一种地铁列车智能组合测速方法
1.本发明涉及电子信息技术领域,具体是涉及一种地铁列车智能组合测速方法。
背景技术:
2.当前,地铁或轻轨信号系统的测速传感器,通常使用测速电机(opg)、里程计(odo)、霍尔式速度传感器、多普勒雷达和加速度计等,这些传感器各有优缺点,如何合理的利用上述多个传感器在时间和空间上的互补或冗余实测数据(信息)进行组合,实现对列车速度的安全可靠测量及实时精确估计,是目前地铁列控车载atp的一大难题,也是各大信号厂商的核心技术。
3.《基于多源信息融合的列车测速方法研究》一文中公开了一种基于opg、多普勒雷达、加速度计三个数据源的列车组合测速方案。如附图1所示,采用分散式卡尔曼融合结构,对各个传感器数据信息源先进行各自的滤波处理,分别获得状态估计值,以该状态估计值为主滤波器的输入值,在主滤波器内进行信息融合和最优估计,从而得到最终状态估计。其中,对于主滤波器进行全局的最优估计,对三个传感器的工作状态和信息分配系数需要进行分配。但该文献中3个传感器的工作状态和信息分配系数(权重分配系数)全部采用的是假设值(经验值),主观性很强,不大适合于列车牵引、惰行、制动等复杂运行工况(包括频繁起动、加减速、恒速(或惰行)和制动)。
技术实现要素:
4.发明目的:针对以上技术问题,本发明提供一种地铁列车智能组合测速方法,运用蚁群算法自适应地调整分散式卡尔曼滤波权重的分配系数,从而达到进一步提高列车速度最优估计的精确性与可靠性的目标。
5.技术方案:为解决上述问题,本发明公开一种地铁列车智能组合测速方法,具体包括以下步骤:
6.(1)分别采用opg、雷达、加速度计测量获取n天各时刻列车速度数据,将获取的数据按比例划分为训练集与测试集;
7.(2)分别针对opg、雷达、加速度计获取的速度数据构建对应速度预测估计模型,三种速度预测估计模型输出的预测值分别记为第一速度估计值、第二速度估计值、第三速度估计值;将训练集的数据对应输入三种速度预测估计模型获得各时刻下第一速度估计值、第二速度估计值、第三速度估计值;
8.(3)构建组合测速模型;将步骤(2)获取每时刻的第一速度估计值、第二速度估计值、第三速度估计值作为一组速度估计值组合输入组合测速模型中,通过蚁群算法对于每一组速度估计值组合下的组合预测模型的权重系数进行迭代寻优,当达到最大迭代次数时获得该组速度估计值组合下对应最优的权重系数,完成训练;所述组合测速模型公式为:
[0009][0010]
式中,为k时刻组合测速模型输出的预测估计值;为k时刻第一速度估计值;
为k时刻第二速度估计值;为第三速度估计值;kf1为第一速度估计值对应权重;kf2为第二速度估计值对应权重;kf3为第三速度估计值对应权重;
[0011]
(4)将测试集的数据对应输入三种速度预测估计模型获取各时刻对应速度估计值组合,再将该速度估计值组合输入训练好的组合测速模型中获得各时刻速度预测估计值。
[0012]
进一步的,步骤(3)中利用蚁群算法对每一组速度估计值组合下组合预测模型中权重系数进行寻优具体包括以下步骤:
[0013]
(3.1)初始化数据;权重系数的取值范围为[0,1]且权重取值区间平均分为100份,则组合预测模型中每个速度估计值对应的每个权重区间表示为[x
i,j
,x
i,j+1
],i=1,2,3,j=1,2,
…
,100;初始化各取值区间的信息素浓度;
[0014]
(3.2)初始化参数并设定最大的迭代次数;初始化参数包括信息启发因子α、期望启发因子β、蚁群数量m、信息挥发因子ρ;
[0015]
(3.3)蚁群遍历搜索三个速度估计值对应的各权重区间,自每个速度估计值对应的各权重区间中确定选择的权重区间;其中单只蚂蚁搜索具体步骤为:
[0016]
(3.3.1)通过伪随机数生成器确定蚂蚁的初始位置,并设置禁忌表,使得蚂蚁搜索每个权重区间有且仅有一次;
[0017]
(3.3.2)计算蚂蚁选择组合预测模型中一个速度估计值对应的各权重区间转移概率,公式为:
