂质体分离的蛋白质的生物分子指纹;并且将生物分子指纹与对象的复杂生物样品的状态相关联。
31.通过以下描述可以清楚地了解本发明的上述和其他方面和优势。在以下说明书中,参照构成说明书的一部分的附图,其中以说明性方式显示了本发明的优选实施方式。这类实施方式不必然代表本发明的全部范围,而是因此对权利要求进行说明并在本文中解释本发明的范围。
附图说明
32.本专利或申请文件包含至少一幅有色附图。本专利或专利申请公开与彩色附图的副本将根据要求,在支付所需的费用之后由政府机关提供。
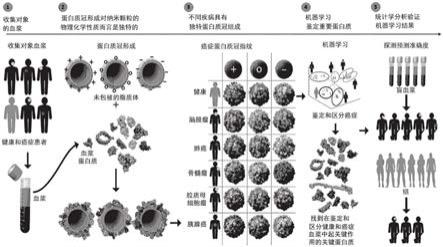
33.图1.一个实施方式的示意图,显示了用于癌症检测的蛋白质冠模式方式的研究设计的示例。将三种类型的脂质体与健康人和癌症患者的血浆孵育,并且通过液相色谱-串联质谱(lc-ms/ms)对每个对象的血浆(健康和不同癌症)中的每个脂质体上形成蛋白质冠模式进行表征。在三种脂质体上形成蛋白质冠导致重叠但不同的选定血浆蛋白质库的富集,并且富集的蛋白质是随后多变量分析的基础。通过分类方法,鉴定了多种冠模式中的重要
蛋白质,并用于使用盲血浆和组样品来预测癌症,以测试多纳米颗粒蛋白质冠纳米系统的准确度。使用29个人类对象(25个癌症患者,即5个癌症类型各5个患者;和4个健康对象)代表261个不同的lc-ms/ms运行(3种脂质体,29个对象,3个重复)来训练分类模型。将16个人类对象(5种癌症类型各3个患者;和1个健康对象)的盲血浆和144次不同的lc-ms/ms运行(3种脂质体,16个对象,3次重复)用于癌症预测,即测试分类模型。15个人类对象(3种癌症类型各5个患者)的组血浆代表135次不同的lc-ms/ms运行(3种脂质体,15个对象,3次重复)也用于非常早期的癌症预测。
34.图2a.脂质体的tem图像及其尺寸分布概况。
35.图2b.不同脂质体在与不同疾病患者人血浆相互作用前后的理化性质。在与来自健康和癌症患者的血浆孵育后获得的与人血浆和不含过量血浆的冠复合物相互作用之前各种脂质体的dls和ζ-电位数据(pdi:来自累积量拟合的多分散指数)。
36.图2c.根据脂质体在健康个体和具有不同类型癌症的患者的人血浆中的生理功能,对由脂质体鉴定的冠蛋白质的分类(所呈现的数据反映了每组5个生物血浆和每个血浆3个技术重复的计算)。
37.图3a.根据传感器阵列元件的生理功能,包括在健康对象和具有不同类型癌症的患者的人血浆中的急性期,对传感器阵列元件鉴定的冠进行分类。
38.图3b.根据传感器阵列元件的生理功能,包括在健康对象和具有不同类型癌症的患者的人血浆中的凝结,对传感器阵列元件鉴定的冠进行分类。
39.图3c.根据传感器阵列元件的生理功能,包括在健康对象和具有不同类型癌症的患者的人血浆中的免疫球蛋白,对传感器阵列元件鉴定的冠进行分类。
40.图3d.根据传感器阵列元件的生理功能,包括在健康对象和具有不同类型癌症的患者的人血浆中的脂蛋白,对传感器阵列元件鉴定的冠状物进行分类。
41.图3e.根据传感器阵列元件的生理功能,包括在健康对象和具有不同类型癌症的患者的人血浆中的组织渗漏,对传感器阵列元件鉴定的冠进行分类。
42.图3f.根据传感器阵列元件的生理功能,包括在健康对象和具有不同类型癌症的患者的人血浆中的补体蛋白,对传感器阵列元件鉴定的冠进行分类。
43.图3g.根据传感器阵列元件的生理功能,包括在健康对象和具有不同类型癌症的患者的人血浆中的其他血浆蛋白,对传感器阵列元件鉴定的冠进行分类。
44.图4a.预测因子探索以及每个预测因子对每个类别的分离所做的贡献(通过pls判别分析)。通过将等级变量逐一添加到pls-da模型并计算内部交叉验证的分类误差(10倍)来执行由加权vip的预测因子探索。减少分类错误导致发现最小69个预测因子的组,其中每个类与其他类的分离具有最高可能的重要性。基于pls判别分析,每个单独标志物对每个类别的分离的贡献。vip图谱针对它们对pls判别分析中每个类别的分离的贡献排列69个选定变量的标志物。vip评分>1表示导致良好的类隶属关系(class membership)预测的重要蛋白质,而vip评分《1的变量表明每个类别的不重要蛋白质。
45.图4b描绘了胶质母细胞瘤的69个变量的结果。
46.图4c.描绘脑膜瘤的69个变量的vip值。
47.图4d.描绘肺癌的69个变量的vip值。
48.图4e.描绘骨髓瘤的69个变量的vip值。
49.图4f.描绘胰腺癌的69个变量的vip值。
50.图5a.pls-da图显示了不同癌样品彼此之间以及与对照物的分离。使用pls-toolbox获得的pls评分图,将对象投影到由模型的第一,第二和第三潜变量创建的子空间中。
51.图5b.pls-da图显示了不同癌样品彼此之间以及与对照物的分离。在显示模型的第4和第5个潜变量的情况下展示的对象。可以看出,脑膜瘤和胶质母细胞瘤的情况没有在三个维度上适当分开,但它们可以在pls模型的第四维和第五维中分开。
52.图5c.通过cpann用所有变量和选定变量获得的分配映射。(c)通过使用整个数据集(1823个变量)训练cpann网络(8
×
8个神经元)获得的分配映射。映射质量不佳,并且在映射方面存在不同类型癌症的冲突。
53.图5d.通过使用69个变量训练cpann网络(8
×
8个神经元)获得的分配映射。高维输入向量(样品)被映射在神经元的二维网络上,保留了相似性和拓扑。颜色表示神经元与特定类型的输入向量(类类型)的相似性。该图还显示了预测因子选择步骤的重要性以及删除非信息性和无关预测因子对模型质量的影响。
54.图5e.描绘被鉴定为能够区分六组癌症的51种蛋白质的树状图。
55.图5f.被鉴定为能够区分六组的51种蛋白质在用无监督式聚类算法(具有最远邻居连锁的凝聚性hca)产生的“热图”中呈现。视觉检查树状图(图5e)和热图(图5f)显示癌症特异性蛋白质冠特征和六组样品(五组癌症样品加正常样品)的清晰聚类,以及预期的每组五个患者的相似性。热图还表明不同癌症的变量(标志物)模式的显著差异(每列代表患者,并且每行代表蛋白质)。较高和较低的蛋白质水平分别以红色和绿色表示。
56.图6a.通过考虑69个重要标志物获得的pls评分图,将组对象投影到由模型的第一和第二潜变量创建的子空间中。
57.图6b.pls-da模型是使用8个变量生成的,这些变量将组对象投射到由模型的第一和第二潜变量创建的子空间中,具有出色的统计数据。
58.图6c.通过使用69个重要标志物训练cpann网络(8
×
8神经元)获得的分配映射。
59.图6d.通过仅使用8个标志物训练cpann网络(8
×
8神经元)获得的分配映射,没有任何错误分类。每个神经元上都标有样品编号。
60.图7a.研究大纲的示意图。信息变量选择与分类模型构建。
61.图7b.列出了69个选定变量的蛋白质名称和id。一些蛋白质存在于超过一种脂质体的蛋白质冠中(dopg,dotap和chol用多种字体表示:分别是斜体带下划线字体,粗体字体和普通字体)。
62.图7c.所提出的模型覆盖疾病特异性生物标志物作为重要变量。
63.图8a.基于针对对照的前69的等级变量,从pls-da导出的接收者操作特征(roc)图。灵敏度(真阳性率,y轴)与1-特异度(假阳性率,x轴)的roc图基于建立在对六类(对照,胶质母细胞瘤,脑膜瘤,骨髓瘤,胰腺,肺)的贡献最高的69个标志物上的pls-da。
64.图8b.基于针对胶质母细胞瘤的前69的等级变量,从pls-da导出的接收者操作特征(roc)图。灵敏度(真阳性率,y轴)与1-特异度(假阳性率,x轴)的roc图基于建立在对六类(对照,胶质母细胞瘤,脑膜瘤,骨髓瘤,胰腺,肺)的贡献最高的69个标志物上的pls-da。
65.图8c.基于针对脑膜瘤的前69的等级变量,从pls-da导出的接收者操作特征(roc)
图。灵敏度(真阳性率,y轴)与1-特异度(假阳性率,x轴)的roc图基于建立在对六类(对照,胶质母细胞瘤,脑膜瘤,骨髓瘤,胰腺,肺)的贡献最高的69个标志物上的pls-da。
66.图8d.基于针对骨髓瘤的前69的等级变量,从pls-da导出的接收者操作特征(roc)图。灵敏度(真阳性率,y轴)与1-特异度(假阳性率,x轴)的roc图基于建立在对六类(对照,胶质母细胞瘤,脑膜瘤,骨髓瘤,胰腺,肺)的贡献最高的69个标志物上的pls-da。
67.图8e.基于针对胰腺的前69的等级变量,从pls-da导出的接收者操作特征(roc)图。灵敏度(真阳性率,y轴)与1-特异度(假阳性率,x轴)的roc图基于建立在对六类(对照,胶质母细胞瘤,脑膜瘤,骨髓瘤,胰腺,肺)的贡献最高的69个标志物上的pls-da。
68.图8f.基于针对肺的前69的等级变量,从pls-da导出的接收者操作特征(roc)图。灵敏度(真阳性率,y轴)与1-特异度(假阳性率,x轴)的roc图基于建立在对六类(对照,胶质母细胞瘤,脑膜瘤,骨髓瘤,胰腺,肺)的贡献最高的69个标志物上的pls-da。
69.图9a.将三向数据矩阵展开为双向矩阵的示意图。
70.图9b.由使用90个样品(重复)全部1823个变量训练的cpann(14
×
14)获得的分配映射。每个神经元上都标有样品编号。基于类标记(6
×
1二元向量)与相应神经元的输出层中的权重向量之间的相似性来确定神经元颜色(指定标记)。尽管使用了所有生物标志物,但是同一癌症类别的样品之间存在一些明显的相似性。重复的样品也映射在相邻或相同的神经元上。
71.图9c.使用10倍交叉验证在不同的图尺寸下计算cpann映射的分类误差。
72.图9d.cpann网络具有69个权重层,其等于用于训练模型的变量的数量。第i个权重层反映第i个变量(生物标志物)对分配映射的模式的影响。
73.图9e.可以计算分配映射和69个权重层(权重映射)的相关性,并且可以帮助识别与每个癌症类别相关的生物标志物。它也可以通过视觉观察来决定;可以通过两个映射的相关系数的绝对值来监视相似性。
74.图9f.可以计算分配映射和69个权重层(权重映射)的相关性,并且可以帮助识别与每个癌症类别相关的生物标志物。它也可以通过视觉观察来决定;可以通过两个映射的相关系数的绝对值来监视相似性。
75.图10a.分类的蛋白质重要性与蛋白质冠纳米系统上吸附的蛋白质的百分比。图(a)-(c)说明了观察到的蛋白质-脂质体相互作用(“变量”)在预测特定癌症中的重要性。蛋白质按其生理功能分组。图(d)-(f)说明了吸附在每个脂质体上的蛋白质的百分比。出现与癌症预测相关的蛋白质-脂质体组在癌症中是高度不同的(图(a)-(c))。此外,这种区别明显比这些癌症间脂质体上吸附的蛋白质百分比的变化更明显(图(d)-(f))。
76.图10b.显示在每种脂质体的冠组合物中鉴定的独特蛋白质的数量及其组合(右表以数字形式呈现相同的数据)的维恩图。
77.图10c.分类的变量重要性。每行表示特定蛋白质的重要性。每行上的三个点对应于观察到的与三种脂质体中的每一种相互作用的重要性。横跨点之间的水平线表示在数据的训练集的1000个随机抽取中训练的分类器的重要性的第25和第75百分位数。这些置信区间表示训练模型在随机抽取数据上在决定性依赖的蛋白质-脂质体相互作用方面的“稳定性”。
78.图11.蛋白质-脂质体相互作用的加权平均值对癌症进行分类。每个患者组的绝对
z评分的分布,在100种最丰富的蛋白质(灰色)和先前鉴定的生物标志物(白与黑点)上绘制直方图。长黑柱对应于蛋白质-脂质体相互作用的线性组合的z评分。特定蛋白质-脂质体相互作用的大z评分表明该组在该特定相互作用中与其余患者“分离”。该图因此表明,虽然没有单独的蛋白质-脂质体相互作用足以对任何癌症进行分类,但是它们的加权组合诱导2至2.5个标准偏差的分离。
79.图12.多脂质体浓缩低丰度和稀有蛋白质。蛋白质冠贡献与已知血浆浓度的关系,以log-log标绘。每个点代表单个蛋白质和脂质体,及其对每种疾病和健康个体的冠贡献,并且相对于白蛋白标准化冠贡献和血浆浓度。血浆浓度变化超过10个数量级,而脂质体阵列检测到超过4-5个数量级的这些相同蛋白质。血浆浓度未知/未报告的蛋白质的冠贡献绘制在右侧的红色区域中。
80.图13.可用于传感器阵列的一些实施方式的纳米级传感器元件的类型的示例。具有各种物理化学性质(例如,不同的,表面性质,尺寸和形状)的不同类型的纳米颗粒(例如,有机,无机和聚合物纳米颗粒)可用作传感器元件。传感器阵列可以由最少两个元件到无限数量元件创建。
81.图14.在体外,离体和体内条件下收集冠包被的颗粒的一种方法的示例。将颗粒与生物流体(例如,患有不同类型疾病的患者的血浆)一起孵育,并收集并储存冠包被的颗粒用于分析。
82.图15a.将纳米物体材料(具有不同物理化学性质)与基材(具有不同物理化学性质)耦合以在与蛋白质源(例如,各种疾病的人血浆)相互作用之前(a)制备蛋白质冠传感器阵列芯片的示例。特定的蛋白质冠将在纳米物体表面形成,具有不同的物理化学性质。基材也可以被几种类型的蛋白质包被,这些蛋白质对芯片的检测功效具有可忽略的影响。
83.图15b.将纳米物体材料(具有不同物理化学性质)与基材(具有不同物理化学性质)耦合以在与蛋白质源(例如,各种疾病的人血浆)相互作用之后制备蛋白质冠传感器阵列芯片的示例。
84.图16a.具有纳米曲率的蛋白质冠传感器阵列芯片(通过像光刻和模具铸造的各种可用方法产生)的示例,其在与蛋白质源(例如,各种疾病的人血浆)相互作用之前,具有不同物理化学性质。特定的蛋白质冠将在纳米物体表面形成,具有不同的物理化学性质。基材也可以被几种类型的蛋白质包被,这些蛋白质对芯片的检测功效具有可忽略的影响。
85.图16b.具有纳米曲率的蛋白质冠传感器阵列芯片(通过像光刻和模具铸造的各种可用方法产生)的示例,其在与蛋白质源(例如,各种疾病的人血浆)相互作用之后,具有不同物理化学性质。特定的蛋白质冠将在纳米物体表面形成,具有不同的物理化学性质。基材也可以被几种类型的蛋白质包被,这些蛋白质对芯片的检测功效具有可忽略的影响。
86.图17a.将纳米物体材料(具有不同物理化学性质)与基材(具有不同物理化学性质)耦合以在与蛋白质源(例如,各种疾病的人血浆)相互作用之前和(b)之后制备蛋白质冠传感器阵列微/纳米流体芯片的示例。特定的蛋白质冠将在纳米物体表面形成,具有不同的物理化学性质。基材也可以被几种类型的蛋白质包被,这些蛋白质对芯片的检测功效具有可忽略的影响。
87.图17b.将纳米物体材料与基材耦合以在与蛋白质源(例如,各种疾病的人血浆)相互作用之后制备蛋白质冠传感器阵列微/纳米流体芯片的示例。特定的蛋白质冠将在纳米
物体表面形成,具有不同的物理化学性质。
88.图18a.在与蛋白质源(例如,各种疾病的人血浆)相互作用之前,具有不同物理化学性质的具有纳米曲率的蛋白质冠传感器阵列微/纳米流体芯片(通过像光刻和模具铸造的各种可用方法产生)的示例。
89.图18b.在与蛋白质源(例如,各种疾病的人血浆)相互作用之后,具有不同物理化学性质的具有纳米曲率的蛋白质冠传感器阵列微/纳米流体芯片(通过像光刻和模具铸造的各种可用方法产生)的示例。
90.图19a.将随机顺序的纳米物体材料(具有不同物理化学性质)与基础(具有不同物理化学性质)耦合以在与蛋白质源(例如,各种疾病的人血浆)相互作用之前(a)制备蛋白质冠传感器阵列芯片的示例。
91.图19b.将随机顺序的纳米物体材料(具有不同物理化学性质)与基础(具有不同物理化学性质)耦合以在与蛋白质源(例如,各种疾病的人血浆)相互作用之后(b)制备蛋白质冠传感器阵列芯片的示例。
92.图20a.在与蛋白质源(例如,各种疾病的人血浆)相互作用之前(a),具有不同物理化学性质的具有随机顺序的纳米曲率的蛋白质冠传感器阵列芯片(通过像光刻和模具铸造的各种可用方法产生)的示例。
93.图20b.在与蛋白质源(例如,各种疾病的人血浆)相互作用之后(b)具有不同物理化学性质的具有随机顺序的纳米曲率的蛋白质冠传感器阵列芯片的示例。
94.图21a.将随机顺序的纳米物体材料(具有不同物理化学性质)与基础(具有不同物理化学性质)耦合以在与蛋白质源(例如,各种疾病的人血浆)相互作用之前(a)制备蛋白质冠传感器阵列微/纳米流体芯片的示例。
95.图21b.将随机顺序的纳米物体材料与基材耦合以在与蛋白质源(例如,各种疾病的人血浆)相互作用之后(b)制备蛋白质冠传感器阵列微/纳米流体芯片的示例。
96.图22a.在与蛋白质源(例如,各种疾病的人血浆)相互作用之前(a),具有不同物理化学性质的具有随机顺序的纳米曲率的蛋白质冠传感器阵列微/纳米流体芯片(通过像光刻和模具铸造的各种可用方法产生)的示例。
97.图22b.在与蛋白质源(例如,各种疾病的人血浆)相互作用之后具有不同物理化学性质的具有随机顺序的纳米曲率的蛋白质冠传感器阵列微/纳米流体芯片的示例。
98.图23.通过二氧化硅基材表面上的氨基与纳米颗粒表面上的羧酸基团之间的酰胺化反应将纳米颗粒耦合到二氧化硅基材表面(作为代表性基材)的示例。
99.图24.通过二氧化硅基材表面上的环氧基团与纳米颗粒表面上的氨基之间的开环反应将纳米颗粒耦合到二氧化硅基材表面(作为代表性基材)的示例。
100.图25.通过二氧化硅基材表面上的马来酰亚胺基团与纳米颗粒表面上的硫醇或氨基之间的迈克尔加成反应将纳米颗粒耦合到二氧化硅基材表面(作为代表性基材)的示例。
101.图26.通过二氧化硅基材表面上的异氰酸酯基团与纳米颗粒表面上的羟基或氨基之间的尿烷反应(urethanereaction)将纳米颗粒耦合到二氧化硅基材表面(作为代表性基材)的示例。
102.图27.通过二氧化硅基材表面上的硫醇基团与纳米颗粒表面上的酮之间的氧化反应将纳米颗粒耦合到二氧化硅基材表面(作为代表性基材)的示例。
103.图28.通过二氧化硅基材表面上的叠氮基团与纳米颗粒表面上的炔基之间的“点击”化学将纳米颗粒耦合到二氧化硅基材表面(作为代表性基材)的示例。
104.图29.通过二氧化硅基材表面上的2-吡啶基二硫醇基团与纳米颗粒表面上的硫醇基团之间的硫醇交换反应将纳米颗粒耦合到二氧化硅基材表面(作为代表性基材)的示例。
105.图30.通过二氧化硅基材表面上的硼酸基团与纳米颗粒表面上的二醇基团之间的配位反应将纳米颗粒耦合到二氧化硅基材表面(作为代表性基材)的示例。
106.图31.通过二氧化硅基材表面上的c=c键与纳米颗粒表面上的c=c键之间的uv光照射的加成反应将纳米颗粒耦合到二氧化硅基材表面(作为代表性基材)的示例。
107.图32.通过au-硫醇键将纳米颗粒耦合到金基材表面(作为代表性基材)的示例。
108.图33.通过金基材表面上的羧酸基团与纳米颗粒表面上的氨基之间的酰胺化反应将纳米颗粒耦合到金基材表面(作为代表性基材)的示例。
109.图34.通过金基材表面上的叠氮基团与纳米颗粒表面上的炔基之间的“点击”化学将纳米颗粒耦合到金基材表面(作为代表性基材)的示例。
110.图35.通过金基材表面上的nhs基团与纳米颗粒表面上的氨基之间的尿烷反应将纳米颗粒耦合到金基材表面(作为代表性基材)的示例。
111.图36.通过金基材表面上的环氧基团与纳米颗粒表面上的氨基之间的开环反应将纳米颗粒耦合到二氧化硅基材表面(作为代表性基材)的示例。
112.图37.通过二氧化硅基材表面上的硼酸基团与纳米颗粒表面上的二醇基团之间的配位反应将纳米颗粒耦合到金基材表面(作为代表性基材)的示例。
113.图38.通过金基材表面上的c=c键与纳米颗粒表面上的c=c键之间的uv光照射的加成反应将纳米颗粒耦合到金基材表面(作为代表性基材)的示例。
114.图39.通过金基材表面上的生物素与纳米颗粒表面上的亲和素之间的“配体-受体”相互作用将纳米颗粒耦合到金基材表面(作为代表性基材)的示例。
115.图40.通过金基材表面上的α-环糊精(a-cd)与纳米颗粒表面上的金刚烷(ad)之间的“主-客”相互作用将纳米颗粒耦合到金基材表面(作为代表性基材)的示例。
116.图41.蛋白质从纳米颗粒表面的解离及其冠组成分析。用监督式和非监督式方法分析蛋白质冠传感器阵列数据以鉴定和区分疾病。
117.图42.具有用于荧光或发光读出的随机顺序的纳米级传感器元件的传感器阵列的示例。
118.图43.具有用于荧光或发光读出的排列纳米级传感器元件的传感器阵列的示例。
119.图44a.具有不同的官能化(无,胺改性(nh2)和羧基改性(cooh))的裸聚苯乙烯和二氧化硅纳米颗粒的表征,显示三种不同的聚苯乙烯纳米颗粒(非官能化,p-nh2和p-cooh),它们的大小,裸颗粒的dls和ζ电位。
120.图44b.具有不同的官能化(无,胺改性(nh2)和羧基改性(cooh))的裸聚苯乙烯和二氧化硅纳米颗粒的表征,显示三种不同的二氧化硅纳米颗粒(非官能化,s-nh2和s-cooh),它们的大小,dls和ζ电位。
121.图44c.具有不同官能化(无,胺改性(nh2)和羧基改性(cooh))的裸聚苯乙烯和二氧化硅纳米颗粒的表征,显示裸聚苯乙烯纳米颗粒的tem。
122.图44d.具有不同官能化(无,胺改性(nh2)和羧基改性(cooh))的裸聚苯乙烯和二
氧化硅纳米颗粒的表征,显示裸二氧化硅纳米颗粒的tem。
123.图45a.具有不同官能化(无,胺改性(nh2)和羧基改性(cooh))的蛋白质冠包被的聚苯乙烯和二氧化硅纳米颗粒的表征,显示蛋白质冠包被的聚苯乙烯纳米颗粒的尺寸,dls和ζ电位。
124.图45b.具有不同官能化(无,胺改性(nh2)和羧基改性(cooh))的蛋白质冠包被的聚苯乙烯和二氧化硅纳米颗粒的表征,显示加载蛋白质冠的二氧化硅纳米颗粒的尺寸,dls和ζ电位。
125.图45c.具有不同官能化(无,胺改性(nh2)和羧基改性(cooh))的蛋白质冠包被的聚苯乙烯和二氧化硅纳米颗粒的表征,显示加载蛋白质冠的聚苯乙烯纳米颗粒的tem。
126.图45d.具有不同官能化(无,胺改性(nh2)和羧基改性(cooh))的蛋白质冠包被的聚苯乙烯和二氧化硅纳米颗粒的表征,显示加载蛋白质冠的二氧化硅纳米颗粒的tem。
127.图46.用聚苯乙烯和二氧化硅纳米颗粒筛选的癌症血浆样品类型的图。
128.图47.通过sds page分析,与具有不同癌症的患者的血浆孵育后,具有普通,胺修饰和羧基修饰表面的聚苯乙烯和二氧化硅纳米颗粒(100nm)的蛋白质冠概况。
129.图48.通过sds page分析,与健康个体的血浆孵育后,具有普通,胺修饰和羧基修饰表面的聚苯乙烯和二氧化硅纳米颗粒(100nm)的蛋白质冠概况。
130.图49.描绘使用本发明的传感器阵列从健康个体分离患有癌症的患者的图。
131.图50a.用于cad筛选的聚苯乙烯和二氧化硅纳米颗粒的表征,显示裸,cad,无cad和对照处理的纳米颗粒的概况。
132.图50b.用于cad筛选的聚苯乙烯和二氧化硅纳米颗粒的表征,显示不同纳米颗粒组的ζ电位。
133.图50c.用于cad筛选的聚苯乙烯和二氧化硅纳米颗粒的表征,显示cad筛选中不同纳米颗粒的tem。
134.图51a.来自cad,无cad,和没有cad风险(对照)的纳米颗粒的分析的不同蛋白质冠的蛋白质浓度,显示了针对不同蛋白质冠的蛋白质浓度的bradford测定。
135.图51b.来自cad,无cad,和没有cad风险(对照)的纳米颗粒的分析的不同蛋白质冠的蛋白质浓度,显示了个性化蛋白质概况已经分析并通过1d-sds-page进行比较。
136.图51c.来自cad,无cad,和没有cad风险(对照)的纳米颗粒的分析的不同蛋白质冠的蛋白质浓度,显示通过光密度测定的cad,无cad和对照pc中蛋白质的量的差异的凝胶分析。
137.图52.描绘了pc中前20丰度蛋白质的百分比贡献差异的条形图。
138.图53.描绘通过分析由蛋白质包被的冠纳米颗粒产生的指纹将对象分类为cad,无cad和对照的图。
139.图54a.在阿尔茨海默病血浆中孵育后纳米颗粒的合成和生物学特性。纳米深度纳米颗粒跟踪分析(大小)。用ad蛋白质冠包被之前和之后的聚苯乙烯纳米颗粒。裸纳米颗粒为90-100nm并且尺寸均匀。ad pc包被的纳米颗粒尺寸更大且均匀性更小。报告每个测量的强度概况和散点图。数值为平均值
±
sd(n=3)。
140.图54b.在阿尔茨海默病血浆中孵育后纳米颗粒的合成和生物学特性。纳米深度纳米颗粒跟踪分析(大小)。用ad蛋白质冠包被之前和之后的二氧化硅纳米颗粒。裸纳米颗粒
为90-100nm并且尺寸均匀。ad pc包被的纳米颗粒尺寸更大且均匀性更小。报告每个测量的强度概况和散点图。数值为平均值
±
sd(n=3)。
141.图55.tem分析。在已通过透射电子显微镜分析用ad蛋白质冠包被之前和之后的纳米颗粒,以评估形态和大小的潜在变化。p:聚苯乙烯;pn:聚苯乙烯-nh2,pc:聚苯乙烯-cooh;s:二氧化硅;sn:二氧化硅-nh2;sc:二氧化硅-cooh。在血浆中孵育后,所有纳米颗粒均显示出尺寸增加。
142.图56.条带的sds-page凝胶和光密度分析。上样顺序:p,p-nh2,p-cooh,s,s-nh2,s-cooh,其中p:聚苯乙烯;pn:聚苯乙烯-nh2,pc:聚苯乙烯-cooh;s:二氧化硅;sn:二氧化硅-nh2;sc:二氧化硅-cooh。已经分析了个性化蛋白质冠概况并通过sds-page进行了比较。显示了阿尔茨海默蛋白质冠和一个健康蛋白质冠的四种代表性凝胶。通过imagej(y轴:强度,x轴:分子量)分析相对于吸附在纳米颗粒上的血浆蛋白质的条带强度。
143.图57.健康和ad疾病的分类。白点是ad,黑点是健康样品。
144.图58.使用相同体积加载(10μl,左)或相同量(10μg,右)的不同直径的二氧化硅纳米颗粒的sds-page凝胶分析。
145.图59.显示用于探测生物分子冠中核酸存在而进行的实验的方案。
146.图60.核酸与三种不同纳米颗粒结合的琼脂糖凝胶分析。
147.图61.血浆中核酸含量的分析。
148.图62.当蛋白质通过尿素从冠解离时,与纳米颗粒的生物分子冠结合的核酸量的分析。
149.图63.当冠蛋白质未从颗粒表面解离时,与纳米颗粒的生物分子冠结合的核酸量的分析。
150.图64.当用纯化试剂盒首先从血浆中纯化核酸然后与纳米颗粒一起孵育时,与纳米颗粒的生物分子冠结合的核酸量的分析。
151.图65.区分复杂生物样品的状态的方法的示意图。
152.图66.计算机系统的示意图。
153.发明详述
154.已通过一个或多个优选的实施方式描述了本发明,但应理解除了明确描述的那些方案之外,许多等同方案、替代方案、变化方案和修改方案是可能实现的并在本发明范围内。
155.本发明提供了用于对对象的疾病状态进行预后,诊断和检测的传感器阵列和方法。本发明的传感器阵列不同于涉及检测特定生物分子的各个传感器的已知传感器阵列。在本发明的传感器阵列中,生物分子不必是已知的,因为该系统不依赖于特定生物分子的存在或不存在或特定疾病标志物的量。该新传感器阵列能够检测与不同传感器元件结合的生物分子冠的组成变化。这种检测相对变化或模式的能力(与不同传感器元件结合的实际生物分子或与每个传感器元件结合的每个生物分子的量和/或构象)允许确定每个阵列的独特生物分子指纹。该生物分子指纹可以对对象的不同健康和疾病状态进行分层。在一些实施方式中,生物分子指纹不仅能够区分健康对象和处于疾病或病症的各种不同阶段中的对象,而且还能够确定将在之后发展疾病或病症的对象中的疾病前状态。这与本领域中测量或检测与疾病或病症相关的特定生物标志物以提供发展疾病的倾向(例如偶然性或可能
