一种高精度土壤重金属浓度空间预测方法
1.本发明涉及生态环境保护领域,特别涉及一种高精度土壤重金属浓度空间预测方法。
背景技术:
2.宏观上土壤重金属污染程度的时空变化主要受两类因素影响与控制:1)地质因素,自然状态下由地质因素导致的土壤重金属本底污染程度较低;2)人类活动,其变化直接反映人类活动强度与污染程度,且导致的重金属浓度变化较大。微观上重金属浓度的变化受重金属自身离子状态、与其它物质(土壤、植物根系、微生物)的相互作用(吸附、迁移、交换)等因素影响。但无论重金属污染源是什么、与其他物质交换速率如何,在空间上的变化均有3点特征:1)空间位置越邻近,重金属浓度越相近(空间自相关性);2)当空间位置间的距离达到一定阈值时,重金属浓度差异较大(空间异质性);3)不同的重金属来源可以借助相关的地理要素表征,如母岩类型可以利用地质资料中的岩性分布来指示。
3.归纳上述特点,土壤重金属污染程度空间推测方法可分为3类:1)空间自相关法,即土壤重金属浓度基于地理位置越相近越相关的原理,依赖于区域空间内实验样本点数据信息,通过插值实现,该类方法单纯利用已知样本信息并由此根据地理距离推测未知点信息,对样点的数量、质量、空间分布要求严格,并未考虑其他影响因素,精度较低。2)基于要素相关法,即综合分析影响重金属浓度的多种地理变量,通过数学模型建立重金属浓度与相关要素之间的映射关系,最终用于对未知区域的预测。该类方法考虑相关地理变量对重金属浓度的影响,通过数据驱动的机器学习方法达到较高精度,但具有严重依赖输入数据集的准确性与完备性的缺点。3)空间自相关与要素相关两者结合的方法,同时将地理距离与其它相关地理变量应用到空间推测。该方法有效综合利用上述两类方法优点,达到了优势互补,但仍然存在两点不足:1)所用的地理变量在小区域内高度空间相似,而重金属浓度高度空间异质,导致地理变量的空间变化不能真实反映重金属浓度的空间变化;2)依赖数据驱动的算法提升精度,不能有效量化重金属污染程度。鉴于上述存在的不足,重金属浓度的空间预测迫切需要找到更优的方法。
技术实现要素:
4.为了解决上述技术问题,本发明提供一种算法简单、适用范围广的高精度土壤重金属浓度空间预测方法。
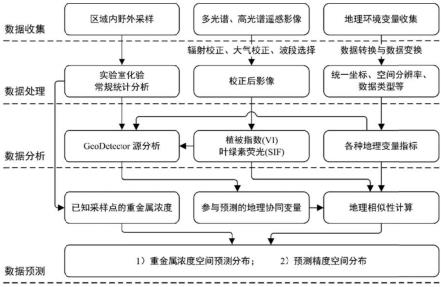
5.本发明解决上述技术问题的技术方案是:一种高精度土壤重金属浓度空间预测方法,包括以下步骤:
6.步骤一,数据获取:包括区域内野外采样、多光谱高光谱遥感影像准备及地理环境变量的获取;
7.步骤二,数据预处理:对野外采样样品的实验室化验及常规统计分析,检测出重金属异常点位;对影像的辐射校正、大气校正与波段选择得到校正后影像待用;地理环境变量
通过数据转换与数据变换使得各种变量统一坐标、统一空间分辨率与统一数据类型;
8.步骤三,数据反演与分析:计算得到各类植被指数和日光诱导叶绿素荧光强度,结合各种地理变量与样本分析点位数据进行地理探测,以决定参与预测的环境地理协同变量;
9.步骤四,重金属浓度预测:由得到的环境地理协同变量,进行地理相似性计算,结合已知采样点的重金属浓度值,实现对未知点重金属浓度预测,得到预测的重金属浓度空间分布;
10.步骤五,精度估算:计算预测的重金属浓度空间分布的精度。
11.上述高精度土壤重金属浓度空间预测方法,所述步骤三中,采用夫琅和费暗线法反演获取日光诱导叶绿素荧光强度;
12.基于夫琅和费暗线的sif反演算法fld:由于太阳大气中某些元素的吸收,太阳辐射在到达地表后其辐照度光谱形成许多波段宽度为0.1-10nm的细小暗线,即夫琅和费吸收暗线,在夫琅和费吸收暗线处,植被的反射光较弱,荧光效果明显,因此利用夫琅和费暗线反演日光诱导叶绿素荧光值sif;
