基于DSIFT与EVM实现三维荧光光谱谱图水样排放源识别追踪的方法及其系统
本发明涉及环境监管,尤其涉及水样识别追踪领域,具体是指一种基于dsift与evm实现三维荧光光谱谱图水样排放源识别追踪的方法、系统、装置、处理器及其计算机可读存储介质。
背景技术:
1、随着环境保护要求的不断发展,对自然环境水体以及排入水体的水质进行快速在线监测的需求日益迫切。实现全过程水质监控,从供水到污水处理完整的水循环管理,是环境监管领域的重点和难点。为便于后续不同企业客户荧光谱图的相似度比对、水样的异常监测预警、溯源以及异常程度评价,有关环境监管部门常常需要首先实现不同企业客户基于三维荧光光谱的水样识别追踪。三维荧光光谱谱图是一定范围内激发、发射波长条件下荧光强度的集合,含有丰富的有机物荧光信息,可对水样中有机物进行充分的识别和解析。在所需样品量少的情况下可以实现更安全、更完整以及更精确地判别。
2、不同企业客户的水样溶解有机物构成不同,其荧光光谱也会发生变化。不同时间下,某一时间点下对于当前水样荧光光谱的判别可能并不适用于后几个月甚至后几个星期的情况。现有的方法常常需要工作人员沿着水体流向或排水管网向上游逐步排查,检测和对比各个企业客户水样,以实现不同客户水样的识别及追踪。但这种方法费时费力,难以实现实时监测,同时要求工作人员具有较强的专业知识和经验。
3、目前,基于三维荧光光谱的分析所取得的许多进展依赖于闭集设置条件,即训练和测试数据有着相同的标签和特征空间。然而在现实情况中,环境往往是开放可变、不可预测的,存在未知水样源,易误判为已知客户。相似性度量方法又存在阈值敏感、模型性能易受影响的问题。同时,工业数据图像难以采集,样本量较少。深度神经网络特征提取方法需要大量不同场景的图像数据,训练困难,计算量大,难以针对性地提取不同企业客户谱图独立的位置、形状、纹理等特征信息。因此,亟需构建一种独立性的特征提取方法以及简单高效的水样排放源开集识别方法或系统。
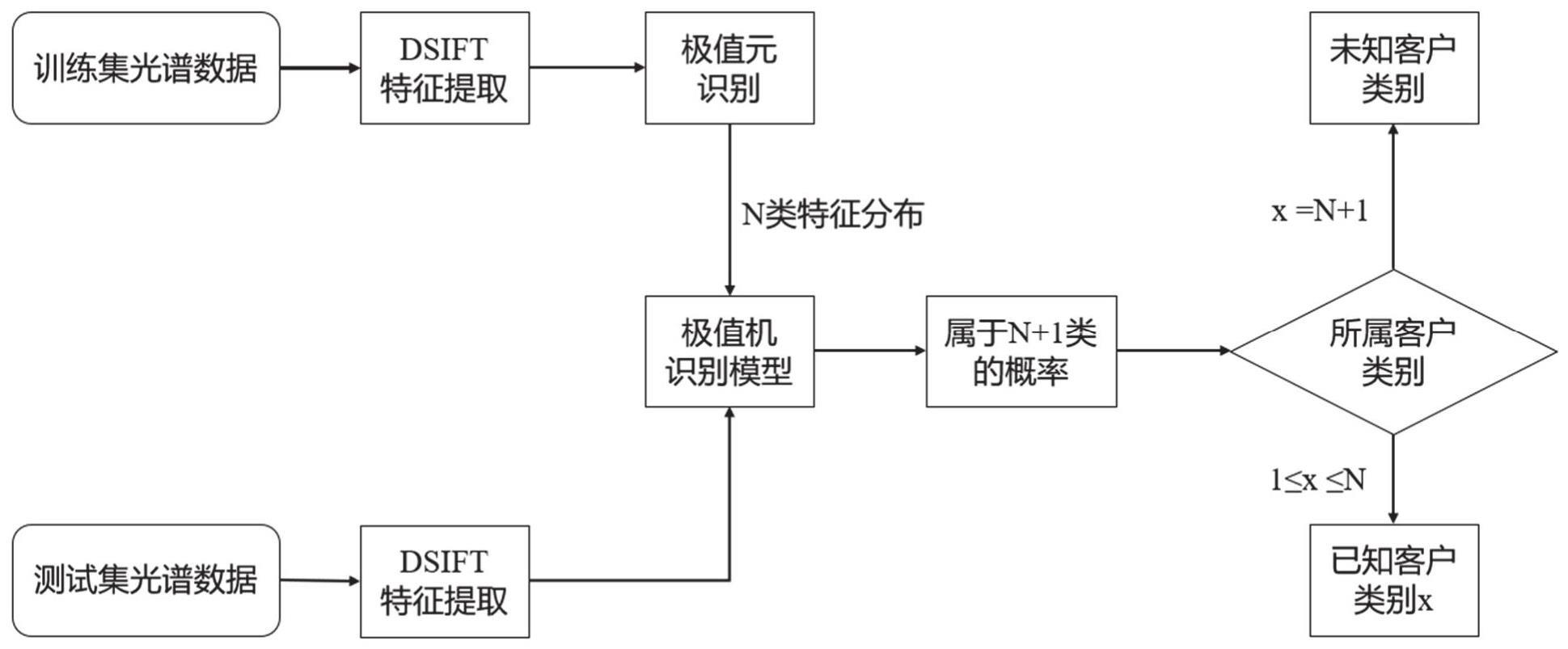
4、针对上述问题,本发明提出了一种基于dsift和evm的不同客户三维荧光光谱水样的识别追踪方法及系统。首先提取各个客户光谱样本的特征向量,构建各个企业客户水质信息的特征向量库,同时引入极值机方法(the extreme value machine,evm),从样本概率分布角度实现开集判定。从而快速识别已知客户、拒绝未知客户水样,避免单一决策,提高排查效率,为后续的应急处理提供参考。
技术实现思路
1、本发明的目的是克服了上述现有技术的缺点,提供了一种满足效率高、操作简便、适用范围较为广泛的基于dsift与evm实现三维荧光光谱谱图水样排放源识别追踪的方法、系统、装置、处理器及其计算机可读存储介质。
