一种基于近红外光谱的烟叶焦油解析方法与流程
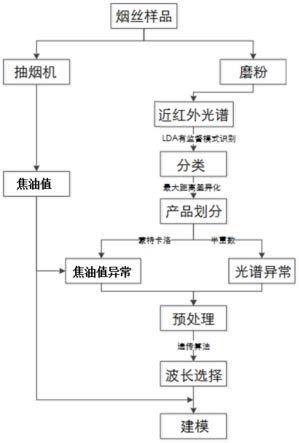
1.本发明涉及卷烟化学值检测技术领域,特别涉及一种基于近红外光谱的烟叶焦油解析方法。
背景技术:
2.焦油是卷烟成品的一种重要致香物质,其是卷烟香气的重要组成部分之一;但是卷烟焦油在烟气的形成中也会对人体形成一定的危害,一般认为卷烟烟气中的有害成分主要集中在焦油中,国际上一般以焦油量的高低来评价卷烟的安全性,因此焦油检测在烟草成品的检测中起到非常重要而且必要的作用。
3.在传统的焦油检测中,一般采取抽烟机的检测形式;抽烟机检测一般耗时比较长,对卷烟质量的尤其是卷烟的安全性指标的评价比较滞后;更重要的是,在抽烟机的检测中,抽烟机的检测结果受卷烟滤嘴,卷烟滤纸等卷烟辅料的影响较大;近年来,近红外光谱由于其含有大量的化学成分信息,以及无损的分析技术作为一种快速的质量解析技术工具取得了广泛的应用,其在复烤厂的烟叶原料质量控制以及质量评价领域较为成熟,但在其分析焦油的检测却尚不成熟。鉴于上述情况,本发明旨在提供一种运用近红外光谱结合化学计量学方法对卷烟焦油的含量进行快速无损的检测以及评价的方式。
技术实现要素:
4.鉴于传统的抽烟机检测方法的滞后性及外部辅料影响的缺点,本发明的目的在于提供一种基于近红外快速无损的焦油解析方法,为卷烟产品的开发以及卷烟产品质量的监控提供指导。
5.本发明所解决的问题可以使用以下技术方案来实现:
6.本发明提供一种基于近红外光谱的烟叶焦油解析方法,其特征在于,包括以下步骤:
7.步骤1,获取不同品种的成品烟丝样品,取该烟丝样品磨粉后进行近红外光谱扫描,获取对应的近红外光谱信息,并且获取抽烟机给出的焦油标准值数据;
8.步骤2,将对应的近红外光谱信息关联到抽烟机给出的焦油标准值数据,并建立焦油模型;
9.步骤3,运用lda线性判别分析算法的有监督模式识别,将焦油光谱标准数据分成不同的类别;
10.步骤4,运用最大距离差异化选择法选择80%的样本数据作为建模集,剩余20%的样本数据作为验证集;
11.步骤5,通过半重数采样法、蒙特卡洛交叉验证进行奇异样本的剔除;
12.步骤6,通过一阶导数对光谱进行预处理;
13.步骤7,利用遗传算法对光谱波长进行筛选;
14.步骤8,利用主成分分析、典型相关分析、多元线性回归相结合构建近红外光谱与
焦油标准值之间的关联模型;
15.步骤9,利用步骤8的关联模型解析成品烟丝的焦油值:先对待测的成品烟丝磨粉后进行近红外光谱扫描,然后将获得的近红外光谱信息输入关联模型,则得出对应的焦油值。
16.进一步地,在本发明提供的基于近红外光谱的烟叶焦油解析方法中,还可以具有这样的特征:其中,步骤3具体包括如下步骤:
17.步骤3-1,输入样本光谱标准值数据集x:
18.x=(x1,x2,
…
,xi,
…
,xn),xi∈rdꢀꢀꢀ
(1)
19.式(1)中,x表示样本光谱标准值数据集;xi表示光谱标准值数据集任意一个样本;rd表示r空间的d维度;
20.步骤3-2,将样本光谱标准值数据集x经过w变换后得到光谱标准值数据集t:
[0021][0022]
w变换的变换规则如下:
[0023]
t=whx
ꢀꢀꢀꢀꢀꢀ
(3)
[0024]
式(2)(3)中,ti表示变换后近红外光谱数据集t中的任意一个样本;表示变换后xi到新的维度w表示投影到的低维空间的维度为时对应的基向量;h表示转换过程中的导向量;
[0025]
定义均值为中心点,并设xk为任意一个划分的类别ck的样本数据集,xk=(x1,x2,
…
,xj,
…
,xn),xj表示数据集任意一个样本,则该类别数据集的中心点为:
[0026][0027]
式(4)中,n为类别ck中样本的总数,即xj的数目;
[0028]
由于样本数据集xk经过w变换后得到据集tk:
[0029]
tk=(t1,t,
…
,tj…
,tn)
ꢀꢀꢀ
(5)
[0030]
则,中心点经过w变换后得到的中心点表示为:
[0031][0032]
式(5)(6)中,即样本集xk的中心点的投影,也即xk中各元素投影后的均值;
[0033]