13.假定地球表面为各向同性表面反射,忽略冠层传感器间的大气效应和邻近效应的影响,认为传感器接收到的地表视反射辐亮度是地表植被太阳反射辐亮度与日光诱导叶绿素荧光反射的两部分之和,如式(1):
[0014][0015]
其中,λ为波长,l(λ)为传感器观测到的地表视反射辐亮度,r(λ)为地表反射率,e(λ)为地表入射辐照度,sif(λ)为植被发射的叶绿素荧光强度;
[0016]
根据夫琅和费吸收暗线区间的太阳辐照度光谱和传感器观测到的辐亮度光谱,可得出各参数满足式(2):
[0017][0018]
其中,l
in
为波长λ
in
处的辐亮度,l
out
为波长λ
out
处的辐亮度,i
in
为波长λ
in
处的太阳辐照度,i
out
为波长λ
out
处的太阳辐照度,f
in
为波长λ
in
处的日光诱导叶绿素荧光强度,f
out
为波长λ
out
处的日光诱导叶绿素荧光强度,r
in
为波长为λ
in
处的地表反射率,r
out
为波长λ
out
处的地表反射率;
[0019]
标准fld算法假设夫琅和费吸收暗线及其相邻谱区的植被反射率和荧光强度在很窄的波段范围内均不随波长变化,即:
[0020]rin
=r
out
=r
fld f
in
=f
out
=f
fld
ꢀꢀ
(3)
[0021]
其中,r
fld
为利用fld算法计算的地表反射率;f
fld
为利用fld算法计算的日光诱导叶绿素荧光强度;
[0022]
联合式(2)和(3),可得:
[0023][0024]
针对gf-5高光谱影像选择对应的夫琅和费吸收暗线波段和其邻近波段。
[0025]
上述高精度土壤重金属浓度空间预测方法,所述步骤四的核心在于每个单独土壤样本点所反映的土壤属性值与其所在环境之间的关系,每个单独的样本点作为具有相似环境条件的位置的替代物,并以此去预测与样本点环境相似性达到要求的那些位置的土壤属性值;具体归纳为三个过程:
[0026]
(1)描述各点的环境特征;用多个环境协变量高程、坡度、坡向、归一化水分指数ndwi
1240
、归一化色素叶绿素指数npci、修正的简单比率植被指数msri-2、日光诱导叶绿素荧光sif和归一化红边植被指数ndvi
705
描述与目标土壤特性相关的环境特征,并形成一个该位置的环境向量e:
[0027]
e=(e1,e2,e3,...,em)
ꢀꢀ
(5)
[0028]
其中,e1,e2,......,em分别指考虑的第1个、第2个,
……
,第m个环境协变量,由这m个环境协变量共同形成一个m维的环境向量e;
[0029]
(2)每个未知点和每个土壤样本点的环境相似性评估;
[0030]
计算未知点与样本点之间的环境相似性:
[0031]si,j
=p(e(e
1i
,e
1j
),e(e
2i
,e
2j
),...,e(e
vi
,e
vj
),...,e(e
mi
,e
mj
))
ꢀꢀ
(6)
[0032]
其中,s
i,j
表示研究区未知点i与样本点j之间的环境相似性,e
vi
和e
vj
分别表示第i个未知点与第j个样本点处第v个环境协变量的属性,e
mi
和e
mj
分别表示第i个未知点和第j个样本点处第m个环境协变量的属性,e(
·
)和p(
·
)分别是环境协变量尺度和土壤样本尺度下的函数;函数e(
·
)用于计算环境协变量尺度下的环境相似性;对于给定的m个环境协变量,有从第1个环境协变量至第m个环境协变量的环境相似性,分别表示为e(e
1i
,e
1j
)、e(e
2i
,e
2j
)、......、e(e
mi
,e
mj
),e(
·
)描述了当未知点的环境协变量值偏离样本点的环境协变量值时,未知点和样本点之间的环境相似性会如何变化;基于此,定义e(
