沉积类型识别模型建立、沉积类型识别方法和相关装置与流程
本发明涉及地球物理,特别涉及沉积类型识别模型建立、沉积类型识别方法和相关装置。
背景技术:
1、沉积相、岩性分类是地球物理资料解释中的一个重要研究内容,对储层预测和生物礁发现提供技术支持,是后续精细资料解释的前提。例如可为后续反演工作提供相约束条件,进而提高反演精度,或用于井震标定以及层序格架建立,进而为地震低频预测提供支持。地球物理领域中,传统的沉积相、岩性分类方法多为利用地震数据的波形分析、地震属性计算、人工解释等手段,这些方法的局限性体现在以下方面:(1)处理解释环节多、流程复杂,每个环节产生的误差可能会逐级传递并累加,影响最终精度;(2)过于依赖数据质量以及解释人员的专业知识和对研究工区的主观判断;(3)面对大数据量的时效性较低;(4)知识累积、提升和迁移使用存在困难。
技术实现思路
1、发明人发现,近年来,随着算力的提升,相关算法研究兴起以及大量数据的积累,使得智能化方法在一些如分类、回归、降维、聚类等应用领域展现出了超越人类的效率和精度优势。以深度学习为例,其中包含了更多的非线性层,具有强大的特征提取能力和表达能力,学习率作为一个重要的超参数,通常由人为给定一个较小的常数或者衰减型数组用于优化损失函数。然而,深度学习中利用随机梯度下降的优化方法时,上述两种学习率的设置可能会使找到的局部极小值与真正的全局最小值差距较大,甚至可能陷入损失函数的鞍点而影响模型的预测精度。另外,为了保证模型训练的成功,通常给定的学习率较小,这会使训练效率尤其是在训练后期变低。而如果人为设定较大的学习率,虽有可能在初期提高学习效率,但可能造成损失函数不收敛进而训练失败。
2、同时,井数据具有纵向分辨率高,涵盖地下多种物性信息的特点。因此提出基于井数据利用深度学习智能化方法进行沉积相、岩性分类,以满足勘探目标愈发隐蔽而勘探精度要求日益提高的生产需求。
3、鉴于上述问题,提出了本发明以便提供一种克服上述问题或者至少部分地解决上述问题的沉积类型识别模型建立、沉积类型识别方法和相关装置,通过该方法建立的模型能够基于井数据快速合理的完成目的井沉积类型数据的预测;使用周期性衰减型学习率对损失函数进行优化,使得损失函数收敛的速度提升,且有较强的能力逃离鞍点以及局部最小值,进而提升预测精度。
4、第一方面,本发明实施例提供一种沉积类型识别模型建立方法,包括:
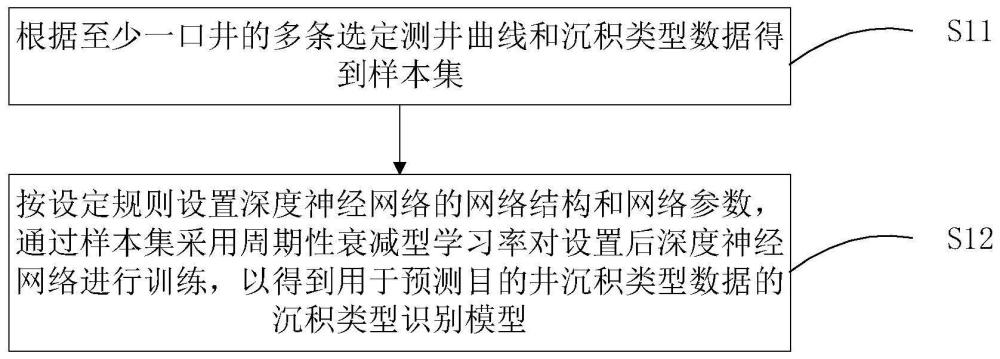
5、根据至少一口井的多条选定测井曲线和沉积类型数据得到样本集,所述样本集中的样本包括对应井一定深度范围内的各选定测井曲线的曲线段和沉积类型;
6、按设定规则设置深度神经网络的网络结构和网络参数,通过所述样本集采用周期性衰减型学习率对设置后深度神经网络进行训练,以得到用于预测目的井沉积类型数据的沉积类型识别模型。
7、第二方面,本发明实施例提供一种沉积类型识别方法,包括:
8、将目的井的各选定测井曲线输入按上述方法建立的沉积类型识别模型中,根据模型的输出结果预测所述目的井的沉积类型数据。
9、第三方面,本发明实施例提供一种沉积类型识别模型建立装置,包括:
10、样本集建立模块,用于根据至少一口井的多条选定测井曲线和沉积类型数据得到样本集,所述样本集中的样本包括对应井一定深度范围内的各选定测井曲线的曲线段和沉积类型;
11、沉积类型识别模型建立模块,用于按设定规则设置深度神经网络的网络结构和网络参数,通过所述样本集采用周期性衰减型学习率对设置后深度神经网络进行训练,以得到用于预测目的井沉积类型数据的沉积类型识别模型。