步骤3-3,计算类内散度矩阵sw:
[0034]
对于投影之后类别为ck的类内散列度为:
[0035][0036]
将式(7)简化得到下式:
[0037]s2k
=whskw
ꢀꢀꢀ
(8)
[0038]
式(8)中,s
2k
表示类别为ck的类内散列度;sk表示类别为ck的类内散列度开根号;
[0039]
式(8)仅表示类别ck的散列度,将所有类别的散列度相加则得到样本整体的类内
离散度:
[0040][0041]
式(9)中,jw表示样本整体的类内离散度;k表示第k个样本类别,k的取值为1,2,
…
,c,样本类别总共划分为c类,第k个样本类别记为ck;
[0042]
将式(9)简化得到下式:
[0043]jw
=whsww
ꢀꢀ
(10)
[0044]
式(10)中,sw为类内散度矩阵;
[0045]
步骤3-4,计算类间散度矩阵sa:
[0046]
①
假设只有两个类别时,两个类别样本数据集合分别为t
c1
,t
c2
,此时,两者的类间离散度ja为:
[0047][0048]
式(11)中,表示样本数据集合t
c1
的中心点;表示样本数据集合t
c2
的中心点;
[0049]
将式(11)整理成只包含x的式子:
[0050][0051]
令:
[0052][0053]
则:
[0054]
ja=whsaw
ꢀꢀꢀꢀ
(14)
[0055]
式(12)(13)(14)中,表示类别样本数据集合t
c1
对应的未经w变换前的类别样本数据集合的中心点;表示类别样本数据集合t
c2
对应的未经w变换前的类别样本数据集合的中心点;sa为类间散度矩阵;
[0056]
②
假设有多个类别时,类间离散度为:
[0057][0058]
式(15)中,此时共有c(c-1)/2项的求和,时间复杂度为0(c2),),分别表示类别样本数据集合tk、tm的中心点;
[0059]
通过式(15),求得tk和tm的类间散度矩阵为:
[0060][0061]
式(16)中,表示类别样本数据集合tk、tm的对应的未经w变换前的类别样
本数据集合的中心点;
[0062]
定义样本数据集整体散度:
[0063][0064]
式(17)中,sh表示样本数据集x的整体散度;x表示所有类别的整体样本数据集,也即步骤3-1输入的样本数据集x;xk表示类别ck的样本数据集;表示整体样本数据集x的中心点;
[0065]
样本数据集x的整体散度为类间散度和类内散度之和,则有:
[0066]
sh=sa+swꢀꢀꢀꢀꢀ
(18)
[0067]
于是,类间散度按照下式进行计算:
[0068][0069]
式(19)中,nk表示类别ck的样本数据集中样本的总数;
[0070]
同样,最终得到类间散度为:
[0071]
ja=whsaw
ꢀꢀ
(20)
[0072]
式(20)中,sa为类间散度矩阵;
[0073]
步骤3-5,构造目标函数,优化矩阵:
[0074]
利用得到的类内散度jw和类间散度ja,现在可以使用这两个散度来构造目标函数j(w):
[0075][0076]
目标函数最大时的w,通过w映射后的样本数据具有最佳的类间距离和类内距离;从目标函数可以看出,当w成倍的放大或缩小时,目标函数保持不变,因而通过目标函数最大只能得到w的方向;为了使计算简化,假设分母的值为1,即:
[0077]
whsww=1
ꢀꢀ
(22)
[0078]
式(22)的计算结果是一个数,而不是一个向量或矩阵,设为:
[0079]
whsww=g
ꢀꢀꢀ
(23)
[0080]
令:
[0081][0082]
则:
[0083][0084]
令导数为零:
[0085]
2saw-2γsww=0,saw=sw(γw)
ꢀꢀꢀ
(26)
[0086]
假设sw是可逆的,则:
[0087]sw-1
saw=γw
ꢀꢀ
(27)
[0088]
式((27)中,γ表示样本数据集的特征向量;w表示投影到的低维空间对应的基向
量;
[0089]
步骤3-6,计算s
w-1
sa的最大的d个特征值和对应的d个特征向量(w1,w2,
…
,wd),得到投影矩阵w,d为降维的维度:
[0090]
