一种电机轴承故障预测方法
1.本发明涉及设备故障预测领域,更具体地,涉及一种电机轴承故障预测方法。
背景技术:
2.滚动轴承的运行状态能够直接影响电机的整体性能,电机故障中有40%左右是由轴承故障引发,是电机健康监测的重要对象,通过有效评估电机轴承的退化状态并及时预测轴承故障,进行早期维护和检修,可以避免工业中的经济损失和重大安全事故。电机轴承故障预测的关键在于两点:一是确定合适的轴承性能退化指标,二是搭建有效的故障预测模型。
3.性能退化指标是故障判别标准的关键,现有的研究中大多用峰度、均方根、峰峰值等无量纲参数作为性能退化指标,预测模型是故障预测的核心,近年来有许多学者利用机器学习算法有效的实现了轴承的故障预测。
技术实现要素:
4.本发明针对现有技术中存在的技术问题,提供一种电机轴承故障预测方法,包括:获取电机轴承的振动信号;利用互补集合经验模态分解ceemd算法对所述振动信号进行分解,获取表征电机轴承振动特征的多个imf分量;计算每组imf分量的奇异值能量,组成奇异值能量谱;将所述奇异值能量谱输入故障预测模型,获取所述故障预测模型输出的电机轴承的故障预测结果,其中,所述故障预测模型为双向长短时记忆网络,基于蝗虫优化算法对所述故障预测模型进行训练。
5.本发明提供的一种电机故障预测方法,首先对电机轴承的振动信号利用互补集合经验模态分解ceemd算法进行分解,获得能够表征振动特征的多组imf分量,计算每组imf分量的奇异值能量,并组成奇异值能量谱作为电机轴承的性能退化指标。其次,采用蝗虫优化算法对bi-lstm网络的超参数进行迭代寻优,提高模型的预测精度与收敛速度。最后,利用优化后的bi-lstm网络实现电机轴承的故障预测。实验结果表明,相较于其他预测模型,本文所提模型具有较高的预测精度同时还具有较强的鲁棒性,能够及时的为检修工作提供理论支撑。
附图说明
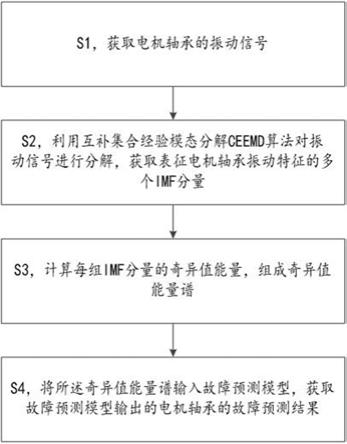
6.图1为本发明提供的一种电机轴承故障预测方法流程图;图2为蝗虫优化算法的流程示意图;图3为长短时记忆网络的单元结构示意图;图4为bi-lstm网络结构示意图;图5为电机轴承故障预测流程图;
图6为采集的电机轴承的振动信号波形图;图7为原始振动信号的奇异值能量谱;图8为降噪后的振动信号的奇异值能量谱;图9为蝗虫优化算法迭代寻优示意图;图10为利用蝗虫优化算法训练bi-lstm网络模型后的电机故障预测结果示意图;图11为elm故障预测结果示意图;图12为td-svr故障预测结果示意图;图13为dcnn故障预测结果示意图;图14为不同预测模型对应的容错性分析预测结果示意图。
具体实施方式
7.下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
8.实施例一一种电机轴承故障预测方法,参见图1,该故障预测方法包括:获取电机轴承的振动信号;利用互补集合经验模态分解ceemd算法对所述振动信号进行分解,获取表征电机轴承振动特征的多个imf分量;计算每组imf分量的奇异值能量,组成奇异值能量谱;将所述奇异值能量谱输入故障预测模型,获取所述故障预测模型输出的电机轴承的故障预测结果,其中,所述故障预测模型为双向长短时记忆网络,基于蝗虫优化算法对所述故障预测模型进行训练。
9.可以理解的是,为了有效预测复杂工况下的电机轴承故障,提出了一种利用蝗虫优化算法(grasshopper optimization algorithm,goa)优化双向长短时记忆网络(bidirectional long short-term memory,bi-lstm)的电机轴承故障预测方法。首先对电机轴承的振动信号利用互补集合经验模态分解(complementary ensemble empirical mode decomposition, ceemd)算法进行分解,获得能够表征振动特征的多组imf分量,计算每组imf分量的奇异值能量,并组成奇异值能量谱作为电机轴承的性能退化指标。其次,采用蝗虫优化算法goa对bi-lstm网络模型的超参数进行迭代寻优,提高模型的预测精度与收敛速度。最后,利用优化后的bi-lstm网络模型实现电机轴承的故障预测。实验结果表明,相较于其他预测模型,本发明所提故障预测模型具有较高的预测精度同时还具有较强的鲁棒性,能够及时的为检修工作提供理论支撑。
