一种基于多视角和多传感器时空融合的自动驾驶障碍物检测方法与流程
【】本发明涉及计算机视觉,具体涉及一种基于多视角和多传感器时空融合的自动驾驶障碍物检测方法。
背景技术
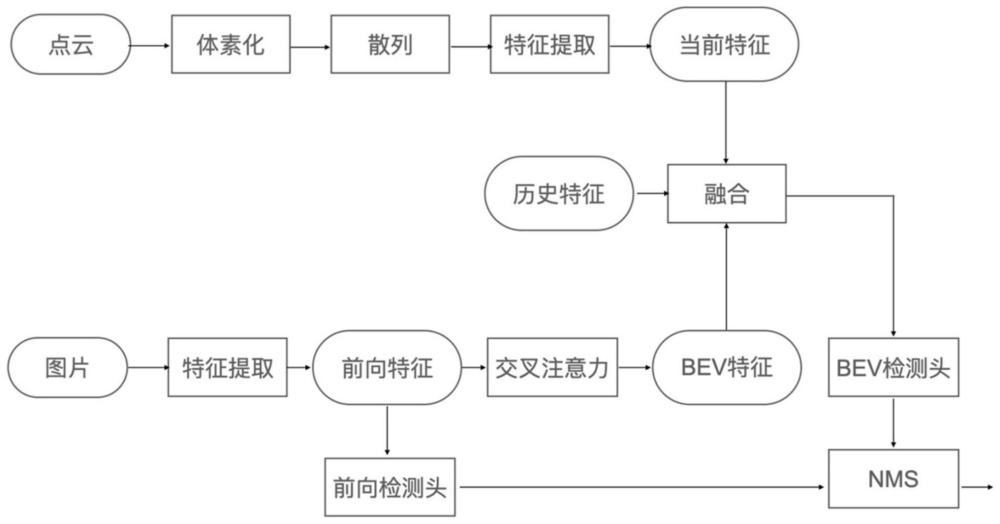
0、
背景技术:
1、自动驾驶技术目前正在飞速发展,感知作为自动驾驶中感知环境信息的关键技术,在自动驾驶中起到了至关重要的作用。障碍物检测是感知技术中最基础,最重要的部分。准确检测出动态、静态障碍物,才能为下游提供可靠的输出,让自动驾驶车辆完成正确的驾驶决策,保证自动驾驶车辆的安全性。
2、当前的障碍物检测技术,主要围绕bev(鸟瞰图bird's eye view)视角,利用视觉信息进行检测。主要问题在于:
3、1.缺少多模态信息的融合,激光点云具有精确的3d信息,而相机生成的图片具有比较好的语义信息,二者结合可以互相弥补各自的不足,提升检测精度的上限。
4、2.单一视角,目前的检测方法集中在正视视角或者bev视角,并没有对多视角进行融合,无法发挥二者的检测优势。
5、3.时序信息结合多模态有所欠缺,时序信息,需要有效结合不同模态数据的特点,在特征层面,将对应时间序列中的多模态信息进行融合,然后再对时序信息进行整体的融合。可以保证不同模态的时序一致性。
6、bev(鸟瞰图bird's eye view)感知是一种将三维场景转化为水平二维平面的方法,在二维和三维物体检测、感知地图生成、可行走区域的检测等方面取得了广泛应用。
7、激光雷达(lidar)点云数据,是由三维激光雷达设备扫描得到的空间点的数据集,每一个点都包含了三维坐标信息,即x、y、z三个元素,有的还包含颜色信息、反射强度信息、回波次数信息等。
8、体素化(voxelization)是将物体的几何形式表示转换成最接近该物体的体素表示形式,产生体数据,包含模型的表面信息和内部属性。
9、经过检索,检索到以下相关专利。
10、相关检索结果1:中国专利申请公布号、cn106908783a,名称、基于多传感器信息融合的障碍物检测方法,该专利采用的是视觉摄像头和毫米波雷达的融合,并非采用视觉摄像头和激光雷达的融合,激光雷达相比于毫米波雷达具有更强的3d空间感知能力、更加准确的高程信息以及更加密集的点云。因此用毫米波雷达与摄像头融合的障碍物检测方案精度相对不高。
11、相关检索结果2:中国专利申请公布号、cn111583337b,名称、一种基于多传感器融合的全方位障碍物检测方法,该专利需要用到空间配准完成图像特征和点云特征的空间位置的对应,并非直接借助了相机的内外参,并使用空间交叉注意力机制,将视觉特征投射到俯视视角,完成和点云的对应,并在对齐后,进行进一步融合。该专利方法需要考虑空间配准的准确性,没有利用神经网络去学习不同模态特征之间的关联关系,鲁棒性相对较差。
12、相关检索结果3:中国专利申请公布号、cn111352112b,名称、基于视觉、激光雷达和毫米波雷达的目标检测方法,该专利的候选区域仅由激光雷达和毫米波雷达生成,没有视觉模块的参与;而视觉模块在针对物体存在性上具有其独特的优势。该专利不属于特征层的融合,没有直接融合不同模态在同一视角下的特征图、然后进行检测,没有充分发挥视觉和激光点云的优势,不具有召回更多的障碍物的能力。同时这篇专利没有利用时序信息,而时序信息是提高检测结果稳定性的关键因素。
13、本发明针对缺少多模态信息融合、单一视角、时序信息结合多模态有所欠缺的技术问题,对自动驾驶障碍物检测方法进行了技术改进。
技术实现思路
0、
技术实现要素:
1、本发明的目的是,提供一种多视角融合、多模态特征层融合、历史帧与当前帧融合的自动驾驶障碍物检测方法。
2、为实现上述目的,本发明采取的技术方案是一种基于多视角和多传感器时空融合的自动驾驶障碍物检测方法,包括以下步骤:
3、s1、通过视觉摄像头拍摄图像,对当前帧图片进行特征提取,生成图像正视视角特征图、检出正视候选障碍物、构建出图像俯视视角特征图;
4、s2、通过激光雷达获取激光雷达点云数据,将点云进行体素化处理并进行特征提取,生成点云俯视视角2d特征图;
5、s3、利用卷积神经网络将点云俯视视角2d特征图与图像俯视视角特征图进行融合,生成当前帧俯视视角融合特征图;