w为特征向量,为特征值最大时所对应的特征向量;特征值最大,则在对应的特征向量上的变化最大;
[0091]
对上式中的saw进行分析得到:
[0092][0093]
设
[0094][0095]
式((29)中,γk表示样本数据集k类的特征向量;
[0096]
则:
[0097][0098]
得到了样本的最佳映射w,w=(w1,w2,
…
,wd),当将样本集x(也即步骤3-1输入的样本数据集x)使用w进行映射后得到了具有最佳分类效果的样本和c个分类类别。
[0099]
进一步地,在本发明提供的基于近红外光谱的烟叶焦油解析方法中,还可以具有这样的特征:其中,步骤4的具体过程如下:步骤4-1,在任意类别ck中,计算每个类别中,两样本的距离:设n维向量a(x
11
,x
12
,
…
,x
ln
)与b(x
21
,x
22
,
…
,x
2n
),则两样本的距离公式表示如下:
[0100][0101]
依次类推,计算每两个样本之间的距离;
[0102]
步骤4-2,选择最远距离d
im
对应的两个样本作为建模基准,选择距离两个样本最远的样本d
im1
和d
im2
,如下比较d
im1
和d
im2
之间的距离,
[0103][0104]
选择最大距者作为建模数据;
[0105]
步骤4-3,在剩余的样本数据中继续按照步骤4-2的标准进行选择,直至选择出80%的样本数据,将此80%的样本数据作为建模集,将剩余20%的样本数据作为验证集;
[0106]
步骤4-4,对于其他类别的建模集的数据,也按照步骤4-1至步骤4-3的过程进行,最终所得的建模集中包含每个类别的最大距离差异化样本。
[0107]
进一步地,在本发明提供的基于近红外光谱的烟叶焦油解析方法中,还可以具有
这样的特征:其中,步骤6中一阶导数的预处理方法是将移动窗口多项式拟合用于求导,利用导数取代窗口的中心点,窗口每次只移动一个数据点,直到整个光谱大数据点都得到求导的结果。
[0108]
进一步地,在本发明提供的基于近红外光谱的烟叶焦油解析方法中,还可以具有这样的特征:其其中,步骤7利用遗传算法对光谱波长进行筛选的具体过程如下:
[0109]
步骤7-1,对近红外波长点进行编码,形成二进制字符;
[0110]
步骤7-2,所有波长点初始化,随机选择初始化种群的数目;
[0111]
步骤7-3,选择近红外定量模型的预测标准偏差sep;
[0112]
步骤7-4,选择近红外波长点适应度高的个体保留到下一代一起搜索新的波长点组,按照通过适应度函数的波长点出现的频率选择近红外建模波长点;
[0113]
步骤7-5,用留一验证法通过验证集的预测标准误差来确定选择近红外波长点的数目,并确定主成分数。
[0114]
进一步地,在本发明提供的基于近红外光谱的烟叶焦油解析方法中,还可以具有这样的特征:其中,步骤8利用主成分分析、典型相关分析、多元线性回归相结合构建近红外光谱与焦油标准值之间的关联模型如下:
[0115]
y=tβq^t+f=tb+f
ꢀꢀꢀꢀ
(32)
[0116]
式(32)中,t为光谱集的得分矩阵;y为光谱集对应的焦油值,u为y的得分矩阵,q为y对应于u的负荷矩阵,β为回归系数矩阵,f为残差矩阵,b为样本标准数据值。
[0117]
本发明的作用和效果:
[0118]
本发明的基于近红外光谱的烟叶焦油解析方法以焦油数据为基础,根据聚类原理,细化类别后最大化包含各个类别的样本量,使得整个建模过程中数据量的合理化来保证整个模型的精准度。是对卷烟企业目前精细化数据管理的有益补充和未来大数据需求提供精准的数据来源保障,同时为卷烟产品的开发以及卷烟产品质量的监控提供指导。
附图说明
[0119]
图1是本发明实施例中近红外光谱的烟叶焦油解析方法的流程图;
[0120]
图2是本发明实施例中获取的烟丝样品的近红外光谱图;
[0121]
图3是本发明实施例中通过抽烟机得到的烟丝样品的焦油标准值分布图;
[0122]
图4是本发明实施例中的样品种类的分布图;
[0123]
图5是本发明实施例中的建模集和验证集的分布图;
[0124]
图6是本发明实施例中的异常光谱样品的分布图;
[0125]
图7是本发明实施例中一阶导数预处理图;
