一种基于PhaseUnet++网络的高精度相位解调方法
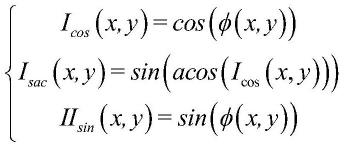
一种基于phaseunet++网络的高精度相位解调方法
技术领域
1.本发明涉及光学干涉测量的技术领域,主要针对光学相位测量技术领域,具体涉及一种基于phaseunet++网络的高精度相位解调方法。
背景技术:
2.在光学球面、非球面的干涉测量中,测试光束被待测表面反射,与参考光束发生干涉,在探测器上形成干涉图。为了获得被测对象的表面形貌,需要对干涉图进行相位解调。干涉图的解调是光学干涉测量中的一个关键问题,其精度直接决定干涉装置最终的测量精度。
3.传统的相位解调方法通常包含两个主要步骤:1.从干涉图得到包裹相位分布;2.采用相位解包裹算法对包裹相位分布去包裹得到无包裹相位分布。对于包含闭合条纹的干涉图,为了得到包裹相位分布,通常需要记录n(n》=2)幅相移干涉图。例如,采用时间相移干涉技术的四步相移算法或采用空间平行相移技术的四步相移算法。在时间相移干涉技术中,要求样品静止不动,需要记录随时间变化的多幅相移干涉图,因此不能用于动态变化样品的测量(daniel malacara,optical shop testing,2007,john wiley&sons,inc.)。在空间平行相移干涉技术中,需要对ccd/cmos感光芯片空间复用,面临空间分辨率降低或者视场减小的问题(li.j,et.al.optics express,26(4),2018:4392-4400.doi:10.1364/oe.26.004392)。
4.从一幅含有闭合条纹的干涉图中,解调得到包裹/无包裹相位分布,不仅可充分利用ccd/cmos的空间带宽积(从而有空间分辨率高的优点),而且可以实现对动态变化样品的实时测量。
5.基于深度学习的数据处理方法具有强大的数据拟和能力,因此在干涉图处理等方面获得了越来越多的关注。目前,针对单幅含有闭合条纹干涉图的解调,基于深度学习已经提出了两种代表性方法:
6.1.基于unet网络的闭合干涉图相位解调方法(yuan.s,et.al.optics express,29(2),2021:2538-2554,doi:10.1364/oe.413385)。该技术基于传统的unet网络,网络主体为四层u形网络结构,每层的处理通过denseblock实现。该神经网络可以从单幅干涉图中得到包裹相位分布,然后采用相位解包裹算法得到无包裹相位分布。网络的输入和输出分别是归一化的干涉图和归一化的包裹相位。但是该方法存在如下缺点:1).只能输入分辨率为256
×
256的固定大小的的干涉图。2).对条纹稀疏的干涉图存在较大的解调误差(大于1.0rad)。
7.2.基于超列卷积神经网络的解调方法(hcnn)(zhao.zh,et.al.optics express,29(11),2021:16406-16421,doi:10.1364/oe.410723)。该技术基于超列卷积神经网络(hcnn)。利用训练好的神经网络,可以从单幅干涉图中直接输出无包裹相位分布。但是该方法存在如下缺点:网络直接输出的无包裹相位分布中存在明显的突变状相位误差(》1rad)。为了得到正确的相位分布,需要对网络直接输出的相位分布进行复杂的误差校正。具体流
程包括误差区域的确定和对误差区域的相位分布进行多项式拟合,然后才能得到最终的无包裹相位分布。
8.综上所述,随着科学技术的进一步发展,优化单幅含有闭合条纹干涉图的解调的方法,成为本领域技术人员的研究重点。
技术实现要素:
9.本发明的目的是提供一种基于phaseunet++网络的高精度相位解调方法,以解决现有技术存在的对条纹稀疏的闭合条纹干涉图存在较大的解调误差、输入干涉图分辨率固定和适用范围小的缺点。
10.为了达到本发明的目的,本发明提出的技术方案是:一种基于phaseunet++网络的高精度相位解调方法,其包括以下步骤:
11.步骤一:首先使用泽尼克(zernike)多项式产生无包裹相位分布φ,然后生成对应的训练数据对,最后生成对应的训练数据,测试数据以及验证数据;
