电机轴承故障诊断方法
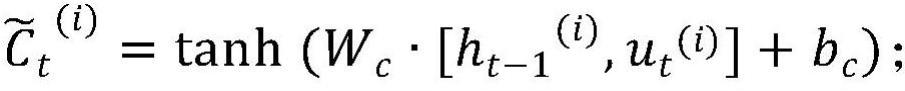
本发明涉及电机轴承故障诊断方法。
背景技术:
1、在现代工业生产中,电机作为电能生产、传输、使用的核心设备占据重要地位。电机轴承是电机的核心组件,在支撑和输送动力方面起着极其重要的作用。电机作为一个复杂的综合电气设备,通常工作在比较恶劣的环境中,电机轴承的内圈、滚动体和外圈很容易出现故障,据统计,在感应电机故障中,电机轴承引发的故障约占电动机故障的40%,因此电机轴承的故障诊断是电机安全运行的重要保障,直接关系到公司的安全生产和经济效益。
2、卷积神经网络(cnn)在处理二维数据时具有一定优势,因为它可以通过其分层结构自主学习并提取输入数据的特征。一种基于卷积网络和振动信号双频谱分析的方案,该方法可用于变速工况下的轴承故障诊断,且诊断精度高。一种基于多尺度卷积神经网络的风电齿轮箱故障诊断,该方法不需要任何耗时的手工特征提取过程,并且在工作负载变化和噪声环境下工作良好。cnn在特征提取方面的表现方面良好,但随着层数增多,在训练的过程中需要大量的样本,且对训练的设备配置要求高。
3、循环神经网络(rnn)。循环神经网络的路径从其隐藏层到输出层时,循环模型可以捕获并建模顺序数据或时间序列数据。长短期记忆网络(lstm)改进了rnn梯度消失的问题。一种基于lstm神经网络的模型,对原始信号采用数据增强技术,取得了很好的故障识别效果。一种基于长短时记忆循环神经网络的智能故障诊断方案,利用空间和时间的依赖性对故障进行预测,并在实验中验证了方案的有效性。但lstm模型的参数多,人工调参困难。
4、在基于深度学习的电机轴承故障诊断算法中,参数的选择决定了算法模型的准确性。近年来,研究人员一直在研究优化算法来解决参数选择的问题,如粒子群算法、蚁群算法、人工蜂群算法、萤火虫算法等。但传统的优化算法在解决多目标问题中,存在参数不具备适应性、易陷入局部最优、收敛速度慢等问题。
5、因此,针对以上问题提出了电机轴承故障诊断方法。
技术实现思路
1、本发明的目的在于克服现有的缺陷而提供的电机轴承故障诊断方法,避免了故障诊断模型人工调参,改善了传统的优化算法收敛精度低、优化速度慢、易陷入局部最优的状况,有效缓解过拟合,提升了故障的诊断效果。
2、实现上述目的的技术方案是:
3、电机轴承故障诊断方法,包括:
4、步骤s1,构建clstm(长短期记忆模型结合的混合深度神经网络模型)故障诊断模型,并采用ssa(麻雀搜索算法)进行优化,获得ssa-clsmt(麻雀搜索算法-长短期记忆模型结合的混合深度神经网络模型)模型;
5、步骤s2,采集电机轴承在正常、外圈损伤、内圈损伤、滚珠损伤的原始振动信号,并对数据集打标签分类,按0.2比例划分为训练集和测试集,输入到ssa-clsmt模型中;
6、步骤s3,初始化ssa-clsmt模型参数——最大迭代次数g、麻雀种群数n、麻雀个体数dim、发现者比例p、上边界ub、下边界lb、预警值r2和适应度函数f;
7、步骤s4,更新麻雀个体的位置,返回当前最佳麻雀个体和最佳适应度值;
8、步骤s5,不满足迭代次数重复步骤s4,满足迭代次数输出最佳的麻雀个体和最佳适应度值并保存;
9、步骤s6,将最佳的麻雀个体回代ssa-clsmt模型,输出相应结果。
10、优选的,所述步骤s1中构建clstm故障诊断模型,对输入数据特征xr={x1,x2,x3…xn},采用一层卷积核的个数为1,大小为7x1,步长为1的2d卷积层对其进行特征提取,窗口数据滑窗(步长为1)与卷积核做内积:
11、
12、其中,x(j)和bi分别表示卷积层的第i个卷积核的权矩阵和偏置矩阵,x(j(j∈r)表示第j个样本,ui(j)表示第j个样本在和第i个卷积核内积后的输出特征;最终输出卷积后的特征ur={u1,u2,u3…un};
13、针对序列数据的特点,引入两层lstm对ur进一步挖掘其潜在联系;lstm是一种rnn特殊的类型,可以学习长期依赖信息,结构核心是在里面加入了三个‘门’机制——忘记门、输入门和输出门;
14、将ur={u1,u2,u3…un}输入lstm模型,遗忘门决定模型从细胞状态中丢弃的信息,该门会读取ht-1和ut,输入一个在[0,1]之间的数值给每个在细胞状态ct-1中的数字,模型可描述为:
15、
16、输入门有两部分功能,一部分找到需要更新的细胞状态,另一部分把需要更新的信息更新到新的细胞状态里,模型可描述为:
17、st(i)=σ(ws·[st-1(i),ut(i)]+bi);
18、
19、忘记门找到需要忘记的信息ft后,再将它与旧细胞状态相乘,丢弃确定需要丢弃的信息。再将结果加上icxct使细胞状态获得新的信息,完成细胞状态的更新,模型可描述为:
20、
21、输出门通过一个sigmoid(逻辑斯谛)层来确定哪部分的信息将输出,接着把细胞状态通过tanh(双曲正切)进行处理,得到一个在(-1,1)之间的值,并将其和sigmoid门的输出相乘,最终得出想要输出的部分,其模型可以描述为:
22、ot(i)=σ(wo·[ht-1(i),ut(i)]+bo);
23、ht(i)=ot(i)*tanh(ct(i));
24、其中,ft(i),st(i),ct(i),ot(i)分别为t时间步长下第i个样本下遗忘门、输入门、记忆单元和输出门的输出;wf,ws,wc,wo分别为遗忘门、输入门、记忆单元和输出门的权重矩阵;bf,bi,bc,bo分别为遗忘门、输入门、记忆单元和输出门的偏置矩阵;σ为sigmiod函数;为t时间步长下第i个样本在记忆单元的细胞状态信息;ht(i)为在t时间步长下第i个样本;
25、为了缓解过拟合,改进lstm,在其中添加dropout(丢弃)层,让某些神经元的激活值以一定的概率停止工作;经两层改进后的lstm的,最终输出特征,h={h1,h2…,ht};
26、输出层使用softmax(归一化指数)作为模型的分类器,对不同类型的信号进行分类,得到最终的故障分类概率,公式如下:
27、
28、其中ypred最终预测故障概率;hj为lstm最终输出特征。
29、优选的,所述步骤s1中采用ssa进行优化,获得ssa-clsmt模型,将多分类交叉熵函损失函数作为麻雀算法中的适应度函数,数学模型为:
30、
31、其中,n为样本数量,m为故障类别的数量;为符号函数,如果样本i的真实类别等于c取1,否则取0;观测样本i属于类别c的预测概率;
32、需要优化的学习率、第一隐层神经元数、第二隐层神经元数、dropout作为虚拟的麻雀个体位置,其搜寻边界设置为其下边界为[0.001,10,10,0.01],上边界为[0.01,150,150,0.2],并由10只麻雀个体构成种群,去寻找最优解,其为数学模型如下:
33、
34、其中,x为麻雀种群,z为麻雀位置参数;
35、麻雀的适应度值可描述为:
36、
37、其中为适应度函数,为麻雀个体;
38、发现者的位置更新描述如下:
39、
40、其中,t为当前迭代数,t表示最大的迭代次数,xi,j(t)表示第i个麻雀在第j维中的位置信息,α为(0,1]是一个随机数,r∈[0,1]和st∈[0.5,1]分别表示预警值和安全值,q是服从正态分布的随机数,l表示一个1×d的矩阵,其中该矩阵内每个元素全部为1;
41、加入者(追随者)的位置更新描述如下:
42、
43、其中,xp(t)+1)是目前发现者所占据的最优位置,xworst(t)则表示当前全局最差的位置,a表示一个1×d的矩阵,其中每个元素随机赋值为1或-1,并且a+=at(aat)-1;
44、当意识到危险时,麻雀种群会做出反捕食行为,其数学表达式如下:
45、
46、其中,xbest(t)是当前的全局最优位置;β作为步长控制参数,是服从均值为0,方差为1的正态分布的随机数;k∈[-1,1]是一个随机数,fi则是当前麻雀个体的适应度值;fg和fw分别是当前全局最佳和最差的适应度值;ε是最小的常数。
47、本发明的有益效果是:该方法避免了故障诊断模型人工调参,改善了传统的优化算法在处理多目标问题,如收敛精度低、优化速度慢、易陷入局部最优的状况,并解决了感应电机轴承序列数据间的关系难以挖掘的问题,有效缓解过拟合,提升了故障的诊断效果;对轴承故障数据集精度诊断到达了99.5%,训练精度和测试精度相差不到1%,30次优化用时0.75小时,验证了所提方法能有效缓解过拟合问题,且对比其他优化算法,ssa的优化速度更快、优化质量更好。
- 还没有人留言评论。精彩留言会获得点赞!