一种航天器姿态轨道协同优化的智能决策方法与流程
本发明涉及一种航天器姿态轨道协同优化的智能决策方法,属于航天器姿态轨道控制。
背景技术:
1、航天器在轨执行任务过程中,当面临实时性较强的场景,例如时敏事件的监测,或者航天器与所处环境存在复杂交互性的场景,例如对非合作目标抵近操作,航天器的姿态和轨道表现出较强的耦合特性,在确定姿态轨道策略时,如果还是采用传统的解耦设计思想,可能影响航天器执行任务的性能,甚至导致任务失败。然而,由于时敏事件或抵近操作类任务场景下环境的动态不确定性,难以建立有效的解析模型,使得传统基于模型的姿态轨道决策方法难以适用。因此,面向未来复杂空间任务,需要一种不依赖解析模型的智能决策方法,实现航天器姿态、轨道的协同决策。
技术实现思路
1、本发明解决的技术问题是:克服现有技术的不足,提出了一种航天器姿态轨道协同优化的智能决策方法,实现在环境模型未知情况下利用深度强化学习方法进行航天器姿态轨道的协同决策。
2、本发明解决上述技术问题是通过如下技术方案予以实现的:
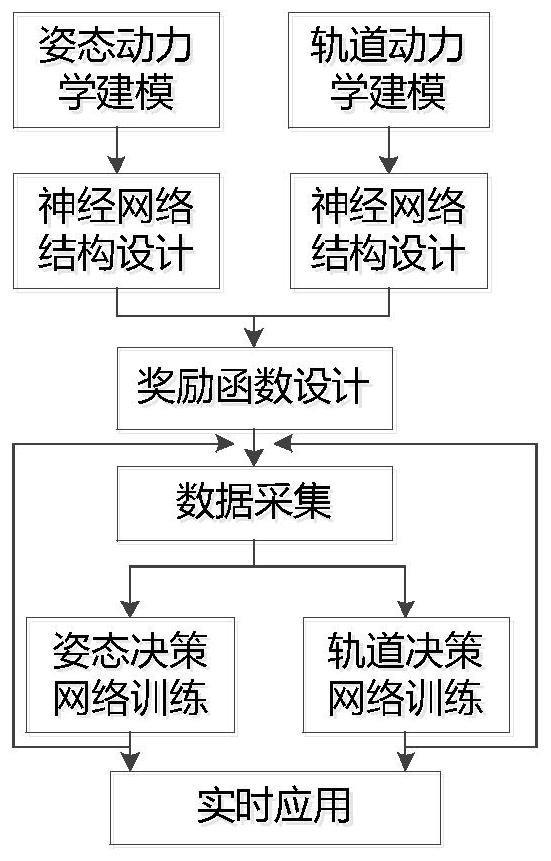
3、一种航天器姿态轨道协同优化的智能决策方法,包括:
4、开展航天器轨道动力学、姿态动力学仿真,以预定的仿真迭代步长,获取航天器相对于预定任务目标的位置、速度、姿态四元素和欧拉角速度;将上述得到的数据、轨道系下太阳的相对位置作为样本池;
5、建立航天器姿轨耦合决策模型,包括姿态决策神经网络、轨道决策神经网络及上述两个决策神经网络进行强化学习的奖励函数算法,姿态决策神经网络、轨道决策神经网络分别生成航天器在轨道系下x、y、z三个方向期望的控制力矩、速度增量,对航天器的姿态、轨道进行控制;
6、以不同的采样频率异步采集样本池数据,分别作为姿态决策神经网络、轨道决策神经网络的训练数据,对上述两个决策神经网络的权值进行迭代更新,完成网络训练,得到训练成功的航天器姿轨耦合决策模型;
7、采集当前待进行预定任务目标监测的航天器相对于预定任务目标的位置、速度、姿态四元素、欧拉角速度以及轨道系下太阳的相对位置,带入训练成功的航天器姿轨耦合决策模型,得到期望的速度增量与期望力矩,驱动航天器进行姿态、轨道变化,实现对预定轨道目标的轨道抵近。
8、优选的,建立轨道决策的神经网络,包括:
9、建立轨道决策神经网络,该网络的输入数据包括航天器相对于预定任务目标的位置和速度、轨道系下太阳的相对位置,输出为航天器在轨道系下的x、y、z三方向期望的速度增量。
10、优选的,建立姿态决策的神经网络,包括:
11、设计姿态决策神经网络,该网络的输入数据包括航天器相对于预定任务目标的姿态四元数、姿态角速度、位置、速度,输出为航天器在轨道系下x、y、z三个方向期望的控制力矩。
12、优选的,所述轨道决策神经网络、所述姿态决策神经网络均为全连接神经网络,网络的激活函数均为relu函数。
13、优选的,奖励函数算法包括公有部分和私有部分:
14、公有部分用于评价预定任务的完成度,对于姿态决策神经网络和轨道决策神经网络的训练是相同的数值;
