基于改进人工势场的多水下机器人协作方法
本发明属于水下机器人路径规划领域,具体说是一种基于改进人工势场的多水下机器人协作方法。
背景技术:
1、随着人工智能理论的不断发展,机器人控制技术日益成熟,并且在不同领域得到广泛应用。机器人所面临的任务也愈加复杂,所处环境从单个机器人转变为多机器人、动态环境。因此,近年来对复杂系统中多机器人协作控制技术的研究得到了学术界和工业界的广泛关注。
2、在多机器人系统中,需要使用路径规划方法帮助机器人避开工作区之间的障碍物,移动机器人在移动到相应目标时必须调整自己的运动方向,避免机器人碰撞。
3、路径规划分为基于局部区域信息的局部路径规划和基于完整区域信息的全局路径规划。由于多机器人环境对灵活性和实时性的要求,局部路径规划更具实用性。人工势场法是一种著名的局部路径规划方法,已被证明在单机器人任务中是有效的。然而,当障碍物和机器人的数量增加,需要机器人协作时,算法的有效性就变得更加难以维持。在这种情况下,需要一种更具适应性的方法。
4、近年来,强化学习在机器人、自动驾驶引用、路径规划等方面取得了显著的进展,其适应性强。大多数强化学习方法关注的是环境中单个个体的行为。在现实生活中,多机器人学习如何在不断变化的环境中合作和竞争是很常见的,机器人不仅要学习如何适应不断变化的环境,还要学习如何与其他机器人协作完成任务。这就需要结合多智能体的强化学习方法帮助机器人更好的完成任务。
技术实现思路
1、本发明目的是提供一种基于改进人工势场的多水下机器人协作方法,对人工势场方法进行改进,并且在地图建立的势场环境中加入多智能体强化学习算法来解决多目标点多障碍物路径规划问题。
2、本发明为实现上述目的所采用的技术方案是:
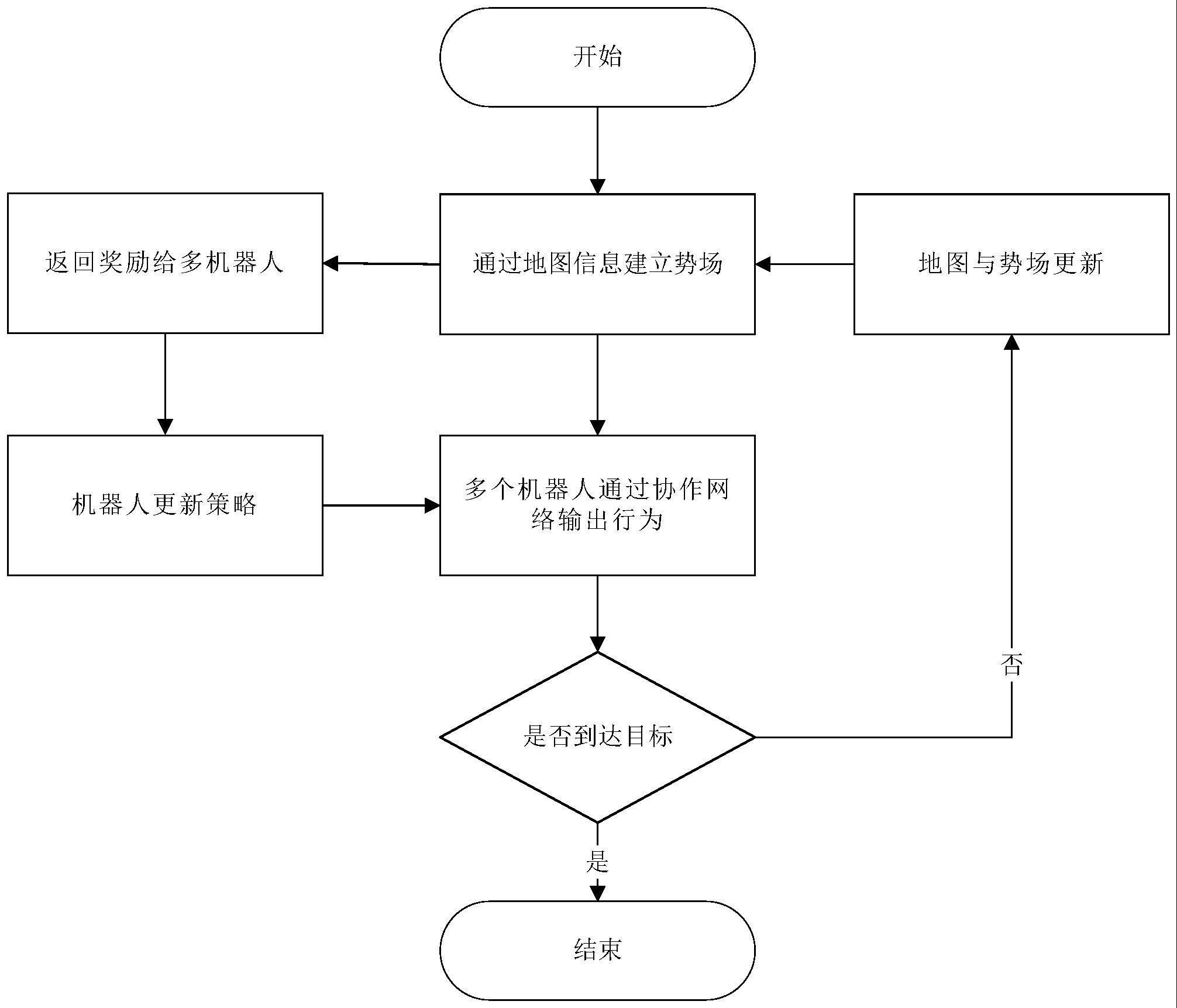
3、基于改进人工势场的多水下机器人协作方法,包括以下步骤:
4、1)根据水下机器人的位置构建改进人工势场;
5、2)基于注意力机制的强化学习在改进人工势场环境中对水下机器人的运动策略进行训练;
6、3)多个水下机器人基于训练好的运动策略进行协作运动,并判断是否到达目标位置,如果到达,则结束运动;否则,更新人工势场,返回步骤1)。
7、所述改进人工势场为障碍物和目标点对水下机器人的引力场、障碍物对水下机器人的斥力场以及水下机器人的域场三场叠加。
8、所述障碍物和目标点对水下机器人的引力场uatt(q)为:
9、
10、其中,katt为障碍物或目标点的引力系数,q为水下机器人位置坐标,qg为障碍物或目标点所在坐标。
11、所述障碍物对水下机器人的斥力场urep(q)为:
12、
13、其中,krep为障碍物的排斥力系数,q-q0为水下机器人当前位置坐标与障碍物距离,p0为障碍物的作用范围。
14、所述水下机器人的域场ustr(q)为:
15、
16、其中,kstr为域场系数,q-qg为当前水下机器人坐标与目标点距离,ps为范围场的作用范围。
17、所述步骤2),包括以下步骤:
18、2.1)构建运动策略的奖励值;
19、2.2)使用注意力机制的强化学习得到水下机器人在改进人工势场中的实时行为和状态;
20、2.3)利用水下机器人的实时行为和状态更新奖励值;
21、2.4)循环步骤2.2)~步骤2.3),使用策略梯度下降方法使每次更新的奖励值大于上一次,输出获得最大期望的奖励值所对应的行为作为水下机器人的运动策略。
22、所述奖励值r为:
23、r=w1+w2+w3
