基于干扰向量和NSGA-II算法的干扰资源分配方法
基于干扰向量和nsga-ii算法的干扰资源分配方法
技术领域
1.本发明属于雷达技术领域,更进一步涉及到雷达干扰技术领域中的一种基于干扰向量和nsga-ii算法的干扰资源分配方法。本发明可用于干扰方在掩护突防目标时,对干扰资源进行合理分配。
背景技术:
2.当干扰方在掩护突防目标的过程中,需要对干扰资源进行分配,从而使干扰方在拥有有限干扰资源的情况下,获得最大的干扰效果。要进行干扰资源分配,首先需要确定评价指标,根据评价指标建立目标函数,然后将目标函数代入到求解算法里得到最优的干扰资源分配方案。在确定评价指标时,所以通常会采用检测概率、定位精度和跟踪精度等指标,传统的方法是对这些评价指标进行固定加权来构建干扰资源分配模型。在搭建了符合突防场景的干扰资源分配模型后,需要选择合适的算法对干扰资源进行分配。但仍存在一些问题:首先是在突防场景中,雷达的工作状态会随着干扰机和雷达之间的距离而发生改变,那么不同工作状态下各评价指标对于干扰效果的影响是变化的,那么采用固定权值对各评估指标进行加权这种方法是不合理的,具有场景局限性;其次,传统的单目标优化算法在对干扰资源进行分配时,一般是基于指标加权的单目标函数来求解最优的干扰资源分配方案,从而导致求解的最优干扰资源分配方案具有指标间的依赖性。
3.哈尔滨工程大学在其申请的专利文献“一种基于定向突变搜索人工蜂群算法的干扰决策方法”(申请号202110111032.9申请公布号cn 112926832 a)中公开了一种基于定向突变搜索人工蜂群算法的干扰资源分配方法。该方法的实现步骤是:第一步,通过时间、空间、功率频率和干扰样式五个方面构建干扰效益矩阵。第二步,通过前方侦察机对雷达工作状态、雷达体制以及雷达的实际作战任务对雷达进行威胁等级评估。第三步,利用干扰效益矩阵、雷达威胁等级和约束条件构建出雷达干扰决策模型以及单目标函数。第四步,通过基于定向突变搜索人工蜂群算法求解得到最优干扰资源分配方案。该方法存在的不足之处是,定向突变搜索人工蜂群算法是单目标优化算法,其单目标函数的建立是采用指标加权的方法,则求解得到的最优干扰资源分配方案具有指标间的依赖性。
4.西安电子科技大学在其申请的专利文献“一种改进粒子群算法的干扰资源分配方法”(申请号201910192524.8申请公布号cn 109872009 a)中公开了一种基于改进粒子群算法的干扰资源分配方法。该方法的实现步骤是:第一步,选取评估指标,选取识别距离损失度、识别概率损失度、干扰样式隶属度、对方系统抗干扰技术隶属度和时空频评估因子隶属度五个指标作为评估指标,对评估指标加权得到总干扰效益值。第二步,根据干扰资源数和对方雷达系统的数量关系,初始化算法参数并生成初始种群,种群中的每个个体代表一种干扰资源分配方案,计算种群中每个个体的总干扰效益值;第三步,引入变异因子和线性变化的惯性因子来改进粒子群算法,将初始种群代入到改进粒子群算法中进行迭代,从而得到最优的干扰资源分配方案。该方法存在的不足之处是,实际场景中随着干扰机和雷达之间距离的变化,各评估指标对于干扰效果的影响是变化的,该方法在整个突防过程中对评
估指标进行固定加权,导致该方法无法应用于突防过程中评估指标的变化情况干扰的资源分配的场景,使得最优干扰资源分配方案具有场景局限性。
技术实现要素:
5.本发明的目的在于针对上述现有技术的不足,提出一种基于干扰向量和nsga-ii算法的干扰资源分配方法,用于解决在突防过程中,最优干扰资源分配方案的场景局限性和指标依赖性的问题。