15、私有部分对于姿态决策神经网络和轨道决策神经网络的训练具有差异性:对于轨道决策神经网络,私有部分设计为与速度增量相关的函数,对于姿态决策神经网络,私有部分设计为与控制力矩相关的函数。
16、优选的,轨道决策神经网络的奖励函数算法为:
17、
18、式中,cosθ为以航天器为顶点、预定任务目标与太阳的夹角,d12为航天器与预定任务目标之间的距离,|δv|为轨道系下x、y、z三个方向速度增量的绝对值之和,|δt|为航天器在x、y、z三个方向期望的控制力矩的绝对值之和,t表示预定任务进行时间,f表示预定任务完成度,t+f为奖励函数的公有部分。
19、优选的,姿态决策神经网络的奖励函数算法为:
20、rew0b2+=c2+|δt|+t+f
21、其中c2为预定任务目标对航天器的影响评估值,|δt|为航天器在x、y、z三个方向期望的控制力矩的绝对值之和,t表示任务进行时间,f表示任务完成度,t+f为奖励函数的公有部分。
22、优选的,将用于姿态决策神经网络的训练数据按照仿真迭代步长的20-100倍时间从样本池中采集,将用于轨道决策神经网络训练的数据按照仿真迭代步长的10000-30000倍时间从样本池中采集。
23、优选的,在网络训练过程中,对航天器的质量、转动惯量、初始状态进行随机初始化,提高姿态决策神经网络和轨道决策神经网络的泛化能力。
24、优选的,将航天器转动惯量、初始位置、初始速度、航天器在轨道系下x、y、z三方向速度增量,带入航天器轨道动力学模型,以预定的仿真迭代步长得到航天器相对于预定任务目标的位置、速度;将航天器质量、初始位置、初始速度、航天器在轨道系下x、y、z三个方向的控制力矩,带入航天器姿态动力学模型,以预定的仿真迭代步长得到航天器相对于预定任务目标的姿态四元素和欧拉角速度。
25、本发明与现有技术相比的优点在于:
26、(1)本发明提供的一种航天器姿态轨道协同优化的智能决策方法,首次提出环境模型未知情况下利用深度强化学习方法进行航天器姿态轨道的协同决策,解决了时敏、强交互场景难以建立精确解析模型导致传统设计方法难以适用的难点问题。当前绝大多数航天器在轨执行任务都工作于确定性环境,主要考虑太阳、地球和自身的相对关系即可,因此利用轨道动力学、刚体姿态动力学,可以获得非常精确的相对关系模型。但是,随着空间任务的复杂程度越来越高,对强实时、高动态、强交互场景下航天器自主执行任务的需求越来越迫切,但是由于未知、高动态环境下航天器与环境的交互模型难以有效建立,使得传统基于模型的设计方法难以适用这类新场景和新任务。本发明基于主动探索自主学习的设计思想,建立了一种深度强化学习框架下航天器姿态轨道的协同决策方法,在训练数据生成、奖励函数设计、网络结构设计方面提出了对应的解决方案,在现有设计方法欠缺的情况下为复杂场景下航天器的姿态轨道协同决策提供了一条可行途径。