性)的系统显著不同且新颖。本发明的传感器和方法能够在任何体征或症状之前检测疾病,换句话说,可以在出现任何特定体征或症状之前预先诊断疾病。
156.本发明的独特性在于来自对象样品的生物分子指纹识别和确定该对象的疾病状态或健康连续性的能力的组合。
157.本发明基于发明人的工作,其已经显示传感器元件(例如,纳米颗粒)的表面,能被一层不同的生物分子(包括蛋白质)迅速覆盖,以在与生物样品接触时形成“生物分子冠”。构成这些生物分子冠的生物分子的类型,数量和类别与传感器元件本身的物理化学性质以及不同生物分子本身和传感器元件之间的复杂相互作用密切相关。这些相互作用导致每个传感器元件产生独特的生物分子冠特征。换句话说,根据哪些生物分子与传感器元件相互作用,不仅影响生物分子冠的组成,而且还可以改变哪些其他不同的生物分子也可以与该特定传感器元件相互作用。
158.可以使各自具有其自身生物分子冠特征的不同传感器元件与样品接触,以产生该样品的独特生物分子指纹。然后该指纹可用于确定对象的疾病状态。下面将更详细地讨论本发明的实施方式。
159.本发明提供了传感器阵列,其包括多个传感器元件,基本上由多个传感器元件组成或由多个传感器元件组成,其中多个传感器元件在至少一种物理化学特性方面彼此不同。在一些实施方式中,每个传感器元件能够结合样品中的多个生物分子以产生生物分子冠特征。在一些实施方式中,每个传感器元件具有不同的生物分子冠特征。
160.当与样品接触时,多个传感器元件产生多个生物分子冠特征,它们一起形成生物分子指纹。“生物分子指纹”是针对多个传感器元件的至少两个生物分子冠特征的生物分子的合并组成或模式。
161.如本文所用,术语“传感器元件”是指当与样品接触时能够结合多个生物分子的元件并且涵盖术语“纳米级传感器元件”。在一个实施方式中,传感器元件是在至少一个方向上从约5纳米到约50000纳米的元件。合适的传感器元件包括,例如但不限于在至少一个方向上约5nm至约50,000nm的传感器元件,包括约5nm至约40000nm,或者约5nm至约30000nm,或者约5nm至约20,000nm,或者约5nm至约10,000nm,或者约5nm至约5000nm,或者约5nm至约1000nm,或者约5nm至约500nm,或者约5nm至50nm,或者约10nm至100nm,或者约20nm至200nm,或者约30nm至300nm,或者约40nm至400nm,或者约50nm至500nm,或者约60nm至600nm,或者约70nm至700nm,或者约80nm至800nm,或者约90nm至900nm,或者约100nm至1000nm,或者约1000nm至10000nm,或者约10000nm至50000nm,以及它们之间的任何组合或量(例如5nm,10nm,15nm,20nm,25nm,30nm,35nm,40nm,45nm,50nm,55nm,60nm,65nm,70nm,80nm,90nm,100nm,125nm,150nm,175nm,200nm,225nm,250nm,275nm,300nm,350nm,400nm,450nm,500nm,550nm,600nm,650nm,700nm,750nm,800nm,850nm,900nm,1000nm,1200nm,1300nm,1400nm,1500nm,1600nm,1700nm,1800nm,1900nm,2000nm,2500nm,3000nm,3500nm,4000nm,4500nm,5000nm,5500nm,6000nm,6500nm,7000nm,7500nm,8000nm,8500nm,9000nm,10000nm,11000nm,12000nm,13000nm,14000nm,15000nm,16000nm,17000nm,18000nm,19000nm,20000nm,25000nm,30000nm,35000nm,40000nm,45000nm,50000nm及其间的任何数字)。纳米级传感器元件是指在至少一个方向上小于1微米的传感器元件。纳米级传感器元件的范围的合适示例包括但不限于例如在一个方向上约5nm至约1000nm的元件,包括例如
约5nm至约500nm,或者约5nm至约400nm,或者约5nm至约300nm,或者约5nm至约200nm,或者约5nm至约100nm,或者约5nm至约50nm,或者约10nm至约1000nm,或者约10nm至约750nm,或者约10nm至约500nm,或者约10nm至约250nm,或者约10nm至约200nm,或者约10nm至约100nm,或者约50nm至约1000nm,或者约50nm至约500nm,或者约50nm至约250nm,或者约50nm至约200nm,或者约50nm至约100nm,以及它们之间的任何组合,范围或量(例如,5nm,10nm,15nm,20nm,25nm,30nm,35nm,40nm,45nm,50nm,55nm,60nm,65nm,70nm,80nm,90nm,100nm,125nm,150nm,175nm,200nm,225nm,250nm,275nm,300nm,350nm,400nm,450nm,500nm,550nm,600nm,650nm,700nm,750nm,800nm,850nm,900nm,1000nm等)。关于本文所述的传感器阵列,术语传感器元件的用途包括纳米级传感器元件用于传感器和相关方法的用途。
162.术语“多个传感器元件”指的是不止一个,例如,至少两个传感器元件。在一些实施方式中,多个传感器元件包括至少两个传感器元件至至少1000个传感器元件,优选地约两个传感器元件至约100个传感器元件。在合适的实施方式中,阵列包括至少两个到至少100个传感器元件,或者至少两个到至少50个传感器元件,或者至少2到30个传感器元件,或者至少2到20个传感器元件,或者至少2个传感器元件,至少10个传感器元件,或者至少3至至少50个传感器元件,或者至少3至至少30个传感器元件,或者至少3至至少20个传感器元件,或者至少3至至少10个传感器元件,或者至少4至至少50个传感器元件,或者至少4至至少30个传感器元件,或者至少4至至少20个传感器元件,或者至少4至至少10个传感器元件,并且包括其间想到的任意数量的传感器元件(例如,至少2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、60、70、80、90、100、110、120、130、140、150、160、170、180、190、200、225、250、300、350、400、450、500、550、600、650、700、750、800等)。在一些实施方式中,传感器阵列包括至少6个传感器元件至至少20个传感器元件,或者至少6个传感器元件至至少10个传感器元件。
163.术语“多个纳米级传感器元件”指的是不止一个,例如,至少两个纳米级传感器元件。在一些实施方式中,多个纳米级传感器元件包括至少两个纳米级传感器元件至至少1000个纳米级传感器元件,优选地约两个纳米级传感器元件至约100个纳米级传感器元件。在合适的实施方式中,阵列包括至少两个到至少100个纳米级传感器元件,或者至少两个到至少50个纳米级传感器元件,或者至少2到30个纳米级传感器元件,或者至少2到20个纳米级传感器元件,或者至少2个纳米级传感器元件,至少10个纳米级传感器元件,或者至少3至至少50个纳米级传感器元件,或者至少3至至少30个纳米级传感器元件,或者至少3至至少20个纳米级传感器元件,或者至少3至至少10个纳米级传感器元件,或者至少4至至少50个纳米级传感器元件,或者至少4至至少30个纳米级传感器元件,或者至少4至至少20个纳米级传感器元件,或者至少4至至少10个纳米级传感器元件,并且包括其间想到的任意数量的纳米级传感器元件(例如,至少2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、60、70、80、90、100、110、120、130、140、150、160、170、180、190、200、225、250、300、350、400、450、500、550、600、650、700、750、800等)。
164.如本文所用,术语“生物分子冠”是指能够结合传感器元件的多种不同生物分子。术语“生物分子冠”包括“蛋白质冠”,其是本领域中用于指代当纳米颗粒与生物样品或生物
系统接触时结合纳米颗粒的蛋白质,脂质和其他血浆组分的术语。本文使用的术语“生物分子冠”还包括本领域中提到的软和硬蛋白质冠,参见例如milani等,“转移到聚苯乙烯纳米颗粒的可逆与不可逆结合:软和硬冠(reversible versus irreversible binding of transferring to polystyrene nanoparticles:soft and hard corona)”,acs nano,2012,6(3),第2532-2541页;mirshafiee等“蛋白质预包被对蛋白质冠组成和纳米颗粒细胞摄取的影响(impact of protein pre-coating on the protein corona composition and nanoparticle cellular uptake)”,biomaterials卷75,2016年1月,第295-304页,mahmoudi等,“在纳米生物界面处对蛋白质冠的新认识(emerging understanding of theprotein corona at the nano-bio interfaces)”,nanotoday 11(6),2016年12月,第817-832页,和mahmoudi等,“蛋白质-纳米颗粒相互作用:机遇和挑战(protein-nanoparticle interactions:opportunities and challenges)”,chem.rev.,2011,111(9),第5610-5637页,其内容通过引用全文纳入本文。如本领域所述,吸附曲线显示强结合单层的积累直至单层饱和点(在几何定义的蛋白质与np比率下),超过该值,形成二级弱结合层。当第一层不可逆地结合(硬冠)时,第二层(软冠)表现出动态交换。以高亲和力吸附的蛋白质形成由不易解吸的紧密结合的蛋白质组成的所谓“硬”冠,并且以低亲和力吸附的蛋白质形成由松散结合的蛋白质组成的“软”冠。软和硬冠也可以根据它们的交换时间来定义。硬冠通常表现出大约几个小时的大得多的交换时间。参见,例如m.rahman等,蛋白质-纳米颗粒相互作用(protein-nanoparticle interactions),spring series in biophysics 15,2013,通过引用全文并入。
165.术语“生物分子冠特征”是指与每个单独的传感器元件结合的不同生物分子的组成,特征或模式。该特征不仅指不同的生物分子,还指与传感器元件结合的生物分子的量、水平或数量的差异,或者与传感器元件结合的生物分子的构象状态的差异。预期每个传感器元件的生物分子冠特征可以包含一些相同的生物分子,可以包含与其他传感器元件的不同生物分子,和/或可以在生物分子的水平或数量,类型或确认方面不同。生物分子冠特征不仅可取决于传感器元件的物理化学性质,还可取决于样品的性质和暴露的持续时间。在某些情况下,生物分子冠特征是蛋白质冠特征。在其他情况下,生物分子冠特征是多糖冠特征。在其他情况下,生物分子冠特征是代谢物冠特征。在某些情况下,生物分子冠特征是脂质组学冠特征。
166.在一些实施方式中,生物分子冠特征包括在软冠和硬冠中存在的生物分子。在一些实施方式中,软冠是软蛋白质冠。在一些实施方式中,硬冠是硬蛋白质冠。
167.术语“生物分子”是指可能参与冠形成的生物组分,包括但不限于例如蛋白质,多肽,多糖,糖,脂质,脂蛋白,代谢物,寡核苷酸,代谢组或其组合。预期每个传感器元件的生物分子冠特征可以包含一些相同的生物分子,可以包含与其他传感器元件的不同生物分子,和/或可以在结合到每个传感器元件的生物分子的水平或数量,类型或确认方面不同。在一个实施方式中,生物分子选自蛋白质,核酸,脂质和代谢组。
168.在一些实施例中,传感器阵列包括第一传感器元件和至少一个第二传感器元件,基本上由其组成或由其组成,第一传感器元件产生第一生物分子冠特征,并且第二传感器元件在传感器阵列与生物样品接触时产生至少一个第二生物分子冠特征。生物分子指纹是第一生物分子特征和至少一个第二生物分子特征的组合。设想生物分子特征可以由至少两
个生物分子冠特征至针对测定的不同生物分子特征数量的生物分子冠特征(例如,至少1000个不同的生物分子冠特征)形成。可以针对每个传感器元件分开测定生物分子冠,以确定每个元件的生物分子冠特征并组合以确定生物分子指纹,或者可以同时测定两个或更多个生物分子冠以立即开发生物分子指纹。
169.在一些实施方式中,生物分子指纹包括至少两个生物分子冠特征。在一些实施方式中,生物分子指纹包括两个生物分子冠特征至至少1000个生物分子冠特征,优选约两个生物分子冠特征至约100个生物分子冠特征。在合适的实施方式中,生物分子指纹包括至少两个到至少100个生物分子冠特征,或者至少两个到至少50个生物分子冠特征,或者至少2到30个生物分子冠特征,或者至少2到20个生物分子冠特征,或者至少2个生物分子冠特征,至少10个生物分子冠特征,或者至少3至至少50个生物分子冠特征,或者至少3至至少30个生物分子冠特征,或者至少3至至少20个生物分子冠特征,或者至少3至至少10个生物分子冠特征,或者至少4至至少50个生物分子冠特征,或者至少4至至少30个生物分子冠特征,或者至少4至至少20个生物分子冠特征,或者至少4至至少10个生物分子冠特征,并且包括其间想到的任意数量的生物分子冠特征(例如,至少2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、60、70、80、90、100、110、120、130、140、150、160、170、180、190、200、225、250、300、350、400、450、500、550、600、650、700、750、800等)。
170.使用质谱进行蛋白质组学分析的进展为包括早期癌症在内的健康和疾病谱系中发生的变化提供了新的见解。然而,质谱方法的灵敏度和特异度还不足以强有力地早期检测癌症,部分原因是由于包含人类蛋白质组的10000种蛋白质产生的高噪音,估计浓度范围对于白蛋白为35-50mg/ml,对于一些细胞因子为1-10pg/ml。现有技术需要在覆盖深度和血浆蛋白质处理的通量之间进行权衡。已经进行了多次尝试以显著增加目前低水平的蛋白质检测,包括高丰度蛋白质的消耗,用于多重相对定量的肽水平同量异位标记,消耗后血浆分级策略,生物标志物收获技术,用于分析高质量数据集的数学方法,和多路复用工作流(即,方法的组合)。尽管有这些努力,但血浆蛋白质组学的质谱方法在癌症的早期检测中并未取得可靠的成功。事实上,还没有任何先前的蛋白质组学或其他方法的研究报道对一系列癌症的准确预测和分类,包括最早的症状前阶段。本传感器阵列提供了第一检测系统,其准确地预测和分类疾病状态,包括针对许多不同疾病的症状发生前的疾病状态。
171.先前的尝试已经尝试使用“疾病特异性蛋白质冠”来使用凝胶电泳和纳米颗粒的聚集尺寸的变化来鉴定一种癌症类型。然而,正如我们在下面的实施例中所示,一种类型的纳米颗粒表面蛋白质冠的微妙差异不足进行具有可接受预测准确度的对于癌症的稳健和准确的鉴定和区分,这主要是由于持续存在蛋白质组学覆盖不足的问题。本文描述的传感器阵列能够准确地分类疾病状态。它不仅能够预测疾病状态,而且还能够对疾病前症状(例如阿尔茨海默症)的患者进行分类,或者根据疾病类型(例如癌症的类型)对患者进行分类。
172.为了实质上增强蛋白质冠以优异预测能力进行稳健和精确的癌症检测的能力,发明人开发了传感器阵列(在本文中有时称为蛋白质冠纳米系统或传感器阵列纳米系统)。与仅限于单个纳米颗粒表面的先前方法相比,它在更宽的动态范围的血浆蛋白浓度下提供了显著更全面的蛋白质组学数据。传感器阵列允许使用具有不同物理化学性质的多纳米颗粒对复杂的生物样品(例如,人血浆样品)进行取样,以显著增加在没有蛋白质消耗的情况下
鉴定的低丰度蛋白和高丰度蛋白的数量和范围。这有效地降低了可用的大量蛋白质组学信息中的噪音,从而产生更准确的疾病特征的蛋白质组学特征的早期分化。另外,由于使用传感器阵列独特地衍生的蛋白质-纳米颗粒和蛋白质-蛋白质相互作用的组合,每种类型的蛋白质可以以不同的浓度存在于不同的纳米颗粒的表面上,从而提供额外的蛋白质组学信息。具有不同物理化学性质的多纳米颗粒的使用主要由我们最近的发现驱动,即甚至纳米颗粒的物理化学性质的微小改变也可以引起蛋白质冠组成的显著但可再现的变化。
173.就使用质谱法的蛋白质检测而言,本发明的传感器阵列具有十(10)个数量级的灵敏度和动态范围。本发明的测定法能够检测样品中亚ng范围内存在的蛋白质。该测定或方法具有比用于测量样品中的蛋白质的当前测定法大得多的动态范围。例如,质谱仅具有4-6个数量级的动态范围。这种新传感器阵列能够采样比以前可实现的更大的动态范围。本发明的传感器阵列允许检测和确定我们之前无法检测到的低丰度和稀有蛋白质。
174.术语“样品”是指从对象获得的生物样品或复杂生物样品。合适的生物样品包括但不限于生物流体,包括但不限于全身血液,血浆,血清,肺灌洗液,细胞裂解液,经血,尿液,加工的组织样品,羊水,脑脊髓液,泪液,唾液,精液等。在一个优选实施方式中,所述样品是血液或血清样品。血浆含有数千种不同的蛋白质,这些蛋白质的浓度有12个数量级的差异。本发明的传感器阵列能够随时间或对象的疾病状态检测这些血液样品内的变化。
175.在一些实施方式中,通过本领域已知的方法和试剂盒制备生物流体或复杂生物样品。例如,可首先以低速离心一些生物样品(例如经血,血液样品,精液等)以去除可能干扰阵列的细胞碎片,血凝块和其他细胞组分。在其他实施方式中,例如,可以处理组织样品,例如,可以将组织样品切碎或均质,用酶处理以破碎组织和/或离心以除去细胞碎片,从而允许在组织样品内测定和提取生物分子。分离和/或适当制备和储存血液样品的合适方法是本领域已知的,并且可包括但不限于添加抗凝血剂。
176.合适的传感器元件包括但不限于,例如颗粒,例如有机颗粒,非有机颗粒或其组合。在一些实施方式中,颗粒是例如纳米颗粒,微粒,胶束,脂质体,氧化铁,石墨烯,二氧化硅,蛋白质基颗粒,聚苯乙烯,银和金颗粒,量子点,钯,铂,钛及其组合。在一些实施方式中,纳米颗粒是脂质体。本领域技术人员将能够选择和制备合适的颗粒。在一些优选的实施方式中,传感器元件是纳米级传感器元件。合适的纳米级传感器元件在至少一个方向上小于1微米。在一些方面,纳米级传感器元件在至少一个方向上小于约100nm。
177.概述
178.本公开提供了使用生物分子冠纳米系统检测疾病状态的方法。在一个实施方式中,该方法包括检测疾病特异性蛋白质冠。
179.传感器阵列
180.图65示出了本发明公开的阵列系统的示例性方案。如图65的步骤1所示,可以从表达生物状态703(例如,疾病状态,例如在疾病的任何身体症状出现之前和/或疾病的早期和中期阶段期间)的对象702收集复杂生物样品(例如,血液704)。合适的生物样品704包括但不限于生物流体,包括但不限于全身血液,血浆,血清,肺灌洗液,细胞裂解液,经血,尿液,加工的组织样品,羊水,脑脊髓液,泪液,唾液,精液等。在一个优选实施方式中,所述样品是血液或血清样品。在一些实施方式中,可以从表达生物状态703的对象(例如健康人(非疾病状态))和癌症患者(疾病状态)的血细胞708中分离血浆706,如图65的步骤2所示。
181.接下来,如图65的步骤3所示,可以将复杂生物样品(例如,血浆706)与包含具有不同物理化学性质的多个颗粒712的传感器阵列710一起孵育。可以将多个颗粒712与血浆706一起孵育,以允许血浆706中的生物分子(例如,血浆706中的蛋白质)结合到颗粒712中的一个或多个。随后,如图65的步骤4所示,结合到颗粒712的生物分子(例如蛋白质)可以在蛋白质溶液714中分离用于进一步分析,例如以确定与每种类型的颗粒712(例如,阴离子,中性和阳离子颗粒712)结合的蛋白质的组成。
182.蛋白质溶液714的特征可以在于,例如,如图65的步骤5所示,液相色谱-串联质谱(lc-ms/ms)716。然后可以在图65的步骤6中分析使用lc-ms/ms716鉴定的蛋白质以确定与生物状态703相关的生物分子指纹718(例如,代表与颗粒712中的一个或多个结合的蛋白质,核酸,脂质和多糖)。
183.在图65的步骤7,计算机720(例如,图66中的计算机系统101)可用于将生物分子指纹718(例如,蛋白质指纹)与生物状态703(例如健康状态,疾病状态)相关联。例如,可以利用计算机系统720进行至少两个样品(例如,复杂生物样品如血浆706)的生物分子指纹718(例如蛋白质指纹)的分析,以产生生物状态703和生物分子指纹718之间的关联722(在图65的步骤8处)。关联722的生成可以通过使用本领域已知的方法的关联分析或统计分类,包括但不限于各种监督式和无监督式的数据分析和聚类方法,例如分层聚类分析(hca),主成分分析(pca),偏最小二乘判别分析(pls-da),机器学习(也称为随机森林),逻辑回归,决策树,支持向量机(svm),k-最近邻,朴素贝叶斯,线性回归,多项式回归,用于回归的svm,k均值聚类和隐马尔可夫模型等。换句话说,每个样品(例如,血浆706)的生物分子指纹718彼此进行比较/分析(例如,使用计算机720)以具有统计学意义的方式确定各个指纹之间共同的模式以确定与生物分子(例如蛋白质)指纹718相关联的生物状态。
184.关联722可以将生物分子指纹718(例如,蛋白质指纹)链接到多种生物状态703。例如,在被诊断患有疾病的对象702(即,生物状态703是疾病状态)和未被诊断患有疾病的对象702(即,生物状态703是非疾病状态)之间比较生物分子指纹718可以产生对象702的生物分子指纹718与疾病和疾病状态之间的关联722。在一些实施方式中,生物标志物指纹718与疾病状态(即,生物状态703)之间的这种关联722可以在疾病进展期间非常早地确定(即,在疾病的任何身体症状出现之前和/或在诊断之前)或后来在疾病进展期间确定。
185.可与生物分子指纹718相关联的生物状态703的其他示例包括对药或药物的响应性或无响应性,免疫系统的活化水平(例如,由于对象暴露于外源性抗原),对象对给药相关不良反应的易感性,以及对对象对给予特定组合物或物质表现出过敏反应的可能性的鉴定。
186.计算机控制系统
187.本公开提供了被编程为实现本公开的方法的计算机控制系统。图66显示了计算机系统100,其被编程或以其他方式配置成将生物分子指纹718与生物状态703相关联。通过使用本领域已知的方法进行这种测定、分析或统计学分类,包括但不限于,例如各种监督式和无监督式的数据分析和聚类方法,例如分层聚类分析(hca),主成分分析(pca),偏最小二乘判别分析(pls-da),机器学习(也称为随机森林),逻辑回归,决策树,支持向量机(svm),k-最近邻,朴素贝叶斯,线性回归,多项式回归,用于回归的svm,k均值聚类和隐马尔可夫模型等。计算机系统100可以执行分析本公开的生物分子指纹718的各个方面,例如,比较/分析
几个样品的生物分子冠,以具有统计学意义地确定各个生物分子冠之间共有的模式以确定与生物状态703相关联的生物分子指纹718。计算机系统可用于开发分类器以检测和区分不同生物分子指纹718(例如,蛋白质冠的组成的特征)。从当前公开的传感器阵列收集的数据可用于训练机器学习算法,特别是从患者接收阵列测量值并输出来自每个患者的特定生物分子冠组成的算法。在训练算法之前,可以首先对来自阵列的原始数据进行去噪,以减少各个变量的变异性。
188.机器学习可以概括为学习机在经历学习数据集之后在新的,未见过的示例/任务上准确执行的能力。机器学习可包括以下概念和方法。监督式学习概念可包括aode;人工神经网络,如反向传播,自动编码器,hopfield网络,玻尔兹曼机器,限制玻尔兹曼机器和尖峰神经网络;贝叶斯统计,如贝叶斯网络和贝叶斯知识库;基于病例的推理;高斯过程回归;基因表达编程;分组数据处理方法(gmdh);归纳逻辑编程;基于示例的学习;懒惰学习;学习自动机;学习矢量量化;物流模型树;最小消息长度(决策树,决策图等),例如最近邻算法和类比建模;可能是近似正确的学习(pac)学习;链波下降规则,一种知识获取方法;符号机器学习算法;支持向量机;随机森林;分类器的集合,例如bootstrap聚集(bagging)和提升算法(元算法);序数分类;信息模糊网络(ifn);条件随机场;方差分析;线性分类器,如fisher线性判别,线性回归,logistic回归,多项logistic回归,朴素贝叶斯分类器,感知器,支持向量机;二次分类器;k-最近邻居;提升算法;决策树,如c4.5,随机森林,id3,cart,sliq,sprint;贝叶斯网络,如朴素贝叶斯;和隐马尔可夫模型。无监督式学习概念可包括:期望最大化算法;矢量量化;生成地形图;信息瓶颈方法;人工神经网络,如自组织图;关联规则学习,如apriori算法,eclat算法和fp-growth算法;分层聚类,例如单链接聚类和概念聚类;聚类分析,如k均值算法,模糊聚类,dbscan和optics算法;和异常值检测,例如局部异常值因子。半监督式学习概念可包括:生成模型;低密度分离;基于图的方法;和共训练。强化学习概念可包括:时间差异学习;q学习;学习自动机;和sarsa。深学习概念可包括:深信念网络;深波尔兹曼机;深卷积神经网络;深递归神经网络;和分级时序记忆。
189.图66中描绘的计算机系统100适于实现本文描述的方法。系统100包括经编程以实现本文所述的示例性方法的中央计算机服务器101。该服务器101包括中央处理单元(cpu,也称为“处理器”)105,其可以是单核处理器、多核处理器或用于并行处理的多个处理器。服务器101还包括存储器110(例如,随机存取存储器、只读存储器、闪存);电子存储单元115(例如,硬盘);通信接口(120例如,网络适配器),用于与一个或多个其他系统进行通信;以及外围装置125,其可包括高速缓存、其他存储器、数据存储和/或电子显示适配器。存储器110、存储单元115、接口120和外围装置125通过诸如主版的通信总线(实线)与处理器通信。储存单元115可以是用于储存数据的数据存储单元。借助于通信接口120,服务器101可以可操作地连接计算机网络(“网络”)130。网络130可以是互联网,内联网和/或外联网,与互联网、远程通信或数据网络通信的内联网和/或外联网。在一些情况中,借助于服务器101,网络130可以实现对等网络,这使得连接到服务器101的装置可以充当客户端或服务器。
190.存储单元115可以存储诸如主题报告之类的文件,和/或与关于个体的数据通信,或者与本公开相关的数据的任何方面。
