基于自适应核卡尔曼滤波的多传感器融合定位系统及方法
本发明涉及自动驾驶车辆定位,尤其涉及基于自适应核卡尔曼滤波的多传感器融合定位系统及方法。
背景技术:
1、自动驾驶是人工智能领域的一种主流应用,也是最具前景的技术之一。其中精准和鲁棒的车辆定位对于自动驾驶车辆十分重要,定位输出的位置和姿态信息是实现导航、碰撞预警和自动泊车等功能的基础。由于自动驾驶技术无需人类来驾驶,所以理论上能够有效避免人类的驾驶失误,减少交通事故的发生,且能够提高公路的运输效率。因此,自动驾驶技术越来越受到重视。
2、在自动驾驶车辆定位技术领域,组合使用gnss和imu进行定位是较为成熟的解决方案。imu对自身测量的三轴加速度和角速度积分估计位置和姿态,gnss提供较高精度的位置观测以保证imu的累计误差收敛。然而在城市峡谷、树林和隧道等环境中,gnss信号可能被遮挡甚至中断,此时仅依靠imu的车辆定位结果精度和鲁棒性较差。同时常采用卡尔曼滤波及其各种变体处理gnss和imu的数据,但是这些滤波器的精度和实时性很难同时得到保证。
3、因此现有技术需要一种利用车载传感器构造观测量,与gnss和imu一同组成多传感器融合定位系统的方法,来解决车辆定位精度和鲁棒性差的问题,并且需要设计一种新的滤波器,来保证定位系统良好的实时性。
技术实现思路
1、针对上述现有技术存在的不足,本发明提供一种基于自适应核卡尔曼滤波的多传感器融合定位系统及方法,旨在解决车辆定位精度和鲁棒性差的问题,同时保证定位系统具有良好的实时性。
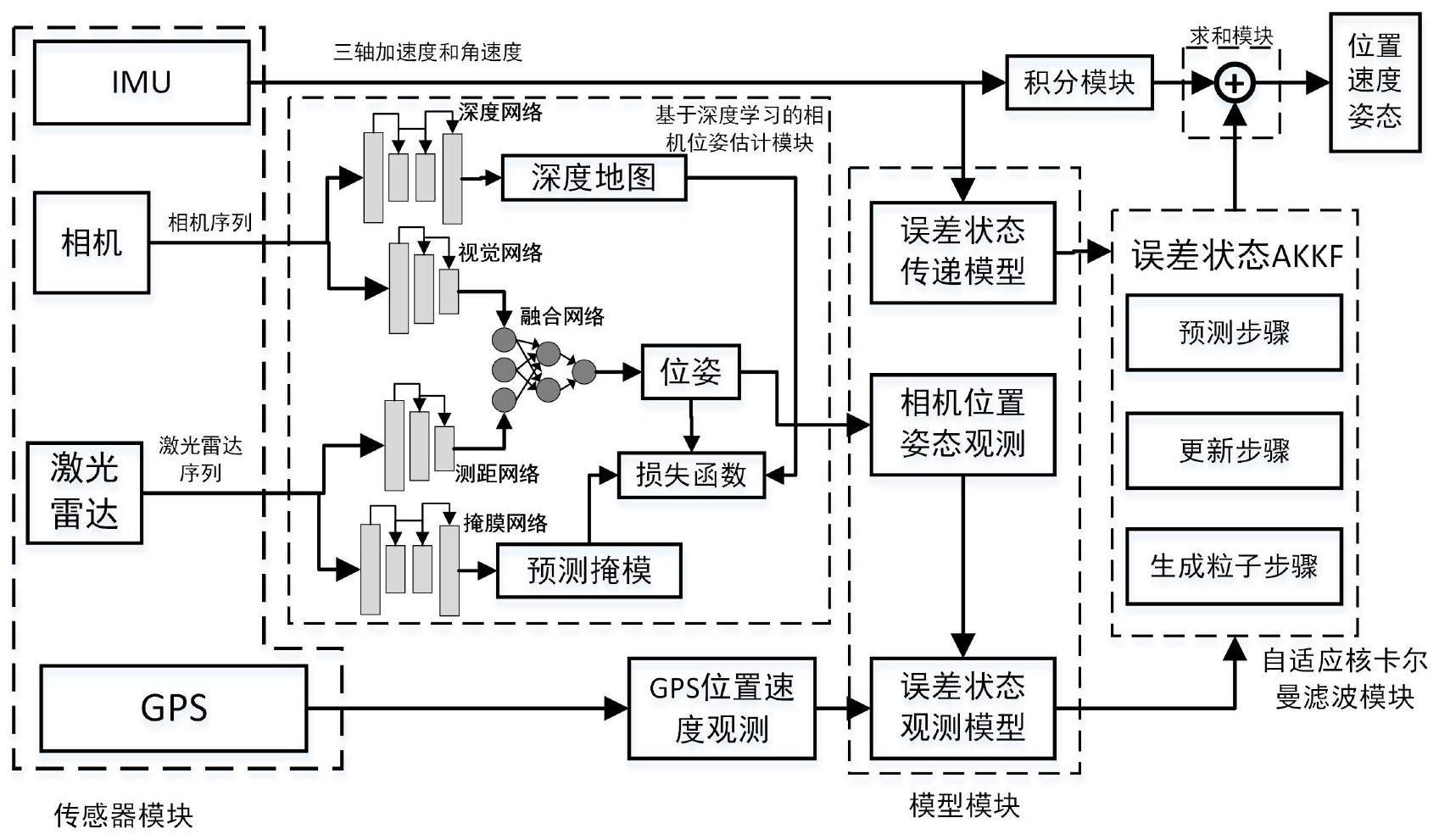
2、为了解决上述问题,本发明第一方面提供一种基于自适应核卡尔曼滤波的多传感器融合定位系统,包括传感器模块、基于深度学习的相机位姿估计模块、模型模块、自适应核卡尔曼滤波模块、求和模块和积分模块;
3、所述传感器模块,包括imu、相机、激光雷达和gps四种传感器;所述imu用于测量三轴加速度和角速度并将测量得到的三轴加速度和角速度发送给模型模块和求和模块;所述相机用于获取相机序列并将相机序列发送给基于深度学习的相机位姿估计模块;所述激光雷达用于获取激光雷达序列并将激光雷达序列发送给基于深度学习的相机位姿估计模块;所述gps用于接收位置和速度观测数据并将接收到的位置和速度观测数据发送给模型模块;
4、所述基于深度学习的相机位姿估计模块,用于接收相机发送的相机序列和激光雷达发送的激光雷达序列;利用神经网络对相机序列和激光雷达序列进行处理,得到相机的位姿;将最终得到相机的位姿发送给模型模块;
5、所述模型模块,用于接收传感器模块发送的三轴加速度和角速度;接收传感器模块发送的位置和速度观测数据;接收基于深度学习的相机位姿估计模块发送的相机的位姿;对三轴加速度和角速度进行处理得到误差状态传递方程并将其发送给自适应核卡尔曼滤波模块;对相机的位姿、位置和速度观测数据进行处理得到观测方程并将其发送给自适应核卡尔曼滤波模块;
6、所述自适应核卡尔曼滤波模块,用于接收模型模块发送的误差状态传递方程和观测方程;利用自适应核卡尔曼滤波算法得到误差状态向量并将其发送给求和模块;
7、所述积分模块,用于接收传感器模块发送的三轴加速度和角速度;对三轴加速度和角速度进行积分推算得到位置速度和姿态信息并将位置速度和姿态信息发送给求和模块;
