一种基于内积距离度量的深度聚类雷达脉冲信号分选方法与流程
本发明涉及信号与信号处理,特别涉及一种基于内积距离度量的深度聚类雷达脉冲信号分选方法。
背景技术:
1、信号分离技术属于信号处理技术在侦查领域的特殊应用,是信号识别、干扰等后续任务的基础。信号接收机接收到的是交错的电磁信号,这些信号是干扰信号和多个感兴趣雷达辐射源发射的脉冲信号的混合,这使得对信号的分析变得十分困难。信号分离是将不同辐射源的脉冲信号分别提取,获得单个辐射源的脉冲信号的过程。通常,信号处理过程中会将雷达中频信号提取脉冲序列特征,然后针对交错的脉冲特征进行分离,信号分离的过程也是一个将序列进行去交错的过程,也称作信号分选。
2、通常信号分选领域的聚类方法是一种无监督学习方法,这些方法使用没有标签的样本数据,通过定义距离度量,利用数据特征本身的可区分性,将距离近的样本视作同一类,距离远的样本视作不同类,将不同辐射源的雷达脉冲信号划为不同的类别,从而完成雷达信号的分选。
3、然而,仅仅使用数据特征本身的性质进行距离设计,难以使用在复杂的数据特征方法上。例如对于典型的五维脉冲描述字(pdw)特征,有到达时间(toa),载频(rf),脉冲宽度(pw),到达角(aoa)等。在一小段时间内,在不使用捷变的情况下,如果多个pdw特征的rf在容差之内,通常情况下这些pdw会属于同一个辐射源。但是,如果有这样一种情况,虽然这些脉冲的rf并不在容差内,但是toa是呈现等差的变化,这种情况下这些脉冲很可能也是属于同一个辐射源。针对上述现象设计距离度量,就会需要大量的专家知识规则。而在实践中,这些现象纷繁复杂,并且具有和环境相关的特征,这就导致了最终设计出的算法冗长累赘,并且难以维护。
4、因此,本发明提出一种基于内积距离度量的深度聚类雷达脉冲信号分选方法,以解决上述问题。
技术实现思路
1、本发明的目的在于:本发明提供了一种基于内积距离度量的深度聚类雷达脉冲信号分选方法,通过设计基于内积距离度量学习方法,将雷达脉冲用高可分性的高维特征进行表达,从而能够轻松地使用基于距离度量的聚类方法,完成信号分选工作。
2、本发明是一种基于内积距离度量的深度聚类雷达脉冲信号分选方法,包括以下步骤:
3、对于雷达脉冲信号的序列特征xi,通过基于注意力机制的序列神经网络模型将其映射到距离度量空间,获得新序列特征zi;
4、对基于注意力机制的序列神经网络模型进行参数训练,将新序列特征zi输入全连接神经网络层,获得逻辑子ui,l,然后使用softmax函数生成概率pi,l,并且与标签g(i)计算交叉熵损失函数,然后使用动量随机梯度下降算法更新模型的所有参数;
5、基于内积距离度量的聚类算法对新序列特征zi进行分选。
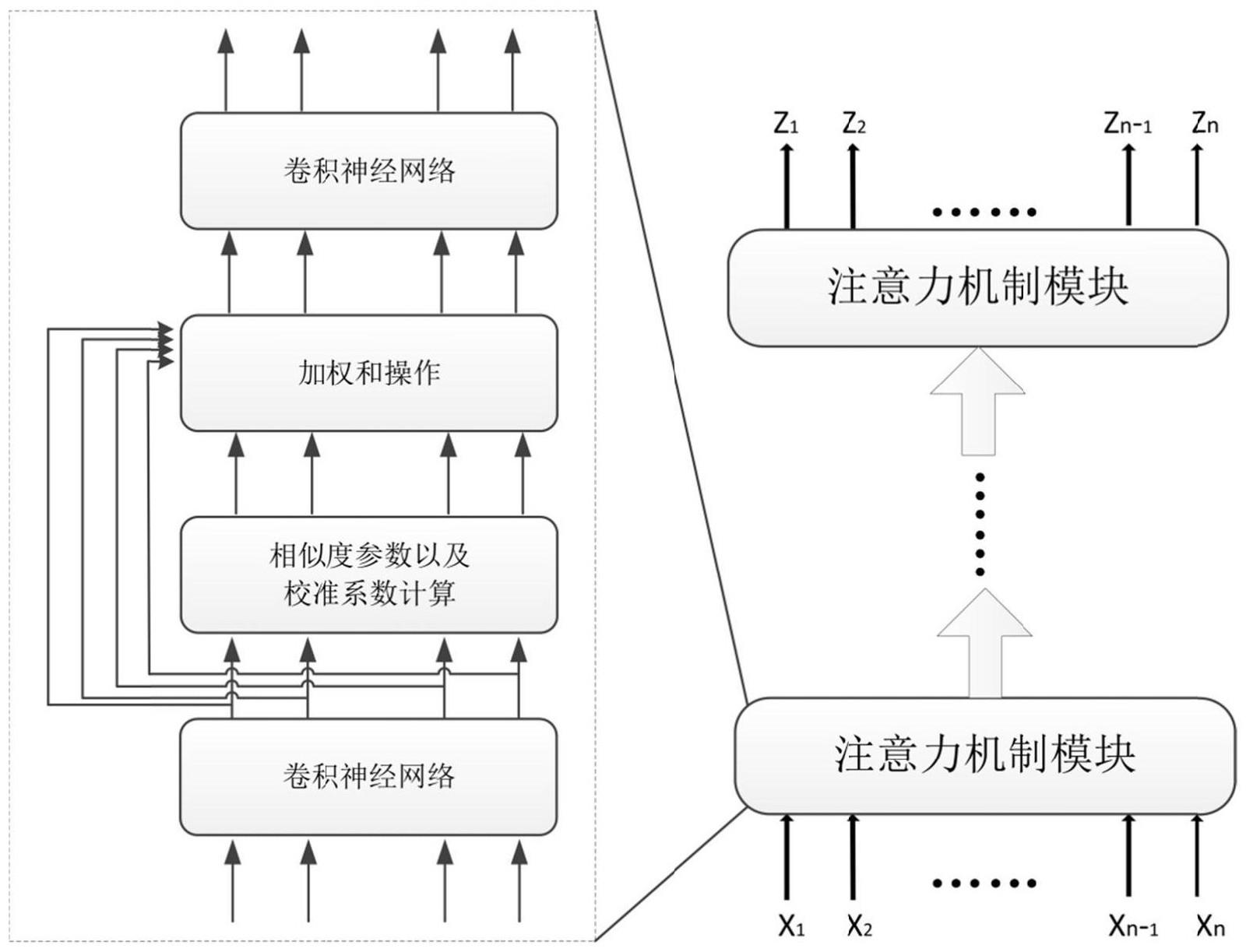
6、进一步的,所述基于注意力机制的序列神经网络模型将序列特征xi映射到距离度量空间,获得新序列特征zi,包括三个步骤,分别为输入映射部分,注意力部分和输出部分,具体的:
7、步骤1、输入映射部分,对于序列特征xi={xi,1,xi,2,xi,3…xi,k},i=1,2,3…n,其中k为特征的维数,n为一段时间电磁信号采样出来的脉冲数据样本的数量,通过1-d卷积神经网络,将序列特征xi映射到新的特征空间,获得特征
8、步骤2、注意力部分,使用特征进行相似度分析并且进行特征融合,获得新特征
9、步骤3、输出部分,对于新特征与步骤1相似,通过1-d卷积神经网络,将新特征映射到新的特征空间,输出新序列特征zi。