[0126]
图8是本发明实施例中近红外光谱与焦油标准值的关联模型图。
具体实施方式
[0127]
为了使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,以下实施例结合附图对本发明的技术方案作具体阐述。
[0128]
《实施例》
[0129]
本实施例的一种基于近红外光谱的烟叶焦油解析方法,该方法包括以下步骤:
[0130]
步骤1,获取不同品种的成品烟丝样品,取该烟丝样品磨粉后进行近红外光谱扫描,获取对应的近红外光谱信息。另外通过获取该批成品烟丝样品通过抽烟机给出的焦油值,该焦油值作为焦油标准值数据。
[0131]
在本实施例中选取某卷烟厂具有代表性的75组不同品种的成品烟丝样本,通过磨粉后扫描实验室近红外光谱,图2为获取对应的近红外光谱信息。
[0132]
步骤2,将对应的近红外光谱信息关联到抽烟机给出的焦油标准值数据,并建立焦油模型。
[0133]
在本实施例中如图3所示,图3示意了对应的近红外光谱信息关联到抽烟机给出的焦油标准值数据。
[0134]
步骤3,运用lda线性判别分析算法的有监督模式识别,将焦油标准值数据分成不同的类别,本实施例的焦油值分类情况如图4所示,其中第一判别式、第二判别式是lda线性判别分析算法软件中自带内容。
[0135]
lda线性判别分析和有监督模式识别其分类的核心思想是将高维样本数据投影到最佳分类的向量空间,保证在新的子空间中,有更大的类间距离和更小的类内距离
[0136]
步骤3具体包括如下步骤:
[0137]
步骤3-1,输入样本数据集x:
[0138]
x=(x1,x2,
…
,xi,
…
,xn),xi∈rdꢀꢀ
(1)
[0139]
式(1)中,x表示样本数据集;xi表示数据集任意一个样本;rd表示r空间的d维度;
[0140]
步骤3-2,将样本数据集x经过w变换后得到据集t:
[0141][0142]
w变换的变换规则如下:
[0143]
t=whx
ꢀꢀꢀꢀ
(3)
[0144]
式(2)(3)中,ti表示变换后近红外光谱数据集t中的任意一个样本;表示变换后xi到新的维度w表示投影到的低维空间的维度为时对应的基向量;h表示转换过程中的导向量。
[0145]
变换的目的在于使得同一类的样本被w作用后距离更近,不同类的样本被w作用后距离更远。
[0146]
为了能更好的度量类内距离和类间距离,定义均值为中心点,并设xk为任意一个划分的类别ck的样本数据集,xk=(x1,x2,
…
,xj,
…
,xn),xj表示数据集任意一个样本,则该类别数据集的中心点为:
[0147][0148]
式(4)中,n为类别ck中样本的总数,即xj的数目;
[0149]
由于样本数据集xk经过w变换后得到据集tk:
[0150]
tk=(t1,t,
…
,tj…
,tn)
ꢀꢀꢀ
(5)
[0151]
则,中心点经过w变换后得到的中心点表示为:
[0152][0153]
式(5)(6)中,即样本集xk的中心点的投影,也即xk中各元素投影后的均值;
[0154]
步骤3-3,计算类内散度矩阵sw:
[0155]
为了使投影之后同类之间样本距离更小,而不同类之间的样本距离越大用类内和类间距离来计算。类内距离主要用各样本点到该样本点所在类别的中心点的距离和来表示,使用散列度来表示一个类别的类内距离。
[0156]
对于投影之后类别为ck的类内散列度为:
[0157][0158]
将式(7)简化得到下式:
[0159]s2k
=whskw
ꢀꢀ
(8)
[0160]
式(8)中,s
2k
表示类别为ck的类内散列度;sk表示类别为ck的类内散列度开根号;
[0161]
式(8)仅表示类别ck的散列度,将所有类别的散列度相加则得到样本整体的类内离散度:
[0162][0163]
式(9)中,jw表示样本整体的类内离散度;k表示第k个样本类别,k的取值为1,2,
…
,c,样本类别总共划分为c类,第k个样本类别记为ck;
[0164]
将式(9)简化得到下式:
[0165]jw
=whsww
ꢀꢀ
(10)
[0166]
式(10)中,sw为类内散度矩阵;