10.实施例二一种电机轴承故障预测方法,该故障预测方法主要包括以下步骤:s1,获取电机轴承的振动信号。
11.可以理解的是,当需要对电机轴承的故障进行预测时,利用传感器采集电机运行过程中电机轴承的振动信号,可在电机轴承的垂直方向和水平方向布置两个振动传感器,采集电机轴承在运行状态中的振动数据。
12.s2,利用互补集合经验模态分解ceemd算法对所述振动信号进行分解,获取表征电机轴承振动特征的多个imf分量。
13.可以理解的是,模态分解的方法很多,ceemd分解是基于emd分解和eemd分解改进
而来,即消除了emd分解中时常存在的模态混叠现象,又优化了eemd分解过程效率较低,时间过长的情况。集合经验模态分解(ensemble empirical mode decomposition, eemd)作为一种自主分解数据方法解决了经验模态分解存在的模态混叠等现象,在处理振动信号时效果较好,但其分解后遗留在分量中的白噪声会出现重构误差。ceemd分解在信号中引入互补的高斯白噪声,借助噪声信号相互独立,绝对负相关,信号分解时能够竟可能的抵消掉冗余的噪声。ceemd分解过程入如下:在振动信号中每一个信号加入n次幅值相同的互补白噪声,组成新序列:其中、为第i次加入的互补白噪声、后的新序列。
14.利用emd分别对获得的新序列、进行分解,得到对应的两组imf分量和;对两组imf分量和求平均值得到ci,为对应的一组imf分量;对每一个分解,得到振动信号x(t)的多组imf分量:对每一个分解,得到振动信号x(t)的多组imf分量。
15.s3,计算每组imf分量的奇异值能量,组成奇异值能量谱。
16.可以理解的是,当电机轴承将要出现故障时,各imf的能量都会发生变化,信号能量逐渐分散,奇异值能量随之变化。当出现明显故障状态时,噪声比例快速增加,信号能量迅速增大,奇异值能量迅速增大。鉴于上述分析,奇异值能量谱可以作为表征电机轴承状态退化的性能指标。
17.振动信号经过cemmd分解,得到imf分量矩阵b:对每组imf分量进行奇异值分解(singular value decomposition,svd),该项技术以其出色的去噪和和周期成分提取效果,在故障诊断领域早有研究,奇异值分解的具体过程如下:一个实矩阵,一定存在一个正交矩阵和正交矩阵,使得:
其中,或其转置,0表示零矩阵,,且有,即为b的奇异值。
18.解出矩阵b对应的奇异值矩阵为:奇异值能量谱可由式(6)表示:。
19.s4,将所述奇异值能量谱输入故障预测模型,获取所述故障预测模型输出的电机轴承的故障预测结果,其中,所述故障预测模型为双向长短时记忆网络,基于蝗虫优化算法对所述故障预测模型进行训练。
20.作为实施例,所述基于蝗虫优化算法对所述故障预测模型进行训练,包括:生成初始代种群,并初始化种群参数;通过不断调整种群内各蝗虫个体的距离,更新种群位置,并重新迭代计算种群适应度函数值,直到基于种群适应度函数值和当前迭代次数判定达到迭代终止条件,得到最优种群参数。
21.可以理解的是,本发明实施例是基于蝗虫优化算法来对故障预测模型进行训练优化的,其中,蝗虫优化算法(grasshopper optimization algorithm,goa)是一种新的启发式优化算法。算法思想是基于蝗虫觅食得来,每个蝗虫个体即为搜索空间的一个搜索个体,成虫的搜索范围较广跳跃能力较强负责种群全局搜索任务,幼虫的搜索范围较窄负责种群的局部搜索任务。goa算法的的过程可参见图2,具体包括如下步骤:(1)初始化种群规模n、种群位置xw、最大迭代次数t
max
以及参数c
max
和c
min
。
22.其中,rw表示种群个体之间对第w个个体的影响,gw表示第w只蝗虫受到的重力影响,aw表示第只蝗虫受到的风力作用。计算式子如下:计算式子如下:其中,表示第w只蝗虫与第e只蝗虫间的距离;h(r)表示蝗虫个体间的相互作用力,当h(r)>0时个体间相互吸引,当h(r)<0时个体间相互排斥;f、l分别表示吸引力度和吸引尺度,均为常数,本发明实施例取值f=0.5,l=1.5。
[0023]23.ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(11);