12.步骤二:卷积神经网络的构建和训练:
13.(2.1)设计phaseunet++神经网络,包括:残差连接块resblock、卷积层conv2d、归一化层batchnorm2d、激活层relu、池化层maxpool2d、反卷积层convtranspose2d、连接层concat、dropout层和clamp层;
14.(2.2)使用数据集(i
cos
、i
sac
和ii
sin
)对phaseunet++神经网络进行训练,直到损失函数不再下降并保持稳定后训练完成,得到网络各层的权重值。
15.步骤三:把实际测量得到的余弦干涉图归一化得到i
cos
,把i
cos
和辅助图i
sac
输入训练好的神经网络phaseunet++,输出归一化的正弦干涉图i
sin
。
16.步骤四:通过反正切公式计算得到包裹相位分布随后,利用传统的解包裹技术进行相位解包裹,最终得到无包裹相位分布φ(x,y)。
17.进一步的,上述步骤(2.1)中,每一个resblock卷积块x
i.j
(i,j=0,1,2,
…
)都是将输入进行卷积,然后通过归一化层batchnorm2d和激活层relu,再经过卷积,通过归一化层batchnorm2d,和输入通过concat层相加,最终通过激活层relu后输出。
18.进一步的,上述步骤(2.1)中,输入的i
cos
和i
sac
图分别通过一个resblock块得到x
cos
和x
sac
,然后通过concat层得到x
0.0
;将x
0.0
作为网络的输入,x
0.0
通过maxpool2d层得到x
1.0
,x
1.0
通过convtranspose2d层上采样后和x
0.0
通过concat层按通道(channel)维度进行拼接得到x
0.1
,其他层的结构依次类推。
19.进一步的,上述网络中,每一层的resblock卷积块的输入都由相同层中的所有前置resblock卷积块的输出和左下角resblock卷积块的输出通过concat层按通道(channel)维度进行拼接得到。
20.与现有技术相比,本发明的有益效果为:
21.1、本发明通过余弦干涉图i
cos
和辅助图i
sac
作为输入,通过训练神经网络获取正弦干涉图i
sin
,然后计算得到包裹相位分布,最终进行相位解包裹得到无包裹相位分布。通过建立神经网络,解决闭合条纹干涉图相位解调的问题,所述测量过程利用一幅归一化的干涉图,可以实现动态样品的相位测量,并且重建结果精度高、步骤简单。
22.2、本发明与采用单幅图i
cos
作为输入的网络相比,该网络可以获得更高的重建精
度。
23.3、本发明适用于不同分辨率大小的干涉图,对于密集或稀疏的干涉图同样适用。训练好的网络可以输入不同大小的干涉图进行相位解调,干涉图的大小不被限制在固定尺寸,例如256
×
256、512
×
512、832
×
832均可以,适用范围广,在光学干涉测量研究领域有着很大的应用前景。
附图说明:
24.图1为本发明神经网络的结构图。
25.图2为本发明的一幅归一化余弦干涉图i
cos
(分辨率256
×
256)的相位解调示意图。
26.其中:
27.图2(a),真实的无包裹相位分布;
28.图2(b),归一化的余弦干涉图i
cos
;
29.图2(c),辅助输入的图i
sac
;
30.图2(d),网络输出的归一化正弦条纹i
sin
;
31.图2(e),包裹相位分布
32.图2(f),重建的无包裹相位分布φ(x,y);
33.图2(g),重建的无包裹相位与真实相位分布之间的误差分布;
34.图2(h),沿图(g)中白线方向的误差分布截面图。
35.图3为本发明的稀疏的归一化余弦干涉图(分辨率256
×
256)和稠密的归一化余弦干涉图(分辨率256
×
256)的相位解调示意图。
36.其中:
37.图3(a),条纹稀疏的归一化的余弦干涉图i
cos1
;
38.图3(b),条纹稠密的归一化的余弦干涉图i
cos2
;
39.图3(c),i