·
):
[0033][0034]
其中,是研究区内第v个环境协变量的标准偏差,是未知点i与样本点j处第v个环境协变量的平均偏差的平方根;
[0035]
[0036]
式(8)中,k为未知点个数;
[0037]
函数p(
·
)用于整合环境协变量尺度与土壤样本尺度的环境相似性,使用最小算子法即将所有环境协变量相似性中的最小值作为土壤样本水平的环境相似性;
[0038]
将每个未知点与所有土壤样本点的环境相似性组织成每个未知点的环境相似性向量si:
[0039]
si=(s
i,1
,s
i,2
,...,s
i,j
)
ꢀꢀ
(9)
[0040]
(3)各未知点的预测不确定性的量化及目标土壤属性值的估算;
[0041]
若未知点与所用样本点之间的环境相似性达不到要求,则现有的样本点就不可用于表示未知点,故需要计算预测不确定性用于评估使用现有样本点对未知点进行估算的可靠性,不确定性与环境相似性呈反比;不确定性计算方法如式(10)所示:
[0042]
uncertaintyi=1-max(s
i,1
,s
i,2
,...,s
i,n
)
ꢀꢀ
(10)
[0043]
其中,uncertaintyi为未知点i的不确定性,n为用于估算目标土壤属性值的未知点的个数,max(s
i,1
,s
i,2
,...,s
i,n
)表示取相似性s
i,1
、s
i,2
、......、s
i,n
的最大值;
[0044]
设置用户定义的不确定性阈值;某一未知点的不确定性若大于自定义的不确定性阈值,则将该未知点设置为无效值;若未知点不确定性小于或等于自定义的不确定性阈值,则使用加权平均值法参与估算未知点目标属性值,如式(11)所示:
[0045][0046]
其中,ci为未知点i的土壤重金属预测浓度,n
′
为所选样本点的个数,其与未知点i的环境相似性大于“1-不确定性阈值”,一般可以设置不确定性阈值为1%~30%,本研究选择30%作为不确定性阈值;cj为样本点j的土壤重金属浓度。
[0047]
上述高精度土壤重金属浓度空间预测方法,所述步骤五中,计算未知点i的重金属浓度预测精度:
[0048]
假定样本点j的重金属浓度为cj,样本点j的地理相似性为sj,未知点i的地理相似性为si,ci为未知点i的土壤重金属预测浓度,则未知点的相似性误差ei为式(12)所示:
[0049]ei
=1-siꢀꢀ
(12)。
[0050]
本发明的有益效果在于:本发明引入对重金属浓度有灵敏响应的sif作为环境协同变量,可以极大提高重金属浓度的预测精度,且能够克服普通插值方法对整体样本平均代表性的依赖,有效利用个体样本点代表性从而克服对样本数量充足、分布均匀的限制,对区域内少量样本、不均匀分布也可以实现高精度空间预测。
附图说明
[0051]
图1为本发明的流程图。
[0052]
图2为日光诱导叶绿素荧光反演原理图。
[0053]
图3为实验区土壤重金属采样点分布图。
[0054]
图4为基于相似性方法对土壤重金属镉、铅预测浓度与误差空间分布图。
具体实施方式
[0055]
下面结合附图和实施例对本发明作进一步的说明。
[0056]
如图1所示,一种高精度土壤重金属浓度空间预测方法,包括以下步骤:
[0057]
步骤一,数据获取:包括区域内野外采样、多光谱高光谱遥感影像准备及地理环境变量的获取。
[0058]
步骤二,数据预处理:对野外采样样品的实验室化验及常规统计分析,检测出重金属异常点位;对影像的辐射校正、大气校正与波段选择得到校正后影像待用;地理环境变量通过数据转换与数据变换使得各种变量统一坐标、统一空间分辨率与统一数据类型。
[0059]