8、所述求和模块,用于接收积分模块发送的位置速度和姿态信息;接收模型模块发送的误差状态向量;将误差状态向量与积分推算得到的位置速度和姿态信息进行广义求和,输出最终的位置速度和姿态信息。
9、所述基于深度学习的相机位姿估计模块进一步包括:
10、视觉网络,包括基于resnet18网络的第一编码器和一个第一全连接层模块;所述基于resnet18网络的第一编码器用于接收相机发送的相机序列并对相机序列进行相机特征提取,得到图像角点特征并将其发送给第一全连接层模块和注意力模块;所述第一全连接层模块包括两个串联的全连接层,用于接收基于resnet18网络的第一编码器发送的图像角点特征,接收注意力模块发送的图像角点特征的重要性权重,通过两个全连接层完成位姿回归,得到相机位姿并将其发送给位姿融合网络和相机损失函数模块;
11、深度网络,包括基于unet架构的一对编码器和解码器,用于接收相机发送的相机序列;预测相机序列中rgb图像每像素的深度,构成预测深度地图d并将其发送给相机损失函数模块;
12、测距网络,包括基于resnet18网络的第二编码器和第二全连接层模块,所述基于resnet18网络的第二编码器,用于接收激光雷达发送的激光雷达序列并对激光雷达序列进行特征提取得到激光雷达特征并将其发送给第二全连接层模块和注意力模块;所述第二全连接层模块包括两个串联的全连接层,用于接收基于resnet18网络的第二编码器发送的激光雷达特征;接收注意力模块发送的激光雷达特征的重要性权重,通过两个全连接层完成位姿回归得到激光雷达位姿并将其发送给激光雷达损失函数模块和位姿融合网络;
13、掩膜网络,包括基于unet架构的一对编码器和解码器,用于接收激光雷达发送的激光雷达序列;检测激光雷达序列的连续帧中的一致性区域,得到预测掩膜m并将其发送给激光雷达损失函数模块;
14、融合模块包括注意力模块和位姿融合网络,所述注意力模块由基于resnet18网络的第三编码器和softmax激活函数组成,该模块用于接收第一全连接层模块发送的相机位姿和第二全连接层发送的激光雷达位姿;生成图像角点特征的重要性权重和激光雷达特征的重要性权重;将图像角点特征的重要性权重发送给第一全连接层模块,将激光雷达特征的重要性权重发送给第二全连接层模块;所述位姿融合网络是多层感知机(multilayer-perceptron,mlp),用于接收第一全连接层模块发送的相机位姿和第二全连接层发送的激光雷达位姿;将相机位姿和激光雷达位姿进行融合,输出最终的融合相机位姿;
15、相机损失函数模块,用于接收第一全连接层发送的相机位姿、深度网络发送的深度地图和位姿融合网络发送的融合相机位姿;计算相机的损失函数;所述相机的损失函数包括光度误差和深度误差;得到相机损失函数后为其中的光度误差和深度误差分配缩放因子;
16、激光雷达损失函数模块,用于接收第二全连接层发送的激光雷达位姿、掩模网路膜网络发送的预测掩膜和位姿融合网络发送的融合相机位姿;计算激光雷达的强度损失函数和预测掩膜的交叉熵损失函数;得到激光雷达损失函数后为其中的强度损失和掩膜损失分配缩放因子。
17、所述模型模块进一步包括:
18、误差状态传递模型,用于接收imu发送的三轴加速度和角速度;通过对imu建模得到误差状态传递方程并发送给自适应核卡尔曼滤波模块;