191.计算机服务器101可以通过网络130与一个或多个远程计算机系统通信。一个或多个远程计算机系统可以是例如个人计算机、笔记本、平板电脑、电话、智能电话或个人数字
助理。
192.在一些应用中,计算机系统100包括单个服务器101。在其他情况中,系统包括通过内联网、外联网和/或互联网彼此通信的多个服务器。
193.服务器101可以适于存储本文提供的测量数据或数据库,来自对象的患者信息,例如病史,家族史,人口统计数据和/或与特定应用可能相关的其他临床或个人信息。这些信息可以存储在存储单元115或服务器101上,并且这些数据可以通过网络传输。
194.本文所述的方法可以通过存储在服务器101的电子存储位置上,例如,存储器110或电子存储单元115上,的机器(或计算机处理器)可执行代码(或软件)来实现。在使用过程中,代码可以由处理器105执行。在某些情况下,可从存储单元115获取代码并将其存储在存储器110供处理器105快速访问。在一些情况中,可以排除电子存储单元115,并将机器可执行指令存储在存储器110中。或者,代码可以在第二台计算机系统140上执行。
195.本文所提供的系统和方法的方面,如处理器101可以在编程中实现。该技术的各个方面可以被认为是“产品”或“制造品”,特别是以在一种计算机可读介质中进行或实施的机器(或处理器)可执行代码和/或相关数据的形式。机器可执行代码可以存储在电子存储单元上,如存储器(例如,只读存储器、随机存取存储器、闪存)或硬盘。“存储”类型的介质可以包括计算机、处理器等或其相关模块的任何或所有有形存储器,如各种半导体存储器,磁带驱动器,磁盘驱动器等,其可以随时提供用于软件编程的非瞬时存储。软件的所有或部分可以有时通过互联网或各种其它远程通信网络通信。例如,这样的通信可以将软件从一台计算机或处理器加载到另一台计算机或处理器中,例如,从管理服务器或主计算机加载到应用服务器的计算机平台中。因此,可以包括软件元件的其它类型的媒介包括光波、电波和电磁波,诸如跨越本地装置之间的物理接口使用的,通过有线和光学陆地线网络以及跨越各种空中链路的。诸如有线或无线连接、光链路等承载这些波的物理元件也可以被认为是承载软件的介质。如本文所用,除非限于非暂时性,有形“存储”介质,诸如计算机或机器“可读介质”之类的术语可以指代参与向处理器提供指令以供执行的任何介质。
196.本文描述的计算机系统可以包括用于执行本文描述的任何算法或基于算法的方法的计算机可执行代码。在一些应用中,本文描述的算法将利用由至少一个数据库组成的存储单元。
197.关于本公开的数据可以通过网络或连接传输以供接收器接收和/或检查。接收器可以是但不限于报告所属的对象;或其护理者,例如,健康护理提供者、管理者、其他医疗专业人员或其他看护人;执行和/或下令进行分析的个人或实体。接收器也可以是用于存储这样报告的本地或远程系统(例如,“云计算”体系结构的服务器或其他系统)。在一个实施方式中,计算机可读介质包括适合传输使用本文所述的方法的生物样品的分析结果的介质。
198.本文所提供的系统和方法的方面,如图66中的计算机系统101可以在编程中实现。该技术的各个方面可以被认为是“产品”或“制造品”,特别是以在一种计算机可读介质中进行或实施的机器(或处理器)可执行代码和/或相关数据的形式。机器可执行代码可以存储在电子存储单元上,如存储器(例如,只读存储器、随机存取存储器、闪存)或硬盘。“存储”类型的介质可以包括计算机、处理器等或其相关模块的任何或所有有形存储器,如各种半导体存储器,磁带驱动器,磁盘驱动器等,其可以随时提供用于软件编程的非瞬时存储。软件的所有或部分可以有时通过互联网或各种其它远程通信网络通信。例如,这样的通信可以
将软件从一台计算机或处理器加载到另一台计算机或处理器中,例如,从管理服务器或主计算机加载到应用服务器的计算机平台中。因此,可以包括软件元件的其它类型的媒介包括光波、电波和电磁波,诸如跨越本地装置之间的物理接口使用的,通过有线和光学陆地线网络以及跨越各种空中链路的。诸如有线或无线连接、光链路等承载这些波的物理元件也可以被认为是承载软件的介质。如本文所用,除非限于非暂时性,有形“存储”介质,诸如计算机或机器“可读介质”之类的术语指代参与向处理器提供指令以供执行的任何介质。
199.因此,诸如计算机可执行代码之类的机器可读介质可以采用许多形式,包括但不限于有形存储介质,载波介质或物理传输介质。非易失性储存介质介质包括,例如,光盘或磁盘,如任何计算机或诸如可以用于实施图中所示的数据库等的那些中的任何储存装置。易失性存储介质包括动态存储器,如此类计算机平台的主存储器。有形传输介质包括同轴电缆、铜线和光纤,包括在计算机系统内包含总线的电线。载波传输介质可以采取电信号或电磁信号的形式,或者诸如在射频(rf)和红外(ir)数据通信期间产生的声波或光波的形式。因此,计算机可读介质的常见形式包括例如软盘(floppy disk)、软磁盘(flexibledisk)、硬盘、磁带、任何其它磁介质、cd-rom、dvd或dvd-rom、任何其它光学介质、打孔卡、纸带、具有孔图样的任何其它物理介质、ram、rom、prom和eprom、flash-eprom、任何其它存储器芯片或盒、传送数据或指令的载波、电缆、或传输诸如载波的链接、或者计算机可从其中读取编程代码和/或数据的任何其它介质。这样形式的计算机可读介质中的许多可能包括将一个或多个指令的一个或多个序列运送到处理器以进行执行。
200.物理化学性质
201.在一些实施方式中,所述多个传感器元件包括多个颗粒,基本上由其组成或由其组成,其中每个颗粒通过至少一种物理化学性质彼此区分,使得每个传感器元件在与同一样品接触时具有独特的生物分子冠特征。
202.在阵列中发现的传感器元件的物理化学性质是指,例如,组成,尺寸,表面电荷,疏水性,亲水性,表面官能度(表面官能团),表面形貌,表面曲率和形状。术语组成包括使用不同类型的材料以及材料的化学和/或物理性质的差异,例如,在传感器元件之间选择的材料的导电性。
203.表面曲率通常由纳米颗粒尺寸确定。因此,在纳米尺度下,随着纳米颗粒的尺寸改变,颗粒的表面曲率改变,并且表面曲率的这种改变影响表面的结合选择性。例如,在一定的曲率下,颗粒的表面可以对特定类型的生物分子具有结合亲和性,其中不同的曲率将具有不同的结合亲和性和/或对不同生物分子的结合亲和性。可以调节曲率以产生对不同生物分子具有改变的亲和性的多个传感器元件。可以创建包括具有不同曲率(例如,不同尺寸)的多个传感器元件的传感器阵列,这导致多个传感器元件各自具有不同的生物分子冠特征。
204.表面形貌也可以通过诸如对表面进行图案化以提供不同的亲和性,在多个长度尺度上的工程改造表面曲率等方法来修改。通过例如由嵌段聚合形成传感器元件,其中至少两个嵌段具有不同的化学性质,使用至少两种不同聚合物的混合物形成纳米颗粒并在聚合期间相分离聚合物,和/或相分离后交联分开的聚合物来提供表面图案化。例如,通过使用由细碎颗粒稳定的pickering乳液(sacanna等,2007)来提供多个长度尺度上的工程改造的表面曲率,用于合成纳米颗粒。在一些实施方式中,细碎颗粒选自,例如,硅酸盐,铝酸盐,钛
酸盐,金属氧化物,例如铝,硅,钛,镍,钴,铁,锰,铬或钒氧化物,碳黑和氮化物或碳化物,例如氮化硼,碳化硼,氮化硅或碳化硅等。
205.例如,包括纳米级传感器元件的传感器元件可各自被功能化以具有不同的物理化学性质。使传感器元件功能化的合适方法在本领域中是已知的并且取决于传感器元件的组成(例如金,氧化铁,二氧化硅,银等),并且包括但不限于例如氨基丙基官能化,胺官能化,硼酸官能化,羧酸官能化,甲基官能化,n-琥珀酰亚胺酯官能化,peg官能化,链霉亲和素官能化,甲醚官能化,三乙氧基丙氨基硅烷官能化,硫醇官能化,pcp官能化,柠檬酸酯官能化,硫辛酸官能化,bpei官能化,羧基官能化,羟基官能化等。在一个实施方式中,纳米颗粒可以用胺基(-nh2)或羧基(cooh)官能化。在一些实施方式中,纳米级传感器元件用极性官能团官能化。极性官能团的非限制性示例包括羧基,羟基,硫醇基,氰基,硝基,铵基,咪唑基,锍基,吡啶鎓基,吡咯烷鎓基,鏻基或它们的任意组合。在一些实施方式中,官能团是酸性官能团(例如,磺酸基,羧基等),碱性官能团(例如,氨基,环仲氨基(例如吡咯烷基和哌啶基),吡啶基,咪唑基,胍基等),氨基甲酰基,羟基,醛基等。在一些实施方式中,极性官能团是离子型官能团。离子型官能团的非限制性示例包括铵基,咪唑基,锍基,吡啶鎓基,吡咯烷鎓基,鏻基。在一些实施方式中,传感器元件用可聚合官能团官能化。可聚合官能团的非限制性示例包括乙烯基和(甲基)丙烯酸基。在一些实施方式中,官能团是丙烯酸吡咯烷酯,丙烯酸,甲基丙烯酸,丙烯酰胺,甲基丙烯酸2-(二甲基氨基)乙酯,甲基丙烯酸羟乙酯等。
206.在其他实施方式中,可以通过改变表面电荷来改变传感器元件的物理化学性质。例如,可以修改表面以提供净中性电荷,净正表面电荷,净负表面电荷或两性离子电荷。可以在元件合成期间或通过表面官能化对电荷进行后合成修饰来控制表面电荷。对于聚合物纳米颗粒,通过使用不同的合成方法,不同的带电共聚单体和通过具有混合氧化态的无机物质,可以在合成期间获得电荷差异。
207.纳米颗粒
208.在一些实施方式中,颗粒是纳米颗粒。在一些实施方式中,颗粒是脂质体。脂质体可包含能够形成颗粒的任何脂质。术语“脂质”是指一组有机化合物,它们是脂肪酸的酯,其特征在于不溶于水但可溶于许多有机溶剂。脂质通常分为至少三类:(1)“简单脂质”,包括脂肪和油以及蜡;(2)“复合脂质”,包括磷脂和糖脂;和(3)“衍生脂质”,如类固醇。在一个实施方式中,脂质体包含一种或多种阳离子脂质或阴离子脂质,和一种或多种稳定脂质。合适的脂质体是本领域已知的,包括但不限于,例如,dopg(1,2-二油酰基-sn-甘油-3-磷酸-(1
′‑
rac-甘油),dotap(1,2-二油酰基-3-三甲基铵-丙烷)-dope(二油酰基磷脂酰乙醇胺),chol(dopc-胆固醇)及其组合。
209.脂质体的基于脂质的表面可以在脂质-生物分子(例如蛋白质)界面处接触复杂生物样品的生物分子(例如,蛋白质)的亚组(例如,血浆,或具有生物分子的复杂混合物的任何样品,例如蛋白质和核酸以及至少一种多糖和脂质),从而结合蛋白质亚组以产生生物分子(例如蛋白质)结合的模式。
210.在一个实施方式中,脂质体包含阳离子脂质。如本文所用,术语“阳离子脂质”是指当ph降低至低于脂质的可电离基团的pk时是阳离子或变成阳离子(质子化),但在较高ph值下逐渐变得更中性的脂质。在低于pk的ph值下,脂质就能够与带负电的核酸结合。在某些实施方式中,阳离子脂质包含两性离子脂质,其在ph降低时呈现正电荷。在某些实施方式中,
脂质体包含阳离子脂质。在一些实施方式中,阳离子脂质包含在选择性ph(例如生理ph)下带有净正电荷的许多脂质物质中的任何一种。这些脂质包括但不限于n,n-二油基-n,n-二甲基氯化铵(dodac);n-(2,3-二油氧基)丙基)-n,n,n-三甲基氯化铵(dotma);n,n-二硬脂基-n,n-二甲基溴化铵(ddab);n-(2,3-二油酰基氧基)丙基)-n,n,n-三甲基氯化铵(dotap);3-(n-(n
′
,n
′‑
二甲基氨基乙烷)-氨基甲酰基)胆固醇(dc-chol),n-(1-(2,3-二油酰氧基)丙基)-n-2-(精胺甲酰胺基)乙基)-n,n-二甲基三氟乙酸铵(dospa),二十八烷基酰基甘氨酰甲酰丙胺(dogs),1,2-二油酰-3-二甲基铵丙烷(dodap),n,n-二甲基-2,3-二油酰氧基)丙胺(dodma),n-(1,2-二肉豆蔻氧基丙-3-基)-n,n-二甲基-n-羟乙基溴化铵(dmrie),1,2-二油酰基-sn-3-磷酸乙醇胺(dope),n-(1-(2,3-二油基氧基)丙基)-n-(2-(精胺甲酰胺基)乙基)-n,n-二甲基三氟乙酸铵(dospa),二十八烷基酰胺基甘氨酸羧基精胺(dogs)和1,2-二十四烷酰基-sn-甘油-3-磷酸胆碱(dmpc)。以下脂质是阳离子的并且在低于生理ph的条件下具有正电荷:dodap,dodma,dmdma,1,2-二亚油酰氧基-n,n-二甲基氨基丙烷(dlindma),1,2-二亚油烯基氧基-n,n-二甲基氨基丙烷(dlendma)。在一些实施方式中,脂质是氨基脂质。
211.在某些实施方式中,脂质体包含一种或多种其他脂质,其在形成过程中稳定颗粒的形成。合适的稳定脂质包括中性脂质和阴离子脂质。术语“中性脂质”是指在生理ph下以不带电或中性两性离子形式存在的许多脂质物质中的任何一种。代表性的中性脂质包括二磷脂酰胆碱,二酰基磷脂酰乙醇胺,神经酰胺,鞘磷脂,二氢鞘磷脂,脑磷脂和脑苷脂。示例性的中性脂质包括,例如,二硬脂酰磷脂酰胆碱(dspc),二油酰磷脂酰胆碱(dopc),二棕榈酰磷脂酰胆碱(dppc),二油酰磷脂酰甘油(dopg),二棕榈酰磷脂酰甘油(dppg),二油酰磷脂酰乙醇胺(dope),棕榈酰油酰-磷脂酰胆碱(popc),棕榈酰油酰-磷脂酰乙醇胺(pope)和二油酰基-磷脂酰乙醇胺4-(n-马来酰亚胺甲基)-环己烷-1-羧酸酯(dope-mal),二棕榈酰磷脂酰乙醇胺(dppe),二肉豆蔻酰基磷酸乙醇胺(dmpe),二硬脂酰基-磷脂酰乙醇胺(dspe),16-o-单甲基pe,16-o-二甲基pe,18-1-反式pe,1-硬脂酰基-2-油酰基-磷脂酰乙醇胺(sope),和1,2-二乙酰基-sn-甘油-3-磷酸乙醇胺(transdope)。在一个实施方式中,中性脂质是1,2-二硬脂酰基-sn-甘油-3-磷酸胆碱(dspc)。
212.术语“阴离子脂质”是指在生理ph下带负电的任何脂质。这些脂质包括磷脂酰甘油、心磷脂、二酰基磷脂酰丝氨酸、二酰基磷脂酸、n-十二烷酰磷脂酰乙醇胺、n-琥珀酰磷脂酰乙醇胺、n-戊二酰磷脂酰乙醇胺、赖氨酰磷脂酰甘油、棕榈酰甘油磷脂酰甘油(popg)和连接中性脂质的其他阴离子修饰基团。在某些实施方式中,脂质体包含糖脂(例如,单唾液酸神经节苷脂gm.sub.1)。在某些实施方式中,脂质体包含甾醇,例如胆固醇。在某些实施方式中,脂质体包含另外的稳定化脂质,其是聚乙二醇-脂质。合适的聚乙二醇-脂质包括peg-修饰的磷脂酰乙醇胺,peg-修饰的磷脂酸,peg-修饰的神经酰胺(例如peg-cerc14或peg-cerc20),peg-修饰的二烷基胺,peg-修饰的二酰基甘油,peg-修饰的二烷基甘油。代表性的聚乙二醇-脂质包括peg-c-domg,peg-c-dma和peg-s-dmg。在一个实施方式中,聚乙二醇-脂质是n-[(甲氧基聚(乙二醇).sub.2000)氨基甲酰基]-1,2-二肉豆蔻基丙基-3-胺(peg-c-dma)。在一个实施方式中,聚乙二醇-脂质是peg-c-domg)。
[0213]
合适的脂质体可以是固体脂质纳米颗粒(sln),其可以由固体脂质,乳化剂和/或水/溶剂制成。sln可包括但不限于以下成分的组合:甘油三酯(三硬脂酸甘油酯),偏甘油酯
(imwitor),脂肪酸(硬脂酸,棕榈酸)和类固醇(胆固醇)和蜡(十六烷基棕榈酸酯))。各种乳化剂及其组合(pluronic f 68,f 127)已用于稳定脂质分散体。用于制备snl传感器元件的合适成分包括但不限于,例如,磷脂,甘油,泊洛沙姆188,大豆磷脂酰胆碱,compritol,十六烷基棕榈酸酯,peg 2000,peg 4500,吐温85,油酸乙酯,海藻酸钠,乙醇/丁醇,三硬脂酸甘油酯,peg 400,肉豆蔻酸异丙酯,pluronic f68,吐温80,三嗪酸酯,三硬脂酸甘油酯,三月桂酸酯,硬脂酸,甘油基癸酸酯如可可豆油,甘油三酯椰子油,1-十八烷醇,山嵛酸甘油酯如棕榈硬脂酸甘油酯如5,和十六烷基棕榈酸蜡等。
[0214]
在一些实施方式中,多个传感器元件包括多个不同几何形状的半颗粒(half particle),基本上由其组成或由其组成,这些半颗粒可以通过模制技术,3d打印或4d打印制成。合适的半颗粒是本领域已知的,并且包括但不限于任何几何形状的半颗粒和部分颗粒,例如球形,棒形,三角形,立方体及其组合。适当地,在一个实施方式中,多个半颗粒具有通过3d打印产生的不同物理化学性质。
[0215]
在一些实施方式中,包括纳米级传感器元件的传感器元件通过3d或4d打印制成。包括纳米级传感器元件的传感器元件的3d和4d打印的合适方法在本领域中是已知的。用于3d和4d打印的合适材料包括但不限于,例如,塑料和合成聚合物(例如,聚乙二醇-二丙烯酸酯(peg-da),聚(ε-己内酯)(pcl),聚(环氧丙烷)(ppo),聚(环氧乙烷)(peo)等),金属,粉末,玻璃,陶瓷和水凝胶。通过3d或4d打印制成的合适形状包括但不限于,例如全球或部分球(例如3/4或半球),杆,立方体,三角形或其他几何或非几何形状。
[0216]
3d打印技术包括但不限于微挤出打印,喷墨生物打印,激光辅助生物打印,立体平版印刷,全方位打印和压模打印。
[0217]
在一些实施方式中,纳米级传感器元件是纳米颗粒。合适的纳米颗粒是本领域已知的,包括但不限于,例如,天然或合成聚合物,共聚物,三元共聚物(其中芯由金属或无机氧化物,包括磁芯组成)。合适的聚合物纳米颗粒包括但不限于,例如,聚苯乙烯;聚(赖氨酸),壳聚糖,葡聚糖,聚(丙烯酰胺)及其衍生物,如n-异丙基丙烯酰胺,n-叔丁基丙烯酰胺,n,n-二甲基丙烯酰胺,聚乙二醇,聚(乙烯醇),明胶,淀粉,(生物)可降解聚合物,二氧化硅等。
[0218]
在各种实施方式中,纳米颗粒的核可包括有机颗粒,无机颗粒,或包含有机和无机材料的颗粒。例如,颗粒可具有核结构,该核结构是或包括金属颗粒,量子点颗粒,金属氧化物颗粒,或核-壳颗粒。例如,核结构可以是或包括聚合物颗粒或基于脂质的颗粒,并且接头可包括脂质,表面活性剂,聚合物,烃链或两亲聚合物。例如,接头可包括聚乙二醇或聚亚烷基二醇,例如,接头的第一末端可包括与聚乙二醇(peg)结合的脂质,并且第二末端可包括与peg结合的官能团。在这些方法中,第一或第二官能团可包括胺基,马来酰亚胺基,羟基,羧基,吡啶硫醇基或叠氮基。
[0219]
在某些实施方式中,纳米颗粒可包含聚合物,所述聚合物包括例如聚苯乙烯磺酸钠(pss),聚环氧乙烷(peo),聚氧乙二醇,聚乙二醇(peg),聚乙烯亚胺(pei),聚乳酸,聚己内酯,聚乙醇酸,聚(丙交酯-共-乙交酯聚合物(plga),纤维素醚聚合物,聚乙烯吡咯烷酮,乙酸乙烯酯,聚乙烯吡咯烷酮-乙酸乙烯酯共聚物,聚乙烯醇(pva),丙烯酸酯,聚丙烯酸(paa),乙酸乙烯酯,巴豆酸共聚物,聚丙烯酰胺,聚乙烯膦酸酯,聚丁烯膦酸酯,聚苯乙烯,
聚乙烯膦酸酯,聚亚烷基,羧基乙烯基聚合物,海藻酸钠,角叉菜胶,黄原胶,阿拉伯树胶,阿拉伯树胶,瓜尔胶,支链淀粉,琼脂,甲壳素,壳聚糖,果胶,刺梧桐树胶,刺槐豆胶,麦芽糖糊精,直链淀粉,玉米淀粉,马铃薯淀粉,大米淀粉,木薯淀粉,豌豆淀粉,甘薯淀粉,大麦淀粉,小麦淀粉,羟丙基化高直链淀粉,糊精,果聚糖,爱生兰,麸质,胶原,乳清蛋白分离物,酪蛋白,乳蛋白,大豆蛋白,角蛋白或明胶,或其共聚物,衍生物或混合物。
[0220]
在其他实施方式中,聚合物可以是或包括聚乙烯,聚碳酸酯,聚酐,聚羟基酸,聚丙烯酸丁酯,聚己内酯,聚酰胺,聚缩醛,聚醚,聚酯,聚(原酸酯),聚氰基丙烯酸酯,聚乙烯醇,聚氨酯,聚磷腈,聚丙烯酸酯,聚甲基丙烯酸酯,聚氰基丙烯酸酯,聚脲,聚苯乙烯或多胺,或其共聚物,衍生物或混合物。
[0221]
在一些实施方式中,本公开提供了包含可生物降解的聚合物的纳米颗粒。非限制性示例性可生物降解聚合物可以是聚-β-氨基-酯(pbae),聚(酰氨基胺),包括聚乳酸-共-乙醇酸(plga)的聚酯,聚酐,生物可分聚合物和其他可生物降解的聚合物。在一些实施方式中,可生物降解的聚合物包含2-(3-氨基丙基氨基)乙醇末端改性的聚(1,4-丁二醇二丙烯酸酯-共-4-氨基-1-丁醇),(1-(3-氨基丙基)-4-甲基哌嗪末端改性的聚(1,4-丁二醇二丙烯酸酯-共-4-氨基-1-丁醇),2-(3-氨基丙基氨基)乙醇末端改性的聚(1,4-丁二醇二丙烯酸酯-共-5-氨基-1-戊醇),(1-(3-氨基丙基)-4-甲基哌嗪末端改性的聚(1,4-丁二醇二丙烯酸酯-共-5-氨基-1-戊醇),2-(3-氨基丙基氨基)乙醇末端改性的聚(1,5-戊二醇二丙烯酸酯-共-3-氨基-1-丙醇)和(1-(3-氨基丙基)-4-甲基哌嗪末端改性的聚(1,5-戊二醇二丙烯酸酯-共-3-氨基)-1-丙醇)。
[0222]
阵列基材
[0223]
在一些实施方式中,传感器阵列包括基材。无论传感器元件的特性如何,本发明都可以通过固定在固体基材上,与固体基材连接和/或耦合到固体基材的传感器元件矩阵来实现。基材可包含聚二甲基硅氧烷(pdms),二氧化硅,金或金包被的基材,银或银包被的基材,铂或铂包被的基材,锌或锌包被的基材,碳包被的基材等,基本上由其组成或由其组成。本领域技术人员能够为传感器阵列选择合适的基材。在一些实施方式中,传感器元件和基材由相同的元素,例如金制成。在一些实施方式中,基材和传感器元件(例如纳米颗粒)形成芯片。
[0224]
在一些实施方式中,多个传感器元件包括单个表面,板或芯片,其包含两个或更多个离散传感器元件(区域),其具有拓扑差异,允许在每个离散元件(区域)处形成离散的生物分子冠。可以通过本文描述的方法将表面板或芯片制造为包括两个或更多个离散元件(区域)。离散区域可以是具有不同几何形状,不同尺寸或不同电荷或其他拓扑差异的凸起表面,这产生具有形成离散生物分子冠能力的离散传感器元件。
[0225]
在一些实施方式中,传感器元件非共价地附接到基材。合适的非共价附连方法是本领域已知的,包括但不限于,例如,金属配位,电荷相互作用,疏水-疏水相互作用,螯合等。在其他实施方式中,传感器元件共价附接到基材。共价附连传感器元件和基材的合适方法包括但不限于,例如点击化学,辐射等。
[0226]
仅出于说明的目的,附连传感器元件,例如,纳米级传感器元件与基材的方法示于图23-40。例如,传感器元件可以通过二氧化硅基材表面上的氨基和纳米颗粒表面上的羧酸基团之间的酰胺化反应(图23),通过二氧化硅基材表面上的环氧基团和纳米颗粒表面上的
氨基之间的开环反应(图24),通过二氧化硅基材表面上的马来酰亚胺基团与纳米颗粒表面上的硫醇或氨基之间的迈克尔加成反应(图25),通过二氧化硅基材表面上的异氰酸酯基团和纳米颗粒表面上的羟基或氨基之间的尿烷反应(图26),通过二氧化硅基材表面上的硫醇基团与纳米颗粒表面上的硫醇基团之间的氧化反应(图27),通过二氧化硅基材表面上叠氮基和纳米颗粒表面上的炔基之间的“点击”化学反应(图28),通过二氧化硅基材表面上的2-吡啶基二硫醇基团和纳米颗粒表面上的硫醇基团之间的硫醇交换反应(图29),通过二氧化硅基材表面上的硼酸基团与纳米颗粒表面上的二醇基团之间的配位反应(图30),通过基材表面上的c=c键和纳米颗粒表面上的c=c键之间的uv光照射的加成反应(图31)等耦合到基材(例如二氧化硅基材)。将传感器元件与金基材耦合的合适方法是本领域已知的,并且包括,例如通过au-硫醇键的耦合(图32),通过金基材表面上的羧酸基团与纳米颗粒表面上的氨基之间的酰胺化反应(图33),通过金基材表面上的叠氮基与纳米颗粒表面上的炔基之间的“点击”化学(图34),通过金基材表面上的nhs基团与纳米颗粒表面上的氨基之间的尿烷反应(图35),通过金基材表面上的环氧基团与纳米颗粒表面上的氨基之间的开环反应(图36),通过二氧化硅基材表面上的硼酸基团与纳米颗粒表面上的二醇基团之间的配位反应(图37),通过金基材表面上的c=c键与纳米颗粒表面上的c=c键之间的uv光照射的加成反应(图38),通过金基材表面上的生物素与纳米颗粒表面上的亲和之间的“配体-受体”相互作用(图39),通过金基材表面上的α-环糊精(a-cd)与纳米颗粒表面上的金刚烷(ad)之间的“主-客”相互作用(图40)等。
[0227]
在另一个示例中,可以使用所谓的“点击化学”将功能性表面基团附连到纳米颗粒的核结构上(参见,例如,西格玛奥德里奇目录和美国专利号7,375,234,它们都通过引用全文纳入本文)。在包含点击化学领域的反应中,一个示例是炔烃向叠氮化物的1,3-偶极环加成形成1,4-二取代-1,2,3-三唑。铜(i)催化的反应温和且非常高效,不需要保护基团,并且在许多情况下不需要纯化。叠氮化物和炔烃官能团通常对生物分子和水性环境是惰性的。三唑与天然存在的普遍存在的酰胺部分具有相似性,但与酰胺不同,它不易于裂解。另外,它们几乎不可能氧化或还原。
[0228]
多个传感器元件可以随机地或以不同的模式附连到基材。传感器元件可以基本上均匀地定位。布置的传感器元件的模式可以根据传感器元件附连到基材的模式而变化。每个传感器元件分开一段距离。布置在基材上的传感器元件(例如纳米颗粒)之间的距离可以根据用于附连的接头的长度或其他制造条件而变化。根据各种实施方式,阵列上的多个传感器元件可以制造成具有期望的元件间距离和模式。合适的不同模式在本领域中是已知的,包括但不限于平行线,正方形,圆形,三角形等。此外,传感器元件可以布置成行或列。在一些实施方式中,基材是平坦基材,在其他实施方式中,基材是微通道或纳米通道的形式。仅出于说明性目的,在图15-22中描述了合适的实施方式。传感器元件可以包含在微通道或纳米通道内,微通道或纳米通道限制或控制样品通过传感器阵列的流动。合适的微通道的尺寸可以为10μm至约100μm。
[0229]
在一些实施方式中,多个传感器元件的非限制性示例包括但不限于(a)由相同材料制成但在物理化学性质上不同的多个传感器元件,(b)多个传感器元件,其中一个或多个传感器元件由具有相同或不同物理化学性质的不同材料制成,(c)由尺寸不同的相同材料制成的多个传感器元件,(d)由相同尺寸的不同材料制成的多个传感器元件;(e)由不同材
料制成并由不同尺寸制成的多个传感器元件,(f)多个传感器元件,其中每个元件由不同材料制成,(g)多个具有不同电荷的传感器元件,等等。多个传感器元件可以是两个或更多个传感器元件的任何合适组合,其中每个传感器元件提供独特的生物分子冠特征。例如,多个传感器元件可包括一种或多种脂质体和一种或多种本文所述的纳米颗粒。在一个实施方式中,多个传感器元件可以是具有不同脂质含量和/或不同电荷(阳离子/阴离子/中性)的多个脂质体。在另一个实施方式中,所述多个传感器可含有一种或多种纳米颗粒,所述纳米颗粒由相同材料制成,但具有不同的尺寸和物理化学性质。在另一个实施方式中,所述多个传感器可含有一种或多种由不同材料(例如二氧化硅和聚苯乙烯)制成的纳米颗粒,所述纳米颗粒具有相似或不同的尺寸和/或物理化学性质(例如,修饰,例如,-nh2,-cooh官能化)。这些组合纯粹作为示例提供,并且不限制本发明的范围。
[0230]
颗粒表面上的曲率角可以根据颗粒的尺寸而改变。曲率角的这种变化又改变了蛋白质可附着并且在颗粒上彼此相互作用的表面积。如图58所示,增加颗粒的尺寸导致蛋白质结合量的变化以及附着于不同尺寸的纳米颗粒的蛋白质的模式的变化(在该实施例中,显示了0.1μm,3μm和4μm直径纳米颗粒上的蛋白质sds-page分析)。
[0231]
传感器阵列的新颖性在于它不仅可以检测不同传感器元件之间的不同蛋白质,而且能够比较不同传感器元件之间相同蛋白质的水平。例如,不受任何理论的束缚,但为了说明本传感阵列的独特性,描述了理论实施例。在一些实施方式中,使样品与第一传感器元件a,第二传感器元件b和第三传感器元件c接触,其中每个传感器元件产生疏离的(distant)蛋白质冠特征(即,a