cos1
对应的作为辅助输入的图i
sac1
;
40.图3(d),i
cos2
对应的作为辅助输入的图i
sac2
;
41.图3(e),i
cos1
(图3(a))对应的真实无包裹相位分布;
42.图3(f),i
cos2
(图3(b))对应的真实无包裹相位分布;
43.图3(g),从i
cos1
和i
sac1
重建得到的无包裹相位分布φ1(x,y);
44.图3(h),从i
cos2
和i
sac2
重建得到的无包裹相位分布φ2(x,y);
45.图3(i),稀疏条纹(图3(a)、3(c))重建得到的相位分布与真实相位之间的误差分布;
46.图3(j),稠密条纹(图3(b)、3(d))重建得到的相位分布与真实相位之间的误差分布。
47.图4为本发明的不同分辨率大小的归一化余弦干涉图i
cos
(依次为384
×
384、512
×
512、640
×
640、832
×
832)的相位解调示意图。
48.其中:
49.图4(a),归一化的余弦干涉图i
cos1
(分辨率大小为384
×
384);
50.图4(b),归一化的余弦干涉图i
cos2
(分辨率大小为512
×
512);
51.图4(c),归一化的余弦干涉图i
cos3
(分辨率大小为640
×
640);
52.图4(d),归一化的余弦干涉图i
cos4
(分辨率大小为832
×
832);
53.图4(e),i
cos1
对应的辅助输入图i
sac1
;
54.图4(f),i
cos2
对应的辅助输入图i
sac2
;
55.图4(g),i
cos3
对应的辅助输入图i
sac3
;
56.图4(h),i
cos4
对应的辅助输入图i
sac4
;
57.图4(i),i
cos1
对应的真实无包裹相位分布(384
×
384);
58.图4(j),i
cos2
对应的真实无包裹相位分布(512
×
512);
59.图4(k),i
cos3
对应的真实无包裹相位分布(640
×
640);
60.图4(l),i
cos4
对应的真实的无包裹相位分布(832
×
832);
61.图4(m),重建的无包裹相位分布φ1(x,y)(384
×
384);
62.图4(n),重建的无包裹相位分布φ2(x,y)(512
×
512);
63.图4(o),重建的无包裹相位分布φ3(x,y)(640
×
640);
64.图4(p),重建的无包裹相位分布φ4(x,y)(832
×
832);
65.图4(q),重建的无包裹相位φ1(x,y)(384
×
384)与真实相位之间的误差图;
66.图4(r),重建的无包裹相位φ2(x,y)(512
×
512)与真实相位之间的误差图;
67.图4(s),重建的无包裹相位φ3(x,y)(640
×
640)与真实相位之间的误差图;
68.图4(t),重建的无包裹相位φ4(x,y)(832
×
832)与真实相位之间的误差图。
69.图5为本发明的单幅图i
cos
作为输入的神经网络和i
cos
、i
sac
作为输入的神经网络相位解调结果对比。
70.其中:
71.图5(a),归一化的余弦干涉图i
cos
(分辨率256
×
256);
72.图5(b),辅助输入的图i
sac
(分辨率256
×
256);
73.图5(c),i
cos
对应的真实无包裹相位分布
74.图5(d),i
cos
作为输入重建的无包裹相位分布φ1(x,y);
75.图5(e),i
cos
和i
sac
同时作为输入重建的无包裹相位分布φ2(x,y);
76.图5(f),φ1(x,y)与真实相位分布之间的误差分布;
77.图5(g),φ2(x,y)与真实相位分布之间的误差分布。
具体实施方式:
78.下面将结合详细的实施例和附图对本发明进行详细的说明。
79.本方法包括如下步骤:1.使用泽尼克(zernike)多项式产生训练数据和测试数据用于网络训练;2.建立并训练神经网络phaseunet++;3.把归一化的余弦干涉图i
cos
和辅助图i
sac