19、观测模型,包括相机位置姿态观测和gps位置速度观测,用于接收融合网络发送的相机位姿和gps发送的位置速度观测数据,将融合相机位姿和gps发送的位置速度观测数据组成纳入观测方程中,并将最终的观测方程发送给自适应核卡尔曼滤波模块。
20、本发明第二方面提供一种基于自适应核卡尔曼滤波的多传感器融合定位方法,该方法包括以下步骤:
21、步骤1对车载传感器进行标定,所述标定包括空间标定和时间标定;所述车载传感器指imu、相机、激光雷达和gps;
22、步骤2利用标定好的激光雷达获取激光雷达序列;利用标定好的相机获取相机序列;
23、步骤3根据激光雷达序列和相机序列,估计相机的位姿,得到融合相机位姿;
24、步骤3.1将相机序列输入视觉网络和深度网络,通过视觉网络进行特征提取,得到相机序列的图像角点特征,通过深度网络预测相机序列中rgb图像每像素的深度,得到深度地图;将激光雷达序列输入测距网络和掩膜网络,通过测距网络提取特征,得到激光雷达特征,通过掩膜网络检测激光雷达序列的连续帧中的一致性区域,得到预测掩膜;
25、步骤3.2将得到的图像角点特征和激光雷达特征输入基于resnet18网络的第三编码器和softmax激活函数,得到图像角点特征的重要性权重和激光雷达特征的重要性权重;
26、步骤3.3将得到的图像角点特征的重要性权重分配给图像角点特征,利用第一全连接层模块进行位姿回归得到相机位姿;将得到的激光雷达特征的重要性权重分配给激光雷达特征,利用第二全连接层模块进行位姿回归得到激光雷达位姿;
27、步骤3.4将得到的相机位姿和激光雷达位姿输入多层感知机,得到所估计的融合相机位姿;
28、步骤3.5根据相机位姿、深度地图和估计的融合相机位姿计算相机的损失函数;根据激光雷达位姿和融合相机位姿计算激光雷达的强度损失函数;根据预测掩膜和融合相机位姿计算预测掩膜的交叉熵损失函数;所述相机的损失函数包括光度误差和深度误差;
29、所述相机的损失函数为:
30、lc=lp+λsls(d) (1)
31、其中,lc表示相机的损失函数;lp表示光度误差;ls(d)表示深度误差,其中的参数d表示深度地图;λs表示为深度误差分配缩放因子;
32、所述激光雷达的强度损失函数为:
33、
34、其中,ll表示激光雷达的强度损失函数;ms(xt)表示从源帧到目标帧的误差权重;it(xt)表示目标帧集合;表示重建的源帧集合;xt表示目标帧;s表示激光雷达序列的总帧数;s表示激光雷达序列的第一帧;
35、所述预测掩膜的交叉熵损失函数为:
36、
37、其中,lm表示预测掩膜的交叉熵损失函数;p(ms(xt)=1)表示当目标帧的预测掩膜为1时的交叉熵;
38、步骤3.6对相机的损失函数、激光雷达的强度损失函数和预测掩膜的交叉熵损失函数分配缩放因子,得到总的损失函数;
39、所述总的损失函数为:
40、l=ll+λclc+λmlm (4)
41、其中,l表示总的损失函数;λc和λm分别为相机的损失的缩放因子和预测掩膜的交叉熵损失的缩放因子;
42、步骤3.7通过总的损失函数计算损失值,若损失值未达到极小值则通过反向传播去更新各个网络权值,返回步骤3.4;若损失值达到极小值则执行步骤3.8;
43、步骤3.8选取总的损失函数最小的融合相机位姿作为最终的融合相机位姿。
44、步骤4对imu建模并构建误差状态传递模型;