步骤三,数据反演与分析:计算得到各类植被指数和日光诱导叶绿素荧光强度,结合各种地理变量与样本分析点位数据进行地理探测,以决定参与预测的环境地理协同变量。
[0060]
采用夫琅和费暗线法反演获取日光诱导叶绿素荧光强度;
[0061]
基于夫琅和费暗线的sif反演算法fld:由于太阳大气中某些元素的吸收,太阳辐射在到达地表后其辐照度光谱形成许多波段宽度为0.1-10nm的细小暗线,即夫琅和费吸收暗线,在夫琅和费吸收暗线处,植被的反射光较弱,荧光效果明显,因此利用夫琅和费暗线反演日光诱导叶绿素荧光值sif;
[0062]
假定地球表面为各向同性表面反射,忽略冠层传感器间的大气效应和邻近效应的影响,认为传感器接收到的地表视反射辐亮度是地表植被太阳反射辐亮度与日光诱导叶绿素荧光反射的两部分之和,如式(1):
[0063][0064]
其中,λ为波长,l(λ)为传感器观测到的地表视反射辐亮度,r(λ)为地表反射率,e(λ)为地表入射辐照度,sif(λ)为植被发射的叶绿素荧光强度。
[0065]
根据夫琅和费吸收暗线区间的太阳辐照度光谱和传感器观测到的辐亮度光谱,可得出各参数满足式(2):
[0066][0067]
其中,l
in
为波长λ
in
处的辐亮度,l
out
为波长λ
out
处的辐亮度,i
in
为波长λ
in
处的太阳辐照度,i
out
为波长λ
out
处的太阳辐照度,f
in
为波长λ
in
处的日光诱导叶绿素荧光强度,f
out
为波长λ
out
处的日光诱导叶绿素荧光强度,r
in
为波长为λ
in
处的地表反射率,r
out
为波长λ
out
处的地表反射率。
[0068]
标准fld算法假设夫琅和费吸收暗线及其相邻谱区的植被反射率和荧光强度在本发明中很窄的波段范围内均不随波长变化,即:
[0069]rin
=r
out
=r
fld f
in
=f
out
=f
fld
ꢀꢀ
(3)
[0070]
其中,r
fld
为利用fld算法计算的地表反射率;f
fld
为利用fld算法计算的日光诱导叶绿素荧光强度。
[0071]
联合式(2)和(3),可得:
[0072][0073]
针对gf-5高光谱影像选择对应的夫琅和费吸收暗线波段和其邻近波段。
[0074]
步骤四,重金属浓度预测:由得到的环境地理协同变量,进行地理相似性计算,结合已知采样点的重金属浓度值,实现对未知点重金属浓度预测,得到预测的重金属浓度空间分布。
[0075]
步骤四的核心在于每个单独土壤样本点所反映的土壤属性值与其所在环境之间的关系,每个单独的样本点作为具有相似环境条件的位置的替代物,并以此去预测与样本点环境相似性达到要求的那些位置的土壤属性值,该方法简写为ipsm法;具体归纳为三个过程:
[0076]
(1)描述各点的环境特征;用多个环境协变量高程、坡度、坡向、归一化水分指数ndwi
1240
、归一化色素叶绿素指数npci、修正的简单比率植被指数msri-2、日光诱导叶绿素荧光sif和归一化红边植被指数ndvi
705
描述与目标土壤特性相关的环境特征,并形成一个该位置的环境向量e:
[0077]
e=(e1,e2,e3,...,em)
ꢀꢀ
(5)
[0078]
其中,e1,e2,......,em分别指考虑的第1个、第2个,
……
,第m个环境协变量,由这m个环境协变量共同形成一个m维的环境向量e。
[0079]
(2)每个未知点和每个土壤样本点的环境相似性评估;
[0080]
计算未知点与样本点之间的环境相似性:
[0081]si,j
=p(e(e
1i
,e
1j
),e(e
2i
,e
2j
),...,e(e
vi
,e
vj
),...,e(e
mi
,e
mj
))
ꢀꢀ
(6)
[0082]