[0167]
步骤3-4,计算类间散度矩阵sa:
[0168]
①
假设只有两个类别时,两个类别样本数据集合分别为t
c1
,t
c2
,此时,两者的类间离散度ja为:
[0169][0170]
式(11)中,表示样本数据集合t
c1
的中心点;表示样本数据集合t
c2
的中心点;
[0171]
将式(11)整理成只包含x的式子:
[0172][0173]
令:
[0174]
[0175]
则:
[0176]
ja=whsaw
ꢀꢀꢀꢀꢀ
(14)
[0177]
式(12)(13)(14)中,表示类别样本数据集合t
c1
对应的未经w变换前的类别样本数据集合的中心点;表示类别样本数据集合t
c2
对应的未经w变换前的类别样本数据集合的中心点;sa为类间散度矩阵;
[0178]
②
假设有多个类别时,类间离散度为:
[0179][0180]
式(15)中,此时共有c(c-1)/2项的求和,时间复杂度为0(c2),),分别表示类别样本数据集合tk、tm的中心点;
[0181]
通过式(15),求得tk和tm的类间散度矩阵为:
[0182][0183]
式(16)中,表示类别样本数据集合tk、tm的对应的未经w变换前的类别样本数据集合的中心点;
[0184]
定义样本数据集整体散度:
[0185][0186]
式(17)中,sh表示样本数据集x的整体散度;x表示所有类别的整体样本数据集,也即步骤3-1输入的样本数据集x;xk表示类别ck的样本数据集;表示整体样本数据集x的中心点;
[0187]
样本数据集x的整体散度为类间散度和类内散度之和,则有:
[0188]
sh=sa+swꢀꢀꢀꢀ
(18)
[0189]
于是,类间散度按照下式进行计算:
[0190][0191]
式(19)中,nk表示类别ck的样本数据集中样本的总数;
[0192]
同样,最终得到类间散度为:
[0193]
ja=whsaw
ꢀꢀ
(20)
[0194]
式(20)中,sa为类间散度矩阵;
[0195]
步骤3-5,构造目标函数,优化矩阵:
[0196]
利用得到的类内散度jw和类间散度ja,现在可以使用这两个散度来构造目标函数j(w):
[0197]
[0198]
目标函数最大时的w,通过w映射后的样本数据具有最佳的类间距离和类内距离;从目标函数可以看出,当w成倍的放大或缩小时,目标函数保持不变,因而通过目标函数最大只能得到w的方向;为了使计算简化,假设分母的值为1,即:
[0199]
whsww=1
ꢀꢀꢀ
(22)
[0200]
式(22)的计算结果是一个数,而不是一个向量或矩阵,设为:
[0201]
whsww=g
ꢀꢀꢀ
(23)
[0202]
令:
[0203][0204]
则:
[0205][0206]
令导数为零:
[0207]
2saw-2γsww=0,saw=sw(γw)
ꢀꢀꢀ
(26)
[0208]
假设sw是可逆的,则:
[0209]sw-1
saw=γw
ꢀꢀꢀ
(27)
[0210]
式((27)中,γ表示样本数据集的特征向量;w表示投影到的低维空间对应的基向量;
[0211]
步骤3-6,计算s
w-1
sa的最大的d个特征值和对应的d个特征向量(w1,w2,
…
,wd),得到投影矩阵w,d为降维的维度:
[0212]
w为特征向量,为特征值最大时所对应的特征向量;特征值最大,则在对应的特征向量上的变化最大;
[0213]
对上式中的saw进行分析得到:
[0214][0215]
设
[0216][0217]
式((29)中,γk表示样本数据集k类的特征向量;
[0218]
则:
[0219][0220]
得到了样本的最佳映射w,w=(w1,w2,
…
,wd),当将样本集x(也即步骤3-1输入的样本数据集x)使用w进行映射后得到了具有最佳分类效果的样本和c个分类类别。
[0221]
步骤4,如图5所示,运用最大距离差异化选择法选择80%的样本数据作为建模集,剩余20%的样本数据作为验证集,图中的第一主成分、第二主成分是最大距离差异化选择法软件自带内容。
[0222]
步骤4的具体过程如下:
[0223]
