改进的隐马尔科夫模型地图匹配方法及装置
1.本发明属于地理信息科学与智能交通研究领域,具体涉及一种改进的隐马尔科夫模型地图匹配方法及装置。
背景技术:
2.随着gps设备普及和定位技术的不断发展,产生的大量gps轨迹数据为基于位置服务(lbs)和智能交通系统(its)的研究提供重要数据来源。但是,由于gps设备本身存在误差和定位时周围环境的复杂性,导致轨迹数据和相应的道路网络之间不匹配,致使对路线规划、交通流量分析、地理社交网络分析、自动驾驶汽车、轨迹异常分析等应用的研究无法继续,需要地图匹配将轨迹点与路网位置联系起来并得到匹配后的轨迹点位置和信息,即地图匹配过程。所以地图匹配是各种基于位置服务(lbs)和智能交通系统中必不可少的数据处理过程。目前,地图匹配方法主要归纳为以下四大类:1)基于几何的算法主要研究路网和轨迹的几何特征,但是该方法忽略了拓扑信息,导致对于复杂的路网场景匹配混乱或错误,如立交桥等场景;2)基于拓扑的算法侧重轨迹数据与路网之间的拓扑关系,该方法通过路网来建立图结构并整合拓扑信息。但是该方法不适用于低采样率的轨迹数据;3)基于概率的算法将gps位置和轨迹分别当作随机变量和随机过程,隐马尔科夫模型(hmm)是其中常用的一种,考虑了几何和拓扑信息,且不需要训练数据,应用效果非常好。但是由于需要计算最短路径,因此计算成本较高;4)基于高等数学理论的算法,该方法需要大量的训练数据集来进行逐点匹配,所以应用非常困难,此外将轨迹数据简单地看作是随机过程中独立和相同分布的随机变量的集合非常不合理。综上所述,隐马尔科夫模型不需要训练数据集,将轨迹视为完整的过程,而且还考虑了几何和拓扑信息,因此基于隐马尔科夫模型是较为优选的选择,近年来被广泛应用于地图匹配。国内学者胡奕公和卢宾宾(2019)提出一种基于隐马尔科夫模型的低采样率轨迹数据地图匹配方法,其以方向和距离计算观察概率,利用路网距离和欧式距离的关系计算转移概率。国外学者paul newson最先使用隐马尔科夫模型进行地图匹配,以gps误差距离符合正态分布计算观察概率,利用路网距离符合指数概率分布计算转移概率。anders hansson等人考虑了距离、速度、航向、车道偏航率及车道标记来计算观察和转移概率,该方法应用于车道级路网地图匹配,非常依赖轨迹数据和路网数据的质量。
技术实现要素:
3.本发明要解决的技术问题主要在于,提供一种更高准确率、更高效和更适用的地图匹配方法,为了实现上述目的,本发明提出了一种改进的隐马尔科夫模型地图匹配方法及装置。
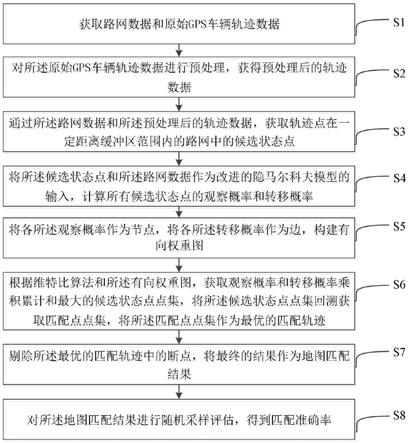
4.根据本发明的一个方面,提供了一种改进的隐马尔科夫模型地图匹配方法,包括以下步骤:
5.获取路网数据和原始gps车辆轨迹数据;
6.对所述原始gps车辆轨迹数据进行预处理,获得预处理后的轨迹数据;
7.通过所述路网数据和所述预处理后的轨迹数据,获取轨迹点在一定距离缓冲区范围内的路网中的候选状态点;
8.将所述候选状态点和所述路网数据作为改进的隐马尔科夫模型的输入,计算所有候选状态点的观察概率和转移概率;
9.将各所述观察概率作为节点,将各所述转移概率作为边,构建有向权重图;
10.根据维特比算法和所述有向权重图,获取观察概率和转移概率乘积累计和最大的候选状态点点集,将所述候选状态点点集回溯获取匹配点点集,将所述匹配点点集作为最优的匹配轨迹;
11.剔除所述最优的匹配轨迹中的断点,将最终的结果作为地图匹配结果。
12.优选地,在所述剔除最优的匹配轨迹中的断点,将最终的结果作为地图匹配结果的步骤之后,还包括:
13.对所述地图匹配结果进行随机采样评估,得到匹配准确率。
14.优选地,所述对原始gps车辆轨迹数据进行预处理的步骤,包括:文件解压、文件分割、数据清洗、数据格式和坐标系转换以及地图投影。
