基于共点声强的小尺寸阵列深度学习声源定位方法
本发明属于音频信号处理领域,特别涉及了一种基于共点声强的小尺寸阵列深度学习声源定位方法。
背景技术:
1、声源定位技术广泛应用于音视频会议系统、人机语音交互以及助听器等领域。在实际应用中,由于人们对产品轻便美观的要求、场地大小等因素,传声器阵列的尺寸受到限制,因此小尺寸阵列下的声源定位技术研究有着现实意义和实用价值。传统的声源定位方法包括广义互相关函数法和可控波束形成法等。然而,由于混响和噪声的存在,传统方法在小尺寸阵列下的精度和可靠性存在局限。
2、近年来,深度学习技术在声源定位领域取得了许多研究进展。基于深度学习的声源定位方法通过训练神经网络模型,构建输入特征与声源位置之间的复杂映射关系,从而有效提高了声源定位的性能(见文献[1]grumiaux p,s,girin l,et al.a survey ofsound source localization with deep learning methods.journal of theacoustical society of america,2022,152(1):107-151.)。本发明提出了一种基于共点声强的深度学习声源定位方法,可以在小尺寸阵列下有效完成定位任务。同时,与现有方法使用的非共点声强特征(见文献[2]liu n,chen h,songgong k,et al.deep learningassisted sound source localization using two orthogonal first-orderdifferential microphone arrays.journal of the acoustical society of america,2021,149(2):1069-1084.)相比,本发明中共点声强特征的声压和振速位于同一点,声强计算更加准确,从而提高了定位精度。
技术实现思路
1、本发明针对现有技术中的限制和不足,提供一种基于共点声强的小尺寸阵列深度学习声源定位方法,对混响和噪声具有良好的鲁棒性。相较于现有基于非共点声强的深度学习定位方法,本方法使用共点声强特征,表现出更好的定位性能。
2、为了实现上述技术目的,本发明的技术方案为:
3、一种基于共点声强的小尺寸阵列深度学习声源定位方法,包括以下步骤:
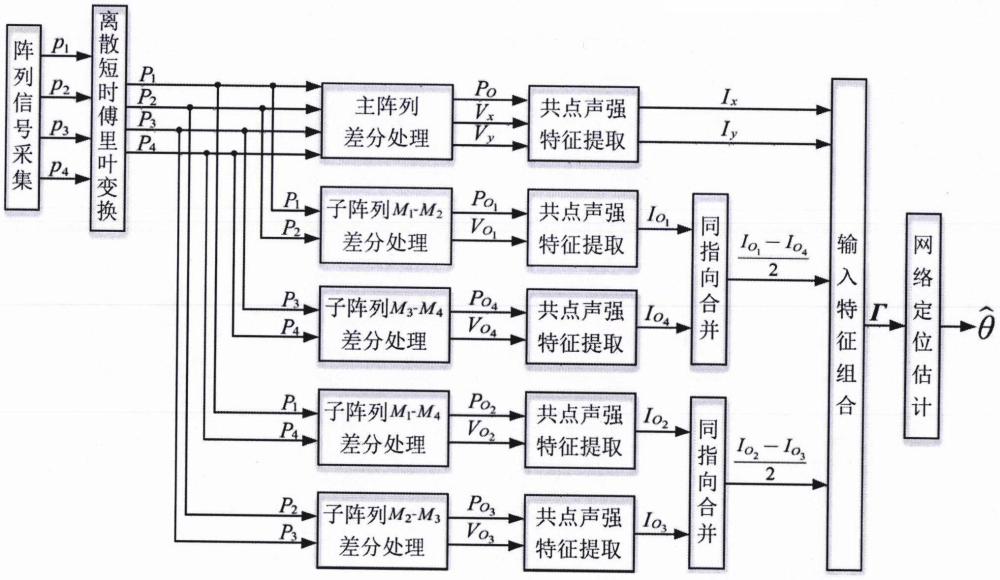
4、(1)在正交一阶差分阵列的基础上,将主阵列分解为四个二阵元子阵列,分别计算主阵列和子阵列的共点声强,并根据声强指向对子阵列声强进行合并;
5、(2)将所有共点声强特征组合,作为网络的输入特征,按照一定比例生成网络的训练集、验证集和测试集;
6、(3)搭建卷积神经网络,设置网络的结构参数和超参数,将训练集和验证集数据分批次输入网络进行训练,直到达到最大训练时期数;
7、(4)用已训练好的网络模型对测试集样本进行预测,得到声源方位角估计结果。
8、进一步地,阵列由两个相互正交的一阶差分阵列构成,阵列阵元分别记为m1、m2、m3、m4。
9、进一步地,声强包含声源方位的信息,将声强特征作为网络输入,可有效用于声源方位的估计;相较于非共点声强,共点声强的声压和振速位于同一点,从而使得声强的计算更加准确。
10、进一步地,在步骤(2)中,共点声强特征的提取步骤为:对传声器阵列采集的信号进行离散短时傅里叶变换,得到各阵元每个时频点的声压pi(t,k),其中i为阵元索引,t为第t个时间帧,k为第k个频点;根据各阵元声压可得到阵列中心点声压为:
11、
12、根据声压可得到x轴和y轴上振速的时频域表达式为:
13、
14、
15、上式中,为虚数单位,ρ为空气密度,d为阵列尺寸。根据式(1)、(2)和(3)可得到x轴和y轴的声强为:
16、
17、
18、上式中,re{·}表示取实部,im{·}表示取虚部,[·]*表示复数的共轭运算。除此之外,将阵列分解为四个二元子阵列,分别为子阵列m1-m2、m2-m3、m3-m4和m4-m1。每个子阵列的两个阵元构成了各自方向上的一阶差分阵列,则四个子阵列求得的声强分别为:
19、
20、
21、
22、
23、注意到所求声强和分别指向5π/4方向和π/4方向,二者实际为同一方向声强,即声强指向一致,可以合并为同一声强特征,作为网络输入特征的一部分。同理,声强和也可以合并,作为输入特征的一部分。记接收信号离散时频域的总时间帧数和总频点数分别为n和f,则x轴和y轴声强和子阵列的合并后声强共同组成了一个4通道的共点声强输入特征每个通道对应的特征为:γ(:,:,1)=ix,γ(:,:,2)=iy,
24、在步骤(3)中,卷积神经网络由输入层、2个卷积层、2个全连接层和输出层组成。每个卷积层设置64个3×3卷积核,每个全连接层包含512个节点。卷积层和全连接层均采用relu函数作为激活函数。卷积层后添加批归一化层,全连接层后添加dropout层。网络输出层设置q个节点,对应声源位置的类别数,并使用softmax函数作为激活函数,用于实现声源分类定位。
25、采用上述技术方案带来的有益效果:
26、相比传统方法,本发明结合深度学习技术完成声源定位,对混响和噪声具有更好的鲁棒性。与现有基于非共点声强特征的深度学习定位方法相比,本方法使用共点声强特征,表现出更优的定位性能。具体而言:
27、(1)将声源定位问题转换为分类问题,通过训练网络模型从传声器阵列接收到的信号特征中提取声源位置信息,以端到端的方式完成声源定位。相比传统方法,本发明所提方法对混响和噪声具有更好的鲁棒性。
28、(2)本发明中利用差分估计声强来完成声源定位,因此在小尺寸阵列的情况下,本发明所提定位方法能够较好地完成定位任务。
29、(3)共点声强特征相对于非共点声强特征,其声压和振速位于同一点,因此声强的计算更加准确。在信噪比较低,混响时间较长的环境下,共点声强特征表现出更优的定位性能。
技术特征:
1.一种基于共点声强的小尺寸阵列深度学习声源定位方法,其特征在于,包括以下步骤:
2.根据权利要求1所述基于共点声强的小尺寸阵列深度学习声源定位方法,其特征在于:阵列由两个相互正交的一阶差分阵列构成,阵列阵元分别记为m1、m2、m3、m4。
3.根据权利要求1所述基于共点声强的小尺寸阵列深度学习声源定位方法,其特征在于:声强包含声源方位的信息,将声强特征作为网络输入,可有效用于声源方位的估计;相较于非共点声强,共点声强的声压和振速位于同一点,从而使得声强的计算更加准确。
4.根据权利要求1所述基于共点声强的小尺寸阵列深度学习声源定位方法,其特征在于:在步骤(1)中,共点声强特征的提取步骤为:对传声器阵列采集的信号进行离散短时傅里叶变换,得到各阵元每个时频点的声压pi(t,k),其中i为阵元索引,t为第t个时间帧,k为第k个频点;根据各阵元声压可得到阵列中心点声压为:
5.根据权利要求1所述基于共点声强的小尺寸阵列深度学习声源定位方法,其特征在于:在步骤(3)中,卷积神经网络由输入层、2个卷积层、2个全连接层和输出层组成,每个卷积层设置64个3×3卷积核,每个全连接层包含512个节点;卷积层和全连接层均采用relu函数作为激活函数;卷积层后添加批归一化层,全连接层后添加dropout层;网络输出层设置q个节点,对应声源位置的类别数,并使用softmax函数作为激活函数,用于实现声源分类定位。
技术总结
本发明公开了一种基于共点声强的小尺寸阵列深度学习声源定位方法。首先,在正交一阶差分阵列的基础上,将主阵列分解为四个二阵元子阵列,分别计算主阵列和子阵列的共点声强,并根据声强指向对子阵列声强进行合并;其次,将所有共点声强特征组合,作为网络的输入特征,按照一定比例生成网络的训练集、验证集和测试集;然后,搭建卷积神经网络,设置网络的结构参数和超参数,将训练集和验证集数据分批次输入网络进行训练,直到达到最大训练时期数;最后,利用已训练好的网络模型对测试集样本进行预测,得到声源方位角估计结果。与现有技术相比,本发明所提的共点声强特征在信噪比较低,混响时间较长的情况下表现出更好的鲁棒性,定位性能更好。
技术研发人员:史文旭,陈华伟
受保护的技术使用者:南京航空航天大学
技术研发日:
技术公布日:2024/3/11
- 还没有人留言评论。精彩留言会获得点赞!