输入训练好的网络,输出得到归一化的正弦干涉图i
sin
;4.利用反正切函数得到包裹相位分布采用相位解包裹算法得到无包裹相位分布φ(x,y)。该技术不仅精度高,而且可以处理不同大小的干涉图,还有较强的抗噪能力。
80.本发明提供的一种基于phaseunet++网络的高精度相位解调方法,具体包括以下步骤:
81.步骤一:数据准备,使用泽尼克(zernike)多项式产生数据用于网络训练,具体步骤如下;
82.步骤1:利用前n(45≥n≥4)阶zernike多项式(mahajan v.n.,et.al.,j.opt.soc.am.a,2007,24(9):2994-3016,doi:10.1364/josaa.24.002994)产生无包裹相位图,如下公式所示:
[0083][0084]
其中,φ(x,y)是无包裹相位分布;zi,ci分别代表第i阶zernike多项式及其系数。第2、3项的泽尼克系数c2、c3是[-25,25]之间的随机数;第4项的系数是[125]之间的随机数,其他的泽尼克系数是位于[-0.50.5]之间的随机数。通过设置泽尼克系数范围,产生弧度范围为10~120rad的无包裹相位分布φ,图片大小为256
×
256像素。
[0085]
步骤2:生成无包裹图后经过以下方式生成对应的训练数据对:
[0086][0087]
其中:i
cos
为归一化余弦干涉图。i
sac
为辅助图,由i
cos
取反余弦后再进行正弦变换得到。ii
sin
为归一化正弦条纹的真实值,作为输出的标签。
[0088]
步骤3:生成40000个分辨率大小为256
×
256的数据对(i
cos
、i
sac
、ii
sin
)后,使用sklearn模块按照8:1:1的比例生成对应的训练数据,测试数据以及验证数据。训练集数据为32000张,测试集数据为4000张,验证集数据为4000张。
[0089]
步骤二:设计phaseunet++网络,用步骤一得到的数据对网络进行训练。具体步骤如下:
[0090]
步骤1、设计phaseunet++神经网络
[0091]
设计相位解调网络phaseunet++,网络的结构图如图1所示。phaseunet++网络有下采样和上采样,通过稠密的网络连接,保留了更多维度的特征信息,这使得后面的网络层可在浅层特征与深层特征间自由选择,同时在卷积层中采用跳跃连接,可以有效减少梯度消失的问题,使训练更容易。本实施例中,phaseunet++神经网络包括:卷积层conv2d、归一化层batchnorm2d、激活层relu、残差连接块resblock、池化层maxpool2d、反卷积层convtranspose2d、连接层concat。
[0092]
对于输入的i
cos
和i
sac
图分别通过resblock层得到x
cos
和x
sac
,然后通过concat层得到x
0.0
。将x
0.0
作为网络的输入,x
0.0
通过maxpool2d层得到x
1.0
,x
1.0
通过convtranspose2d层上采样后和x
0.0
通过concat层按通道(channel)维度进行拼接得到x
0.1
。其他层的结构依次类推(见图1所示)。网络中,每一层的resblock卷积块的输入都由相同层中的所有前置resblock卷积块的输出和左下角resblock卷积块的输出通过concat层按通道(channel)维度进行拼接得到,可以抓取不同层的特征。
[0093]
对于每一个resblock卷积块x
i.j
(i,j=0,1,2,
…
)都是将输入进行卷积,然后通过归一化层batchnorm2d和激活层relu,再经过卷积,通过归一化层batchnorm2d,和输入通过concat层相加,最终通过激活层relu后输出。
[0094]
步骤2、使用步骤一中的训练数据对phaseunet++神经网络进行训练,具体是将归一化余弦干涉图i
cos
和辅助图i
sac
作为网络的输入;i
cos
相移90度后的正弦干涉图ii
sin
作为
网络的输出标签,与网络的输出i
sin