2、为了实现上述目的,本发明的基于dsift与evm实现三维荧光光谱谱图水样排放源识别追踪的方法、系统、装置、处理器及其计算机可读存储介质如下:
3、该基于dsift与evm实现三维荧光光谱谱图水样排放源识别追踪的方法,其主要特点是,所述的方法包括以下步骤:
4、(1)采集不同企业客户的水样,并进行紫外可见吸收光谱测试得到三维荧光光谱谱图,对光谱谱图进行裁剪、缩放的图像预处理操作,并按照一定比例划分为训练集和测试集;
5、(2)对预处理后的光谱谱图进行稠密sift特征提取,获得对应每个像素位置的特征描述子,并保存对应每个样本的特征向量;
6、(3)将所有训练数据的特征与对应的类别标签作为evm算法的输入,建立基于威布尔分布的evm模型;
7、(4)将测试样本对应的特征矩阵输入训练后的evm模型进行预测,从样本概率分布角度进行开集判定。
8、较佳地,所述的步骤(1)具体包括以下步骤:
9、(1.1)对不同客户的三维荧光谱图进行裁剪,保留对应的荧光强度集合区域裁去其他区域,并将图像缩放为统一像素大小;
10、(1.2)根据对应数据集和模型按照一定比例,任意选择x个类作为已知类,y个类作为未知类,且未知类设定为同一个类别标签。
11、较佳地,所述的步骤(2)具体包括以下步骤:
12、(2.1)输入统一像素大小的源图像并将其转化为灰度图;创建高斯滤波器,并求出其x、y方向的梯度;分别与源图像作卷积运算生成源图像在x、y方向的方向梯度gx、gy,并计算图像的梯度幅值|j(x,y)|和梯度幅角θj(x,y);
13、(2.2)将图像等分成一个个相同大小的邻域块,并将每个邻域块划分为1个4×4的cell,在每个cell中,使用具有8个bin的方向直方图量化梯度信息,累积cell中所有像素的梯度方向构建直方图,对加权后的量化梯度进行16次采样生成128维的特征向量作为对应位置的特征描述子;
14、(2.3)将单位特征向量中的值阈值化,重新归一化为单位长度,将其展为一维特征向量;将所有样本的一维特征拼接成n×d维的特征矩阵,其中n表示样本的数目,d表示样本特征的维数。
15、较佳地,所述的步骤(2.1)中生成源图像在x、y方向的方向梯度gx、gy,具体为:
16、根据以下公式生成源图像在x、y方向的方向梯度gx、gy:
17、
18、
19、
20、所述的步骤(2.1)中计算图像梯度幅值|j(x,y)|和梯度幅角θj(x,y),具体为:
21、
22、θj(x,y)=atan2(gx,gy)……(5)
23、其中,f为图像特征块,g为高斯核卷积模板,i(x,y)为源图像,g(x,y)为二维高斯函数。
24、较佳地,所述的步骤(2.2)中量化梯度信息,具体为:
25、根据以下公式计算幅值权值和量化梯度信息:
26、ω(θj(x,y)-θt)=max(0,cos(θj(x,y)-θt));
27、|j(x,y,θt)|=ω(θj(x,t)-θt)|j(x,y)|……(6)