12、第四方面,本发明实施例提供一种计算机程序产品,包括计算机程序/指令,其中,该计算机程序/指令被处理器执行时实现上述沉积类型识别模型建立方法,或实现上述沉积类型识别方法。
13、第五方面,本公开实施例提供一种服务器,包括:存储器、处理器及存储于存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述沉积类型识别模型建立方法,或实现上述沉积类型识别方法。
14、本发明实施例提供的上述技术方案的有益效果至少包括:
15、本发明实施例提供的沉积类型识别模型建立方法,能够基于井数据快速合理的完成目的井沉积类型数据的预测;使用周期性衰减型学习率对损失函数进行优化,使得损失函数收敛的速度提升,且有较强的能力逃离鞍点以及局部最小值,进而提升预测效率和精度。
16、本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
17、下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
技术特征:
1.一种沉积类型识别模型建立方法,其特征在于,包括:
2.如权利要求1所述的方法,其特征在于,所述按设定规则设置深度神经网络的网络结构,具体包括:
3.如权利要求2所述的方法,其特征在于,所述按设定规则设置深度神经网络的网络结构,具体包括:
4.如权利要求1所述的方法,其特征在于,按设定规则设置深度神经网络的网络参数,具体包括:
5.如权利要求1所述的方法,其特征在于,所述通过所述样本集采用周期性衰减型学习率对设置后深度神经网络进行训练,以得到用于预测目的井沉积类型数据的沉积类型识别模型,具体包括:
6.如权利要求1所述的方法,其特征在于,所述根据至少一口井的多条选定测井曲线和沉积类型数据得到样本集后,还包括:
7.如权利要求1所述的方法,其特征在于,所述根据至少一口井的多条选定测井曲线和沉积类型数据得到样本集前,还包括:
8.如权利要求1~7中任一项所述的方法,其特征在于,所述选定测井曲线为归一化后的测井曲线。
9.如权利要求8所述的方法,其特征在于,所述选定测井曲线为均值归零处理后的测井曲线。
10.如权利要求1~7中任一项所述的方法,其特征在于,所述沉积类型为沉积相类型或岩性类型。
11.一种沉积类型识别方法,其特征在于,包括:
12.一种沉积类型识别模型建立装置,其特征在于,包括:
13.一种计算机程序产品,包括计算机程序/指令,其特征在于,该计算机程序/指令被处理器执行时实现权利要求1~10中任一项所述的沉积类型识别模型建立方法,或实现权利要求11所述的沉积类型识别方法。
技术总结
本发明公开了沉积类型识别模型建立、沉积类型识别方法和相关装置。其中,沉积类型识别模型建立方法包括,根据至少一口井的多条选定测井曲线和沉积类型数据得到样本集,样本集中的样本包括对应井一定深度范围内的各选定测井曲线的曲线段和沉积类型;按设定规则设置深度神经网络的网络结构和网络参数,通过样本集采用周期性衰减型学习率对设置后深度神经网络进行训练,以得到用于预测目的井沉积类型数据的沉积类型识别模型。通过该方法建立的模型能够基于井数据快速合理的完成目的井沉积类型数据的预测;使用周期性衰减型学习率对损失函数进行优化,使得损失函数收敛的速度提升,且有较强的能力逃离鞍点以及局部最小值,进而提升预测效率和精度。
技术研发人员:张鑫,杨昊,晏信飞,葛强,隋京坤
受保护的技术使用者:中国石油天然气集团有限公司
技术研发日:
技术公布日:2024/2/25
- 还没有人留言评论。精彩留言会获得点赞!