6.实现本发明目的的技术思路是,本发明通过计算突防航线上各个距离处的检测概率、定位精度和跟踪精度的干扰值,并对突防航线上的所有距离点的三种干扰值进行了加权求和,得到整个突防过程的检测概率、定位精度和跟踪精度的干扰值,最后将这三种干扰值向量化得到干扰向量,由于生成干扰向量的过程考虑到了干扰机和雷达之间的距离变化带来的影响,解决了突防过程中最优干扰资源分配方案的场景局限性问题。本发明通过nsga-ii算法中的交叉变异方法来更新干扰资源分配向量集和干扰向量集,再利用nsga-ii算法中的快速非支配排序和拥挤度方法对干扰资源分配向量集进行分层和排序,之后从干扰资源分配向量集合中选取前10个干扰资源分配向量作为当前最优解,经过重复迭代后选取最优解中的一个干扰资源分配向量作为最优干扰资源分配方案,通过nsga-ii算法解决了最优干扰资源分配方案具有指标间依赖性的问题
7.实现本发明目的的技术方案的步骤如下:
8.(1)生成干扰资源分配向量集:
9.(1a)随机生成d个干扰对象向量和与其对应的干扰样式向量,其中,d≥100,xd表示d个干扰对象向量中第d个干扰对象向量,xd=[x
d1
,x
d2
,..x
dm
...,x
dm
]
t
,x
dm
表示第m部干扰机的干扰对象,m表示干扰方干扰机的总数,t表示转置操作,yd表示d个干扰对象向量中与其对应的干扰样式向量,yd=[y
d1
,y
d2
,..y
dm
...,y
dm
]
t
,y
dm
表示第m部干扰机采用的干扰样式;
[0010]
(1b)将每个干扰对象向量与其对应的干扰样式向量组成一个干扰资源分配向量,将所有的干扰资源分配向量组成干扰资源分配向量集;
[0011]
(2)生成干扰向量集:
[0012]
(2a)根据每个干扰资源分配向量对应的当前有无干扰的资源分配情况,分别计算突防航线上干扰目标与组网雷达中心之间每个距离点的检测概率、定位精度和跟踪精度的三种干扰值;
[0013]
(2b)对突防航线上所有距离点的三种干扰值进行加权求和处理后,得到突防航线上的三种干扰值,并对三种干扰值向量化,得到干扰向量;
[0014]
(2c)将所有干扰向量组成干扰向量集;
[0015]
(3)基于nsga-ii算法的交叉变异方法,更新干扰资源分配向量集和干扰向量集:
[0016]
(3a)从干扰资源分配向量集中随机选取两个未选过的干扰资源分配向量,对所选的两个干扰资源分配向量进行交叉,得到两个交叉后的干扰资源分配向量;
[0017]
(3b)从干扰资源分配向量集中随机选取一个未选过的干扰资源分配向量,对所选的干扰资源分配向量进行变异,得到一个变异后的干扰资源分配向量;
[0018]
(3c)将两个交叉后的干扰资源分配向量与一个变异后的干扰资源分配向量添加
到干扰资源分配向量集中,得到更新后的干扰资源分配向量集;
[0019]
(3d)采用与步骤(2a)、(2b)相同的方法,得到两个交叉后的干扰资源分配向量和一个变异后的干扰资源分配向量的三个干扰向量,将这三个干扰向量添加到干扰向量集中,得到更新后的干扰向量集;
[0020]
(4)基于nsga-ii算法中的快速非支配排序方法,根据更新后的干扰向量集对干扰资源分配向量集进行分层:
[0021]
(4a)从更新后的干扰向量集中选取一个未选过的干扰向量,将所选干扰向量与其余干扰向量分别进行比较,若所选干扰向量中的所有元素均大于其它干扰向量中的元素,则将该所选干扰向量对应的干扰资源分配集中的干扰资源分配向量吗,确定为与其它干扰向量对应的干扰资源分配向量为支配关系,否则,确定为无支配关系;
[0022]
(4b)将所有无支配关系的干扰资源分配向量组成一级非支配层,并将该级非支配层中的干扰向量标记为已选取的状态,将所有有支配关系的干扰资源分配向量对应的干扰向量集中的干扰向量标记为未选取的状态;
[0023]
(4c)判断更新后的干扰向量集中是否还有未选过的干扰向量,若是,则执行步骤(4a),否则,执行步骤(5);
[0024]
(5)基于nsga-ii算法中的拥挤度方法,计算每层中每个干扰资源分配向量的拥挤度:
[0025]