′
,b
′
和c
′
)。每个蛋白质冠特征a
′
,b
′
和c
′
的组成可以彼此不同。在一些实施方式中,a
′
,b
′
和c
′
可包含相同的蛋白质但含量不同,这可提供通过用先前已知的方法表征样品无法获得的额外蛋白质组学信息。换句话说,来自每个纳米颗粒的每个独特的冠蛋白质信息用作独特变量,因此提供更多数据蛋白质组学数据。例如,白蛋白可以仅在一个传感器元件a的蛋白质冠特征,在两个传感器的特征中,例如,a和b,b和c或a和c,或所有三种传感器生物分子特征(a,b,c)中存在。此外,传感器阵列不仅确定蛋白质(例如白蛋白)的存在或不存在,而且还可以确定从一个传感器与另一个传感器的蛋白质量的比较。例如,对于特定生物分子指纹,白蛋白可以浓度x存在于a的特征中,以1/3x浓度存在于传感器b处,以2x浓度存在于传感器c中。在另一种生物分子指纹中,可以找到3种不同浓度的相同蛋白质白蛋白,例如传感器d中的1/8x,传感器e中的3x和传感器f中的1/4x。因此,多个传感器不仅给出了蛋白质浓度的数据点,也可以比较两个或更多个传感器之间的蛋白质浓度。此外,可以将浓度或稀有或低丰度蛋白质与已知蛋白质的浓度进行比较,提供关于蛋白质冠的进一步数据。例如,为了说明的目的,在不同生物分子冠中,可以将未知蛋白质,例如,蛋白质z的浓度与已知蛋白质,例如百蛋白的量进行比较。例如,z可以在传感器a上与白蛋白的比例为1∶8,在传感器b上为1∶50,而在传感器c上不存在。图12提供了分析的蛋白质冠中稀有蛋白质与白蛋白浓度的比较分析。因此,与分析数据时,统计分析可以同时采用蛋白质的存在,每个传感器元件之间的相对浓度,和与特定浓度的已知蛋白质相比的稀有或低丰度蛋白质的浓度。
[0232]
在一些实施方式中,通过聚合物表面的光刻,蚀刻,压花或模塑形成通道。通常,制造工艺可以涉及这些工艺中的任何一个或多个,并且阵列的不同部分可以使用不同的方法制造并组装或粘合在一起。
[0233]
光刻涉及使用光或其他形式的能量(例如电子束)来改变材料。通常,将聚合物材料或前体(例如光致抗蚀剂,耐光材料)涂覆在基材上并选择性地暴露于光或其他形式的能量。取决于光致抗蚀剂,光致抗蚀剂的曝光区域在通常称为“显影”的后续处理步骤中保留或溶解。该过程产生基材上的光致抗蚀剂图案。在一些实施方式中,光致抗蚀剂在模制过程中用作母版。在一些实施方式中,将聚合物前体倾倒具有光致抗蚀剂的基材上,聚合(即固化)并剥离。
[0234]
在一些实施方式中,光致抗蚀剂用作蚀刻工艺的掩模。例如,在硅基材上图案化光致抗蚀剂之后,可以使用深度反应离子蚀刻(drie)工艺或本领域已知的其他化学蚀刻工艺(例如等离子蚀刻,koh蚀刻,hf蚀刻等)将通道蚀刻到基材中。除去光致抗蚀剂,并使用本领域已知的任何键合过程(例如阳极键合,粘合剂键合,直接键合,共晶键合等)将基材键合到另一基材上。根据需要,可以包括多个光刻和蚀刻步骤以及诸如钻孔的机械加工步骤。
[0235]
在一些实施方式中,可以将聚合物基材加热并压在主模上以进行压花加工。主模可以通过各种工艺形成,包括光刻和机械加工。然后将聚合物基材与另一基材键合以形成通道和/或混合设备。如有必要,可以包括机械加工过程。
[0236]
在一些实施方式中,将熔融聚合物或金属或合金注入合适的模具中并使其冷却并固化以进行注塑过程。模具通常由两部分组成,其允许移除模制部件。由此制造的部件可以结合以产生基材。
[0237]
在一些实施方式中,牺牲蚀刻(sacrificial etch)可用于形成通道。可以使用光刻技术来图案化基材上的材料。这种材料被另一种不同化学性质的材料覆盖。该材料可以经历光刻和蚀刻工艺,或其他加工工艺。然后将基材暴露于化学试剂,该化学试剂选择性地除去第一材料。在第二材料中形成通道,在蚀刻工艺之前留下存在第一材料的孔隙。
[0238]
在一些实施方式中,通过激光机械加工或cnc机械加工将微通道直接机械加工到基材中。这样机械加工的几个层可以结合在一起以获得最终的基材。
[0239]
在一些实施方式中,每个通道的宽度或高度范围为约1μm至约1000μm。在一些实施方式中,每个通道的宽度或高度范围为约5μm至约500μm。在一些实施方式中,每个通道的宽度或高度范围为约10μm至约100μm。在一些实施方式中,每个通道的宽度或高度范围为约25μm至约100μm。在一些实施方式中,每个通道的宽度或高度范围为约50μm至约100μm。在一些实施方式中,每个通道的宽度或高度范围为约75μm至约100μm。在一些实施方式中,每个通道的宽度或高度范围为约10μm至约75μm。在一些实施方式中,每个通道的宽度或高度范围为约10μm至约50μm。在一些实施方式中,每个通道的宽度或高度范围为约10μm至约25μm。
[0240]
在一些实施方式中,通道的最大宽度或高度为约1μm,约5μm,约10μm,约20μm,约30μm,约40μm,约50μm,约60μm,约70μm,约80μm,约90μm,约100μm,约250μm,约500μm或约1000μm。
[0241]
在一些实施方式中,每个通道的宽度范围为约5μm至约100μm。在一些实施方式中,通道的宽度为约5μm,约10μm,约15μm,约20μm,约25μm,约30μm,约35μm,约40μm,约45μm,约50μm,约60μm,约70μm,约80μm,约90μm,或约100μm。
[0242]
在一些实施方式中,每个通道的高度范围为约10μm至约1000μm。在一些实施方式中,通道的高度为约10μm,约100μm,约250μm,约400μm,约500μm,约600μm,约750μm或约1000μm。在特定实施方式中,样品流过的通道的高度为约500μm。在特定实施方式中,样品流过的
通道的高度为约500μm。
[0243]
在一些实施方式中,每个通道的长度范围为约100μm至约10cm。在一些实施方式中,通道的长度为约100μm,约1.0mm,约10mm,约100mm,约500mm,约600mm,约700mm,约800mm,约900mm,约1.0em,约1.1cm,约1.2cm,约1.3cm,约1.4cm,约1.5cm,约5cm,或约10cm。在特定实施方式中,样品流过的通道的长度为约1.0cm。在特定实施方式中,样品流过的通道的长度为约1.0cm。
[0244]
生物分子冠纳米系统
[0245]
本发明提供了生物分子冠纳米系统或传感器阵列,其包括多个传感器元件,基本上由多个传感器元件组成或由多个传感器元件组成,其中所述多个传感器元件在至少一种物理化学特性方面彼此不同。在一些实施方式中,多个传感器元件是多个纳米颗粒。在一些实施方式中,多个纳米颗粒是多个脂质体。在一些实施方式中,每个传感器元件能够结合复杂生物样品中的多个生物分子以产生生物分子冠特征。在一些实施方式中,每个传感器元件具有不同的生物分子冠特征。
[0246]
生物分子冠特征是指与各单独传感器元件或各纳米颗粒结合的不同生物分子的组成,特征或模式。在某些情况下,生物分子冠特征是蛋白质冠特征。在其他情况下,生物分子冠特征是多糖冠特征。在其他情况下,生物分子冠特征是代谢物冠特征。在某些情况下,生物分子冠特征是脂质组学冠特征。该特征不仅指不同的生物分子,还指与传感器元件或纳米颗粒结合的生物分子的量、水平或数量的差异,或者与传感器元件或纳米颗粒结合的生物分子的构象状态的差异。设想每个传感器元件的生物分子冠特征可以包含一些相同的生物分子,可以包含与其他传感器元件或纳米颗粒的不同生物分子,和/或可以在生物分子的水平或数量,类型或确认方面不同。生物分子冠特征不仅可取决于传感器元件或纳米颗粒的物理化学性质,还可取决于样品的性质和暴露的持续时间。在一些实施方式中,生物分子冠特征包括在软冠和硬冠中存在的生物分子。
[0247]
在一些实施例中,传感器阵列包括第一传感器元件和至少一个第二传感器元件或至少一个纳米颗粒,基本上由其组成或由其组成,第一传感器元件产生第一生物分子冠特征,并且第二传感器元件或纳米颗粒在传感器阵列与复杂生物样品接触时产生至少一个第二生物分子冠特征。生物分子指纹是第一生物分子特征和至少一个第二生物分子特征的组合。设想生物分子特征可以由至少两种生物分子冠特征至针对测定的不同生物分子特征数量的生物分子冠特征(例如,至少1000种不同的生物分子冠特征)形成。可以针对每个传感器元件分开测定生物分子冠,以确定每个元件每个纳米颗粒或每个脂质体的生物分子冠特征并组合以确定生物分子指纹,或者可以同时测定两个或更多个生物分子冠以立即开发生物分子指纹。
[0248]
生物分子指纹可以区分对象的不同可能生物状态(例如,疾病状态)。在一些实施方式中,生物分子指纹与疾病或病症的发展相关和/或能够与对象的疾病状态相关。
[0249]
在一些实施方式中,生物分子指纹能够确定对象的疾病状态。如本文所用的术语“疾病状态”是指本技术的传感器阵列能够区分对象内疾病的不同状态的能力。该术语包括疾病或病症的疾病前状态或前兆状态(对象可能没有任何疾病或病症的外部体征或症状但将来会发展疾病或病症的状态)和患有一定阶段(例如,疾病或病症的早期,中期或晚期)的疾病或病症的对象的疾病状态。换句话说,疾病状态是包括关于对象关于疾病或病症的健
康的连续过程的谱。本发明的阵列能够通过确定生物分子指纹来区分对象的不同疾病状态,所述生物分子指纹可以与与谱上的不同疾病状态和健康对象相关的不同生物分子指纹进行比较。在另一个示例中,生物分子指纹可以与疾病前状态或前驱疾病状态相关联,其中对象当时看起来是健康的,没有疾病的外在迹象或症状,但将来会发展疾病。在另一个示例中,生物分子指纹可以指示对象患有疾病,并且能够通过与每个阶段相关联的独特生物分子指纹来区分疾病是处于早期,中期还是晚期。
[0250]
如上所述,疾病状态还包括疾病或病症的前兆状态。该前兆状态是对象没有任何疾病或病症的外在迹象或症状的状态(尽管在他们的血液或其他生物体液中发现的对象的生物分子内可能存在亚微观变化)但是未来会发展该疾病或病症。该前兆状态也可以描述为可以其中发现疾病的第一病理变化的状态,例如,来自患者的生物样品的生物分子指纹的变化。
[0251]
生物状态的另一个示例是健康的非疾病状态。该阵列还可以确定与健康的非疾病状态相关的特定生物分子指纹,其中对象将来不会发展该疾病。在这种情况下,对象在测试时没有证据表明他们患有该疾病或将来会发病。
[0252]
本文中术语“生物状态”包括对象的任何生物学特征,其可以在如本文定义的生物样品中表现出来。可以使用本文公开的方法检测生物状态,其中生物状态不同的两个对象表现出样品组成的差异。例如,生物状态包括对象的疾病状态。当疾病状态引起表达疾病状态的对象的样品的分子组成(例如,一种或多种蛋白质的水平)相对于没有疾病状态(即,生物状态是健康状态或非疾病状态)的对象的样品的变化时,可以检测到该疾病状态。
[0253]
生物状态的另一个例子是对象对特定治疗性治疗(例如,给予一种药物或药物组合)的响应性水平。在一些实施方式中,生物状态是对象对特定药物的响应性(例如,相对于特定的分析阈值)。在另一个实施方式中,生物状态是对象对特定药物的无响应性(例如,相对于特定的分析阈值)。在一些实施方式中,对象对药物的响应性水平(即,对药物的响应的生物状态或对药物的无响应性的生物状态)与诸如对象间药物的代谢或药物动力学变化的因素相关。
[0254]
生物状态的另一个示例是对象表现出的免疫应答水平。在一些实施方式中,生物状态可以是增强的免疫应答。在其他实施方式中,生物状态可以是降低的免疫应答。由于许多变量,对象之间的免疫应答可能不同。例如,由于对外源性引入的抗原(例如与病毒或细菌相关)的不同暴露,由于它们对自身免疫疾病或病症的易感性的差异,或者次要地由于对对象中其他生物状态(例如,癌症等疾病状态)的反应,对象之间的免疫应答可以不同。
[0255]
可以与生物分子指纹相关联的生物状态的其他示例包括对象对与给予药物相关的不利影响的灵敏度,以及对对象对给予给予特定组合物或物质的过敏反应的潜力的鉴定。
[0256]
该传感器阵列和相关方法的创新不同于当前检测或测量某些生物标志物的存在或不存在或水平的方法以在很早的时候,在可以监测到任何体征或症状之前预测对象是否可能具有发生疾病或病症的可能性或前兆。适当地,该阵列能够区分对象的健康与没有疾病或病症,具有疾病或病症的前兆,和患有疾病或病症。然而,本发明不限于这些实施方式,并且涵盖可能在对象的健康和疾病的连续期内发生的其他疾病状态的范围。
[0257]
此外,本发明的传感器阵列的创新可以通过以下实施例来说明。本发明的传感器
阵列非常灵敏,并且不仅能够检测样品中少量生物分子的变化,还能够检测生物分子之间的相互作用。例如,不受任何理论的束缚,但为了说明本传感阵列的独特性,描述一理论实例。例如,如果随时间(例如,在疾病的任何体征和症状之前,病前状态以及疾病的早期和中期阶段)从对象收集生物样品。在这些样品中,通过仅测量样品中生物分子x的水平(例如量的定量),可以发现浓度在不同疾病状态下并无改变。因此,测量生物分子x将不是疾病的有用标志物。然而,使用本发明的传感器阵列,尽管生物标志物x的水平可能会相同,但生物分子x与其他生物分子y和z的相互作用可能会随时间推移在多个样品中改变与样品相关的蛋白质冠特征的组成。例如,生物标志物x可以将其与生物分子y的关联变为与生物分子z的关联,或者随着时间的推移,x与y和z的相互作用导致x的构象变化。不会改变总体浓度但是会改变与疾病状态(包括生物分子x)相关的独特生物分子指纹的这种类型的变化将允许与其他疾病状态进行区分和关联。如果使用仅测量样品中生物分子x的定量的本领域方法,则不会发现这一点,因为该水平在整个疾病中保持相同。这是一种前所未见的意想不到的高度特异性和有用的分析方法。通过该测定,可以确定先前未被表征为生物标志物的疾病的生物标志物,包括生物标志物的模式,因为这些标志物在样品内的绝对量可能不会改变,但是对于与传感器阵列中的传感器元件的相互作用而言将具有一致且可测量的变化。通过分析生物分子冠来区分多种模式的能力允许将这些模式与不同疾病状态相关联的能力。
[0258]
如上所述,本传感器阵列具有检测超过十个数量级的蛋白质的能力,这比任何先前描述的方法具有更高的灵敏度。无论样品中的浓度水平如何,本发明的传感器阵列的独特性在于阵列检测蛋白质的能力。该测定依赖于样品中已知或未知的生物分子(例如蛋白质)与传感器元件相互作用,并且与不同的传感器元件以不同的量和不同的量相互作用并且还和与传感器元件相关的其他生物分子相互作用的能力。由此,即使在样品中存在高丰度蛋白质(例如白蛋白)的情况下也能够检测低丰度和稀有蛋白质。如实施例1的图12所示,已经显示了即使在高丰度蛋白质存在下,传感器阵列也能检测超过10个数量级的浓度的能力。此外,传感器阵列还能够检测具有未知/未报告的血浆浓度的蛋白质,这在先前的方法中尚未发现。本发明传感器阵列的一个独特特征是本发明的系统能够检测低丰度蛋白质和稀有蛋白质的能力。本发明的传感器阵列不仅可用于确定疾病状态(无疾病,疾病前,或早期和晚期疾病),而且在某些情况下可用于区分疾病的亚型(例如,区分不同类型的癌症,例如肺癌症,乳腺癌,骨髓瘤等)。
[0259]
检测方法
[0260]
本发明的传感器阵列可以用于本文描述的各种方法中。确定样品的独特生物分子指纹的能力提供了一种用于测量对象中的特定疾病状态的新颖且创新的方法。这些生物分子指纹可用于确定对象的疾病状态,对对象的疾病进行诊断或预后或鉴定与疾病状态或疾病或病症相关的生物标志物的独特模式。例如,对象中生物分子指纹随时间(天,月,年)的变化允许跟踪对象(例如疾病状态)中的疾病或病症的能力,其可广泛适用于确定可能与疾病的早期阶段或任何其他疾病状态有关的生物分子指纹。如上所述,即使在疾病完全发展或转移之前,早期检测疾病(例如癌症)的能力允许这些患者的阳性结果显著增加,并且能够增加预期寿命并降低与该疾病相关的死亡率。因此,本发明的传感器阵列提供了能够开发与疾病的前期或前兆状态相关的生物分子指纹的独特机会。
[0261]
应当理解,甚至在疾病进展为显示任何可测量的体征或症状之前,在宏观水平上,
在对象的身体和生物系统内也有变化发生。能够通过使用本发明的传感器阵列来识别这些早期疾病前兆征。发明人已经发现,通过在疾病状态的不同时间(例如在疾病已经表现出症状并发展之前,在疾病的早期体征或症状之后,和/或在疾病的晚期阶段)比较对象的生物分子指纹能够提供与疾病进展相关的不同疾病状态相关的独特生物分子指纹。换而言之,可以确定生物分子指纹,其将允许鉴定将在以后发展疾病的对象。这将允许早期监测和早期治疗,大大改善了被诊断患有该疾病的对象的结果。
[0262]
在一些实施方式中,提供了检测对象中的疾病或病症的方法。该方法包括以下步骤:(a)从对象获得样品;(b)使样品与如本文所述的传感器阵列接触,和(c)确定与样品相关的生物分子指纹,其中所述生物分子指纹就处于疾病状态而言的对象的健康状况,与例如,没有疾病或病症,患有疾病或病症的前兆,和患有疾病或病症相区分。
[0263]
确定与样品相关的生物分子指纹的步骤可包括检测至少两个传感器元件的生物分子冠特征,其中至少两个生物分子冠特征的组合产生生物分子指纹。在一些实施方式中,分别测定至少两个传感器元件的生物分子冠特征,并将结果组合以确定生物分子指纹。在一些实施方式中,至少两种元件的生物分子冠特征同时或在相同样品中测定。
[0264]
在一些实施方式中,确定生物分子指纹的方法包括检测和确定至少两个传感器元件的生物分子冠特征。在一些实施方式中,该步骤可以通过分离附着于每个传感器元件的多个生物分子(例如,将生物分子冠与传感器元件分离)并测定多个生物分子以确定多个生物分子冠状物的组成以确定生物分子指纹。取决于阵列的设计,在一些情况下,每个传感器元件的每个生物分子冠特征的组成被独立地测定,并且结果被组合以产生生物分子指纹(例如,每个传感器元件在单独的通道或隔室中,其中可以单独分析该特定传感器元件的生物分子冠的特定组成(例如,通过剥离生物分子并通过质谱法和/或色谱法分析或通过荧光,发光或其他方式检测仍附着于传感器元件的多个生物分子)。在另一个实施方式中,所述至少两个传感器元件在同一阵列上,并且通过将来自两个传感器元件的生物分子冠解离为一个溶液并且测定该溶液以确定生物分子特征来同时测定至少两个传感器元件的生物分子冠的组成。如果使用芯片阵列技术,该后述方法应该是首选方法。
[0265]
测定构成生物分子冠特征或生物分子指纹的多种生物分子的方法是本领域已知的,包括但不限于,例如,凝胶电泳,液相色谱,质谱,核磁共振光谱(nmr),傅里叶变换红外光谱(ftir),圆二色性,拉曼光谱法及其组合。在优选的实施方式中,该测定是通过液相色谱,质谱或其组合进行。
[0266]
在优选的实施方式中,传感器测定是非标记阵列。
[0267]
在一些实施方式中,设想可以使用标记的阵列,其中冠特征能够被确定为信号(例如荧光,发光,电荷,色度染料)的变化。合适的示例显示在图42和43中。例如,阵列可包括可印刷制剂中的化学响应性着色剂,用于基于与生物分子和响应性染料的平衡相互作用来检测和鉴定生物分子。
[0268]
在一些实施方式中,传感器元件包含具有第一组分和聚合物荧光团或与第一组分化学互补的其他猝灭剂组分的复合物,其中这种复合物具有初始背景或参考荧光。一旦第一组分与生物分子冠接触,它将影响荧光团的猝灭,并且可以测量荧光的这种变化。在用激光照射和/或激发传感器之后,可以测量每个传感器元件的荧光效果和/或变化,并与背景荧光进行比较以产生生物分子指纹。
[0269]
本文描述的传感器阵列和方法可用于确定疾病状态,和/或对疾病或病症进行诊断或预后。预期的疾病或病症包括但不限于例如癌症,心血管疾病,内分泌疾病,炎性疾病,神经疾病等。
[0270]
在一个实施方式中,疾病或病症是癌症。在合适的实施方式中,本文描述的传感器阵列和方法不仅能够诊断癌症(例如,确定对象(a)是否患有癌症,(b)是否处于癌症前发展阶段,(c)是否处于癌症的早期阶段,(d)是否处于癌症的晚期阶段)且在一些实施方式中还能够确定癌症的类型。如以下实施例中所示,包含六个传感器元件的传感器阵列能够准确地确定癌症存在与否的疾病状态。另外,实施例证明包含六个传感器元件的传感器阵列能够区分不同的癌症类型(例如肺癌,胶质母细胞瘤,脑膜瘤,骨髓瘤和胰腺癌)。
[0271]
本文中可互换使用的术语“癌症”和“肿瘤”意指包括以细胞异常生长为特征的任何癌症,肿瘤和肿瘤前疾病。例如,癌症可以选自肺癌,胰腺癌,骨髓瘤,骨髓性白血病,脑膜瘤,胶质母细胞瘤,乳腺癌,食道鳞状细胞癌,胃腺癌,前列腺癌,膀胱癌,卵巢癌,甲状腺癌,神经内分泌癌,结肠癌,卵巢癌,头颈癌,霍奇金病,非霍奇金淋巴瘤,直肠癌,尿癌,子宫癌,口腔癌,皮肤癌,胃癌,脑肿瘤,肝癌,喉癌,食管癌,乳腺肿瘤,纤维肉瘤,粘液肉瘤,脂肪肉瘤,软骨肉瘤,成骨肉瘤,脊索瘤,血管肉瘤,内皮肉瘤,尤文氏肉瘤,鳞状细胞癌,基材细胞癌,腺癌,汗腺癌,皮脂腺癌,乳头状癌,乳头状腺癌,囊腺癌,髓样癌,支气管肺癌,肾细胞癌,肝癌,胆管癌瘤,绒毛膜癌,精原细胞瘤,胚胎癌,肾母细胞瘤,宫颈癌,睾丸肿瘤,子宫内膜癌,肺癌,小细胞肺癌,膀胱癌,上皮癌,胶质母细胞瘤,神经瘤,颅咽管瘤,神经鞘瘤,神经胶质瘤,星形细胞瘤,脑膜瘤,黑色素瘤,神经母细胞瘤,视网膜母细胞瘤,白血病和淋巴瘤,急性淋巴细胞白血病和急性髓细胞性真性红细胞增多症,多发性骨髓瘤,瓦尔登斯特伦巨球蛋白血症和重链疾病,急性非淋巴细胞白血病,慢性淋巴细胞白血病,慢性粒细胞白血病,儿童无效急性淋巴细胞白血病(all),胸腺all,b细胞all,急性巨核细胞白血病,伯基特淋巴瘤和t细胞白血病,小细胞和大细胞非小细胞肺癌,急性粒细胞白血病,生殖细胞肿瘤,子宫内膜癌,胃癌,毛细胞白血病,甲状腺癌和本领域已知的其他癌症。在优选的实施方式中,癌症选自肺癌,胰腺癌,骨髓瘤,骨髓性白血病,脑膜瘤,胶质母细胞瘤,乳腺癌,食道鳞状细胞癌,胃腺癌,前列腺癌,膀胱癌,卵巢癌,甲状腺癌,和神经内分泌癌。
[0272]
如本文所用,术语“心血管疾病”(cvd)或“心血管疾病”用于分类影响身体的心脏,心脏瓣膜和脉管系统(例如,静脉和动脉)的许多病症,并且其所涵盖的疾病和病症,包括,但不限于动脉粥样硬化,心肌梗塞,急性冠状动脉综合征,心绞痛,充血性心力衰竭,主动脉瘤,主动脉夹层,髂动脉或股动脉瘤,肺栓塞,心房颤动,中风,短暂性脑缺血发作,收缩功能障碍,舒张功能障碍,心肌炎,房性心动过速,心室颤动,心内膜炎,外周血管疾病和冠状动脉疾病(cad)。此外,术语心血管疾病是指最终具有心血管事件或心血管并发症的对象,指心血管疾病引起的对象的不良状况的表现,例如心源性猝死或急性冠状动脉综合征,包括但不是仅限于,心肌梗死,不稳定性心绞痛,动脉瘤,中风,心力衰竭,非致命性心肌梗死,中风,心绞痛,短暂性脑缺血发作,主动脉瘤,主动脉夹层,心肌病,异常心导管术,异常心脏成像,支架或移植物血运重建,经历异常应激试验的风险,经历心肌灌注异常的风险,和死亡。
[0273]
如本文所用,检测,诊断或预后心血管疾病(例如,动脉粥样硬化)的能力可包括确定患者是否处于心血管疾病的前期(pre-stage),是否已发展为心血管疾病的早期,中度或严重形式,或者是否具有一种或多种心血管事件或与心血管疾病相关的并发症。
[0274]
动脉粥样硬化(也称为动脉硬化性血管疾病或asvd)是一种心血管疾病,其中动脉壁由于侵入和积聚以及在动脉壁的最内层含有白细胞的动脉斑块的沉积而变厚,导致动脉变窄和硬化。动脉斑块是巨噬细胞或碎片的积累,含有脂质(胆固醇和脂肪酸),钙和不同量的纤维结缔组织。与动脉粥样硬化相关的疾病包括但不限于动脉粥样硬化血栓形成,冠心病,深静脉血栓形成,颈动脉疾病,心绞痛,外周动脉疾病,慢性肾病,急性冠状动脉综合征,血管狭窄,心肌梗塞,动脉瘤或中风。
[0275]
出于说明性目的,在一个实施方式中,传感器阵列可以区分动脉粥样硬化的不同阶段,包括但不限于对象中的不同程度的狭窄。
[0276]
此外,仅出于说明性目的,以下实施例证明了使用传感器阵列来检测冠状动脉疾病的不同状态。包含六个传感器元件的传感器阵列能够区分冠状动脉造影诊断的cad患者,具有健康冠状血管症状的患者(无cad),再狭窄患者(治疗后复发cad)和没有危险因素的健康对象(图53)。本发明的传感器阵列足够灵敏,可以检测具有冠状动脉疾病症状但没有动脉狭窄的人之间的差异(例如无cad与cad组)。这提供了一种新颖的诊断性cad测试,可用作风险患者的非侵入性筛查。
[0277]
术语“内分泌疾病”用于指与对象的内分泌系统失调相关的病症。内分泌疾病可能是由于腺体产生过多或过少的内分泌激素导致荷尔蒙失调,或由于内分泌系统中病变(如结节或肿瘤)的发展,这可能会或可能不会影响激素水平。能够治疗的合适内分泌疾病包括但不限于例如肢端肥大症,艾迪生病,肾上腺癌,肾上腺疾病,甲状腺未透化癌,库欣综合征,亚急性甲状腺炎,糖尿病,滤泡性甲状腺癌,妊娠糖尿病,甲状腺肿大,甲状腺机能亢进,生长障碍,生长激素缺乏,桥本氏甲状腺炎,许特耳氏细胞甲状腺癌,高血糖症,甲状旁腺功能亢进症,甲亢,低血糖症,甲状旁腺功能减退症,甲状腺功能减退症,低睾酮,甲状腺髓样癌,men 1,men 2a,men 2b,更年期,代谢综合症,肥胖症,骨质疏松症,乳头状甲状腺癌,甲状旁腺疾病,嗜铬细胞瘤,垂体疾病,垂体瘤,多囊卵巢综合症,前驱糖尿病,无症状性甲状腺炎(silent thyroiditis),甲状腺癌,甲状腺疾病,甲状腺结节,甲状腺炎,特纳综合征,1型糖尿病,2型糖尿病等。
[0278]
如本文所提及的,炎性疾病是指由对象体内不受控制的炎症引起的疾病。炎症是对象对有害刺激的生物反应,所述有害刺激可能是外部或内部的,如病原体,坏死细胞和组织,刺激物等。但是,当炎症反应变得异常时,它会导致自身组织损伤并可能导致各种疾病和病症。炎性疾病可包括但不限于哮喘,肾小球肾炎,炎性肠病,类风湿性关节炎,过敏症,盆腔炎性疾病,自身免疫疾病,关节炎;坏死性小肠结肠炎(nec),肠胃炎,盆腔炎(pid),肺气肿,胸膜炎,肾盂炎,咽炎,心绞痛,寻常痤疮,尿路感染,阑尾炎,滑囊炎,结肠炎,膀胱炎,皮炎,静脉炎,鼻炎,肌腱炎,扁桃体炎,血管炎,自身免疫性疾病,乳糜泻,慢性前列腺炎,过敏,再灌注损伤,结节病,移植排斥,血管炎,间质性膀胱炎,枯草热,牙周炎,动脉粥样硬化,牛皮癣,强直性脊柱炎,青少年特发性关节炎,白塞病,脊柱关节炎,葡萄膜炎,系统性红斑狼疮和癌症。例如,关节炎包括类风湿性关节炎,银屑病关节炎,骨关节炎或幼年特发性关节炎等。
[0279]
神经病症或神经疾病可互换使用,指的是大脑,脊柱和连接它们的神经的疾病。神经疾病包括但不限于脑瘤,癫痫,帕金森病,阿尔茨海默病,肌萎缩侧索硬化症,动静脉畸形,脑血管疾病,脑动脉瘤,癫痫,多发性硬化,外周神经病,疱疹后神经痛,中风,额颞叶痴