其中,g表示引力常数;表示风力常数;和分别为指向地心的单位向量和风向的单位向量。
[0024]
(2)计算每只蝗虫个体的适应度函数值,并将最优蝗虫个体寄存在变量。
[0025]
(3)基于式(12)更新参数c。
[0026]
ꢀꢀꢀꢀꢀꢀꢀ
(12);其中,t表示当前的迭代次数。
[0027]
(4)在解决实际问题中,通常不考虑重力作用g,并且设定风向总是指向最优目标,因此不考虑gw和aw,基于式(13)更新蝗虫个体的位置并计算每只个体的适应度值。
[0028]
ꢀꢀꢀ
(13);其中:表示当前最优个体;d表示d维空间即优化参数的个数;和分别表示第d个优化参数的上界和下界;表示种群在d维空间的最优解。
[0029]
(5)判断步骤(4)所得最优蝗虫个体是否为种群到该代为止的最优个体,更新。
[0030]
(6)判断是否达到迭代终止条件,若是则返回最优个体,否则重复(3)-(5),其中,达到迭代终止条件为适应度函数值满足设定阈值或者当前迭代次数达到最大迭代次数。
[0031]
本发明实施例中的电机轴承故障预测模型采用的是双向长短时记忆网络(bidirectional long short-term memory,bi-lstm),下面对bi-lstm网络进行介绍。
[0032]
首先对长短时记忆网络进行介绍,长短时记忆网络继承了循环神经网络的可记忆性功能,有利于读取信号序列的非线性特点,lstm网络还引入了门控单元从而解决长序列数据的长期依赖问题,避免网络训练过程中出现梯度消失或爆炸,以便保留每一循环单元的不同时间尺度信息特征,lstm单元结构如图3所示。
[0033]
lstm网络的计算过程如下:(1)由遗忘门判断是否保留前一时刻细胞的状态信息。遗忘门输入前一时刻的隐藏状态和新输入的数据,输出遗忘门的值:
ꢀꢀꢀꢀꢀꢀꢀꢀ
(14);(2)输入门计算能够从输入、前一时刻状态以及遗忘门的输出中学习到的信息,并决定将要使用和保存的信息输、出记忆门的值,当前的细胞候选状态:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(15);
ꢀꢀꢀꢀꢀꢀꢀꢀ
(16);(3)输出门根据输入、前一时刻的隐藏层状态、当前时刻的细胞候选状态计算当前时刻的细胞状态以及输出:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(17);
ꢀꢀꢀꢀꢀꢀ
(18);其中对应各门的权重矩阵和偏差,表示sigmoid函数。此处介绍的是前向lstm,后向lstm的基本结构与此相同,区别在于将原信号以倒序的方式输入网络。
[0034]
虽然lstm网络记忆功能强大,能够提取历史序列中的有用信息,但其只能提取序列的前向信息从而造成后向序列中的有用信息被浪费掉。bi-lstm网络是对lstm的改进,该网络连接了一前一后两个反向的lstm网络,使得模型的序列信息提取能力有了进一步上升。bi-lstm网络结构如图4所示,前传层训练前向序列,后传层训练后向序列,共同作用。
[0035]
bi-lstm网络数学表达式如下:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(19);
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(20);
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(21);其中,f、b分别表示信号序列按前向和后向两个方向输入lstm网络;和分别表示前向和后向lstm网络在t时刻的影藏隐藏层输出;表示与在t时刻的组合输出的最终结果。
[0036]
其中,利用蝗虫优化算法goa来优化训练bi-lstm故障预测模型,利用bi-lstm模型进行预测时,超参数众多影响着模型的精度与效率,其中初始学习率、隐藏层神经元个数m以及迭代次数h影响作用较大。本发明实施例利用goa算法对这3个参数进行迭代寻优,以增强模型的故障预测性能。基于goa优化的bi-lstm电机轴承故障预测步骤如下,流程如图5所示。
[0037]
(1)数据采集:在电机轴承的垂直方向和水平方向布置两个振动传感器,采集不同工况下的原始振动数据。
[0038]
