疾病鉴别支援方法、疾病鉴别支援装置以及疾病鉴别支援计算机程序与流程
1.在本说明书中,公开疾病鉴别支援方法、疾病鉴别支援装置以及疾病鉴别支援计算机程序。
背景技术:
2.疾病的鉴别是通过检查从被检者获取到的检体而进行的。例如,在非专利文献1中,公开有根据在下一代测序中获取的基因表现,进行“骨髓增生性肿瘤”(myeloproliferative neoplasms:mpn)中的真性红细胞增多症(pv)、原发性血小板增多症(et)、原发性骨髓纤维化症(pmf)的鉴别的方法。
3.现有技术文献
4.非专利文献
5.非专利文献1:manja meggendorfer et al.,deep learning algorithms support distinction of pv,pmf,and et based on clinical and genetic markers,blood 2017 130:4223
技术实现要素:
6.但是,以往的用于疾病鉴别的检查需要复杂的检查工序,需要由熟练的检查者进行检查,所以要求新的疾病鉴别的支援方法。
7.本发明的目的在于提供能够支援疾病的鉴别的新的疾病鉴别支援方法、疾病鉴别支援装置以及疾病鉴别支援计算机程序。
8.在本说明书中,公开用于支援疾病的鉴别的疾病鉴别支援方法。在所述疾病鉴别支援方法中,获取通过解析包括从被检者提取的试样中包含的细胞的图像而得到的第1参数,获取与所述试样中包含的细胞的数量有关的第2参数,使用计算机算法,根据所述第1参数以及所述第2参数来生成用于支援疾病的鉴别的鉴别支援信息。
9.在本说明书中,公开用于支援疾病的鉴别的疾病鉴别支援方法。在所述疾病鉴别支援方法中,根据通过解析包括从被检者提取的试样中包含的细胞的图像而得到的第1参数和与所述试样中包含的细胞的数量有关的第2参数,使用计算机算法生成用于支援疾病的鉴别的鉴别支援信息。
10.在本说明书中,公开用于支援疾病的鉴别的疾病鉴别支援装置(200a、200b、100b)。疾病鉴别支援装置(200a、200b、100b)具备处理部(20a、20b、10b)。处理部(20a、20b、10b)获取通过解析包括从被检者提取的试样中包含的细胞的图像而得到的第1参数,获取与所述试样中包含的细胞的数量有关的第2参数,使用计算机算法,根据所述第1参数以及所述第2参数来生成用于支援疾病的鉴别的鉴别支援信息。
11.在本说明书中,公开用于支援疾病的鉴别的计算机程序。在使计算机执行所述计算机程序时,执行具备如下步骤的处理:获取通过解析包括从被检者提取的试样中包含的
细胞的图像而得到的第1参数的步骤;获取与所述试样中包含的细胞的数量有关的第2参数的步骤;以及使用计算机算法,根据所述第1参数以及所述第2参数来生成用于支援疾病的鉴别的鉴别支援信息的步骤。
12.本说明书所公开的疾病的鉴别支援方法、鉴别支援装置以及计算机程序能够利用通过日常在临床检查室等进行的检查方法得到的信息,支援疾病的鉴别。
13.提供新的疾病鉴别支援方法、疾病鉴别支援装置以及疾病鉴别支援计算机程序。
附图说明
14.图1示出用于支援疾病的鉴别的方法的概要。
15.图2示出第1参数群的例子。
16.图3示出第2参数群的例子。
17.图4示出训练数据的例子。
18.图5示出疾病鉴别支援系统1的结构例。
19.图6示出细胞图像解析装置的结构的概略。
20.图7示出具备光学检测部的血球计数装置的结构例。
21.图8示出具备电阻方式检测部的血球计数装置的结构例。
22.图9示出训练装置100a以及疾病鉴别支援装置100b的硬件结构。
23.图10示出训练装置100a的功能结构例。
24.图11示出训练程序的处理的流程。
25.图12示出疾病鉴别支援装置200a、200b以及终端装置200c的硬件结构。
26.图13示出疾病鉴别支援装置200a的功能结构例。
27.图14示出用于支援疾病的鉴别的计算机程序的处理的流程。
28.图15示出疾病鉴别支援系统2的结构例。
29.图16示出疾病鉴别支援装置200b的功能结构例。
30.图17示出疾病鉴别支援系统3的结构例。
31.图18示出疾病鉴别支援装置100b的功能结构例。
32.图19示出基于机器法的疾病的预测结果与医生的诊断的比较。
33.图20示出基于机器法的pv的预测结果的roc曲线。
34.图21示出基于机器法的et的预测结果的roc曲线。
35.图22示出基于机器法的pmf的预测结果的roc曲线。
36.图23示出机器法的预测精度。
37.图24示出基于非专利文献1所记载的算法的预测结果。
38.符号说明
39.200a、200b、100b 疾病鉴别支援装置
40.20a、20b、10b 处理部
具体实施方式
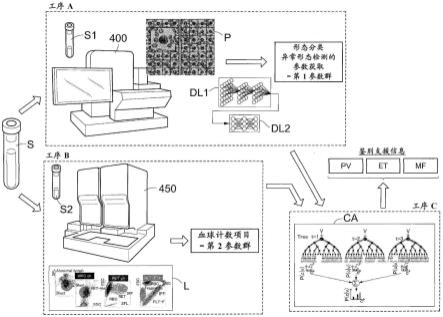
41.以下,参照附图,详细地说明本发明的概要以及实施方式。此外,在以下的说明以及附图中,相同的符号表示相同或者类似的构成要素,因而,省略与相同或者类似的构成要
素有关的说明。
42.1.用于支援疾病的鉴别的方法
43.1-1.支援方法的概要
44.本实施方式涉及用于支援疾病的鉴别的疾病鉴别支援方法(以下,简称为“支援方法”)。支援方法从包含从被检者提取的细胞的试样获取与细胞有关的多种第1参数和多种第2参数,使用计算机算法,根据所述多种第1参数以及所述多种第2参数生成用于支援疾病的鉴别的鉴别支援信息。
45.第1参数从通过解析包括从被检者提取的试样中包含的细胞的图像而得到的解析结果获取。另外,第2参数是与细胞的数量有关的参数,从通过解析从所述试样中包含的细胞得到的光学信号或者电信号而得到的解析结果获取。在本说明书中,与细胞的数量有关的参数除了包括细胞数以外,还包括作为根据细胞数计算出的值的、特定的细胞的每预定量的试样的浓度(例如,每1μl的红细胞的浓度)以及特定的细胞与某个细胞的比率(例如,每100个白细胞的嗜酸性粒细胞的比率)。
