用于无人系统的避障系统及避障方法与流程
本发明涉及无人系统避障,尤其涉及一种用于无人系统的避障系统及避障方法。
背景技术:
1、通常,智能无人系统搭载各类传感器获取周围环境数据,需要借助避障算法获取障碍物的实时状态信息,进而传递至决策控制系统进行路径规划和实时避障,因此,行之有效的避障策略保障了无人系统行进过程中的安全性,具有重要的研究意义。
2、一些避障算法要求采用激光雷达、结构光或声呐等主动式传感器获取精确的障碍物深度,然而此类传感器成本高、重量大、测距范围较小且功耗高,难以满足实际场景的应用需求。
3、近些年,随着深度学习理论和硬件设备的发展,使用深度神经网络自适应提取的图像深度特征已被证明显著优于sift、hog和lbp等人工设计特征,在目标检测、分割和深度预测等视觉任务中取得卓越表现,并在无人系统避障设计的研究方面取得一定进展。现有基于图像的避障方法中,通常结合目标检测、语义分割等算法给出的结果寻找可通行区域实现避障。
4、现有传统避障方法可分为基于全局路径规划与基于局部防碰撞2类,前者方法假设全局障碍信息已知,随后规划出一条由起始点到目标点的可达路径,如遗传、智能群和a*/d*等启发算法,适用于规避静态障碍物;后者方法不依赖于全局信息,是一类实时地、局部的防碰撞算法,常见方法有基于制导率、基于速度障碍法和基于人工势场法等。
5、这些方法虽然在特定场景下可以完成避障任务,但在稳定性和适用性方面易受环境影响,鲁棒性差且计算过程较为复杂。基于图像深度学习的避障方法并未顾及无人系统的几何形状,导致避障方法的实用性受限。基于深度强化学习的避障方法,如深度q学习网络等,是一种建立在奖惩机制之上根据已发动作指令的反馈学习避障决策的方法,使无人系统逐渐具备全局规划与路径寻优的能力,且无需依赖人类经验和先验规则干预。然而需要根据实际任务和传感器数据设计合理的奖励函数,受限于样本规模和学习效率,目前大多数研究主要集中于仿真环境,推广到现实环境仍有待进一步研究。
技术实现思路
1、本发明要解决的技术问题是如何实现无人系统的可靠避障,本发明提出一种用于无人系统的避障系统及避障方法。
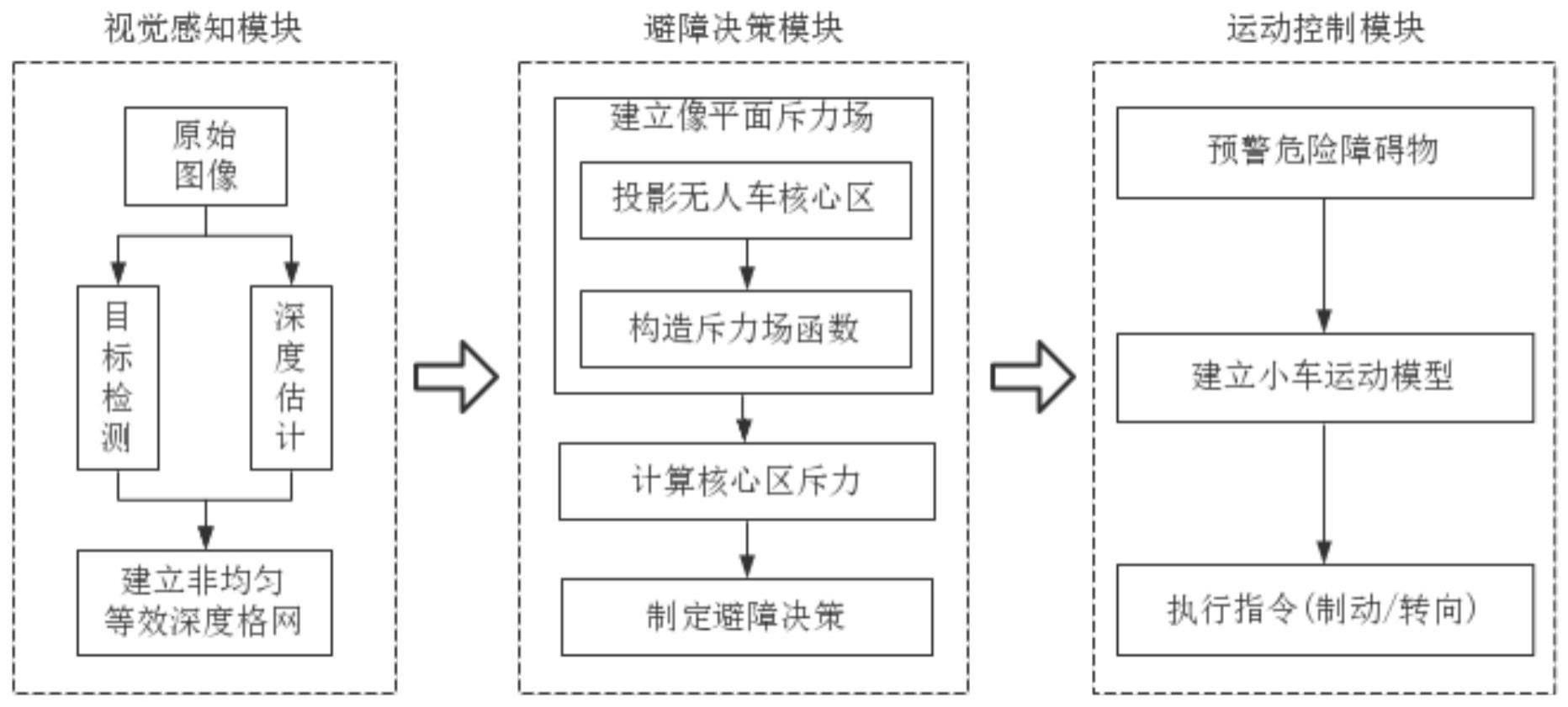
2、根据本发明实施例的用于无人系统的避障系统,包括:
3、视觉感知模块,用于为无人系统探测障碍物的类别、像素位置及深度,并进行融合计算,建立非均匀等效深度网格;
4、避障决策模块,用于将无人系统的几何形状投影到像平面构成核心区,构造斥力场计算所述核心区受到的斥力合力,并根据所述斥力合力提供避障决策;
5、运动控制模块,用于负责对潜在造成危险的障碍物进行预警,同时根据无人系统运动模型,基于避障决策执行避障动作。