呆,脱髓鞘疾病(包括但不限于多发性硬化症,德维克病(devic’s disease)(即视神经脊髓炎),脑桥中央髓鞘溶解,进行性多灶性白质脑病,脑白质营养不良,格林-巴利综合征,进展性炎性神经病,腓骨肌萎缩症,慢性炎性脱髓鞘多发性神经病和抗mag外周神经病变)等。神经障碍还包括免疫介导的神经障碍(imnd),其包括具有免疫系统的至少一种成分的疾病,该免疫系统与存在于中枢或外周神经系统中的宿主蛋白反应并且有助于疾病病理学。imnd可包括但不限于脱髓鞘疾病,副肿瘤性神经综合征,免疫介导的脑脊髓炎,免疫介导的自主神经病,重症肌无力,自身抗体相关性脑病和急性播散性脑脊髓炎。
[0280]
在非限制性示例中,以下实施例提供了使用本文所述的传感器阵列和方法诊断患者的阿尔茨海默病的方法。传感器阵列不仅能够准确地区分患有或不患有阿尔茨海默病的患者,而且还能够检测出筛选后数年(通过群组血浆确定)处于症状发生前和发展阿尔茨海默病的患者。这提供了在疾病发展之前能够在非常早期阶段治疗疾病的优点。
[0281]
在一些实施方式中,本发明的传感器阵列和方法能够检测疾病或病症的疾病前阶段。疾病前阶段是患者未出现任何疾病迹象或症状的阶段。癌前阶段将是在对象体内还未发现癌症或肿瘤或癌细胞的阶段。神经前疾病阶段是一个人没有出现一种或多种神经疾病症状的阶段。在疾病的一种或多种体征或症状出现之前诊断疾病的能力允许密切监测对象和在非常早期阶段治疗疾病的能力,增加了能够阻止进展的前景,或减少疾病的严重程度。
[0282]
在一些实施方式中,本发明的传感器阵列和方法能够检测疾病或病症的早期阶段。疾病的早期阶段是指疾病的最初体征或症状可能在对象体内出现的时间。通常,能够在疾病发展前或早期阶段中捕获的疾病更容易治疗并且为患者提供更积极的结果。例如,对于癌症,疾病的早期阶段可包括0期和1期癌症。0期癌症描述原位癌症,这意味着表示癌症仍位于其开始的位置并且尚未扩散到附近的组织的“处于原位(in place)”。癌症的这个阶段通常是高度可治愈的,通常通过手术切除整个肿瘤。1期癌症通常是一种小癌症或肿瘤,其未深入到附近组织中并且未扩散到淋巴结或身体的其他部位。此外,疾病的早期阶段可以是没有外在迹象或症状的阶段。例如,在阿尔茨海默病中,早期阶段可能是阿尔茨海默症前阶段,其中没有检测到症状,但患者将在数月或数年后患上阿尔茨海默症。
[0283]
在一些实施方式中,传感器阵列和方法能够检测疾病的中间阶段。疾病的中间状态描述了已经通过第一体征和症状并且患者正经历疾病的一种或多种症状的疾病的阶段。例如,对于癌症,ii期或iii期癌症被认为是中间阶段,表明更大的癌症或肿瘤已经更深地生长到附近的组织中。在某些情况下,ii期或iii期癌症也可能扩散到淋巴结,但不扩散到身体的其他部位。
[0284]
此外,传感器阵列和方法能够检测疾病的后期或晚期。疾病的后期或晚期也可称为“严重”或“晚期”,并且通常表明对象患有该疾病的多种症状和影响。例如,严重阶段性癌症包括iv期,其中癌症已经扩散到身体的其他器官或部分,并且有时被称为晚期或转移性癌症。
[0285]
在一些实施方式中,本发明技术的方法包括将样品的蛋白质指纹与一组与多种疾病和/或多种疾病状态相关的蛋白质指纹进行比较,以确定样品是否指示疾病和/或疾病状态。例如,可以随时间从一群对象收集样品。一旦对象发展疾病或病症,本发明通过比较来自在其发病之前的相同对象的样品的生物分子指纹与对象发病后的生物分子指纹,允许表征和检测对象中生物分子指纹随时间的变化的能力。在一些实施方式中,样品可以取自全
部患有相同疾病的患者群,允许分析和表征与这些患者的疾病的不同阶段相关的生物分子指纹(例如,从疾病前到疾病状态)。
[0286]
仅出于说明性目的,实施例已经显示本发明的方法和传感器阵列不仅能够区分不同类型的癌症,而且能够区分癌症的不同阶段(例如癌症的早期阶段)。
[0287]
考虑了确定与至少一种疾病或病症和/或疾病状态相关的生物分子指纹的方法。该方法包括以下步骤:从诊断患有至少一种疾病或病症或具有相同疾病状态的至少两个对象获得样品;使每个样品与本文所述的传感器阵列接触以确定每个传感器阵列的生物分子指纹,并分析所述至少两个样品的指纹以确定与所述至少一种疾病或病症和/或疾病状态相关的生物分子指纹。
[0288]
生物分子冠的分类
[0289]
确定与疾病或病症和/或疾病状态相关的生物分子指纹的方法包括分析至少两个样品的生物分子指纹。该确定,分析或统计分类通过本领域已知的方法完成,包括但不限于,例如,各种有监督式和无监督式的数据分析,机器学习,深度学习和包括分层聚类分析的聚类方法(hca),主成分分析(pca),偏最小二乘判别分析(pls-da),随机森林,逻辑回归,决策树,支持向量机(svm),k近邻,朴素贝叶斯,线性回归,多项式回归,svm用于回归,k均值聚类和隐马尔可夫模型等。换句话说,将每个样品的生物分子指纹彼此进行比较/分析,以考虑统计学意义的方式确定各个指纹之间有共同模式,以确定与疾病或病症或疾病状态相关的生物分子指纹。
[0290]
通常,机器学习算法用于构建模型,该模型基于描述示例的输入特征准确地将类标记分配给示例。在某些情况下,对本文所述的方法采用机器学习和/或深度学习方法可能是有利的。例如,机器学习可用于将生物分子指纹与各种疾病状态相关联(例如,没有疾病,疾病的前兆,疾病的早期或晚期等)。例如,在一些情况下,结合本发明的方法使用一种或多种机器学习算法来分析由生物分子冠和由其衍生的生物分子指纹检测和获得的数据。例如,在一个实施方式中,机器学习可以与本文描述的传感器阵列耦合,以不仅确定对象是否具有癌症前阶段,癌症或不具有或发展癌症,而且还用于区分癌症的类型。
[0291]
以下实施例已经显示了本文所述的传感器阵列能够以具有统计学意义的方式确定多种不同疾病的疾病状态的能力,所述疾病包括癌症,心血管疾病和神经疾病(例如阿尔茨海默病)。该测定不限于这些具体实施方式,因为传感器阵列可以应用于如本文所述的多种疾病和疾病状态。
[0292]
在一些实施方式中,该方法包括从与传感器阵列接触的对照对象获得样品以产生对照生物分子指纹。然后可以使用这些对照生物分子指纹与具有疾病或病症和/或特定疾病状态的对象的生物分子指纹进行比较,以确定对该疾病或病症和/或特定疾病状态具有特异性的生物分子指纹。
[0293]
该方法可包括,例如,从至少一个对照对象获得对照样品,使对照样品与传感器阵列接触以产生多个对照生物分子冠,并测定每个对照生物分子冠的多个生物分子。该方法可以进一步包括将多个对照生物分子冠的多个生物分子与来自患有疾病或病症的对象的多个生物分子冠的多个生物分子进行比较,以确定与至少一种疾病或病症相关的生物分子指纹。
[0294]
还考虑了对疾病或病症进行诊断或预测的方法。该方法包括从对象获得样品;使
样品与传感器阵列接触以产生生物分子指纹,并将生物分子指纹与一组与多种疾病或病症相关的生物分子指纹进行比较;并对所述疾病或病症进行诊断或预测。
[0295]
在一些实施方式中,考虑了鉴定与疾病或病症相关的生物标志物或特定生物标志物的模式的方法。合适的方法包括,例如,进行上述方法(例如,从诊断患有疾病或病症的至少两个对象和至少两个对照对象获得样品;使每个样品与传感器阵列接触以产生生物分子指纹,和将患有疾病或病症的对象的生物分子指纹与对照对象的生物分子指纹进行比较,以确定与疾病或病症相关的至少一种模式和/或生物标志物。合适的,该方法可包括至少2个疾病对象和至少两个对照对象,或者至少5个疾病对象和至少5个对照对象,或者至少10个疾病对象和至少10个对照对象,或者至少15个疾病对象和至少15个对照对象,或者至少20个疾病对象和至少20个对照对象,并且包括其间的任何变化(例如,至少2-100个疾病对象,和至少2-100个对照对象)。
[0296]
在一些实施方式中,阵列和方法允许确定与疾病状态或疾病或病症相关的生物标志物的模式,或者在一些实施方式中,确定与疾病或病症相关的特定生物标志物。不仅能够鉴定可能与疾病状态相关的生物标志物,例如,本文列出的生物标志物,而且可以确定可能与疾病状态或疾病或病症相关的新的生物标志物或生物标志物的模式。如上所述,特定疾病或病症的一些生物标志物或生物标志物的模式可以是与本发明的传感器阵列相关的生物分子的变化,并且不同于本领域通常称为生物标志物的生物标志物,例如,并且增加与疾病相关的特定生物分子的表达。如上所述,它可以是生物分子的相互作用,例如,生物分子x,与其他生物分子,例如,生物分子y和z,其产生与特定疾病状态相关联的能力,并且可能与样品中生物标志物x的绝对浓度随时间或疾病状态的任何变化无关。因此,在传统意义上由于其在样品中的绝对浓度不会在疾病前到疾病状态的过程中变化而不会被认为是生物标志物的分子,可能在本公开中被视为生物分子,因为通过本发明的阵列测量的其相对变化与疾病状态有关。换句话说,它可能是生物分子x与提供生物标志物与疾病相关的信号的阵列的相互作用的增加或减少(由于x与样品中的传感器元件和其他生物分子的相互作用)。
[0297]
合适的癌症生物标志物包括但不限于,例如ahsg(α2-hs-糖蛋白),akr7a2(黄曲霉毒素b1醛还原酶),akt3(pkbγ),asgr1(asgpr1),bdnf,bmp1(bmp-1),bmper,c9,ca6(碳酸酐酶vi),capg(capg),cdh1(钙粘蛋白-1),chrdl1(腱蛋白-样1),ckb-ckm-(ck-mb),clic1(氯化物细胞内通道1),cma1(胃促胰酶),cntn1(接触素-1),col18a1(内皮抑素),crp,ctsl2(组织蛋白酶v),ddc(多巴脱羧酶),egfr(erbb1),fga-fgb-fgg(d-二聚体),fn1(纤连蛋白fn1.4),ghr(生长激素受体),gpi(葡萄糖磷酸异构酶),hmgb1(hmg-1),hnrnpab(hnrnp a/b),hp(触珠蛋白,混合型),hsp90aa1(hsp90α),hspa1a(hsp 70),igfbp2(igfbp-2),igfbp4(igfbp-4),il12b-il23a(il-23),itih4(间-α-胰蛋白酶抑制剂重链h4),kit(scf sr),klk3-serpina3(psa-act),l1cam(ncam-l1),lrig3,mmp12(mmp-12),mmp7(mmp-7),nme2(ndp激酶b),pa2g4(erbb3结合蛋白ebp1),pla2g7(lppla2/pafah),plaur(supar),prkaca(prka c-α),prkcb(pkc-β-ii),prok1(eg-vegf),prss2(胰蛋白酶-2),ptn(多效生长因子),serpina1(α1-抗胰蛋白酶),stc1(斯钙素-1),stx1a(突触融合蛋白1a),tacstd2(ga733-1蛋白),tff3(三叶因子3),tgfbi(βigh3),tpi1(磷酸丙糖异构酶),tpt1(翻译控制肿瘤蛋白(fortilin)),ywhag(14-3-3蛋白γ),ywhah(14-3-3蛋白质η),前列腺癌生物标志
物,例如,psa,pro-psa,phi,pca3,tmprss3:erg,pcmt,mten,乳腺癌标志物,例如,表皮生长因子受体2(her2)致癌基因,黑素瘤生物标志物braf,肺癌生物标志物eml4-alk,a2ml1,bax,c10orf47,c1orf162,csda,eifc3,etfb,gabarapl2,guk1,gzmh,hist1h3b,hla-a,hsp90aa1,nrgn,prdx5,ptma,rabac1,rabagap1l,rpl22,sap 18,sepw1,sox1,egfr,egfrviii,载脂蛋白ai,载脂蛋白ciii,肌红蛋白,肌腱蛋白c,msh6,密蛋白-3,密蛋白-4,窖蛋白-1,凝血因子iii,cd9,cd36,cd37,cd53,cd63,cd81,cd136,cd147,hsp70,hsp90,rabl3,桥粒糖蛋白-1,emp-2,ck7,ck20,gcdf15,cd82,rab-5b,膜联蛋白v,mfg-e8,hla-dr,mir200微小rna,mdc,nme-2,kgf,pigf,flt-3l,hgf,mcp1,sat-1,mip-1-b,gclm,opg,tnf rii,vegf-d,itac,mmp-10,gpi,ppp2r4,akr1b1,amy1a,mip-1b,p-钙粘着蛋白,epo等。例如,乳腺癌的生物标志物包括但不限于er/pr,her-2/neu等。结直肠癌的生物标志物包括但不限于例如egfr,kras,ugt1a1等。与白血病/淋巴瘤相关的生物标志物包括但不限于,例如cd20抗原,cd30,fip1l1-pdgfrα,pdgfr,费城染色体(bcr/abl),pml/rarα,tpmt,ugt1a1等。与肺癌相关的生物标志物包括但不限于例如alk,egfr,kras等。生物标志物是本领域已知的,并且可以在以下中找到,例如bigbee w,herberman rb.肿瘤标志物和免疫诊断(tumor markers and immunodiagnosis).刊于:bast rc jr.,kufe dw,pollock re等编.《癌症医学》(cancer medicine).第6版.hamilton,ontario,加拿大:bc decker公司,2003;andriole g,crawford e,grubb r,等,来自随机前列腺癌筛查试验的死亡率(mortality results from a randomized prostate-cancer screening trial).new england journal of medicine 2009;360(13):1310-1319; fh,hugosson j,roobol mj,等,欧洲随机研究中的筛查和前列腺癌死亡率(screening and prostate-cancer mortality in a randomized european study).new england journal of medicine 2009;360(13):1320-1328;buys ss,partridge e,black a,等,筛查对卵巢癌死亡率的影响:前列腺癌,肺癌,结肠直肠癌和卵巢癌(plco)癌症筛查随机对照试验(effect of screening on ovarian cancer mortality:the prostate,lung,colorectal and ovarian(plco)cancer screening randomized controlled trial).jama 2011;305(22):2295-2303;cramer dw,bast rc jr,berg cd,等,卵巢癌生物标志物在前列腺癌,肺癌,结直肠癌和卵巢癌筛查试验标本中的表现(ovarian cancer biomarker performance in prostate,lung,colorectal,and ovarian cancer screening trial specimens).cancer prevention research 2011;4(3):365-374;sparano ja,gray rj,makower df,等,乳腺癌中21基因表达分析的前瞻性验证(prospective validation of a 21-gene expression assay in breast cancer).new england journal of medicine 2015;2015年9月28日首次在线发表.doi:10.1056/nejmoa1510764,其通过引用全文纳入本文。
[0298]
合适地,这些方法可用于确定与癌症相关的生物标志物。例如,在一个实施方式中,癌症是胶质母细胞瘤,并且其中生物标志物选自habp1,vtnc,co3,itih2,itih1,co7,fhr5,cbpn,albu,plmn,co4a,prdx2,vwf,c4bpa,apob,hbb,cndp1,crp,saa4,apoe,cscl7及其组合。在另一个实施方式中,癌症是脑膜瘤,并且其中生物标志物选自fcn3,ret4,habp2,cbpn及其组合。在另一个实施方式中,癌症是胰腺癌,并且其中生物标志物选自kng1,ic1,cbpb2,trfe,gels,cxcl7,hptr,pgk1,aact,lum,apoe,fibb,apoa2,a1bg,a1at,lbp,apoa1,h4,fibg及其组合在另一个实施方式中,癌症是肺癌,并且生物标志物选自co0,crp,saa4,
apoa1,a1at,gels及其组合。在另一个实施方式中,癌症是骨髓瘤,并且生物标志物是albu。
[0299]
生物标志物还可以与心血管疾病相关,其在本领域中已知,并且包括但不限于脂质概况,葡萄糖和激素水平以及基于测量重要生物分子水平的生理学生物标志物,例如血清铁蛋白,甘油三酯与hdlp(高密度脂蛋白)比率,脂蛋白胆固醇比率,脂质-脂蛋白比率,ldl胆固醇水平,hdlp和载脂蛋白水平,脂蛋白和ltp比率,鞘脂,ω-3指数和st2水平等。适用于心血管疾病的生物标志物可以在本领域中找到,例如但不限于van holten等,“用于预测心血管疾病风险的循环生物标志物;系统评价和meta分析的综合概述(ciculating biomarkers for predicting cardiovascular disease risk;a systemic review and comprehensive overview of meta-analyses)”plos one,20138(4):e62080,通过引用全文纳入。
[0300]
生物标志物也可能与神经疾病有关。合适的生物标志物是本领域已知的,并且包括但不限于例如,aβ1-42,t-tau和p-tau181,α-突触核蛋白等。参见,例如,chintamaneni和bhaskar“阿尔茨海默病中的生物标志物:综述(biomarkers in alzheimer
′
s disease:a review)”isrn pharmacol.2012.2012:984786.2012年6月28日在线发表,通过引用全文纳入。
[0301]
炎性疾病的生物标志物是本领域已知的,包括但不限于例如,细胞因子/趋化因子,免疫相关效应物,急性期蛋白[c-反应蛋白(crp)和血清淀粉样蛋白a(saa)],活性氧(ros)和活性氮物质(rns),前列腺素和环加氧酶(cox)相关因子,以及转录因子和生长因子等介质,可包括例如c-反应蛋白(crp),s100,lif,cxcl1,cxcl2,cxcl4,cxcl5,cxcl8,cxcl9,cxcl10,ccl2,ccl23,il-1β,il-1ra,tnf,il-6,il-10,il-17a,il-17f,il-21,il-22,ifnγ,cxcr1,cxcr4,cxcr5,gm-csf,gm-csfr,g-csf,g-csfr,egf,vegfa,lep,saa1,vcam1,crp,mmp1,mmp3,tnfrsf1a,retn,chi3l1,抗核抗体(ana),类风湿因子(rf),抗环瓜氨酸肽(抗ccp)抗体]和慢性ibd(粪钙卫蛋白)等。例如,炎性肠病的合适生物标志物包括crp,esr,panca,asca和粪钙卫蛋白。参见,例如,yi fengming和wu jianbing,“炎性肠病的生物标志物(biomarkers of inflammatory bowel disease)”,《疾病标志物》(disease markers),第一卷,2014,article id 710915,11页,2014.doi:10.1155/2014/710915,其全部内容通过引用纳入本文。
[0302]
术语“个体”,“对象”和“患者”在本文中可互换使用,而不管对象是否已经或正在进行任何形式的治疗。如本文所用,术语“对象”通常是指任何脊椎动物,包括但不限于哺乳动物。哺乳动物的示例包括灵长类动物,包括猿猴和人类,马(例如马),犬(例如狗),猫科动物,各种驯养牲畜(例如,有蹄类动物,例如猪,猪,山羊,绵羊等),以及驯养的宠物(例如,猫,仓鼠,小鼠和豚鼠)。优选地,对象是人。
[0303]
本文所述的阵列和方法可在许多不同条件下使用,以提供所需的生物分子指纹。例如,传感器元件的尺寸,样品通过传感器的流速,传感器阵列与样品一起孵育的时间以及传感器阵列孵育的温度都可以改变,以提供可再现的生物分子指纹。传感器元件的合适尺寸包括在至少一个方向上小于1微米的纳米级传感器元件。
[0304]
孵育阵列或多个传感器元件的合适时间包括,例如,至少几秒钟,例如,至少10秒至约24小时,例如至少约10秒,至少约15秒,至少约20秒,至少约25秒,至少约30秒,至少约40秒,至少约50秒,至少约60秒,至少约90秒,至少约2分钟,至少约3分钟,至少约4分钟,至
少约5分钟,至少约6分钟,至少约7分钟,至少约8分钟,至少约9分钟,至少约10分钟,至少约15分钟,至少约20分钟,至少约25分钟,至少约30分钟,至少约45分钟,至少约50分钟,至少约60分钟,至少约90分钟,至少约2小时,至少约3小时,至少约4小时,至少约5小时,至少约6小时,至少约7小时,至少约8小时,至少约9小时,至少约10小时,至少约12小时,至少约14小时,至少约15小时,至少约16小时,至少约17小时,至少约18小时,至少约19小时,至少约20小时,并且包括其间的任何时间和增量(例如,10秒,11、12、13、14、15、15、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52、53、54、55、56、57、58、59、60秒等;1分钟,2、3、4、5、6、7、9、10、11、12、13、14、15、15、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52、53、54、55、56、57、58、59、60等;1小时,2小时,3小时,4小时,5小时,6小时,7小时,8小时等)
[0305]
此外,进行测定的温度可以由本领域技术人员确定,并且包括约4℃至约40℃,或者约4℃至约20℃,或者约10℃至约15℃,或者约10℃至约40℃,例如,约4℃,约5℃,约6℃,约7℃,约8℃,约9℃,约10℃,约11℃,约12℃,约13℃,约14℃,约15℃,约16℃,约17℃,约18℃,约19℃,约20℃,约21℃,约22℃,约25℃,约30℃,约35℃,约37℃等的温度。适合地,该测定可在室温下进行(例如约37℃,例如约35℃至约40℃)。
[0306]
本发明的方法可包括使样品与传感器阵列接触。样品与传感器阵列的接触可以使用允许样品在传感器阵列上流动的任何合适的流速。在一些方面,可以改变流的流速,雷诺数或流动流的相对横截面积,以在样品和传感器阵列之间提供足够的接触。
[0307]
例如,在使用纳米通道或微通道的实施方式中,第一流的横截面积可以大于通道横截面积的1%。在另一个示例中,第一流的横截面积可小于通道横截面积的90%。横截面积比可以是10∶1至1∶10,1∶5至5∶1,1∶3至3∶1,1∶2至2∶1或1∶1。
[0308]
在某些其他情况下,样品在阵列上的流动在样品引入位置处具有300和1,000,000之间的雷诺数。在一些情况下,样品引入的位置是纳米通道或微通道。
[0309]
试剂盒
[0310]
关于方法描述的本公开的各方面可以在本公开中讨论的传感器阵列或试剂盒的背景下使用。类似地,可以在试剂盒的背景下利用关于传感器阵列和方法描述的本公开的方面,并且可以在方法和传感器阵列的背景下利用关于试剂盒描述的本公开的方面。
[0311]
本公开提供了试剂盒。该试剂盒可适用于本文所述的方法。合适的试剂盒包括用于确定样品的生物分子指纹的试剂盒,其包含如本文所述的传感器阵列。在一个方面,该试剂盒提供了一种传感器阵列,其包括至少两个传感器元件,这些传感器元件具有彼此不同的物理化学性质。在一些方面,试剂盒提供生物分子指纹的比较组,以便使用生物分子指纹来确定对象的疾病状态。在一些方面,包括关于如何确定生物分子指纹的说明。在一些合适的实施方式中,传感器阵列作为芯片阵列提供在试剂盒中。
[0312]
在其他方面,提供了用于确定对象的疾病状态或对于对象的疾病进行诊断或预后的试剂盒。合适的试剂盒包括传感器阵列,该传感器阵列包括至少两个传感器元件,这些传感器元件彼此具有不同的物理化学性质以确定生物分子指纹。此外,试剂盒还可以包括不同疾病状态或不同疾病或病症的生物分子指纹的比较组。提供了关于确定生物分子指纹和分析的说明。
[0313]
对本领域技术人员显而易见的是,除了已描述的那些外,在不背离所述发明理念的前提下可以进行更多的改良。在解释本公开时,所有术语应以与上下文一致的最广义的方式解释。术语“包含”的变体应该被解释为以非排他的方式引用元件,组件或步骤,因此引用的元件,组件或步骤可以与不明确引用的其他元件,组件或步骤组合。被称为“包含”某些元件的实施方式也被认为是“基本上由(这些元件)组成”和“由(这些元件)组成”。术语“基本上由......组成”和“由...组成”应根据mpep和相关联邦巡回法院的解释进行解释。过渡术语“基本由......组成”将权利要求的范围限制到指定的物质或步骤以及要求保护的发明的“本质上不影响基本和新特征的那些”。“由......组成”是一个封闭的术语,不包括权利要求中未指定的任何元件,步骤或成分。
[0314]
包括以下非限制性实施例仅用于说明的目的,并不意图限制本发明的组合物和方法可以发现实用性的技术和方案范围的范围,如本领域技术人员理解并可以容易地实施的那样。
实施例
[0315]
实施例1a用于癌症的早期检测的无标记传感器阵列
[0316]
本实施例提供了用于各种癌症的早期检测的无标记传感器阵列。传感器阵列由具有不同表面电荷的三种不同交叉反应脂质体组成(即阳离子(dopg(1,2-二油酰-sn-甘油-3-磷酸-(1
′‑
rac-甘油)),阴离子(dotap(1,2-二油酰基-3-三甲基铵-丙烷)-dope(二油酰基磷脂酰乙醇胺)和中性(chol(dopc-胆固醇)),其蛋白质冠组成随着它们与具有不同类型癌症,即肺癌,胰腺癌,骨髓瘤,脑膜瘤和胶质母细胞瘤的患者的血浆的相互作用而变化。虽然没有单一蛋白质冠组成对任何一种癌症类型具有特异性,但冠组成模式的变化为每种类型的癌症提供了独特的“指纹”。
[0317]
使用来自早期,中期和晚期癌症患者的血浆的传感器阵列元件的硬冠概况。在传感器阵列元件(纳米颗粒)的表面上形成的蛋白质冠的组成强烈地依赖于那些纳米颗粒的物理化学性质,并且同时可能受到存在于用于孵育的人血浆供体中的疾病类型的强烈影响。使用动态光散射(dls/nanosight)和透射电子显微镜(tem)探测与五种不同类型的癌症患者(即多形性胶质母细胞瘤,肺癌,脑膜瘤,多发性骨髓瘤和胰腺癌)和健康个体的血浆孵育后的冠包被的纳米颗粒的尺寸和电荷(见表1),并且结果证明冠包被的纳米颗粒的物理化学性质基本上取决于癌症的类型(图2a,b)。
[0318]
表1.该研究中使用的血浆的来源患者的一般信息(以及它们的癌症类型)。
[0319]
[0320]
[0321][0322]