15.优选地,所述对原始gps车辆轨迹数据进行预处理的步骤,包括:
16.判断所述原始gps车辆轨迹数据是否是以轨迹点的id、经度、纬度和时间戳字段记录的txt文件格式,若是,则进入下一步,否则,将所述原始gps车辆轨迹数据进行格式转换成该类型的txt格式;
17.将包含多个轨迹数据的txt文件根据轨迹点的id进行分割,分割成一定数量的txt轨迹数据文件;
18.计算分割后的txt轨迹数据文件中相邻点间的平均速度和车辆方向角,剔除超过预设速度最大值和预设方向角范围的轨迹点;
19.将相邻轨迹点时间间隔小于零的轨迹点剔除,把相邻点的速度和方向角均为零,但是地理位置和时间在变的轨迹点剔除,得到清洗后的轨迹数据txt文件;
20.将所述清洗后的轨迹数据txt文件批量转换为shapefile文件格式,同时把原来的火星坐标系转换为大地坐标系;
21.通过arcgis软件对轨迹数据进行批量投影,将大地坐标系转换为投影坐标系,即平面坐标系,对原始gps车辆轨迹数据的预处理过程完成。
22.优选地,所述通过路网数据和所述预处理后的轨迹数据,获取轨迹点在一定距离缓冲区范围内的路网中的候选状态点的步骤,包括:
23.以轨迹点的位置为中心,构建缓冲半径r的缓冲区,所述缓冲区半径r的计算公式如下:
24.r=l
max
+υ
25.式中,l
max
为道路宽度的最大值;υ是通过查阅文献资料得出的参数;
26.构建路网的strtree空间索引结构,查询缓冲区范围内的路段;
27.获取轨迹点到缓冲区范围内的路段上的投影点,并作为候选状态点。
28.优选地,所述计算所有候选状态点的观察概率的步骤,包括:
29.计算距离因素的观察概率,计算公式如下:
[0030][0031]
式中,oi和分别表示观察点和对应的候选匹配点,即第i个观察点和对应的第k个候选状态点;表示gps观察点oi和候选状态点之间的欧式距离;μ表示定位误差期望值,包括gps设备的系统误差和测绘误差;σ表示gps定位误差的标准差;表示第i个观察点对应的第k个候选状态点之间计算距离因素的观察概率值;
[0032]
计算角度因素的观察概率,计算公式如下:
[0033][0034][0035]
式中,β表示轨迹点记录的方向角度值;γ表示候选状态点所在的道路的角度方向值;α表示轨迹点记录方向角和道路方向角的差值,取值范围为[0,180
°
];表示第i个观察点对应的第k个候选状态点之间计算角度因素的观察概率值;
[0036]
根据所述距离因素的观察概率和所述角度因素的观察概率,计算候选状态点的观察概率,计算公式如下:
[0037][0038]
优选地,所述计算所有候选状态点的转移概率的步骤,包括:
[0039]
计算距离因素的转移概率,计算公式如下:
[0040][0041]
式中,d
i-1,i
是轨迹点pi和p
i-1
之间的欧式距离;表示轨迹点p
i-1
对应的第t个候选状态点;表示轨迹点pi对应的第r个候选状态点;d
(i-1,t),(i,r)
表示轨迹点p
i-1
和pi对应的第t个候选状态点和第r个候选状态点之间用最短路径算法a*计算得到的最短路径长度;
[0042]
计算速度因素的转移概率,计算公式如下:
[0043][0044]
式中,v
i-1
和vi分别表示轨迹点pi和p
i-1
对应的速度值;表示轨迹点p
i-1
和pi对应的第t个候选状态点和第r个候选状态点之间用最短路径算法a*计算得到的最短路径长度除以时间间隔得到的速度值;
[0045]
根据所述距离因素的转移概率和所述速度因素的转移概率,计算候选状态点的转移概率,计算公式如下:
[0046][0047]
优选地,所述根据维特比算法和所述有向权重图,获取观察概率和转移概率乘积
累计和最大的候选状态点点集,将所述候选状态点点集回溯获取匹配点点集,将所述匹配点点集作为最优的匹配轨迹的步骤,包括:
[0048]
获取所述有向权重图中候选状态点的观察概率和转移概率;
[0049]
计算候选状态点的综合概率,第一个轨迹点的候选状态点的综合概率为观察概率,除第一个轨迹点的其他轨迹点的候选状态点的综合概率为观察概率和转移概率的乘积,获取最大综合概率的候选状态点作为匹配点;
[0050]
根据维特比算法,获取综合概率累计和最大的候选状态点点集,并对该点集回溯获取匹配点点集,作为最优的匹配轨迹。
[0051]
优选地,所述对地图匹配结果进行随机采样评估,得到匹配准确率的步骤,包括:
[0052]
随机选取一定数量的匹配轨迹;
[0053]
将匹配后的轨迹点叠加在相同坐标系的路网和openstreetmap上进行量化统计分析,判别匹配准确的原则如下:
[0054]
1)整体轨迹的方向和所在道路的方向要求一致:
[0055]
2)前后轨迹点的平均速度与所在道路的等级相一致,且前后轨迹点所在道路需要拓扑连接;
[0056]
满足条件1)和2)则认为匹配准确;
[0057]
统计匹配正确的轨迹点数量,计算评估指标;
[0058]
所述评估指标包括:每条轨迹的匹配准确率和所有轨迹平均匹配准确率。
[0059]
根据本发明的第二方面,还提供了一种改进的隐马尔科夫模型地图匹配装置,包括以下模块:
[0060]
数据获取模块,用于获取路网数据和原始gps车辆轨迹数据;
[0061]
预处理模块,用于对所述原始gps车辆轨迹数据进行预处理,获得预处理后的轨迹数据;
[0062]
候选状态点获取模块,用于通过所述路网数据和所述预处理后的轨迹数据,获取轨迹点在一定距离缓冲区范围内的路网中的候选状态点;
[0063]
概率计算模块,用于将所述候选状态点和所述路网数据作为改进的隐马尔科夫模型的输入,计算所有候选状态点的观察概率和转移概率;
[0064]
有向权重图构建模块,用于将各所述观察概率作为节点,将各所述转移概率作为边,构建有向权重图;
[0065]
最优结果获取模块,用于根据维特比算法和所述有向权重图,获取观察概率和转移概率乘积累计和最大的候选状态点点集,将所述候选状态点点集回溯获取匹配点点集,将所述匹配点点集作为最优的匹配轨迹;
[0066]
断点剔除模块,用于剔除所述最优的匹配轨迹中的断点,将最终的结果作为地图匹配结果;
[0067]
随机采样评估模块,用于对所述地图匹配结果进行随机采样评估,得到匹配准确率。
[0068]
本发明提供的技术方案具有以下有益效果:
[0069]
本发明主要针对隐马尔科夫模型进行改进,整个处理流程均是为了充分利用隐马尔科夫模型得到最优的地图匹配结果。首先在原先隐马尔科夫模型中观察概率的计算仅考
虑距离因素的基础上考虑了角度因素,且该计算公式符合线性变化具有一定的稳定性和可靠性。其次在原先隐马尔科夫模型中转移概率的计算仅考虑距离因素的基础上考虑了速度因素。对上述隐马尔科夫模型的改进和整个流程的优化处理后,通过实际数据实验验证了该方法的可行性,并且提出的地图匹配方法平均准确率达到88.83%,相较于目前其他基于hmm的地图匹配方法准确率得到了提高。
附图说明
[0070]
下面将结合附图及实施例对本发明作进一步说明,附图中:
[0071]
图1是本发明改进的隐马尔科夫模型地图匹配方法流程图;
[0072]
图2是本发明原始轨迹数据预处理后的部分叠加在路网上可视化专题图;
[0073]
图3是本发明获取gps轨迹点对应的候选状态点示意图;
[0074]
图4是本发明改进隐马尔科夫模型计算观察概率和转移概率示意图;
[0075]
图5是本发明地图匹配结果叠加在路网上可视化专题图;
[0076]
图6是本发明匹配结果叠加在openstreetmap和路网上可视化专题图;
[0077]
图7是本发明随机采样轨迹匹配结果统计准确率的折线图;