46.图1示出支援方法的概要。如图1所示,从被检者提取的试样s被分割为在工序a中的解析中利用的检体s1和在工序b中的解析中利用的检体s2。在工序a中,由细胞图像解析装置400对检体s1中包含的细胞进行摄像,解析所得到的细胞图像p,从而获取由包括与异常发现有关的参数的多种第1参数构成的第1参数群。在工序b中,由血球计数装置450从检体s2中包含的细胞获取光学信号l或者电信号,解析所得到的光学信号l或者电信号,从而获取由包括细胞的每个种类的数量或者比率等的多种第2参数构成的第2参数群。在工序c中,将由多种第1参数构成的第1参数群以及由多种第2参数构成的第2参数群输入到预先训练的计算机算法ca,生成用于支援疾病的鉴别的鉴别支援信息。
47.在本实施方式中,试样中包含的细胞属于预定的细胞群。预定的细胞群是构成人的各器官的细胞群。预定的细胞群在正常的情况下包括通过组织学的显微镜观察、细胞学的显微镜观察在形态学上分类的多个细胞的种类。形态学的分类(还称为“形态分类”)包括细胞的种类的分类和细胞的形态学的特征的分类。优选的是,解析对象的细胞是属于位于预定的细胞群的预定的细胞体系的细胞群。预定的细胞体系是指属于从某一种组织干细胞分化的相同的体系的细胞群。作为预定的细胞体系,优选的是造血系统,作为造血系统细胞更优选的是末梢血细胞或者骨髓细胞。
48.一般而言,在血液检查中,使用从被检者提取的造血系统的试样s,在血球计数装置中测定红细胞数、白细胞数、血小板数、血红蛋白浓度、血细胞比容值、红细胞常数、白血分类值等。另外,特别是在疑似是血液系统的疾病的情况下,除了进行使用了血球计数装置的血球检查以外,还从试样s制作涂抹标本,实际地进行血球细胞的形态观察,检查细胞的形态学的异常的有无。
49.(1)第1参数群
50.在本实施方式中,在图1所示的工序a中,获取第1参数,所以关于从检体s1制作出的涂抹标本上的1个1个细胞,从在显微镜下或者通过滑动扫描仪取入的图像中的细胞进行形态学的特征的抽取。
51.在形态学的特征的抽取中,优选使用实施了明视野染色的标本。明视野染色优选从瑞氏染色、吉姆萨染色、瑞氏吉姆萨染色以及梅吉姆萨染色选择。更优选的是梅吉姆萨染
色。标本只要能够分别观察属于预定的细胞群的各细胞的形态,就不被限制。例如,能够举出涂抹标本以及盖章标本等。优选的是将末梢血或者骨髓液作为试样的涂抹标本。
52.在来自细胞的形态学的特征的抽取中,进行标本上的各个细胞的形态学的分类。另外,在细胞存在异常发现的情况下,进行异常发现的分类。根据细胞的形态学的分类,细胞的种类和试样中包含的同种细胞的比率中的至少一方作为与细胞的形态学的分类有关的参数而被获取。另外,根据异常发现的分类,异常发现的种类和呈现同种异常发现的细胞的比率中的至少一方作为与异常发现有关的参数而被获取。第1参数是与形态学的分类有关的参数和与异常发现有关的参数中的至少一个参数。第1参数群优选是通过1次观察检测到的第1参数的群。图2示出第1参数群的例子。
53.作为与异常发现有关的参数,例如能够举出与从核形态异常、颗粒异常、细胞的大小异常、细胞畸形、细胞破坏、空胞、未成熟细胞、包涵体的存在、杜勒小体、卫星现象、核网异常、花瓣样核、n/c比大、疱疹样形态、斑点以及毛细胞样形态选择的至少一个关联的值。
54.核形态异常可以包括从过分叶、低分叶、假性佩尔格尔核异常(pseudo-pelger anomaly)、环状核、球形核、椭圆形核、细胞凋亡、多核、核破裂、脱核、裸核、核边缘不规则、核断裂、核间桥、复数核、切口核、核分裂以及核小体异常选择的至少一种。
55.颗粒异常可以包括从脱粒、颗粒分布异常、中毒性颗粒、棒状小体(auer rod)、柴捆细胞(faggot cell)以及假chediak-higashi颗粒样颗粒选择的至少一种。
56.细胞的大小异常可以包括巨大血小板。
57.与细胞的形态学的分类有关的参数可以包括与从中性粒细胞、嗜酸性粒细胞、血小板、淋巴细胞、单核细胞、嗜碱性粒细胞、后髓细胞、髓细胞、前髓细胞、芽细胞、浆细胞、异型淋巴细胞、未成熟嗜酸性粒细胞、未成熟嗜碱性粒细胞、成红细胞以及巨核细胞选择的至少一种细胞的每个种类的数量关联的值以及与从中性粒细胞、嗜酸性粒细胞、血小板、淋巴细胞、单核细胞、嗜碱性粒细胞、后髓细胞、髓细胞、前髓细胞、芽细胞、浆细胞、异型淋巴细胞、未成熟嗜酸性粒细胞、未成熟嗜碱性粒细胞、成红细胞以及巨核细胞选择的至少一种细胞的每个种类的比率中的至少一个关联的值。
58.第1参数的获取方法只要能够获取与上述形态学的分类有关的参数以及/或者与异常发现有关的参数,就不被限制。例如,第1参数的获取也可以由检查者进行,但优选使用后述细胞图像解析装置300、400。
59.第1参数的获取也可以使用美国专利公开2019-0347467号公报等所记载的深度学习算法进行。美国专利公开2019-0347467号公报被编入到本说明书。在第1参数的获取方法中使用的鉴别器如图1所示包括具有神经网络构造的多个深度学习算法。鉴别器包括第1深度学习算法dl1和第2深度学习算法dl2,第1深度学习算法dl1抽取细胞的特征量,第2深度学习算法dl2根据第1深度学习算法抽取出的特征量,识别所述解析对象的细胞。第2深度学习算法dl2针对每个细胞输出形态学的分类结果及与其分类对应的概率或者异常发现的分类及与其分类对应的概率。第1深度学习算法dl1是卷积连接的神经网络,位于第1深度学习算法的下游的第2深度学习算法dl2是全连接的神经网络。
60.能够通过对涂抹标本或者盖章标本实施明视野染色而制作在第1参数群的获取中利用的标本。能够通过在将检体涂抹或者按压到载玻片之后风干并固定细胞而制作涂抹标本或者盖章标本。根据需要,也可以用甲醇、乙醇等醇、福尔马林、丙酮等公知的固定剂固定
细胞。
61.以下例示明视野染色。