其中,s
i,j
表示研究区未知点i与样本点j之间的环境相似性,e
vi
和e
vj
分别表示第i个未知点与第j个样本点处第v个环境协变量的属性,e
mi
和e
mj
分别表示第i个未知点与第j个样本点处第m个环境协变量的属性,e(
·
)和p(
·
)分别是环境协变量尺度和土壤样本尺度下的函数;函数e(
·
)用于计算环境协变量尺度下的环境相似性;对于给定的m个环境协变量,有从第1个环境协变量至第m个环境协变量的环境相似性,分别表示为e(e
1i
,e
1j
)、e(e
2i
,e
2j
)、......、e(e
mi
,e
mj
),e(
·
)描述了当未知点的环境协变量值偏离样本点的环境协变量值时,未知点和样本点之间的环境相似性会如何变化;基于此,定义e(
·
):
[0083][0084]
其中,是研究区内第v个环境协变量的标准偏差,是未知点i与样本点j处第v个环境协变量的平均偏差的平方根;
[0085][0086]
式(8)中,k为未知点个数;
[0087]
函数p(
·
)用于整合环境协变量尺度与土壤样本尺度的环境相似性,使用最小算子法即将所有环境协变量相似性中的最小值作为土壤样本水平的环境相似性;
[0088]
将每个未知点与所有土壤样本点的环境相似性组织成每个未知点的环境相似性向量si:
[0089]
si=(s
i,1
,s
i,2
,...,s
i,j
)
ꢀꢀ
(9)
[0090]
(3)各未知点的预测不确定性的量化及目标土壤属性值的估算;
[0091]
若未知点与所用样本点之间的环境相似性达不到要求,则现有的样本点就不可用于表示未知点,故需要计算预测不确定性用于评估使用现有样本点对未知点进行估算的可靠性,不确定性与环境相似性呈反比;不确定性计算方法如式(10)所示:
[0092]
uncertaintyi=1-max(s
i,1
,s
i,2
,...,s
i,n
)
ꢀꢀ
(10)
[0093]
其中,uncertaintyi为未知点i的不确定性,n为用于估算目标土壤属性值的未知点的个数,max(s
i,1
,s
i,2
,...,s
i,n
)表示取相似性s
i,1
、s
i,2
、......、s
i,n
的最大值。
[0094]
设置用户定义的不确定性阈值;某一未知点的不确定性若大于自定义的不确定性阈值,则将该未知点设置为无效值;若未知点不确定性小于或等于自定义的不确定性阈值,则使用加权平均值法参与估算未知点目标属性值,如式(11)所示:
[0095][0096]
其中,ci为未知点i的土壤重金属预测浓度,n
′
为所选样本点的个数,其与未知点i的环境相似性大于“1-不确定性阈值”,一般可以设置不确定性阈值为1%~30%,本研究选择30%作为不确定性阈值;cj为样本点j的土壤重金属浓度。
[0097]
步骤五,精度估算:计算预测的重金属浓度空间分布的精度。
[0098]
假定样本点j的重金属浓度为cj,样本点j的地理相似性为sj,未知点i的地理相似性为si,ci为未知点i的土壤重金属预测浓度,则未知点的相似性误差ei为式(12)所示:
[0099]ei
=1-siꢀꢀ
(12)。
[0100]
实施例
[0101]
数字高程数据(dem)采用的是美国国家航空和航天局(nasa)发布的30米分辨率数据;影像数据采用的是我国国家高分五号(gf-5)高光谱影像,获取时间为2019年12月22日,具体影像幅为:gf5_ahsi_e111.64_n29.83_20191222_008627_l10000068607。
[0102]