6、根据本发明实施例的用于无人系统的避障系统,组成模块成本低,且能使无人系统有效、可靠地实现避障。
7、根据本发明的一些实施例,所述视觉感知模块包括:目标检测网络和深度估计网络。
8、在本发明的一些实施例中,所述视觉感知模块采用yolov5s目标检测网络在单目图像中探测障碍物的类别和像素位置,所述视觉感知模块采用单目深度估计开源工具实现对障碍物深度的预测。
9、根据本发明的一些实施例,利用所述单目深度估计开源工具在预设数据集进行迁移学习,使所述视觉感知模块基于单目图像实现对障碍物的深度预测。
10、在本发明的一些实施例中,所述无人系统包括无人车,所述障碍物包括:行人、车辆和信号灯。
11、根据本发明实施例的无人系统的避障方法,所述避障方法采用如上所述的用于无人系统的避障系统实现无人系统的避障,所述避障方法包括:
12、s10,探测障碍物的类别、像素位置和深度,并进行融合计算,获取非均匀等效深度网格;
13、s20,将无人车投影到成像空间,建立核心区;
14、s30,构造关于障碍物深度和进入核心区面积的斥力场函数,计算障碍物对核心区中心的斥力大小和方向;
15、s40,计算所有障碍物对核心区斥力合力,并根据所述斥力合力确定避障决策;
16、s50,根据无人系统运动模型,结合斥力合力,由算法给出偏航角和线速度,指导无人系统进行动态避障。
17、根据本发明实施例的无人系统的避障方法,具备成本低、轻量化、低延迟的优点。本发明融合了目标检测与单目深度估计两种视觉感知网络确定障碍物的类别、像素位置和距离,并依据针孔成像原理严格推导了三维空间与成像平面空间的约束关系,基于此改进传统人工势场法,建立像平面斥力场,最后综合分析感知结果指导无人车完成对车辆、行人等目标的避障任务。
18、根据本发明的一些实施例,步骤s10具体包括:
19、s11,用yolov5s目标检测网络在单目图像中探测障碍物的类别和像素位置;
20、s12,利用深度估计网络预测出像素级别的单目密集深度图;
21、s13,以障碍物的探测框为边界在图像中建立非均匀格网,并在每个网络区域中确定障碍物的等效深度,实现障碍物位置和深度信息的融合。
22、在本发明的一些实施例中,步骤s20中,依据相机针孔成像模型推导投影公式,通过所述投影公式将无人系统几何体投影到成像空间。
23、根据本发明的一些实施例,步骤s40中,当斥力合力大小不为零且方向水平向左,则控制无人系统向左转向实施避障;
24、当斥力合力大小不为零且方向水平向右,则控制无人系统向右转向实施避障;
25、当斥力合力大小为零,则判断核心区内等效深度小于安全距离的格网面积s,若s大于零,则无人系统采取制动,若s等于零,则无人系统保持当前运动状态。