62.在明视野染色是吉姆萨染色的情况下,将固定后的载玻片浸渍于吉姆萨染色液,或者用吉姆萨染色液覆盖干燥后的载玻片,染色预定时间。染色后用水等清洗载玻片,再次通过风干使载玻片干燥。根据需要,在用二甲苯等清除之后,用盖玻片和密封剂密封载玻片的观察面。
63.在明视野染色是瑞氏染色的情况下,将固定后的载玻片浸渍于瑞氏染色液,或者用瑞氏染色液覆盖干燥后的载玻片,染色预定时间。在染色后,用磷酸缓冲液等(例如,1/15m-磷酸缓冲液,ph6.4)清洗载玻片,再次通过风干使载玻片干燥。根据需要,在用二甲苯等清除之后,用盖玻片和密封剂密封载玻片的观察面。
64.在明视野染色是梅吉姆萨染色的情况下,首先将固定后的载玻片浸渍于迈格林华染色液,或者用迈格林华染色液覆盖干燥后的载玻片,染色预定时间。在染色后,将载玻片浸渍于磷酸缓冲液(例如,1/15m-磷酸缓冲液,ph6.4)等。接下来,将载玻片浸渍于吉姆萨染色液,或者用吉姆萨染色液覆盖载玻片,染色预定时间。在染色后,用水等清洗载玻片,再次通过风干使载玻片干燥。根据需要,在用二甲苯等清除之后,用盖玻片和密封剂密封载玻片的观察面。
65.在明视野染色是瑞氏吉姆萨染色的情况下,首先将固定后的载玻片浸渍于瑞氏吉姆萨染色液,或者用瑞氏吉姆萨染色液覆盖干燥后的载玻片,染色预定时间。在染色后,将载玻片浸渍于磷酸缓冲液(例如,1/15m-磷酸缓冲液,ph6.4)等。接下来,用水等清洗载玻片,再次通过风干使载玻片干燥。根据需要,在用二甲苯等清除之后,用盖玻片和密封剂密封载玻片的观察面。
66.(2)第2参数
67.在本实施方式中,在图1所示的工序b中,使用血球计数装置测定检体s2,获取第2参数。
68.第2参数是根据由血球计数装置350、450检测到的光学信号或者电信号获取的参数,是与细胞的每个种类的数量、细胞的每个种类的比率、细胞的大小以及细胞中包含的成分的浓度中的至少一个关联的值。第2参数的获取也可以使用美国专利公开2014-0051071号公报等所记载的深度学习算法进行。美国专利公开2014-0051071号公报被编入到本说明书。
69.图3示出从血球计数装置350、450获取的参数的例子。
70.作为第2参数,优选的是,能够举出(i)与从红细胞、有核红细胞、小型红细胞、血小板、血红蛋白、网织红细胞、未成熟粒细胞、中性粒细胞、嗜酸性粒细胞、嗜碱性粒细胞、淋巴细胞以及单核细胞选择的至少一种细胞的每个种类的数量关联的值、(ii)与从红细胞、有核红细胞、小型红细胞、血小板、血红蛋白、网织红细胞、未成熟粒细胞、中性粒细胞、嗜酸性粒细胞、嗜碱性粒细胞、淋巴细胞以及单核细胞选择的至少一种细胞的每个种类的比率关联的值以及(iii)与从血细胞比容值、平均红细胞容积(mcv)、平均红细胞血红蛋白量(mch)、平均红细胞血红蛋白浓度(mchc)、平均血小板容积(mpv)选择的至少一个关联的值。第2参数可以包括从(i)、(ii)以及(iii)选择的至少一个参数。
71.(3)疾病的鉴别
72.在本实施方式中,根据第1参数群以及所述第2参数群生成用于支援疾病的鉴别的鉴别支援信息。
73.在本实施方式中鉴别的疾病只要是人的疾病,就不被限制。优选的是造血疾病。造血系统疾病可以包括骨髓增生性肿瘤、白血病、骨髓异常性综合征、淋巴瘤、骨髓瘤等。骨髓增生性肿瘤优选可以包括真性红细胞增多症、原发性血小板增多症、原发性骨髓纤维化症等。白血病优选可以包括急性骨髓芽细胞性白血病、急性前髓细胞性白血病、急性骨髓单核细胞性白血病、急性单核细胞性白血病、红白血病、急性巨核芽细胞性白血病、急性骨髓性白血病、急性淋巴细胞性白血病、淋巴芽细胞性白血病、慢性骨髓性白血病、慢性淋巴细胞性白血病等。淋巴瘤可以包括霍奇金淋巴瘤、非霍奇金淋巴瘤等。骨髓瘤可以包括多发性骨髓瘤等。
74.用于鉴别疾病的支援信息的生成由后述处理部20使用计算机算法进行。计算机算法可以包括机器学习算法以及深度学习算法等。
75.机器学习算法可以包括树、回归、支持向量机、贝叶斯、聚类以及随机森林等算法。作为机器学习算法优选是梯度提升树算法。作为梯度提升树,更优选是多模态深度神经网络(multimodal deep neural networks,multimodaldnn)。
76.深度学习算法具有神经网络构造。
77.计算机算法依照下述方法训练,作为疾病的鉴别器发挥功能。
78.1-2.鉴别器的生成
79.训练数据是通过将训练用第1参数群和训练用第2参数群作为相同层级的矩阵进行排列进而将表示疾病名的标签(以下,还称为“疾病名的标签”)关联起来而生成的。训练用第1参数群从训练用涂抹标本获取。图4示出训练数据的例子。例如,图4的第1列表示参数群的类别。图4的第2列表示行编号。图4的第3列表示各参数的名称(标签),第4列表示各参数。参数例如如果是具有细胞种类、异常发现的细胞的比率,则用%单位表示,如果是浓度,则例如用g/dl单位表示,如果是细胞数,则用10^4/ul(
×
104个/μl)单位表示。这些单位是在血球检查等中普遍使用的单位。第1参数是通过使用深度学习算法dl2,对形态学的分类结果或者异常发现的分类的结果进行计数,根据与该分类对应的概率对所得到的计数结果进行加权而得到的。例如,在分类为中性粒细胞杆状核细胞的细胞是100个细胞中的1个,分类为中性粒细胞杆状核细胞的细胞被分类为中性粒细胞杆状核细胞的概率是90%的情况下,对1个乘以90%,设为0.9个。图4的第5列是表示疾病名的标签。
80.从自附有医生诊断的疾病名的确定诊断的患者提取的试样(以下,还称为“训练用试样”),针对每个试样生成训练用第1参数群和训练用第2参数群。然后,针对每个试样,包括训练用第1参数群和训练用第2参数群的矩阵与疾病名对应起来成为训练数据。
81.在图4的例子中,在行方向上排列有训练用第1参数群和训练用第2参数群,但也可以在列方向上排列。另外,如图4那样,各参数既可以用简称表示,也可以用标签值表示。另外,也可以将疾病名的标签也用标签值表示。
