一种基于VAE模型数据增强算法的电池RUL预测方法与流程
本发明涉及电池和电化学,尤其是一种基于vae模型数据增强算法的电池rul预测方法。
背景技术:
1、电化学阻抗谱(electrochemical impedance spectroscopy,eis)是一种用于表征电池内部电化学过程的测试方法。电池的阻抗谱eis数据,由实部阻抗和虚部阻抗组成。
2、电池rul(remaining useful life)即电池的剩余寿命,是评估电池健康状态的一个重要指标。电池rul反映了电池从现在时刻起,在正常使用情况下还可以继续使用的预期时间或循环次数。
3、测试电池阻抗谱数据需要使用专业的仪器设备,测试条件严苛,成本较高,导致了测试数据的数量较少。在已有的测试数据基础上,使用数据增强方法来增加电池阻抗谱数据的数量,是一个值得探索的路径,这可以为模型提供更多数据,增强模型的泛化能力和鲁棒性,避免模型出现过拟合现象。
4、变分自编码器(variational autoencoder,vae),是一种生成模型,可以学习训练数据的潜在分布,可以通过对潜在分布中的采样来生成新的样本,同时保留原始数据的特征。这种数据增强方法可以增加训练样本的多样性,帮助提高模型的泛化能力。
5、具体而言,vae通过在潜在分布进行采样,然后利用解码器将采样的潜在向量转换成新的数据样本。由于vae的编码器将原始数据映射到潜在分布中的高斯分布上,因此可以通过对该高斯分布进行采样来获得潜在向量。采样后的潜在向量再经过解码器,就可以生成与原始数据分布相似的新数据。
6、在验证模型效果时,验证集不能使用增强之后的数据。
7、电池阻抗谱的真实测试数据和增强数据都是覆盖几十个频率范围,维度较高,存在冗余信息,会导致模型精度降低,因此可以使用主成分分析(principle componentanalysis,pca)对阻抗谱数据进行降维,提炼出主要的信息,降低数据的噪声。
8、多层感知机(multi layer perceptron, mlp)模型,可以将输入数据映射到输出数据,它由输入层、输出层以及多个中间的隐藏层组成。网络中的节点按层连接,中间层的节点对上一层的输入进行加权和,然后通过激活函数进行非线性映射生成输出。
9、可以将eis数据作为输入数据,rul作为输出数据,通过mlp模型的多层非线性变换提取eis的特征,预测电池rul。本发明预测的电池rul为电池剩余循环次数。
10、综上,数据增强方法可以增加阻抗谱的数据量,提升模型的泛化能力和鲁棒性;pca可以去除eis数据的噪声;mlp模型可以学习eis和rul之间的非线性映射关系。
技术实现思路
1、为了实现上述目的,本发明提供一种基于vae模型数据增强算法的电池rul预测方法,在pca-mlp模型上,对比分析了单独使用电池eis数据和同时使用eis及其增强数据的预测rul的效果,并且使用vae模型对eis数据进行增强,基于eis原始数据和增强数据,共同预测电池rul。
2、本发明解决其技术问题所采用的技术方案是:
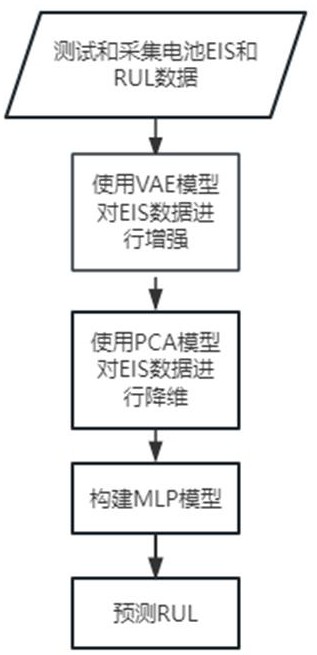
3、一种基于vae模型数据增强算法的电池rul预测方法,包括如下步骤:
4、步骤s1.测试并采集电池eis和rul数据:
5、步骤s2.使用vae模型对eis数据进行增强:将eis数据作为输入数据,通过vae模型对eis本身进行预测;所述vae模型通过学习数据分布并随机采样,生成类似但不同的新数据,并通过训练vae模型时的目标函数来实现生成的新数据与原始数据集的分布相似;采用最小化重构误差和潜在向量的kl散度来训练vae模型,确保生成的新数据与原始数据集分布相似,从而保证生成的新数据质量;