通过bca或nanoorange测定法对吸附在纳米颗粒上的总蛋白质进行定量评估,结果显示在来自患有各种类型癌症的患者的血浆中孵育后吸附蛋白质的量的显著差异(图2b)。吸附在脂质体表面上的总蛋白质的定量评估显示蛋白质量对癌症类型的强烈依赖性(图2b)。通过液相色谱-质谱(lc-ms/ms)评估三种脂质体表面的蛋白质冠组成,其中定义了1,800种已知蛋白质的丰度。确定了单个蛋白质及其类别(即补体,凝血,组织渗漏,脂蛋白,急性期,免疫球蛋白和其他血浆蛋白)对冠组成的贡献(图2c;图3a-f)。这些结果证明了蛋白质组成不仅与癌症类型,还与传感器元件的类型(即,纳米颗粒的类型)之间的显著关联。
[0323]
根据大量文献,癌症发展与补体,凝血,组织渗漏,脂蛋白,急性期和免疫球蛋白的变化之间存在相当大的关系。因此,这些蛋白质类别与纳米颗粒的交叉反应性相互作用可以为每种类型的癌症提供独特的“指纹”,这可以促进癌症鉴定和鉴别。因此,可以预期蛋白质冠传感器阵列交叉反应性地吸附可用于癌症鉴定和鉴别的癌症诱导和发展中涉及的多种蛋白质。
[0324]
开发监督式的分类分析以使用蛋白质冠传感器阵列结果识别和区分癌症。为了研究各种传感器元件的蛋白质冠指纹(pcf)是否可以用作生物传感器并形成针对不同疾病的独特模式,我们对三种脂质体的蛋白质冠组成(阳离子,阴离子,和中性)的蛋白质组学数据应用了聚焦分类方法(focused classification approach)。方法的详细信息在方法部分中描述。引入投影(vip)得分中的加权变量重要性,并将其应用于基于偏最小二乘判别分析(pls-da)作为线性投影方法的变量分级。可以由一组获得的等级变量引导在构建分类模型中选择最相关的变量(蛋白质)。在这方面,将最高的等级变量逐一添加到模型中,并监测pls-da模型的分类误差。我们观察到,通过仅使用前69个特征,该分类模型具有最小误差(图4a)。新的69维特征空间成功地用于通过pls-da以高分类精度(0.97)区分属于六个类别的30个样品,使用弃一(leave-one-out)和10倍交叉验证(图4a,b)。分类参数在表2中给出。每种单一选择的蛋白质对每个癌症组(vip)的分离的贡献分别绘制在y轴和x轴上,以提供所得发现结果的相对特异性的直观表示(图4b-f)。具有较高vip分数的蛋白质可被认为是区分每种疾病与对照和所有癌症类别中的最佳信息或诊断组。
[0325]
表2.从6组样品的2个发展和非线性模型中获得的分类结果。
[0326][0327]
然后将pls-da和反向传播人工神经网络(cpann)应用于所选变量,并将整个样品分别应用于监督式分类,线性和非线性方法。应该注意的是,在变量选择之前具有所有变量的主要数据集具有较差的区分力并且不能被分成六组。
[0328]
接下来,为了进一步验证和分析数据,我们决定利用非线性分类方法。可视化特征空间可以帮助我们理解模式之间的隐藏结构和拓扑关系。为了在保留数据结构中的拓扑关系的同时降低特征空间的维数,使用cpann(自组织映射/som的监督变体)来学习和预测模式的类隶属关系,同时产生神经元的二维映射并提供关于数据结构的有价值信息(来自非
线性方法)。有关cpann的详细信息,请参见方法部分。使用10倍交叉验证检查cpann映射的不同大小;由于最小分类误差,选择包括64(8
×
8)个神经元的映射(图9c)。此外,高维空间中的数据的拓扑结构反映在由cpann产生的分配映射中(图5c,d)。考虑到神经元与输入向量的相似性,可以将映射划分为与不同类型的癌症和对照样品相关的六个不同区域。具有相同类别标记的样品被映射到附近或相同的神经元上,这意味着所选择的变量提供了有价值的信息,其在区分特征空间中的样品方面具有价值。映射上六个区域的相对位置和方向可以提供关于癌症类型之间相似性的定性信息。为了表示变量选择对映射质量的影响,用所有1823个变量训练另一个cpann,并且得到的映射显示所选择的生物标志物(变量)在区分癌症类型并对它们进行正确分类中起重要作用(图5c,d)。
[0329]
在获得的结果的基础上,线性和非线性模型都显示出高精度,这从其可接受的特异度,灵敏度和类别误差值得以推断。与这些发现一致,基于69种标志物的无监督式聚类(hca)能够强力地分离各种类型的癌症和对照样品(图5e-f)。如图5中可见,胶质母细胞瘤和脑膜瘤组之间存在紧密相似性,这意味着难以区分,这最可能与这两种脑癌中的类似血浆蛋白质组学模式有关。这些结果反映了这样的事实:冠中许多蛋白质的血浆浓度差别很大,不仅在具有不同类型癌症的对象中,而且在健康个体中也是如此。
[0330]
为了说明生物传感器的模式识别能力,对从单个纳米颗粒获得的数据进行了一组分析。正如所料,癌症特异性指纹的模式不能仅从每个纳米颗粒的pcf中提取。我们发现,应用于在三种不同脂质体(阳离子,阴离子和中性)上形成的蛋白质冠中的蛋白质丰度的模式识别技术不仅正确区分了来自对照样品的癌性,还正确区分考虑的其他类型的癌症。
[0331]
鉴定在癌症检测和鉴别中具有关键作用的蛋白质,作为特定类型癌症的有希望的生物标志物。在癌症诊断之前(风险评估和筛查/早期检测)和诊断之后(监测治疗,选择其他治疗和检测复发)使用生物标志物将产生实质性的治疗和健康经济益处。为了理解区分癌症样品的69种选定蛋白质的潜在生物学相关性,我们手动检索了pubmed中关于根据不同疾病阶段上调或下调的特定类型癌症的蛋白质生物标志物的先前发表的报告。将得到的数据与模型中的所选蛋白质进行比较,以鉴定匹配的标志物并确定所提出的模型的生物学相关性。有趣的是,我们注意到,在已经报道为特定癌症生物标志物的所选预测因子中,对五个经研究的癌症组具有特异性的大量的生物标志物(图7b)。
[0332]
所选择的标志物用于区分五组癌症的高特异性,其源自本文介绍的蛋白质冠传感器阵列方法,证明了与复杂癌症蛋白质组学空间中正在进行的工作的显著相关性;因此,这种策略不仅为癌症预测提供了基础,而且还将这种前景变为现实。值得注意的是,不同组之间的区别是由于几种预测因子(而非个体生物标志物)以系统性方式同时改变而形成的,形成了每种特定类型癌症独特的模式。基于该证据,由所提出的模型选择的尚未被报道为癌症特异性生物标志物的最具信息性的预测因子可能具有作为新的诊断生物标志物候选者的巨大潜力。为了确定它们在癌症发展中的作用,应仔细监测癌症患者中这些有希望的候选物的变异和功能性。通过一组信息预测因子关注来自大量对象的独特模式,研究人员应该能够比使用现有方法更准确地预测不同阶段的癌症。
[0333]
组数据分析。为了探测这种创新的传感器阵列在癌症的非常早期检测方面的能力,我们使用了来自健康人的组血浆,这些人在血浆采集几年后被诊断出患有五种癌症类型之一。使用组样品,我们评估了我们提出的具有69个选定预测因子的线性和非线性模型
是否可用于癌症预测。
[0334]
为此,将与69个变量相关的值放入模型中,并且在给定固定的最佳参数值的情况下预测每个组对象的类隶属关系。值得注意的是,69个变量中的19个变量(蛋白质)在组样品的蛋白质组学的蛋白质组学概况中缺失;因此,它们在验证数据矩阵中的量为零。有趣的是,线性和非线性模型都为所有五个样品提供了良好的预测。训练和组样品之间观察到的距离(图6a,b),最可能受到为这19个缺失变量添加到数据矩阵的零值的影响。如图6c,d所示,组样品在cpann映射中被置于与胶质母细胞瘤相关的正确神经元中。
[0335]
方法
[0336]
脂质体。胆固醇(chol)购自西格玛-奥德里奇公司(美国密苏里州圣路易斯)。dopc(二油酰磷脂酰胆碱),dope(二油酰磷脂酰乙醇胺),dopg(1,2-二油酰基-sn-甘油-3-磷酸-(1
′‑
rac-甘油))和dotap(1,2-二油酰基-3-三甲基铵丙烷))购自阿凡提极性脂质公司(avanti polar lipids)(美国阿拉巴马州阿拉巴斯特)。通过将适量的脂质9∶1(v/v)溶解在氯仿:甲醇中制备dopg,dotap-dope(1∶1摩尔比)和dopc-chol(1∶1摩尔比)脂质体。通过旋转蒸发蒸发氯仿∶甲醇混合物。将脂质膜在真空下保持过夜,并用10mmol/l的磷酸盐水缓冲液(pbs)(ph 7.4)水合至最终脂质浓度为1mg/ml。获得的脂质体悬浮液由avanti微型挤出器(阿拉巴马州阿拉巴斯特的阿凡提极性脂质公司)通过50-nm聚碳酸酯碳酸盐过滤器挤出而定尺寸。
[0337]
人血浆采集,制备和储存。从健康和诊断患有多形性胶质母细胞瘤,肺癌,脑膜瘤,多发性骨髓瘤或胰腺癌的癌症患者收集人血浆(hp)。本研究得到了罗马大学(sapienza university of rome)伦理委员会(多形性胶质母细胞瘤,脑膜瘤,多发性骨髓瘤),那不勒斯腓特烈二世大学(university ofnapoli federico ii)(肺癌)和罗马大学校园生物医学中心(university campus bio-medico di roma)(胰腺癌)的批准。简而言之,通过bd p100血液收集系统(美国新泽西州富兰克林湖)通过静脉穿刺对健康对象和癌症患者进行血液采集,采用按钮技术减少血液浪费,同时将污染风险降至最低。凝块形成后,将样品以1000
×
g离心5分钟以沉淀血细胞,并除去上清液。在确认没有溶血后,将从每个供体(1ml)收集的血浆分成200微升等分试样并在-80℃下储存在标记的蛋白质lobind管中直至使用。为了分析,将等分试样在4℃下解冻,然后在室温(rt)下加热。
[0338]
组血浆样品。我们在血浆采集后的八年内使用来自被诊断患有脑癌,肺癌和胰腺癌的健康人的人血浆。血浆样品通过nih资助的golestan组研究收集,该研究由美国国家癌症研究所(nci),法国国际癌症研究机构(iarc)和伊朗的德黑兰医学大学(tums)进行。这项研究涉及收集和储存来自50,000个健康对象的血浆,其中超过1,000个患者在随后的几年中继续发展各种类型的癌症。在该研究中使用来自每种癌症的五个个体的样品。这些重要的血浆样品为我们提供了探索我们创新的蛋白质冠传感器阵列用于癌症的早期检测的能力的独特机会。
[0339]
尺寸和ζ电位。将裸脂质体与hp(1∶1v/v)在37℃孵育1小时。随后将样品在4℃以14000rpm离心15分钟以使脂质体-hp复合物沉淀。将得到的沉淀用磷酸盐缓冲盐水(pbs)洗涤三次,并重悬于超纯水中。对于尺寸和ζ电位测量,用990μl蒸馏水稀释10μl每种样品。使用配备有5-mw hene激光器(波长λ=632.8nm)的zetasizer nano zs90(英国马尔文公司(malvern))和数字对数相关器在室温下进行所有尺寸和ζ电位测量。通过contin方法分析
标准化强度自相关函数,以获得颗粒的扩散系数d的分布。通过斯托克斯-爱因斯坦方程(rh=kbt/6πηd)将d转换为有效的水动力半径rh,其中kbt是热能,并且η是溶剂粘度。通过激光多普勒电泳测量样品的电泳迁移率u。通过斯莫路科夫斯基关系(ζ电位=uη/g)计算ζ电位,其中η和ε分别是溶剂相的粘度和介电常数。脂质体-hp复合物的尺寸和ζ-电位给出五次独立测量的平均值
±
标准偏差(s.d.)。
[0340]
蛋白质测定。将脂质体制剂与hp(1∶1v/v)在37℃孵育1小时。然后,将脂质体-hp复合物在4℃以15000
×
g沉淀15分钟并用pbs洗涤三次。将洗涤的沉淀重悬于8mol/1的尿素,50mmol/1的nh4co3中。将10微升每种样品加入96孔板的5个孔中。添加150微升/孔的蛋白质测定试剂(pierce,美国马萨诸塞州沃特汉姆市的热科学公司(thermo scientific))进行蛋白质定量。摇动多孔并在室温下孵育5分钟。用glomax discover system(美国威斯康星州麦迪逊的普罗麦格公司(promega))在660nm处测量吸光度。适当地校正背景效应并使用标准曲线计算蛋白质浓度。结果以五个独立的重复的平均值
±
s.d给出。
[0341]
蛋白质鉴定和定量。如其他地方所述进行孵育过程(用于研究纳米颗粒和血浆蛋白质之间的相互作用的无标记定量分析(label-free quantitative analysis for studying the interactions between nanoparticles and plasma proteins),analytical and bioanalytical chemistry,2013,405,2-3,635-645,通过引用全文纳入)。将脂质体制剂与hp(1∶1v/v)在37℃孵育1小时。样品以15000x g离心15分钟以使脂质体-hp复合物沉淀。用10mmol/l tris hcl(ph 7.4),150mmol/l nacl和1mmol/l edta洗涤沉淀三次。洗涤后,将沉淀空气干燥并重悬于消化缓冲液中。消化和肽脱盐如先前所述进行(用于研究吸附在脂质体表面上的蛋白质的鸟枪蛋白质组学分析方法(shotgun proteomic analytical approach for studying proteins adsorbed onto liposome surface).analytical and bioanalytical chemistry,2013,401,4,1195-1202,通过引用全文纳入)。简而言之,将沉淀重悬于40微升8mol/1的尿素,50mmol/1的nh4co3中,并通过加入2微克胰蛋白酶进行消化。使用spe c18柱将消化的肽脱盐,用适当体积的0.1%甲酸溶液重建,并储存在-80℃直至分析。通过与串联质谱(ms/ms)耦合的纳米高效液相色谱(hplc)分析消化的肽。使用通过纳电喷雾离子源直接连接到混合线性离子阱-orbitrap质谱仪(orbitrap ltq-xl,德国不来梅的热科学公司)的dionex ultimate 3000(美国加利福尼亚州日照谷的戴安公司(dionex corporation))进行nanohplc ms/ms分析。将肽混合物富集在300μm id
×
5mm acclaim pepmap 100 c18预柱(美国加利福尼亚州日照谷的戴安公司)上,以10微升/分钟的流速使用由含有0.1%(v/v)hcooh的ddh2o/can,98/2(v/v)组成的预混流动相。然后通过反相(rp)色谱分离肽混合物。使用由流动相addh2o/hcooh(99.9/0.1,v/v)和流动相b acn/hcooh(99.9/∶0.1,v/v)组成的3小时优化lc梯度检测最大的肽组。使用60,000(半峰全宽,m/z 400)的分辨率设置,在数据依赖性模式下操作,在350-1700的m/z范围内收集洗脱肽的ms谱。收集每次ms扫描中五种最丰富离子的ms/ms谱。其它详细信息可以在别处找到(用于研究吸附在脂质体表面上的蛋白质的鸟枪蛋白质组学分析方法(shotgun proteomic analytical approach for studying proteins adsorbed onto liposome surface).analytical and bioanalytical chemistry,2013,401,4,1195-1202)。对于每个实验条件,制备三个独立样品(生物重复),每个样品一式三份测量(技术重复),对每个实验条件产生九个测量值。使用thermo-finningan lcq/deca raw文件数据导入过滤器将raw
数据文件提交给mascot(v2.3,英国伦敦的矩阵科学公司(matrix science)),以针对非冗余swiss-prot数据库执行数据库检索(09-2014,546000个序列,智人分类学限制)。对于数据库检索,胰蛋白酶被指定为蛋白水解酶,最多有两个未切割(missed cleavage)。将氨基甲酰基甲基化设定为半胱氨酸的固定修饰,而选择甲硫氨酸的氧化作为可变修饰。前体离子和片段化离子的单同位素质量耐受性分别设定为10ppm和0.8da。选择+2或+3的电荷状态作为前体离子。将蛋白质组输出文件提交给商业软件scaffold(v3.6,美国俄勒冈州波特兰的蛋白质组软件公司(proteome software))。如果肽鉴定结果超过peptideprophet算法设定的95%概率阈值,则验证它们。如果蛋白质鉴定结果成立的可能性大于99.0%并且含有至少两种独特的肽,则接受它们。含有共有肽并且仅基于ms/ms分析无法区分的蛋白质被分组以满足简约性原则。未加权的谱计数(usc)用于评估定量分析中生物重复的一致性,并且使用标准化的谱计数(ncs)来检索蛋白质丰度。
[0342]
统计学分析。所有统计学分析均使用pls,kohonen和cpann工具箱进行,并使用microsoft excel,xlstat和matlab创建图表。
[0343]
数据矩阵。与每个个体相关的预测因子矩阵(x)的每行来源于从三蛋白冠传感器阵列获得的所有蛋白质丰度(图4a)。在预处理步骤中,矩阵x中的标准化数据,相对蛋白质丰度(rpa)被自动缩放。
[0344]
分类和聚类。
[0345]
偏最小二乘判别分析(pls-da)。偏最小二乘判别分析是一种众所周知的多变量方法,被视为线性分类和降维方法,由两个主要部分-结构部分组成,它将潜变量作为原始自变量的线性组合(即数据矩阵x)进行搜索,它与相应的因变量(即类隶属关系,y)具有最大协变。测量的组分包括潜变量作为分数和负载,它们显示潜变量及其原始变量是如何相关的。基于plsda降低数据维度的能力,它允许不同数据模式的线性映射和图形可视化。pls-da特别适合处理高共线和噪声模式。与蛋白质组学中的大数据集相关的主要问题是大量监测变量(即蛋白质)和相对少量的样品。因此,变量之间可能存在高冗余度,这使得其中许多变量无法提供信息且与分类无关。通过这种方式,消除无信息变量或找到新的不相关变量可以提高分类的预测性能。由于生物医学应用,如当前工作中,我们不仅必须决定样品是否属于众多已知群体中的一个,而且还要确定哪些变量与类别之间的最佳区分最为相关,如pls-da是一种很好的用于找到不相关的新潜变量,同时保留数据的变化的候选方法。原始变量产生隐投影的无能也可以通过投影(vip)分析中的变量重要性来计算,并且可以发挥重要作用角色来决定变量。
[0346]
根据加权vip识别最相关的变量。偏最小二乘判别分析(pls-da)用于探索与变量相关的vip值。vip是变量对以下两组数据描述的贡献程度的综合度量:因变量(y)和自变量(x)。pls模型中的权重反映了自变量和因变量之间的协方差,并且权重的利用允许vip不仅反映因变量的描述有多好,而且反映信息对于自变量模型的重要程度。
[0347]
开发了一种基于vip分数来识别变量的最佳亚组的方法。可以通过对数据集执行pls-da来计算vip分数。在该方法中,变量的vip分数被计算50次,每次使用训练和验证集的随机排列(通过考虑每类对象的80%覆盖率来迭代地选择随机训练集)。考虑到最重要的变量,即大的vip分数值(>2),可以在每次重复时选择前200个变量并将其添加到顶部变量集合中。之后,可以根据顶部变量集合获得每个变量的出现频率(freqi)和平均vip分数
因此,由于依赖于训练和验证集,因此不太建议选择变量i(具有高值和低值)。因此,每个变量的值可以由freqi加权,并且可以使用加权的来完成最相关变量的排序。fig_appr是所提出方法的示意图。建立分类模型的最相关变量的选择可以通过如下获得的排序来指导:将高度等级变量逐个添加到数据集,并且计算pls-da的分类误差以找到最小数量的相关预测因子(图4a)。
[0348]
反向传播人工神经网络(cpann)。反向传播人工神经网络(cpann)是自组织映射的监督式变体,其由布置在预定义n
×
n网格上的两层神经元组成。cpann可用于将来自高维特征空间的数据映射到低维(通常为2)离散的神经元空间,以及预测未知样品的类隶属关系。输入向量(样品特征向量)和对应的类隶属关系向量(二元向量)分别呈现给cpann的输入和输出层。两层中神经元的权重校正基于神经元的竞争性学习和协作来执行(参见表3)。因此,类似的输入向量可以映射在相同或相邻的神经元上,反之亦然。最终的分配映射正确地揭示了特征空间中数据的结构,并保留了神经元低维网格中模式的距离。图9c显示了使用顶部等级生物标志物的cpann的高质量分配映射。根据每个类别的不同区域,分类错误的风险被最小化。可以通过在不同的映射尺寸上执行10倍交叉验证来确定映射的适当尺寸。训练的cpann可用于将类隶属关系分配给未标记的样品。在训练数据中存在冗余和无信息变量将影响映射的质量并增加分类错误的风险(图5c)。该过程是非线性映射,其有助于在二维神经元网格上可视化高维输入对象。这是一种自组织过程,以透明的方式解决分类问题。关于cpann方法的更多细节可以在以下参考文献中找到。
[0349]
分层聚类分析(hca)。分层聚类分析是一种无监督式方法,广泛用于探索和可视化整个异质大数据集,如蛋白质组学中常用于不同和同质聚类的那些。分层聚类策略可以分为两类:凝聚和分裂方法。凝聚过程首先将每个对象分成它自己的单个聚类,然后按顺序组合聚类;合并类似的对象或聚类,直到每个对象只属于一个聚类。相反,分裂过程从一个大聚类中的所有对象开始,逐渐将它们分成较小的聚类,直到每个对象都在一个单独的聚类中。最后,将对象组织成树形图,其分支是定义的聚类。在聚类分析中,为了识别同质子群,应该定义两个重要概念,相似性(确定对象之间的相似性的数值和构建相似性矩阵)和链接(对象与群连接与否)。在此,我们应用具有最远邻域链接算法的凝聚分层聚类,用于基于所选变量的无监督式分析。
[0350]
组样品预测。通过群组样品分析评估具有69个选定预测因子的线性和非线性变量的预测能力。为此,将与69个变量相关的值放入模型中,并且在固定的最佳参数值的情况下预测每个组对象的类隶属关系。我们的组样品的蛋白质冠传感器阵列的蛋白质组学概况中的19个变量(蛋白质)未被检测到,并且在验证数据矩阵中认定这些变量为零。有趣的是,线性和非线性模型都为所有五个样品提供了良好的预测。图6a中显示的训练和组样品之间观察到的距离最可能与为这19个缺失变量添加到数据矩阵的零值相关。我们通过从训练集和预测集的两个数据矩阵中删除这19个蛋白,检查了缺失的变量的替换零值的影响;然后建立pls-da模型并预测组样品。正如预期的那样,没有观察到组和训练样品之间有大距离。
[0351]
表3.六类中各变量的cpann权重映射的相关系数。
[0352][0353]
[0354]
[0355][0356]
对于每个变量,可以计算相应的权重映射与分配映射模式的相关系数。
[0357]
cc=0:表示生物标志物与相关类别之间无相关性;
[0358]
1>cc(i)>0:生物标志物强度与癌症相关类别之间的一致性。
[0359]
0<cc<-1:生物标志物值与癌症相关类别之间的反相关。
[0360]
cc值>0.5或<-0.5是彩色的。例如,生物标志物1282的权重映射与分配映射上的癌症类别4模式高度相关,从而它可以是来自骨髓瘤患者的样品的重要生物标志物。
[0361]
实施例1b使用多纳米颗粒蛋白质冠表征的人蛋白质组深度分析和机器学习能够在早期准确识别和区分癌症
[0362]
在第二实施方式中,来自单个纳米颗粒的蛋白质冠概况的给定血浆样品的集体蛋白质冠数据能够使用机器学习(例如,随机森林方法)来识别和区分不同类型的癌症以分析数据。使用如实施例1a中所述的传感器阵列,并且通过机器学习进一步详细地分析所收集的数据。该传感器阵列(即蛋白质冠纳米系统)明确且稳健地鉴定癌症并允许区分不同类型的癌症。该系统可用于使用盲血浆样品预测癌症类型。通过在血浆采集几年后被诊断患有癌症的现有组中使用健康人的血浆来进行非常早期检测的能力,以确定癌前生物分子指纹。
[0363]
图1呈现了使用传感器阵列(纳米颗粒系统)使用多蛋白-冠蛋白质组学在已知癌症患者中进行癌症检测以及使用盲血浆和组样品进行癌症预测的示意图。
[0364]
结果
[0365]
使用来自早期,中期和晚期癌症患者的血浆的纳米系统的蛋白质冠概况。
[0366]
我们的蛋白质冠纳米系统由具有不同表面电荷的三种不同交叉反应脂质体组成(即阴离子(dopg(1,2-二油酰-sn-甘油-3-磷酸-(1
′‑
rac-甘油)),阳离子(dotap(1,2-二油酰基-3-三甲基铵-丙烷)-dope(二油酰基磷脂酰乙醇胺)和中性(chol(dopc-胆固醇)),其在与以下五种癌症之一的患者或健康对象的血浆接触后测量蛋白质冠概况:肺癌,胰腺癌,骨髓瘤,脑膜瘤和胶质母细胞瘤。
[0367]
我们对每个患者(5个患者/组)进行了蛋白质组学分析,对于我们的蛋白质冠纳米系统中的三种脂质体(参见图2a,b,关于脂质体的尺寸和电荷的详细信息),每种情况设三复样(即,总试验:3*(29)*3=261)。尽管如实施例1a中所述,没有单一蛋白质冠组成对任何一种癌症类型具有特异性,但是来自不同脂质体的给定血浆样品的集体蛋白质冠组成为每
种类型的癌症提供了独特的“指纹”。
[0368]
尽管在脂质体表面形成的蛋白质冠的组成强烈依赖于它们的物理化学性质,但它也可能受到给定患者血浆中存在的蛋白质和其他生物分子的独特类型,浓度和构象的强烈影响。在与来自健康个体和具有五种不同类型的癌症(参见表1)的患者的血浆孵育后,使用动态光散射(dls/nanosight)探测冠包被的脂质体的尺寸和电荷。结果证实,冠包被的纳米颗粒的物理化学性质在不同类型的癌症间变化(图2a,b)。
[0369]
通过bca(二辛可宁酸)或nanoorange测定法对吸附在脂质体上的总蛋白质进行定量评估,结果显示在来自患有各种类型癌症的患者的血浆中孵育后吸附蛋白质的量的显著差异(图3a-f)。吸附在脂质体表面上的总蛋白质的定量评估显示蛋白质量对癌症类型的依赖性(图3a-f)。通过液相色谱-串联质谱(lc-ms/ms)评估三种脂质体表面的蛋白质冠组成,其中定义了876种已知蛋白质。确定了单个蛋白质及其类别(即补体,凝血,组织渗漏,脂蛋白,急性期,免疫球蛋白和其他血浆蛋白)对冠组成的贡献(图3a-f)。结果证明了蛋白质组成与不仅与癌症类型相关,还与脂质体的类型相关。这种变化背后的机制是,纳米颗粒的高表面积-体积比为各种人血浆蛋白(高丰度蛋白质,较低丰度血浆蛋白和非常罕见的蛋白质)提供了独特的机会参与冠组成,不需要消耗高丰度蛋白质,也不与血浆蛋白质浓度直接相关。此外,在我们的系统中,血浆蛋白的构象变化也可以通过显著改变蛋白质与纳米颗粒的相互作用位点来改变蛋白质冠组成。这些特征使蛋白质冠概况在用于分析人血浆中蛋白质开发的其他方法中是独特的。
[0370]
脂质体表面的蛋白质冠组合物含有广泛的人血浆蛋白,包括高丰度蛋白质(如白蛋白,转铁蛋白,补体蛋白,载脂蛋白和α-2-巨球蛋白)和非常罕见的蛋白质(定义为<100ng/ml)例如转化生长因子β-1诱导的转录物1蛋白(约10ng/ml),果糖-二磷酸醛缩酶a(约20ng/ml),硫氧还蛋白(约18ng/m1)和l-选择素(约92ng/ml)。我们还鉴定了388种没有已知血浆浓度的蛋白质(http://plasmaproteomedatabase.org/)。然后通过机器学习方法分析获得的蛋白质信息,以探测我们的蛋白质冠纳米系统进行稳健和准确的癌症检测的能力。
[0371]
开发使用蛋白质冠纳米系统结果检测和区分癌症的分类器。
[0372]