28、其中,θt表示8个方向角度,ω(θj(x,y)-θt)表示源图像在特征点(x,y)处对应方向角度的权重值,|j(x,y,θt)|为对应方向角度的梯度大小;
29、根据以下公式生成128维密集描述符:
30、
31、
32、
33、其中,kj(y)是高斯核函数y方向的加权值,ki(x)是高斯核函数x方向的加权值,σwin是高斯核函数的方差,*表示卷积运算,mσ是采样范围大小的控制参数。
34、较佳地,所述的步骤(3)具体包括以下步骤:
35、(3.1)拟合训练样本的边界分布,输入所有训练数据的特征向量和类别标签,计算每两个特征向量之间的余弦距离并乘以边界缩放尺度,得到距离矩阵,并根据距离矩阵、对应样本类别标签和排序标号三部分数据进行威布尔拟合;
36、(3.2)选择边界分布和极值向量的最优组合来覆盖每一类,基于贪婪算法对现有样本模型减少冗余,选择能够表示一类的特征点的最小子集,使其能够覆盖整个类。
37、较佳地,所述的步骤(3.1)中进行威布尔拟合,具体为:
38、根据以下公式进行威布尔拟合:
39、
40、其中,‖xi-x'‖是x'与样本xi间的距离,ki和λi分别是对最小的边际估计值mij进行威布尔拟合得到的威布尔形状参数和尺度参数。
41、较佳地,所述的步骤(3.2)中对现有样本模型减少冗余,具体为:
42、确定xi为某一类ci中的一点,ψ(xi,x',ki,λi)是其对应的威布尔模型,取xj为类ci中除xi外的另一点,对应模型为ψ(xj,x',kj,λj),令为冗余概率阈值,即若两个点对应的评估概率则对于模型对<xi,ψ(xi,x',ki,λi)>来说,模型对<xj,ψ(xj,x',kj,λj)>是冗余的;令i(xi)为指标函数,其基本形式如下式所示:
43、
44、若xi和ψ(xi,x',ki,λi)被保留下来,则组成最终模型的极值向量,优化目标函数的基本形式如下式所示:
45、
46、
47、其中,nl为该类所有点的数目,所有被保留点的样本数据vl(x)、标签y和对应的威布尔模型存储起来即为evm模型。
48、较佳地,所述的步骤(4)具体包括以下步骤:
49、(4.1)计算消除冗余后的evm模型中所有样本数据x和测试样本x'对应的余弦距离矩阵ml;根据ml和evm模型中的weibull模型数据计算测试样本的评估概率ψ(x,x',ki,λi);
50、(4.2)对于每一个测试样本x',选取evm模型的样本数据x中每一个类别对应的最大的若干个评估概率ψ(x,x',ki,λi),并计算出每个类的平均评估概率对于任意测试样本x',计算属于类ci的概率;
51、(4.3)基于反向威布尔分布函数得出样本属于未知类的概率,设定概率阈值δ来定义所有已知类和不支持的开放空间之间的边界,得到分类决策函数y*。