82.在此,关于训练用第1参数群和训练用第2参数群,也可以进行预定的统计解析,选择与疾病的关联性高的参数。作为预定的统计解析,例如能够举出一维方差解析(anova)、皮尔逊相关性、斯皮尔曼等级相关性等。优选的是一维方差解析。通过进行统计学的参数的选取,能够提高鉴别精度。
83.接下来,将训练数据输入到计算机算法,训练计算机算法,生成鉴别器。在此,在使用机器学习算法的情况下,针对每个疾病训练1个算法。另一方面,在使用深度学习算法的情况下,能够通过1个算法对多个疾病进行训练。
84.计算机算法的训练能够使用python等软件进行。
85.为了支援疾病的鉴别而使用所训练的计算机算法作为疾病的鉴别器。
86.1-3.解析数据的生成和鉴别支援信息的生成
87.从自被检者提取的解析对象试样获取解析用第1参数群和解析用第2参数群,将它们进行组合而生成解析数据。解析用第1参数群和解析用第2参数群分别优选与训练用第1参数群和训练用第2参数群同样地生成。另外,解析数据中包含的参数的种类也优选与训练数据中包含的参数相同。解析数据将解析用第1参数群和解析用第2参数群作为相同的层级,优选按照与训练数据相同的顺序进行矩阵化而生成。
88.接下来,将解析数据输入到在上述1-2.中训练的鉴别器,生成用于支援疾病的鉴别的信息。所述信息是从解析数据预测出的表示被检者具有与鉴别器对应的疾病的概率的值。进而,也可以根据所述概率,输出表示患者的疾病名的标签。
89.2.疾病鉴别支援系统1
90.本公开中的某个实施方式涉及疾病鉴别支援系统1。
91.参照图5,说明疾病鉴别支援系统1的结构。疾病鉴别支援系统1具备训练装置100a和疾病鉴别支援装置200a。供应商侧装置100作为训练装置100a发挥功能,用户侧装置200作为疾病鉴别支援装置200a进行动作。
92.训练装置100a连接于细胞图像解析装置300和血球计数装置350。训练装置100a从细胞图像解析装置300获取训练用第1参数群,从血球计数装置350获取训练用第2参数群。
93.疾病鉴别支援装置200a连接于细胞图像解析装置400和血球计数装置450。疾病鉴别支援装置200a从细胞图像解析装置400获取解析用第1参数群,从血球计数装置350获取解析用第2参数群。
94.记录介质98例如是dvd-rom、usb存储器等计算机能够读取且非易失性的记录介质。
95.以下说明各结构。
96.2-1.细胞图像解析装置
97.参照图6,说明细胞图像解析装置300的结构。细胞图像解析装置300至少具备摄像部304,摄像部304具备用于承载标本的载物台309、显微镜等放大镜部302以及用于对显微图像进行摄像的摄像元件301。获取设置于载物台309上的训练用标本308上的各细胞的图像。细胞图像解析装置300从获取到的图像进行第1参数群的获取。细胞图像解析装置300添加有信息处理单元305,信息处理单元305进行第1参数群的获取以及写入及与训练装置100a的通信。
98.接下来,说明细胞图像解析装置400的结构。细胞图像解析装置400的结构与细胞图像解析装置300基本上相同,具备摄像部404,摄像部404具备用于承载标本的载物台409、显微镜等放大镜部402以及用于对显微图像进行摄像的摄像元件401。细胞图像解析装置400获取设置于载物台409上的解析用标本408上的各细胞的图像。细胞图像解析装置400从获取到的图像进行解析用第1参数群的获取。细胞图像解析装置400具备信息处理单元405,
信息处理单元405进行第1参数群的获取以及写入及与疾病鉴别支援装置200的通信。
99.作为细胞图像解析装置300、400,例如能够使用希森美康株式会社制的automated digital cell morphology analyzer di-60等。
100.2-2.血球计数装置
101.使用图7以及图8,说明血球计数装置350的结构。血球计数装置350是具备用于检测具备图7所示的流通池的光学信号的光学检测部411的流式细胞仪等。
102.在图7中,从作为光源4111的激光器二极管射出的光经由照射透镜系统4112照射到通过流通池4113内的细胞。
103.在本实施方式中,流式细胞仪的光源4111不被特别限定,选择适于荧光色素的激发的波长的光源4111。作为这样的光源4111,例如使用包括红色半导体激光器以及/或者蓝色半导体激光器的半导体激光器、氩激光器、氦-氖激光器等气体激光器、水银电弧灯等。特别是半导体激光器相比气体激光器非常便宜,所以是优选的。
104.如图7所示,从通过流通池4113的粒子发出的前方散射光经由聚光透镜4114和针孔部4115由前方散射光受光元件4116接收。前方散射光受光元件4116可以是光电二极管等。侧方散射光经由聚光透镜4117、分色镜4118、带通滤波器4119以及针孔部4120由侧方散射光受光元件4121接收。侧方散射光受光元件4121可以是光电二极管、光电倍增器等。侧方荧光经由聚光透镜4117以及分色镜4118由侧方荧光受光元件4122接收。侧方荧光受光元件4122可以是雪崩光电二极管、光电倍增器等。
105.从各受光部4116、4121以及4122输出的受光信号分别由具有放大器4151、4152以及4153的模拟处理部实施放大以及波形处理等模拟处理,被发送到测定单元控制部480。
106.测定单元控制部480与信息处理单元351连接,信息处理单元351根据在光学检测部411中获取到的光学信号,获取第2参数。