基于以上两类数据,在arcgis10.8软件平台下提取8个环境因子:高程、坡度、坡向、归一化水分指数(ndwi1240)、归一化色素叶绿素指数(npci)、修正的简单比率植被指数msri-2、日光诱导叶绿素荧光(sif)、归一化红边植被指数(ndvi705),基于gf-5影像数据提取的各指标中r
λ
所示在波长λ处的光谱反射率。对所提取的环境因子进行共线性检验,如果两个环境因子间的方差扩展因子(vif)小于10,说明这两个环境因子之间的共线性较弱,可被视为最佳因子。表1列出用于构建预测重金属镉、铅浓度模型的变量及其部分变量计算公
式。
[0103]
表1地理协同变量共线性检验
[0104][0105]
说明:vif值小于10的环境协同变量可用于重金属浓度的空间预测。
[0106]
对通过共线性检测的环境协变量分两组:
[0107]
(1)第一组环境协变量包括:高程、坡度、坡向、ndwi、msri-2;
[0108]
(2)第二组环境协变量包括:高程、坡度、坡向、ndwi、msri-2、sif。
[0109]
以上两组变量的区别只在于是否考虑日光诱导叶绿素荧光参数用于预测土壤重金属浓度,以验证sif对提升土壤重金属预测浓度的效果。
[0110]
分别构建镉、铅浓度ipsm模型对整个区域重金属镉、铅浓度进行空间预测。
[0111]
从14个样本点中随机抽取任意3个样本点作为验证样本集,余下的11个样本点用于空间预测。为了提高验证模型精度的准确性,对14个样本点进行3次随机选择得到三组不同数据,再利用选出的三组不同数据进行空间预测及模型验证。
[0112]
表2中的cd(变量组1),cd(变量组2),pb(变量组1),pb(变量组2)分别表示以下含义:
[0113]
(1)cd(变量组1):由第一组环境协变量作为因子构建的镉浓度预测模型;
[0114]
(2)cd(变量组2):由第二组环境协变量作为因子构建的镉浓度预测模型;
[0115]
(3)pb(变量组1):由第一组环境协变量作为因子构建的铅浓度预测模型;
[0116]
(4)pb(变量组2):由第二组环境协变量作为因子构建的铅浓度预测模型;
[0117]
模型参数如下表所示:
[0118]
对比cd(变量组1)和cd(变量组2)的决定系数(r2)和均方根误差(rmse)可知,加入sif环境因子作为环境协变量构建的镉浓度预测模型cd(变量组2)的精度与稳定性优于cd(变量组1)模型;同样,对比pb(变量组1)和pb(变量组2)的决定系数(r2)和均方根误差(rmse),含有sif环境变量的pb(变量组2)模型的精度与稳定性优于不包含sif环境变量的pb(变量组1)模型。不过,加入sif环境因子的因子组合对与镉浓度ipsm模型的精度和稳定性改善效果比较明显,而对于铅浓度ipsm模型稳定性的改善并不是十分明显。
[0119]
此外,没有sif环境因子作为环境协变量构建的镉浓度ipsm模型稳定性虽优于铅浓度ipsm模型,但其精度并不如铅浓度ipsm模型,而加入sif环境因子作为环境协变量的镉浓度ipsm模型精度和稳定性都明显优于铅浓度ipsm模型,具体结果如表2所示。
[0120]
表2基于不同地理协变量组合预测镉、铅浓度效果评价表
[0121][0122]
说明:组合1包含的地理协变量为:高程、坡度、坡向、归一化水分指数、比值植被指数;组合2包含的地理协变量为:高程、坡度、坡向、归一化水分指数、比值植被指数、叶绿素荧光强度。第一组、第二组、第三组表示对研究区域内采样点按预测点、验证点随机分成三组进行预测与检验所得评价指标。
[0123]
