机器人导航规划方法及存储介质和终端设备与流程
本发明涉及控制领域,特别是涉及一种机器人的导航技术。
背景技术:
1、当前机器人技术在各行各业都有着广泛的应用,例如送餐机器人、安防机器人等。这些场景中,机器人可能会面对复杂的地形环境,遇到人和车辆等各种障碍物,给导航带来极大挑战。所以应运而生了机器人导航技术,即根据地图和环境信息给出机器人的移动方向和速度大小,引导机器人朝着目标点运动,同时能够防止碰到障碍物。
2、传统算法,如专利申请cn107436148b公开了根据全局路径、局部代价地图、障碍物的运动状态信息和估计的运动轨迹,来计算机器人的导航策略,提高避障能力,没有使用深度学习算法,其导航响应速度和准确度都不太高。
3、随着深度学习技术的发展,已应用于机器人导航中,如专利申请cn115585813a公开了一种基于注意力机制的深度强化学习机器人导航方法,来提高陌生且复杂环境中进行导航能力;专利申请cn112882469b公开了将全局路径作为初始路径,并在该路径中选择一个位于机器人和目标点间的路点作为机器人的临时目标,用于训练基于深度强化学习的导航模型,能够提高机器人的导航效率。
4、这些方法取得了不错的效果,但仍然至少存在以下两个问题:1)为应对环境信息的更新或者障碍物的出现,导航系统需要进行全局路径的重规划,但是现有重规划的时机都是通过设置规则来选择的,可能会出现过于频繁或者不够及时的问题;2)在局部路径的规划中,忽略了移动障碍物之间的位置和速度关系,导致在行人、障碍物较多的拥挤环境中性能较差。
5、因此,如何进一步提高机器人的导航效果,改善上述至少一个问题,是本领域亟待解决的核心要点。
技术实现思路
1、为解决上述技术问题,本发明提供一种机器人导航规划方法,包括:
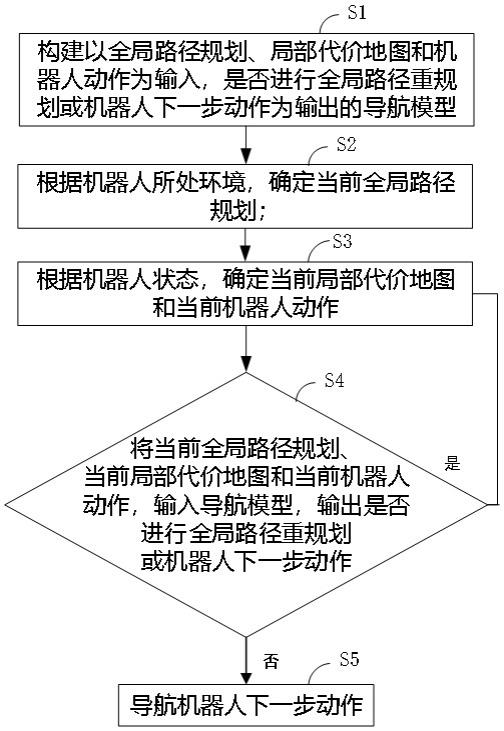
2、s1:构建以全局路径规划、局部代价地图和机器人动作为输入,是否进行全局路径重规划或机器人下一步动作为输出的导航模型;
3、s2:根据机器人所处环境,确定当前全局路径规划;
4、s3:根据机器人状态,确定当前局部代价地图和当前机器人动作;
5、s4:将当前全局路径规划、当前局部代价地图和当前机器人动作,输入导航模型,输出是否进行全局路径重规划或机器人下一步动作;
6、s5:若输出为进行全局路径重规划,则返回步骤s2;若输出为机器人下一步动作,则根据输出结果导航机器人下一步动作;
7、导航模型,包括输入层、特征提取层、拼接层和输出层;
8、输入层,以状态空间state=[keypoints, costmap, velocity]为输入;其中keypoints表示由当前位置到m个路径点的坐标向量,为全局路径规划;costmap表示局部代价地图;velocity表示机器人速度;m是后续路径点的个数;
9、特征提取层,包括三部分;第一部分以状态空间state中的机器人速度为输入,包括两个全连接层,提取得到第一特征;第二部分以状态空间state中的m个路径点的坐标向量为输入,包括两个全连接层,提取得到第二特征;第三部分以状态空间state中的局部代价地图为输入,包括一个深度卷积网络,和一个全连接层,提取得到第三特征;
10、拼接层,将第一特征、第二特征和第三特征进行拼接,再将拼接结果输入到一个全连接层中;
11、输出层,以动作空间action=[replan, vs]为输出;其中,replan表示是否进行全局路径重规划, vs表示下一步动作,包括速度大小和方向。
12、进一步地,vs包括若干个离散动作,用速度和方向表示。
13、进一步地,vs由a*b个离散动作组成;其中a为速度数量,a个速度在 (0, v_max ]之间呈平均间隔;b为方向数量,b个方向均匀分布在 [-turn_max, turn_max)之间;其中v_max是机器人的最大速度,turn_max是机器人的最大角度;动作空间总共有a*b+1维。
14、进一步地,选择导航模型输出得分最高的动作确定是否进行全局路径重规划或下一步动作。
15、进一步地,采用深度强化学习方法对导航模型进行训练,训练的奖励函数表示为:
16、r = r_step + r_collision + r_safety + r_waypoint