27、(2)本发明提供的一种航天器姿态轨道协同优化的智能决策方法,首次提出姿态轨道的异步数据生成方法,解决了姿态轨道决策周期差异大影响训练数据生成效率的问题。常规的强化学习场景中,例如机械臂操控任务,一般不涉及多决策频率的场景,数据采集在统一的规范下进行。但是对于航天器姿态轨道协同决策任务,由于姿态的短周期特点和轨道的长周期累积效应特点,如果还是按照统一的数据采集规范,例如统一按照姿态的决策周期进行采样,那么轨道决策网络的训练时,会存在大量无效训练样本,而如果统一按照轨道决策周期进行采样,那么姿态决策网络训练时,会缺少训练样本。因此,本发明提出姿态轨道异步数据生成方法,为姿态决策和轨道决策分配不同的神经网络,按照不同的频率进行采样,以确保高效地获得姿态决策和轨道决策的神经网络。
技术特征:
1.一种航天器姿态轨道协同下的智能决策方法,其特征在于,包括:
2.根据权利要求1所述的一种航天器姿态轨道协同下的智能决策方法,其特征在于,建立轨道决策的神经网络,包括:
3.根据权利要求1所述的一种航天器姿态轨道协同下的智能决策方法,其特征在于,建立姿态决策的神经网络,包括:
4.根据权利要求1-3任一项所述的一种航天器姿态轨道协同下的智能决策方法,其特征在于,所述轨道决策神经网络、所述姿态决策神经网络均为全连接神经网络,网络的激活函数均为relu函数。
5.根据权利要求1所述的一种航天器姿态轨道协同下的智能决策方法,其特征在于,奖励函数算法包括公有部分和私有部分:
6.根据权利要求1或5所述的一种航天器姿态轨道协同下的智能决策方法,其特征在于,轨道决策神经网络的奖励函数算法为:
7.根据权利要求1或5所述的一种航天器姿态轨道协同下的智能决策方法,其特征在于,姿态决策神经网络的奖励函数算法为:
8.根据权利要求1所述的一种航天器姿态轨道协同下的智能决策方法,其特征在于,将用于姿态决策神经网络的训练数据按照仿真迭代步长的20-100倍时间从样本池中采集,将用于轨道决策神经网络训练的数据按照仿真迭代步长的10000-30000倍时间从样本池中采集。
9.根据权利要求1所述的一种航天器姿态轨道协同下的智能决策方法,其特征在于,在网络训练过程中,对航天器的质量、转动惯量、初始状态进行随机初始化,提高姿态决策神经网络和轨道决策神经网络的泛化能力。
10.根据权利要求1所述的一种航天器姿态轨道协同下的智能决策方法,其特征在于,将航天器转动惯量、初始位置、初始速度、航天器在轨道系下x、y、z三方向速度增量,带入航天器轨道动力学模型,以预定的仿真迭代步长得到航天器相对于预定任务目标的位置、速度;将航天器质量、初始位置、初始速度、航天器在轨道系下x、y、z三个方向的控制力矩,带入航天器姿态动力学模型,以预定的仿真迭代步长得到航天器相对于预定任务目标的姿态四元素和欧拉角速度。
技术总结
本发明公开了一种航天器姿态轨道协同下的智能决策方法,通过建立航天器姿轨耦合决策模型,合理设计奖励机制,根据目标与自身的相对位置、相对速度、相对姿态、相对角速度,在线实时采集数据并训练航天器的决策网络权值,网络输出速度增量和控制力矩,驱动航天器轨道和姿态运动。经过多次迭代,决策网络权值收敛到最优值,输出最优决策策略,使得航天器更好地完成轨道抵近任务。
技术研发人员:黄煌,袁利,汤亮,刘磊,张聪,耿远卓,马亮,王英杰
受保护的技术使用者:北京控制工程研究所
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!