[0018][0019]
式中,为第k只蚂蚁转移到权重区间j的概率;τj为权重区间j的信息素强度;nj为权重区间j的信息期望启发参数;jk为第k只蚂蚁下一步可选择的权重区间的集合;
[0020]
(3.3.3)基于转移概率采用俄罗斯轮盘赌的方式确定蚂蚁在该速度估计值对应的各权重区间中选择的权重区间;
[0021]
(3.3.4)蚂蚁遍历剩余两个速度估计值对应的各权重区间,重复步骤(3.3.2)至步骤(3.3.3),分别确定在剩余两个速度估计值对应的各权重区间中选择的权重区间;
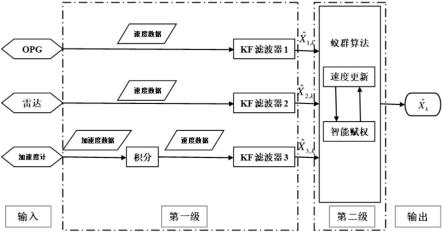
[0022]
(3.4)更新信息素;蚁群中所有蚂蚁完成一次搜索后,计算各蚂蚁选择的权重区间下的组合预测模型综合评价指标,选取综合评价指标最大对应蚂蚁为最优蚂蚁,最优蚂蚁选择的权重区间为最优权重区间;对最优蚂蚁选择的权重区间的信息素浓度更新,更新公式:
[0023]
τi=(1-ρ)τ
i-1
+l
[0024]
式中,l为蚂蚁选择的权重区间下的组合测速模型精度指标值;
[0025]
对未选择的权重区间的信息素更新,更新公式:
[0026]
τi=(1-ρ)τ
i-1
[0027]
(3.5)判断当前迭代次数是否达到最大迭代次数,若达到,则输出最优权重区间;否则,返回至步骤(3.3)继续循环直至达到最大迭代次数。
[0028]
进一步的,步骤(2)中构建对应速度预测估计模型获取速度估计值具体为:
[0029]
构建三种预测估计模型;第一种速度预测估计模型为采用第一卡尔曼滤波器对于
opg获得列车速度数据进行速度预测,获取第一速度估计值;第二种速度预测估计模型为采用第二卡尔曼滤波器对于雷达获得列车速度数据进行速度预测,获取第二速度估计值;第三种速度预测估计模型为采用第三卡尔曼滤波器对于加速度计获得列车速度数据进行速度预测,获取第三速度估计值。
[0030]
进一步的,步骤(3.4)中l选用均方根误差(rmse)指标,即:
[0031][0032]
式中,x(t)为第t时刻的组合测速模型速度估计值;为第t时刻的实际速度值,n为正数,速度序列的个数。
[0033]
此外,本发明还提供一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述任一所述方法的步骤。一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述任一所述方法的步骤。
[0034]
有益效果:本发明提供一种地铁列车智能组合测速方法相对于现有技术,其显著优点是:将卡尔曼滤波和蚁群算法的优势有机结合,以三个不同车速传感器卡尔曼滤波输出的速度最优估计值作为蚁群算法的输入,通过蚁群算法对三个传感器的速度最优估计值的权重系数进行自适应调整,进而获得更为精准的列车速度值估计。具体的,通过采用两级结构、分散化滤波智能优化算法,设计三个标准卡尔曼滤波器构成第一级,分别对opg、雷达、加速度获得的测量值进行卡尔曼滤波获得三个独立的速度估计值;再采用蚁群智能优化器构成第二级,优化器通过对分配滤波器输出结果的权重寻优,实现滤波器测速结果的更优估计,进而得到列车各时刻的速度最优估计值。
附图说明
[0035]
图1所示为现有技术中列车组合测速方法的流程图;
[0036]
图2所示为本发明所述方法的流程图;
[0037]
图3所示为本发明所述方法中卡尔曼滤波示意图;
[0038]
图4所示为本发明所述方法中蚁群算法寻优的示意图。
具体实施方式
[0039]
下面结合附图对本发明的技术方案进一步说明。
[0040]
如图2所示,本发明提供的一种地铁列车智能组合测速方法,具体包括以下步骤:
[0041]
步骤一、分别采用opg、雷达、加速度计测量获取若干列车速度数据,将获得数据分为训练集和测试集。具体的,选取某一周7天的各个时刻(间隔为1秒钟的时间序列)速度数据为训练集,选取第8天的各时刻速度数据作为测试集进行组合测速实测效果验证。