[0078]
图8是本发明改进的隐马尔科夫模型地图匹配装置结构图。
具体实施方式
[0079]
为了对本发明的技术特征、目的和效果有更加清楚的理解,现对照附图详细说明本发明的具体实施方式。
[0080]
参考图1,本发明实施例提供的一种改进的隐马尔科夫模型地图匹配方法,详细步骤如下:
[0081]
步骤s1:获取路网数据和原始gps车辆轨迹数据;
[0082]
步骤s2:对原始gps轨迹数据预处理,获得预处理后的轨迹数据:
[0083]
(1)解压原始轨迹数据压缩文件:原始轨迹数据压缩文件是lzo后缀文件,需要通过lzop方法解压并从lzo格式转换为txt文件格式,该数据包含轨迹点的车辆id、经度、纬度、时间戳等字段信息,采样率1/30~1/120s-1
;
[0084]
(2)轨迹数据txt文件分割:一天的轨迹数据包含在一个txt文件,将包含txt文件根据订单id数10万的准则进行分割,分割成一定数量的txt轨迹数据文件;
[0085]
(3)清除漂移点:利用python编程,通过计算相邻点间的平均速度和根据车辆方向角,剔除超过速度的最大值27.78m/s(通过查阅资料可知,城市车辆行驶速度一般不超过27.78m/s,即100km/h)和方向角范围[0,360];
[0086]
(4)剔除属性字段记录错误的轨迹点:通过python代码,将相邻轨迹点时间间隔小于零的轨迹点剔除,把相邻点的速度和方向角均为0,但是地理位置和时间在变轨迹点剔除;
[0087]
(5)轨迹数据格式和坐标系转换:利用python代码,实现将清洗后的轨迹数据txt文件批量转换为shapefile文件格式,同时把原来的火星坐标系(gcj-02)转换为1984年世界大地坐标系(wgs-84);
[0088]
(6)轨迹数据地图投影:通过arcgis软件中的arcmap模块中的批量投影进行轨迹
数据的批量投影,将地理坐标系转换为投影坐标系,该操作可使后续距离和速度的计算更加精确,轨迹数据预处理后的部分结果如图2所示。
[0089]
步骤s3:通过路网数据和预处理后的轨迹数据,获取轨迹点在一定距离缓冲区范围内的路网中的候选状态点;
[0090]
此过程的示意图如图3所示,{p
i-1
,pi,p
i+1
}为gps轨迹点;虚线圆圈表示缓冲区圆;为候选状态点;过程如下:
[0091]
(1)以轨迹点的位置为中心,根据查阅某一城市道路的一般宽度和其他相关文献来构建半径为r=50m的缓冲区圆,所述缓冲区半径r的计算公式如下:
[0092]
r=l
max
+υ
[0093]
式中,l
max
为道路宽度的最大值,一般l
max
=40m;υ是通过查阅文献资料得出的参数,本实施例υ=10m。
[0094]
(2)读取路网数据,构建python中的strtree空间索引结构,其查询方法可用于对索引上的对象进行空间查询;
[0095]
(3)利用缓冲区、路网数据和strtree空间索引结构,快速查询缓冲区范围内的道路路段信息,如图3中的单双向车道;
[0096]
(4)根据获取的道路路段信息,获取轨迹点到道路链路的投影点,将投影点的详细信息和道路链路信息以字典数据结构输出,这些路段上的投影点就是轨迹点在缓冲区范围内的路网上的候选状态点,如图3中的候选状态点。
[0097]
步骤s4,将候选状态点和路网数据作为改进的隐马尔科夫模型的输入,计算所有候选状态点的观察概率和转移概率;
[0098]
这一过程的示意图如图4所示,分为观察层和状态层两层,分别计算观察概率和转移概率,其中{p
i-1
,pi,p
i+1
}为gps轨迹点与图3中的轨迹点对应;{o
i-1
,oi,o
i+1
}表示对应的观察点;为候选状态点与图3中的候选状态点对应;详细过程如下:
[0099]
(1)根据和路网数据,计算考虑了距离和方向的观察概率:
[0100]
距离因素:假设候选状态点的位置条件概率服从正态分布,虽然gps误差不是严格遵守高斯分布的,但这个假设在地图匹配算法中被证明是有效的,所以距离因素的观察概率计算公式如下:
[0101][0102]
式中,oi和分别表示观察点和对应的候选匹配点,即第i个观察点和对应的第k个候选状态点;表示gps观察点oi和候选状态点之间的欧式距离;μ表示定位误差期望值,包括gps设备的系统误差和测绘误差,根据文献资料在本实施例设置为μ=0;σ表示gps定位误差的标准差,根据本实施例的轨迹数据特征设置为σ=25m;表示第i个观察点对应的第k个候选状态点之间计算距离因素的观察概率值。
[0103]
角度因素:考虑道路单双向方向角和观察轨迹点记录的方向角,如图4所示中的单双向车道,角度因素的观察概率计算公式如下:
[0104][0105][0106]
式中,β表示轨迹点记录的方向角度值;γ表示候选状态点所在的道路的角度方向值;α表示轨迹点记录方向角和道路方向角的差值,取值范围为[0,180
°
];表示第i个观察点对应的第k个候选状态点之间计算角度因素的观察概率值。
[0107]
观察概率:综合距离和角度两个因素来计算观察概率,计算公式如下:
[0108][0109]
式中是由(1)式计算可得;值由(2)式计算可得;二者乘积为隐马尔科模型中的观察概率此外根据不同应用场景,可以根据距离因素和角度因素的影响来确定权重,从而使得计算的观察概率更加合理。本实施例设置距离因素的权重为w
distance
=0.7,而角度因素的权重为w
angle
=0.3。
[0110]
(2)计算考虑了距离和速度的转移概率:
[0111]
距离因素:
[0112][0113]
式中,d
i-1,i
是轨迹点pi和p
i-1
之间的欧式距离;表示轨迹点p
i-1
对应的第t个候选状态点;表示轨迹点pi对应的第r个候选状态点;d
(i-1,t),(i,r)
表示轨迹点p
i-1
和pi对应的第t个候选状态点和第r个候选状态点之间用最短路径算法a*计算得到的最短路径长度;
[0114]
速度因素:
[0115][0116]
式中,v
i-1
和vi分别表示轨迹点pi和p
i-1
对应的速度值;表示轨迹点p
i-1
和pi对应的第t个候选状态点和第r个候选状态点之间用最短路径算法a*计算得到的最短路径长度除以时间间隔得到的速度值。
[0117]
转移概率:综合距离和速度两个因素来计算转移概率,计算公式如下:
[0118][0119]
式中是由式(5)计算得到;是由式(6)计算得到;二者乘积即为隐马尔科模型中的转移概率此外可根据不同应用场景,可根据距离因素和速度因素的影响来确定权重,从而使得计算的转移概率更加合理。本实施例设置距离因素的权重为w
distance
=0.7,而角度因素的权重为w
velocity
=0.3
[0120]
步骤s5:将各所述观察概率作为节点,将各所述转移概率作为边,构建有向权重图;
[0121]
利用python中的networkx库创建一个空的有向图,根据步骤4中(1)计算当前状态
点的观察概率作为有向权重图的节点,权重为观察概率值,根据步骤4中(2)的当前和前一个状态点作为有向权重图的边,而计算的转移概率为对应边的权重。重复以上过程可以构建整个轨迹的有向权重图。
[0122]
步骤s6:根据维特比算法和有向权重图,获取观察概率和转移概率乘积累计和最大的候选状态点点集,将候选状态点点集回溯获取匹配点点集,将匹配点点集作为最优的匹配轨迹;
[0123]
根据步骤s5构建的有向权重图,首先提取出所有观察点的包含的候选状态点的观察概率,然后提取每个观察点的综合概率,首个观察点的综合概率只有观察概率,其他均是观察概率和转移概率的乘积,寻找所有观察点中候选状态点的最大综合概率的候选状态点为对应的匹配点,以此类推,得到综合概率累计和最大的候选状态点点集,将该候选状态点点集逆序依次获取对应的候选状态点记为匹配点,从而得到匹配轨迹点点集,作为最优的匹配轨迹。