52、较佳地,所述的步骤(4.2)中计算属于类ci的概率,具体为:
53、根据以下公式计算属于类ci的概率:
54、
55、其中,i=0,1,…,k,k代表已知类别总数,m代表训练集中已知类的数量。
56、较佳地,所述的步骤(4.3)中得到分类决策函数y*,具体为:
57、根据以下公式得到分类决策函数y*:
58、
59、其中,若最大的平均估计概率则x'的类别为ci,若则x'被识别为未知客户类别。
60、较佳地,所述的方法在(1)~(3)使用dsift对训练数据集提取特征,并建立每个训练样本对应的evm模型,以离线的形式进行计算,并保存对应的特征矩阵和evm模型,并在(4)使用建立好的模型对输入的测试数据集进行识别,检测出未知类的同时对已知类别进行分类,以在线的形式对测试数据集进行实时处理。
61、该基于dsift与evm进行三维荧光光谱谱图水样排放源识别追踪的系统,其主要特点是,所述的系统包括:
62、光谱预处理模块,用于对经过紫外可见吸收光谱测试得到的三维荧光光谱谱图进行裁剪、缩放的图像预处理操作,并按照一定比例划分为训练集和测试集;
63、特征提取模块,与所述的光谱预处理模块相连接,用于对预处理后的光谱谱图进行稠密sift特征提取,获得图像每个像素位置的特征描述子,并保存对应每个样本的特征向量存储至特征知识库;
64、识别追踪模块,与所述的特征提取模块相连接,用于利用所有训练数据的特征向量与对应的类别标签,并使用evm算法建立基于威布尔分布的evm模型。将待识别光谱样本的特征向量作为evm模型的输入数据进行预测,实现待识别水样的开集识别。
65、该用于实现基于dsift与evm的三维荧光光谱谱图水样排放源识别追踪的装置,其主要特点是,所述的装置包括:
66、处理器,被配置成执行计算机可执行指令;
67、存储器,存储一个或多个计算机可执行指令,所述的计算机可执行指令被所述的处理器执行时,实现上述的基于dsift与evm实现三维荧光光谱谱图水样排放源识别追踪的方法的各个步骤。
68、该用于实现基于dsift与evm的三维荧光光谱谱图水样排放源识别追踪的处理器,其主要特点是,所述的处理器被配置成执行计算机可执行指令,所述的计算机可执行指令被所述的处理器执行时,实现上述的基于dsift与evm实现三维荧光光谱谱图水样排放源识别追踪的方法的各个步骤。
69、该计算机可读存储介质,其主要特点是,其上存储有计算机程序,所述的计算机程序可被处理器执行以实现上述的基于dsift与evm实现三维荧光光谱谱图水样排放源识别追踪的方法的各个步骤。
70、采用了本发明的基于dsift与evm实现三维荧光光谱谱图水样排放源识别追踪的方法、系统、装置、处理器及其计算机可读存储介质,所需样本量少、时效性高,在保证已知客户类别分类精度的前提下,有效地提高了未知水样的识别追踪。
- 还没有人留言评论。精彩留言会获得点赞!