6、步骤s3.使用pca模型对eis输入数据进行主成分提取:将电池的eis数据作为输入数据,计算eis数据的协方差矩阵,求解协方差矩阵的特征值和特征向量,按特征值大小排序,选择主要的前10个特征向量,这些特征向量就是主成分,将原始eis数据投影到这10个主成分上得到新的10维特征表示,即降维到10维;
7、步骤s4.构建mlp模型:将pca提取到的电池eis数据的主要成分数据,作为mlp模型的输入数据,通过多个全连接层,提取输入数据的特征;
8、步骤s5.预测电池剩余循环次数即rul:mlp模型的输出层是一个线性回归层,预测值是电池剩余循环次数即rul,激活函数为linear函数。
9、进一步的,所述步骤s1,具体包括如下步骤:步骤s11.eis数据采集:使用电化学工作站配置频率扫描测试,在不同频率点测试电池的阻抗值和相位,记录频率响应数据,主要是测试阻抗的实部数据和虚部数据。
10、步骤s12.rul数据采集:进行充放电循环测试,并记录充放电循环次数。
11、步骤s13.匹配采集数据:同一组电池同时进行eis和循环充放电测试,匹配对应电池的eis数据和rul水平。
12、进一步的,在步骤s11中,采集eis配置频率范围为10-2hz至105hz,优选60个频率值作为样例。
13、进一步的,在步骤s2中,所述vae模型的网络结构包含编码器、采样器、解码器。所述编码器用于将输入数据编码成潜在空间的分布;所述采样器从编码器输出的分布中采样,得到潜在空间的样本点;所述解码器将采样得到的潜在表示映射回数据空间。
14、进一步的,在步骤s2中,所述vae模型中的重构误差采用均方误差;整个模型的损失函数为均方误差与kl散度误差之和。
15、进一步的,在步骤s2中,所述输入数据为120维度,映射到维度为80的编码器;所述编码器分别映射到高斯分布的均值和方差,维度均为40;对高斯分布进行采样,加入服从n(0,0.01)分布的随机扰动,生成40维度的潜在变量;所述潜在变量映射到解码器,维度为80;所述解码器映射到输出变量,维度为120。
16、进一步的,在步骤s3中,所述eis数据包括真实测试的eis数据和数据增强之后的eis数据,分别通过pca模型计算主成分。
17、进一步的,在步骤s4中,所述mlp结构包含两层全连接层和一个输出层,激活函数均为relu函数,全连接层的神经元个数均为32个,输出层的神经元个数为1个。
18、进一步的,在步骤s5中,所述mlp模型的损失函数为均方误差,优化器为rmsprop,评估指标为平均绝对误差,即目标值和预测值之差的绝对值之和。
19、本发明有益效果是
20、本发明完全使用模型进行数据增强,无需人工参与,避免了人工因素可能导致的偏差;采用的vae模型是一种无监督学习算法,它不需要标记数据就能学习;vae模型的复杂度不高,容易训练和预测;vae模型可以学习到数据中的潜在变量,因此可以生成全新的样本,而不是简单地重复输入数据;在增强数据中,只对输入数据eis进行预测,不对预测目标进行预测,减少了预测误差发生的概率。
21、本发明使用vae模型对真实eis测试数据进行增强,增加了训练数据量,提升了模型的泛化能力和鲁棒性,避免了模型过拟合;在pca-mlp模型上对比测试了加入eis增强数据之前和之后预测rul的效果,加入eis增强数据之后模型精度预测效果明显提升。本发明提出的eis数据增强方法可以推广到其它的模型当中使用。
- 还没有人留言评论。精彩留言会获得点赞!