(5a)对每层中每个干扰资源分配向量按照其元素值从大到小进行排序;
[0026]
(5b)计算每层中每个干扰资源分配向量的拥挤度;
[0027]
(5c)对每层所有的干扰资源分配向量按照拥挤度从大到小进行排序;
[0028]
(6)将排序后的干扰资源分配向量集中的前10个干扰资源分配向量作为当前最优解;
[0029]
(7)判断当前最优解的迭代次数是否等于干扰资源分配向量集中干扰资源分配向量的总数,若是,则执行步骤(8),否则,将当前最优解包含的10个干扰资源分配向量组成新的干扰资源分配向量集后再执行步骤(2);
[0030]
(8)选择最优的干扰资源分配方案:
[0031]
从当前最优解中选取一个与雷达的工作状态对应的干扰资源分配向量,作为最优的干扰资源分配方案。
[0032]
本发明与现有技术相比有以下优点:
[0033]
第1,本发明通过计算突防航线上各个距离处的检测概率、定位精度和跟踪精度的干扰值,并对突防航线上的所有距离点的三种干扰值进行了加权求和,得到整个突防过程的检测概率、定位精度和跟踪精度的干扰值,最后将这三种干扰值向量化得到干扰向量,克服了现有技术存在的最优干扰资源分配方案的受场景局限的缺陷,使得本发明得到的最优干扰资源分配方案的应用场景更广。
[0034]
第2,本发明将nsga-ii算法引入到干扰资源分配领域,采用nsga-ii算法的快速非支配和拥挤度方法比较不同干扰资源分配向量的干扰向量选取最优的干扰资源分配向量,得到最优的干扰资源分配方案,克服了现有技术存在的突防过程中最优干扰资源分配方案的指标间依赖性的不足,使得本发明得到的最优干扰资源分配方案具有指标的独立性。
附图说明
[0035]
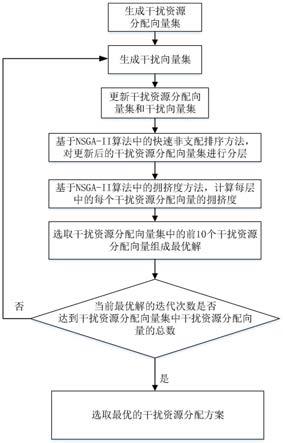
图1为本发明的实现流程图;
[0036]
图2为本发明中空间对抗场景的示意图。
具体实施方式
[0037]
以下结合附图对本发明做进一步的详细描述。
[0038]
参照图1,对本发明的实现步骤做进一步的详细描述。
[0039]
步骤1,生成干扰资源分配向量集。
[0040]
第1步,随机生成d个干扰对象向量和与其对应的干扰样式向量,其中,d≥100,xd表示d个干扰对象向量中第d个干扰对象向量,xd=[x
d1
,x
d2
,..x
dm
...,x
dm
]
t
,x
dm
表示第m部干扰机的干扰对象,m表示干扰方干扰机的总数,t表示转置操作,yd表示d个干扰对象向量中与其对应的干扰样式向量,yd=[y
d1
,y
d2
,..y
dm
...,y
dm
]
t
,y
dm
表示第m部干扰机采用的干扰样式。
[0041]
第2步,将每个干扰对象向量与其对应的干扰样式向量组成一个干扰资源分配向量,将所有的干扰资源分配向量组成干扰资源分配向量集。
[0042]
步骤2,生成干扰向量集。
[0043]
第1步,根据每个干扰资源分配向量对应的当前有无干扰的资源分配情况,分别计算突防航线上干扰目标与组网雷达中心之间每个距离点的。
[0044]
所述检测概率、定位精度和跟踪精度的三种干扰值计算公式如下:
[0045][0046][0047][0048]
其中,y1(r)表示在突防航线上干扰目标与组网雷达中心位于第r个距离点的检测概率的干扰值,r的取值范围为[r
min
,r
max
],r
max
表示组网雷达对干扰目标的最大探测距离,r
min
表示组网雷达对干扰目标进行有效拦截的最小距离,| |表示取绝对值操作,pd(r)表示干扰目标与组网雷达中心之间位于第r个距离点无干扰情况的检测概率,表示干扰目标与组网雷达之间位于第r个距离点有干扰情况的检测概率,y2(r)表示突防航线上干扰目标与组网雷达中心之间位于第r个距离点定位精度的干扰值,pg(r)表示干扰目标与组网雷达中心之间位于第r个距离点无干扰情况的定位精度,表示干扰目标与组网雷达中心之间位于第r个距离点有干扰情况的定位精度,y3(r)表示突防航线上干扰目标与组网雷达中心位于第r个距离点跟踪精度的干扰值,p