[0124]
步骤s7:剔除最优的匹配轨迹中的断点,将最终的结果作为地图匹配结果。
[0125]
匹配后的轨迹数据叠加至路网数据上的部分可视化结果如图5所示。叠加到openstreetmap和路网数据上的部分可视化结果如图6所示。从图中可以看出匹配点都在路网上,但是不知道量化的匹配准确率,所以需要进行量化评估匹配结果。
[0126]
步骤s8:对所述地图匹配结果进行随机采样评估,得到匹配准确率;
[0127]
具体包括:
[0128]
(1)随机选取25条的匹配轨迹,平均每条轨迹的点数有115个;
[0129]
(2)将随机选取的匹配轨迹叠加在相同坐标系的路网和openstreetmap上,定量统计每条轨迹的匹配准确率,判别匹配准确的原则如下:
[0130]
1)整体轨迹的方向和所在道路的方向要求一致:
[0131]
2)前后轨迹点的平均速度与所在道路的等级相一致,且前后轨迹点所在道路需要拓扑连接。
[0132]
(3)满足以上两个条件就认为匹配正确,计算评估指标:每条轨迹的匹配准确率=轨迹中正确匹配的点数/轨迹中的总点数;所有轨迹平均匹配准确率=所有轨迹的匹配准确率累计和/所有轨迹点总数。
[0133]
最终评估结果如图7所示,最低匹配准确率为82.14%,最高匹配准确率为98.48,平均匹配准确率达到88.83%。
[0134]
在一些实施例中,还提供了一种改进的隐马尔科夫模型地图匹配装置,用于实现本实施例中的一种改进的隐马尔科夫模型地图匹配方法。参考图8,该装置包括以下模块:
[0135]
数据获取模块1,用于获取路网数据和原始gps车辆轨迹数据;
[0136]
预处理模块2,用于对所述原始gps车辆轨迹数据进行预处理,获得预处理后的轨迹数据;
[0137]
候选状态点获取模块3,用于通过所述路网数据和所述预处理后的轨迹数据,获取轨迹点在一定距离缓冲区范围内的路网中的候选状态点;
[0138]
概率计算模块4,用于将所述候选状态点和所述路网数据作为改进的隐马尔科夫模型的输入,计算所有候选状态点的观察概率和转移概率;
[0139]
有向权重图构建模块5,用于将各所述观察概率作为节点,将各所述转移概率作为
边,构建有向权重图;
[0140]
最优结果获取模块6,用于根据维特比算法和所述有向权重图,获取观察概率和转移概率乘积累计和最大的候选状态点点集,将所述候选状态点点集回溯获取匹配点点集,将所述匹配点点集作为最优的匹配轨迹;
[0141]
断点剔除模块7,用于剔除所述最优的匹配轨迹中的断点,将最终的结果作为地图匹配结果;
[0142]
随机采样评估模块8,用于对所述地图匹配结果进行随机采样评估,得到匹配准确率。
[0143]
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者系统不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者系统所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括该要素的过程、方法、物品或者系统中还存在另外的相同要素。
[0144]
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。在列举了若干装置的单元权利要求中,这些装置中的若干个可以是通过同一个硬件项来具体体现。词语第一、第二、以及第三等的使用不表示任何顺序,可将这些词语解释为标识。
[0145]
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1