计算损失函数值,直到损失函数不再下降并保持稳定后训练完成,得到网络各层的权重值。
[0095]
步骤三:把实际测量得到的余弦干涉图归一化得到i
cos
,把i
cos
和辅助图i
sac
输入训练好的神经网络,输出归一化的正弦干涉图i
sin
。
[0096]
步骤四:通过余弦干涉图i
cos
和正弦干涉图i
sin
的计算得到包裹相位分布具体实现如下:
[0097][0098]
其中,是包裹相位分布,i
sin
(x,y)为归一化的正弦干涉图,i
cos
(x,y)为归一化余弦干涉图。计算得到包裹相位分布后,利用传统的解包裹算法进行相位解包裹,最终得到无包裹相位分布φ(x,y)。
[0099]
实施例1.一种基于深度学习的相位解调方法,包括以下步骤:
[0100]
步骤一:数据准备,使用泽尼可(zernike)多项式产生数据用于网络训练;
[0101]
步骤1:利用zernike多项式的前10阶产生无包裹相位图,如下公式所示;
[0102][0103]
其中,φ(x,y)是无包裹相位分布;zi,ci分别代表第i阶zernike多项式及其系数。第2、3项的泽尼克系数c2、c3是[-25,25]之间的随机数;第4项的系数是[125]之间的随机数,其他的泽尼克系数是位于[-0.50.5]之间的随机数。通过设置泽尼可系数范围,产生弧度范围为10~120rad的无包裹相位分布φ(x,y),图片大小为256
×
256像素。图2(a)所示为一幅无包裹相位φ的分布图。
[0104]
之后将通过φ计算得到归一化的余弦干涉图i
cos
(图2(b)),公式如下所示:
[0105]icos
(x,y)=cos(φ(x,y))
[0106]
步骤2:对余弦条纹进行归一化(对非归一化的条纹)得到i
cos
后,通过以下公式获取另一幅输入图i
sac
(图2(c)):
[0107]isac
(x,y)=sin(acos(i
cos
(x,y)))
[0108]
步骤二:设计phaseunet++网络,用步骤一得到的数据对网络进行训练。
[0109]
步骤1:设计phaseunet++神经网络。i
cos
、i
sac
作为输入、ii
sin
作为输出标签对神经网络进行训练。phaseunet++神经网络包括:卷积层conv2d、归一化层batchnorm2d、激活层relu、残差连接块resblock、池化层maxpool2d、反卷积层convtranspose2d和连接层concat;
[0110]
对于输入的i
cos
和i
sac
图分别通过resblock层得到x
cos
和x
sac
,然后通过concat层得到x
0.0
。将x
0.0
作为网络的输入,x
0.0
通过maxpool2d层得到x
1.0
,x
1.0
通过convtranspose2d层上采样后和x
0.0
通过concat层按通道(channel)维度进行拼接得到x
0.1
。其他层的结构依次类推(见图1所示)。网络中,每一层的resblock卷积块的输入都由相同层中的所有前置resblock卷积块的输出和左下角resblock卷积块的输出通过concat层按通道(channel)维度进行拼接得到,
[0111]
对于每一个resblock卷积块x
i.j
(i,j=0,1,2,
…
)都是将输入进行卷积,然后通过归一化层batchnorm2d和激活层relu,再经过卷积,通过归一化层batchnorm2d,和输入通过
concat层相加,最终通过激活层relu后输出。
[0112]
步骤2:使用训练数据对phaseunet++神经网络进行训练。直到损失函数不再下降并保持稳定后训练完成,得到网络各层的权重值。
[0113]
步骤三:把实际测量得到的余弦干涉图归一化得到i
cos
,把i
cos
和辅助图i
sac
输入训练好的神经网络,输出归一化的正弦干涉图i
sin
(图2(d))。
[0114]
步骤四:通过余弦干涉图i
cos
和正弦干涉图i
sin
的计算得到包裹相位分布(图2(e))。具体实现如下公式:
[0115][0116]
其中,为包裹相位分布,i
sin
(x,y)为归一化的正弦干涉图,i
cos
(x,y)为归一化余弦干涉图。用传统的解包裹算法对进行相位解包裹,最终得到无包裹相位分布图φ(x,y)(图2(f))。
[0117]
图2(g)是重建的得到的无包裹相位分布与真实相位分布之间的差值,从中可以看出,最大的重建误差小于0.05rad。为了定量衡量重建的无包裹相位分布的精度,计算了重建的相位分布和真实值之间的均方根误差rmse(root mean squared error),结果为0.0013rad,表明重建结果具有较高的精度。为了直观的显示误差的分布,我们给出了沿图2(g)中白线方向的截面图,如图2(h)所示。
[0118]
实施例2:步骤1和2同实施例1,得到训练好的神经网络,这样在具体实施的时候,只需要从本发明方法的步骤三开始执行即可。该实施例通过输入不同密集程度的干涉图,验证其有效性,具体步骤如下。
[0119]
步骤3:分别把条纹稀疏、稠密的归一化的余弦干涉图输入到训练好的phaseunet++网络。图3(a)、3(c)分别是条纹稀疏的余弦干涉图i
cos1
及其辅助图i
sac1
,图3(b)、3(d)分别是条纹较密集的余弦干涉图i
cos2
及其辅助图i
sac2
。图3(a)、3(c)输入phaseunet++网络,输出得到归一化的正弦条纹i
sin1
;图3(b)、3(d)输入phaseunet++网络,输出对应的归一化的正弦条纹i
sin2
。
[0120]
步骤4:计算包裹相位分布。具体实现如下公式:
[0121][0122]
其中,(i=1,2)为对应的包裹相位分布,i
sini
(x,y)为对应的正弦干涉图,i
cosi
(x,y)为对应的余弦干涉图,下标i=1,2分别表示条纹稀疏、条纹密集的两种情况。利用传统的相位解包裹算法对进行解包裹,最终得到无包裹相位分布φi(x,y),分别如图3(g)、图3(h)所示。
[0123]
图3(e)、图3(f)分别为条纹稀疏(图3(a))、条纹密集(图3(b))的干涉图对应的真实无包裹相位分布。图3(i)、图3(j)为重建的相位分布与真实值之间的误差分布。图3(i)的均方根误差rmse为0.0018rad,图3(j)的rmse为0.0022rad。结果表明,在干涉图稀疏、稠密的时候,都可以高精度的重建相位分布。
[0124]
实施例3:步骤1和2同实施例1,得到训练好的神经网络,这样在具体实施的时候,
只需要从上面的步骤三开始执行即可。该实施例通过输入不同大小(384
×
384,512
×
512,640
×
640以及832
×
832)的干涉图,验证其有效性。神经网络输入不同大小的图片,输出的图片与输入的图片分辨率大小相同。
[0125]
步骤3:分别将不同分辨率大小的归一化的余弦干涉图i
cos1
(384
×
384)(图4.a)以及其对应的辅助图i
sac1
(图4.e);归一化的余弦干涉图i
cos2
(512
×
512)(图4.b)以及其对应的辅助图i
sac2
(图4.f);归一化的余弦干涉图i
cos3
(640
×
640)(图4.c)以及其对应的辅助图i
sac3
(图4.g);归一化的余弦干涉图i
cos4
(832
×
832)(图4.d)以及其对应的辅助图i
sac4
(图4.h)分别输入phaseunet++网络。
[0126]
phaseunet++网络分别输出得到相对应大小(384
×
384,512
×
512,640
×
640以及832
×
832)的归一化的正弦干涉图i
sin1
、i
sin2
、i
sin3
和i
sin4
。
[0127]
步骤4:分别从余弦干涉图i
cosi
(i=1,2,3,4)和对应的正弦干涉图i
sini
(i=1,2,3,4)得到包裹相位分布。具体实现如下公式:
[0128][0129]
其中,为对应的包裹相位分布。
[0130]