(2)数据预处理:采集电机轴承的振动信号,利用ceemd分解提取振动信号的imf分量并进行归一化。
[0039]
(3)建立退化指标:计算每组imf分量的奇异值并求其能量组成奇异值能量谱,并进行平滑去噪处理,将奇异值能量谱作为性能退化指标。
[0040]
(4)训练模型:将奇异值能量谱以一定比例分为训练集和测试集,基于训练集数据,以真实值与预测值的均方根误差为适应度值,利用蝗虫优化算法优化bi-lstm网络。
[0041]
(5)故障预测:将训练好的最优超参数代入bi-lstm网络,进行故障预测测试并与真实状态进行对比。
[0042]
下面以一个具体的实施例来说明本发明提出的电机轴承故障预测方法,为验证本发明建立的电机轴承的故障预测模型有效可行,使用轴承退化数据集进行实验验证。振动信号的采样频率为20khz,采样周期为10min,第一组实验包含4个电机轴承,本实施例选用其中一个电机轴承的振动数据,该电机轴承共有2156组振动数据,每组数据包含20180个点,反映了该电机轴承从正常运行到出现内圈故障整个运行周期的振动特征。为了加快运算速度,这里提取每组数据的前10000个点进行计算,得到信号波形如图6所示。
[0043]
(1)建立性能退化指标。
[0044]
首先利用ceemd算法对轴承振动信号进行分解,得到10个imf分量以及1个剩余分量,然后计算各组imf分量的奇异值能量,得到奇异值能量谱如图7所示,由图7看出数据中存在很多噪声,这会影响预测效果,于是对其进行平滑降噪处理,如图8所示。
[0045]
由图7可知电机轴承衰退过程中,在每个阶段其性能退化指标会出现局部差异的特点,可将整个周期的运行退化情况划分成三个阶段,阶段ⅰ实验刚起步,轴承状态优异、运行稳定,性能退化指标随时间变化非常稳定;阶段ⅱ轴承正常运转,局部时而出现不合理的波动,表示在其工作过程中可能出现机械整体抖动或是误采样的情况属于正常现象,利用bi-lstm模型进行故障预测时是基于时序信号的整体趋势,出现这种现象并不会影响预测的效果;阶段ⅲ性能退化指标波动幅度加大,同时波动频率增多,此时轴承处于性能衰退期,轴承最终会发生故障。根据实验经验,设置故障阈值为70,性能退化指标超过阈值则被认定为出现故障,为避免振动信号出现波动或误采样的情况,规定指标超过阈值5次,电机停机进行检修。
[0046]
(2)基于goa的超参数优化。
[0047]
由于电机在运行至2156min时轴承故障程度已经加剧,应当更早的停止运行,因此在故障加剧后的数据不具有预测意义,选取第1900组到2125组的数据作为训练集,第2126组到2150组的数据作为测试集。利用训练集数据利用蝗虫优化算法训练bi-lstm网络模型,蝗虫优化算法初始参数如表1,为了比较goa算法的优越性,这里同时使用鲸鱼优化算法(whaleoptimizationalgorithm,woa)进行优化,依据经验设置woa的参数,以均方根误差(rmse)作为适应度函数,其随迭代次数变化曲线如图9所示。获得最优超参数为:初始学习率、隐藏层神经元个数m=152以及迭代次数h=237。
[0048]
表1goa参数
由图9可得,goa算法在迭代进行到第20代时开始有了较好的收敛效果,woa算法在第13次迭代时开始了收敛,收敛速度较快但其收敛时未达到最低适应度值,说明woa算法容易陷入局部最优解。其次,goa算法在收敛时的均方根误差也较小,表明其预测精度更优。
[0049]
(3)故障预测模型对比。
[0050]
利用训练好的bi-lstm网络进行一步迭代预测,在进行每一次预测时,将前一次预测的结果加在当前输入的结尾,预测结果如图10所示。
[0051]
为验证本发明实施例所建立模型的优越性,选取极限学习机(extreme learning machine,elm)、时滞性支持向量回归(time delay support vector regression, td-svr)模型、卷积神经网络(deep convolutional neural networks, dcnn)模型进行对比实验,数据集划分与本发明实施例完全相同,参数设置完全依照经验数据,预测结果如图11-图13所示。
[0052]