t
(r)表示干扰目标与组网雷达中心位于第r个距离点无干扰情况的跟踪精度,表示干扰目标与组网雷达中心之间位于第r个距离点有干扰情况的跟踪精度。
[0049]
第2步,对突防航线上所有距离点的三种干扰值进行加权求和处理后,得到突防航
线上的三种干扰值,并对三种干扰值向量化,得到干扰向量。
[0050]
所述由突防航线上检测概率、定位精度和跟踪精度的三种干扰值组成的干扰向量的计算公式如下:
[0051]
f=[f1,f2,f3]
[0052][0053]
其中,f表示由突防航线上检测概率、定位精度和跟踪精度的三种干扰值组成的干扰向量,f1表示突防航线上所有距离点处检测概率的干扰值进行加权求和处理后检测概率的干扰值,f2表示突防航线上所有距离点处定位精度的干扰值进行加权求和处理后定位精度的干扰值,f3表示突防航线上所有距离点处跟踪精度的干扰值进行加权求和处理后跟踪精度的干扰值,w(
·
)表示线性权值函数。
[0054]
第3步,将所有干扰向量组成干扰向量集。
[0055]
步骤3,基于nsga-ii算法的交叉变异方法,更新干扰资源分配向量集和干扰向量集。
[0056]
第1步,从干扰资源分配向量集中随机选取两个未选过的干扰资源分配向量,对所选的两个干扰资源分配向量进行交叉,得到两个交叉后的干扰资源分配向量。
[0057]
所述交叉公式如下:
[0058][0059][0060]
其中,和分别表示选取的两个干扰资源分配向量对应位置的元素进行交叉后的两个干扰资源分配向量,x1和x2分别表示随机选取的两个干扰资源分配向量,γ表示交叉算子,u表示在[0,1]范围选取的一个随机数。
[0061]
第2步,从干扰资源分配向量集中随机选取一个未选过的干扰资源分配向量,对所选的干扰资源分配向量进行变异,得到一个变异后的干扰资源分配向量。
[0062]
所述变异公式如下:
[0063]
x
new
=x+δ
[0064][0065]
其中,x
new
表示对所选的干扰资源分配向量中每个位置的元素进行变异后的干扰资源分配向量,x表示所选的干扰资源分配向量,δ表示变异算子。
[0066]
第3步,将两个交叉后的干扰资源分配向量与一个变异后的干扰资源分配向量添
加到干扰资源分配向量集中,得到更新后的干扰资源分配向量集。
[0067]
第4步,采用与步骤2中的第1步和第2步相同的方法,得到两个交叉后的干扰资源分配向量和一个变异后的干扰资源分配向量的三个干扰向量,将这三个干扰向量添加到干扰向量集中,得到更新后的干扰向量集。
[0068]
步骤4,基于nsga-ii算法中的快速非支配排序方法,根据更新后的干扰向量集对干扰资源分配向量集进行分层。
[0069]
第1步,从更新后的干扰向量集中选取一个未选过的干扰向量,将所选干扰向量与其余干扰向量分别进行比较,若所选干扰向量中的所有元素均大于其它干扰向量中的元素,则将该所选干扰向量对应的干扰资源分配集中的干扰资源分配向量吗,确定为与其它干扰向量对应的干扰资源分配向量为支配关系,否则,确定为无支配关系。
[0070]
第2步,将所有无支配关系的干扰资源分配向量组成一级非支配层,并将该级非支配层中的干扰向量标记为已选取的状态,将所有有支配关系的干扰资源分配向量对应的干扰向量集中的干扰向量标记为未选取的状态。
[0071]
第3步,判断更新后的干扰向量集中是否还有未选过的干扰向量,若是,则执行本步骤的第1步,否则,执行步骤5。
[0072]
步骤5,基于nsga-ii算法中的拥挤度方法,计算每层中每个干扰资源分配向量的拥挤度。
[0073]
第1步,对每层中每个干扰资源分配向量按照其元素值从大到小进行排序。
[0074]