为了评估蛋白质冠纳米系统检测各种癌症的能力,我们使用从29种血浆样品(来自5种癌症类型的各5个患者;和4个健康样品)中收集的3种不同脂质体的蛋白质组学数据来训练分类器,特别是接收来自患者的阵列测量并输出六个标记之一(五种癌症类型中的一种,或健康)的算法。在训练分类器之前,来自3个纳米颗粒的原始数据首先通过后面部分深入讨论的低秩张量因子分解来“去噪”。这种去噪可以隐含地减轻个体冠元件中观察到的显著变化。然后,我们在得到的去噪数据上训练随机森林分类器,一种流行的非线性分类算法。
[0373]
我们在16个盲样品上测试了该分类器的准确度(5个癌症类型各3个患者;1个健康样品)。我们测量了将这些盲样正确分配到六个标记之一的任务的整体分类准确度,以及对五种癌症类型中的每一种的灵敏度和特异度(表4)。由于血浆样品数量相对较少(总共45个),并且为了确保结果的稳健性,我们执行了此程序(在29个样品上训练随机森林分类器并测量剩余16个样品的准确度,灵敏度和特异度)共1000次。从数据的所有类分层分区中随机选择实验的1000次重复中的每一次中的训练和测试集。这种方法允许我们计算我们报告
的分类准确度的p值的无偏估计(见表4)。具体而言,表4的最后一行显示1000次重复的平均总体准确度为96.2%,或等同地,总误差为3.8%。我们还观察到零假设的p值为0.04,即整体分类误差低于87.5%,因此我们可以95%的置信度拒绝这个零假设(null hypothesis)。五种单独癌症类型的灵敏度范围为87.4%至100.0%,个体特异度范围为97.0%至100.0%。
[0374]
表4.总体分类准确度,灵敏度和特异度。具有一个,两个和三个脂质体的蛋白质冠纳米系统的总体分类准确度(第2列)。分类准确度和相关的p值均随着附加的脂质体而改善。对胶质母细胞瘤,肺癌,脑膜瘤,骨髓瘤和胰腺癌的个体灵敏度和特异度(第3-12列)也表明,其他脂质体可提高灵敏度和特异度。实验结果在包括29个血浆的训练集的1000次独立抽取中取平均值,并对剩余的16个血浆进行评估。p值用于分类误差低于87.5%的零假设。
[0375][0376]
蛋白冠纳米系统中多脂质体的价值
[0377]
为了评估在蛋白质冠纳米系统中包含多脂质体的重要性,我们使用1000次不同的数据分割成训练和测试样品来重复整个分类过程,但这次使用仅从单个脂质体测量的数据。这是针对三种脂质体中的每一种进行的,并且结果报告在表4的第一行中。相对于包括所有三种脂质体的整个阵列,单脂质体阵列显示出明显更低的准确度,灵敏度和特异度。我们还重新进行了两种脂质体组的程序(有三种这样的独特组合);这些结果见表4的第二行。双脂质体系统比单脂质体系统更精确,但仍然比三个脂质体的整个阵列弱。总之,这表明不同脂质体之间冠组成模式的变化值以及包括这种多次观察的必要性。
[0378]
变量和蛋白质重要性和稳定性
[0379]
随机森林模型还产生每个变量(即每个脂质体-蛋白质对)的重要性分数。该分数基本上衡量该变量在区分不同癌症类型的患者中的重要性。在随机森林的单个“树”上,用于构建树的任何变量的重要性得分被定义为使用该变量的节点“叶”中的训练集的比例(对未用于构造树的变量分配分数零);那么变量的总体重要性得分是每个树上其重要性得分的平均值。
[0380]
对于蛋白质的不同生物家族(与图3a-f中使用的那些相同),我们计算了区分不同
癌症类型的总体重要性(图10a,(a)-(c))。结果表明,不同的蛋白质家族在检测不同的癌症中很重要。例如,急性期蛋白在检测脑膜瘤中相对重要,而脂蛋白在检测胶质母细胞瘤中相对重要。值得注意的是,这些变化不同于吸附在脂质体上的每个类别的百分比的变化(图10a,(d)-(f))。有趣的是,这些结果与这些蛋白质类别的生物学功能非常一致。例如,与健康组织相比,在胶质母细胞瘤中脂质代谢被明显改变是公认的,这可能是观察到脂蛋白与脂质体相互作用的显著变化的主要原因(图2c和10a)。图10b提供了不同脂质体及其组合的冠状组成中鉴定的蛋白质和独特蛋白质的数量的详细内容。
[0381]
我们还计算了最重要的总蛋白质(图10c和表5)。在所有三种脂质体的组合中检测到这些蛋白质,再次显示了多脂质体在纳米系统中的关键作用。我们还评估了这组“重要”蛋白质在前面讨论的1000个训练数据分割中估计的分类器的稳健性。具体地,图10b显示了平均30种最重要蛋白质的重要性得分的第25至第75百分位数。这些表明,这组重要蛋白质对于用于模型训练的数据分割是稳健的。在这些最重要的蛋白质中(见表5),一些已被认为在癌症发展中起关键作用。例如,纤维胶凝蛋白(纤维胶凝蛋白2和纤维胶凝蛋白3)都是具有调理特性(opsonic property)的血清模式识别分子,具有调节补体激活的实质能力。已经证实,卵巢癌患者的纤维胶凝蛋白3血清浓度高于健康对象。此外,纤维胶凝蛋白3在前列腺癌血清的差异蛋白质组学分析中被鉴定,表明该蛋白质在前列腺癌中也有作用。另一方面,已确定载脂蛋白a2及其同种型在前列腺癌血清中过表达,并且在炎性疾病如癌症存在下,急性期蛋白质(例如,补体蛋白)的浓度可以改变≥25%。癌症和止血系统之间的明确关联早已有文献记载。止血通过调节血小板的粘附和纤维蛋白沉积来调节血流。参与止血的几种蛋白质已与血管生成的调节有关。其中,纤维蛋白原是止血过程中的主要蛋白质,已在许多肿瘤中发现;它调节血管生成和肿瘤生长,并且与转移形成有关。实际上,血浆纤维蛋白原水平已被用于预测非转移性肾细胞癌患者的临床结果,并预测胰腺癌的远处转移。
[0382]
表5.发现在所有三种脂质体的组合上检测到了最重要的总蛋白质的信息。*浓度是使用来自血浆蛋白质组数据库(www.plasmaproteomedatabase.org)的光谱计数获得的值。
[0383]
[0384]
[0385][0386]
为了进一步探讨我们的机器学习方法确定的重要蛋白质的作用,我们在open targets数据库中搜索了它们,这是一个治疗靶标识别和验证的平台。该数据库根据来自各种其他数据库(包括gwas目录,uniprot,gene2表型,癌症基因普查,intogen,欧洲pmc和reactome)的证据计算每种蛋白质的疾病关联分数,以得出0分(最低)至1.0(最高)规模的分数的疾病关联。在列出的蛋白质中,三种与癌症有很强的相关性。透明质酸结合蛋白与癌症有很强的一般联系(1.0);纤维蛋白原β链与肺癌有中度强关联(0.4);而角蛋白,1型细胞骨架14与前列腺癌强相关(0.72)。表5中的几乎所有其他蛋白质与各种类型的癌症具有一定程度的弱关联性(0.05-0.4)。因此,总体而言,蛋白质与已知的癌症关联具有联系。
[0387]
克服采用张量因子分解的单次测量中的变异性
[0388]
由于患者群体的显著变异性以及通过测量误差引入的噪声,我们发现任何单一蛋白质都不足以进行分类。对于100种最丰富的蛋白质中的每一种(产生3*100=300个变量),我们计算了在每种癌症类型的患者中观察到的冠中蛋白质浓度的平均绝对z分数。对于给定蛋白质,癌症类型的较高z分数表明该蛋白质可用于检测该癌症类型。图11(蓝色柱)显示了每种癌症类型和健康组的这些平均绝对z分数的直方图。我们还测量了先前与这些特定癌症类型相关的蛋白质的平均绝对z分数,其显示在图10中的相同直方图中(浅灰色柱)。在所有这些数百个变量中,仅一种蛋白质的绝对z值高于2.0,并且在仅一种癌症类型(骨髓瘤)上,这表明单个蛋白质均不足以用于准确分类。
[0389]
在我们构建随机森林之前的张量分解有效地起到了在给定样品上计算观察到的冠中蛋白质组成的少量加权平均值的作用。该平均值覆盖给定血浆样品中的所有蛋白质和纳米颗粒,并且起到减轻任何给定蛋白质的观察浓度的变化的作用。例如,在图11(长黑柱)中,针对每种癌症类型绘制这些加权平均值之一的平均绝对z分数。这些加权平均值的绝对z分数显著高于任何单个变量。除了直觉(intuition)之外,这还提供了我们的方法如何克服具有相同适应症的样品中单个蛋白质的变化,这种去噪也会对我们的分类能力产生重大影响。如果没有去噪,只在原始冠数据上简单训练随机森林分类器就可以得到94%的分类准确度(p值为0.07),而表4中报告96.2%(p值为0.04)。对于表7中报告的组数据,去噪使我们能够将分类准确度从92%(p值为0.04)提高到94.1%(p值为0.01)。
[0390]
分类准确度对数据的依赖
[0391]
我们对45个非组患者的最终评估具有数据的价值。我们的原始分类器针对每种癌症类型的5个样品进行了训练。为了测量包含更多或更少训练数据的价值,我们重复了分类程序(将数据分割成训练和测试样品,在训练样品上训练分类器,并测量测试样品的性能,全部完成1000次),针对每个类别不同数量的训练样品,范围从4到6(表6)。分类准确度,灵敏度和特异度均随着训练样品数量的增加而增加。每个类别6个训练样品,总体准确度达到
96.8%(即整体误差率为3.2%)。这强烈表明,随着训练分类器中包括更多数据,准确度,灵敏度和特异度将继续增加。
[0392]
表6.分类准确度随着更多数据而提高。(第2列)当训练集由来自每个癌症的四个,五个和六个样品组成时的总体分类误差以及相关的p值。分类误差和相关的p值均随着来自各癌症的额外样品而改善。(第3-12栏)当训练集由4到6个样品组成时,对胶质母细胞瘤,肺癌,脑膜瘤,骨髓瘤和胰腺癌的灵敏度和特异度。实验结果在训练集中超过1000个独立抽取取平均,其中包括4个健康患者,以及4到6个患有每种癌症类型的患者。p值用于至少两个分类误差的零假设。
[0393][0394][0395]
用脂质体取样低丰度和高丰度血浆蛋白,不需要蛋白质消耗
[0396]
使用机器学习技术的多脂质体蛋白质冠纳米系统为每种类型的癌症和健康个体产生独特的“指纹”蛋白质模式。为了追寻蛋白质冠在癌症鉴定和鉴别中独特能力的潜在机制,我们彻底分析了高丰度和低丰度蛋白质对冠组成的贡献,并将这些结果与人血浆中冠蛋白质的浓度进行了比较。在这方面,分别使用(蛋白质冠中白蛋白的总肽)/(蛋白质冠中蛋白质x的总肽)和(蛋白质冠的蛋白质x的总肽)和(血浆中白蛋白浓度)/(血浆中蛋白质x浓度)将各蛋白质(例如,蛋白质x)对蛋白质组成和血浆的贡献相对于白蛋白进行标准化。值得注意的是,我们使用在线蛋白质组数据库(http://plasmaproteomedatabase.org/)手动搜索了血浆中鉴定的冠蛋白质的浓度。由于蛋白质冠中白蛋白的总肽与白蛋白在蛋白质冠中的总重量成比例,将这些肽除以蛋白x的肽与血浆中白蛋白浓度与蛋白质x浓度的比率相当。如图12所示,我们发现血浆浓度在10个数量级上变化(以对数-对数(log-log)标度),而脂质体在4-5个数量级上检测到这些相同蛋白质。换句话说,我们发现蛋白质冠组成具有很大的能力来浓集各种低丰度蛋白质(≤100ng/mg)和非常稀有的蛋白质(≤10ng/mg)。这意味着获得蛋白质冠中高丰度蛋白质的数据不会干扰对来自较低丰度和稀有蛋白质的肽的检测。值得注意的是,大多数检测到的蛋白质是低丰度,稀有或未知/未报告的蛋白质。低丰度蛋白质在冠组成中的参与主要是由于用具有较高亲和力和较慢吸附动力学的蛋白质交换具有较低亲和力的冠蛋白质。
[0397]
检测人血浆中的低丰度蛋白质需要消耗高丰度蛋白质和消耗后的血浆分离策略;然而,即使使用这些消耗策略,血浆蛋白质组学在癌症的早期检测中也没有取得很大的成功。使用我们的系统获得的结果表明,与人血浆蛋白质相比,蛋白质冠组成含有多种较低丰度且非常罕见的血浆蛋白质,无需消耗(这可能导致意外去除低丰度蛋白/生物标志物)。此外,我们在蛋白质冠中发现了几种蛋白质,其在人血浆中的浓度未知/未报告,可能是由于它们在人血浆中的浓度非常低。更具体地,阴离子,中性和阳离子脂质体分别占具有未知/未报告血浆浓度的蛋白质的323,189和155)。这些蛋白质对蛋白质冠的贡献由图12右侧的矩形框表示。
[0398]
多脂质体(具有不同表面形式)的使用提供了增加低丰度蛋白质和非常稀有蛋白质的检测深度的独特机会(参见图12),其显著增强了蛋白质冠纳米系统的灵敏度,特异度和预测准确度。每种脂质体提供了贡献蛋白质的不同模式,其对癌症类型具有强烈依赖性。
[0399]
组样品间的癌症检测和区分
[0400]
最后,为了研究蛋白质冠纳米系统在非常早期检测癌症的能力,我们使用来自健康人的组血浆(获自nih资助的golestan组研究;详细信息在方法部分提供),他们在收集血浆后数年被诊断为胰腺癌,肺癌和脑癌。我们按照相同的程序进行了1000次实验。在每个实验中,我们将数据划分为12个(3个癌症类型各4个)训练样品和3个测试样品(3个癌症类型各1个)。通过先前描述的程序对观察结果进行去噪,然后在训练样品上训练随机森林分类器。最后,在测试样品上测量总体准确度,灵敏度和特异度(表7)。总体准确度为94.1%(错误率为5.9%),对于零假设,p值为0.01,总体准确度<66.7%(因此以95%置信度拒绝)。三种癌症类型的灵敏度范围为83.2%至100.0%,特异度范围为91.6%至100.0%。这些相对较高的值表明蛋白质冠阵列可以在其最早阶段成功地检测到癌症。
[0401]
表7.组样品的总体分类准确度,灵敏度和特异度。(第2列)一,二和三个脂质体的总体分类准确度。随着脂质体添加到纳米系统,分类误差和相关的p值都得到改善。(第3-8列)脑癌,肺癌和胰腺癌的灵敏度和特异度。同样,添加脂质体提高灵敏度和特异度。实验结果在包括12个患者的训练集的1000次独立抽取中取平均值,并对剩余的3个患者进行评估。p值用于分类准确度<66.7%的零假设。
[0402][0403]
我们还用较小的脂质体亚组进行了相同的实验,包括每个脂质体,以及两个脂质体的全部三个独特组。同样,随着脂质体数量的增加,总体准确度,灵敏度和特异度显示显著增加,再次表明阵列系统的价值。
[0404]
讨论
[0405]
没有使用蛋白质冠或任何其他方法进行血浆蛋白质组分级的在先研究使得能以可接受的特异度,灵敏度和预测准确度进行多癌症筛查。这是第一次开发出一种传感器阵
列,其特异度,灵敏度和预测准确度不仅适用于癌症,还适用于特定的癌症亚型。
[0406]
通过蛋白质冠的血浆蛋白质组分离已被证明与特定血浆蛋白质的丰度无关,而是通过多种因素发生,包括蛋白质对纳米颗粒表面的亲和力,包括库仑力,伦敦分散,氢-键酸度和碱度,极化率,孤对电子和冠结构中参与蛋白质之间的蛋白质-蛋白质相互作用。已显示蛋白质冠组成是动态的并且最初由丰富蛋白质主导,包括白蛋白,免疫球蛋白和纤维蛋白原,其与19种其他蛋白质一起构成血浆蛋白质组中超过99%的蛋白质质量。其余1%的血浆蛋白质组由超过10,000种蛋白质组成;对纳米颗粒表面具有较高的亲和性和/或较低的吸收动力学的这些蛋白质的一部分与高丰度蛋白质竞争包含在冠组成中。除了用对纳米颗粒表面具有较低结合亲和性的蛋白质交换具有较高结合亲和性的蛋白质外,在外部蛋白质冠层中的其他低亲和性蛋白质由于其有利的蛋白质-蛋白质相互作用而有可能发挥作用。这意味着交换的低丰度蛋白质可能能够指导蛋白质冠的形成以吸附更多低丰度蛋白质。
[0407]
在这里,我们首次分析了蛋白质冠在富集低丰度蛋白质(定义为《100ng/ml)中的相对浓度,证明这些蛋白质中的许多浓度<10ng/ml且接近1pg/ml。更重要的是,我们发现这些蛋白质中的许多通过机器学习方法在癌症鉴定和区分中发挥着至关重要的作用。蛋白质冠在浓缩各种低丰度和非常稀有蛋白质中的作用可能大大有助于克服当前质谱技术(包括lc-ms/ms)在早期检测癌症中成功有限的主要原因,因为这些技术可以检测4-6个数量级的动态范围的蛋白质。换句话说,蛋白质冠组成能够在大动态范围的血浆蛋白质组中进行取样,这可以显著增强蛋白质覆盖的深度而不会消耗蛋白质。由于从单个纳米颗粒获得的蛋白质冠构成至多数百种不同的蛋白质(总蛋白质组的一小部分),我们假设使用具有不同物理化学性质的多纳米颗粒可能产生蛋白质组学信息的额外维度:1)每个具有不同物理化学性质的额外纳米颗粒潜在能够招募额外的独特低丰度蛋白质(图12);2)重叠超过一个纳米颗粒表面的冠蛋白质以不同冠贡献百分比参与,从而改变其他参与的冠蛋白质的浓度和特性;和3)来自每个纳米颗粒的独特和重叠的冠蛋白质信息都作为独特的变量,因此为我们的机器学习方法提供更多的数据。结合更多的纳米颗粒进行血浆分离和蛋白质组学分析,与较少的纳米颗粒相比,为以更高的灵敏度,特异度和预测准确度癌症检测和鉴别提供了明显更多的信息(表4)。从概念上讲,我们的多纳米颗粒方法类似于嗅觉系统,其中气味识别的特异性源自几百个高度交叉反应的嗅觉受体的反应模式,其中任何一个受体提供不完整的信息,但组合在鉴定给定的气味时具有高度特异性(即,在人类中约400个活性受体可以检测和区分约10,000种气味,并且在狗中约个1200种活性受体可以检测约1,000,000种气味)。其他研究人员也使用类似的方法来检测和区分不同的分析物家族,各种食品和饮料,病原菌和真菌,生物分子,甚至纳米颗粒本身。
[0408]
使用三种不同的交叉反应性脂质体(具有负,中性和正表面电荷),其在暴露于具有以下五种癌症之一的个体患者的血浆后测量蛋白质冠概况:肺癌,胰腺癌,骨髓瘤,脑膜瘤或胶质母细胞瘤。为了使用蛋白质冠纳米系统结果识别和区分癌症,我们使用了明确定义的随机森林机器学习方法。我们已经指定了1000个不同组的样品作为训练(即,已知癌症和健康状况的血浆)或测试(即盲血浆)样品,以确保我们的蛋白质冠纳米系统对于以极好的预测准确度检测癌症是稳健且准确的。虽然单个纳米颗粒中没有一种蛋白质冠组成对任何特定癌症类型具有具有可接受的预测准确度的特异度(即86.0%,p值为0.43,分类误差低于87.5%),我们发现衍生自多脂质体的冠组成的模式以极好的预测准确度为每种类型
的癌症提供了独特的“指纹”(即96.2%,p值为0.04,分类误差低于87.5%)。基于使用多脂质体蛋白冠表征和机器学习对人类蛋白质组进行的深入分析的这些结果证实了该系统对癌症的明确鉴定和鉴别以及以极佳特异度对健康对象进行无差错区分的希望(从97.0%到100.0%)。
[0409]
为了探测蛋白质冠纳米系统用于非常早期检测癌症的能力,使用组血浆样品。这些样品是从收集血浆八年后被诊断患有肺癌,胰腺癌或脑癌的健康人中收集的。使用来自组研究中的15个患者的血浆的蛋白质冠纳米系统的结果显示,即使在这些预诊断组样品中,我们的方法也准确地鉴定和区分癌症,目前的替代方案不能针对这些样品进行癌症检测。与我们对新鲜血浆样品的发现一致,与单脂质体取样相比,多脂质体血浆采样提供了更高的分类准确度(94.1%对75.4%)和特异度[即脑(100.0%对86.1%)肺(96.6%对90.9%)和胰腺(91.6%对比86.9%)]。值得注意的是,与先前的新鲜癌症样品相比,组样品的蛋白质冠概况是不同的。这主要是因为在筛选健康个体时收集样品时,组样品的长期冷冻储存(大约10年)。越来越多的人认为,血浆样品的长期储存会强烈影响蛋白质亚组的浓度和完整性,从而改变蛋白质冠组成并降低我们的蛋白质冠纳米系统的灵敏度。因此,当使用新鲜血浆时,可以实现纳米系统的最大灵敏度,作为癌症筛查的一部分或诊断后的癌症检查。后一种情况下的值可能是蛋白质冠模式随时间的变化可提供与早期肿瘤复发或肿瘤切除后残留疾病的存在相关的有价值信息。
[0410]
总之,我们提出的概念验证表明,多纳米颗粒蛋白冠纳米系统具有相当大的潜力,可以增加蛋白质检测的深度,从而具有即使在现有技术未能检测疾病的最早阶段也可以准确地检测和区分癌症独特的能力。来自我们的蛋白质冠纳米系统的多纳米颗粒蛋白质冠模式为癌症检测提供了独特的多变量“指纹”,当仅分析单个纳米颗粒的蛋白质冠时,这是不可能的。此外,蛋白质冠模式代表了使用不同纳米颗粒对各种血浆蛋白质(包括丰富和稀有蛋白质)的统一富集,明确区别于其他多变量全血浆蛋白质组学方法,这些方法未能产生合适的结果用于早期癌症检测。通过使用具有不同物理化学性质的其他纳米颗粒,可以进一步增强纳米系统的蛋白质检测的深度(人血浆中蛋白质分析的主要限制)和预测准确度。我们用于盲新鲜血浆和追溯组血浆的机器学习和蛋白质-冠表征方法的成功预测结果为随后的癌症前瞻性研究提供了合适的基础。此外,多纳米颗粒蛋白冠纳米系统的实用性可以应用于其他重要人类疾病,对于这些疾病而言,早期检测可以显著改善寿命和生活质量。
[0411]
如实施例1a中所述制备脂质体。
[0412]
如实施例1a中所述进行人血浆收集,制备和储存。
[0413]
如实施例1a中所述制备组血浆样品。
[0414]
透射电子显微术(tem)。如前所报告,脂质体制剂已通过tem表征。简言之,将10μl每种样品沉积在formvar包被的网格上,使用1%乙酸铀酰负染,用超纯水洗涤,并风干。用zeiss libra 120进行测量,并用imagej软件进行图像分析。
[0415]
如实施例1a中详述的确定尺寸和ζ电位。
[0416]
如实施例1a中所述进行蛋白质测定。
[0417]
如实施例1a中那样进行蛋白质鉴定和定量。未加权的谱计数(usc)用于评估定量分析中生物重复的一致性,并且使用标准化的谱计数(ncs)来检索蛋白质丰度。
[0418]
统计学分析。主要文本中的所有统计学分析都是使用scikit-learn,numpy和
scipy包在python中执行的,图和照片是使用python中的散景包以及microsoft excel,xlstat和matlab创建的。
[0419]
数据矩阵。对于标记为i=1,...,60的所有60个血浆样品(45个非组和15个组),生成数据矩阵xi(具有3行和约900列),使得矩阵的每行对应于从蛋白质冠纳米系统获得的单个纳米颗粒的蛋白质丰度。作为预处理步骤,我们通过标准化所有矩阵的行将蛋白质丰度转换为相对蛋白质丰度(rpa)。
[0420]
分类和聚类
[0421]
张量因子分解。我们将数据处理为三模张量,前两模对应于纳米颗粒和蛋白质,第三模对应于血浆样品;这基本上等同于将对应于每个样品xi的观察矩阵堆叠在彼此之上。使用该项目在python中实施的代码(可根据要求提供学术用途),通过低tucker秩张量因子分解(135,136,137)对数据进行去噪。每个矩阵xi由采用以下形式的张量分解近似
[0422]
xi~us
ivt
,
[0423]
其中u是矩阵,其行可以被视为对应于每个纳米颗粒的潜在特征,并且类似地,v是矩阵,其行可以被视为对应于每种蛋白质的潜在特征;这些潜在特征在所有数据矩阵中共有。最后,每个si是编码纳米颗粒和蛋白质特征之间的相互作用的矩阵,并且这些在样品之间是独特的。我们通过两个步骤估计这种分解:我们(a)通过对张量的模-1和模-2展开的截断奇异值分解来估计u和v,然后给出这些估计,我们(b)通过最小二乘计算分开拟合每个si矩阵。
[0424]
随机森林分类。随机森林模型是众所周知的用于分类的机器学习算法。随机森林由多个决策树组成,每个决策树根据相对较少的变量做出简单的分类决策。这些树是用不同的、随机绘制的变量亚组创建(或“训练”)的,这样很可能没有两个树是相同的。给定一个新样品,每个树都是自上而下遍历的,直到一组训练样品到达底部。将森林作为一个整体用于分类等于让多个决策树在标记上“投票”(在这种情况下,五种癌症类型中的一种,或者健康),其中每个树的投票是来自训练样品的底部组的标记。对于我们自己的算法,每个随机森林由1000个决策树组成,并使用scikit-learn包进行训练。重要性分数也使用相同的包计算。
[0425]
实施例2.用于检测疾病的附加传感器阵列构造
[0426]
制备由12种不同的交叉反应性纳米颗粒组成的传感器阵列,包括三种脂质体,三种超顺磁性氧化铁纳米颗粒和六种金纳米颗粒。根据我们之前的报道合成具有负、中性和正表面电荷的这些类型的脂质体(dopg(1,2-二油酰基-sn-甘油-3-磷酸-(1
′‑
rac-甘油)),dotap(1,2-二油酰基-3-三甲基铵-丙烷)-dope(二油酰磷脂酰乙醇胺),和chol(dopc-胆固醇))。从获得20nm尺寸和各种peg分子量(即300,3000和6000)的超均匀peg涂覆的超顺磁性氧化铁纳米颗粒。合成具有约2nm核心尺寸和不同表面官能度的金纳米颗粒。
[0427]
所有纳米颗粒具有相同的尺寸但具有不同的表面性质,预期其响应于患有各种类型的癌症的患者的血浆而形成明显不同的蛋白质冠组成。传感器阵列探测蛋白质冠传感器阵列通过患者的血浆蛋白质鉴定和区分癌症类型的能力,如实施例1中所述。
[0428]
探测来自多种癌症的样品,包括肺癌,胰腺癌,骨髓瘤,脑膜瘤,胶质母细胞瘤,食道鳞状细胞癌和胃腺癌。设计基于不同纳米颗粒(脂质体,氧化铁和金)的蛋白质冠阵列用于探测各种癌症类型中生物分子指纹的变化。传感器测定还将允许鉴定作为特定类型癌症
的标志物的蛋白质,包括针对不同癌细胞类型的新的和未知的生物标志物。可以基于不同类型的癌症或癌症阶段确定的模式识别。
[0429]
将分析来自健康人的各种人血浆,其在血浆收集后几年被诊断出患有各种类型的癌症。血浆样品通过nih资助的组研究,即golestan组研究收集,该研究由美国国家癌症研究所(nci),法国国际癌症研究机构(iarc)和伊朗的德黑兰医学大学(tums)进行。该研究涉及收集和储存来自50,000个健康对象的血浆。在随后的几年中,超过1,000个这些对象继续发展各种类型的癌症。样品存储在iarc,供我们的团队用于分析。这些重要的血浆样品为我们提供了探索我们创新的蛋白质冠传感器阵列用于早期检测癌症的能力的独特机会。此外,我们还将评估和鉴定可用于鉴定和区分这些癌症的蛋白质。
[0430]
我们相信,将这种创新的传感器阵列应用于组血浆样品的结果不仅有助于早期阶段的癌症检测和筛查,还有助于识别癌症发展中涉及的新蛋白质标志物。与其他开发的方法相比,我们的传感器阵列组件选择具有更特殊的能力,以非特定,交叉反应的方式为广泛各种蛋白质提供指纹,以识别和区分癌症。
[0431]
使用来自中期和晚期癌症患者的血浆探测传感器阵列元件的硬冠概况:
[0432]
在传感器阵列元件的表面上形成的蛋白质冠的组成强烈地依赖于那些纳米颗粒的物理化学性质,并且同时可能受到存在于用于孵育的人血浆供体中的疾病类型的强烈影响。为了制备冠涂覆的纳米颗粒,将制备的12种纳米颗粒与九种类型的癌症(肺癌,胰腺癌,骨髓瘤,骨髓性白血病,脑膜瘤,胶质母细胞瘤,乳腺癌,食道鳞状细胞癌和胃腺癌)的人血浆(分开)一起孵育并通过明确的离心方法从游离蛋白中分离出来。离心通常在15℃下以13000g进行30分钟。除去上清液,将收集的颗粒再分散在500微升pbs中。重复该过程以除去松散附着的蛋白质。为了从纳米颗粒表面除去松散附着的蛋白质,将收集的纳米颗粒再分散在冷pbs(15℃)中并通过离心收集。然后使用dls/nanosight确定冠包被的纳米颗粒的尺寸和电荷,并将其与在缓冲液中获得的初始值进行比较。吸附在纳米颗粒上的总蛋白质的定量评估将通过bca或nanoorange测定进行,而定性鸟枪蛋白质组学分析鉴定吸附在12种纳米颗粒表面上的蛋白质。简言之,在从纳米颗粒表面分离蛋白质后(根据方案(saha,k.;rahimi,m.;yazdani,m.;kim,s.t.;moyano,d.f.;hou,s.;das,r.;mout,r.;rezaee,f.;mahmoudi,m.acs nano 2016,10,(4),4421-4430,通过引用纳入),将蛋白质注入液相色谱-质谱(lc-ms/ms)设备。通过筛选相关数据库,从得到的数据中鉴定出蛋白质。为了获得归因于匹配蛋白质的所有肽的lc-ms/ms谱图的总数,将通过光谱计数(spc)进行对来自对蛋白质量的累积拟合的定量评估的半-a多分散指数。lc-ms/ms谱图中鉴定的每种蛋白质的标准化spc(npspc)量将使用以下等式计算:
[0433][0434]
其中npspck是蛋白质k的光谱计数的标准化百分比(即离子的原始计数),spc是光谱计数,mw是蛋白质k的分子量(以kda计)。
[0435]
开发监督式和无监督式聚类分析,以使用传感器阵列结果识别和区分癌症:
[0436]
为了研究各种传感器元件的蛋白质冠指纹(pcf)是否可以用作生物传感器并形成
针对不同疾病的独特模式(生物分子冠特征),我们对三种脂质体的蛋白质冠组成(阳离子,阴离子,和中性)的蛋白质组学数据应用了重点分类方法,如实施例1中所述。
[0437]
实施例3.纳米颗粒与基材耦合以制备传感器阵列。
[0438]
在本发明的实践中,不同类型的颗粒可用作纳米级传感器元件。此外,提供了将纳米级传感器元件与基材耦合的不同方法。另外,纳米级传感器元件可以以不同的模式附着到基材。
[0439]
在图15-43中举例说明了不同基材上的传感器元件的不同构造的具体示例。
[0440]
实施例4.用于筛查癌症的包含二氧化硅和聚苯乙烯纳米颗粒的传感器阵列
[0441]
该实施例证明,具有与实施例1中使用的纳米颗粒不同的纳米颗粒的本发明的传感器阵列仍然能够检测来自健康患者样品的癌症样品。
[0442]
利用实施例1的实验方案,使用官能化二氧化硅和聚苯乙烯颗粒设计传感器阵列。在该实施例中,使用总共六种纳米颗粒:两种纳米颗粒类型,即聚苯乙烯(p)和二氧化硅(s),具有三种不同的表面官能化,即无,胺改性和羧基改性(p-nh2,p-cooh,s-nh2和s-cooh)。
[0443]
具有不同官能化(无,胺改性(nk2)和羧基改性(cooh)的裸聚苯乙烯和二氧化硅纳米颗粒的表征显示在图44a-44d中,显示它们的尺寸,裸颗粒的dls和ζ电位以及tem图像。具有不同官能化的蛋白质冠包被的聚苯乙烯和二氧化硅纳米颗粒的表征在图45a-45d中以负载蛋白质冠的聚苯乙烯和二氧化硅纳米颗粒的尺寸,dls,ζ电位和tem进行了说明。
[0444]
将6个纳米颗粒传感器阵列与健康个体或患有直肠癌,乳腺癌,膀胱癌,甲状腺癌,子宫癌,卵巢癌,肾癌(每个癌症5个患者)的患者的血浆接触,如图46中通过实施例1所述的方法所述。通过sds page分析聚苯乙烯和二氧化硅纳米颗粒(100nm)的蛋白质冠概况。通过sds page比较普通,胺修饰的和羧基修饰的颗粒的蛋白质冠,如图47所示。
[0445]
通过sds-page分析的聚苯乙烯和二氧化硅纳米颗粒(100nm)的健康血浆的蛋白质冠概况显示在图48中。普通,胺修饰的和羧基修饰的颗粒的蛋白质冠的比较。
[0446]
如实施例1所述分析数据。统计分析和聚类结果如图49所示。如图所示,健康个体能够对比癌症患者而被鉴定和分类(健康对照在正交空间中对比癌症患者样品,如图49所示)。
[0447]
该实施例证明,使用六纳米颗粒阵列的该传感器阵列可以从健康个体中区分和检测患有癌症的患者。
[0448]
材料:三种不同功能化的二氧化硅颗粒购自kisker-products(https://www.kisker-biotech.com/);三种不同官能化的聚苯乙烯颗粒购自聚合科学公司(polyscience,inc.)(http://www.polysciences.com/)。所有颗粒具有相同的尺寸(100nm)。通过tem,dls和ζ电位测量表征它们的形态,平均尺寸,多分散指数(pdi)和ζ电位。
[0449]
实验信息:在50%人健康血浆中孵育1小时。sds page:4-20%丙烯酰胺45分钟40ma/凝胶。染色:胶体考马斯蓝过夜。使用的纳米颗粒:0.5mg)。
[0450]
实施例5.蛋白质冠传感器阵列纳米系统识别冠状动脉疾病
[0451]
冠状动脉疾病(cad)是最常见的心脏病类型,并且代表了男性和女性的主要死亡原因。早期发现cad对于预防死亡,延长患者生存期和改善患者生活质量至关重要。该实施例描述了包含六种纳米颗粒的非侵入性传感器阵列纳米系统,其用于使用特定pc模式识别
来进行cad的超精密检测。虽然单个纳米颗粒的pc不能提供所需的特异度,但是具有不同表面化学性质的六种不同纳米颗粒的多变量pc提供了选择性区分所研究的每种心血管病症的理想信息。
[0452]
cad是一种慢性病,在青春期开始,并在受影响的人的整个生命中逐渐发展。其特征在于冠状动脉中存在动脉粥样硬化斑块。动脉粥样硬化的发生在于内皮功能障碍:当受到应激刺激和炎症因子(例如氧化应激和血液动力推动)时,内皮细胞表达表面粘附分子,诱导循环白细胞和含有低密度脂蛋白(ldl)的胆固醇的募集5。这些事件诱导动脉粥样硬化斑块的形成,这使得冠状动脉变窄并因此损害血流。根据斑块发展的速度和动脉阻塞的严重程度,症状最终可能导致心肌梗死5。
[0453]
在风险对象中准确及时地诊断cad对于迅速开始临时治疗并避免进一步并发症非常重要。冠状动脉造影是迄今为止最准确和最值得信赖的cad诊断方法。然而,将导管插入手臂(或颈部或上部紧固(upper tight))的动脉直至心脏是侵入性的、昂贵的并且引起许多副作用,包括感染,导管动脉损伤,过敏和过度出血。因此,迫切需要开发用于cad检测的新测试。虽然已经报道了几种炎症生物标志物可用于诊断,但遗憾的是,它们都没有用于临床实践,突出了对新诊断测试仍然有非常普遍的需求。发明人已经开发了基于纳米的血液测试作为用于诊断cad的新工具。
[0454]
如先前的癌症实施例中所证明的,个性化pc充当给定血浆条件的指纹。该实施例使用相同的方法通过其诱导的血浆组成变化准确地确定动脉粥样硬化斑块的形成。实际上,斑块相关细胞(例如泡沫细胞,巨噬细胞,肥大细胞,单核细胞和t细胞)将大量生物分子(例如,细胞因子,蛋白酶和血管活性生物分子)排出到血液中
22
,并因此可诱导相对于没有斑块形成的患者的pc,各种纳米颗粒表面的pc组成模式的变化。
[0455]
该实施例使用来自i)在冠状动脉血管造影(cad)后被诊断患有cad的患者,ii)经过冠状动脉血管造影并且其冠状血管被发现健康的患者(无cad),iii)再狭窄(治疗后cad复发)和iv)没有心血管疾病的风险因素(如家族史,烟草使用,肥胖,高血压)的健康志愿者(对照组)的血浆来分析在纳米颗粒周围形成的pc。
[0456]
为了获得更广谱的吸附蛋白质,该实施例使用六种可商购的纳米颗粒作为传感器阵列元件,具有不同的组成和表面化学和/或功能化,产生能够用作简单非侵入性诊断测试的基于6纳米颗粒pc的传感器阵列。这种新颖的诊断性cad测试用作风险患者的非侵入性筛查。值得注意的是,这些结果表明pc模式允许对于cad,无cad,再狭窄和对照患者之间的超精确区分,从而提供了一种新的,精确的,非侵入性的,之前从未开发过的基于血液的cad诊断工具。
[0457]
结果
[0458]
在该实施例中,使用总共六种纳米颗粒:两种纳米颗粒类型,即聚苯乙烯(p)和二氧化硅(s),具有三种不同的表面官能化,即无,胺改性和羧基改性(p-nh2,p-cooh,s-nh2和s-cooh),如图50中所述。测量了在血浆中孵育之前和之后的纳米颗粒的尺寸,ζ电位和形态,以比较裸纳米颗粒的合成特性与其相应的生物特性(pc包被的纳米颗粒)之间的结果差异。动态光散射分析显示裸纳米颗粒都是高度单分散的,如多分散指数≤0.02所示,并且尺寸均匀为约100nm,在93nm至120nm的范围内(图50a)。在与患者的血浆孵育1小时后,由于存在一层吸附的蛋白质(pc),所有纳米颗粒的尺寸增加,其厚度和组成已经证明依赖于蛋白
质浓度,表面性质和纳米颗粒的尺寸。所有裸纳米颗粒都具有负表面电荷(图50b),由于正胺基的贡献,那些胺官能化的负性略低于其他的。这些结果符合供应商和其他研究提供的规范。用胺基改性不足以转换二氧化硅和聚苯乙烯纳米颗粒的表面电荷,其特征在于在生理ph下其表面上的所有带负电荷的残基。
[0459]
一旦暴露于血浆,由于在生理ph下大多数血浆蛋白的电荷,所有表面电荷变得更小负值(从-5mv到-25mv)。总体而言,pc包被的纳米颗粒的物理化学性质显示出类似的趋势,与其裸对应物相比总是更大且更小负值,而与用于孵育的血浆无关。然而,当与无cad血浆孵育时,p和s纳米颗粒表现出≈85nm的尺寸增加,大于使用其他条件(40-50nm)的血浆所显示的大小。另一方面,与cad血浆一起孵育的s-nh2纳米颗粒的pc厚度比来自相同纳米颗粒与其他血浆类型(≈30nm)孵育的那些更大(≈40nm)。透射电子显微镜显示纳米颗粒在血浆中孵育后不改变其形态和结构(图50c)。此外,观察到包被后尺寸的增加,从而证实了通过动态光散射获得的结果。通过bradford测定评估不同pc的蛋白质浓度,显示总体上所有二氧化硅纳米颗粒在pc中吸附的蛋白质少于聚苯乙烯纳米颗粒(图51a)。通过1d-sds page分析pc证实了这一观察结果。已经使用cad,无cad和没有cad风险(control)的5个患者来收集血浆,并且将针对所有纳米颗粒获得的pc分解到考马斯染色的sds page凝胶上(图51b)。已经通过光密度测定法分析凝胶,并且已经检测到相同纳米颗粒的cad,无cad和对照pc中蛋白质量的差异(图51c,箭头)。在一些情况下,我们还注意到特定pc中某些蛋白质的存在和/或不存在(图51c,蓝色箭头)。这些结果证实,动脉粥样硬化斑块的形成诱导血浆组成的变化,并因此导致pc的差异。通过lc-ms/ms分析来分析蛋白质冠。在每个pc包被的纳米颗粒样品中已经鉴定出超过150种蛋白质。此外,光谱计数值代表了归因于特定蛋白质的所有肽的片段谱的总数,已被用于获得有关蛋白质丰度的信息,并因此获得每种鉴定蛋白质在pc中的百分比贡献。在图52中报道了pc中前20种丰富蛋白质的百分比贡献的差异。结果证明了pc组成,血浆条件,纳米颗粒的类型和表面官能化之间的相关性。
[0460]
从所有样品获得的数据已经被收集,分析和分类:通过级联(concatenate)纳米颗粒,表面改性,血浆类型和标记产生每个测量的关键。用少于2个肽鉴定的蛋白质被排除在考虑范围之外,并且使用tibco spotfire analyst 7.6.1来旋转数据,以便由蛋白质加入来识别行,由关键和包含百分比贡献的值来识别列。
[0461]
除了数学分析,我们还分析了给定条件下冠中排他性蛋白质的存在。为此,我们创建了venn diagrams,它有助于研究蛋白质或基因的大数据集中的常见和独特蛋白质。已经分别分析了总共6个分类的每个纳米颗粒的pc。我们通过比较cad,无cad和对照的所有5个患者衍生pc的共同蛋白质来寻找排他性(专有)蛋白质。我们的结果表明,对于本研究中使用的每种纳米颗粒,各种特定蛋白质仅在特定pc模式中被排他性地鉴定。其中,参与调节补体激活的几种蛋白质(补体因子h相关蛋白3,补体成分c8γ)仅在cad患者的pc模式中被排他性地鉴定。该结果与最近描述的补体激活在心血管疾病(动脉粥样硬化,斑块破裂和血栓形成的发展)的发病机理中的作用一致。另一个示例是载脂蛋白(a),它被认为是用于cad临床实践的有吸引力的生物标志物候选物,我们仅在cad患者的pc模式中排他性地检测到。载脂蛋白(a)是脂蛋白(a)的主要成分,众所周知,其经历蛋白水解切割并且其片段在动脉粥样硬化斑块中积累。
[0462]
我们通过分析9个盲血浆样品(每个条件3个和3个对照),证实了该方法在鉴别cad
和无cad患者方面的准确度。pc围绕我们的pc传感器阵列纳米系统的6个纳米颗粒形成。然后,已通过lc-ms/ms(支持信息)鉴定pc中的蛋白质,并使用相同的分类和聚类方法分析结果。
[0463]
统计和数据分析在图54中以图形表示,显示了cad,无cad和对照(没有cad风险)的分类的离散分离。
[0464]
总之,我们已经证明了用于检测cad的6纳米颗粒pc传感器阵列的准确度。在这项工作中开发的pc传感器阵列纳米系统在cad,再狭窄,无cad和健康个体的鉴别中也被证明是敏感和准确的,这进一步显示了其作为临床环境中使用的技术平台的巨大潜在价值。实际上,尽管存在许多通常与动脉粥样硬化斑块相关的症状,但该研究中的在研无cad组患者的动脉中没有任何阻塞。
[0465]
由该平台产生的pc模式代表独特的多变量指纹,其比使用单个纳米颗粒的pc获得的指纹更准确和广谱。这里介绍的方法不仅可以有检测cad的大价值,还可以检测其他各种人类疾病,从而提高许多患者的生活质量。特别是由于测试的非侵入性,我们设想与血管造影术相比,患者将更加自愿和更频繁地使用这样的测试。与血管造影不同,该测试易于管理且无副作用,允许患者从最初的症状检查动脉状态,并且由于早期检测而显著减少cad并发症。
[0466]
方法
[0467]
纳米颗粒。三种不同功能化的二氧化硅颗粒购自kisker-products(https://www.kisker-biotech.com/);三种不同官能化的聚苯乙烯颗粒购自聚合科学公司(polyscience,inc.)(http://www.polysciences.com/)。所有颗粒具有相同的尺寸(100nm)。通过tem,dls和ζ电位测量表征它们的形态,平均尺寸,多分散指数(pdi)和ζ电位。
[0468]
蛋白质冠形成。通过将0.5mg纳米颗粒在去离子水中与相同体积的人血浆一起孵育来产生pc。孵育在37℃,搅拌下进行1小时。孵育后立即在14,000rpm和10℃下离心30分钟以形成沉淀。接下来,将沉淀洗涤并在4℃下悬浮于200μl磷酸盐缓冲盐水(pbs)中。在相同的先前条件下重复离心测量三次。将pc包被的纳米颗粒的沉淀重悬于8m尿素,50mm碳酸氢铵中,随后进行sds-page凝胶和lc/msms分析或在去离子h2o中随后分析尺寸和ζ-电位。
[0469]
纳米颗粒表征。裸露和蛋白质冠包被的纳米颗粒的尺寸和ζ-电位已经通过在1m1总蒸馏水中稀释10μl每种样品来表征。使用zetasizer nano zs90(英国马尔文公司)进行测量。尺寸和表面电荷值以三次独立测量的平均值
±
s.d给出。
[0470]
蛋白质浓度测定。使用已知浓度的牛血清白蛋白作为标准物以构建5点标准曲线(r2=0.99),通过bradford测定法(bio-rad)测定冠中蛋白质的量。将蛋白质浓度记录为三次实验的平均值
±
s.d。
[0471]
1d-sds page凝胶。将冠中的蛋白质溶于8m尿素,50mm碳酸氢铵中。将等量的laemmli缓冲液2x加入到沉淀中并在90℃下加热5分钟,然后加载并分解到4-20%tgx
tm
预制凝胶(加利福尼亚州赫尔克里斯的伯乐实验室公司(bio-rad laboratories))上,在120v下持续1小时。将蛋白质用考马斯亮蓝(美国新泽西费尔劳恩的飞世尔科技公司(fisher scientific))染色过夜,然后在超纯水中充分洗涤。
[0472]
质谱/统计学/pls-da。如实施例1中所述进行质谱,统计分析和pls-da。
[0473]
实施例6.用于在早期检测阿尔茨海默病的多纳米颗粒蛋白质冠测试
[0474]
阿尔茨海默病的病变在检测到临床症状之前数十年开始。对阿尔茨海默病的准确和非侵入性早期诊断的需求正在迅速增长。为了解决这个问题,开发了一种先进的传感器阵列纳米系统,它成功地检测了血浆蛋白质模式的微小变化,并使用聚类技术来确定阿尔茨海默病的存在。由于传感器阵列为每种由于疾病引起的血浆蛋白质组变化创建了独特的指纹,并且与当前技术不同,其灵敏度足以捕获这些变化,因此该开发的技术还可以在将来应用于诊断其他疾病。
[0475]
如前面实施例中所讨论的,pc的组成基于血浆蛋白质组而改变,其可以由于疾病而改变,这产生“个性化蛋白质冠”(ppc)。然而,ppc不能提供用于疾病早期检测的稳健且精确的策略,这主要是由于蛋白质冠组成中相似蛋白质的巨大重叠。在这项研究中,使用在含有六个纳米颗粒的多np平台周围形成的ppc,我们提供了指纹-模式,用于以前所未有的预测准确度和特异度对ad的稳健和精确检测。开发的传感器阵列测试成功地区分了有和没有ad的患者,以及几年后发展ad的患者(使用组血浆)。该实施例提供了当前ad检测的可行的非侵入性替代方案,允许提供无与伦比的早期检测和治疗的能力。
[0476]
结果和讨论
[0477]
传感器阵列测试由将血浆样品与6种不同的纳米颗粒一起孵育组成。后者是100nm聚苯乙烯和二氧化硅纳米颗粒,每种都具有可调节的表面化学性质(普通,-氨基和-羧基耦合的,在下文称为p,p-nh2,p-cooh,s,s-nh2,s-cooh)和如实施例5中所述用于cad分析的窄尺寸分布。作为最初的概念验证,为了寻找ad和对照血浆之间的差异,已经分析了在pc形成之前和之后纳米颗粒的尺寸,表面电荷和形态。纳米颗粒跟踪分析(nanosight)已被用于表征纳米颗粒的尺寸。在这样的分析期间,激光束照射纳米颗粒,通过光学显微镜从该纳米颗粒可视化散射光。同时,通过与光束对准的照相机记录视频,显示了纳米颗粒的移动(30-60帧/秒)。在血浆中孵育之前,所有纳米颗粒的尺寸均匀(图58,聚苯乙烯纳米颗粒90-100nm;二氧化硅纳米颗粒80-100nm),具有与制造商提供的一致的负表面电荷(表8)。在37℃下在血浆中搅拌下孵育1小时后,通过离心回收pc包被的纳米颗粒,然后进行大量洗涤以除去未结合的和松散附着的蛋白质。在所有情况下,我们揭示了pc包被的纳米颗粒的尺寸增加和更宽的尺寸分布,这表明不均匀的群体(图54,散点图)。尺寸的平均增加30nm,因此表明pc层的厚度为15nm,这与文献1中报道的数据和使用来自健康志愿者的血浆观察到的数据一致(数据未显示)。纳米颗粒表面上的血浆蛋白的存在诱导其电荷的变化,其变得较小负值,达到血浆蛋白质的典型值(-20mv至-0mv至表8)。
[0478]
表8:裸纳米颗粒或接触血浆后的纳米颗粒的ζ电位
[0479][0480]
观察到与ad血浆和健康血浆一起孵育的相同纳米颗粒的表面电荷的轻微差异(表8)。然而,这些差异并不大,因此不能用于区分不同血浆的条件。透射电子显微镜(tem)也用于评估纳米颗粒的形态,其在pc形成后保持不变。实际上,在用血浆孵育之前和之后,所有纳米颗粒都具有圆形均匀的形状(图55)。观察到与pc包被的纳米颗粒的尺寸增加相关的薄蛋白质层的存在,证实了nanosight获得的结果(图55)。
[0481]
通过凝胶电泳(sds-page)解析与颗粒相关的pc,随后通过用考马斯亮蓝染色显现(图56)。通常,通过视觉评估泳道,6种纳米颗粒具有不同的pc模式,这是我们的方法的最佳性能所预期和期望的。与聚苯乙烯纳米颗粒相比,二氧化硅纳米颗粒在其表面上吸附的蛋白质似乎较少。在大多数样品中,普通聚苯乙烯的pc在分子量≈60kda的蛋白质中比其他样品更富集,这很可能归因于白蛋白。对于ad患者的血浆和对照血浆都是如此(图56,箭头)。对每个pc相关的条带的光密度分析证实,二氧化硅纳米颗粒通常吸附较少量的蛋白质,但也表明更多的蛋白质构成其pc:例如,对于聚苯乙烯纳米颗粒的pc在白蛋白水平上存在超过一个条带(图56,箭头)。另一方面,在ad患者和健康个体的ppc概况中记录了若干差异,特别是在二氧化硅纳米颗粒的情况下(图56,箭头)。然而,这些差异在统计学上并不显著,不足以准确区分正在研究的两组患者。为了更深入研究pc并了解构成不同pc的蛋白质的确切种类和数量,所有样品都已通过质谱分析。广泛用于纳米颗粒周围的pc的定量分析
2-4
的光谱计数无标记分析用于确定每种蛋白质在pc中的百分比贡献。对于每个血浆患者进行六次该计算(与每个纳米颗粒分开孵育),从而允许形成ad特异性pc概况,其衍生自与六种纳米颗粒相关的pc的贡献的组合。表9描述了使用的患者群。
[0482]
表9:在该实施例中使用的血浆的来源患者的信息。
[0483][0484][0485]
结论
[0486]
这项工作代表了一项概念验证研究,用于开发用于诊断ad的mnpc血液检测。mnpc测试显示出前所未有的预测准确度和特异度。虽然个别生物标志物血液基检测往往与假阳
性相关,因此需要进一步分析以确认诊断,我们的方法记录了所有高亲和性的蛋白质与设定6种纳米颗粒之间的相互作用,从而允许创建特定疾病的高特异度pc指纹图谱。纳米颗粒作为在其表面上的血浆蛋白质(每个纳米颗粒以趋向其表面更高的亲和力浓缩血浆蛋白质)的纳米集中器:这有助于其水平仅在病理条件下相对于健康状态略有变化的蛋白质的启示。这些微小变化可能属于高丰度和低丰度血浆蛋白。在这项研究中,我们报告了相对较少的患者,因为每位患者的血浆使用不同的纳米颗粒进行了6次分析,因此每位患者获得的结果比进行单次分析时获得的结果的特异度高6倍。
[0487]
材料和方法
[0488]
纳米颗粒。二氧化硅颗粒(普通的,氨基和羧基耦合的)购自kisker-products(https://www.kisker-biotech.com/)。聚苯乙烯颗粒(普通的,氨基和羧基耦合的)由购自聚合科学公司(http://www.polysciences.com/)。根据制造商的说法,所有颗粒都具有相同的尺寸(90-100nm)。它们的形态,平均尺寸和ζ电位的特征如本节后面所述。
[0489]
个性化蛋白质冠形成。
[0490]
通过将0.5mg纳米颗粒在去离子水中与相同体积的人血浆一起孵育来产生pc。孵育在37℃,搅拌下进行1小时。孵育后立即通过离心(14,000rpm和10℃持续30分钟)回收pc包被的纳米颗粒,并在冷的磷酸盐缓冲盐水(pbs)中充分洗涤以除去未结合或弱结合的蛋白质。将pc包被的纳米颗粒的沉淀重悬于8m尿素,50mm碳酸氢铵中,用于进行sds-page凝胶和lc/msms分析或在去离子h2o中用于动态光散射和ζ-电位分析。
[0491]
纳米颗粒的物理化学表征。通过纳米颗粒跟踪分析(nanosight,英国马尔文公司)测量尺寸。该软件根据裸和pc包被的纳米颗粒的ζ-电位计算尺寸,以使用zetasizer nano zs90(马尔文公司)测定。在分析之前将纳米颗粒在水中稀释至50μg/ml的浓度。尺寸和表面电荷值以三次独立测量的平均值
±
s.d给出。对于透射电子显微镜(tem)分析,样品和网格已用1%乙酸铀酰标记。使用配备有amt 2k ccd相机的tecnai g2 spirit biotwin透射电子显微镜。
[0492]
一维凝胶电泳。将个性化蛋白质冠溶于8m尿素,50mm碳酸氢铵中。将等量的laemmli缓冲液2x加入到沉淀中并在90℃下加热5分钟,然后加载并分解到4-20%tgx
tm
预制凝胶(加利福尼亚州赫尔克里斯的伯乐实验室公司(bio-rad laboratories))上,在120v下持续1小时。将蛋白质用考马斯亮蓝(美国新泽西费尔劳恩的飞世尔科技公司(fisher scientific))染色过夜,然后在超纯水中充分洗涤。由imagej(网站:imagej.nih.gov/ij/)对带强度进行光密度分析。
[0493]
通过质谱鉴定和定量蛋白质。将蛋白质用10mm二硫苏糖醇(西格玛公司(sigma))在56℃还原1小时,然后用55mm碘乙酰胺(美国密苏里州圣路易斯的西格玛-奥德里奇公司(sigma-aldrich))在25℃避光烷基化1小时。然后用改良的胰蛋白酶(美国威斯康星州麦迪逊的普罗麦格公司(promega))在100mm乙酸铵,ph 8.9,25℃下以1:50的酶/底物比率过夜消化蛋白质。通过加入乙酸(99.9%,西格玛-奥德里奇公司)至5%的终浓度来终止胰蛋白酶活性。使用c18 spintips(西弗吉尼亚州摩根敦的protea公司)将肽脱盐,然后真空离心并在-80℃下储存直至分析当天。使用预柱(内部制造,6cm的10μm c18)和自包装5μm尖端分析柱(12cm的5μm c18,兴悟杰公司(new objective))在140分钟梯度上通过反相hplc(沃特汉姆的赛默飞世尔公司(thermo fisher),ma easy nlc1000),然后使用qexactive质谱仪
(赛默飞世尔公司)进行纳米电喷雾之前的新目标分离肽。。溶剂a为0.1%甲酸,溶剂b为80%mecn/0.1%甲酸。梯度条件为2-10%b(0-3分钟),10-30%b(3-107分钟),30-40%b(107-121分钟),40-60%b(121-126分钟),60-100%b(126-127分钟),100%b(127-137分钟),100-0%b(137-138分钟),0%b(138-140分钟),并且质谱仪以数据依赖方式运行。全扫描ms的参数是:350-2000m/z的分辨率为70,000,agc 3e6和最大it 50ms。全ms扫描之后是每个循环中前10个前体离子的ms/ms,nce为28,动态排除30秒。使用proteome discoverer(赛默飞世尔公司)和mascot版本2.4.1(矩阵科学公司(matrix science))搜索原始质谱数据文件(.raw)。mascot搜索参数为:前体离子的10ppm质量耐受性;用于片段离子质量公差的15毫克单位(mmu);2个错失的胰蛋白酶的分裂;固定修饰为半胱氨酸的氨甲酰甲基化;可变的修饰是甲硫氨酸氧化。数据分析中仅包括mascot评分≥25的肽。通过将选择用于每种蛋白质片段化的肽的总数相加来进行光谱计数。
[0494]
实施例7.颗粒尺寸影响蛋白质结合量
[0495]
该实施例证明,使用由相同材料制成的不同尺寸的纳米颗粒为每种尺寸提供不同的生物分子指纹。将三种不同直径(100nm(0.1μm),3μm和4μm)的二氧化硅纳米颗粒与相同的血浆样品一起孵育。通过sds-page分析珠。如图58所示,珠越大,生物分子特征中包含的蛋白质越多。此外,每个珠尺寸具有不同的生物分子冠特征,因此仅不同尺寸的纳米颗粒的组合允许形成不同的生物分子指纹。如图所示,三种不同尺寸的珠之间的模式或蛋白质存在不同的差异。
[0496]
可以使用不同尺寸的纳米颗粒制造传感器阵列,每个纳米颗粒将给出不同的生物分子指纹。
[0497]
实施例8.传感器阵列可提供包含核酸的生物分子指纹
[0498]
传感器阵列和相关的生物分子冠特征以及蛋白质含有构成生物分子冠的核酸。该实施例证明了与具有中性表面纳米颗粒的二氧化硅纳米颗粒结合的核酸的组成。将纳米颗粒与血浆一起孵育,并分析相关的核酸(图59)。图60和61描绘了所有样品中核酸的分析及其在血浆中的含量(血浆中的核酸量为33.8pg/μl)。分析了与纳米颗粒相关的生物分子冠的核酸含量。使用尿素将蛋白质从纳米颗粒中解离,随后分析核酸(图62,核酸量14.0)或蛋白质未从冠解离并分析核酸(图63,14.4pg/μl)。或者,可以将纳米颗粒与用血浆试剂盒从血浆中纯化的核酸一起孵育,然后与裸颗粒一起孵育(图64,核酸量13.2pg/μl)。
[0499]
结果揭示了纳米颗粒吸附生物分子冠组成中的核酸的能力。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1