17、其中,r_step表示较小的负的步长得分;
18、r_collision表示对碰撞的惩罚得分;
19、r_safety表示避免碰撞的安全得分;
20、r_waypoint表示靠近目标的奖励得分。
21、进一步地,骤s2,包括:
22、s21:根据机器人所处环境,确定全局路径点;
23、s22:将全局路径点做路径规划,确定从当前点到目标点的可行路径。
24、进一步地,步骤s3,包括:
25、s31:机器人感应周围环境的点云数据;
26、s32:根据点云数据,分别确定周围障碍物的位置坐标、x轴速度和y轴速度,以分别得到局部障碍物位置代价图、x轴速度代价图和y轴速度代价图;
27、s33:将局部障碍物位置代价图、x轴速度代价图和y轴速度代价图进行拼接,得到局部代价地图。
28、进一步地,步骤s32,包括:
29、根据点云数据,计算周围障碍物的位置坐标,并填充至栅格地图中,得到局部障碍物位置代价图;
30、对点云数据进行聚类,估计周围移动障碍物的速度,分别投射到x轴和y轴上,并将其值填充至地图中障碍物的位置上,得到x轴速度代价图和y轴速度代价图。
31、另一方面,本发明还提供一种计算机存储介质,存储有可执行程序代码;所述可执行程序代码,用于执行上述任意的机器人导航规划方法。
32、另一方面,本发明还提供一种终端设备,包括存储器和处理器;所述存储器存储有可被处理器执行的程序代码;所述程序代码用于执行上述任意的机器人导航规划方法。
33、本发明提供一种机器人导航规划方法及存储介质和终端设备,针对导航过程中全局信息的更新问题,将全局路径信息与重规划动作融合到深度强化学习的模型构建训练中,能够自动判断是否需要进行全局路径重规划,并给出机器人下一步的运动导航信息。针对局部环境中动态障碍物的问题,基于网络模型,如深度卷积神经网络来处理机器人周围移动障碍物的位置、速度信息,能够更好挖掘移动障碍物之间的空间和移动关系,能进一步提高导航规划的及时性和准确性。
技术特征:
1.一种机器人导航规划方法,其特征在于,包括:
2.根据权利要求1所述的机器人导航规划方法,其特征在于,vs包括若干个离散动作,用速度和方向表示。
3.根据权利要求2所述的机器人导航规划方法,其特征在于,vs由a*b个离散动作组成;其中a为速度数量,a个速度在 (0, v_max ]之间呈平均间隔;b为方向数量,b个方向均匀分布在 [-turn_max, turn_max)之间;其中v_max是机器人的最大速度,turn_max是机器人的最大角度;动作空间总共有a*b+1维。
4.根据权利要求3所述的机器人导航规划方法,其特征在于,选择导航模型输出得分最高的动作确定是否进行全局路径重规划或下一步动作。
5.根据权利要求4所述的机器人导航规划方法,其特征在于,采用深度强化学习方法对导航模型进行训练,训练的奖励函数表示为:
6.根据权利要求1所述的机器人导航规划方法,其特征在于,步骤s2,包括:
7.根据权利要求1-6任意一项所述的机器人导航规划方法,其特征在于,步骤s3,包括:
8.根据权利要求7所述的机器人导航规划方法,其特征在于,步骤s32,包括:
9.一种计算机存储介质,其特征在于,存储有可执行程序代码;所述可执行程序代码,用于执行权利要求1-8任意一项所述的机器人导航规划方法。
10.一种终端设备,其特征在于,包括存储器和处理器;所述存储器存储有可被处理器执行的程序代码;所述程序代码用于执行权利要求1-8任意一项所述的机器人导航规划方法。
技术总结
本发明涉及机器人导航规划方法及存储介质和终端设备,包括:构建以全局路径规划、局部代价地图和机器人动作为输入,是否进行全局路径重规划或机器人下一步动作为输出的导航模型;根据机器人所处环境,确定当前全局路径规划;根据机器人状态,确定当前局部代价地图和当前机器人动作;将当前全局路径规划、当前局部代价地图和当前机器人动作,输入导航模型,输出是否进行全局路径重规划或机器人下一步动作;若输出为进行全局路径重规划,则返回;若输出为机器人下一步动作,则根据输出结果导航机器人下一步动作。
技术研发人员:陈俊逸,汤继敏
受保护的技术使用者:长沙小钴科技有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!