26、根据本发明的一些实施例,步骤s50中,偏航角可由核心区内障碍物与核心区边界的最大水平距离推算得到,线速度由制动力和水平斥力共同决定,直到解除避障后,再使无人系统回归到全局规划的航线。
27、在本发明的一些实施例中,所述避障方法用于所述无人系统的实时动态避障。
技术特征:
1.一种用于无人系统的避障系统,其特征在于,包括:
2.根据权利要求1所述的用于无人系统的避障系统,其特征在于,所述视觉感知模块包括:目标检测网络和深度估计网络。
3.根据权利要求1所述的用于无人系统的避障系统,其特征在于,所述视觉感知模块采用yolov5s目标检测网络在单目图像中探测障碍物的类别和位置,所述视觉感知模块采用单目深度估计开源工具实现对障碍物深度的预测。
4.根据权利要求3所述的用于无人系统的避障系统,其特征在于,利用所述单目深度估计开源工具在预设数据集进行迁移学习,使所述视觉感知模块基于单目图像实现对障碍物的深度预测。
5.根据权利要求1-4中任一项所述的用于无人系统的避障系统,其特征在于,所述无人系统包括无人车,所述障碍物包括:行人、车辆和信号灯。
6.一种无人系统的避障方法,其特征在于,所述避障方法采用如权利要求1-5中任一项所述的用于无人系统的避障系统实现无人系统的避障,所述避障方法包括:
7.根据权利要求6所述的无人系统的避障方法,其特征在于,步骤s10具体包括:
8.根据权利要求6所述的无人系统的避障方法,其特征在于,步骤s20中,依据相机针孔成像模型推导投影公式,通过所述投影公式将无人系统几何体投影到成像空间。
9.根据权利要求6所述的无人系统的避障方法,其特征在于,步骤s40中,当斥力合力大小不为零且方向水平向左,则控制无人系统向左转向实施避障;
10.根据权利要求6-9中任一项所述的无人系统的避障方法,其特征在于,所述避障方法用于所述无人系统的实时动态避障。
技术总结
本发明提出了一种用于无人系统的避障系统及避障方法,避障系统包括:视觉感知模块、避障决策模块及运动控制模块,视觉感知模块用于为无人系统探测障碍物的类别、像素位置及深度,并进行融合计算,建立非均匀等效深度网格表示障碍物状态;避障决策模块用于将无人系统的几何形状投影到像平面构成核心区,构造斥力场计算核心区受到的斥力合力,并根据斥力合力提供避障决策;运动控制模块用于负责对潜在造成危险的障碍物进行预警,同时根据无人系统运动模型,基于避障决策执行避障动作。本发明具备成本低、轻量化、低延迟的优点,能够对行人、车辆等障碍物进行实时检测,并能指导控制无人系统进行有效、可靠避障。
技术研发人员:刘鑫,纪宇航,王礼贺,蔡文婧
受保护的技术使用者:中国电子科技集团公司第十一研究所
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!