107.另外,血球计数装置350也可以具备图8所示的电阻方式检测部412。图8示出电阻方式检测部412是鞘流式电阻检测部412的情况。鞘流式电阻检测部412具备腔壁412a、测定细胞的电阻的小孔部412b、供给试样的试样喷嘴412c以及回收通过了小孔部412b的细胞的回收管412d。腔壁412a内的试样喷嘴412c和回收管412d的周围被鞘液充满。用符号412s表示的虚线箭头表示鞘液流动的方向。从试样喷嘴排出的红细胞412e以及血小板412f一边包含于鞘液流412s,一边通过小孔部412b。对小孔部412b施加有恒定电压的直流电压,在仅有鞘液流动的期间,控制成恒定的电流流过。细胞不易通电,即电阻大,所以当细胞通过小孔部412b时,电阻发生改变,能够在小孔部412b中检测细胞通过的次数及其电阻。电阻与细胞的体积成比例地变大,所以测定单元信息处理部481能够根据与电阻值有关的信号强度计算通过了小孔部412b的细胞的容积,将每个容积的细胞的计数数作为直方图而发送到信息处理单元351。
108.血球计数装置350测定训练用试样,获取训练用第2参数群。
109.血球计数装置450的结构也与血球计数装置350相同。血球计数装置450测定训练用试样,获取解析用第2参数群。
110.作为血球计数装置350、450,例如能够举出希森美康株式会社制的xn-2000的血球计数装置。
111.2-3.训练装置
112.训练装置100a将训练用第1参数群以及训练用第2参数群和与它们关联起来的疾病名作为训练数据,对计算机算法进行训练,生成鉴别器。训练装置100a经由记录介质98或者网络99从细胞图像解析装置300获取第1参数。训练装置100a经由记录介质98或者网络99从血球计数装置350获取第2参数。训练装置100a将所生成的鉴别器提供给疾病鉴别支援装置200a。鉴别器的提供是经由记录介质98或者网络99进行的。疾病鉴别支援装置200a使用鉴别器生成用于支援疾病的鉴别的鉴别支援信息。
113.(1)训练装置的硬件结构
114.使用图9,说明训练装置100a的硬件的结构。训练装置100a具备处理部10(10a)、输入部16以及输出部17。训练装置100a例如由通用计算机构成。
115.处理部10具备进行后述数据处理的cpu(central processing unit,中央处理单元)11、在数据处理的作业区域使用的存储器12、记录后述程序以及处理数据的存储部13、在各部分之间传送数据的总线14、进行与外部设备的数据的输入输出的接口部15以及gpu(graphics processing unit,图形处理单元)19。输入部16以及输出部17连接于处理部10。例示性地,输入部16是键盘、触摸面板或者鼠标等输入装置,输出部17是液晶显示器等显示装置。gpu19作为对cpu11进行的运算处理(例如,并行运算处理)进行辅助的加速器发挥功能。即,在以下的说明中cpu11进行的处理意味着还包括cpu11将gpu19用作加速器而进行的处理。
116.另外,处理部10将用于进行在以下的图11中说明的训练处理的计算机程序以及计算机算法例如以执行形式预先记录到存储部13。执行形式例如是从编程语言通过编译程序变换而生成的形式。处理部10与保存于存储部13的操作系统协作,使用用于进行训练处理的计算机程序(以下,有时简称为“训练程序”),进行计算机算法的训练处理。
117.在以下的说明中,只要不特别限定,处理部10进行的处理意味着cpu11根据保存于存储部13或者存储器12的用于进行训练处理的计算机程序以及计算机算法进行的处理。cpu11将存储器12作为作业区域而易失性地临时存储所需的数据(处理中途的中间数据等),将运算结果等长期保存的数据非易失性地适当地记录于存储部13。
118.(2)训练装置的功能结构
119.参照图10,训练装置100a的处理部10a作为训练数据生成部101、训练数据输入部102以及算法更新部103发挥功能。这些功能是通过将使计算机执行训练处理的训练程序(例如python等)安装到处理部10a的存储部13或者存储器12并由cpu11执行该程序而实现的。训练数据数据库(db)104中保存处理部10a从细胞图像解析装置300获取到的训练用第1参数群和从血球计数装置350获取到的训练用第2参数群。另外,训练数据db104中还保存与参数对应的疾病名的标签。算法数据库(db)105中能够保存训练前的计算机算法以及训练后的计算机算法。
120.训练数据生成部101对应于后述步骤s11,训练数据输入部102对应于步骤s12,算法更新部103对应于步骤s15。
121.(3)训练程序的处理
122.训练装置100a的处理部10a执行图11所示的训练程序的各步骤。
123.处理部10a受理操作者从输入部16输入的训练数据获取处理开始指令,在步骤s11中,从细胞图像解析装置300获取训练用第1参数群,并保存到存储部13内的训练数据
db104。另外,处理部10a从血球计数装置350获取训练用第2参数群,并保存到存储部13内的训练数据db104。处理部10a依照上述1-2.所记载的方法,将训练用第1参数群以及训练用第2参数群与疾病名的标签关联起来生成训练数据,并保存到存储部13内的训练数据数据库104。关于与各参数群对应的疾病名的标签,受理操作者针对各参数群从输入部16输入的标签,并可以与训练用第1参数群以及训练用第2参数群关联起来。或者,也可以当在细胞图像解析装置300或者血球计数装置350中获取到各参数时,将患者信息与各参数关联起来,处理部10a读入该信息。
124.处理部10a受理操作者从输入部16输入的训练处理开始指令,在步骤s12中,读出保存于存储部13内的算法db105的计算机算法,进而从训练数据db10读出训练数据,将训练数据输入到计算机算法。
125.处理部10a在步骤s13中,判定是否使用所有的训练数据来训练了计算机算法,在未使用所有的训练数据训练计算机算法的情况下(“否”的情况)进入到步骤s14,从训练数据db10读出接下来的训练数据,返回到步骤s12而继续处理。