步骤4-1,在任意类别ck中,计算每个类别中,两样本的距离:
[0224]
设n维向量a(x
11
,x
12
,
…
,x
1n
)与b(x
21
,x
22
,
…
,x
2n
),则两样本的距离公式表示如下:
[0225][0226]
依次类推,计算每两个样本之间的距离;
[0227]
步骤4-2,选择最远距离d
im
对应的两个样本作为建模基准,选择距离两个样本最远的样本d
im1
和d
im2
,如下比较d
im1
和d
im2
之间的距离,
[0228][0229]
选择最大距者作为建模数据;
[0230]
步骤4-3,在剩余的样本数据中继续按照步骤4-2的标准进行选择,直至选择出80%的样本数据,将此80%的样本数据作为建模集,将剩余20%的样本数据作为验证集;
[0231]
步骤4-4,对于其他类别的建模集的数据,也按照步骤4-1至步骤4-3的过程进行,最终所得的建模集中包含每个类别的最大距离差异化样本。
[0232]
步骤5,通过半重数采样法、蒙特卡洛交叉验证进行奇异样本的剔除。
[0233]
步骤5具体过程是:随机将焦油的验证集样本进行预测误差计算,正常焦油样本的预测误差一般较小,其均值在零附近,呈正态分布趋势,异常样本数据奇异的预测误差则一般较大,远离零点,但是焦油样本光谱奇异点预测误差分布的方差一般较大,即不同性质的样本具有不同的分布,以焦油预测样本的均值绝对值为x轴,标准差为y轴作图,可以得到附图6所示的散点图,根据图可以判断出异常光谱和异常化学值焦油样本并进行剔除。
[0234]
步骤6,通过一阶导数对光谱进行预处理。
[0235]
本步骤中一阶导数的预处理方法是将移动窗口多项式拟合用于求导,利用导数取代窗口的中心点,窗口每次只移动一个数据点,直到整个光谱大数据点都得到求导的结果。
[0236]
本实施例中使用移动窗口宽度为13对每个校正集的焦油样本逐步移动平滑,过滤掉无用的噪声,保留有效的光谱信息,结果如附图7。
[0237]
步骤7,利用遗传算法对光谱波长进行筛选。
[0238]
步骤7利用遗传算法对光谱波长进行筛选的具体过程如下:
[0239]
步骤7-1,对近红外波长点进行编码,形成二进制字符;
[0240]
步骤7-2,所有波长点初始化,随机选择初始化种群的数目;
[0241]
步骤7-3,选择近红外定量模型的预测标准偏差sep;
[0242]
步骤7-4,选择近红外波长点适应度高的个体保留到下一代一起搜索新的波长点组,按照通过适应度函数的波长点出现的频率选择近红外建模波长点;
[0243]
步骤7-5,用留一验证法通过验证集的预测标准误差来确定选择近红外波长点的数目,并确定主成分数。
[0244]
步骤8,利用主成分分析、典型相关分析、多元线性回归相结合构建近红外光谱与焦油标准值之间的关联模型,本实施例中模型图如图8所示。
[0245]
该关联模型可表示为如下:
[0246]
y=tβq^t+f=tb+f
ꢀꢀꢀꢀ
(32)
[0247]
式(32)中,t为光谱集的得分矩阵;y为光谱集对应的焦油值,u为y的得分矩阵,q为y对应于u的负荷矩阵,β为回归系数矩阵,f为残差矩阵,b为样本标准数据值。
[0248]
步骤9,利用步骤8的关联模型解析成品烟丝的焦油值:先对待测的成品烟丝磨粉后进行近红外光谱扫描,然后将获得的近红外光谱信息输入关联模型,则得出对应的焦油值。
[0249]
参阅图8,在本实施例中为验证模型的测试效果,本实施例中采用验证集进行验证,见下表;
[0250] 预测水分平均值真实水分平均值平均绝对误差平均相对误差%校正集12.4112.410.181.47验证集12.0211.990.141.18
[0251]
校正集自身模型平均绝对误差为0.18,平均相对误差为1.47%,相关系数0.85,验证的平均绝对误差为0.14,平均相对误差为1.18%,相关系数0.87,统计整个校正模型中数据的平均绝对误差在
±
0.5%范围内的合格率为91.4%,说明使用本发明方法建立的关联模型能够应用于实际生产中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1