24、其中,w1为水下机器人碰撞的惩罚,w2为水下机器人到达目标位置的奖励,w3为水下机器人受到人工势场的奖励,w3=(pt-pt-1),pt为水下机器人移动前的势场,pt-1为水下机器人移动后的势场。
25、所述步骤2.2)包括以下步骤:
26、2.2.1)将每个水下机器人在人工势场某一时刻的观测值oi经过全连接层到一个隐特征层hi,将hi通过lstm神经网络得到水下机器人的当前状态;
27、2.2.2)通过水下机器人的状态计算不同水下机器人之间的关联程度,进而得到水下机器人的实时行为;
28、2.2.3)计算水下机器人的实时状态。
29、所述关联程度wj为:
30、
31、其中,wk和wq为关联矩阵,ei和ej为水下机器人i和j的当前状态;
32、所述水下机器人的实时行为ai为:
33、ai=π(hi,xi)
34、π为当前水下机器人采用的策略。
35、所述水下机器人的实时状态xi为:
36、xi=∑j≠i wjhj。
37、本发明具有以下有益效果及优点:
38、1.本发明使用多智能体强化学习具有协作的优点,在原始算法陷入局部最优的情况,多智能体强化学习可以学习如何跳出多目标点和不规则障碍物引起的局部稳定点问题。
39、2.本发明针对多目标点的情况加入自适应域场动态去除多目标点和不规则障碍物引起的局部稳定点问题,同时帮助多智能体强化学习更好学习理解环境的作用。
技术特征:
1.基于改进人工势场的多水下机器人协作方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于改进人工势场的多水下机器人协作方法,其特征在于,所述改进人工势场为障碍物和目标点对水下机器人的引力场、障碍物对水下机器人的斥力场以及水下机器人的域场三场叠加。
3.根据权利要求2所述的基于改进人工势场的多水下机器人协作方法,其特征在于,所述障碍物和目标点对水下机器人的引力场uatt(q)为:
4.根据权利要求2所述的基于改进人工势场的多水下机器人协作方法,其特征在于,所述障碍物对水下机器人的斥力场urep(q)为:
5.根据权利要求2所述的基于改进人工势场的多水下机器人协作方法,其特征在于,所述水下机器人的域场ustr(q)为:
6.根据权利要求1所述的基于改进人工势场的多水下机器人协作方法,其特征在于,所述步骤2),包括以下步骤:
7.根据权利要求6所述的基于改进人工势场的多水下机器人协作方法,其特征在于,所述奖励值r为:
8.根据权利要求6所述的基于改进人工势场的多水下机器人协作方法,其特征在于,所述步骤2.2)包括以下步骤:
9.根据权利要求8所述的基于改进人工势场的多水下机器人协作方法,其特征在于,所述关联程度wj为:
10.根据权利要求8所述的基于改进人工势场的多水下机器人协作方法,其特征在于,所述水下机器人的实时状态xi为:
技术总结
本发明属于水下机器人路径规划领域,具体说是一种基于改进人工势场的多水下机器人协作方法。包括以下步骤:1)根据水下机器人的位置构建改进人工势场;2)基于注意力机制的强化学习在改进人工势场环境中对水下机器人的运动策略进行训练;3)多个水下机器人基于训练好的运动策略进行协作运动,并判断是否到达目标位置,如果到达,则结束运动;否则,更新人工势场,返回步骤1)。本发明使用多智能体强化学习具有协作的优点,在原始算法陷入局部最优的情况,多智能体强化学习可以学习如何跳出多目标点和不规则障碍物引起的局部稳定点问题。
技术研发人员:张奇峰,么庆丰,王聪
受保护的技术使用者:中国科学院沈阳自动化研究所
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!