126.处理部10a在步骤s13中在使用所有的训练数据训练了计算机算法的情况下(“是”的情况),进入到步骤s15,将训练的计算机算法记录于存储部13内的算法db105。
127.训练的计算机算法作为生成用于支援疾病的鉴别的鉴别支援信息的鉴别器发挥功能。
128.2-4.疾病鉴别支援装置
129.疾病鉴别支援装置200a获取解析用第1参数群以及解析用第2参数群和鉴别器,生成用于支援疾病的鉴别的鉴别支援信息。疾病鉴别支援装置200a经由记录介质98或者网络99从细胞图像解析装置400获取解析用第1参数。疾病鉴别支援装置200a经由记录介质98或者网络99从血球计数装置450获取解析用第2参数。
130.(1)疾病鉴别支援装置的硬件结构
131.使用图12,说明疾病鉴别支援装置200a的硬件的结构。疾病鉴别支援装置200a的结构基本上与训练装置100a相同。但是,将训练装置100a的处理部10(10a)、输入部16、输出部17在疾病鉴别支援装置200a中换称为处理部20(20a)、输入部26、输出部27。
132.另外,将训练装置100a的cpu11、存储器12、存储部13、总线14、接口部15以及gpu19在疾病鉴别支援装置200a中换称为cpu21、存储器22、存储部23、总线24、接口部25以及gpu29。
133.另外,处理部20将用于进行在以下的图14中说明的各步骤的处理的计算机程序例如以执行形式预先记录于存储部13。执行形式例如是从编程语言通过编译程序变换而生成的形式。处理部10使用记录于存储部13的用于支援疾病的鉴别的计算机程序和训练装置100a生成的鉴别器,生成用于支援疾病的鉴别的鉴别支援信息。
134.另外,处理部20为了进行在以下的疾病解析处理中说明的各步骤的处理,将后述用于支援疾病的鉴别的计算机程序以及鉴别器例如以执行形式预先记录于存储部23。执行形式例如是从编程语言通过编译程序变换而生成的形式。处理部20与保存于存储部23的操作系统协作,使用用于支援疾病的鉴别的程序以及鉴别器来进行用于支援疾病的鉴别的鉴别支援信息的生成处理。
135.在以下的说明中,只要不特别限定,处理部20进行的处理意味着处理部20的cpu21
实际地根据保存于存储部23或者存储器22的用于支援疾病的鉴别的计算机程序以及鉴别器进行的处理。cpu21将存储器22作为作业区域而易失性地临时存储所需的数据(处理中途的中间数据等),将运算结果等要长期保存的数据非易失性地适当地记录到存储部23。
136.(2)疾病鉴别支援装置的功能结构
137.参照图13,疾病鉴别支援装置200a的处理部20a作为解析数据获取部201、解析数据输入部202、解析部203、解析数据数据库(db)204以及鉴别器数据库(db)205发挥功能。这些功能是通过将使计算机执行鉴别支援信息的生成处理的计算机程序(例如python等)安装到处理部20a的存储部23或者存储器22并由cpu21执行包括该计算机程序和鉴别器的用于支援疾病的鉴别的计算机程序而实现的。解析数据数据库(db)204中保存处理部10a从细胞图像解析装置400获取到的解析用第1参数群和从血球计数装置450获取到的解析用第2参数群。鉴别器数据库(db)205中保存从训练装置100获取到的鉴别器。
138.解析数据获取部201对应于后述步骤s21,解析数据输入部202对应于步骤s22以及步骤s23,解析部203对应于步骤s24。
139.(3)用于支援疾病的鉴别的计算机程序的处理
140.疾病鉴别支援装置200a的处理部20a执行图14所示的各步骤。
141.处理部20a受理操作者从输入部26输入的解析数据获取处理开始指令,在步骤s21中,从细胞图像解析装置400获取解析用第1参数群,并保存到存储部23内的解析数据db204。另外,处理部20a从血球计数装置450获取解析用第2参数群,并保存到存储部23内的解析数据db204。
142.处理部20a受理操作者从输入部26输入的鉴别器获取处理开始指令,在步骤s22中,从训练装置100a获取鉴别器。或者,在鉴别器预先保存于存储部23内的鉴别器数据库205的情况下,读出所保存的鉴别器。
143.处理部20a受理操作者从输入部26输入的解析处理开始指令,在步骤s23中,将在步骤s21中获取到的解析用第1参数群和解析用第2参数群从解析数据db204调出,并输入到鉴别器。
144.处理部20a在步骤s24中,作为用于支援疾病的鉴别的鉴别支援信息生成表示各疾病的概率的值,并记录到存储部23内。
145.处理部20a在步骤s25中,将在步骤s24中生成的结果输出到输出部27。
146.3.疾病鉴别支援系统2
147.使用图15以及图16,说明疾病鉴别支援系统的别的方式。图15示出疾病鉴别支援系统2的结构例。疾病鉴别支援系统2具备用户侧装置200、细胞图像解析装置400以及血球计数装置450,用户侧装置200作为进行训练和疾病鉴别支援这两方的疾病鉴别支援装置200b进行动作。疾病鉴别支援装置200b承担训练装置100a以及疾病鉴别支援装置200a这两方的功能。疾病鉴别支援装置200b连接于细胞图像解析装置400以及血球计数装置450。
148.(1)疾病鉴别支援装置200b的硬件结构
149.疾病鉴别支援装置200b的硬件结构与图12所示的用户侧装置200的硬件结构相同。在图12中,在疾病鉴别支援装置200b中,将处理部20a换称为处理部20b。
150.(2)疾病鉴别支援装置200b的功能结构
151.图16示出疾病鉴别支援装置200b的功能结构。疾病鉴别支援装置200b的处理部