模型参数是评估模型准确性的一种指标,同时还可以通过有效预测范围对不同因子组合构建的ipsm模型预测结果的准确性进行分析。ipsm模型主要通过评估研究区内未知点与样本点的环境相似性判断是否可以利用样本点数据对未知点进行预测,其中用户自定义的不确定性阈值是衡量未知点与样本点之间的环境相似性是否达到要求的指标。本次研究,将不确定性阈值设置为0.4,当未知点的不确定性小于0.4时才能通过样本点对其进行预测,研究区内像元数共计93570个,如表3所示,采用第一组环境因子组合即没有加入sif因子所建立的预测模型对整个区域预测的范围达到46.73%,而加入sif环境因子作为环境变量的第二种因子组合构建的预测模型对整个区域预测的范围下降到29.82%。范围的缩小,并不意味着模型精度、准确性降低,而是没有加入sif作为环境协变量构建的模型,在整个研究区有大约46.73%的区域与样本点的预测不确定性小于0.4,而加入了sif环境协变量后,整个区域中与样本点的预测不确定性低于0.4的区域只有29.82%,余下的区域由于预测不确定性过高,不适合通过样本数据对其进行空间预测。这表明,加入日光诱导叶绿素荧光(sif)环境协变量使得未知点与样本点之间的环境相似性的评估更加严格、准确,同时印证了加入日光诱导叶绿素荧光环境协变量构建的ipsm模型的预测结果将更加合理、可靠。
[0124]
表3基于不同地理协变量组合预测重金属浓度空间范围对比
[0125][0126]
说明:说明:组合1包含的地理协变量为:高程、坡度、坡向、归一化水分指数、比值植被指数;组合2包含的地理协变量为:高程、坡度、坡向、归一化水分指数、比值植被指数、叶绿素荧光强度。第一组、第二组、第三组表示对研究区域内采样点按预测点、验证点随机分成三组进行预测与检验所得评价指标。
[0127]
研究区坐落在湖南省常德市津市以北,交通发达。属于中亚热带湿润季风气候,冬冷夏热;具有夏季闷热,冬季湿冷,季风发达等气候特点。研究区由澧水分为南北两部分,地势由南向北倾斜,澧水以北为长江中下游平原边地——澧阳平原,地势平坦,河湖纵横。从全球30米地表覆盖数据产品中得知,研究区主要由耕地和人造地表组成,耕地贯穿整个研究区,占比约为68.5%,人造地表依澧水而建,占比约为22%。丰富的土地资源为农业发展提供了有利条件,津市粮食、棉花、油料等农副产品资源丰富,发展了优质稻、棉花、油类、渔业等多个生产地,于2020年被定为湖南省综合油料大县。经筛选后,如图3所示,用于估算研究区重金属浓度的样本数为14个,分布于澧水以南地区。
[0128]
样本点采集于该区的平原、耕地区,地势起伏较小,海拔在20-30米范围内。在对研究区进行了初步野外考察、现场实验、样品采样后,获取了14件表层土壤样品。研究区域内采用不规则随机采样,形成的空间数据中每个点包括地理信息、地质信息、以及土壤类型和人类活动干扰程度等基本信息;土壤样品的采集深度为0~30cm。通过酸消解,等离子质谱/光谱仪定量分析对土壤固体样中的重金属含量进行检测,检出限达到《gb15618-1995/2008土壤环境质量标准》检出要求,单位为μg/g。送检后得到14个样本点8种土壤重金属元素浓度数据,其空间分布图3所示。
[0129]
图4a)与b)表明,研究区内重金属镉、铅浓度整体较低,高浓度值主要出现在澧水以北的平原地区,澧水以南地区以低浓度为主,且镉、铅高浓度值出现的区域相对保持一致,一般重金属镉浓度高的地方,其铅浓度也较高。此外从预测结果看研究区内铅高浓度值相较于镉高浓度值出现更多,表明研究区内铅污染相对来说更严重。从图4c)中可以看出河流、湖泊及其他一部分地区不确定性非常高,说明这些地方与样本点的环境相似性非常低(符合实际情况,因为样本点均位于耕地区),因此ipsm模型并没有对这部分区域的重金属浓度进行空间预测。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1