第2步,按照下式,计算每层中每个干扰资源分配向量的拥挤度。
[0075][0076]
其中,表示第q层中第i个干扰资源分配向量的拥挤度,拥挤度的值越大则代表其对应的干扰资源分配向量的分布越均匀,拥挤度的值越小代表其对应的干扰资源分配向量的分布越集中,q=1,2,...,q,q表示整个干扰资源分配向量被分层的总层数,i=2,3,...,i-1,i表示第q层干扰资源分配向量的总数,每层的第1个和最后一个干扰资源分配向量的拥挤度均为无穷大,m表示干扰向量中元素的总数,表示第q层的第i+1个干扰资源分配向量对应的干扰向量中第j个元素,|
·
|表示取绝对值操作,表示第q层的第i-1个干扰资源分配向量对应的干扰向量中第j个元素。
[0077]
第3步,对每层所有的干扰资源分配向量按照拥挤度从大到小进行排序。
[0078]
步骤6,将排序后的干扰资源分配向量集中的前10个干扰资源分配向量作为当前最优解。
[0079]
步骤7,判断当前最优解的迭代次数是否等于干扰资源分配向量集中干扰资源分配向量的总数,若是,则执行步骤8,否则,将当前最优解包含的10个干扰资源分配向量组成新的干扰资源分配向量集后再执行步骤2。
[0080]
步骤8,选择最优的干扰资源分配方案。
[0081]
从当前最优解中选取一个与雷达的工作状态对应的干扰资源分配向量,作为最优的干扰资源分配方案。具体方法为:如果雷达的工作状态为搜索阶段,则选取当前最优解中检测概率干扰值最大的干扰向量对应的干扰资源分配向量;如果雷达的工作状态为定位阶
段,则选取当前最优解中定位精度干扰值最大的干扰向量对应的干扰资源分配向量;如果雷达的工作状态为跟踪阶段,则选取当前最优解中跟踪精度干扰值最大的干扰向量对应的干扰资源分配向量。
[0082]
下面结合仿真实验对本发明的效果做进一步的说明:
[0083]
1.仿真条件:
[0084]
本发明的仿真实验的硬件平台为:处理器为intel i7 1065g7 cpu,主频为1.3ghz,内存16gb。
[0085]
本发明的仿真实验的软件平台为:windows 10操作系统和matlab 2018b。
[0086]
参照图2,对本发明仿真实验的具体突防场景做进一步的描述。
[0087]
图2中的x轴坐标、y轴坐标和z轴坐标分别表示空间各点到原点的距离在x轴方向、y轴方向和z轴方向的投影,x轴、y轴和z轴坐标的单位均为km。本发明仿真实验中组网雷达有四部,分别标记为雷达1、雷达2、雷达3和雷达4,四部雷达的位置坐标分别为(0,10,0)、(10,10,0)、(0,0,0)和(10,0,0),四部雷达均处于搜索状态。干扰方有四部,分别标记为干扰机1、干扰机2、干扰机3和干扰机4。每部干扰机可选的干扰样式均为:噪声干扰、灵巧噪声干扰和欺骗干扰,四部干扰机伴随干扰目标沿着突防航线向组网雷达的中心运动。突防航线为直线,干扰目标的突防航线起点和终点的位置坐标分别为(4.7,8.1,0.75)和(252,355,121)。四部干扰机的突防航线起点分别为(4.51,7.77,0.8)、(4.25,7.96,0.6)、(4.9,7.6,0.65)和(4.5,7.8,0.55)。四部干扰机的突防航线终点分别为(250,355,122.6)、(237.5,360.5,121)、(260,353.5,120.8)和(249,359.4,118.2)。
[0088]
根据干扰方所拥有的干扰资源,生成100个干扰资源分配向量,即对应100个干扰资源分配方案,求解最优干扰资源分配方案的迭代次数设为500次,每部干扰机最多可同时干扰组网雷达内的两部雷达,每部干扰机只能选取噪声干扰、灵巧噪声干扰和欺骗干扰这三种干扰样式中的一种。
[0089]
2.仿真内容与结果分析:
[0090]