20b作为训练数据生成部101、训练数据输入部102、算法更新部103、解析数据获取部201、解析数据输入部202、解析部203、参数数据库(db)314以及算法数据库(db)315发挥功能。参数数据库(db)314兼具在上述2-3.(2)中叙述的训练数据db104和在上述2-4.(2)中叙述的解析数据db204的功能。另外,算法数据库(db)315兼具在上述2-3.(2)中叙述的算法db105和在上述2-4.(2)中叙述的鉴别器db205的功能。即,参数db314中保存处理部20b从细胞图像解析装置400获取到的训练用第1参数群以及解析用第1参数群和从血球计数装置450获取到的训练用第2参数群和解析用第2参数群。算法db315中保存作为训练前的计算机算法以及训练后的计算机算法的鉴别器。
152.疾病鉴别支援装置200b的处理部20b在训练时进行上述2-3.(3)以及图11所示的处理。训练数据生成部101对应于在上述2-3.(3)中叙述的步骤s11,训练数据输入部102对应于步骤s12,算法更新部103对应于步骤s15。在此,将上述2-3.(3)所记载的“处理部10a的存储部13”、“训练数据db104”、“算法db105”分别换称为“处理部20b的存储部23”、“参数db314”、“算法db315”。
153.疾病鉴别支援装置200b的处理部20b在鉴别支援信息的生成处理时,进行上述2-4.(3)以及图14所示的处理。解析数据获取部201对应于在上述2-4.(3)中叙述的步骤s21,解析数据输入部202对应于步骤s22以及步骤s23,解析部203对应于步骤s24。在此,将上述2-4.(3)所记载的“解析数据db204”、“鉴别器db205”分别换称为“参数db314”、“算法db315”。
154.4.疾病鉴别支援系统3
155.使用图17以及图18,说明疾病鉴别支援系统的别的方式。图17示出疾病鉴别支援系统3的结构例。疾病鉴别支援系统3具备供应商侧装置100和用户侧装置200。供应商侧装置100具备处理部10(10b)、输入部16以及输出部17。供应商侧装置100与上述疾病鉴别支援装置200b同样地作为进行训练处理和鉴别支援信息生成处理这两方的疾病鉴别支援装置100b进行动作。另一方面,用户侧装置200作为终端装置200c进行动作。
156.在此,疾病鉴别支援装置100b例如是由通用计算机等构成的云服务器侧的装置。疾病鉴别支援装置100b与细胞图像解析装置300以及血球计数装置350能够通信地连接。另外,疾病鉴别支援装置100b经由网络99而与终端装置200c能够通信地连接。
157.终端装置200c是通用计算机等,与细胞图像解析装置400以及血球计数装置450能够通信地连接。
158.(1)疾病鉴别支援装置100b的硬件结构
159.疾病鉴别支援装置100b的硬件结构与图10所示的供应商侧装置100的硬件结构相同。在图10中,在疾病鉴别支援装置100b中,将处理部10a换称为处理部10b。
160.(2)疾病鉴别支援系统3的功能结构
161.图18示出疾病鉴别支援系统3的功能结构。疾病鉴别支援装置100b的功能结构与上述3.(2)以及图16相同。
162.终端装置200c从细胞图像解析装置400获取解析用第1参数,从血球计数装置450获取解析用第2参数,经由网络99将这些解析参数发送到疾病鉴别支援装置100b。疾病鉴别支援装置100b从自终端装置200c发送的解析参数生成鉴别支援信息,并发送到终端装置200c。
163.5.计算机程序
164.本公开的其它实施方式涉及使计算机执行包括上述2-3.(3)以及图11所示的步骤s11至s15的训练处理的计算机程序。
165.另外,本公开的其它实施方式涉及使计算机执行包括上述2-4.(3)以及图14所示的步骤s21至s25的用于支援疾病的鉴别的处理的计算机程序。
166.所述计算机程序也可以作为存储有所述计算机程序的记录介质等程序产品而提供。所述计算机程序存储于硬盘、闪存存储器等半导体存储器元件、光盘等记录介质。关于向所述记录介质的程序的存储形式,只要所述处理部能够读取所述程序,就不被限制。向所述记录介质的存储优选是非易失性的。
167.6.治疗方法
168.本实施方式的治疗方法除了包括在上述1.支援方法中叙述的各工序之外,还包括根据附于被检者的疾病名的标签对被检者进行治疗的工序。优选的是,在治疗工序中,通过施用与被检者的疾病相应的药剂来被检者被治疗。
169.能够对赋予有表示真性红细胞增多症的标签的被检者施用阿司匹林、羟基脲、干扰素α等。
170.能够对赋予有表示原发性血小板增多症的标签的被检者进行阿司匹林、羟基脲、阿那格雷等的施用。
171.能够对赋予有表示原发性骨髓纤维化症的标签的被检者进行来那度胺等沙利度胺或者达那唑的施用等。
172.能够对赋予有表示骨髓异形成综合征的标签的被检者进行阿扎胞苷施用、地西他滨施用、地西他滨和西达尿苷的同时施用或者来那度胺等沙利度胺施用等。
173.能够对赋予有表示急性骨髓芽细胞性白血病的标签的被检者进行阿糖胞苷(或者依诺他滨)施用、依诺他滨施用、全反式维甲酸和6-巯基嘌呤甲氨蝶呤的同时施用、阿扎胞苷施用、来那度胺水和物等沙利度胺施用等。
174.能够对赋予有表示急性前髓细胞性白血病或者急性骨髓性白血病的标签的被检者进行阿糖胞苷(或者依诺他滨)施用、依诺他滨施用、柔红霉素施用、伊达比星施用、米托蒽醌施用、全反式维甲酸和他米巴罗汀的同时施用或者吉姆单抗奥佐米星施用等。
175.能够对赋予有表示急性骨髓单核细胞性白血病或者急性单核细胞性白血病的标签的被检者进行阿糖胞苷(或者依诺他滨)和蒽环类抗癌药(柔红霉素、伊达比星、米托蒽醌等)的同时施用、全反式维甲酸施用、三氧化二砷和全反式维甲酸的同时施用等。
176.能够对赋予有表示红白血病的标签的被检者进行阿扎胞苷施用等。
177.能够对赋予有表示急性巨核芽细胞性白血病的标签的被检者进行依托泊苷、阿糖胞苷(或者依诺他滨)施用、胞嘧啶阿拉伯糖苷以及道诺霉素的同时施用等。
178.能够对赋予有表示急性淋巴细胞性白血病或者淋巴芽细胞性白血病的标签的被检者例示性地施用来那度胺水和物等沙利度胺、依诺他滨、长春新碱、泼尼松龙、阿霉素、l-天冬酰胺酶,或者将它们组合施用。