计算得到包裹相位分布后,利用传统的解包裹算法对进行相位解包裹,得到最终的无包裹相位分布φi(x,y)。结果如图4(m)、4(n)、4(o)、4(p)所示,图片的大小分别为384
×
384、512
×
512、640
×
640以及832
×
832。
[0131]
为了比较重建结果的精度,图4(i)、4(j)、4(k)、4(l)分别展示了图4(a)、4(b)、4(c)、4(d)对应的真实无包裹相位分布,图4(q)、4(r)、4(s)、4(t)为重建结果的误差分布图,他们的均方根误差rmse分别为0.0028rad、0.0035rad、0.0037rad、0.0071rad。结果表明,该网络对于不同分辨率大小的干涉图都能得到精确的重建结果。
[0132]
对比例.仅输入单幅余弦干涉图i
cos
的phaseunet++1网络与把归一化余弦干涉图i
cos
、辅助图i
sac
同时作为输入的phaseunet++2的重建精度进行对比。结果表明i
cos
、i
sac
同时作为输入的phaseunet++2网络的重建结果更好,精度更高。具体步骤如下:
[0133]
步骤一:数据准备,使用泽尼克(zernike)多项式产生数据用于网络训练;
[0134]
步骤1:利用zernike多项式的前10阶产生无包裹相位分布图,如下公式所示:
[0135][0136]
其中,φ(x,y)是无包裹相位分布;zi、ci分别代表第i阶zernike多项式及其系数。第2、3项的泽尼克系数c2、c3是[-25,25]之间的随机数;第4项的系数是[125]之间的随机数,其他的泽尼克系数是位于[-0.50.5]之间的随机数。通过设置泽尼克系数范围,产生弧度范围为10~120rad的无包裹相位分布φ,图片大小为256
×
256像素。
[0137]
步骤2:生成无包裹相位φ后经过以下方式生成对应的训练数据:
[0138][0139]
步骤3:生成40000个分辨率大小为256
×
256的数据对后,使用sklearn模块按照8:
1:1的比例生成对应的训练数据,测试数据以及验证数据。训练集数据为32000张,测试集数据为4000张,验证集数据为4000张。
[0140]
步骤二:训练神经网络phaseunet++1:直接将归一化的余弦干涉图i
cos
和归一化正弦条纹ii
sin
分别作为输入和输出标签进行训练。
[0141]
训练神经网络phaseunet++2:将归一化的余弦干涉图i
cos
和辅助图i
sac
同时作为输入,归一化正弦条纹ii
sin
作为输出标签进行训练。
[0142]
phaseunet++1、phaseunet++2的区别仅在于输入层卷积核的维度不同,网络的其他参数完全相同。
[0143]
步骤三:把归一化的余弦干涉图i
cos
(图5(a))输入训练好的神经网络phaseunet++1,输出得到归一化的正弦干涉图i
sin1
,根据反正切函数得到包裹相位分布进而得到无包裹相位分布φ1(x,y),(图5(d))所示;
[0144]
把同一幅干涉图i
cos
(图5(a))和辅助图i
sac
(图5(b))同时输入phaseunet++2,输出得到归一化的正弦干涉图i
sin2
,根据反正切函数得到包裹相位分布进而得到无包裹相位分布φ2(x,y),如图5(e)所示;
[0145]
为了比较重建结果的精度,图5(c)所示为真实的无包裹相位分布,图5(f)、5(g)为分别为采用phaseunet++1和phaseunet++2的重建结果误差分布,他们的均方根误差rmse分别为0.0031rad和0.0018rad。结果表明,采用i
cos
和i
sac
作为输入的phaseunet++2网络具有更高的重建精度。
[0146]
以上所述,仅是本发明的较佳实施例,并非对本发明作任何形式上的限制,凡是依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与修饰,均仍属本发明技术方案的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1