6、s4、利用循环神经网络将当前帧俯视视角融合特征图与时序对齐后的上一帧俯视视角融合特征图进行融合,生成多模态时序融合特征图;
7、s5、利用多模态时序融合特征图,基于俯视视角检出俯视候选障碍物;
8、s6、将正视候选障碍物和俯视候选障碍物在3d空间中进行非极大抑制处理,生成最终的障碍物检测结果。
9、优选地,步骤s1具体包括以下子步骤:
10、s11、第一处理支路在当前帧,对输入图片进行特征提取,生成图像正视视角特征图;
11、s12、第一处理支路将图像正视视角特征图接入正视障碍物检测器,基于正视视角检出正视候选障碍物;
12、s13、第一处理支路从输入图片俯视空间固定位置出发,利用相机内外参投射到对应的图像特征图上,采样相应图像正视视角特征图的图像特征,利用空间交叉注意力机制构建出图像俯视视角特征图。
13、优选地,步骤s2具体包括以下子步骤:
14、s21、第二处理支路利用激光雷达的外参矩阵,将激光雷达点云数据从激光雷达坐标系转到车载坐标系;
15、s22、第二处理支路将点云进行体素化处理,生成体素块集合,每个体素块存放体素块中点云的信息;
16、s23、第二处理支路将体素化后的点云,进行特征编码,每个体素块从3d坐标x、y、z、反射强度、时间戳的5维特征编码到11维特征,增加的维度信息包括单个点与几何中心,聚类中心的关系信息;
17、s24、第二处理支路将编码后的体素块集合,通过多层感知机进行特征提取,生成体素化3d特征;
18、s25、第二处理支路将体素化3d特征通过池化,将高度方向特征压到一个平面,将体素化3d特征压扁到俯视视角的2维平面特征,生成点云俯视视角2d特征图。
19、优选地,步骤s22:体素为空间立方格子,体素化的过程为将点云的空间分布离散化成等大小的空间立方格子。
20、优选地,步骤s3:采用1x1大小的卷积核对齐卷积神经网络将点云俯视视角2d特征图与图像俯视视角特征图两个模态的特征通道数,然后把卷积神经网络将点云俯视视角2d特征图与图像俯视视角特征图两个特征图连接在一起,随后利用3x3的卷积进行特征的进一步融合。
21、优选地,步骤s4:利用车辆的位姿,构建从上一帧到当前帧的变换矩阵,利用双线性插值法在上一帧俯视视角融合特征图上进行采样,变换采样点的位置,实现相对当前帧俯视视角融合特征图的时序对齐,生成时序对齐后的上一帧俯视视角融合特征图。
22、优选地,步骤s5:通过transformer神经网络解码器进行解码,再通过俯视障碍物检测头,基于俯视视角检出俯视候选障碍物。
23、优选地,步骤s6非极大抑制处理包括以下子步骤:
24、s61、按照每个3d检测框的置信度进行排序;
25、s62、从高到低遍历,分值低于当前3d检测框的依次与当前框进行iou匹配,超过阈值的丢弃;
26、s63、直到遍历完所有3d检测框。
27、优选地,上述的一种基于多视角和多传感器时空融合的自动驾驶障碍物检测方法:
28、所述正视障碍物检测器用于对特征图进行下采样,生成特征图,对每个栅格位置分别进行类别的预测和3d box的预测,其中3d box的预测包括了x,y,z,长宽高以及在俯视视角下的方向角;
29、所述空间交叉注意力机制,是通过3d空间中固定位置,利用相机的外参内参,投射到图像的固定坐标位置,然后利用注意力机制,生成特定的3d空间中的图像特征;
30、所述多层感知机由多层全连接神经网络,加上激活层提供非线性拟合能力;
31、所述俯视障碍物检测头是一种端到端的检测器,通过初始化特定的query,利用transformer神经网络的注意力机制,生成每个query对应的特征,再将特征连接到分类器和3d box回归器上,完成物体检测。
32、本发明一种基于多视角和多传感器时空融合的自动驾驶障碍物检测方法有益效果如下:1、多视角的融合,基于纯视觉的前向视角的检测结果、与基于俯视视角(bev)上的检测结果的后融合,前向视角对远距离物体的存在性检测具有一定的优势,并对高程信息敏感的障碍物(交通锥桶)更加友好,俯视视角对近距离物体在多个相机范围的拼接融合更加自然,并且俯视视角与激光点云的融合更加直接;2、多模态的特征层融合,在特征层融合可以提升多模态信息互补的效果,可以改善多模态数据异构问题以及降低融合多模态数据对齐要求较高的问题;3、历史帧与当前帧的融合,可以提升检测结果的稳定性。
- 还没有人留言评论。精彩留言会获得点赞!