本发明仿真实验是采用本发明的干扰向量方法和现有技术的nsga-ii算法,分别求解干扰方在整个突防航线上的最优干扰资源分配方案,即从100个干扰资源分配方案中选取一个最优干扰资源分配方案,从而实现在此突防场景下干扰方的干扰资源分配达到最大的干扰效果。
[0091]
现有技术的nsga-ii算法是指,kalyanmoy deb等人在其发表论文“a fast elitist non-dominated sorting genetic algorithm for multi-objective optimization:nsga-ii”(ieee trans.evolutionary computation,2002,6(2):182-197)中提出的基于快速非支配排序的遗传算法,简称nsga-ii算法。
[0092]
下面结合表1和表2对本发明的效果做进一步的描述。
[0093]
表1为最优干扰资源分配方案表,表1包含10种干扰方案,每一种干扰方案包含四部干扰机的干扰对象和采用的干扰样式,每部干扰机的第一列和第二列分别代表干扰对象编号和采用的干扰样式编号,干扰对象的编号i代表第i部雷达,干扰样式编号1、2、3分别表示噪声干扰、灵巧噪声干扰和欺骗干扰。
[0094]
表1最优干扰资源分配方案表
[0095][0096]
表2干扰向量表
[0097]
干扰方案检测概率干扰值定位精度干扰值跟踪精度干扰值10.00040.93961.374820.16521.14121.112730.40350.67910.723440.00040.93981.374850.16580.65320.898560.40350.67920.723370.16580.65320.898580.00090.91681.253190.16491.13801.1302100.16561.03430.7577
[0098]
表2为干扰向量表,表2对应表1的10种干扰方案的干扰向量,每一种干扰方案的干扰向量由检测概率值、定位精度干扰值和跟踪精度干扰值组成,干扰值越大代表此方案的干扰效果越好。
[0099]
表1和表2在本发明的仿真实验中是通过干扰向量方法和nsga-ii算法对初始生成的100个干扰资源分配方案选取,进行500次的迭代以后得到的前10个干扰效果最好的干扰资源分配方案和其对应的干扰向量。
[0100]
结合表1和表2可以看出,根据对方雷达的状态来选择干扰资源分配方案,如果对方的组网雷达处于搜索干扰目标的状态,那么干扰方可以选择检测概率的干扰值最大时对应的干扰资源分配方案3,如果对方的组网雷达处于对干扰目标进行定位的阶段,那么干扰方可以选择定位精度的干扰值最大时对应的干扰资源分配方案2,如果对方的组网雷达处于干扰目标进行跟踪的阶段,那么干扰方可以选择跟踪精度的干扰值最大时对应的干扰资
源分配方案1,由于此突防场景下的组网雷达处于搜索状态,将干扰资源分配方案3作为最优干扰资源分配方案,即在4部干扰机伴随干扰目标在突防航线上运动时,干扰机1采用干扰样式1干扰组网雷达内的雷达1和雷达4和第四部雷达,干扰机2采用干扰样式1干扰组网雷达内的雷达1和雷达4,干扰机3采用干扰样式3干扰组网雷达内的雷达1和雷达3,干扰机4采用干扰样式1干扰组网雷达内的雷达1和雷达4
[0101]
以上仿真实验表明,本发明方法所得到的最优干扰资源分配方案是基于检测概率、定位精度和跟踪精度三个评估指标,求解了多种干扰资源分配向量在整个突防航线上对应的干扰向量,克服了突防过程中最优干扰资源分配方案的场景局限性的问题;采用nsga-ii算法比较不同干扰资源分配向量的干扰向量选取最优的干扰资源分配向量,得到最优的干扰资源分配方案,克服了突防过程中最优干扰资源分配方案的指标间依赖性的问题,使得本发明得到的最优干扰资源分配方案具有指标的独立性。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1