[0042]
步骤二、构建三种速度预测估计模型;具体的:
[0043]
第一种速度预测估计模型为采用第一卡尔曼滤波器对于opg获得列车速度数据进行速度预测,获取第一速度估计值;第二种速度预测估计模型为采用第二卡尔曼滤波器对
于雷达获得列车速度数据进行速度预测,获取第二速度估计值;第三种速度预测估计模型为采用第三卡尔曼滤波器对于加速度计获得列车速度数据进行速度预测,获取第三速度估计值;
[0044]
其中,每种速度预测估计模型中卡尔曼滤波器均采用标准卡尔曼滤波器。利用卡尔曼滤波器获得预测估计值具体为:卡尔曼滤波器的输入为opg或雷达或加速度计获得的速度值,采用卡尔曼滤波算法对于输入值进行滤波处理得到输出的状态估计值,即预测的速度值。具体卡尔曼滤波算法步骤如图3所示:
[0045]
针对k时刻被估计状态量xk(速度估计值)受到系统过程激励噪声影响,随机线性离散系统状态方程设为:
[0046]
xk=a
k,k-1
x
k-1
+b
k,k-1wk-1
[0047]
xk满足线性关系,观测方程为:zk=hkxk+ek[0048]
式中,a
k,k-1
为n*n维状态转移矩阵;b
k,k-1
系统噪声矩阵;w
k-1
为系统过程激励噪声;hk为m*n维测量转换矩阵;ek为测量噪声;
[0049]
(1)系统状态预测,公式为:
[0050][0051]
式中,为xk下一步预测值;为系统状态的估计值;
[0052]
(2)系统状态估计,公式为:
[0053][0054]
式中,zk为k时刻系统状态观测值,m维观测向量;k为滤波增益;
[0055]
(3)预测误差方差矩阵,公式为:
[0056]
p
k,k-1
=a
k,k-1
p
k-1ak,k-1t
+b
k,k-1qk-1bk,k-1t
[0057]
式中,q
k-1
为系统噪声的p*p维对称非负定方差阵;
[0058]
(4)滤波增益的计算,公式为:
[0059]
k=p
k,k-1hkt
[hkp
k,k-1hkt
+rk]-1
[0060]
式中,pk为观测噪声的m*m维对称正定方差阵;
[0061]
(5)估计误差方差矩阵,公式为:
[0062]
pk=[1-khk]p
k,k-1
[0063]
卡尔曼滤波每个递推周期都是由时间更新和测量更新组成的,在循环中完成数据滤波及参数更新。时间更新根据上一时刻的更新值和协方差矩阵计算当前时刻的状态预测值及协方差矩阵。状态转移矩阵a
k,k-1
和前一时刻的状态值x
k-1
可以预测估计出k时刻的被估计量xk,一步预测出均方差p
k,k-1
,实现从k-1时刻到k时刻的时间转换,测量更新阶段根据测量值和预测值来估计真实值,并更新协方差矩阵p
k,k-1
和卡尔曼增益k,利用k时刻的测量值zk及前一阶段的被估计量及残差,可以进一步优化被估计量xk减小误差。
[0064]
将训练集的数据对应的输入三种速度预测估计模型获取对应天数中每时刻的第一速度估计值、第二速度估计值、第三速度估计值。
[0065]
步骤三、根据三种速度预测估计模型获取的速度估计值建立组合测速模型,所述组合测速模型公式为:
[0066][0067]
式中,为k时刻组合测速模型输出的预测估计值;为k时刻第一速度估计值;为k时刻第二速度估计值;为第三速度估计值;kf1为第一速度估计值对应权重;kf2为第二速度估计值对应权重;kf3为第三速度估计值对应权重。
[0068]
将步骤二获取每时刻的第一速度估计值、第二速度估计值、第三速度估计值作为一组速度估计值组合输入组合测速模型中进行训练,采用蚁群算法对于每一组速度估计值组合下的组合预测模型的权重系数进行迭代寻优,当达到最大迭代次数时获得该组速度估计值组合下对应最优的权重系数;训练完成后获得不同组速度估计值组合对应的最优权重系数。
[0069]
具体的,如图4所示,采用蚁群算法对于组合预测模型中权重系数进行迭代寻优过程:
[0070]
(1)初始化数据;权重系数的取值范围为[0,1]且权重取值区间平均分为100份。按照三个kf滤波器的输出结果,对应有3个不同权重的kf1、kf2、kf3参与到组合测速中。即将3个测速估计值输进组合测速模型中,组合预测模型中每个kf测速权重取值区间表示为[x
i,j
,x
i,j+1
],i=1,2,3,j=1,2,
…
,100;初始化各取值区间的信息素浓度,均取为1;
[0071]
(2)初始化参数并设定最大的迭代次数;其中,参数包括信息启发因子α、期望启发因子β、蚁群数量m、信息挥发因子ρ;具体各项参数的定义和取值详见下表1:
[0072]
表1
[0073]
[0074][0075]
(3)蚁群依次搜索三个测速估计值对应各权重区间,其中单只蚂蚁搜索具体步骤为:
[0076]
(3.1)通过伪随机数生成器确定蚂蚁的初始位置,并设置禁忌表,使得蚂蚁搜索每个kf权重区间有且仅有一次。
[0077]
(3.2)计算转移概率;
[0078]
计算蚂蚁选择组合预测模型中第一测速估计值对应各权重区间转移概率,公式为:
[0079][0080]
式中,为第k蚂蚁转移到权重区间j的概率;τj为权重区间j的信息素数量;nj为权重区间j的信息期望启发参数;jk为第k蚂蚁下一步可选择的权重区间的集合。
[0081]
(3.3)通过俄罗斯轮盘赌的方式确定蚂蚁k在该第一测速估计值对应的各权重区间中选择的权重区间;具体的:
[0082]
将该第一测速估计值对应各权重区间转移概率pj(j=1,2,
…
,100)求和得到总概率p;其中,三个测速估计值对应各权重区间转移概率之和为1。再在概率[0,p]之间生成一个随机概率,再依次循环遍历所有权重区间,将随机概率与每个权重区间的积累概率依次相减,当出现概率小于0的权重区间即为蚂蚁最终选择的权重区间。
[0083]
(3.4)蚂蚁k遍历剩余两个测速估计值对应各权重区间,按照上述步骤(3.2)至步骤(3.3)相同方法分别确定在剩余测速估计值对应各权重区间中选择的权重区间。
[0084]
(4)更新信息素;
[0085]
每次迭代需要对各权重区间的信息素浓度更新,选取基于全局信息更新的蚁周模型对各权重区间信息素计算并更新。即蚁群所有蚂蚁完成一次搜索后,计算各蚂蚁选择的权重区间下的组合预测模型综合评价指标,综合评价指标最大的对应蚂蚁为最优蚂蚁,最优蚂蚁选择的权重区间为最优权重区间,对其选择的权重区间的信息素更新公式:
[0086]
τi=(1-ρ)τ
i-1
+l
[0087]
式中,l为蚂蚁选择的权重区间下的组合测速模型精度指标值;
[0088]
对于未选择的权重区间的信息素更新公式:
[0089]
τi=(1-ρ)τ
i-1
[0090]
其中,l选用均方根误差(rmse)指标,即:
[0091][0092]
式中,x(t)为第t时刻的组合测速模型速度估计值;为第t时刻的实际速度值,n为正数,速度序列的个数。
[0093]
(5)判断当前迭代次数n是否达到最大迭代次数n
max
,若达到,则输出当前最优权重区间;否则,返回至步骤(3)继续循环直至达到最大迭代次数。
[0094]
步骤四、将测试集的数据输入训练好的组合测速模型中获得最终的组合速度预测值。
[0095]
具体的,根据训练集中一周7天的各个时刻速度数据,得出组合测速模型的3个传感器对应的kf输出速度估值的最优权重区间,将第8天的各时刻测量的速度数据输入训练好组合测速模型中获得最终预测值。
[0096]
由于训练集数据采集的为7天且间隔为1秒的各时刻的速度数据,按每天18小时计算,将有7*18*3600个速度值序列样本,训练集中样本数量达45万个。45万样本数据训练获得的组合测速模型足以完全覆盖车速范围0-80km/h(对应0-22.22m/s)内速度,速度增加步长为0.1m/s。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1