一种基于深度强化学习的局部路径规划方法
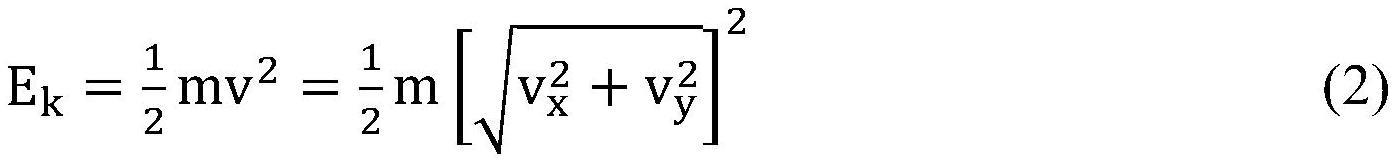
本发明属于移动机器人路径规划,具体是涉及一种基于深度强化学习dueling double dqn算法的路径规划方法。
背景技术:
1、工业4.0概念被提出后,工业智能化的需求被重新定义。其中智能工厂、智能生产与智能物流的实现无一例外都需要自动化机器人的参与。自动化机器人需要机器人自主做出决策,移动是机器人的基本功能之一。因此需要机器人独立完成导航功能。如今它被广泛应用在医学、工业、航天、救援任务以及军事等领域。尤其在近年全球大环境下,如何避免人与人之间的接触完成送隔离餐、核酸检测等任务成为了研究热点。有关机器人的路径规划方面的研究正在如火如荼的进行着。
2、移动机器人路径规划的目标是通过环境感知与主动避障功能找到一条可行的最佳路径,此路径从起始点至终点在给定的工作空间中不与任何障碍物相交,同时要优化机器人运动路径,使其尽可能达到更短、更平滑的要求。可以通过对环境信息掌握的程度来将路径规划分为全局路径规划和局部路径规划。根据环境信息判断使用何种路径规划方法至关重要。路径规划算法分为传统算法与智能算法,传统算法需要先验环境信息才能进行路径规划;而智能算法这类中的深度强化学习算法通过学习经验,可以在未知环境下进行探索能更好的进行实时路径规划。
3、强化学习算法对环境依赖程度低、能够快速适应周围环境。mdp是强化学习问题在数学上的表示,而路径规划是天然的马尔可夫决策过程,因此强化学习非常适合处理路径规划问题。其中具有代表性的算法就是q-learning算法。首先,它是无模型算法,不需要预先知道关于环境的信息,智能体通过与环境交互来获取有关环境的信息。其次,智能体进行在线训练,并将每个动作的奖惩情况存储在表格中。通过使用q-learning算法更新表,智能体的“经验”开始积累,其计算效率高且不需要先验模型。不幸的是,它有泛化能力差、收敛速度慢且不适用高维环境等缺点。
4、为了解决高维环境下或来纳许动作中大量数据带来的内存爆炸问题,deepmind提出了dqn算法,它将神经网络与q-learning结合,利用神经网路为动作生成q值,把q表的更新问题变成一个函数拟合问题,这是首次将强化学习与深度学习结合起来被称为deepreinforcement learning(drl)。d3qn算法在未知环境下的局部路径规划表现很好。然而d3qn在进行价值评估时由于环境的随机性和神经网络的不确定性,导致目标值的逼近误差不断增大。而且d3qn在采样时采用均匀采样方式,导致智能体忽视重要的学习经验。综上所述,基于d3qn方法的路径规划技术存在两个主要问题:1)数据利用率低;2)算法的探索策略简单难以在复杂的环境使用。
技术实现思路
1、针对基于d3qn算法的路径规划方法存在的不足,本发明的提出一种样本高效的在未知动态环境下进行路径规划的方法,它同时能够在稀疏奖励的环境或者没有充分的奖励函数指引的情况下提供有效的探索。
2、本发明提供了一种基于一种基于深度强化学习框架的局部路径规划方法,所述方法步骤如下:
3、步骤1:确定机器人的初始位置与目标点的初始位置,初始化相关参数;
4、步骤2:初始化评估神经网络参数θ和目标网络参数θ',经验回访池r以及ε-greedy探索策略的初始概率与最小概率以及经验池的大小m。
5、步骤3:机器人通过激光雷达获取的数据和障碍物的距离以及角度等数据作为状态s。将专家经验存储到经验回放池中,并从中抽样一个目标g作为作为初始状态s0。
6、步骤4:在当前回合中,使用行为策略从动作集合中采样一个动作a。智能体执行动作at得到新的状态值st+1。
7、步骤5:根据(st,at,g)计算出奖励rt,得出一条transition(st||g,at,rt,st+1||g,p)。将该transition存入到经验回访池r。
8、步骤6:结合课程学习,根据自适应步长优先函数计算出每条轨迹的难度,赋予不同的优先级。基于轨迹优先级p(τ)从经验回访池中采取对应的轨迹,再从该轨迹中采样transitions(st,at,st+1,done)。在轨迹τ的未来某个时间步中采样虚拟目标g’={st+1,...,st-1}。
9、步骤7:根据均方误差损失函数公式计算出损失值,并使用小批量随机梯度下降法更新评估网络的网络参数θ。
10、步骤8:每隔一定时间步将评估网络的网络参数θ硬更新方式赋值到目标网络的网络参数θ’。
11、步骤9:以ε的概率随机选择q值对应的动作执行,以1-ε的概率选择最大q值的动作a作为动作策略执行。
12、步骤10:若第t步移动机器人位置状态未到达目标点状态则重复步骤2~步骤9,否则判断episode是否到达网络训练总episodes,若未到达网络训练总episodes则重复步骤1~步骤9,若达到网络训练总episodes则结束训练,并根据移动机器人选择的最大q值动作,规划出从起点到达终点的路径,算法结束。
技术特征:
1.一种基于深度强化学习框架的局部路径规划方法,其特征在于,所述路径规划包括如下步骤:
2.根据权利要求1所述的一种基于深度强化学习框架的局部路径规划方法,其特征在于:所述步骤1的所初始化的相关参数为:
3.根据权利要求1所述的基一种基于深度强化学习框架的局部路径规划方法,其特征在于,所述步骤4中动作的采样公式为:
4.根据权利要求1所述的基一种基于深度强化学习框架的局部路径规划方法,其特征在于,所述步骤4中的计算transition能量的方法如等式2所示:
5.根据权利要求1所述的基一种基于深度强化学习框架的局部路径规划方法,其特征在于,所述步骤6中自适应步长优先函数为:
技术总结
本发明公开了基于深度强化学习的局部路径规划方法,针对目前路径规划难以应用在未知动态环境的问题。它通过激光雷达获取环境数据作为输入,使用神经网络拟合Q值输出对应的离散动作。本发明在基于价值的深度强化学习Dueling Double DQN(D3QN)框架,实现了一种在未知动态环境下进行局部路径规划的新颖和高效的方法。与现有算法比较,有以下优点:(1)训练前在经验回放池中加入专家样本并同时引入动量作为优先级评价标准改进优先经验回放方法提高数据利用率。(2)基于现实世界的动量考虑了物理因素,使得方法更加契合真实机器人的规划。(3)将规划任务分解成多任务的同时引入Hindsight Experience Replay(HER)解决稀疏奖励下环境探索困难的问题。
技术研发人员:殷焱,陈志雨,郭建伟,刘钢,胡艳鑫,尹家松
受保护的技术使用者:长春工业大学
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!