10、进一步的,所述1-d卷积神经网络包含一个或多个卷积模块,多个这样的卷积模块顺序相连,一个模块的输出作为下一个模块的输入使用,卷积模块由卷积层-relu激活函数-批规范化层构成,该1-d卷积神经网络的卷积核尺寸为1,输出特征维度为d,且d>k。
11、进一步的,使用特征进行相似度分析并且进行特征融合,具体包括以下步骤:
12、步骤21,计算序列特征xi中每一数据与序列特征xi中其它所有特征xj,j≠i的相关系数si,j:
13、
14、步骤22,用softmax函数进行归一化,计算校准系数ai,j
15、
16、其中,exp()表示e指数函数;
17、步骤23,加权和操作获得新特征
18、
19、进一步的,所述将新序列特征zi输入全连接神经网络层,获得逻辑子ui,l,具体步骤为:
20、步骤4,引入一组可学习参数wl∈rd,l=1,2,3…c表示聚类中心,通过计算特征zi与wl的内积作为距离度量,以距离远近作为雷达脉冲特征类别的评判标准,具体公式为:
21、
22、然后使用softmax函数进行归一化,生成概率pi,l,
23、
24、其中,exp()表示e指数函数,pi,l是zi属于第l个类别的概率,最终,zi由pi,l,l=1,2,3…c中最大值对应的类别决定;
25、采用标签g(i)计算交叉熵损失函数,
26、
27、其中,qi,j真实概率:
28、
29、其中,g(i)为数据类别标签。
30、进一步的,在模型参数训练阶段,使用动量随机梯度下降法对交叉熵损失函数进行优化,更新模型所有参数,并且采用单个样本进行一次更新的方式,学习率设置为0.0001。
31、进一步的,所述聚类算法为kmeans聚类算法、层次聚类或者knn算法。
32、进一步的,基于内积距离度量的聚类算法对特征序列zi进行分选,具体使用kmeans算法对特征序列zi进行分选,步骤如下:
33、步骤51,随机在序列特征zi中选取k个样本作为中心,记为vm,m=1,2,3…k;
34、步骤52,使用内积计算序列特征zi到vm的距离
35、步骤53,选取距离最小的中心类别作为序列特征zi的类别,
36、ci=argmaxmdi,m;
37、步骤54,将所有相同类别的特征进行求平均操作,获得新的类别中心:
38、
39、
40、步骤55,重复迭代52-54步骤,迭代次数为t,最终输出的类别ci作为信号分选的结果。
41、本发明的有益效果如下:
42、1、本发明是一种基于内积距离度量的深度聚类雷达脉冲信号分选方法,通过kmeans聚类完成信号的分选,该方法与过去方法的主要不同在于,使用了基于注意力机制的序列神经网络模型进行特征提取,极大地增加数据特征的可分性,通过有标记的数据进行监督学习,该模型可以自主学习在分选中需要的特征,减少了人工特征的工作量,同时,该方法使用内积聚类来使得模型训练阶段的损失函数和聚类阶段的距离度量一致,保证了分选的有效性和准确率。高准确率的分选,可以为后续信号识别等模块和算法提供强有力的支撑,增强了侦查的效能。
43、2、本发明是一种基于内积距离度量的深度聚类雷达脉冲信号分选方法,提出基于注意力机制的序列神经网络模型,能够很好地进行高维特征提取,充分利用上下文信息,相比过去的基于单个脉冲的特征提取方法有着序列特征能力,从而提取的信息具有更强的健壮性。本发明设计的高准确率分选框架,有利于增强后续型号识别、意图识别等模块的能力,实现侦查能力的提升。
- 还没有人留言评论。精彩留言会获得点赞!