45、步骤4.1对imu建模得到imu的动态微分方程;
46、步骤4.2定义误差状态向量,并将误差状态向量改写为关于误差状态向量的微分方程组的矩阵形式;所述误差状态向量包括导航状态误差和传感器误差;
47、步骤4.3根据线性系统理论,将矩阵形式的微分方程组转化,得到离散的系统误差状态传递模型。
48、步骤5根据融合相机位姿和gps接收的位置和速度观测数据,得到误差状态的观测模型;所述相机位姿包括的相机位置和相机的姿态;
49、步骤5.1接收融合相机位姿和gps接收到导航坐标系下位置和速度,建立相机位置、相机的姿态、gps接收的位置和gps接收的速度四个观测量的估计值或测量值的关系式;
50、所述四个观测量的估计值或测量值关系如下:
51、
52、其中,和分别表示导航坐标系下的融合相机的位置的估计值和姿态的估计值、gps接收到导航坐标系下的位置信息观测值和gps接收到导航坐标系下的速度观测值;和分别是imu到相机杆臂和imu到gps的杆臂,表示n系下imu的位置,表示导航坐标系下imu的速度,表示从导航坐标系到imu坐标系的旋转矩阵,表示从imu坐标系到相机坐标系的旋转矩阵,和分别是相机姿态的估计噪声、相机位置的估计噪声、gps位置的估计噪声和gps速度的估计噪声;ωi表示角速度的真实值;
53、步骤5.2根据各观测量的估计值与实际值,得到误差状态的观测模型;
54、所述误差状态的观测模型为:
55、
56、其中,为观测量残差,为观测量残差关于误差状态向量的雅可比矩阵,为观测噪声向量;ξ是误差状态向量,vk是观测噪声向量,为融合相机姿态观测残差,为融合相机位置观测残差,为gps位置观测残差,为gps速度观测残差;分别表示融合相机姿态观测、融合相机位置观测、gps位置观测、gps速度观测的雅可比矩阵;分别表示融合相机姿态观测、融合相机位置观测、gps位置观测、gps速度观测的观测噪声。
57、步骤6利用自适应核卡尔曼滤波算法对误差状态向量进行滤波,得到下一时刻的误差状态向量;
58、步骤6.1对误差状态向量的原始粒子进行核均值嵌入操作,得到生成粒子;
59、步骤6.2利用步骤6.1的误差状态向量生成粒子和步骤4.3的误差状态传递模型进行预测,得到预测的下一时刻先验误差状态向量的生成粒子;
60、步骤6.3根据k时刻的观测和利用误差状态的观测模型修正步骤6.2中计算的先验误差状态向量的生成粒子,得到更新的后验误差状态向量。
61、步骤7对imu输出的三轴加速度和角速度进行积分推算得到位置、速度和姿态信息;
62、步骤8将下一时刻更新的后验误差状态向量与积分推算得到位置、速度和姿态信息进行广义求和,得到最终的位置速度估计和姿态估计。
63、本发明提出的一种基于自适应核卡尔曼滤波的多传感器融合定位系统及方法,与现有技术相比较具有如下有益效果:
64、考虑到gnss信号可能被遮挡甚至中断,此时观测信息缺失会使仅依靠imu的车辆定位误差迅速发散,本发明利用深度学习对相机序列和激光雷达序列处理获得额外的观测量,与gnss观测量一同构成多观测量,提升了定位的精度和鲁棒性;针对融合数据时常使用的卡尔曼滤波器及其变体计算量大的缺点,本发明在融合众多传感器数据时采用自适应核卡尔曼滤波算法,该算法能够使定位精度和定位系统的实时性同时得到保证。
- 还没有人留言评论。精彩留言会获得点赞!