从图11-图13可以直观的看出,本发明实施例所建立的模型预测精度要优于其他模型的精度。为了准确评估模型预测的精度,本文利用rmse和那什系数(nash-sutcliffe efficiency coefficient, nse)作为评估标准,公式如下:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(22);
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(23);其中y’表示预测结果,ya表示实际值,n代表测试点数,表示实际值的平均值;nse越趋近于1则模型精度越高,。保持数据集和模型参数不变,分别进行20次实验,计算指标平均值和,结果如表2所示。
[0053]
表2 预测结果对比
由表2可以看出相较于elm、rd-svr、dcnn模型,本文所提模型的nse值最接近于1,rmse值最小仅有5.713,说明goa-bi-lstm的拟合效果最好,相比于elm、td-svr、dcnn模型在电机轴承故障预测领域的预测精度最高。
[0054]
(4)预测容错性分析。
[0055]
在数据采集的过程中,有时会出现漏采样或者误采样的状况,本发明实施例采用随机数据置零的方法,模拟采样出错的状况。为验证发明实施例模型在数据误采样状况下仍具有较高的预测精度,将奇异值能量谱的训练集中随机10%的数据置0。利用goa-bi-lstm、elm、td-svr、dcnn模型对处理后的数据进行训练,预测结果如图14所示,计算预测评估指标和结果如表3所示。
[0056]
表3误采样对预测结果的影响由图14和表3可以看出,在模拟实验数据出现误采样的状况下,基于本发明实施例所提goa-bi-lstm模型的预测精度仍然是最高的,其他模型的值增加均超过了10,而本发明实施例模型的值仅增加了8.5,说明本发明实施例所建立的模型还具有很强的鲁棒性。
[0057]
本发明提供的一种电机轴承故障预测方法,首先利用ceemd分解振动信号,提取振动信号的特征分量并计算奇异值能量谱构造性能退化指标,其次利用goa对bi-lstm网络进行优化返回最优超参数,最后利用优化好的bi-lstm网络实现电机轴承的故障预测,具有如下优点:(1)利用奇异值能量谱作为性能退化指标,能够很好的体现出电机轴承状态的变化趋势,能够间接反应电机轴承的故障变化。
[0058]
(2)利用蝗虫优化算法对双向长短时记忆网络的超参数进行优化,蝗虫优化算法相较于鲸鱼优化算法具有更高的收敛精度。
[0059]
(3)针对lstm网络处理前向序列,仅考虑考虑前向信息而忽略了后向信息的情况,提出bi-lstm网络,具有一前一后两个互补的lstm网络,分别处理时间序列的前向和后向信息,提高了模型信息提取能力。
[0060]
(4)基于开源数据集,将本发明实施例的bi-lstm网络模型与elm、td-svr、dcnn模型进行对比分析,bi-lstm网络模型具有更高的预测精度以及更强的鲁棒性。
[0061]
需要说明的是,在上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详细描述的部分,可以参见其它实施例的相关描述。
[0062]
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
[0063]
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式计算机或者其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0064]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0065]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0066]
尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
[0067]
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包括这些改动和变型在内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1