179.能够对赋予有表示慢性骨髓性白血病的标签的被检者例示性地施用伊马替尼、尼洛替尼、达沙替尼、博舒替尼、普纳替尼、羟氨基酰胺,或者将它们组合施用。
180.能够对赋予有表示慢性淋巴细胞性白血病的标签的被检者例示性地施用环磷酰
胺、长春新碱、氟达拉滨、利妥昔单抗,或者将它们组合施用。
181.能够对赋予有表示霍奇金淋巴瘤的标签的被检者进行放射线疗法等。另外,能够对赋予有表示霍奇金淋巴瘤的标签的被检者进行将长春花碱、博来霉素、阿霉素以及达卡巴嗪进行组合的abvd疗法或者维布妥昔单抗、长春花碱、阿霉素以及达卡巴嗪的并用疗法等。
182.能够对赋予有表示非霍奇金淋巴瘤的标签的被检者进行放射线疗法等。另外,能够对赋予有表示非霍奇金淋巴瘤的标签的被检者进行利妥昔单抗、长春新碱、阿霉素、环磷酰胺、泼尼松龙、吡柔比星、依托泊苷、长春酰胺或者它们的组合的施用以及/或者来那度胺等沙利度胺施用等。
183.能够对赋予有表示多发性骨髓瘤的标签的被检者进行硼替佐米、地塞米松或者来那度胺等沙利度胺的施用等。
184.7.效果的验证
185.验证本说明书所公开的疾病的鉴别的支援方法的效果。
186.7-1.试样
187.(1)训练用试样
188.在2017年2月至同年9月期间在顺天堂大学附属医院接受诊断,已经从被诊断的真性红细胞增多症(pv)34名、原发性血小板增多症(et)168名以及原发性骨髓纤维化症(pmf)69名患者将末梢血进行edta采血,用作训练用试样。
189.(2)验证用试样
190.在顺天堂大学医院接受诊断,已经从被诊断的真性红细胞增多症(pv)9名、原发性血小板增多症(et)53名以及原发性骨髓纤维化症(pmf)12名患者将末梢血进行edta采血,用作验证用试样。
191.7-2.各参数的获取和选取
192.(1)第1参数群的获取
193.制作末梢血的涂抹标本,使用automated digital cell morphology analyzer di-60(希森美康株式会社),获取与异常发现有关的参数。关于异常发现,获取了细胞的种类和分类值17项目、异常形态特征164项目的共计181项目。
194.(2)第2参数群的获取
195.使用血球计数装置xn系列,获取174项目的血球检查项目的测定值。
196.(3)第1参数以及第2参数的选取
197.关于上述第1参数群以及第2参数群,为了选取与疾病鉴别相关性更强的项目,进行基于一维方差解析(anova)的选定。
198.anova的零假设h0设为“在群间没有差异”,对立假设h1设为“在群间有差异”。显著性水平p值设为0.05,作为与疾病的关联性高的项目而抽取出p<0.05的项目。通过基于anova的显著差异检验,从第1参数群抽取出44个项目,从第2参数群抽取出121个项目。表1示出抽取出的项目和p值的例子。
199.[表1]
[0200]
参数p值hct(%)3.08e-47
rbc(10^4/ul)2.40e-46[ig%(%)]3.97e-46q-flag(left shift?)4.07e-41hgb(g/dl)4.17e-41morph_mmy1.77e-37[ne-wy]1.76e-36nrbc%(%)1.06e-34morph_my8.74e-34ip sus(wbc)left shift?1.56e-3lhfr(%)2.34e-31q-flag(rbc agglutination?)7.47e-31[ne-wx]1.96e-30morph_erb1.27e-29[rbc-o(10^4/ul)]4.70e-29morph_bne1.24e-28irf(%)1.04e-27rbc/m2.24e-26eo%/m2.42e-24[plt-f(10^4/ul)]2.67e-24[plt-i(10^4/ul)]3.10e-24plt(10^4/ul)6.90e-24plt/m1.07e-23rdw-cv(%)4.78e-23pct(%)7.57e-23
[0201]
7-3.训练
[0202]
关于各个训练用试样,获取在上述6-2.(3)中选定的第1参数群和第2参数群,针对每个训练用试样生成了将它们作为相同的层级而排列的矩阵。将采血了训练用试样的各患者的疾病标签与各矩阵关联起来制作出训练数据。将制作出的训练数据输入到梯度提升树,对算法进行训练,生成鉴别器。关于软件,使用了python。
[0203]
7-4.验证
[0204]
关于各个验证用试样,获取在上述6-2.(3)中选定的第1参数群和第2参数群,针对每个验证用试样生成将它们作为相同的层级而排列的矩阵,将其作为各验证用试样的解析数据。将所生成的各解析数据输入到鉴别器,获取了鉴别结果。
[0205]
图19示出使用了鉴别器的机器法与基于医生的确定诊断的结果的比较。由医生诊断为pv的患者9名在机器法中也全部预测为pv。由医生诊断为et的患者53名中的49名在机器法中也预测为et,2名在机器法中预测为pv,2名预测为pmf。另外,由医生诊断为pmf的患者12名中的10名在机器法中也预测为pmf,1名预测为pv,1名预测为et。
[0206]
图20、图21、图22分别示出在机器法中预测出的pv、et、pmf的roc曲线。另外,图23示出从各roc曲线得到的灵敏度、特异度、auc值。关于任意的疾病,都是灵敏度以及特异度
超过90%,是良好的。另外,auc值也超过0.96,是良好的。
[0207]
7-5.与以往方法的比较
[0208]
图24示出非专利文献1的图b的图。在非专利文献1的方法中,在pmf中,被判定为et或者pt,或无法判定的情形较常见。因此,认为本说明书所公开的疾病的鉴别的支援方法适于疾病的鉴别支援。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1